一种上下文信息融合的安全帽识别算法
2023-03-21肖立华商浩亮罗仲达吴小忠马小丰江志文陈俊杰
肖立华,徐 畅,商浩亮,罗仲达,吴小忠,马小丰,江志文,陈俊杰
(1.国网湖南省电力有限公司,湖南 长沙 410007;2.北京洛斯达科技发展有限公司,北京 100088;3.湖南省智能信息感知及处理技术重点实验室,湖南 株洲 412008)
0 引言
随着信息化和数字化技术的发展及应用,智慧工地被提上日程。智慧工地是指利用互联网和信息化技术,使用信息技术和数字技术为手段提升工地的管理和决策水平。其中,采用计算机视觉技术的智能视频监控系统是应用最广泛的。各地也发布文件要求各新开工项目要安装在线监控系统,完善安全生产动态监控及预警体系。安全帽是施工人员的关键防护用具,在突发情况下能有效保护施工人的头部,减少伤害。实时检测在施工现场的人员是否正确佩戴安全帽是智慧工地的基本要求。计算机视觉技术具有使用方便、能适应多种复杂场景的优点。因此,采用计算机视觉技术自动化的安全帽识别对智慧工地的建设、减少事故具有重要意义[1]。
施工场所一般处于室外,这类场景具有光照不稳定、环境复杂、人员流动性高的特点,对安全帽佩戴检测算法的实时性和准确性提出了更高的要求。目前,对安全帽的检测都是采用基于深度学习的目标检测方法[2-9]。根据使用的检测方法的原理,可以将这些方法分为2 类:一阶段的方法(one-stage)和两阶段的方法(two-stage)。一阶段的方法采用的是直接回归的方法,只提取一次图像特征,同时预测物体的类别并回归物体在图像中的坐标位置。这类方法的优点是速度快,适合应对实时性要求高的场景或者移动端设备,但这类方法的检测精度比两阶段的方法低。代表性的一阶段目标检测方法有YOLO[10]、SSD[11]、UnitBox[12],在这些方法的基础上改进得到了诸多安全帽检测方法[2-6]。两阶段的目标检测方法使用两阶段级联的方式检测目标,先进行粗定位,再进行分类和精细定位。两阶段的方法精度高,但速度慢、训练复杂。代表性的两阶段目标检测方法有RCNN[13]、Fast R-CNN[14]、Faster R-CNN[15]、Mask R-CNN[16]。在两阶段目标检测方法的基础上发展出了基于两阶段的安全帽检测方法[7-9]。
为了满足施工场景下安全帽检测的实时性需求,本文改进UnitBox 目标检测算法[12]并将其应用于安全帽检测问题中。本文有针对性地解决了如下2 个问题:1)特征鉴别力不足问题,安全帽纹理单一,导致提取的特征鉴别力不足;2)小目标识别问题,施工场景范围广,图像中大部分待检测的安全帽都小于45个像素。
