一种面向肥胖人群的无袖带血压测量方法研究*
2023-03-23李清福赵宇波赵景波蒋泽宇
李清福,赵宇波,赵景波,蒋泽宇
(1.青岛理工大学信息与控制工程学院,山东青岛 266520;2.山东产业技术研究院(青岛),山东青岛 266101)
0 引言
研究显示,肥胖是引起高血压的主要因素,且在肥胖人群中,高血压发病率高于同年龄的正常群体的一倍,年龄越大比例越高[1]。因此,准确测量肥胖人群的血压,对及时发现和治疗高血压非常必要。目前有3 种比较主流的无创血压测量方法:台式水银血压计测量法,示波器电子血压计测量法[2],基于光电容积脉搏波(PPG)测量血压法。前两个方法都是通过对袖带气囊的充放气实现对血压的测量,目前市面上使用的袖带过短,找到适合肥胖人群的袖带成为一种问题[3]。因肥胖人群胳臂粗大,有可能得到不正确的血压值。因此为了摆脱袖带的束缚,基于光电容积脉搏波(PPG)技术测量血压的方法应运而生,其具有成本低廉、容易采集等优点,成为最近几年研究的重点[4]。
2017 年,Miao 等[5]利用线性回归模型结合PPG 信号中的14 个特征参数进行血压测量,虽然降低了舒张压的平均误差,但该方法舍弃了对血压非线性影响的特征参数,导致总体上对收缩压测量精度不高。2018 年,Syed等[6]使用昆山兰大学采集的包含年龄、性别、身高等生命体征数据集,提取原始PPG 信号及其相应的收缩压和舒张压,分别建立回归树、多元线性回归、支持向量机(SVM)模型,发现加入生命体征信息之后,回归树模型可以使血压测量结果达到AAMI 标准。同年,Wang 等[7]建立多参数的人工神经网络模型(ANN),将PPG 特征反馈给多层感知器结构,该结构有22 个输入神经元和2个输出神经元,以同时估计SBP 和DBP,虽然获得了更好的精度,却耗费了时间成本和内存成本。2019 年,吴绍武等[8]通过提取PPG 信号中(如波谷与波峰的水平距离、纵向距离、斜率等)15 个特征参数,建立lightBGM模型,且在原有特征参数的基础上加入历史血压,提高了舒张压测量精度,但因测试数据不一致,使得收缩压测量精度比线性回归模型差。2020 年,贺楚芳[9]基于PPG 信号的形态学特征并结合生命体征信息,建立极端随机树和随机森林血压测量算法,发现与线性模型的拟合程度相比,非线性模型的性能更好。
近几年针对PPG 信号进行血压测量的研究存在两个缺陷:(1)很多研究基本上都是用单一机器学习算法模型进行训练,而将集成机器学习方法应用于血压测量的相关研究非常少,导致血压测量效果不好;(2)很多算法都是对全部人群的血压测量数据进行模型训练,没有把肥胖人群分开。有研究表明,用此算法测量肥胖人群的收缩压时,其结果普遍偏低[10]。这就造成一个问题,由于肥胖人群特殊的情况,血压测量不准确可能会错过高血压的最佳治疗时间,造成不可忽视的后果。因此,本文在前人研究的基础上,构建基于Stacking 集成机器学习模型,在提取的43 个特征参数的基础上,把BMI 的数值作为新的特征参数加入到模型中,分别对非肥胖人群(BMI<25)和肥胖人群(BMI>25)数据集进行模型训练,并与文献[5]、文献[8]、文献[9]用到的机器学习方法进行结果对比,构建对肥胖人群血压测量有着更高精度的算法模型。本文的主要的创新点如下。
