RF-BPNN模型在税收预测中的应用研究
2023-03-14周彦秋宁红梅邓皓云
陈 卓 周彦秋 宁红梅 邓皓云 凤 强
(1.广西科技大学 理学院,广西 柳州 545000;2.大庆市大同区统计局,黑龙江 大庆 163000)
一、引言
税收是国家调控经济最有效又最常用的手段之一,税收收入在保障财政收入、配置基础资源、调整产业结构等方面扮演着重要角色。税收收入预测是以经济的客观规律和相关政策为依据,分析历史税收收入数据和影响税收收入的因素,运用经济学知识和相关预测方法,估计未来特定时期的税收收入,并加以分析[1]。当前,税收收入预测方向的研究文献较少,且集中在使用单一历史数据对未来进行预测,忽视了影响税收收入的重要因素。因此,对影响税收收入的因素进行分析并预测税收收入具有重大意义。
本文结合已有文献研究,选取广东省作为研究对象,以广东省2012—2021年的年度税收收入数据为基准,对影响税收收入的因素进行分析,使用LASSO算法以及随机森林算法对收集到的6个指标进行筛选,通过组合方式将筛选算法分别与支持向量回归、BP神经网络进行结合,建立四种税收收入预测模型,在不同模型的预测效果中展开比对研究,以预测结果的误差为判断依据对模型进行评价。
本文的创新点在于,在研究方法方面,通过查阅相关文献,以往研究者使用的方法不外乎是ARIMA模型和GM(1,1)模型等传统时间序列预测模型。本文结合经典统计学和机器学习两个方面,以广东省年度税收收入为研究对象,分析影响税收收入的诸多因素,建立LASSO-SVR、LASSO-BPNN、RF-SVR和RF-BPNN四种多变量税收收入预测模型。
二、文献综述
税收收入数据具有时序性,加之受到国家经济和政策等因素影响,呈现非线性特点。传统的税收收入预测方法主要有多元回归预测、时间序列模型、指数平滑法、灰色理论法等[2-4]。孙杨(2019)[5]以重庆市民营经济为研究对象,分析影响税收收入的因素,对变量进行主成分筛选,按不同的税种构建主成分回归的指数平滑模型,采用三次指数平滑对不同税种的数值进行预测分析。随着计算机技术的大放异彩,税收收入预测研究方面出现了很多机器学习的分析预测方法,例如SVM[6]、BP神经网络[7]、LSTM[8]等。田永青和杨斌等(2002)[9]分析影响税收收入的各种因素,通过多次多元线性拟合,剔除对税收收入影响较小的指标。针对BP神经网络存在的局部最优、训练慢效率低等问题,构建基于RBF神经网络的税收收入预测模型,对山东省真实数据进行实证分析,证明了该模型的有效性。张吉刚和梁娜(2007)[10]在总结传统计量和代数方法的基础上,采用新型Elman神经网络,建立反映国内生产总值与税收之间非线性映射关系的税收收入预测模型,以某经济特区的实际数据进行仿真训练,结果表明Elman神经网络较传统计量方法的预测误差精度提高了4%。张淑娟和邓秀勤等(2017)[11]考虑影响税收收入的各种线性和非线性因素,使用更为稳定的LS-SVM模型对税收收入进行预测,并使用PSO算法对LS-SVM预测模型的参数C和γ进行超参数寻优,经过与网格搜索、遗传算法等方法优化的SVM相比,证明基于PSO算法的LS-SVM模型在税收预测上的精确性和稳定性更优。
三、相关理论
(一)影响因素
