基于组合神经网络的软件命名实体识别仿真
2023-03-11卢青华袁丽娜
卢青华,袁丽娜
(广州大学华软软件学院,广东 广州 510990)
1 引言
命名实体识别为自然语言技术中的一种[1],通过文本中的特殊意义将文字和词汇加以分类,并根据划分的区域准确识别人名、时间、地名等信息[2],为智能人工等高级NLP任务提供准确且有效的信息,目前的命名实体识别需要消耗大量的人力和物力,为改变这一现状,现对命名实体识别展开研究[3]。
严红[4]等人提出基于深度神经网络的软件命名实体识别方法,该方法通过卷积神经网络获取软件字符特征前需要抽取出软件的词嵌入、字符嵌入和语句特征向量,并在双向门控循环神经网络和条件随机场识别器的基础上根据词嵌入、字符特征和语句特征向量实现软件命名实体识别,该方法直接提取文本中的语句特征向量,没有将命名实体中的文字和词汇映射到低维度空间获取低维度空间向量,因此在识别命名实体过程中无法全面提取命名实体特征标签,导致其中存在大量冗余信息。冯艳红[5]等人提出基于BLSTM的软件命名实体识别方法,该方法利用文章词向量描述命名实体的上下文信息,采用词向量构成命名实体的前缀、后缀和领域信息,同时基于标注序列标签的相关性约束BLSTM代价函数将领域知识嵌入模型代价函数中以此增强模型的识别能力,最终实现软件命名实体识别,该方法在识别命名实体过程中没有在字特征向量的基础上加入词特征和词性特征向量再获取标注序列的标签,导致该方法的标签不完整,以此降低了识别性能,不能完全识别命名实体,导致F1值较低。李健龙[6]等人提出基于双向LSTM的软件命名实体识别方法,该方法利用无监督训练得出软件中语料的分布式向量,基于双向LSTM递归神经网络模型加入字词结合的输入向量和注意力机制对双向LSTM递归神经网络模型进行扩展和改进,从而实现软件命名实体识别,该方法在识别命名实体前没有采用组合神经网络预测命名实体标签再进行命名实体识别,无法完善命名实体识别结果,KS值较低。
为解决上述方法中存在的问题,提出基于组合神经网络的软件命名实体识别仿真。
2 基于组合神经网络的命名实体标签预测
在识别命名实体过程中可将识别问题转化成对文本中的各个字进行一次“SBEIO”的标签预测问题[7],目前标注字体的方法大多通过人工选取相对应的特征模板后进行标注,由此会消耗大量的人力和物力,为避免浪费,可通过组合神经网络模型对NLP任务进行标注,组合神经网络模型通过训练获取可代表文本词汇特征的低维度词向量[8],此方法即可以提高效率也可节省人力、物力和财力等资源消耗,且通过训练得到的词汇向量之间存在一种语义联系,此联系可直接提高命名实体的识别召回率,除此之外,组合神经网络模型还可轻松添加额外的命名实体特征信息[9]。
组合神经网络模型由输入层、组合神经网络层和输出层三大部分组成,其中输入层的主要功能为映射输入层中文字的词向量,且每个字的向量都为固定的低维度向量,同时将所有词向量保存到Lookup内,每当输入层出现新的词汇,输入层都会对新词汇进行映射,同时重新排列组合输入层内的所有向量,将排列组合后的向量当作下一层的输入向量再进行下一步操作。组合神经网络层由一个非线性层和两个线性层构成,此层的主要作用为连接上下层。输出层主要利用Viterbi算法总结出上层语句和词汇中的最优标签序列。
2.1 词向量特征
假设软件中存在一个字典DC和词典DW,并将字向量和词向量分别存储在字向量矩阵Mc∈Rdc×|DC|和词向量矩阵Mw∈Rdw×|DW|内,且|DC|和|DW|为字和词的向量大小,dc和dw为字和词的向量维度。
2.1.1 字特征
令软件中某句中文为c[1:n],此句由n个字向量ci构成,其中ci属于字典DC,且i大于等于1小于等于n。
提取c[1:n]中各个字的特征向量当作组合神经网络中的输入层,为简化输入特征,利用映射函数Ψc(·)∈Rdc表达其特征,映射后的特征表达式为
Ψc(ci)=Mc
(1)