(1)选用多功能参数仪,设计采集实验,采集志愿者的PPG 信号和真实血压值,然后依次进行降噪处理、特征参数提取,建立了区别于目前大多数研究使用的MIMIC血压数据集的新数据集。
(2)整合K近邻、极端随机树、lightGBM、线性回归单一机器学习模型,提出基于Stacking 集成机器学习血压测量模型,弥补了单一模型的不足。
(3)将人群分类研究,把训练数据分成非肥胖人群(BMI<25)和肥胖人群(BMI>25),并把BMI 数值作为特征输入,提高了肥胖人群的血压测量精度。
1 实验数据集建立
目前很多研究使用的MIMIC-II 数据集虽然包含心血管患者的PPG 信号波形以及血压值[11],但是因其信号失真严重,处理起来难度大,且缺乏患者的身高、体重、年龄等生理信息,故需建立一个更适合本算法的数据库。
1.1 PPG原理
光电容积脉搏波描记法(PPG)以Lambert-Beer 定律作为理论基础,其数学表达式为:
式中:A为吸光度;T为透过血液容积的强度It与入射光强度I0的比值;a为吸收系数;b为吸收层厚度;c为血液的浓度[12]。
基本原理:当红蓝光照射到如手指等皮肤时,骨骼、肌肉等组织对光的吸收基本不发生改变,而心脏的搏动是有节奏的,血液随着心脏搏动运输各种人体所需的营养物质的过程中,动脉血管的血液容积不断发生改变。利用光电传感器测量到此种变化,然后经信号转换形成光电容积脉搏波信号(PPG 信号)。通过相关算法提取PPG 信号中的特征参数并与真实血压值进行回归分析,就可以得到血压值与特征参数之间的算法模型[13]。
1.2 PPG信号采集
本研究使用某公司研发的多功能参数仪采集了某小区540 位年龄在25~80 岁的健康志愿者的PPG 信号以及使用鱼跃水银血压计采集了真实血压。告知每位志愿者在参加测试之前不做剧烈运动,不饮用可乐、咖啡、酒水等影响心血管系统的饮品。志愿者将个人体征信息填写完毕之后,处于静坐姿势,然后佩戴仪器开始采集PPG 信号和真实血压值。以每天11:00-12:00、14:00-15:00、17:00-18:00 为固定的采集时间,每次测量时长为3 min,连续测量半个月并做好记录。然后整理所有实验数据以矩阵的形式存放在Matlab 的mat 文件中,该数据集由矩阵的单元格cell阵列组成,每个单元格cell都是一个矩阵形式,将其命名为RAWDATA。
1.3 信号预处理
在采集过程中,因测试者操作不当或身体的抖动,导致早期PPG 信号含有毛刺、高频噪声和基线漂移等噪声干扰[14]。为了得到纯净的PPG 信号,需要对RAWDATA 数据进行预处理。因II型切比雪夫滤波器的幅频特性具有等波纹特性,且冲激响应不变[15],因此为了保证PPG 信号的完整性,使波形形状不发生任何变化,选用II 型切比雪夫滤波器,滤波器参数截止频率FC、高通频率FH、低通频率FL、频率响应的纹波PR依次设置为FC= 0.4 Hz、FH= 50 Hz、FL= 0.2 Hz、PR= 5,然后用Matlab 软件进行验证和仿真,选取10 s 采样样本,滤波后纯净的PPG信号如图1所示。

图1 滤波后纯净的PPG信号
1.4 特征参数提取
PPG 信号反映了人体心血管健康状况,其中含有的生理信息与血压有很大关联[16],因此在建立血压测量算法模型之前,需要对滤波后的PPG 信号进行特征参数提取。具体做法参考文献[17]使用五点平滑、二阶导数最大值以及数值微分法,对Y 区域进行特征参数提取,如图2所示。

