机器学习算法在糖尿病预测中的应用及分析
2023-03-16青海师范大学数学与统计学院谢妮妮
青海师范大学数学与统计学院 谢妮妮
糖尿病是多发慢性病,如何准确预测是否患有糖尿病以及找到影响糖尿病的因素对预防和控制糖尿病显得尤为重要。本文通过几种机器学习算法分析一组糖尿病数据比较几种模型的优劣及影响糖尿病的主要因素。首先在训练集上通过交叉验证找到每个模型的最优参数,然后根据混淆矩阵图计算出每个模型的F1-score作为模型的评价标准。研究发现最适合该数据集的预测模型是Voting,其次是KNN、SVM及随机森林;属性的顺序是 :Glucose, BMI, Diabetes Pedigree Function,Age,Blood Pressure,Pregnancies,Insulin,Skin Thickness。
糖尿病是一种多发慢性病,会引发众多并发症,比如视力减退、中风、心脏病发作等,让患者身心备受煎熬,一直被社会广泛关注。据国际糖尿病联盟(IDF)的2017年调研结果显示,全球约有4.25亿的糖尿病患者,患病率逐年上升,其中我国糖尿病患者比例大于25%[1],预防控制糖尿病是世界各国面临的重大公共卫生问题[2,3]。糖尿病中的2型糖尿病临床确诊前有较长的潜伏期且患病人数众多。因此,对高危人群的筛查预防是控制2型糖尿病患病率的有效途径[4,5]。糖尿病发病风险预测模型是针对健康人群(非糖尿病患者)的糖尿病风险评估工具,也是识别高危人群的有效工具。许多学者利用机器学习算法对糖尿病进行分析预测。例如,Smith等人使用了早期的神经网络模型(ADAP)来预测Pima India高危人群糖尿病的发病率,通过逻辑回归和线性感知器对ADAP结果进行比较[6];Yuvaraj等研究了基于Hadoop集群的机器学习算法在医疗保健系统中的糖尿病预测[7];Hsin-Yi等利用支持向量机、决策树、逻辑回归等方法来研究糖尿病引起的眼底病变[8]等。
大多数糖尿病患者,在他们生病之前并没有察觉到太多,而且仅仅凭借诊断过程中的各种症状来判断是否患糖尿病是不科学的。医院目前进行糖尿病诊断主要是通过检测各类指标[9,10],包括血糖、尿糖、尿酮体等。不仅需要检测这些指标是否在正常范围[11],而且在至少2周的观察期后,还要在医院进行血糖测定等,这需要耗费大量的人力、物力、财力等资源。基于机器学习算法的糖尿病检测与分类研究,不仅不能提供高效的检测方法,还可以探索导致糖尿病的一些被忽视的疾病因素,提高医生效率,减少隐藏患病危险性。目前,抵抗糖尿病最安全的方法是使用机器学习算法来分析和预测糖尿病,为治疗提供新的思路。本文基于机器学习算法来比较几个模型的优缺点和影响糖尿病的主要因素,致力于促进糖尿病治疗的发展,它具有很大的研究价值和重要性。
1 数据来源及预处理
