多尺度特征和注意力融合的生成对抗壁画修复
2023-03-18陈永陈锦陶美风
陈永,陈锦,陶美风
(1.兰州交通大学电子与信息工程学院,兰州 730070;2.甘肃省人工智能与图形图像处理工程研究中心,兰州 730070)
敦煌莫高窟是世界上现存规模最宏大、内容最丰富的佛教石窟壁画宝库,其内所存的壁画、经卷等具有珍贵的研究价值。然而,由于自然风化的破坏及人为因素的影响,窟内壁画出现了地仗脱落、划痕、褪色、裂纹等严重的灾害,亟待保护。因此,研究病害敦煌壁画的修复极其重要。但是,人工修复存在风险大、不可逆等问题,将数字化虚拟修复应用于古代壁画的保护是目前的研究热点问题[1]。
数字化图像修复(image inpainting)是一种根据图像已知内容去推测并修复出破损或缺失区域内容,使修复后的图像尽可能满足人类视觉感知需求的技术手段[2]。图像修复算法主要分为传统图像修复算法和基于深度学习的图像修复算法。传统的图像修复算法主要包括基于扩散的图像修复方法[3-4]和基于样本块的图像修复方法[5],传统图像修复算法利用纹理和结构等先验信息,可以完成小面积的图像修复。Li 等[6]提出一种基于压缩全变分(compressive total variation)的模型来描述图像的稀疏性和低秩先验知识,以实现对图像的重构。Fan[7]在Criminisi 算法的基础上引入邻域和结构信息对优先权和匹配策略进行改进,避免了错误匹配的问题。陈永等[8]提出了一种改进曲率驱动扩散的敦煌壁画修复算法,提高了对壁画裂纹的修复效果。Yang 等[9]在偏微分方程修复算法的基础上通过对结构张量进行改进,提高了对小尺度细粒纹理的处理能力。
上述传统图像修复算法对小面积破损具有一定的修复能力,当破损面积过大时,修复效果较差。基于深度学习的图像修复算法相较于传统图像修复算法能够学习得到更高层的图像特征[10]。国内外学者相继开展了基于深度学习方法的图像修复研究。例如,Qin 等[11]提出了基于多尺度注意力网络的修复模型,通过引入多尺度注意组来提高修复后图像的真实性。Zeng 等[12]提出了基于上下文编码(contextencoder)修复网络,通过对全分辨率输入的上下文语义进行编码完成破损图像的修复。Iizuka等[13]通过引入全局判别器和局部判别器提高了修复后图像的局部清晰度。Yan 等[14]在U-net 模型的基础上增加了Shift 连接层,并在解码器特征上引入引导损失,提高了修复后图像的精度。Zeng 等[15]利用深度卷积神经网络对破损图像产生粗略修复图,利用最邻近像素匹配进行可控制修复,使得修复的图像更具高频真实感。曹建芳等[16]针对古代壁画起甲、脱落等问题提出一种增强一致性生成对抗网络的图像修复算法,提高了修复后壁画全局与修补区域的一致性。Liu 等[17]提出了一种联合互编解码器和卷积神经网络(convolutional neural networks,CNN)的修复模型,将编码器的深层和浅层特征作为卷积神经网络的输入,使得修复后的图像结构和纹理更加一致。
然而,敦煌壁画的破损呈现的形状是多种多样的,破损的壁画往往存在细节丢失、特征不足等问题[8]。综上所述,现有的基于深度学习方法虽然能够修复较大面积破损的普通图像,但是对于特征多变、纹理密集壁画图像的修复仍存在较多缺陷,如存在特征提取不足及细节重构丢失等问题[11,16]。针对上述问题,本文提出了一种多尺度特征和注意力融合的生成对抗壁画修复算法。首先,设计多尺度特征金字塔网络提取壁画中不同尺度的特征信息,充分利用壁画特征多样性,增强了壁画图像之间的特征关联性,克服了现有深度修复模型特征提取单一的问题。然后,采用自注意力机制及特征融合编码器构建多尺度特征生成器,以获取丰富的上下文信息,提升网络的修复能力,克服了修复后细节重构丢失的问题。最后,引入最小化对抗损失与均方误差促进判别器的残差反馈,从而结合不同尺度的特征信息完成壁画修复。通过对敦煌壁画的修复实验结果表明,本文算法较对比算法获得了较好的主客观评价效果。
1 相关理论
生成对抗网络(generative adversarial networks,GAN)主要由生成器和判别器组成,生成器一般由编码器和解码器组成,其基本构成如图1 所示[18]。其中,生成器主要是将输入的随机噪声或样本图像利用已学习到的概率分布重新生成新的图像,而判别器用来判别输入数据的真假,其输出为一个概率值。

图1 生成对抗网络基本结构框架[18]Fig.1 Basic structural framework of GAN[18]
如果x为真实数据,则判别器D(x;ϕ)输出表示为
若x为生成数据,则判别器输出表示为
模型通过最大化 log2(D(x))和 log2(1−D(G(z)))训练判别器,通过最小化 log2(1−D(G(z)))训练生成器,如下:
式中:z为随机噪声;V(G,D)为估值函数;Pdata(x)为数据分布函数;P z(z)为噪声分布函数。
GAN 将图像修复问题转化为生成器与判别器相互博弈的问题,利用生成器和判别器的对抗学习达到图像修复的目的。
2 本文算法
2.1 网络总体框架
壁画图像通常含有复杂的纹理结构等特征信息,并且特征之间具有较强的关联性。而现有GAN等深度学习图像修复算法在修复壁画图像时仅利用一系列卷积核提取壁画单一层特征,忽略了壁画特征信息的多样性,导致修复后的壁画存在特征提取不足及细节重构丢失等问题。基于此,本文提出了一种多尺度特征融合的生成对抗网络(multi-scale feature fusion generative adversarial network, MS-FFGAN)模型对破损敦煌壁画进行修复。
本文MS-FFGAN 网络整体结构如图2 所示,主要由多尺度特征提取和自注意力机制融合的生成器和判别器构成。首先,对于输入破损壁画图像,利用本文MS-FFGAN 网络生成器中的多尺度融合特征编码器和解码器,结合注意力机制将学习到的特征分布生成所需的壁画图像;然后,将生成的壁画图像及真实样本图像作为判别器的输入进行判别,并将反馈信息反馈到生成器更新网络参数,通过两者对抗训练达到壁画修复的目的。

图2 本文总体模型框架Fig.2 Overall framework of the proposed model
2.2 多尺度特征融合生成器
在MS-FFGAN 网络模型中,生成器由多尺度特征金字塔、特征融合编码器和解码器3 部分组成,如图3 所示。本文算法设计了多尺度特征金字塔网络作为生成器的特征提取网络,用以提取壁画的不同尺度特征,再利用特征融合编码器对提取到的特征进行融合,把低分辨率、高语义信息的壁画高层特征和高分辨率、低语义信息的壁画低层特征进行自上而下的侧边连接,使得所有尺度下的壁画特征都有丰富的语义信息,使网络可以学习到更加全面的壁画图像特征。

图3 多尺度特征融合的生成器结构Fig.3 Structure of generator based on multi-scale feature fusion
在MS-FFGAN 网络的生成器中,多尺度特征金字塔网络利用卷积等操作提取图像不同尺度的特征图。首先采用7×7 卷积核对原图像进行特征提取得到首层特征图,然后通过最大池化得到次层特征图,最后分别通过4 次下采样操作后得到不同尺度的特征图,计算如下:
式中:si,j为 特征图的第i行j列的元素;xi,j为原图中第i行j列的元素;wm,n为权重;wb为偏置;f为ReLU激活函数;w0和h0分别为池化后特征图的宽度和高度;t为滤波器卷积核尺寸大小;s为 步长;n为输入特征图大小;p为边补充大小;l为卷积核大小;m为下采样后的特征图大小。
特征融合编码器主要包括纵向和横向2 个网络分支。纵向路径通过对空间上低分辨率、高语义信息的壁画高层特征图进行上采样,来获取高分辨率的特征;横向路径通过将多尺度特征金字塔网络特征图与相应的低层特征进行融合,得到所需的多尺度融合特征图,如图4 所示。

图4 特征融合过程示意图Fig.4 Schematic diagram of feature fusion process
特征融合编码器采用上采样及加和操作将图像中不同尺度的特征进行融合。以特征图C3 与P4融合为例,首先通过1×1 卷积对特征图C3 通道数降维得到C3′,然后为使特征图P4 大小与C3′保持一致,对P4 进行2 倍上采样,最后将C3′与上采样后的P4 进行加和得到融合后的特征图P3。为减少计算量且保持加和后特征图通道数不变,利用式(7)对特征图进行加和,之后再进行卷积。
式中:xi和yi分 别表示进行加和操作的双方的通道;ki为 第i个通道卷积核;“ ∗”表示卷积。
在图4 中,网络特征融合时,对于输入原始壁画图像,通过卷积及最大池化得到特征图C0~C5,在C2~C5 的基础上,通过1×1 卷积在特征图尺寸大小不变且通道数保持一致的情况下得到待融合特征图C2′~C4′,通过加和操作分别与最邻近上采样后的P5~P3 进行融合,最终得到特征图P2。图5为融合部分结构原理。

图5 融合结构原理Fig.5 Schematic of fusion structure
此外,为了消除上采样产生的混叠效应[11],对融合后的特征图P4~P2 采用3×3 卷积进行处理,得到最终的特征图F4~F2,计算公式如下:
式中:F i为 最终生成的特征图;为卷积核尺寸3×3、步长1 的卷积层;S2×up为 2 倍上采样操作;“ ⊕”表示融合操作;Pi+1、Ci+1分别为待融合的两路输入。
在深度学习模型中,采用跳跃连接结构可以较好地解决训练过程中梯度爆炸和梯度消失的问题,提升网络的表征能力[19]。借鉴这一思想,在特征融合编码器和解码器之间采用跳跃连接结构,将最终的特征图作为解码器的输入,通过跳跃连接和解码功能将潜在的特征解码回图像,达到生成图像的目的。特征融合编码器与解码器工作原理如图6 所示。
在图6 中,特征融合编码器通过式(9)中转换函数f对输入图像x进行编码,将其转换为中间语义C。解码器通过式(10)中的函数g及 中间语义C、历史生成信息y1,y2,···,yi−1生 成所需图像yi。
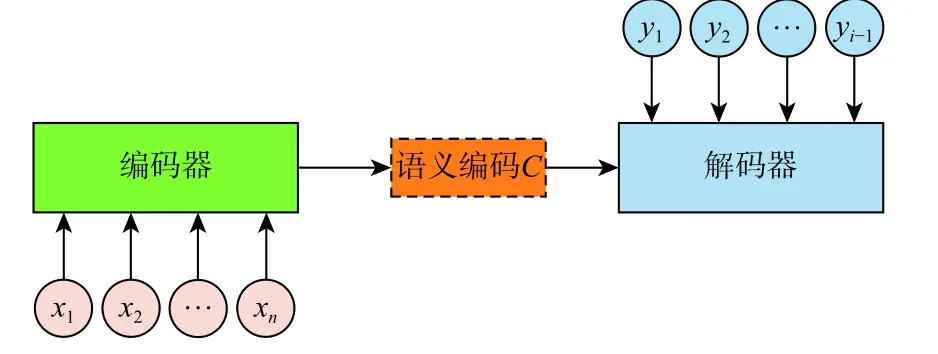
图6 编码器与解码器示意图Fig.6 Diagram of encoder and decoder
2.3 自注意力机制
在MS-FFGAN 特征融合网络中,通过多尺度特征融合的方法增强了壁画图像局部特征与全局特征的关联性,克服了单一尺度壁画图像修复算法特征提取不足的问题。但由于卷积操作是卷积核对局部感受野邻域内的信息进行处理的过程,无法对关联全局信息建立长距离的依赖关系,而注意力机制能够捕获全局的依赖关系[20]。自注意力机制通过捕捉全局的信息来获得更大的感受野和上下文信息,因此,本文提出将自注意力机制结合到壁画修复GAN 网络结构中,克服了特征提取不足及信息利用率低等问题,使MS-FFGAN 网络能够学到更加精细的壁画特征,从而克服细节重构丢失等问题。在特征融合时引入自注意力机制,其结构如图7 所示。

图7 自注意力模型结构Fig.7 Structure of self-attention model
在图7 中,输入为壁画多尺度金字塔相应层的特征图X∈RC×H×W,通过大小为1×1、通道数为L的卷积层 C1、 C2、 C3得 到特征f、q、h, 其中,{f,q,h}∈RC×H×W;将f、q重构为 RC×N,其中,N=H×W表示像素点的个数。为了保证自注意力特征图与输入特征图大小一致,需要将fT与q矩 阵相乘得到N×N大小的特征图,经过Softmax 层得到注意力映射图P∈RN×N,公式如下:
将注意力映射图P与 特征h、 权重因子 α相乘后并与特征X相加,从而得到大小为C×N的自注意力特征图Y,公式如下:
2.4 损失函数
采用MS-FFGAN 网络对壁画进行修复训练时,通过壁画不同尺度的特征及自注意力机制,并结合对抗损失对生成器和判别器进行优化,从而完成壁画的修复。其中,损失函数采用对抗损失函数与均方误差(mean square error,MSE)来优化网络模型。
首先,对生成器的最终预测进行定义:
式中:x为像素真实值;“ ⊗”为逐元素相乘;m代表掩码;1 为破损区域。
判别器的损失表示为
式中:D(x)和D(z)为判别器输出的归一化概率。
生成器的损失表示为
采用均方误差MSE 作为本文算法的损失函数,公式如下:
式中:m为训练数据集数量。
通过最小化对抗损失和MSE 的残差反馈实现本文模型的优化,MS-FFGAN 损失函数定义如下:
3 实验结果与分析
为了验证本文算法的有效性,通过对敦煌壁画人为添加破损和真实破损壁画分别进行修复实验,并与Crim inisi 算法[5]及文献[14,17]的修复结果进行对比。评价指标采用峰值信噪比(peak signal-tonoise ra t io,PSNR)及结构相似性(s t r uc t u r a l sim ilarity,SSIM)2 种客观评价指标和人眼主观视觉对修复结果进行分析。实验在W indows10 下进行,使用Python3.6及Tensorflow1.14 搭建深度学习环境。硬件环境为Intel(R)Core i7-10700K CPU @3.80 GHz,32.0 GB RAM,NVIDIA GeFo r ceRTX2060SUPER,对比实验均在相同配置环境下进行。
3.1 数 据 集
选取以唐代壁画为主的2 915 张不同敦煌壁画图像作为数据集来源,并对其进行数据集扩展,形成15 000 张壁画数据集进行实验,其中训练数据集壁画图像120 0 0 张,测试集壁画图像3 000 张。为了更好地对模型进行有效训练,对掩膜数据集进行制作,掩膜数据集分为2 种,即中心掩膜和随机掩膜。中心掩膜为模型自动生成,占比为壁画的30%,随机掩膜由人为制作,数量为1000 张。模型通过将掩膜图像与壁画图像合成得到人为破损壁画图像,对其进行修复以达到训练模型的目的。
3.2 人为添加中心掩膜修复
为了验证本文算法对于破损区域较大壁画的修复效果,首先选取7 幅敦煌壁画对其添加中心掩膜进行修复实验,修复结果如图8 所示。从修复结果可以看出,Crim inisi 算法对于大区域破损的壁画图像修复效果较差,出现了结构紊乱、错误填充等问题,这是因为Crim inisi 算法采用全局搜索复制匹配块的方法进行修复,对于较大面积破损无法完成有效块匹配操作。文献[14]在U-net 模型的基础上增加了Shift 连接层,提高了修复的鲁棒性,但在修复中心掩膜破损壁画时,存在修复不彻底的问题,导致修复后的壁画出现了掩膜块状阴影残留。文献[17]采用联合互编解码器和卷积神经网络的修复模型来提高修复精度,但由于缺乏考虑特征之间的关联性,使得修复后的壁画出现色彩失真、特征缺失等情况。图8(f)为本文算法修复结果,可以看出,本文算法相对于其他3 种算法具有更好的修复效果,对于前4 幅壁画不仅可以修复出其细微特征,并且对于人脸轮廓、眉眼等结构可以有效地进行修复。图8 中第6、7 行为整幅壁画修复比较实验,可以看出,对于大面积人为添加中心掩膜破损,本文算法修复虽有一定的误差,但整体修复结果相对于其他3 种算法更加合理且主观视觉也比较流畅,对于整体结构的重构效果更好。
为了进一步对图8 的修复结果做出定量评价,采用PSNR 和SSIM 进行比较,如表1 所示。PSNR和SSIM 是衡量图像质量的重要定量评价指标。其中,PSNR 值越大,代表失真越少,即修复效果越好;SSIM 是一种衡量2 幅图像相似度的指标,该值越大,表明修复后图像的失真程度越小[8]。从表1 中可以发现,本文算法在PSNR 和SSIM 上均优于其他对比算法,表明其修复质量更好,从而验证了本文算法对于人为破损壁画修复的有效性。

表1 不同算法修复结果PSNR 和SSIM 对比Table 1 Comparison of PSNR and SSIM repair results of different algorithm s

图8 不同算法对人为添加中心掩膜破损壁画的修复结果对比Fig.8 Comparison of different algorithms in inpainting of murals with artificially added central damage
3.3 人为添加随机破损修复
为了进一步分析本文算法对于随机破损修复的有效性,选取6 幅敦煌壁画对其随机添加掩膜进行修复实验,修复结果如图9 所示。从实验结果可以看出,Crim inisi 算法修复后的壁画中第1 幅壁画因为错误填充导致眼角出现了黑色空洞的情况,第2 幅壁画眼部则出现了线条结构紊乱及模糊的问题,第3 幅壁画鼻翼区域及第4 幅壁画眼部上下区域均出现了修复不当、残留等问题,第5、6 幅壁画同样出现了错误填充、像素扩散的问题,导致修复后的壁画主观视觉效果突兀。文献[14]算法修复结果中,前4 幅壁画均出现了色彩失真、错误修复的问题,第5、6 幅壁画则存在模糊、残影等问题。文献[17]算法修复后的壁画中,前2 幅壁画眼部均出现伪影、修复不彻底的问题,其余壁画修复后均出现了像素错误扩散和残影的问题。与对比算法相比,本文算法修复后的壁画在主观视觉效果均有所提高,并且修复后的壁画视觉效果更加合理。图10为不同算法修复后的壁画PSNR 和SSIM 对比。可以较为直观地看出,本文算法修复后的结果在PSNR及SSIM 2 个评价指标上均高于对比算法。

图9 不同算法对人为添加随机掩膜破损壁画的修复结果对比Fig.9 Comparison of different algorithms in inpainting of murals with artificially added random damage

图10 不同算法人为添加破损修复结果PSNR和SSIM对比Fig.10 Comparison of PSNR and SSIM repair results of different algorithms with artificially added random damage
3.4 真实破损壁画修复
为了进一步验证本文算法对于真实破损壁画修复的有效性,选取6 幅真实破损敦煌壁画进行修复实验,修复结果如图11 所示。从第1 幅修复结果可以看出,Crim inisi 算法修复后的结果出现了结构紊乱及线条丢失等问题,文献[14,17]算法修复后出现修复不彻底、痕迹残留等问题,而本文算法修复后的结果线条流畅,比较符合主客观视觉效果。对于第2 幅壁画,Crim inisi 算法修复后结果脸部出现残留及块效应,文献[14]算法修复后结果出现区域模糊的问题,文献[17]算法则出现错误修复及失真等问题,而本文算法对于额头区域的修复相对于其他算法效果较好,并且对于脸颊区域修复也较为彻底,未出现结构错误、纹理缺失等问题。同样,对于第3 幅和第4 幅壁画,Criminisi 算法、文献[14,17]算法均出现修复不彻底、结构断裂的问题,修复效果较差。对于第5 幅壁画,除了文献[17]存在色彩失真及错误填充的问题,其他算法修复效果较符合主观视觉效果和客观逻辑性。第6 幅壁画修复结果可以看出,Crim inisi算法修复后出现了误匹配的问题,文献[14,17]算法均出现了修复区域模糊及色彩丢失的问题,相较于其他算法,本文算法修复视觉效果更好。

图11 不同算法对真实破损壁画的修复效果对比Fig.11 Comparison of different algorithms in inpainting of murals with real damage
4 结 论
本文针对现有深度学习图像修复算法在修复壁画时,存在细节重构丢失、修复效果欠佳等问题展开了相关研究,得到如下结论:
1)提出的多尺度壁画特征提取方法,增强了壁画图像局部特征与全局特征的关联性,克服了单一尺度壁画图像修复算法特征提取不足的问题。
2)提出的自注意力机制及特征融合模块,通过捕捉壁画全局信息来获得更大的感受野和上下文信息,提升了壁画修复网络的细节重构能力。
3)通过对破损敦煌壁画的修复实验表明,本文算法对破损壁画的细节特征能够进行有效修复,其修复视觉效果更好,且PSNR 和SSIM 等定量评价指标均优于比较算法。