图2 PPG信号特征提取示意图(Y区域)
特征参数主要包括:PPG 信号的谷值点(A点)、上升沿中心点(B点)、峰值点(C点)、重搏波节点(D点)的幅度A-amp、B-amp、C-amp、D-amp,收缩时间T1、峰值点(C点)和重搏波节点(D点)的时间间隔T2,舒张时间T2+T3、重搏波节点(D点)和PPG 信号结束点(E点)的时间间隔T3,整个心动周期T4,A点与C点之间的面积S1等。
除了以上提到的时域特征外,还有一阶导数极值参数、二阶导数极值参数等一共43 个特征参数。去掉其中的异常数据和空白信息之后,最终保留5 238 条包含年龄、性别、身高、体重、特征参数、真实血压的数据,保存为CSV 格式,以此作为算法模型的数据集。编号为cstcn40480 志愿者的部分特征参数如表1 所示。模型搭建、数据集人群分类以及实验结果将在接下来的章节中介绍。

表1 志愿者cstcn40480的部分PPG特征参数
2 基于Stacking血压测量模型
Stacking 集成学习利用了组合策略的思想,将多个算法模型组合到一起形成一个更强的模型。在回归问题中,第一层个体学习器(初级学习器)先在训练集中单独训练,再在测试集中分别输出各自的训练结果,然后将输出结果作为第二层个体学习器(次级学习器)的输入进行模型训练,这样做可以使不同个体学习器的能力得到叠加,输出一个测量精度更高的结果[18]。
2.1 初级学习器选择
文献[8]将历史血压加入到lightGBM 算法模型中,文献[9]构建极端随机数模型并结合生命体征信息均得到不错的实验结果。一致说明某些生命体征信息在传统机器学习算法测量血压的过程中可以发挥很大作用。故本研究采用极端随机树、lightGBM、KNN 算法模型作为初级学习器,同时加入身体质量指数(BMI)来训练和测试数据集。
K近邻回归(KNR):是比较经典的机器学习算法,由于其训练时间少,又被称作懒惰学习算法[19]。由于一个人的正常血压值随着时间不断发生变化,故利用K 近邻进行血压测量属于回归任务。KNN 通过相关距离计算,选择最近的K个邻居的平均值,进而决策出血压数据的测量值。通常选取曼哈顿距离和欧几里得距离。
曼哈顿距离对应的特征值只有一个,其数学表达式:

K值的选择对算法的最终决策值影响极大,这直接影响回归器的性能,因此合理的选择K值,可以提高训练结果的精度,降低估计误差。
极端随机树(ETR):由随机森林模型变化而来,和随机森林一样都以决策树作为基学习器,但又不同于随机森林模型[20]。该模型使用全部的血压数据进行训练,并且在构建每棵决策树的时候,随机选择PPG 信号的k个特征参数进行分裂,在这个过程中,不修剪树枝。极端随机树的拟合能力和测量能力都强于随机森林。极端随机树对血压测量的步骤为:第一步选择血压数据集的全部数据进行训练;第二步根据CART算法,从n个特征参数中随机选择k个生成决策树;第三步对上面两个步骤多次迭代,直至生成所有的决策树,记为m;第四步重复步骤一至步骤三,构成随机森林,通过求森林中多个决策树对血压的测量值的平均而得到D数据集最后的血压测量值。