首先,为了解决特征鉴别力不足的问题,本文提出局部上下文感知模块(Local Context Perception Module,LCPM)。如图1 所示,通过对局部图像区域的上下文信息建模,同时提取多尺度的人体头部特征和安全帽的特征,提升特征的识别能力。同时引入了全局上下文信息融合模块(Global Context Fusion Module,GCFM),融合不同层的特征,增强特征的抽象能力。其次,为了应对小目标识别问题,本文设计的多尺度目标检测模块使用了多个目标检测器分别处理不同大小的目标。此外,为了提高检测速度,本文使用速度更快的MobileNet[17]替换UnitBox 算法[12]中原有的主干网络VGG-16[18]。在安全帽检测数据集上的实验结果表明,本文提出的方法在没有降低检测速度的前提下,大幅提高了检测精度。实地测试表明,可满足安全帽检测任务高精度和实时的要求。

图1 多尺度的上下文建模
1 相关工作
1.1 UnitBox目标检测算法
UnitBox[12]是一种基于图像分割的一阶段人脸检测算法,采用全卷积神经网络,将人脸检测问题转化为图像分割问题和边界框回归问题。对于图像分割问题,UnitBox将图像中的像素点分为人脸和非人脸2个类别,直接预测每一个像素点的类别,使用交叉熵损失。为了得到人脸的坐标,UnitBox 预测人脸区域内每一个像素点相对人脸上下左右4 个边界的偏移量,根据像素点的坐标和偏移量得到预测人脸矩形框的坐标位置,优化预测矩形框与真实矩形框的交并比。UnitBox 同时优化交叉熵损失和交并比来训练模型。UnitBox 具有速度快的优点,但UnitBox 没有融合上下文信息,提取的特征的识别能力有限,精度较低。本文在UnitBox算法的基础上加入了局部多尺度特征提取模块和金字塔特征融合模块,提升特征的鉴别能力。此外,本文还将UnitBox从单类别目标检测(人脸检测)推广到了多类别目标检测任务(佩戴安全帽的人员、未佩戴安全帽的人员)。
1.2 多尺度特征融合
在目标检测中有诸多工作通过融合不同尺度的特征来提升特征的鉴别能力[19-22],这些方法提出融合神经网络不同层的特征来达到融合不同尺度的上下文信息的目的,从而提升特征的鉴别能力。王成济等[19]提出使用双线性插值将不同层的特征图调整为相同的大小再进行融合。文献[20-22]则提出将高层特征经过双向性插值放大后与浅层特征融合改善特征的抽象能力。从本质上来说,这些方法都是从不同的特征层感知不同尺度的信息。与这些方法不同的是,本文在同一个特征层提取多尺度的特征,受到图像分割工作[23-24]的启发,提出了局部上下文感知模块,充分建模局部上下文信息,提高特征的识别能力。
