基于MrsP协议的任务划分优化算法
2023-03-19张海涛张宇辉管银凤张凤登
张海涛,张 通,张宇辉,管银凤,张凤登
(上海理工大学 光电信息与计算机工程学院,上海 200093)
随着计算机技术的进步和发展,越来越多的复杂系统依赖于计算机控制,实时系统在当今社会中扮演着至关重要的角色[1]。与此同时,人们对实时系统的功能和性能有了更高的要求,实时系统逐渐被构建在多处理器平台之上[2]。
多处理器实时调度算法主要解决两个问题:任务划分问题和优先级分配问题[3]。其中,划分调度中关键的就是任务划分算法。这个划分问题类似于经典装箱问题。使用P-RM调度算法时,文献[4]研究了首次适应算法(First-Fit,FF)、最佳适应算法(Best-Fit,BF)和最坏适应算法(Worst-Fit,WF)等经典的装箱算法的性能,并得到了可调度的利用率上限条件。文献[5]提出了在划分EDF(Earliest Deadline First)和划分固定优先级调度下基于整数线性规划(Integer Linear Programming,ILP)的划分问题求解方法。然而,上述方法利用率上限都没有考虑共享资源的影响。当考虑任务访问共享资源时,由于任务可以通过访问共享资源来阻塞其他处理器上的任务,会导致划分问题的复杂化。文献[6]提出了将任务访问本地资源而导致的阻塞合并到ILP中的任务划分方法。文献[7]提出了多处理器共享资源访问协议(Multiprocessor Resource Sharing Protocol,MrsP),该协议使用了帮助机制来减小阻塞时间,这也是本文主要研究的多处理器共享资源访问协议。然而,上述算法未解决任务分组的利用率大于单个处理器利用率时的拆分和再分配问题。
对此,本文的研究内容主要分为两个部分:第1部分研究使用划分调度(Partitioned Scheduling)算法,并在每个处理器上使用单调速率(Rate Monotonic,RM)算法(以下简称P-RM算法),而对共享资源的管理则使用多处理器共享资源访问协议[7]。通过将P-RM算法和MrsP协议相结合,得出了多处理器实时系统的整体可调度性条件,为MrsP协议的实际使用奠定了基础。第2部分则在研究共享资源约束的基础上,针对MrsP协议的任务划分算法,提出了任务划分的优化方法。
1 系统模型与假设
本文的研究基于同构多处理器(Symmetric Multiprocessor)平台[8]。处理器的集合记为P={p1,p2,…,pm},pk表示第k个处理器,其中1≤k≤m且k为整数。实时任务则记为Γ={τ1,τ2, …,τn},τi表示第i个的实时任务,其中1≤i≤n且i为整数。共享资源可以分为硬件共享资源和软件共享资源两种,针对硬件类共享资源的访问控制可以使用相应的机制来同步[2,9]处理。本文的共享资源为软件类的共享资源,例如任务之间数据结构或者变量的共享。设共享资源的数量为q(q≥1),记为R={r1,r2,…,rq},用rs表示第s个共享资源,其中1≤s≤q且s为整数。此外,本文假设系统中的共享资源不存在嵌套访问的情况,因此在实际使用时可以使用分组锁解决该问题[10-11]。
在划分调度下,映射G(rs)返回使用共享资源rs的任务集合,映射F(τi)返回任务τi使用的共享资源集合,映射map(Γ)返回任务集合划分到的处理器集合,映射map-1(pk)返回划分到处理器集合的任务集合。
本文规定对于给定任务集合Γ={τ1,τ2, …,τn},任务优先级按降序排序,使用Πi表示任务τi的优先级,即pri(τi)=Πi。
由于本文的研究是基于划分调度算法,对于实时任务集Γ到处理器集合P的划分,定义为Φ={Ψ1,Ψ2,…,Ψm},其中Ψk为分配到第k个处理器上的任务集合。