LightGBM 回归:基于树学习的梯度提升框架,提出的动机是为了弥补Xgboot 空间消耗大、运行时间长、不友好的chche 优化等缺点。其在运算速度上较Xgboot 模型快了好几倍,占用内存少,并且处理具有超多数据的数据集时准确度明显高于其他的算法模型[21]。其对血压测量的原理为:第一是直方图算法,首先将和血压有关的特征参数进行离散化,形成一个宽度为k 的直方图,然后依次遍历数据,寻找直方图上最优的数值;第二是带深度限制的Leaf-wise 算法,该算法实现每次从当前所有叶子中,找到分裂增益最大的一个叶子,接着进行下一步的分裂,依次循环;第三是GOSS 技术,即梯度单边采样技术,该技术舍弃那些对于血压测量值没有帮助的特征参数保留帮助性大的特征参数;第四为了减少特征参数过多,导致测量结果不准确的问题,互斥特征捆绑技术可以将相互独立的特征进行捆绑。
2.2 次级学习器选择
为了防止第一层模型在用非线性变化寻求最优空间假设而产生的过拟合现象,一般选择比较简单的机器学习模型作为次级学习器[22],本研究考虑使用文献[5]中的线性回归模型。
线性回归算法(Linear Regression)表征的是因变量(目标值)和自变量(特征输入)之间的线性关系,假设有k个样本数据,每个样本数据仅有1个特征参数,则线性回归模型的损失函数为:
式中:x1,x2,…,xk为特征输入;y为目标值;β0,β1,…,βk为回归系数,回归系数可通过最小二乘法集中拟合求得,最小二乘法就是要找到一组β0,β1,…,βk,使线性回归模型的残差平方和方(SSE)达到最小[23],从而得到使得损失函数最小化的拟合函数的模型。
SSE可表示为:
式中:yβ(xi)为线性回归模型的测量值;yi为真实值。
因人体血压值是受多个特征值共同影响的,则线性回归模型特征输入X是一个k维矢量,此时的线性回归模型为y=Xβ,化成矩阵形式为:
2.3 Stacking血压测量模型搭建
本研究构建基于Stacking 血压测量算法模型的框架如图3 所示。首先按8∶2 的比例划分数据集,记训练集为D={(x1,y1),(x2,y2),…,(xn,yn)},其 中x1,x2,…,xn是 与真实血压值有关的特征参数,y1,y2,…,yn是对应的每个志愿者的真实血压值。为了防止数据量不够而导致训练结果产生过拟合现象,将训练集作十折交叉验证处理,即每次拿9份血压数据作为初级学习器l1i(i= 1,2,3)的训练集分别进行训练,剩下的一份血压数据作为测试集,交叉验证10次后加权平均得到k(k=1,2,3)个回归模型,此为第一层机器学习模型。然后以l1i个模型输出的血压测量结果[i= 1,2,3,j=size(10 - fold)]作为特征输入,真实血压值ym(m= 1,2,…,n)作为训练标签组成次级训练集D′,最后把D′放到次级学习器l2中进行模型训练,此为第二层机器学习模型,从而得到最终血压测量结果hm(m= 1,2,…,n)。

图3 基于Stacking血压测量算法模型的框架图
3 实验过程与结果分析
3.1 拆分数据集
每个志愿者测得脉搏波参数的量纲不同,故在训练数据之前首先根据式(7)将脉搏波原始数据标准化为均值为0,方差为1 的分布,再根据式(8)将原始数据归一化至[0,1]区间内,目的是降低训练权重,使模型获得更好的训练效果。

式中:μ为未处理数据的均值(mean);σ为未处理数据的标准差(std)。