2 算法框架
本章将详细介绍所提出的安全帽识别的训练和测试流程,整体流程如图2所示。在训练阶段,有3个输入:监控相机采集到的图像、像素点得分标签、坐标迁移标签。从监控相机采集到的图像经过预处理,输入基于全卷积神经网络(Fully Convolutional Neural Network,FCN)的目标检测模型(FCN 模型)中得到三通道的像素点类别得分图和四通道的坐标偏移图。使用梯度下降法更新模型的参数。在测试阶段,从摄像机采集图像,经过预处理输入FCN 模型中,分别得到像素点类别得分和坐标偏移预测,经过非极大值抑制得到最终的识别结果。
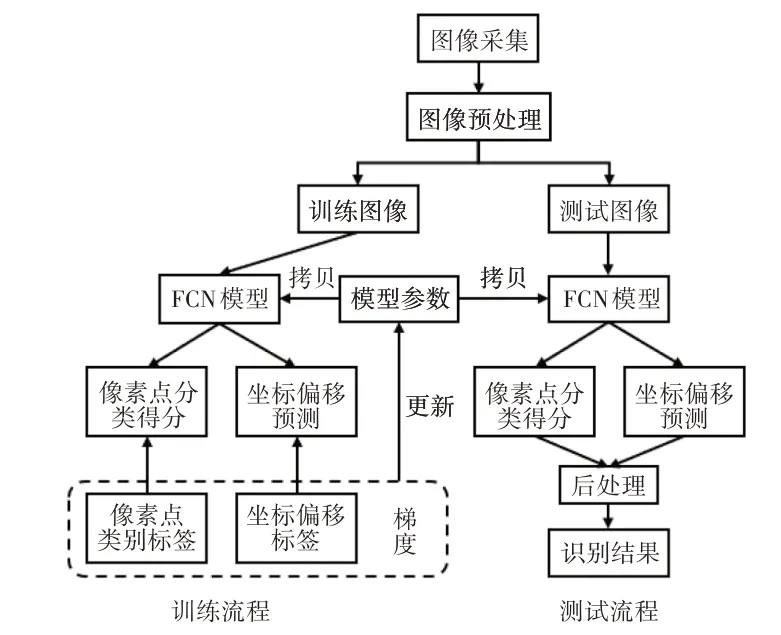
图2 安全帽识别训练和测试流程
2.1 上下文信息融合的安全帽识别模型
本文提出模型的整体网络结构如图3 所示,使用MobileNetv1[17]作为主干网络,分别从第6 个卷积层、第12 个卷积层和第14 个卷积层提取特征,提取的特征表示为x1、x2和x3。首先,将3个特征分别输入局部上下文感知模块中,获得编码了局部上下文信息的特征表示;其次,将特征输入全局上下文融合模块中,将高层的语义信息融合进浅层特征中,提升特征的识别能力;最后,使用3 个目标检测器分别识别不同大小的目标。
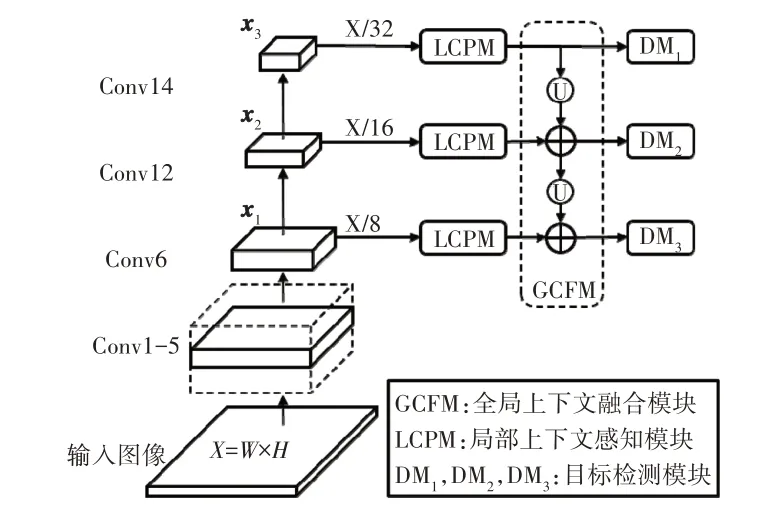
图3 提出模型的结构
2.1.1 局部上下文感知
人类视觉感知系统是由多个具有不同大小的感受野的子系统组成的,能在不同的尺度上感知物体。人在观察一个物体时,不仅会提取物体本身的信息,也会提取物体周边的背景信息。卷积神经网络每层特征的感受野是固定的,无法在同一层捕获不同尺度的信息,同时,安全帽本身的纹理信息不足,只提取颜色特征和形状特征还不足以应对多样的安全帽识别问题,因此不仅需要安全帽本身的信息,还需要利用人体头部的信息来识别安全帽。受人类视觉系统的启发,如图4所示,本文提出使用不同大小的卷积核来感知多尺度的上下文信息,以增强特征的鉴别能力。

图4 多尺度的上下文信息
如图5 所示,本文提出的局部上下文感知模块包含4 个卷积操作,分别感知不同尺度的上下文信息:一个1×1卷积,3个空洞卷积[25](空洞数量r分别为0、1、2)。本文将得到的多尺度上下文特征按照通道拼接在一起,使用一个1×1卷积层融合上下文特征。假定输入特征为x,上述计算过程可以表示如下:
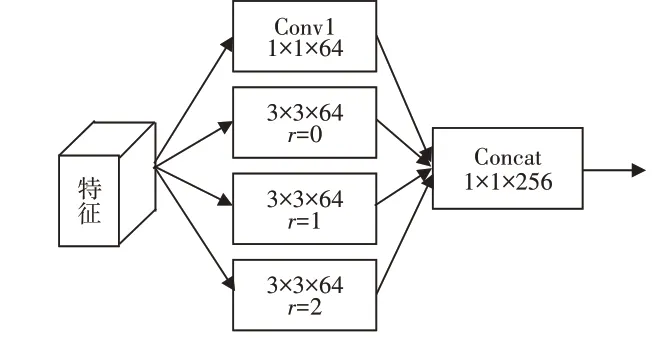
图5 局部上下文感知模块(LCPM)
其中,Conv1()表示1×1 卷积层,DConvr()表示空洞数量为r的空洞卷积,ReLU()为激活函数,[…]表示按通道拼接特征。给定多尺度的特征x1、x2和x3,得到的融合了局部上下文信息的特征可以表示为:l(x1)、l(x2)和l(x3)。此处,不同特征层的局部上下文感知模块的参数不共享,不同卷积层参数不共享。
2.1.2 全局上下文融合
高层特征编码了丰富的语义信息,浅层特征缺乏抽象的语义信息。将高层特征与浅层特征融合,能够让深层特征的语义信息融合到浅层特征中,提升浅层特征的语义识别能力。此外,高层特征具有更大的感受野,将高层特征与浅层特征融合能够有效地建模全局上下文信息。本文引入特征金字塔将高层特征与浅层特征融合,改善特征的识别能力。如图3 所示,使用上采样层将高层特征的分辨率放大后与浅层特征相加得到语义增强的特征表示。对于最高层的特征直接应用一个1×1卷积层得到最终的特征表示,全局上下文融合模块的计算过程表示如下:
其中,U()表示上采样层。
2.1.3 多尺度安全帽识别
由于施工人员离摄像机的远近不同,图像中的安全帽的尺度变化大。受到特征感受野的限制,单一特征层无法应对多尺度的目标检测问题。因此,本文使用3 个参数共享的目标检测模块(Detection Module,DM)在不同的特征层检测不同大小的目标。给定特征f(x1)、f(x2)和f(x3),目标检测模块由2 个独立的子网络组成,分别预测类别得分和坐标偏移,如图6 所示,第一个卷积层有256 个卷积核,第二个卷积层得到预测结果,这4个卷积层不改变特征图的大小。
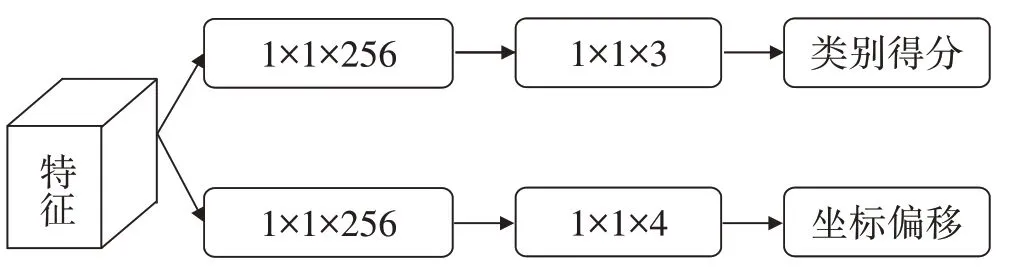
图6 目标检测模块(DM)
分别将特征f(x1)、f(x2)和f(x3)输入到目标检测模块中。特征f(xi)的第k个类别的得分表示为pki。相应的坐标偏移表示为(t,b,li,ri),分别表示像素点坐标相对目标上下左右4 个边界的坐标偏移量,根据像素点的坐标和预测的坐标偏移量,可以得到预测矩形框qi。
本文使用3 个目标检测模块(DM1,DM2,DM3)来检测不同大小的目标,不同目标检测模块与待检测目标的关系见表1。

表1 检测模块与目标大小的关系
2.1.4 损失函数