1.地区生产总值。地区生产总值是指地区内全部常住单位在一定时期的生产生活的最终成果[12]。收入法公式为:地区生产总值=L+S+G+Y,其中L是劳动报酬;S是生产税净额;G是固定资产折旧;Y是营业盈余。从公式可以看出,税收收入与地区生产总值之间是正相关,税收收入和地区生产总值相互影响。
2.规模以上工业增加值。规模以上工业增加值是从事工业活动的企业在一定时期内进行生产得到的总值,剔除了生产过程中的消耗与价值转移额,包含增值税部分。收入法公式为:工业增加值=L+S+G+Y,其中L是劳动报酬;S是生产税净额;G是固定资产折旧;Y是营业盈余。从公式可以看出,税收收入与规模以上工业增加值之间是正相关,税收收入和规模以上工业增加值相互影响。
3.金融机构(含外资)本外币存款余额。金融机构本外币存款余额是指截至特定时间点金融机构在人民币和外币商的持有额度。一般来说,存款余额越高,居民用于消费的部分就越少,增值税随之降低,存款余额与税收收入之间呈负相关。
4.地方一般公共预算收入。地方一般公共预算收入是指一个地区的财政收入上交完省级和中央财政之后,剩余的收入。公式为:地方一般公共预算收入=T+F,其中T为各类税收,包括增值税、消费税、进出口税、企业所得税和个人所得税等;F为非税收收入,包括专项收入、行政事业性收费收入等。该指标和税收性质较为相似,有密切的关系。
5.居民消费价格指数。居民消费价格指数是指一定时期内该地区居民在生活中消费和服务支出价格的变动趋势和程度的相对数。公式为:居民消费价格指数=(当前期价格/基期价格)*100%,该指标反映地区的消费水平,消费会产生增值税和消费税。居民消费价格指数上涨,增值税随之增加,两者之间为正相关。
6.财政支出。财政支出指对筹集而来的资金进行经济建设和其他事项的使用。财政支出源于财政收入,而税收收入作为财政收入的一部分,税收收入会影响到财政支出。反之,财政支出对税收收入也有反作用,倘若财政支出较大,出现财政赤字,会通过增加税收的形式进行财政收入与支出的平衡。
(二)LASSO 算法
LASSO算法是统计学中一种可以实现变量精简的估计算法。Robert Tibshirani[13]在1996年首次提出LASSO算法。该算法是改良的最小二乘法,通过最小化残差的平方和,从而产生系数为0的变量并将其剔除,实现降维。
假设存在数据(X,Y),其中X=(X1,X2,…Xi)是i个指标的值,对应的Y=(Y1,Y2,…,Yj)是j个响应变量,将X中的数据标准化处理。
式中,Bj为最小二乘估计;t为调整参数,通过控制调整参数t可以实现对总体回归系数的压缩,t值通过交叉验证法来估计。
上述表达式等价于:
式中,a是L1正则化参数,a越大,压缩力度越大。
(三)随机森林算法
随机森林(Random Forest,RF)[14]于2001年提出,一般用于数据分类或回归,其主要思想是从原始数据中采取自助法有放回的采样获得k个子集,对每个子集训练出不同的决策树,得到k个回归结果,最后对所有组合的结果取平均值。
鉴于随机森林采取有放回采样方式,因此存在部分数据无法参与训练而被浪费,这部分数据被称为袋外数据(Out of Bag,OOB)。随机森林对特征进行评估的步骤如下:
1.对每一颗决策树,选择相应的袋外数据,计算袋外数据误差,记为eOOB1。