PimaIndians糖尿病数据集有9个特征,通过几种机器学习算法分析数据,根据诊断指标来分析预测是否患病,以及找到主要影响因素。样本量为768,500个被标记为0,用圆锥表示;268个标记为1,用圆柱表示。“结果(标签:是否患病)”是我们将要预测的特征,0意味着未患病,1意味着患病。数据结构如表1所示,预测变量具体情况如表2所示,变量的描述统计量如表3所示,样本标记情况如图1所示。
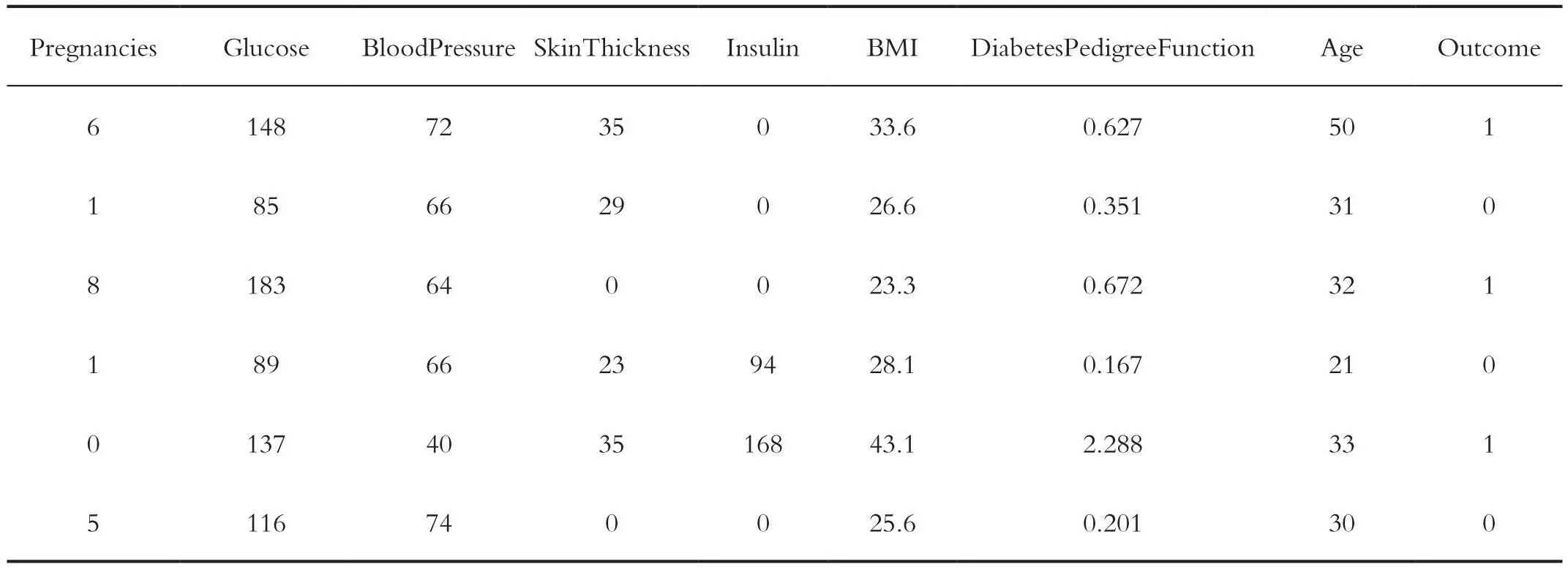
表1 数据结构表Tab.1 Data structure table

表2 预测变量表Tab.2 Predictive variability scale
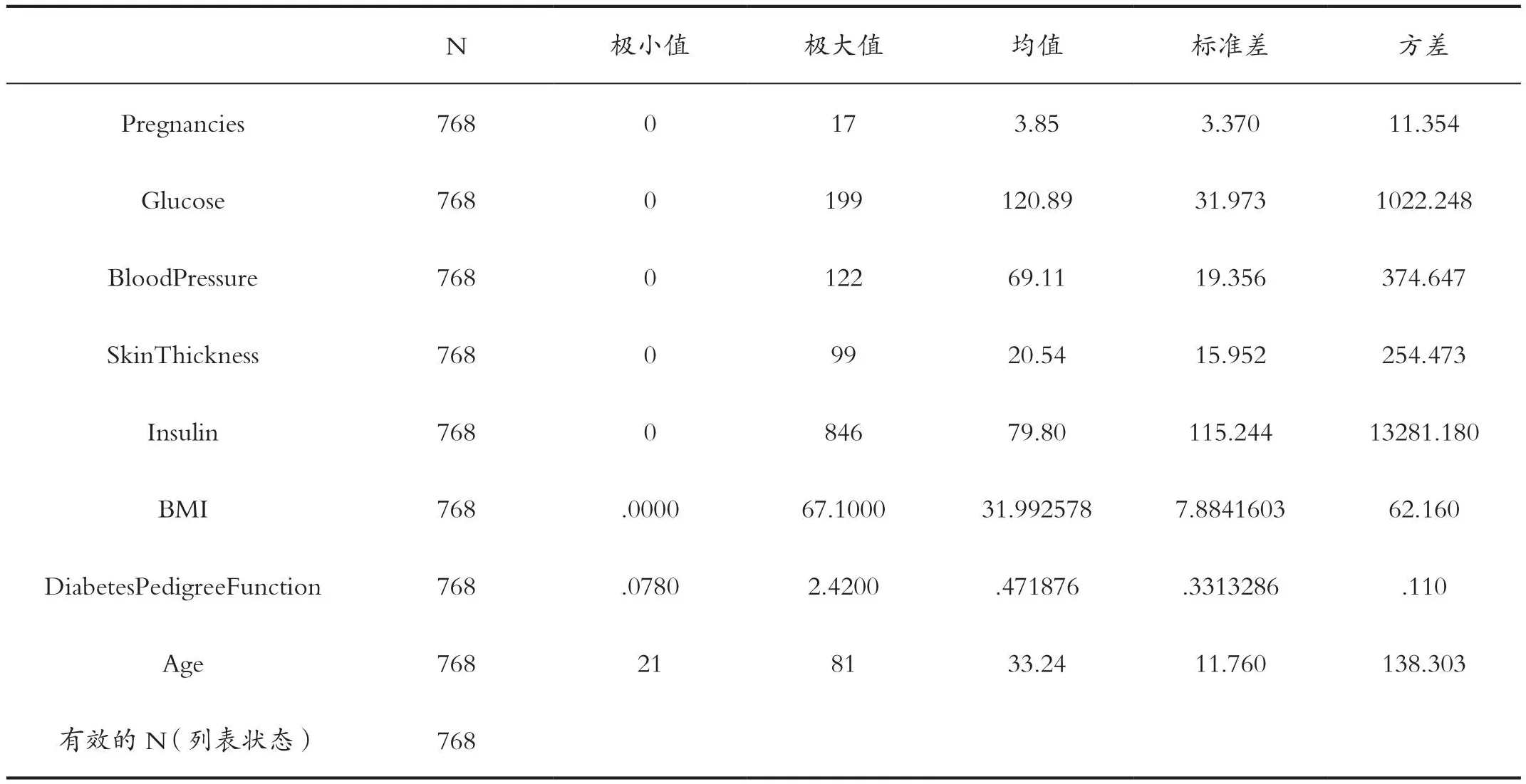
表3 变量的描述统计量Tab.3 Descriptive statistics of variables
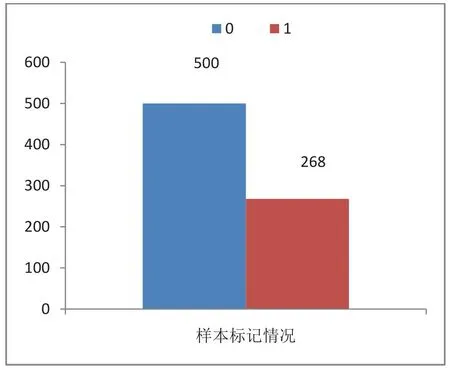
图1 样本标记情况图Fig.1 Sample labeling diagram
2 基本理论与算法分析
2.1 KNN
KNN是机器学习中最简单且应用最广泛的方法之一,所以,我们要先考虑用KNN。KNN是一种惰性学习,没有特定的学习过程。因此,KNN首先要考虑3个要素:K值、距离测量和分类规则。我们用欧氏距离测量距离,用投票的方法得到最终的分类结果,所以我们只需要考虑如何选择K值,K值的选择基于交叉验证法。交叉验证的思想是将数据随机划分,然后,使用训练集在不同条件下训练模型,例如改变参数的数量,改变参数的值。从这些模型中可以找到检验误差最小的模型,即精度最高的模型。
如图2所示为不同K值下KNN模型的精度。横轴表示邻居数,即K值,纵轴表示K值对某一特定值的精度。这里取的K值范围是(0,10)。训练集用蓝线 表示,测试集用黄线 表示。由图2分析可得,训练集的准确率随着k的增加有下降的趋势。测试集的准确率总体趋势是随着k的增加先增加后趋于稳定。我们想要学习模型,在测试集中获得更高的准确率。我们发现,当k为(6,10)时,测试集的准确率略高于训练集;当k=7时,精度最高。
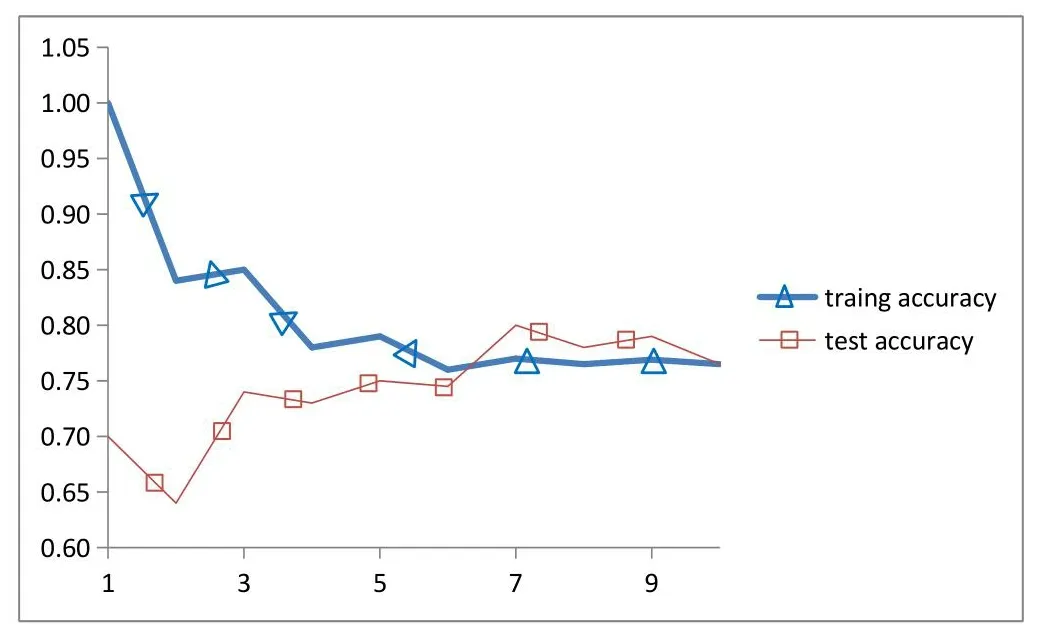
图2 KNN模型的训练集和测试集精度图Fig.2 Precision diagrams of training set and test set of KNN model
通过观察不同k值下KNN模型训练集和测试集的准确率,我们发现当k=7时,测试集的正确率较高,因此我们选择k=7进行建模,得到KNN的混淆矩阵:实际类别是1,预测类别是-1,样本量是20;实际类别是-1,预测类别是-1,样本量是34;实际类别是1,预测类别是-1,样本量是117;实际类别是-1,预测类别是1,样本量是20。通过计算,我们可以得到在K=7时,测试集Accuracy=0.79,F1-score=0.85。