给定一张图像,在制作类别标签时,本文将标注的目标中心的10×10区域(以像素为单位)视为前景,设为1;标注区域外视为背景,设为0;使用交叉熵损失训练模型。同样地,计算对应的10×10区域的交并比损失。
使用交叉熵函数计算分类损失,设置类别0 表示背景,类别1表示佩戴安全帽的人员,类别2表示未佩戴安全帽的人员。分类损失计算如下:
本文增加预测矩形框与真实矩形框的交并比,交并比损失计算如下:
其中,gi和qi分别表示标注的矩形框和预测的矩形框。
采用多任务学习同时优化分类损失和交并比损失来训练模型。最终的损失函数表示如下:
其中,λ1和λ2是损失函数的权重。
2.2 模型性能评价指标
本文使用平均精度值(Average Precision,AP)和平均精度均值(mean AP,mAP)来评价模型的结果。AP 是Precision-Recall 曲线下的面积,AP 可以用于评价单个类别精度。mAP 是所有类别的平均精度值的平均,可以评价所有类别的检测结果的好坏。
3 实验与结果分析
3.1 数据采集与处理
本文使用的数据集包括10000张图片,分别来自于历年施工场所的监控照片和以“施工”“工地”“施工人员”等作为关键字从图片网站(https://image.baidu.com/和https://cn.bing.com/images/trending?form=HDRSC2)爬取的施工场景下的人员图片,如图7 所示。经过人工筛选后手工标注了佩戴安全帽的人员和未佩戴安全帽的人员。使用开源标注软件labelImg(https://github.com/tzutalin/labelImg)进行标注。标注了2 类物体:佩戴安全帽的人员(Helmet,紫色框标注)、未佩戴安全帽的人员(Person,绿色框标注)。数据集中标注的目标最小为16×16。总共标注了48762个Helmet目标,13954 个Person 目标。所有的图片通过裁剪、拼接等手段调整为640×640,按照8:2 的比例随机将数据集划分为训练集和测试集,详细的数据集划分见表2。其中8000张图片作为训练集,2000张图片作为测试集,并按照VOC 数据集格式进行存储。经过粗略统计,本数据集中标注的小目标(长和宽均小于45个像素点)占比超过83.4%,80%的照片是户外场景。本数据集更符合实际施工场景,但给安全帽识别问题提出了较大的挑战。

图7 数据集标注样例(紫色矩形框表示佩戴安全帽,绿色矩形框表示未佩戴安全帽)
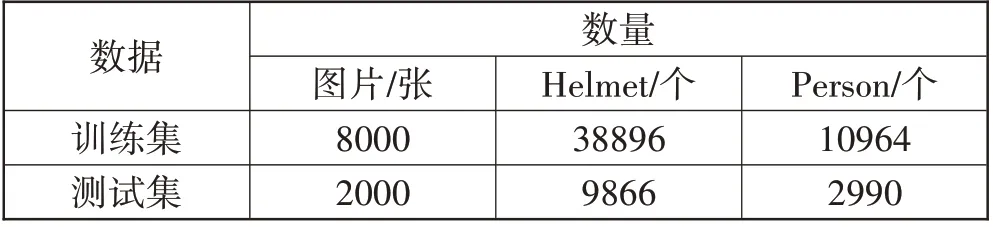