2.随机对袋外数据中所有样本的特征xi加入噪声干扰,再次计算袋外数据误差,记为eOOB2。
3.假设森林中有N棵树,则特征xi的重要性=∑(eOOB2-eOOB1)/N。
综上,当特征xi加入随机噪声后,袋外数据的准确率大幅度下降,即eOOB2增大,说明特征xi对于最终的预测结果有很大影响,进而说明特征xi重要。通过计算每个特征的重要性并排序,得到一个新的特征集,对新的特征集重复上述过程,直到剩下目标特征个数,最后得到各个特征集并计算对应的袋外误差率,选择袋外误差率最低的特征集。
(四)支持向量回归
支持向量回归(Support Vector Regression,SVR)建立在SVM算法基础之上,其不依赖输入数据维度的性质,使其拥有较高的预测精度。通过核函数进行非线性变换,把数据xi映射到高维特征空间,继而在高维特征空间里进行线性回归,寻找能够准确表明xi与y存在关系的函数f(xi)[15],即SVR函数:
对于所有落入间隔带(2ε)内的数据,不计其误差,不敏感损失函数ε的表达式为:
式中,yi为原始数据xi映射到高维特征空间中的代表值。
根据结构风险最小化原则,并引入松弛变量ξi和得到如下公式:
式中,C为惩罚参数。
通过引入拉格朗日乘子a和a*,将上述问题转化为对偶问题:
式中,当ai-非零时,对应的训练样本为支持向量。求解此二次规划问题可求出a的值,同时求得w的值:
满足KKT条件计算出偏差b:
最后得到回归函数f(x)的表达式:
式中,K(xi,x)为满足Mercer条件的核函数,负责对输入数据进行非线性变换。
SVR核函数中使用最多的是带有宽度为σ的径向基核函数(RBF)。RBF函数为:
(五)BP 神经网络
BP神经网络一般由输入层、隐藏层和输出层构成。其中输入层输入xi,隐藏层输出zi,输出层输出y,层与层之间为全连接形式,层内的节点互不相连。
BP神经网络的训练实质是不断调整层与层之间的权值与阈值。首先从输入到输出进行正向传播,计算预测值与实际值的误差;然后进行反向传播,目的是调整权值与阈值,通过多次迭代实现降低误差。其数学形式为:
给定训练集D={(x1,y1),(x2,y2),…,(xi,yi)},其中xi∈Rn,表示具有n个指标的输入,yi∈Rm表示m维的输出。
设置BP神经网络的输入层、隐藏层和输出层分别有n、q、m个节点,隐藏层中第h个节点的阈值为yh,则有:
式中,αh是隐藏层第h个节点接收的输入;vih是输入层第i个节点与隐藏层第h个节点的连接权重;βj是隐藏层第j个节点接收的输入;bh是隐藏层中第h个节点的输出;whj是隐藏层第h个节点与输出层第j个节点的连接权重。
以激活函数Sigmoid为例,对(xk,yk),设为网络的实际输出,则有:
式中,θj表示输出层第j个神经元的阈值。
则(xk,yk)上的均方差Ek可以表示为:
BP神经网络在学习过程中,每一次迭代会更新参数,其任意参数v的更新式可以表示为:
设神经网络学习率为η(0<η<1),再由一系列的推导公式可得:
最后可得新的权值更新公式:
四、实证研究
(一)数据处理
通过查阅相关文献和资料,本文选取了税收收入预测中常用的6个自变量指标。所有指标的数据来源于《广东统计年鉴》,选取2012—2021年共10年的数据。表1展示了本文选取的对税收收入有影响的6个指标和年度税收收入数据的描述性统计。