本研究将处理过的5 238条数据进行数据拆分,通过式(9)计算每一条志愿者数据的身体质量指数(BMI)数值,然后根据计算结果,将数据集分成BMI>25和BMI<25的子数据集,并将BMI的数值作为新的特征参数输入。
式中:志愿者的体重单位为kg;志愿者的身高单位为m。
最终得到3 293 条非肥胖人群的子数据集,1 945 条肥胖人群子数据集,分别随机选择每个子数据集的80%作为算法模型的训练集,20%作为测试集。
3.2 实验过程
本研究第一个实验是利用单层机器学习模型对BMI>25 和BMI<25 的数据集分别进行训练,以提取的43 个特征参数和BMI 数值作为模型的输入,真实收缩压和舒张压值作为训练标签。K近邻回归模型使用枚举方法、lightGBM 回归模型和极端随机树使用网格搜索方法进行超参数优化、线性回归使用最小二乘法进行调参优化。十折交叉验证测试结果显示,K近邻回归模型最优参数:距离的权重weight=distance、闵可斯基距离为曼哈顿距离即P=2、邻居个数k=13。lightBGM 回归模型最优参数:每个基学习器的最大叶子节点、学习率、基学习器的数量分别为num_leaves=31、learning_rate=0.1、n_estimators=40。极端随机树回归模型最优参数:基学习器的数量、决策树最大深度、最大特征数分别为n_estimators=50、max_depth=60、max_features=11。第二个实验是利用搭建好的Stacking 集成模型,融合K近邻、lightGBM、极端随机森林、线性回归的最优模型对血压数据集进行训练和测量。实验一和实验二的结果如表2所示。

表2 单模型和Stacking模型对不同人群血压测量结果对比mmHg
为了与本研究搭建的stacking 集成模型的性能作对比,接下来做了第三个实验:将任意3 个单模型作为初级学习器,另外一个单模型作为次级学习器,通过不同的Stacking 集成模型分别在肥胖人群数据集中进行训练和测试,实验结果如表3所示。
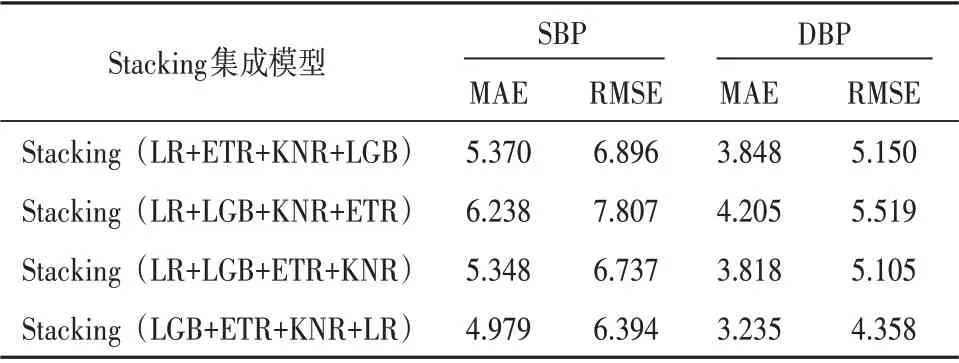
表3 肥胖人群中不同集成模型测试结果对比mmHg
3.3 实验结果分析
血压算法的准确与否可用平均绝对误差(MAE)和均方根误差(RMSE)进行评估,AAMI国际电子血压计标准为模型的评价指标MAE<5 mmHg,RMSE<8 mmHg[24]。其计算公式分别如式(10)和式(11)所示。其中,ytrue,i为水银血压计测得的真实血压值,ypred,i为算法模型的血压测量值,n为数据总数。
根据表2和表3的实验结果,可以分析得出如下结果。

表3 涡轮结果验证表
(1)对于收缩压SBP 的测量,在肥胖人群(BMI>25)中4 个单模型估计的误差MAE/RMSE 较非肥胖人群(BMI<25)都有所降低;对于舒张压DBP 的测量,在肥胖人群中LGB 模型估计的误差MAE 低于非肥胖人群,ETR 模型估计的误差RMSE 低于非肥胖人群。以上结果显示,将人群分开且加入BMI 之后,虽然单个模型某些测量结果没有达到AAMI 标准,但整体上来说对于肥胖人群的血压测量精度更高,符合本研究预期结果。