将字向量简化后,结合上下文收集尽可能多的关于字ci的信息,通过滑动窗口在语句字数有差异时提取字ci的特征,可保证特征的完整性。令字窗口的面积为ωc,将文本中的每个字从左到右依次输入到滑动窗口,可获取其输入特征为

(2)
当存在字不属于词典的情况时,需将此字通过映射设置成固定的向量,并将每个维度空间中的向量进行归一化[10]。根据组合神经网络模型可知,在输入层得到归一化向量后,将字特征向量输入组合神经网络中,字向量会按照线性转换、非线性转换和线性转换的顺序提取出字特征,其中非线性转换向量可根据sigmoid函数进行计算,则非线性转换提取字特征的表达式为
g(x)=1/(e-x+1)
(3)
令Tc为命名实体识别的标签类别,由此可知|Tc|维向量为组合神经中的输出,即当组合神经网络中含有5个节点时,ci中含有每个标签概率的大小就为|Tc|输出向量,则ci中具有标签的概率表达式为

(4)

2.1.2 词特征
提取词特征与提取字特征的方法大致相同,首先设置词特征窗口为ωw,并通过映射函数Ψw(·)∈Rdw进行提取,映射函数方程式为
Ψw(wj)=Mw
(5)
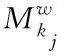
则根据上述方程可将词wj的输入特征设置成
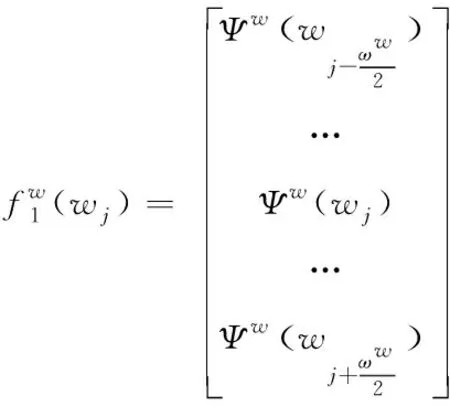
(6)
词向量与字向量的不同点为词向量可以随时加入新特征,以此方便特征提取,因为命名实体为根据外界语言环境进行命名,因此可轻易抽取词性属性,从而得出软件语句之间的结构关系,所以为优化命名实体识别的性能,需要在词特征内添加词性属性。
假设POS为词性标注集,令单位方阵为MP,且MP属于R|POS|×|POS|,则词wj的标记映射函数表达式为
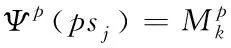
(7)
式中,psj表示词性wj被标记,k表示psj的相应词性序列,Ψp(psj)表示词性向量,且Ψp(psj)属于R|POS|。
假设软件中的某个语句为利用m个词w[1:m]构成,则此句话中词特征的表达式为

