面向监控视频的人群异常事件检测综述
2023-03-24黄少年文沛然全琪
黄少年 文沛然 全琪
关键词:人群异常事件;深度学习;无监督学习
0 引言
由于人群聚集的情况经常在各种城市公共场所中出现,一旦在人群聚集的公共场所出现突发异常事件,很容易造成因人群拥挤引发的灾难性事件。另一方面,随着视频监控系统的日益普及,基于监控视频内容分析技术对公共场所的人群行为进行分析、挖掘和管理成为可能。因此,分析并建模城市公共场所下密集人群的行为动态,预警并检测人群场景的突发异常事件,避免人群灾难性事件的发生,成为亟待解决的一个研究课题。
本文从监控视频场景下的人群异常事件检测的定义出发,对现有的视频异常检测方法进行综述,详细阐述了其研究现状及各类方法的优劣,介绍视频异常检测常用的数据集及评价指标,最后面向监控视频的人群异常检测的未来的发展方向进行总结和展望。
1 人群异常事件检测概述
1.1 人群异常事件定义
面向监控视频的人群异常事件检测技术是指:从海量监控视频数据中检测出与大多数人不一致的少量异常事件。如:在养老院等机构的监控系统中,实现对老人跌倒事件的远程监控;在机场、车站以及地铁站等公共安防监控系统,检测打架斗殴、异常奔跑、包裹滞留以及逃票等异常事件;在智能交通监控系统中,实现对超速、闯红灯、逆行等交通违章事件的检测等;在不同的人群场景下,其人群异常事件的含义可能不同。
1.2 人群异常事件分类
根据应用场景的不同,现有研究将通常把人群异常事件分成4种类型[1]:
(1) 外观异常。如:人行道上的骑自行车者,或马路上的障碍物。
(2) 短期运动异常。这类异常可被认为是场景中不寻常的物体运动。如:一个人在图书馆跑步。
(3) 长期轨迹异常。这类异常通常在场景中具有不寻常的物体轨迹。如:在人行道上拐来拐去的人,或在车流中不断加塞的汽车。
(4) 群体异常。这类异常在场景中具有不寻常的相互作用。如:一群人突然向四周跑动。
2 基于深度学习的视频异常检测方法
相较于计算机视觉领域其他检测任务,视频异常事件检测任务的挑战性在于:异常事件定义具有场景依赖性、异常事件的稀少性、异常样本的不确定性及视频信息的多样性[2-3]。不同于图像以及文本数据,视频数据不仅仅具备空间信息同时也具备极强的时序信息。伴随着深度学习的发展,针对视频异常检测任务所面临的挑战,利用深度学习方法可以在一定程度上弱化异常检测任务对场景地依赖性,增加模型的泛化能力。同时,无监督的方法也能一定程度上解决样本不均衡引发的问题。目前,利用无监督的深度学习方法对视频进行异常事件检测已成为主流的研究趋势。现有的无监督视频异常检测方法可大致分为基于重构的方法、基于预测的方法及混合方法。
2.1 基于重构的方法
基于重构的方法通常假设异常事件具有较高的重构误差,并根据重构误差的阈值判断异常。该类方法基于大量的正常样本训练网络,学习正常事件的特征模式;测试时,由于异常事件模式难以被网络很好的重构,生成较大的重构误差,从而被判定为异常。
自动编码器(Auto Encoder,AE) 是基于重构方法的常见结构,通过采用编码器提取正常事件模式进行编码,采用解码器将编码后的特征表示解码回它的原始形式,形成对正常事件进行重构。Hasan等[4]通过训练全连接自动编码器进行视频序列重构,并基于重构误差计算异常分数。Luo等[5]则采用卷积长短期记忆网络(Convolutional Long Short Term Memory , ConvLSTM)) 作为卷积AE的主干结果进行视频序列重构。Hu等[6]提出了一种时空融合的视频异常检测方法。首先通过对象检测网络进行对象提取,然后提取光流信息和可视信息,并基于时空双流网络进行视频帧的重构。