(2)在非肥胖人群中,对比最好单模型ligthGBM 模型,本研究搭建的Stacking 集成模型对SBP 估计的MAE/RMSE 从5.748/7.309 mmHg 下 降 至5.624/6.842 mmHg,DBP 则 从3.714/4.750 mmHg 下 降 至3.594/6.684 mmHg;在肥胖人群中,对SBP 估计的MAE/RMSE 较ligthGBM 模型从5.415/7.034 mmHg 下降 至4.979/6.394 mmHg,DBP则从3.636/4.798 mmHg 下降至3.235/4.358 mmHg。此结果说明Stacking 集成模型对肥胖人群血压测量精度高于非肥胖人群,且满足AAMI国际电子血压计标准。图4和图5显示了Stacking集成模型对不同人群的收缩压和舒张压的测量值与真实值之间的相关性。肥胖人群的SBP 和DBP测量血压与真实血压之间的相关系数R2分别为0.702和0.791,两值之间具有高度相关性,高于非肥胖人群的0.655和0.729,进一步说明Stacking集成模型对肥胖人群血压测量精度更高。

图4 Stacking模型对非肥胖人群血压测量的相关性
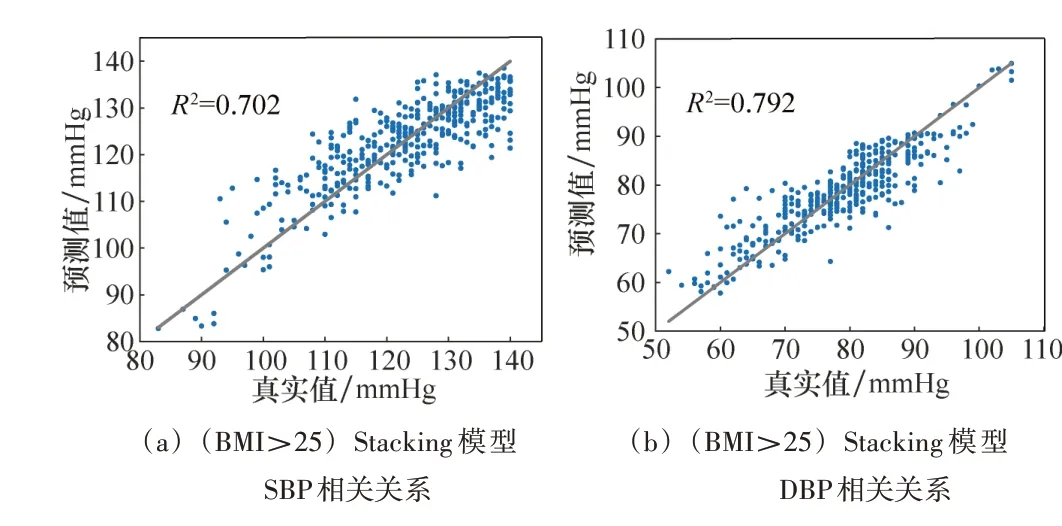
图5 Stacking模型对肥胖人群血压测量的相关性
(3)当LGB、ETR、KNR、LR 中的任意一个作为次级学习器时,对肥胖人群血压的测量精度各不相同。对于收缩压的测量,Stacking(LR+LGB+KNR+ETR)模型性能最差,甚至不如ETR、LGB、LR 单模型,对于舒张压 的 测 量,Stacking(LR+ETR+KNR+LGB)模 型 和Stacking(LR+LGB+KNR+ETR)模 型 精 度 不 如ETR、LGB 单模型。无论收缩压还是舒张压,Stacking(LGB+ETR+KNR+LR)集成模型测量精度最高,性能最佳。
综合以上所有实验,Stacking(LGB+ETR+KNR+LR)集成模型性能优于4 个单模型和另外3 个Stacking 集成模型,且对肥胖人群更有效,收缩压和舒张压的测量结果均符合AAMI 国际电子血压计标准(RMSE<8 mmHg,MAE<5 mmHg)。
3.4 Bland-Altman图分析
为了进一步评价Stacking(LGB+ETR+KNR+LR)集成模型对肥胖人群血压测量的可行性,对收缩压和舒张压的测量值与真实值进行Bland-Altman分析,如图6所示。

图6 肥胖人群SBP&DBP的Bland-Altman图
从图6 中可以得知,模型对于肥胖人群的血压(SBP&DBP)测量值与真实值的差值平均数(Mean)接近于0,并且其差值绝大部分落在95%一致性界限(即-d± 1.96sd)之内,说明Stacking 模型对肥胖人群血压测量与真实血压的一致程度高,可靠性好。
4 结束语
本文建立的Stacking 集成机器学习模型,在提取的PPG 信号特征值的基础上,把身体质量指数(BMI)作为新的特征参数加入到模型进行训练和测试。经过不同人群的多次实验对比,发现基于Stacking 集成机器学习模型对于肥胖人群的血压测量结果有效改善了原有算法对肥胖人群血压测量准确度不高的问题,且其误差MAE/RMSE均符合AAMI国际电子血压计标准。对于非肥胖人群,本研究显示,基于Stacking 集成机器学习模型效果不显著,应用价值不大。下一步的工作方向是建立更为广泛的PPG 信号数据集,进一步对模型进行优化,构建一个适合所有肥胖人群的血压测量模型。