表2 安全帽识别数据集划分
本文对训练集中的图片做了数据增强,对图片进行随机翻转、旋转,改变对比度、饱和度和亮度,以扩充数据集,提高模型的训练精度和性能。此外,模型对图片做了归一化处理。在后处理阶段,使用非极大值抑制算法去除重复矩形框。余下的检测框与真实标注的矩形框的交并比大于0.5 则为正确的检测结果。本文使用平均精度值评价模型。
3.2 实验设置
本文所有实验都是在深度学习服务器上进行。硬件配置为NVIDIA GeForce GTX 1080 Ti 显卡,Inter Core i7-8750H6 处理器,32 GB 内存,1 TB 机械硬盘。使用Ubuntu18.04 操作系统,所有代码都是使用Python 语言和PyTorch 深度学习库实现。使用Adam 优化器训练模型[26],模型的关键实验参数如表3 所示。所有的模型都是使用MobileNetv1 作为主干网络,对比算法使用MobileNetv1 和PyTorch 深度学习库复现后在相同的实验环境下进行实验。模型完成训练需要4 h 20 min。

表3 部分实验参数
本文的基线模型为复现后的UnitBox 模型,使用MobileNetv1作为主干网络,分别从Conv14层、Conv12层和Conv6层提取特征,使用3个目标检测模块进行目标检测。基线模型在Helmet 和Person 这2 个类上的AP分别为82.12%和76.45%,平均精度均值为79.28%。
3.3 实验结果对比与分析
表4 是本文方法与其他先进方法的对比,对比方法 有UnitBox[12]、YOLO-V3[10]、SSD[11]、Faster RCNN[7]。表4 中模型的训练配置所使用的硬件和软件设置都相同。本文的方法在平均检测精度(AP)和检测帧速度(fps)上都是最优的,本文提出的改进方案将mAP 提升了11.46 个百分点,安全帽识别的平均精度提高了10.55 个百分点,足以说明本文方法的优越性。UnitBox[12]、YOLO-V3[10]、SSD[11]检测速度快,但是检测精度低,不能满足复杂施工场景下的高精度要求;虽然Faster R-CNN[7]检测精度较高,但速度慢。本文的方法在没有牺牲检测速度的前提下,显著提高了模型的检测精度。基于上述实验结果,可以发现本文改进的模型在真实场景下有更好的性能,且能满足实时性的应用要求,具有速度和精度的双重优势。
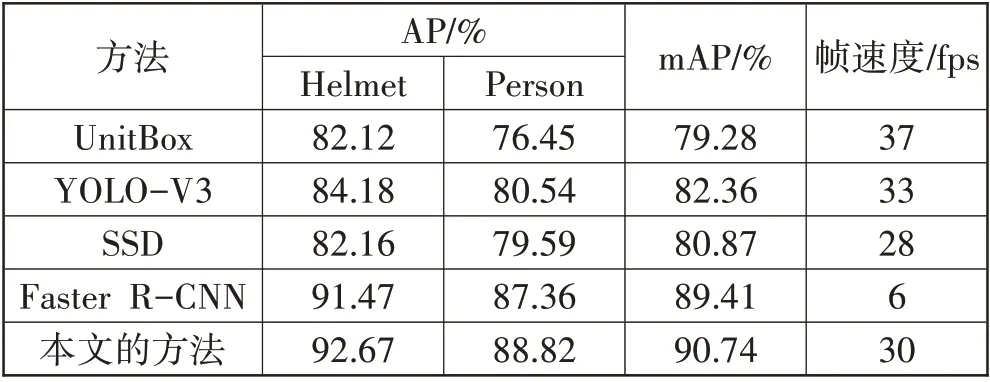