Ber?gaoui等[7]提出了一种以对象为中心的正常事件模式学习模型,采用基于对象动作特征的cosine距离函数进行异常估计,并在重构框架引入了几何限制。通过记忆模块平衡对象的外观信息和运动信息,从而捕获事件的原型模式。Wang等[8]针对现有基于重构方法的时序依赖性差和训练样本过拟合问题,提出时空Trans?formmer编码器进行连续帧重构。采用可学习的卷积自注意力模块学习时序相关性。在测试过程中提出了一种新的基于重建的输入扰动策略,以进一步区分异常帧。Ouyang等[9]提出了一种无需离线训练模型的视频异常检测方法。采用随机初始化多层感知机的方法进行视频帧重构。基于相邻帧间的信息偏移,采用增量学习进行参数更新,在线训练模型。
除AE模型之外,生成对抗模型GAN和变分编码器模型VAE也被引入到视频异常检测问题中。Rav?anbakhsh等[10]提出了基于GAN的視频异常检测方法, 基于对抗损失生成器与判别器, 使得异常帧具有较大的重构误差。Dong等[11]提出了一种双判别器生成对抗网络,基于半监督学习方式进行视频异常检测。Feng等[12]针对视频异常检测中正常模式的时空有效性问题,提出了基于双对抗生成网络的卷积Trans?former模型。Fang等[13]提出了一种基于全卷积VAE的端-端视频异常检测框架,基于高斯混合模型对正常事件模式进行编码,并采用双流网络提取视频的可视特征及运动特征进行异常检测。
2.2 基于预测的方法
由于异常可以被视为不符合某些预期的事件,研究者认为基于预测的方法可能是看待异常检测问题的更自然的方式。基于预测的方法采用过去一段时间内视频帧的特征预测当前帧;为增强预测效果,通常基于视频帧间的时序依赖性增强特征表示。
Huang等[14]基于帧可视信息与光流运动信息的一致性进行视频异常检测。采用双流编码器编码可视信息与运动信息,并引入一致性损失增强语义特征的一致性,从而使得具有较低可视、运动信息一致性的异常事件能被检测。最后,结合一致性损失与预测损失进行异常检测。Leery等[15]提出了一种自监督的同步预测模型。与现有的单帧预测方法不同的是,该模型可以一次性预测连续帧中的遮挡帧,因此该模型可以充分考虑视频的上下文信息。这种同时进行自我监督的未来帧预测有助于模型产生预测输出更加接近训练数据分布,而不是简单地学习特征函数,从而缓解了泛化的问题。针对基于重构的方法均假设异常事件具有较大的重构误差的问题,Zhao等[16]设计了卷积LSTM自动编码器预测网络增强时空记忆交换。双向网络结构通过前向预测和反向预测学习时序规律,独特的高阶机制进一步加强了编码器和解码器之间的空间信息互动。并采用注意力模块进行预测。针对现有工作现有考虑帧级局部一致性以及时序动态的全局相关性问题,Feng等[17]提出了基础双生成对抗网络的卷积Transformer模型。首先采用卷积Trans?former进行将来帧预测;再采用双生成对抗网络进行训练,该网络判别器在保持图像帧局部一致性的同时,增强视频的时序全局一致性。
基于预测的视频异常检测方法可以对运动信息进行建模,并且可以学习到不同类型的时空依赖。但这类方法局限于序列数据异常检测,并且序列预测的计算成本高,由于其潜在目标是序列预测而不是异常检测,因此学习的结果可能是次优的。
2.3 混合方法