(8)
式中,ps[1:m]表示词性标注的序列。
上述中的词性向量为One-hot向量,因此可以首尾拼接词向量和其词性向量,使其成为词特征。
2.1.3 字词结合特征
由于只利用字向量进行命名实体识别无法全面理解其含义,又由于组合神经网络中的窗口对文字有字数要求,且无法将其扩展后识别,因此不能精确地识别命名实体。而词向量太过依靠外界环境,导致外界环境的好坏直接影响命名实体识别的准确性,并且词向量自身具有一个可将毫无相关的词汇通过映射形成特殊词向量的特性,因此在识别过程中,极有可能将特殊向量当作正常向量进行提取,导致识别结果中出现大量错误特征,所以结合两者的优点构成字词向量结合的形式进行命名实体识别,进而提高命名实体识别的性能。
假设字词向量结合的识别方法中含有一种字词映射关系ci⊆wj,且wj=ci-t…ci…ci+k(k≥0,t≥0)。获取字ci的相邻信息及上下文信息,设置字窗口的大小为ωc,词窗口的大小为ωw,则根据从左到右的顺序滑动窗口,得出字词结合的输入特征表达式为
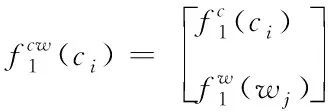
(9)
由于在字词结合中添加词性特征,因此在提取字特征的过程中可自动扩展字词,并以扩展后的词汇进行字和词的特征连接,将其输入到组合神经网络中,则特征表达式为
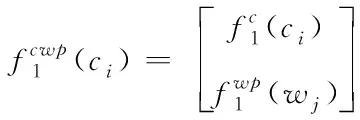
(10)
若T为字词标签集合,经过组合神经网络模型,输出的向量为|T|维,将其加入到字向量预测标注概率中,则其软件命名实体函数表达式为
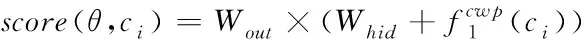
(11)
式中,Whid∈RH×(ωcdc+ωwdw)表示预测标签过程中的训练参数,Wout∈RH×|T|表示除预测标签外的训练参数,H表示隐藏节点数量。
3 基于支持向量机分类器的软件命名实体识别
目前的文本分类器中只有支持向量机适用于命名实体识别,此分类方法根据将风险降到最小的原则,将决策平面由超平面构成。支持向量机在命名实体识别中表现突出,它可以将字词向量利用相应的非线性映射函数映射到高维度特征空间中,在高维度特征空间中获取最优决策平面,实现命名实体样本准确识别,同时保证类别间隙较大方便查看类别[11]。
假设软件命名实体的训练集合为S,此训练集可利用超平面进行线性分割,则S的表达式为