2.2 支持向量机
支持向量机是特征空间中具有最大距离的线性分类器,其本质是解决凸二次规划的优化问题,即最小化正则化的损失函数。SVM最重要的两个参数,一个是惩罚因子C,惩罚因子C的作用是通过改变大小,来控制SVM分类标准的严格程度。当C趋于无限大时,意味着分类严格不能有偏差;当C趋近于很小时表示错误容忍度较高。因此分析可得,惩罚因子取值C=1。核函数是第二个重要的参数,由于支持向量机可以在特征空间中线性分离样本,所以特征空间的选择非常重要。特征空间隐式依赖于核函数。同时,哪个特征空间最适合模型是未知的。因此选取核函数对于支持向量机尤为重要。核函数选取的如果不合适,特征空间就会选择不合适,从而也会导致模型选择不当。通过交叉验证,我们选择了线性核函数,因为当选取线性核函数时,测试集正确率最高,Accuracy=0.78。
选择线性核函数和惩罚因子后,通过建立支持向量机模型得到支持向量机混淆矩阵图。由混淆矩阵可以得到:在预测类别是-1,实际类别是1时,样本量是19;在预测类别是-1,实际类别是-1时,样本量是31;在预测类别是1,实际类别是1时,样本量是118;在预测类别是1,实际类别是-1时,样本量是23,F1-score=0.849。
2.3 随机森林
随机森林基于决策树。随机森林构建完成,新样本将进入随机森林。每棵树都会根据样本做出相应的判断结果,整个随机森林的预测结果遵循少数服从多数的原则。
构建随机森林是决策树的随机组合,其中非叶节点是决策点和测试条件;分支是测试结果,叶节点代表最终的分类标记,构建决策树的基本思想是随着树的深度增加,节点的熵加快降低,熵值降低的越低越好,因此,可以得到最短的决策树,如果熵值变小,则表示当前的分类效果比上一步好,分类效果得到了提高,分类进度用信息增益表示。信息熵的值越小,特征的纯度越高。决策树分割的属性选择需要信息增益,信息增益越大,通过属性分割得到“纯度改善”越大。
随机森林的优点是速度快,容易实现并行计算,并且可以检测到属性之间的相互作用,根据收敛定理,当随机森林的数量趋于无穷时,可以用大数定理证明训练误差和检验误差可以收敛在一起。在实际问题中,决策树的数量不是无限的,模型参数的改变也会影响模型的训练结果,拟合效果也不同,树的数量是随机森林的一个重要参数。不同决策树下随机森林训练集和测试集正确性可视化如图3所示。横坐标表示决策树的个数,纵坐标表示准确率,当决策树个数为n(0,10)时,训练集的准确率趋于提高;当n>10时,训练集的精度趋于稳定,测试集的总体趋势波动很大;当n为(10,15)时,测试集的准确率最高,通过观察,当决策树数量为n=13时,测试集的准确率相对最好,为0.77。
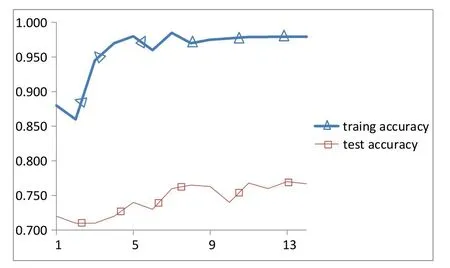
图3 随机森林模型的训练集和测试集精度图Fig.3 Precision graphs of training and testing sets of random forest model