表1 各指标描述表
表1中,x1为地区生产总值(亿元),x2为规模以上工业增加值(亿元),x3为金融机构(含外资)本外币存款余额(亿元),x4为地方一般公共预算收入(亿元),x5为居民消费价格指数,x6为财政支出(亿元),y为税收收入(亿元)。
通过观察表1中各指标的情况,各指标的单位和数量级并不完全一致,为了方便变量筛选和模型建立,规避数据量纲不一致带来的其他影响,将自变量数据归一化。公式为:
式中,xi'是归一化后的指标数据;xi是影响税收收入的指标;xi,min是指标的最小值;xi,max是指标的最大值。
由于因变量的数量级过大,本文对因变量数据进行对数处理。公式为:
式中,y→是对数化后的税收收入数据。
为了评价预测模型的拟合效果,需要选择合适的评价指标来衡量模型。本文的评估指标为MAPE、RMSE和R2,其公式如式(19)、式(20)和式(21)所示:
(二)特征筛选
1.LASSO特征筛选。利用R软件对各个变量因子进行LASSO降维,选出对因变量税收收入影响较大的一些因素,筛选结果如表2所示。

表2 各特征相关系数表
通过相关系数的大小排序,选取x2、x3、x4、x5、x6几个指标,由于x5和x6相关系数较小,故将其剔除,最后保留了x2规模以上工业增加值、x3金融机构(含外资)本外币存款余额和x4地方一般公共预算收入3个指标作为预测模型的解释变量。
2.随机森林特征筛选。利用Python的Scikit-learn库对影响税收收入的6个因素进行特征降维,依据重要性排序结果筛选出3个特征。经过多次训练,各特征重要性排序结果如图1所示。

图1 影响税收收入特征重要性排序
从图1可以看出,x6的重要程度与前4个变量存在较大差异,为了和LASSO算法进行对比,选择重要程度排序前3的x2规模以上工业增加值、x4地方一般公共预算收入和x1地区生产总值这3个指标作为预测模型的解释变量。
(三)SVR预测与评价
通过LASSO算法以及随机森林算法对变量进行筛选,分别将x2、x3、x4以及x1、x2、x4的数据作为SVR的输入分别进行训练。设置核函数为径向基核函数,其表达式如式(10)所示。设置惩罚系数C为1,当残差小于0.001时停止训练。采取五折交叉检验的方式,将数据集划分为5个规模一致的互斥子集,每次使用4个子集作为训练集,剩下的1个子集作为测试集,进行5次轮换训练,最后将5次训练的误差结果取均值作为整个训练过程的误差。
从图2可以看出,结合LASSO算法和随机森林算法的SVR模型在2014—2017年表现优异,重合率较高,但2012年、2013年、2020年、2021年与实际值差异较大。相对来说,RF-SVR的预测值较LASSO-SVR的预测值与实际值更贴近,说明其预测效果略优于LASSO-SVR。进一步通过评价指标来量化模型的预测精度,支持向量回归的评价指标如表3所示。

图2 支持向量回归拟合结果图

表3 支持向量回归评价指标
从表3可知,LASSO-SVR和RF-SVR的MAPE都比较小,说明两个模型在税收收入预测上表现都很好。LASSO-SVR在RMSE和MAPE上都优于RF-SVR,但是在拟合优度R2上都略逊于RF-SVR,综合说明RF-SVR的预测误差更小,精度更高。