(12)
利用最小二乘法支持向量机计算最优决策平面就为计算二次规划,则其表达式为
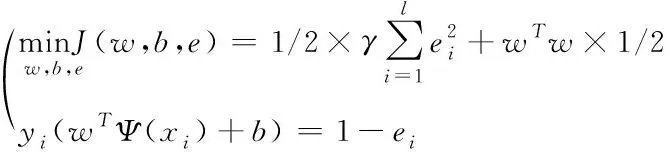
(13)
式中,γ表示训练过程中的惩罚参数。
并通过拉格朗日函数计算出一次规划,其表达式为
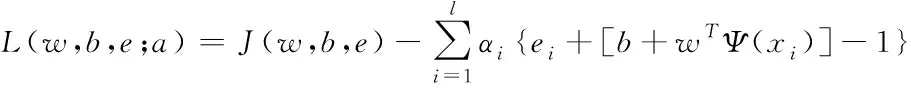
(14)
其中,αi表示拉格朗日函数中乘子的支持值,ei表示训练样本中的错误分类。
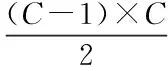
为进一步确定命名实体的类别[14-15],得出其识别决策函数表达式为
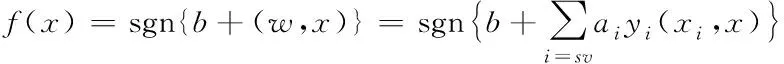
(15)
根据式(16)的结果可确定出命名实体的最终类别,根据以上步骤实现软件命名实体的识别。
4 实验与结果
为了验证所提方法的整体有效性,对基于组合神经网络的软件命名实体识别方法、文献[4]方法和文献[5]方法进行精度等级(P@N)、F1值和KS曲线进行测试。
4.1 精度等级(P@N)
利用精度等级P@N在训练集合中任意选取一定数量的样本进行命名实体识别,正确识别的样本个数与总个数的比值即为P@N,根据图1可知,在多次迭代中,选取10个命名实体进行识别,文献[4]方法的P@N最高值为0.6,且该方法在识别过程中结果不稳定,文献[5]方法虽稳定,但此方法的P@N仅为0.5,只有所提方法不仅稳定而且P@N达到0.9,因为所提方法在实现命名实体识别前将命名实体中的所有文字和词汇通过映射获取其低维空间向量,全面提取命名实体特征标签,因此可以更加省时省力的识别命名实体,同时排除冗余信息,进而提高精度等级。
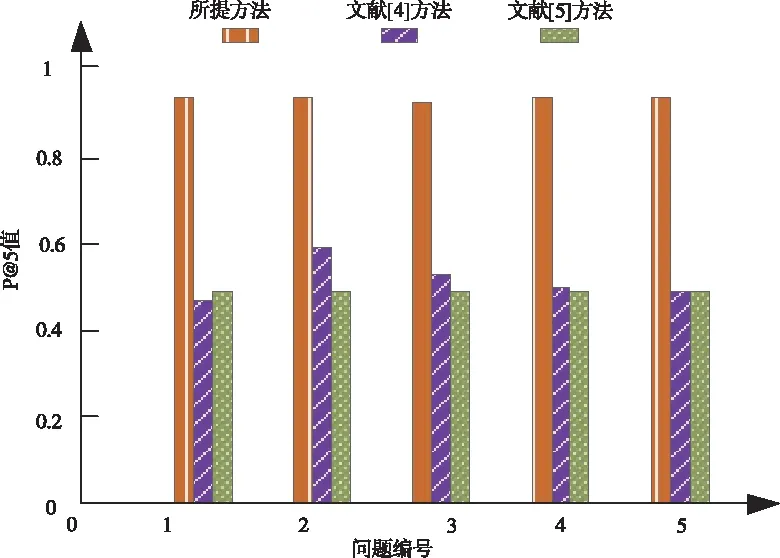
图1 不同方法的精度等级(P@N)
4.2 F1值
在不同向量维度空间下对比三种方法识别命名实体的F1值,经实验后发现特征向量的维度大小直接决定最终的识别结果,因此提高向量维度可以提高识别性能,进而提高F1值。
由于传统方法只利用字特征向量提高F1值,忽略了词特征和词性特征向量,因此F1值还有待升高。所提方法在字特征向量的基础上加入词特征和词性特征向量再进行命名实体识别,将识别性能发挥到极致,进而大大升高F1值。

图2 不同方法的F1值
4.3 KS曲线
KS值为真正类率(FPR)和假正类率(TPR)的比值,将KS值设为纵坐标,横坐标为识别阈值,即类别的概率分布,通常情况下KS值在[0,1]范围内越大越好。
实验结果显示,所提方法的KS值最大为0.5,接近最优KS值,由此可证明利用所提方法进行命名实体识别可区分出最精确的类别并实现命名实体识别。这是因为该方法在识别命名实体前采用组合神经网络方法预测命名实体标签后再进行命名实体识别,不仅方便后续识别,也可完善命名实体标签类别,进而提高了KS值。
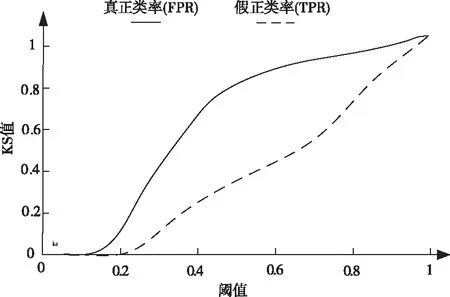
图3 KS曲线
5 结束语
为解决目前软件命名实体识别所存在的问题,提出基于组合神经网络的软件命名实体识别方法,该方法首先预测软件中的识别标签,并通过支持向量机进行标签识别,从而实现软件命名实体识别,解决精度等级(P@N)低、F1值低和KS曲线低的问题,为智能人工等高级NLP任务节约了大量资源成本。