本文研究的任务模型是偶发任务模型。该模型中每个任务有3个参数:相对截止时间D以及参数最坏执行时间C和周期T。偶发任务τi的模型表示为τi=(Ci,Di,Ti)。这样的一个偶发任务会释放一个无限的实例序列。任意两个相邻实例的释放时间的间隔有一个最小的约束周期Ti。任务τi释放的每个实例最坏执行时间为Ci,相对截止时间Di是指从到达时间起始到截止时间的时间间隔。本文中一个任务系统通常被表示为Γ={τ1,τ2, …,τn}。
2 系统整体可调度性分析
原有的MrsP协议多侧重于最坏响应时间分析,实时调度算法又多基于传统的独立任务模型。因此本节整体研究了实时调度算法、共享资源访问协议,弥补了独立研究的不足,并在资源共享下,得出系统可调度性条件。
MrsP协议可以解决多处理器平台上实时任务访问共享资源的任务同步问题。根据MrsP协议的定义和性质,实时任务访问共享资源的阻塞可以分为两类:本地阻塞和远程阻塞[12]。
本地阻塞指同一处理器上低优先级任务通过访问或者占用共享资源,使自身优先级高于原来的高优先级任务,造成对高优先级任务的阻塞。
远程阻塞是指在不同处理器上一个任务访问一个已被占用的共享资源时的等待时间,例如在不同处理器上的任务τi和τj,任务τj首先锁定共享资源,当任务τi试图访问共享资源时便会进入自旋等待,此时任务τj对任务τi的阻塞便称为远程阻塞。任务τi自旋等待时间被称为忙等待(Busy Waiting,BW)时间。本文定义任务τi访问所有共享资源的远程阻塞时间为BW,除去任务自身访问共享资源的时间后可得
(1)
由文献[13]可知,在使用RM调度算法调度实时任务时,PCP协议管理共享资源的系统中的一组实时任务可以被调度的条件如式(2)所示。
(2)
在使用RM调度算法调度实时任务时,PCP协议管理共享资源的系统中,一组实时任务可以被调度的条件为式(3)。
(3)
对于实时任务集合Γ到处理器集合P的划分Φ={Ψ1,Ψ2,…,Ψm},由以上的定理和推论可得,划分到处理器pk上的任务集合Ψk的可调度条件为
(4)
或者
(5)
其中
nk=|map-1(pk)|
(6)
定义系统单个处理器利用率为
(7)
或者
(8)
定义系统利用率为式(9)。
U(Φ)=max{U(Ψk)|∀pk}
(9)
最后,可以得到如下可调度性条件:在使用P-RM调度算法和MrsP协议管理共享资源的多处理器平台上,对于实时任务集合Γ到处理器集合P的划分Φ={Ψ1,Ψ2,…,Ψm},系统的可调度性条件为式(10)。
(10)
根据RM调度算法的可调度性条件和MrsP协议的最坏响应时间分析进行系统分析,得出系统的整体性可调度条件,这是后续划分算法设计和系统可调度性判定的重要基础。
3 MrsP协议下任务划分算法
本节针对MrsP协议的规则特性,在考虑任务访问共享资源造成的阻塞情况下,提出了MrsP任务划分算法。
3.1 任务划分算法
任务的划分将直接影响远程阻塞时间,进而影响系统的可调度性。在基于P-RM调度算法和MrsP协议的多处理器平台上,任务执行时的延迟来自3个方面:(1)本地阻塞;(2)远程阻塞;(3)相同处理器上高优先级任务的抢占。其中本地阻塞相对远程阻塞占比较小,且本地阻塞是共享资源互斥访问的必然结果,帮助机制解决了处理器上高优先级任务抢占造成的阻塞。因此,为了避免浪费处理器计算能力,应该尽量减小不同处理器上的任务访问共享资源时造成的远程阻塞。
划分调度中的任务划分具有NP-Hard复杂度,针对此类问题,通常采用启发式算法进行任务划分。传统的装箱算法不考虑任务之间的资源共享关系,仅按照任务的利用率分配到处理器上。文献[14]提出的同步感知划分算法和文献[15]提出阻塞感知划分算法使用了相似的思想,即将访问相同资源的任务划分到同一处理器上以减小远程阻塞。然而两种算法均未解决任务分组大于单个处理器利用率时的任务拆分和再分配问题。本节将研究使任务之间远程阻塞时间最小的任务划分问题。
算法1MrsP任务划分算法
输入:实时任务集合Γ={τ1,τ2, …,τn},处理器数量M。