部分研究者采用混合方法实现视频异常检测,取得了较好的检测效果。Cao等[18]提出了一种根据测试事件和正常事件知识一致性的异常事件检测方法,采用基于上下文恢复和知识检索的双流框架进行异常检测。在上下文恢复分支中,采用时空U-Net网络预测将来帧,并提出了最大恢复误差机制缓解由前景对象引起的较大恢复误差问题。在知识检索分支中,采用Siamese 网络和交互差异损失,基于可学习的locality-sensitive hashing 策略,从而编码正常事件知识并存储在hash表中。测试事件和知识表示的差异被用来进行异常检测。Wang等[19]提出了一种基于时空拼图的视频异常检测方法,将视频异常检测问题作为一个多标签的细粒度分类问题来解决。时空拼图分别负责捕捉高辨识度的外观和运动特征。完整的排列组合被用来提供丰富的涵盖不同难度的拼图,使网络能够区分正常和异常事件之间微妙的时空差异。Barbalau等[20]提出了一种基于多任务自监督学习的视频异常检测框架。首先采用Yolov3进行目标检测,并采用卷积transformer网络作为主干网络。同时,引入自监督学习任务提升模型性能,如:通过知识蒸馏解决拼图问题,预测人体姿态等。
基于预测重构的混合方法也引起了研究者的兴趣。Liu等[21]提出了一种基于记忆增强重构和光流帧重构的视频异常检测方法,首先进行可视特征及预测特征的重构,然后采用条件变分自动编码器进行帧预测。Morais 等[22]则基于行人的骨架轨迹特征同时进行预测和重构,并学习正常时间模式。Zhao等[23]提出了一种时空自动编码器(STAE) ,并同时采用重构损失和预测损失训练3D卷积网络。Ye等[24]提出了基于预测编码网络的视頻异常检测方法,引入误差修正单元对预测误差进行重构,从而提升预测精度。以上基于预测重构混合的方法均取得了较好的检测性能,但模型较复杂。
3 常用数据集与评价标准
3.1 常用数据集
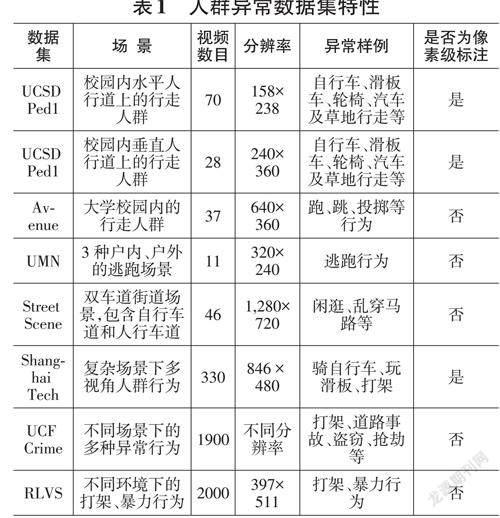
基准数据集在计算机视觉任务中起到重要作用,包括:定义问题范围、为算法性能比较提供途径等。基准数据集的建立需要考虑数据集大小、数据大小、标签数据的可获得性及数据多样性等多种因素。由于实际监控场景中,人群的异常活动较少见,因此,人群异常行为基准数据集的数量较少。常见的人群异常基准数据集包括:UCSD行人数据集①、Avenue数据集② 、UMN 数据集③ 、Street Scene 数据集④ 、ShanghaiTech数据集⑤、UCF Crime数据集⑥、RLVS数据集⑦。本文从数据集场景、视频数目、分辨率、异常样例、是否包含像素级标注等方面对以上数据集进行描述,表1 展示了常见人群异常数据集的具体特性。
3.2 评价标准
通常来说,人群异常检测和定位的性能评估标准有3种:(1)帧级标准:以帧为单位判断帧中是否存在异常;(2) 像素级标准:至少40%真实异常区域的像素被检测为异常;(3) 双像素级标准:至少10%真实异常区域的像素被检测为异常。人群异常检测的定量评价指标则一般采用接收器操作特性曲线(receiver oper?ating characteristic curve,ROC) 及其对应的曲线下面积(Area Under Curve,AUC) 两种形式[25]。此外,等错误率(Equal Error Rate,EER) 也被用来作为异常检测评价的性能指标,EER 是指当假阳性率(False PositiveRate,FPR) 等于假阴性率(False Negative Rate失误率)时,被错误分类的帧的百分比。
最近,一些研究者还提出了基于区域的异常检测标准和基于轨迹的异常检测标准[26]。基于区域的检测标准即计算所有异常区域被正确检测的比率;而基于轨迹的检测标准则计算行人异常轨迹被正确检测的比率。以上两种评价标准均需要进行异常区域和异常轨迹的标注,且同样采用ROC和AUC进行定量评价。
4 总结
人群异常事件检测是现阶段视频监控领域的重要应用,本文对基于深度学习的人群视频异常检测问题的常用方法、主流数据集及评价标准进行了概述。基于深度学习的异常行为检测在常用数据集上展现出优异的性能,展现出深度学习模型在人群异常事件检测中的巨大优势。但多数模型仅针对特定场景下的异常检测,更具泛化性能的模型有待进一步研究。
