基于RoBERTa的多标签作业许可文本分类方法
2023-03-16长庆油田公司许斌张亮陈喆
长庆油田公司 许斌 张亮 陈喆
作业许可的本质与核心是风险管理,作业前危害辨识与风险分析是一项费时费力的工作,过于依赖人的专业经验。随着信息化的发展,大量作业许可风险数据被保存下来,但这些数据多以文本形式存在,难以提取有用信息实现共享和复用。针对此问题,本文提出一种基于RoBert的多标签作业许可文本分类模型,可实现对高危作业的作业类型、危害因素、安全措施等信息的多标签自动分类和提取。最后在中石油某企业近10万条作业许可数据集上进行模型训练与测试,实验结果表明,该多标签分类模型在测试数据集上的平均F1值达到86%,可有效提取高危作业风险信息。
作业许可是指在从事高风险作业及在生产或施工作业区域内工作规程未涵盖到的非常规作业(简称高危作业)等之前,为保证作业安全,必须取得授权许可方可实施作业的一种制度[1],是开展危害识别和作业前风险分析的前提和保障,是减少和避免事故发生的重要措施之一[2]。
高危作业实行作业许可制度的核心和灵魂是风险辨识与评估,然而风险辨识与评估是一个专业、费时且以人为中心的分析过程,其本质上是主观的,依赖于专业经验与能力。当前作业许可的管理过程中,存在许多走过场的现象,如在危害因素辨识时,大多是简单标注一下许可证上罗列的有关风险,没有真正开展危害因素辨识和风险评估工作,所制定的措施也多是抽象型内容,不具可操作性[3]。随着网络技术的迅速发展,国内大多数石油化工企业建立了作业许可管理信息系统,积累了大量作业许可证数据,但这些数据大多处于静态数据库中,且大量数据以文本形式保存,无法实现共享和复用[4]。
通过研发基于RoBert的多标签作业许可文本分类模型,挖掘现有作业许可风险数据,提炼和聚合大量风险评估专家的知识和经验,实现对高危作业的作业类型、危害因素、安全措施等信息的多标签自动分类和提取,解决作业许可风险辨识不全面、安全措施不具体的问题,从而提升作业许可管理水平。
1 相关研究
目前主流的多标签文本分类模型为端到端的模型,模型结构分为文本特征提取器和分类器。其中对性能影响最大的是文本特征提取器部分,目前主流的文本特征提取器有卷积神经网络、循环神经网络与预训练语言模型。
1.1 卷积神经网络
卷积神经网络(Convolutional Neural Network)简称为CNN,与普通的全连接神经网络相比,卷积神经网络的结构有很大不同,可以看成是一种对全连接神经网络的改进,通过添加一种被称为卷积核的特殊结构来提取图像的局部特征。卷积核相当于一个滤波器,卷积操作就相当于对图像使用滤波器进行滤波,得到该滤波器对应的特征图。在传统的图像处理中,滤波器也就是卷积核都是经过特殊设计的,而在卷积神经网络中每一个卷积核只需要进行随机初始化,卷积核的参数会在训练过程中自动优化。