输出:可调度划分Φ或者划分失败。
1Φ=Φc=Ø
2Γ′=TasksetClust(Γ)//任务聚类算法
3Φc=TaskClassPart(Γc,Φc,m)/*任务类分配算法(WFD)*/
4 ifΦc=Ø then
5 return fail
6 end if
7Φ=SingleTaskPart(Γs,Φc)//见算法2
8 ifΦ=Ø then
9 return fail
10 end if
11 returnΦ
算法1总体概述了MrsP任务划分算法的基本步骤。算法输入为实时任务集合Γ和处理器数量m,输出为可调度划分Φ或者划分失败。首先,第1行定义Φ为可调度划分集合并初始化为空集,定义Φc为之后任务类划分的结果并初始化为空集。算法第2行为任务聚类算法,聚类算法时任务集合为Γ,输出为聚类后的任务集合为Γ′。算法第3行为任务类的划分算法,该输入为任务类集合Γc、任务类划分的结果Φc(此时为空集)和处理器数量m,输出为任务类划分的结果Φc。算法第4~第6行判断算法的任务类划分结果Φc是否为空集,若Φc为空集,则算法返回划分失败,否则继续执行下一步骤。算法第7行为单个任务的划分算法,输入为单个任务集合Γs和任务类划分结果Φc,输出为可调度划分Φ。算法2的详细步骤见下文。算法第8行~第10行判断可调度划分Φ是否为空集,若Φ为空集,则算法返回划分失败,否则算法第11行返回可调度划分Φ。
3.2 单个任务分配
在传统的任务划分算法中,待划分的任务是按照固定的任务利用率来确定划分顺序。然而,在原始的MrsP协议最坏响应时间分析中,并没有考虑任务访问共享资源更细致的情况,这种分析方法在计算忙等待时间时可能存在对一个关键区进行重复计算的问题,这是一种过于悲观的计算方法。
考虑图1中所示的情况,在一个多处理器实时系统上,处理器数目m为3,系统共包括5个实时任务,其中pri(τi)=i,假设在任一任务的释放期间,其余任务也仅释放一次。对于任务τ3来说,需要访问共享资源r3次,在任务的执行期间,会受到处理器p1上任务τ1的3次阻塞和处理器p3上任务τ5的两次阻塞,则任务τ3的执行时间为C′3=C3+3cs+3cs+2cs=C3+8cs。然而,使用根据MrsP协议最坏响应时间分析可得C′3=C3+3×3cs=C3+9cs。对于任务τ4来说,使用MrsP协议最坏响应时间分析可得到C′4=C4+3×3cs=C4+9cs,然而,任务τ4只会受到处理器p1上任务τ2的两次阻塞,任务τ4第3次请求访问共享资源将不会受到阻塞。导致这种重复计算问题的原因是,原始的MrsP协议最坏响应时间分析计算假设任务的每次访问共享资源都会受到所有处理器上任务的阻塞。因此,这种计算方式是过于悲观的。
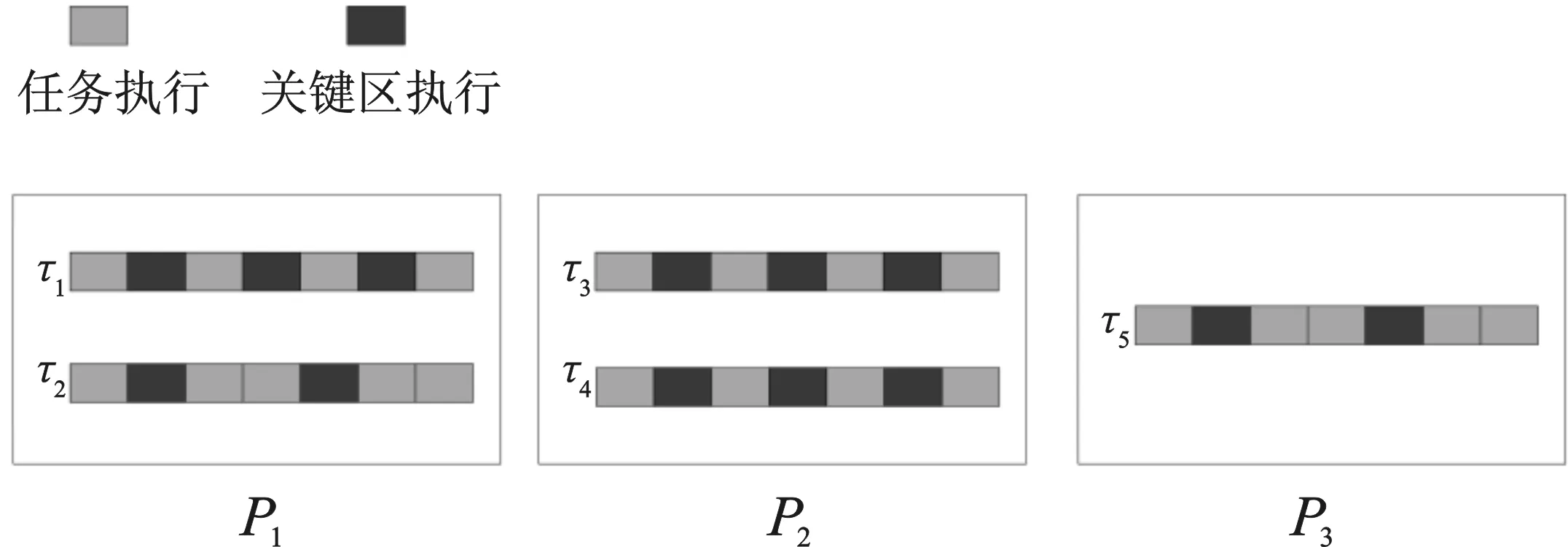
图1 关键区重复计算问题示例Figure 1. An example of a critical area double-counting problem
在P-RM调度算法下,若在不同处理器上有任务τi和任务τj,则任务τi的一个实例在执行过程中受到任务τj释放的实例影响的个数为
(11)
式中,mod(x,y)表示x除以y得到的余数。
为解决重复计算问题,本节算法在划分单个任务τi时考虑了3个因素,分别为:
(1)除map(τi)之外每个处理器对任务τi的阻塞次数;
(2)处理器集合对任务τi总的阻塞次数;
(3)任务之间的周期对阻塞次数的影响。
算法通过使用min函数取3种影响因素的最小值来解决重复计算问题。
算法2单个任务分配算法
输入:单个任务集合Γs,任务类划分Φc。
输出:可调度划分Φ。
1Φ=Φc
2 util[s]={0}
3 whileΓs≠Ø do
4 fori=1:sdo
5 util[i]=calU(τi,Φ)//见算法3
6 end for
7τi=getMax(util)/*返回util数组利用率最大的任务*/
8k=findProcessor(τi,Φ)//寻找处理器算法
9 ifk=0 then
10 return Ø
11 end if
12Ψk=Ψk∪{τi}
13Φ={Ψ1,Ψ2,...,Ψm}
14Γs=Γs-{τi}
15 end while
16 returnΦ
算法2为单个任务分配算法。算法输入为单个任务集合Γs和任务类划分Φc,输出为可调度划分Φ。算法第1行使用任务类划分Φc初始化可调度划分结果Φ,第2行定义util数组并初始化为0,其中数组元素个数为单个任务的数量s。算法第3行~第15行循环将任务划分到m个处理器上。算法第4行~第6行计算s个单独任务相对于当前划分Φ的任务利用率u。算法第7行的getMax函数返回util数组中利用率最大的任务τi。算法第8行定义的findProcessor函数为任务τi根据当前的划分Φ寻找最合适的处理器,返回值为处理器代号k。算法第9行~第11行判断处理器代号k是否为0,若为0,则表明任务τi为找到合适的处理器,返回划分失败;若不为0,算法继续执行。第12行~第13行将任务τi划分到处理器k的集合Ψk上,并从单个任务集合Γs中删除任务τi,接着当集合Γs不为空时继续循环,直到所有任务都划分完成,算法返回可调度划分结果Φ。
3.3 任务利用率算法
该算法的提出主要是解决任务利用率重复计算的问题。
算法3利用率计算算法
输入:任务τi,当前划分Φc。
输出:利用率ui。
1ui=0
2 BW′i=0
3 forrs=Rido
4 max_block[k]=Ni,s
5 sum=(m-1)Ni,s
6 BW′is=0
7 forzj,s,y∈Θsdo
8 if ∃k,τj∈Ψkthen
9 count=min(ai,j,sum, max_block[k])
10 max_block[k]-=count
11 else
12 count=min(ai,j,sum,Ni,s)
13 end if
14 BW′is+=count*Cs
15 sum-=count
16 if sum ==0
17 break
18 end if
19 end for
20 BW′i+= BW′is
21 end for
22ui=(Ci+ BW′i)/Ti
23 returnui
其中Ri为任务访问的共享资源集合,zj,s,y是任务τj访问共享资源rs的一个关键区,0≤y≤Ni,s,zj,s是任务τj需要访问共享资源rs的关键区集合,Θs是任务集Γ中所有任务访问共享资源rs的关键区集合。
4 实验与结果
实验平台主机采用Windows10操作系统,并虚拟机上安装配置LITMUSRT实验平台[16-17]。
任务集按表1生成,共设计了3个实验。每次控制一个参数变动,算法性能评价指标为调度给定任务集所需处理器的数量。本文中,3个实验分别研究了共享资源访问时间、访问共享资源任务数量和任务集合利用率3个变量变化时,调度任务集合所需的处理器数量[18]。

表1 实验参数范围
实验的对比算法为WF算法、同步感知算法和阻塞感知算法。其中,WF算法在传统装箱算法中性能最好[18],因此选择WF算法作为传统装箱算法的代表。同步感知算法和阻塞感知算法都采用了任务捆绑分配的思想,即将访问相同共享资源的任务划分到同一个处理器上,以减小远程阻塞。

图2 共享资源访问时间与所需处理器数量的关系Figure 2. The relationship between shared resource access time and the number of required processors
图2的实验条件为:生成的任务集合的利用率为8,其中每个任务最多有3个临界区,每个共享资源被10个任务访问。在此实验条件下,改变任务访问共享资源rs的时间cs,测试各个任务划分算法的性能。随着任务访问共享资源时间的增大,任务被阻塞的时间也随之增加,任务访问共享资源的竞争程度增大,这导致任务集合被调度所需要的处理器数目不断增加。其中,WF算法在划分中并未考虑共享资源因素的影响,而同步感知划分算法和阻塞感知划分算法通过尽量将访问相同共享资源的任务划分到同一个处理器上减少了任务的远程阻塞,提高了处理器利用率。本文的MrsP任务划分算法在任务分类的基础上,将超过单个处理器利用率的任务根据当前划分集合的实际情况划分到使系统利用率增加最少的处理器上。由图2的结果可知,WF算法的处理器数目增加最快,同步感知任务划分算法和阻塞感知任务划分算法的处理器数目增加稍慢一些,两者中阻塞感知任务划分算法效率略好,MrsP任务划分算法所需处理器数目始终最少。相对于次优的同步感知任务划分算法,MrsP任务划分算法所需处理器数目减少了4%~10%。

图3 共享资源任务数与所需处理器数量的关系Figure 3. The Relationship between the number of shared resource tasks and the number of required processors
图3的实验条件为:生成的任务集合的利用率为8,其中每个任务最多有3个临界区,并固定任务访问共享资源的时间为5 ms。由图3可以看出,由于WF任务划分算法未考虑资源共享问题,所需处理器数量增加最快,而同步感知划分算法和阻塞感知划分算法考虑了共享资源问题并减少了任务阻塞尤其是远程阻塞的发生。因此,这两种算法分配给相同的任务集合的处理器数量明显少于WF算法。本文提出的MrsP任务划分算法在同步感知划分算法和阻塞感知划分算法的基础上,考虑了任务类利用率高于单个处理器时的任务分配算法。对高于单个处理器利用率的任务,根据当前的划分分配到使系统利用率增加少的处理器上。相对于次优的同步感知任务划分算法,MrsP任务划分算法所需处理器数目减少了2%~10%。

图4 任务集利用率与所需处理器数量变化关系Figure 4. The relationship between the number of required processors and task set utilization
图4的实验条件为:任务访问共享资源的时间为5 ms,其中每个任务最多有3个临界区,每个共享资源被10个任务访问。在此实验条件下,增加生成任务集合的利用率,测试各个任务划分算法的性能。任务集合的利用率反映了系统的负载,随着任务集合的利用率增大,所需的处理器数目不断增加。由图4可得,相对于次优的同步感知任务划分算法,MrsP任务划分算法所需处理器数目减少了15%~20%。
针对传统装箱算法、阻塞感知算法、同步感知算法和MrsP任务划分算法,设计了3个实验来验证4种算法的划分性能,3个实验分别改变了共享资源访问时间、访问共享资源任务数量和任务集合利用率3个变量。根据调度任务集合所需的处理器数量来判断4种划分算法的性能,结果表明MrsP任务划分算法调度给定的任务集合所需要的处理器数目少于其他几种任务划分算法。
5 结束语
本文结合P-RM算法和MrsP协议得出了多处理器实时系统的整体可调度性条件。随后,根据MrsP协议的特性,改进任务利用率的计算方式,解决了关键区重复计算的问题,并在此基础上提出了一种减小阻塞时间的任务划分算法。相对于之前的任务划分算法,该算法解决了对任务分类后进行适当拆分并再分配的问题。实验表明,本文提出的任务划分算法调度给定的任务集合所需要的处理器数目少于之前的任务划分算法。
本文的研究基于同构多处理器平台。然而当前多处理器的发展趋势是异构多处理器系统[19-20]。未来的研究工作应当基于异构多处理器平台,其中异构多处理器平台上的实时调度和共享资源访问问题是需要重点研究的方向。当在异构多处理器平台上使用划分调度算法时,将任务划分至不同大小的处理器上也是急需解决的问题。