(四)BP神经网络预测与评价
通过LASSO算法以及随机森林算法对变量进行筛选,分别将x2、x3和x4以及x1、x2和x4的数据作为BP神经网络的输入进行分别训练。设置输入层神经元为3个,输出层神经元为1个;根据隐藏层计算公式设置隐藏层神经元为8个,学习效率为0.1%,激活函数选择Sigmoid,对数据进行拟合。图3为选取不同特征筛选方法时,BP神经网络的拟合效果。

图3 BP神经网络拟合结果图
从图3可以看出,结合两种特征筛选算法的BP神经网络的拟合效果均较好,仅在2018年出现了较大的预测误差。其中RF-BPNN的预测值较LASSO-BPNN的预测值与实际值更贴近,说明其预测效果略优于LASSO-BPNN。进一步通过评价指标量化模型的预测精度,BP神经网络的评价指标见表4。

表4 BP神经网络评价指标
从表4可知,LASSO-BPNN和RF-BPNN的MAPE都非常小,说明两个模型在税收收入预测上表现都很好。RF-BPNN无论是在RMSE和MAPE上,还是在拟合优度R2上都略优于LASSO-BPNN,说明RF-BPNN在税收收入预测中的表现更好。
(五)结果对比
本文在税收收入预测方面选择了多种模型进行预测,为了实现对税收收入的精准预测,将不同模型的拟合效果进行对比,选择效果更好的模型对广东省未来三年的年税收收入进行预测。图4是不同预测模型的拟合效果。
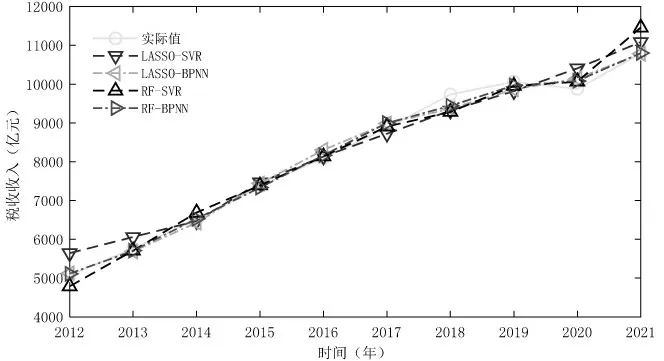
图4 不同模型拟合效果对比图
从图4可以看出,相对SVR来说,BP神经网络在首尾年份的预测上也表现出较高的精度。在所有拟合曲线中与税收收入实际值曲线贴合最紧密的是RF-BPNN,该曲线多次与实际值曲线相交,在2012—2017年时几乎处处重合,说明RF-BPNN组合模型的拟合效果优于其他组合模型。进一步通过评价指标度量模型的预测效果,结果见表5。
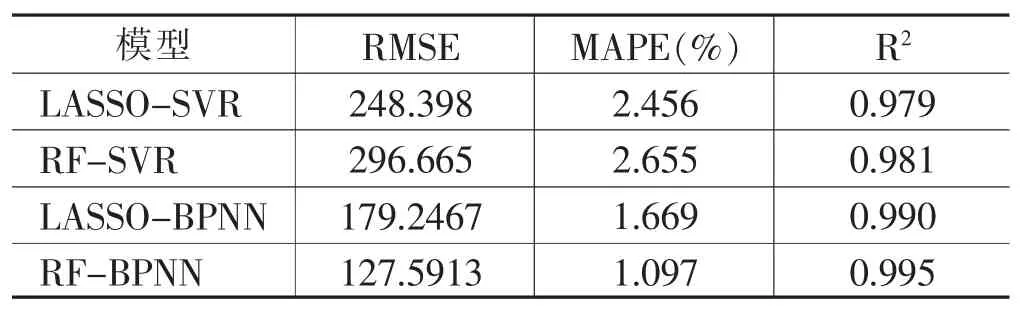
表5 不同模型的评价指标
从表5可以看出,RF-SVR模型的MAPE为2.655%,在所有模型中最大,说明其预测精度最低。RF-BPNN模型的MAPE为1.097%,在所有模型中最小,说明其预测精度最高。不同特征筛选算法的组合模型存在差异,但总体来说BP神经网络在税收收入预测方面的表现要优于SVR,且在本文中机器学习中的随机森林算法略优于传统的LASSO算法。
五、结论
税收与人们的生产生活息息相关,对税收收入进行预测和分析,有利于为相关部门提供调整税收政策的理论依据。本文从传统统计学方法和机器学习方法入手,采取特征筛选算法对预测模型进行优化,提出四种组合模型对广东省税收收入进行年度预测。结论如下:
1.本文提出的四种组合模型融入了影响税收收入的多种指标,结合线性和非线性特征来进行税收收入的趋势预测。通过LASSO算法和随机森林算法对指标进行筛选,简化模型结构的同时提高了训练速度和泛化能力。
2.不同特征筛选算法的组合模型存在差异,但总体来说BP神经网络在税收收入预测方面的表现优于SVR,且机器学习中的随机森林算法略优于传统的LASSO算法。
3.在税收收入预测的相关文献中,使用不同特征筛选算法进行组合,进而对税收收入进行预测的较少,本文具有一定的参考意义。◆