一般来讲,图像的特征向量的维度等于该图像所包含的像素的数量,一张100×100的三通道图像的像素点有30000个,该图像的特征向量有30000维,若使用全连接神经网络则网络的参数量会特别庞大,不仅会大大提高训练的难度还会导致过拟合,并且真实场景中的图像大小会远远超过100×100。卷积神经网络使用了参数共享机制来解决这一问题,同一个卷积核所做的卷积操作本质上就是使用同一套参数在整张图像滑动做内积,以此达到参数共享的目的,这大大减少了模型的参数量。这一操作的依据为图像数据具有一种叫做局部感知野的特性,即在图像中距离近的像素往往关系并具有相同的语义特征。
卷积神经网络同样可以应用于自然语言处理中[5],因为人类语言同样具备一定的局部感知野,在一句话中往往邻近的汉字之间具有更加紧密的关系。在自然语言处理中,每一个汉字或词语都对应一个N维的字向量或者词向量,一个包含M个字或词的句子可以表示为一个MxN的矩阵,可以进行卷积操作。不同的是对于图像的卷积是二维卷积,卷积核可以在整张图片的X轴和Y轴上移动,而对词向量矩阵的卷积是一维卷积,这是因为卷积核必须有一个维度与词向量的维度相同,即卷积核只能在代表句子长度的维度上做卷积运算,以确保句子中每一个词语的信息不丢失。如图1所示是用于作业许可数据文本分类的卷积神经网络模型,其中Embedding层为双通道,两个通道都使用了CNPC词向量进行映射,不同的是其中一个通道的数值随着模型的训练一起更新,而另一个通道的参数保持不变。卷积层使用了3个不同长度的一维卷积核来提取文本数据的N-Gram特征,最后将三个不同的卷积核提取的特征拼接起来接入一个线性分类器进行分类。本章节中的基于卷积神经网络的文本分类模型参考了TextCNN的模型结构。
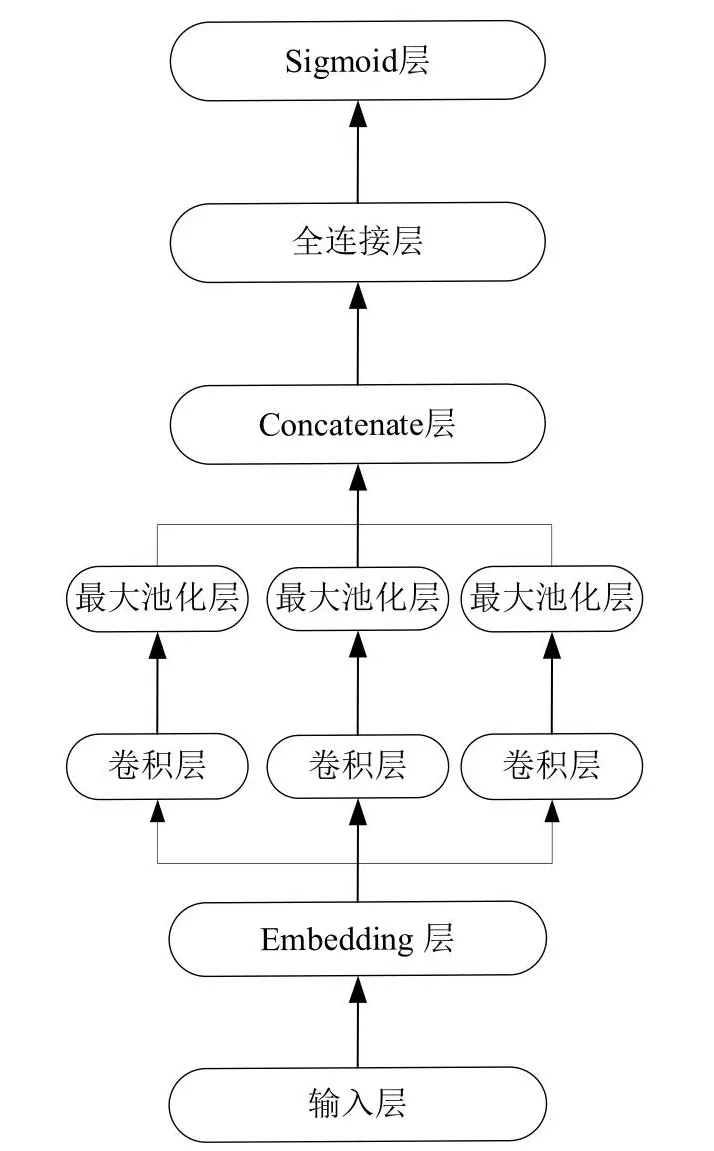
图1 CNN文本分类模型Fig.1 CNN text classification model
1.2 循环神经网络
循环神经网络(Recurrent Neural Network)简称为RNN。不同于卷积神经网络和全连接神经网络,循环神经网络主要用于处理序列数据,即在时间或空间上有先后顺序的数据,例如人类的语言文字、股票的走势等。卷积神经网络和全连接神经网络并不适合处理这类序列数据,因为这类网络无法捕捉到序列数据在时间和空间上的关系,模型在处理某一个序列的某一个时间点上的数据时只会关注该时间点上的数据,这意味着该数据会被孤立。循环神经网络能够回顾序列中当前时间点之前的数据来产生当前时间点的输出,通过回顾可以了解所有之前的输入。但从实际操作中看,它只能回顾最后几步。如图2所示为本论文设计的用于作业许可数据文本分类的循环神经网络模型。RNN同样可以用于文本分类任务[6],本论文使用Bi-LSTM来提取作业许可文本的上下文特征,最后接入全连接层与Softmax层进行分类并输出分类结果。该基于循环神经网络的文本分类模型参考了TextRNN的模型结构。
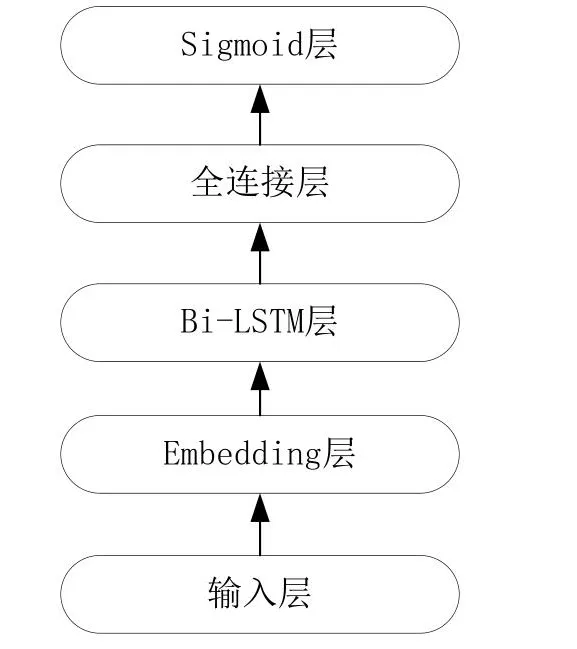
图2 RNN文本分类模型Fig.2 RNN text classification model
1.3 预训练语言模型
深度学习技术在NLP任务中已有广泛应用,基于人工神经网络的NLP方法正在逐步取代传统的NLP方法。传统的NLP文本分类方法需要人工设计文本特征,人工设计特征效率低下且分类效果并不理想,而基于神经网络的NLP方法能够从大量的训练样本中自动提取文本特征,相比于传统NLP方法,基于人工神经网络的NLP方法更加高效且分类准确率更高,人工神经网络技术大大简化了各类NLP系统的开发难度。尽管已经能够将神经网络模型应用于NLP任务中,但由于缺少像ImageNet那样的大规模的经过人工标注的数据集,与计算机视觉领域相比,神经网络模型为NLP任务带来的性能改进并不显著。而且深度神经网络通常具有大量的参数,使得它们在这些小的训练数据上过于拟合,在实际应用中不能很好地推广,所以早期NLP任务的模型结构相对简单(浅层神经网络)。本论文所研究的作业许可文本分类任务同样是一个有监督的学习任务且训练样本较少、获取成本较高,本论文使用的前3种网络均为浅层神经网络。
目前机器在自然语言阅读理解上的表现甚至已经超越了人类的表现,这都归功于新的模型结构的提出,那就是基于Self-attention机制的Transformer模型[7]。Transformer是由谷歌公司提出的一种Seq2Seq模型,在原始论文中用于语言翻译任务。Transformer相对于LSTM来说最大的不同点就是LSTM是迭代计算的,即计算得出前一个字符的隐状态后才能计算下一个字符的隐状态。而Transformer是并行计算的,即能够同时计算整个序列中所有字符的隐状态,本质上就是能够转化为张量运算。这一特征使得Transformer能够很好地利用GPU进行加速,从而使得训练大型模型成为可能。目前在自然语言处理领域的各项任务中表现最好的模型都是基于Transformer模型结构在大规模语料数据上训练得到的,如BERT、XLNet、RoBERTa 等。
Transformer相较于LSTM的另一个明显优势就是Transformer能够解决长期依赖问题,尽管LSTM相较于经典RNN模型在长期依赖方面有所改善,但依然不能完全解决长期依赖问题。Transformer中使用的自注意力机制能够使序列中每一个字符的隐状态都包含序列中其他字符的信息,无论该字符与序列中其他字符距离多远都能够等价编码。Transformer有编码器和解码器两部分组成,而基于Transformer的预训练语言模型仅使用了其编码器部分。下面对Transformer模型的编码器进行详细介绍。
如图3所示为Transformer编码器的模型结构。其中“位置信息”节点代表的操作是为对输入向量添加位置编码,因为对于Transformer来说一个序列中的所有字符在位置上都是等价的,但对于自然语言来说字符的位置信息至关重要,包含相同汉字的两段中文其含义可能截然不同。所以要为输入字符向量添加位置编码,一般使用正弦函数进行位置编码。“多头自注意力”节点所代表的操作为对输入向量进行Self-attention操作,这是Transformer模型的核心操作,通过该操作使得每个字符的隐状态包含有该句子中其他所有字符的信息。“Add&Norm”节点所代表的操作为Layer Nomalization和残差连接。在反向传播的过程中,残差连接梯度可以直接传到初始层。Layer Nomalization的作用是将隐状态归一为标准正态分布。通过添加这两个特殊的层,能够加快训练过程中模型的收敛速度。下面为各个步骤的主要数学表示:
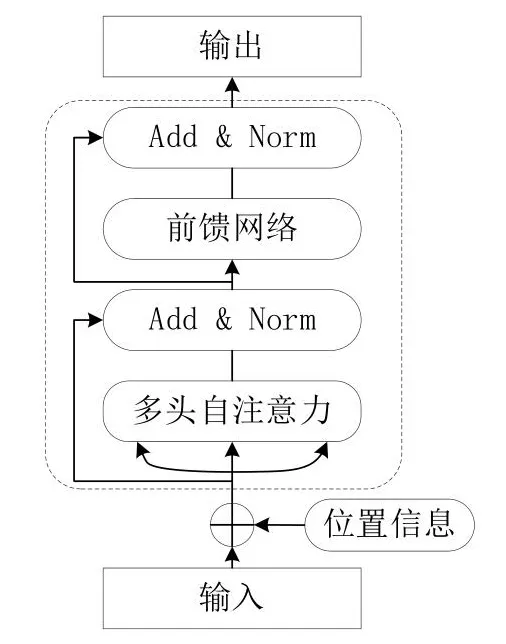
图3 Transformer编码器模型结构Fig.3 Transformer encoder architecture
(1)字向量与位置编码
(2)自注意力机制
(3)残差连接与Layer Normalization
(4)Feed Forward
图3为一个处理单元,Transformer的编码器由多个这样的单元组成,通过增加层数来增加参数量,提高模型特征提取能力和泛化能力。
BERT[8]是最具代表性的一种预训练语言模型,其模型架构本质上就是Transformer的编码器部分。BERT首先在大规模公开语料上进行预训练,学习语言的通用特征,然后再将该预训练模型在具体的下游任务中进行微调。BERT的预训练过程是无监督的,即无需人工标注的训练数据,这意味着能够充分利用互联网上的各种文本数据。
预训练语言模型有上下文相关模型和上下文无关模型两种。上下文无关模型为词典中的每一个词都生成一个向量表示,即词向量。但上下文无关模型会存在一词多义的问题,即同一个词向量编码了多种语义,Word2Vec和GloVe是最具有代表性的上下文无关模型。与上下文相关语言模型不同,上下文相关的预训练语言模型能够根据句子的上下文来为词语生成词向量,BERT是最具有代表性的上下相关模型。
BERT的模型架构与Transformer的编码器部分基本一致。该模型使用了两种特殊的训练方式,第一种是将输入序列中15%的单词(中文以汉字为单位)屏蔽掉,然后使用一个深层的Transformer编码器来预测被屏蔽掉的单词;第二种是判断两个随机抽取的句子是否存在上下文关系。
1.4 二元交叉熵损失
二元交叉熵损失简称为BCELoss(Binary Cross Entropy Loss),主要用于作为多标签文本分类的损失函数。单标签文本分类的目标是根据输入序列,找出概率最高的一个标签。多标签文本分类的目标是根据输入序列找出所有与输入序列相关的标签。在模型构造层面的区别是,单标签分类模型使用Softmax函数将神经网络最后一层的输出映射到和为1的0~1区间上,并使用CELoss(Cross Entropy Loss)作为损失函数。与单标签分类不同,多标签分类使用Sigmoid将神经网络最后一层每一个神经元的输出独立的映射到0~1区间,使用BCELoss(Binary Cross Entropy Loss)作为损失函数,单独计算一每个标签的二分类损失并求均值,BCELoss的计算公式如式(9)所示:
2 基于RoBERTa的多标签分类模型
由于作业许可数据中所涉及的与审核主题相关的要素较多,并且作业许可数据大多记录不规范,存在大量的噪声数据,所以浅层的神经网络模型较难取得理想的分类效果。为尽可能提高作业许可数据分类的准确率,本论文使用由Brightmart开源的Large版本的中文RoBERTa预训练模型[9,10],该模型在多个中文文本分类数据集上取得了state-of-the-art的成绩。RoBERTa的模型结构与BERT基本一致,与谷歌的原版BERT模型相比在如下几个方面做出了改进:
(1)改进训练数据的生成方式和预训练任务:使用全词遮盖来代替字符遮盖。首先将训练语料进行分词,然后随机选取10%的词进行遮盖操作,除进行全词遮盖之外还取消了句子预测任务。
(2)使用丰富的训练语料:训练语料涵盖了多个领域共计超过30G中文文本数据。
(3)训练更久:总共训练了近20万个Epoch,总计约近16亿个训练样本。
(4)增大预训练Bach Size:使用8k的Batch Size进行预训练。
在此基础上,本论文对该预训练语言模型做出了如下改进[11]:
在RoBERTa模型中,越靠近输入层就能够提取越底层的通用的语义和语法信息。基于此,在微调过程中冻结前3层的参数且后续的层不再使用固定的学习率,而是对于较低的层次使用较小的学习率,较高的层次使用较大的学习率,即使用线性衰减学习率。通过实验得出当初始学习率设为2e-5,衰减系数设为0.9时可以获得较好的效果。
如图4所示为基于RoBERTa的多标签作业许可文本分类模型,在该模型中RoBERTa可以看做输入文本的上下文特征提取器,该特征提取器可以用来获得整个输入句子的特征。

图4 多标签RoBERTa文本分类模型Fig.4 Multi-label RoBERTa text classification model
RoBERTa模型在使用时需要预先指定输入序列的最大长度,超过最大长度需要进行截断处理,不足则补0,若最大长度设置过大会导致显存溢出,无法进行训练。本论文通过计算得出作业许可数据的平均文本长度为231,结合实验中使用的GPU的显存大小,本论文设置输入序列的最大长度为256。
RoBERTa在输出句子每个字符对应的上下文相关词向量的同时还会输出一个特殊标记CLS对应的向量。CLS中包含有整个输入文本的文本特征,可以将CLS视为整个句子的特征向量。使用模型进行多标签预测时只要将CLS向量接入一个线性分类器(即一个全连接层与一个Sigmoid层的组合)获得模型在各个标签上的预测得分,将得分大于0.5的标签作为最终预测结果。
3 实验结果及分析
3.1 实验数据
实验选取中石油某企业2019—2021年10万条作业许可证数据集,每一条作业许可数据样本均为人工填报,已被标注为多个类别标签,是典型的多标签多分类任务。数据包括工作内容文本描述和每条文本对应的工作类型、危害识别、安全措施多个主题类别,数据具体形式如表1所示。

表1 作业许可证数据形式Tab.1 Data forms of operation permits
多标签分类就是要将作业许可证工作内容描述标记为临时用电、高处作业等7类工作类型的一种或多种;触电、坠落等15类危害因素的一种或多种;绝缘服、安全带等29类安全措施的一种或多种;共计51个标签。每类标签的样本数统计如表2、表3和表4所示。

表2 各类工作类型样本数统计Tab.2 Statistics of samples of various types of jobs
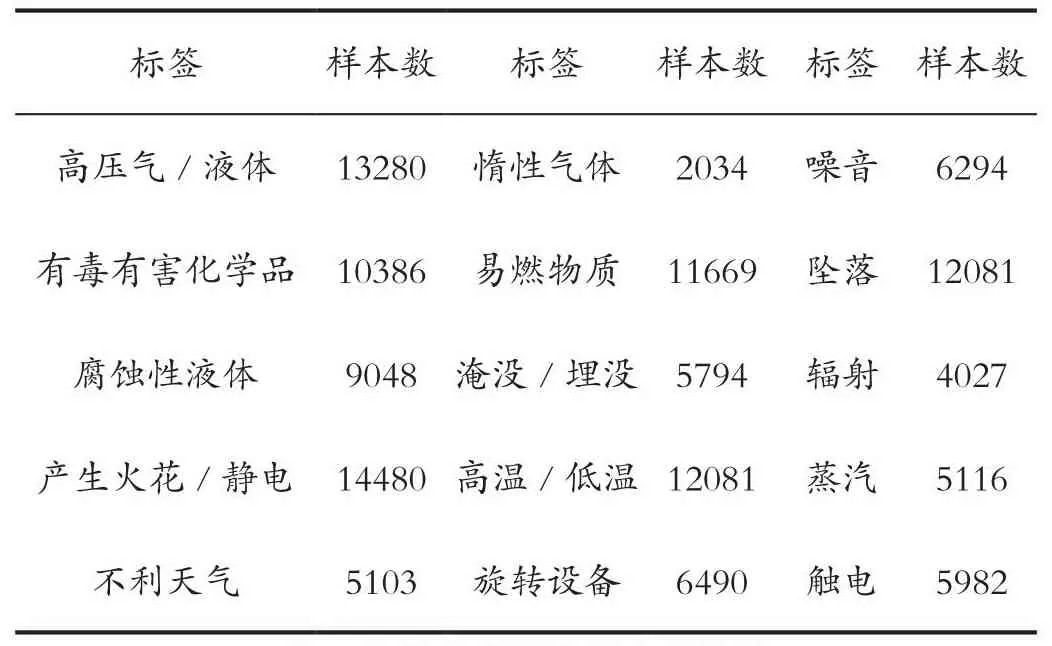
表3 各类危害因素样本数统计Tab.3 Sample number statistics of various hazard factors
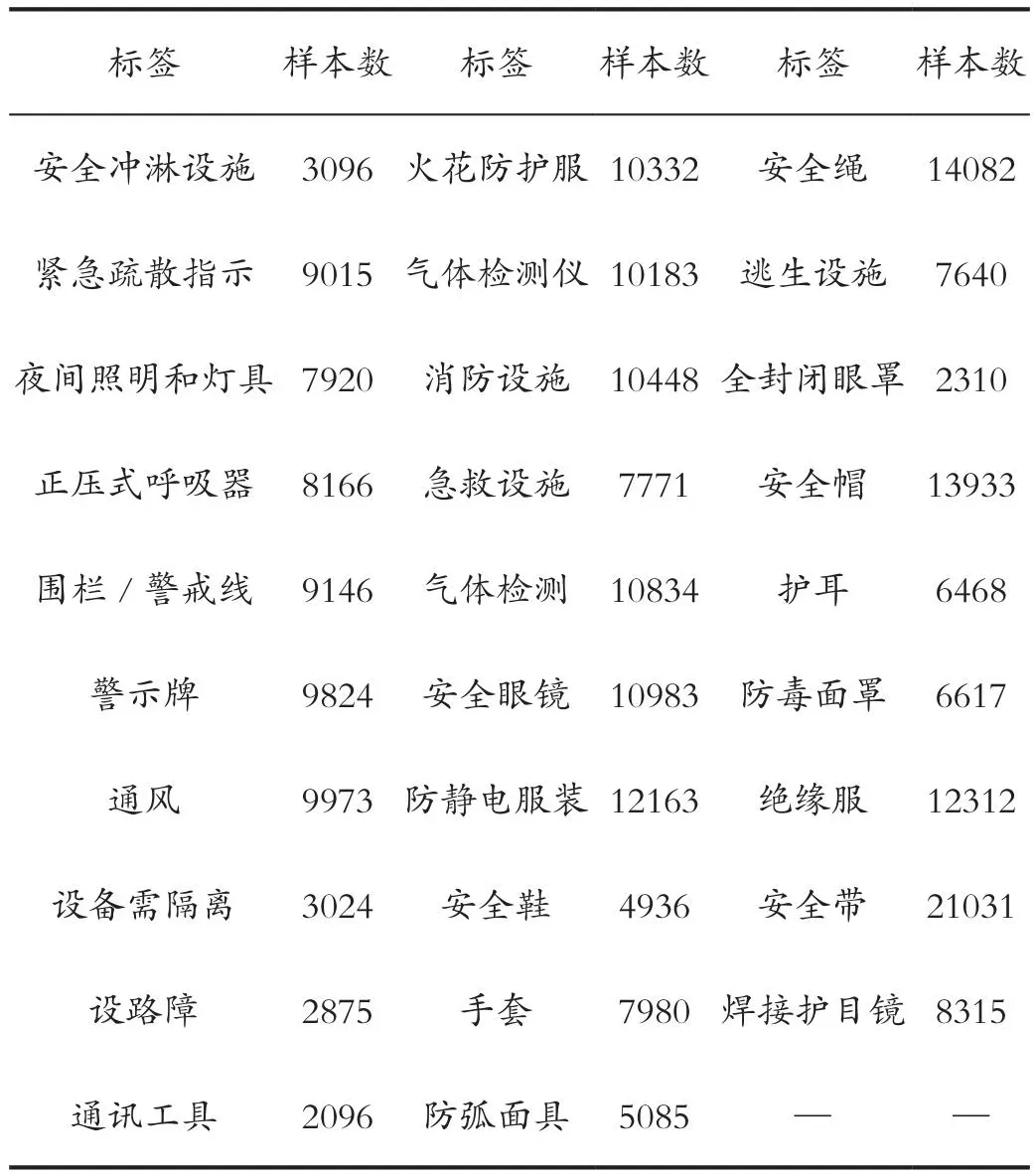
表4 各类安全措施样本数统计Tab.4 Statistics on samples of various security measures
3.2 模型参数
本文选取全连接神经网络、卷积神经网络、循环神经网络与本文提出的基于RoBERTa的多标签分类模型进行对比实验。在模型训练过程中,4种模型均使用AdamW算法作为优化算法更新模型权重。除此之外,在模型调优过程中使用贝叶斯优化算法与十折交叉验证选取最优的超参数组合,相比于网格搜索与随机搜索,基于高斯过程贝叶斯优化算法可以从概率上找到一个“很可能”更好的超参数。
3.3 评估指标
多标签分类可以看作多个单标签二分类问题,二分类问题最常使用的评价指标为F1值。因此,本论文使用平均F1值(macro F1)作为多标签文本分类的评价指标。原始的F1值只针对二分类问题,包括2个指标:精确率(precision)和召回率(recall)。如式(10)、式(11)、式(12)所示分别为精确率、召回率和F1值的数学表达式。
其中TP和FP分别代表真阳性和假阳性的预测结果数目,FN代表真阴性和假阴性的预测结果数目。宏平均F1值为各个类别的F1值的平均值,宏平均F1值的数学表达式如式(13)所示,其中N为类别总数。
3.4 实验结果分析
本论文在多标签作业许可文本分类任务上分别尝试了全连接神经网络(FCNN)、卷积神经网络(CNN)、循环神经网络(RNN)和预训练语言模型。如表5所示展示了不同的模型在测试集上的实验结果,其中各个模型的超参数均为经过贝叶斯优化与十折交叉验证所获得的超参数组合,在本小节中将这些通过该种方法得到的超参数组合称为最优超参数组合。
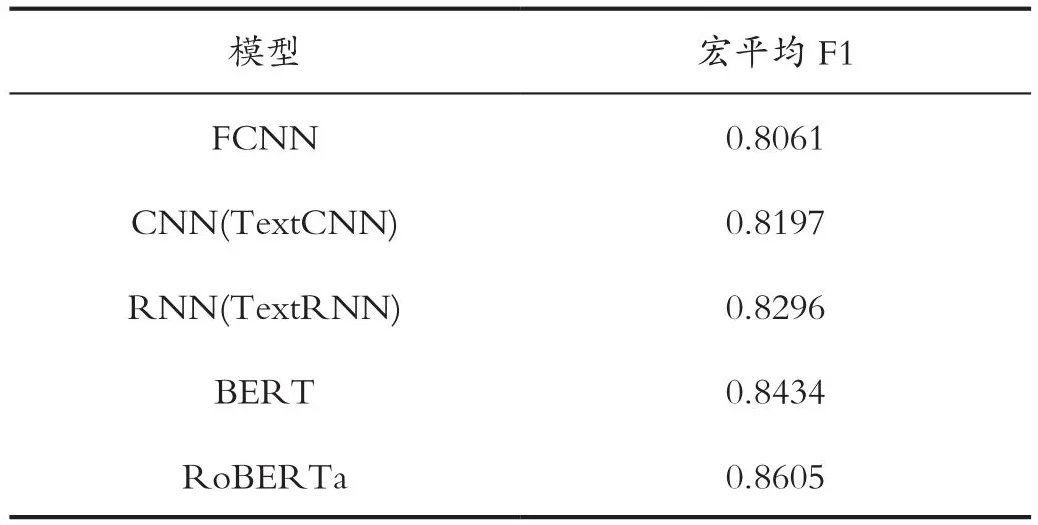
表5 多标签文本分类实验结果Tab.5 Multi-label text classification experiment results
其中RoBERTa为由Brightmart开源的中文RoBERTa模型,从实验结果可以明显看出,预训练语言模型都具有显著优势。其中一个重要的原因是RoBERTa预训练语言模型含有更多的参数。已有研究表明,模型的参数量越大,其拟合能力越强,也越容易发生过拟合。在训练样本较少的情况下,全连接神经网络、卷积神经网络与循环神经网络采用深层结构会造成较为严重的过拟合,故而只能采用浅层网络结构。本实验中使用的RoBERTa模型的参数量远大于其他3个模型,且RoBERTa在大量的公开语料上进行过预训练,在下游任务微调的过程中能够有效地防止过拟合。在体系审核数据文本分类任务中,由于训练样本获取成本较高、可使用的训练样本较少,使用RoBERTa预训练模型能够获得明显超过全连接神经网络、卷积神经网络和循环神经网络的分类效果。
在本次实验中,RoBERTa模型的分类效果最佳,平均F1值达到0.8605,超过了未经过专业培训人员人工分类的加权F1值(0.72),并且接近经过专业培训人员的分类的加权F1值(0.88)。
4 总结
本文主要针对多标签作业许可文本分类问题进行了研究,在给定许可工作内容描述时能够对该数据所属的类别进行预测。分别使用了全连接神经网络、卷积神经网络、循环神经网络、BERT与RoBERTa进行多标签文本分类,并且针对RoBERTa做出了进一步优化。与其他模型相比,优化后的RoBERTa模型的宏平均F1值最高。实验结果表明本文提出的方法是可行的,在节省人力和时间上做出了巨大贡献。目前自然语言处理还在发展阶段,作业安全问题却不容小觑,因此将深度学习技术和作业安全问题相结合是时代发展的需求,为进一步降低人力成本,减少作业现场事故的发生,我们还需要做出更进一步的研究。
引用
[1]刘冲,范伟,姜春丰,等.基于风险控制的作业许可管理系统开发与应用[J].云南化工,2018,45(2):226-229.
[2]胡月亭.正确使用作业许可有效防范高危作业事故发生[J].工业安全与环保,2014,40(1):96-98.
[3]尚鸿志,刘玉东.国内外作业许可制度建立与实施的初步探讨[J].中国安全生产科学技术,2012,8(S2):140-143.
[4]于菲菲,王廷春,蔡宝华,等.炼化企业作业许可体系探析[J].中国安全生产科学技术,2012,8(07):194-199.
[5]RAKHLIN A.Convolutional Neural Networks for Sentence Classification[J].GitHub,2016.
[6]LAI S,XU L,LIU K,et al.Recurrent convolutional Neural Networks for Text Classification[C].Proceedings of the AAAI Conference on Artificial Intelligence,2015.
[7]VASWANI A,SHAZEER N,PARMAR N,et al.Attention is all You Need[J].ArXiv preprint ArXiv:1706.03762,2017.
[8]DEVLIN J,CHANG M W,LEE K,et al.Bert:Pre-training of Deep Bidirectional Transformers for Language Understanding[J].ArXiv Preprint ArXiv:1810.04805,2018.
[9]CUI Y,CHE W,LIU T,et al.Pre-training with Whole Word Masking for Chinese Bert[J].ArXiv Preprint ArXiv:1906.08101,2019.
[10]LIU Y,OTT M,GOYAL N,et al.Roberta:A Robustly Optimized Bert Pretraining Approach[J].ArXiv Preprint ArXiv:1907.11692,2019.
[11]SUN C,QIU X,XU Y,et al.How to Fine-tune BERT for Text Classification?[C]//China National Conference on Chinese Computational Linguistics,2019:194-206.