表4 本文方法与其他方法对比
3.4 消融实验结果与分析
为了验证本文提出的模块的有效性,进行了消融实验。实验结果见表5,分别对局部上下文感知模块(LCPM)、全局上下文融合模块(GCFM)进行实验分析。有如下观察:1)当增加了局部上下文感知模块后,2 个类别的AP 分别提高了5.22 个百分点和7.33个百分点,这说明该模块能有效地感知到多尺度的局部上下文信息;2)当使用了全局上下文融合模块后,AP 分别提高了7.47 个百分点和8.94 个百分点,这说明全局上下文融合模块能够将深层的语义特征融合到浅层特征中,解决浅层特征语义不足的问题。在图8 中,对比了本文方法与基线模型的检测结果,可以看出最终模型的检测效果显著好于基线模型。
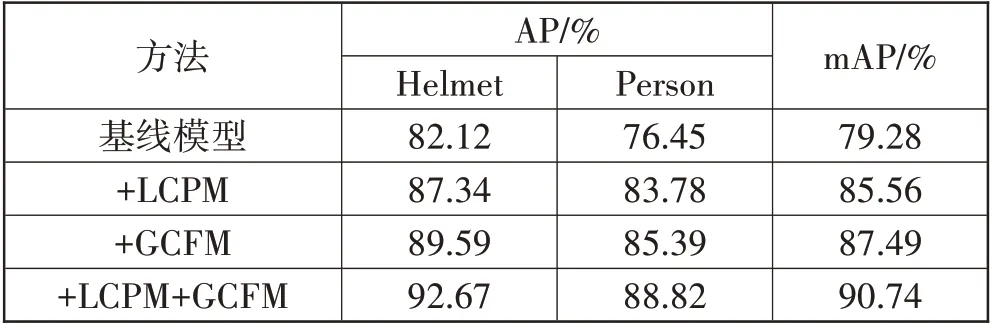
表5 消融实验结果

图8 本文方法与基线模型的检测结果对比(紫色矩形框表示佩戴安全帽,绿色矩形框表示未佩戴安全帽)
3.5 损失函数权重分析
在这个实验中,通过改变λ1和λ2的值进行了参数分析。为了识别出安全帽,分类损失和交并比损失是缺一不可的。因此,本文将λ1和λ2的范围设定为[0,1,2],固定其中一个参数的值为1,变化另一个参数的值,从而分析分类损失和交并比损失对实验结果的影响,对应的实验结果见图9。可以观察到:1)随着参数λ1和λ2值的增加,模型的准确率先稳步上升后开始下降;2)当参数λ1和λ2的值在1 附近时,模型取得最好的结果。3)图9(a)和图9(b)中3 条曲线的变化规律基本一致;4)随着参数λ1和λ2值的差距的增加,模型准确率随之下降。以上观察结果说明2个损失是同等重要的。基于以上观察,本文设置λ1=1和λ2=1。
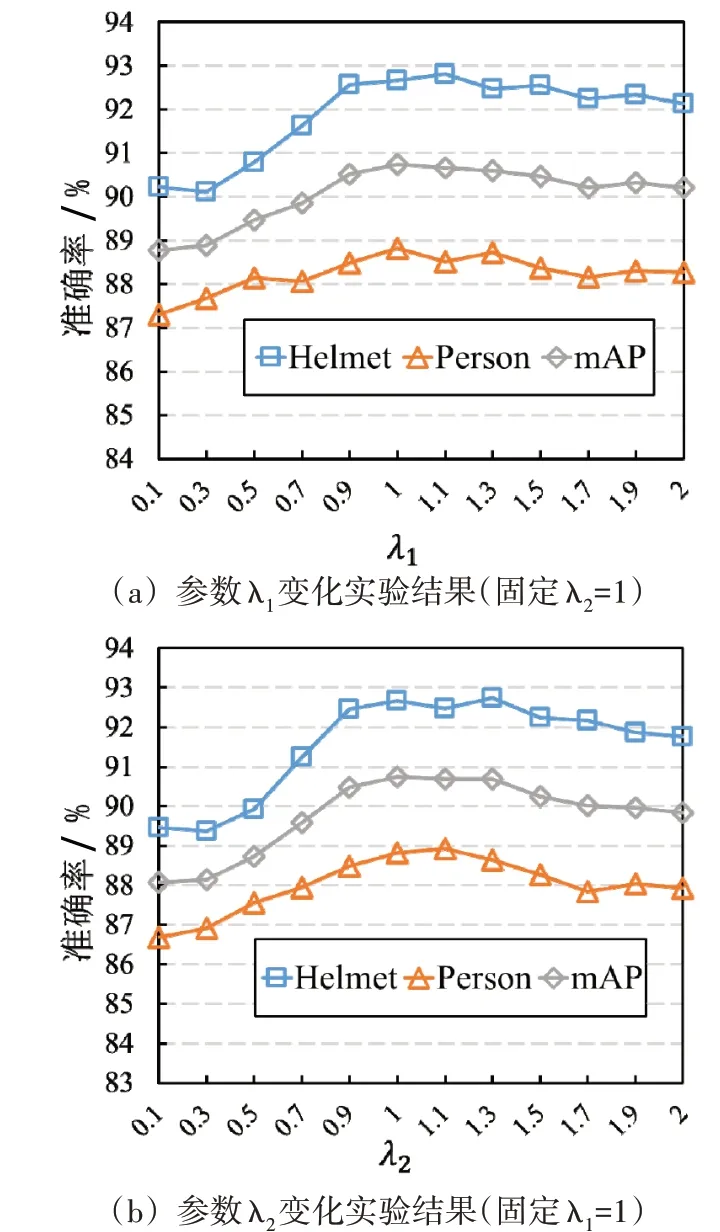
图9 参数λ1和λ2变化实验结果
4 结束语
针对安全帽识别实际应用中小目标识别困难问题,对一阶段的目标检测方法进行改进,提出了局部上下文感知模块和全局上下文融合模块,增强网络的表征学习能力。通过采集10000 张施工场景下的图像,构建了面向施工场景下的安全帽识别数据集,进行训练和测试。在该数据上的实验结果表明,本文提出的改进方案将mAP 提升了11.46 个百分点,安全帽识别的平均精度提高了10.55个百分点。本文提出的安全帽识别方法能有效解决复杂开放场景下的安全帽识别问题,显著提升了智慧工地的建设水平。在下一步研究中,将开展危险环境和施工人员不安全动作的实时识别,从更多角度为智慧工地建设提供技术解决方案。