基于不同决策树数下训练集的准确率和随机森林测试集的准确率的比较图,当决策树个数为n=13时,测试集的准确度为0.77。考虑到训练集正确率随决策树数的变化趋势,一般情况下,我们仍然选择决策树个数n=13进行随机森林建模,由混淆矩阵图可以看出,当预测类别为-1,实际类别为1时,样本量为29;当预测的类别为-1,实际类别为-1时,样本大小为37;当预测类别为1,实际类别为1时,样本量为108;当预测类别为1,实际类别为-1时,样本量为17,计算是可用的,随机森林的优点之一是它可以比较每个属性的重要性。
通过分析,得到了随机森林中的特征排序图如图4所示,横轴表示属性索引值,纵轴表示特征的重要性,从特征排序图中我们可以看到,糖尿病检测最重要的属性是:血糖、BMI和糖尿病遗传系数。

图4 随机森林特征排序图Fig.4 Random forest feature ranking diagram
2.4 Voting
在机器学习中对于分类问题, 投票法是最常用的结合策略。首先每个弱分类器做出分类预测,接着基于投票法结合后得出最终结果。投票法在机器学习中有不同的投票方式,简单投票是最频繁使用的方法,通过基于简单投票法中的相对多数表决法结合不同分类器的预测结果,投票数最大的类别是综合模型的最终预测类别。
通过投票对多个模型的结果进行聚合就是分类聚合投票,模型的选择应该是好的或坏的,这样,最终的聚合效果提高。在这里,选择KNN,支持向量机和随机森林作为基本聚合模型,每个模型基于一个简单的交叉验证方法选择最佳参数。
研究分析可得,由混淆矩阵可知:在预测类别是-1,实际类别是1时,样本量是14;在预测类别是-1,实际类别是-1时,样本量是29;在预测类别是1,实际类别是1时,样本量是123;在预测类别是1,实际类别是-1时,样本量是25。计算可得,Voting测试集准确率为0.80,F1-score=0.86。
3 实验及结论
我们通过KNN、SVM、随机森林以及Voting分类聚合模型可以看出,每个模型对数据的影响是不同的,通过比较模型的效果,最终选择F1-score作为模型效果的评价基准。
在单一分类模型中,我们使用KNN和SVM,它们的分类效果也比较显著,在对KNN和SVM模型建模之前,我们采用交叉验证方法,使用测试集精度最高的参数,然后通过建模得到模型结果的混淆矩阵图,由KNN模型的混淆矩阵图可知,Accuracy=0.79,F1-score=0.854;从支持向量机的混淆矩阵图可得Accuracy=0.78,,F1-score=0.849。显然,在单分类器中,KNN模型得分结果要好于SVM模型,效果最好的是KNN分类器。
本文选取了并行积分方法中的随机森林法,随机森林是通过Bagging的扩展和变化得到的,在基于决策树的学习装置的基础上,它在训练过程中比套袋有更多的随机属性选择,综合考虑后,选择随机森林算法。
结合不同学习者的学习效果,选择效果相对较好的分类器对投票模型进行聚合,在投票聚合模型中,我们选择了3个效果比较好的分类器,分别是KNN、SVM和Random Forest,通过建立分类聚合模型,得到了混淆矩阵图,由投票的混淆矩阵图,我们可以得到:测试集Accuracy0.80,从前面的分析可以看出,KNN是分类效果最好的单一分类器,Random Forest是集合中最好、最适合的分类模型,但它们的得分都低于分类投票的聚合模型。
4 结语
在机器学习的单一模型中,我们选择了SVM和KNN两个分类效果最好的模型,KNN更适合于糖尿病的预测,因为KNN的F1-score=0.854,同时获得KNN的准确性:Accuracy=0.79,将单个学习者表现最好的模型和与分类投票聚类模型综合学习效果最好的模型的结果进行比较,发现分类投票聚类模型的效果最好,因为我们在实验中选择了KNN、SVM和Random Forest这3个最好的模型作为聚合的基本模型,我们想验证:如果我们把所有优秀的模型结合起来,是否可以得到更好的模型?从我们选择的皮玛印第安人糖尿病的数据集来看,答案是肯定的,我们是否能在其他数据集中得到一致的答案还需要进一步验证。
因此,我们最终选择了最好的分类投票聚合模型,然后选择了KNN以及支持向量机和随机森林。在选取的8个属性中,属性的重要性由高到低依次为:血糖值、BMI、遗传指数、年龄、血压、怀孕次数、胰岛素含量、皮脂厚度。从预防糖尿病的观点来看,应该更加注意血糖值是否在稳定的范围内,随着年龄的增长,患糖尿病的风险较高,控制体重尤为重要,由于遗传因素,我们不能有心理负担,要保持良好的精神、积极的生活方式和健康习惯。
引用
[1]CHO N H,SHAW J E,KARURANGA S,et al.IDF Diabetes Atlas:Global Estimates of Diabetes Prevalence for 2017 and Projections for 2045[J].Diabetes Research and Clinical Practice,2018,138(1):271-281.
[2]LU C,SUN W.Prevalence of Diabetes in Chinese Adult[J].JAMA,2014,311(2):199-200.
[3]YANG W,LU J,WENG J,et al.Prevalence of Diabetes Among Men and Women in China[J].The New England Journal of Medicine,2010,362(25):2425-2426.
[4]BHUSHAN R,ELKIND H K E,BHUSHAN M,et al.Improved Glycemic Control and Reduction of Cardiometabolic Risk Factors in Subjects with Type 2 Diabetes and Metabolic Syndrome Treated with Exenatide in a Clinical Practice Settin[J].Diabetes Technol Ther,2009,11(6):353-359.
[5]TUOMILEHTO J,LINDSTRÖM J,ERIKSSON J G,et al.Prevention of Type 2 Diabetes Mellitus by Changes in Lifestyle Among Subjects with Impaired Glucose Tolerance[J].New England Journal of Medicine,2001(344):1343-1350.
[6]SMITH J W,EVERHART J E,DICKSON W C,et al.Using the ADAP Learning Algorithm to Forecast the Oneset of Diabates Mellitus[J].Prock Annu Symp Comput Appl Med Care,1988,56(10):261-265.
[7]YUVARAJ N,SRIPREETHAA K R.Diabetes Prediction in Healthcare Systems Using Machine Learning Algorithms on Hadoop Cluster[J].Cluster Computing,2017(1):1-9.
[8]TSAO H Y,CHAN P Y,SU E C Y.Predicting Diabetic Retinopathy and Identifying Interpretable Biomedical Features Using Machine Learning Algorithms[J].BMC Bioinformatics,2018,19(S9):195-205.
[9]马晓云.糖化血红蛋白与果糖胺在妊娠糖尿病患者中的诊断效果及价值研究[J].糖尿病新世界,2016,24(12):122-123.
[10]程捷,万斌,李雯霞.影响2型糖尿病患者血糖监测依从性相关因素调查分析[J].护士进修杂志,2012,27(18):1654-1656.
[11]PARK P J,GRIFFIN S J,SARGEANT L,et al.The Performance of a Risk Score in Predicting Undiagnosed Hyperglycemia[J].Diabetes Care,2002(25):984-988.
