基于精英反向学习策略的麻雀搜索算法
2023-03-11冯增喜李诗妍赵锦彤陈海越
冯增喜,李诗妍,赵锦彤,陈海越
(西安建筑科技大学建筑设备科学与工程学院,陕西 西安 710055)
1 引言
麻雀搜索算法(Sparrow Optimization Algorithm,SSA)是受自然界中麻雀觅食行为和反捕食行为的启发,由学者XUN等[1]人于2020年提出的一种新的全局搜索算法。该算法具有搜索精度高、寻优能力强、稳定性好等优点[2],但是在求解优化问题易陷入局部最优,收敛精度低、求解复杂函数优化效率不高仍是需解决的难题。自SSA算法被提出以来,已被应用于数据处理[3]、路径规划[4]、负荷预测、智能电网、能源优化等多个领域。
为了提高SSA算法优化性能以更好地解决于实际问题,许多学者专家对此进行了研究。文献[5]通过改进ten混沌初始化种群和引入高斯变异的方法来提高算法种群多样性和全局优化能力,但是求解过程中依旧存在“早熟”现象。文献[6]基于鸟群算法中飞行行为的思想优化麻雀搜索算法,进行基于类间方差和Kapur熵的多阈值图像分割,使改进的麻雀搜索算法具有更优的搜索能力和开拓能力,且分割速度和分割精度均得到提升。文献[7]将柯西变异策略和反向学习策略引入至麻雀搜索算法中增强其跳出局部空间能力。文献[8]通过融合改进的熊闻味搜索(IBSS)和麻雀搜索算法(SSA),形成一种混合可再生能源(HRES)的优化潮流管理方法,基于该方法的控制改进了功率控制器在潮流变化下的控制参数。利用所提出的基于源侧和负载侧参数变化的技术,实现了智能电网系统的潮流管理。文献[9]提出自适应麻雀搜素算法,通过引入调整行列式与差分进化策略提高其稳定性与寻优精度。
为了更好地克服基本麻雀搜索算法诸如容易陷入局部最优、收敛精度低及复杂函数优化效率不高等问题,进一步提升麻雀搜索算法的探测和开发能力,本文引入精英反向学习机制,提出了一种基于精英反向学习的麻雀搜索算法,其通过对比麻雀搜索算法的当前解与反向解,选取较优秀个体进入下一次迭代,加快算法收敛速度。
2 基本麻雀搜索算法
SSA算法是一种模拟生物界麻雀觅食行为和反捕食行的新型群体智能优化算法。在该算法中,将麻雀分为发现者、加入者,并在这其中加入侦察预警的模型使部分麻雀充当警戒者。发现者自身的适应度高,搜索范围广,可为所有加入者提供觅食方向和区域。在觅食过程中,加入者总是能够搜索到提供最好食物的发现者,然后从最好的食物中获取食物或者在该发现者周围觅食。与此同时,一些加入者为了增加自己的捕食率可能会不断地监控发现者动态进而去争夺食物资源。当意识到危险时,群体边缘的麻雀会迅速向安全区域移动,以获得更好的位置,位于种群中间的麻雀则会随机走动,以靠近其它麻雀。
发现者位置更新如下

(1)
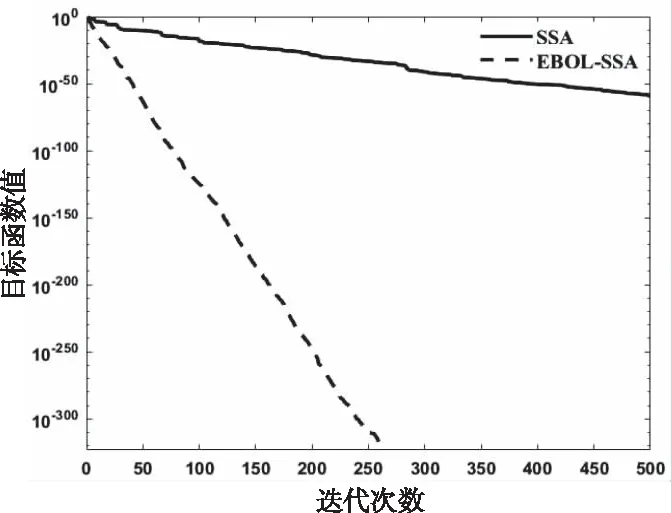
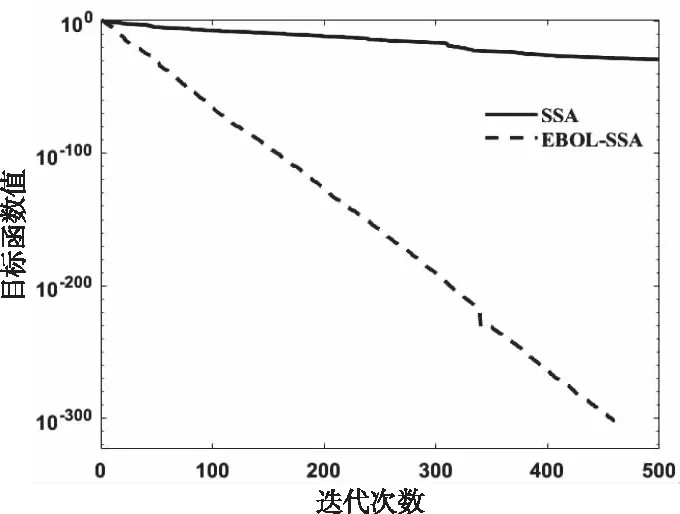
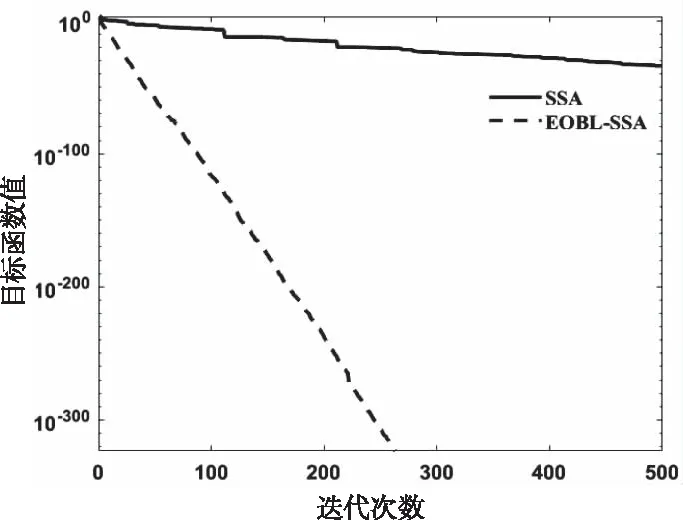
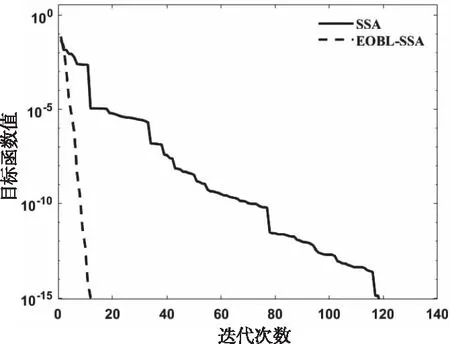
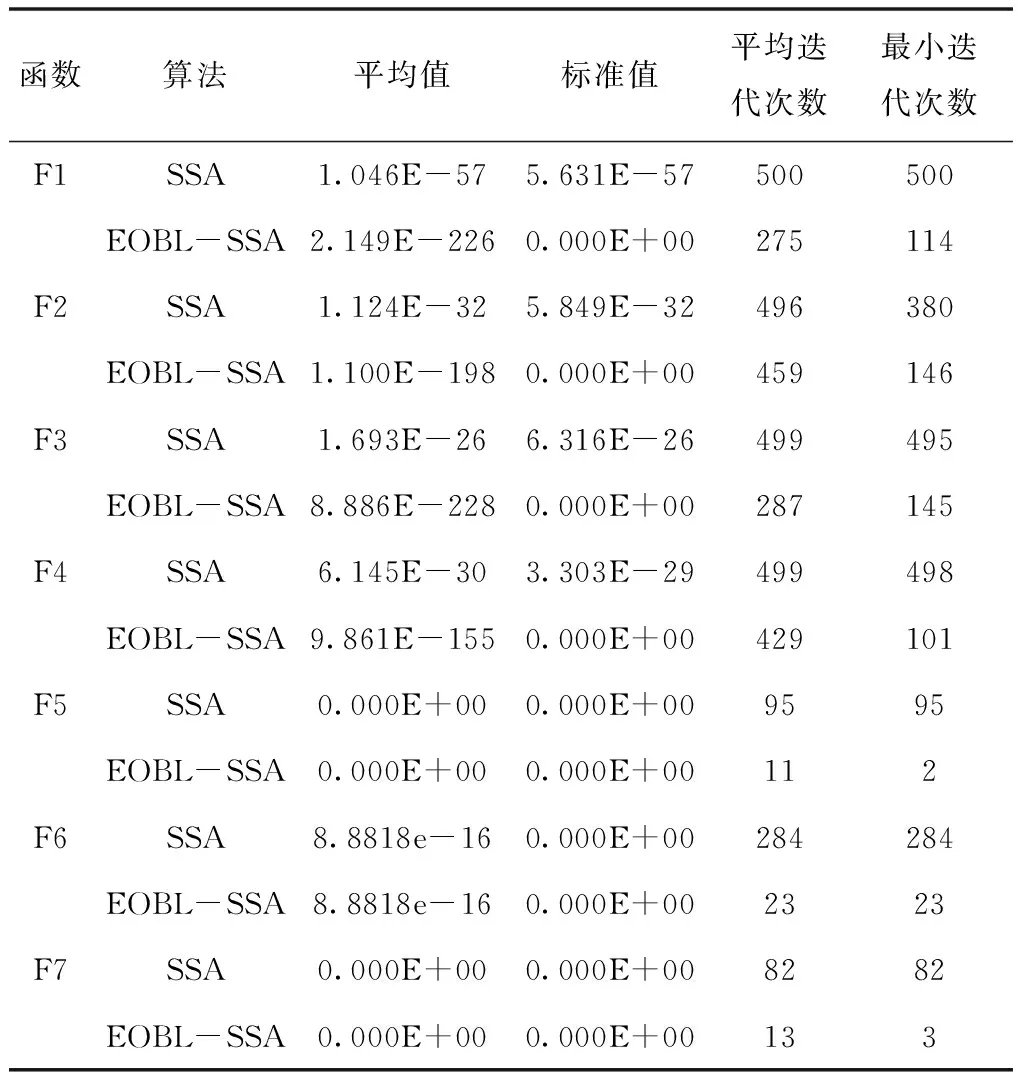
式中:t代表当前迭代数,itermax是表示最大的迭代次数,是一个常数。Xi,j表示第i个麻雀在第j维中的位置信息。α∈(0,1]是一个随数,R2∈(0,1]和ST∈(0.5,1]分别表示预警值和安全值。Q是服从正态分布的随机数。L表示一个 1×d的矩阵,其中该矩阵内每个元素全部为 1。当R2 加入者位置更新如下 (2) 式中:XP是目前发现者所占据的最优位置,Xworst则表示当前全局最差的位置。A表示一个1×d的矩阵,其中每个元素随机赋值为 1 或-1,并且A+=AT(AAT)-1。当i>N/2时,这表明,适应度值较低的第i个加入者没有获得食物,处于十分饥饿的状态,此时需要飞往其它地方觅食,以获得更多的能量。 侦察预警位置更新如下 (3) 式中:Xbest表示全局最佳的位置,β为步长调整系数,是一个均值为0、方差为 1 的正态分布随机数,k∈[-1,1]范围内的一个均匀随机数。fi是当前麻雀的适应度值。fg和fw依次为目前全局最优和最差适应度值。ε为最小常数,防止分母出现 0 的情况。当fi>fg时,表示麻雀处于种群的边缘地带,非常容易被天敌所袭击;fi=fg表明在种群中心的麻雀察觉到了被天敌袭击的危险,需要向其它麻雀靠拢。k表示麻雀运动的方位,为步长调整系数。 精英反向解定义:设xi(t)定义为第t次迭代的一个解,则反向解为xi(t)′,f(x)为目标函数。当f(xi(t))≥f(xi(t)′)时,则称xi(t)为第t次迭代精英个体,当f(xi(t))≤f(xi(t)′)时,则称xi(t)′为 第t次迭代精英个体,设xij为普通个体xi在第j维上的值,则其反向解为 xij(t)′=m(lij(t)+uij(t))-xij(t) (4) 式中:m是介于0到1的随机数,称为精英反向系数。lij(t)和uij(t)为xi(t)′在第j维上的最小值、最大值。[lij,uij]为精英群体所构造的区间; 基于精英反向学习的麻雀搜索算法较基本麻雀搜索算法,其改进主要是在麻雀更新后,取麻雀适应度排名10%作为精英解,同时获取精英麻雀的动态边界,利用反向学习策略求解反向解,对比更新前后麻雀,如果更优则替代之前的麻雀。融合了精英反向学习策略的改进麻雀搜索算法简易步骤如下: Step1:利用精英反向学习策略初始化种群,迭代次数,初始化发现者和加入者比列。 Step2:计算适应度值,并排序。 Step3:麻雀更新发现者位置。 Step4:麻雀更新加入者位置。 Step5:麻雀更新警戒者位置。 Step6:计算适应度值并更新麻雀位置。 Step7:获取精英麻雀,求取其边界动态变化,利用精英反向学习策略更新精英麻雀。 Step8:计算适应度值并更新麻雀位置。 Step9:是否满足停止条件,满足则退出,输出结果,否则,重复执行Step2-8。 为验证EOBL-SSA算法的性能,选用如表1所示的7个典型基准测试函数进行算法性能测试,并与基本算法SSA性能进行对比。测试函数中包括单峰、多峰函数,其维数和初始值的上下界和按照表1 中各基准函数具体选定。针对各基准测试函数的测试在同一运行环境下进行,仿真软件采用MATLAB2020a 版本,操作系统为Microsoft Windows 8.1。通用条件设置相同:种群数量为 30,迭代次数为 500,预警值ST=0.8,发现者的比例PD=0.2,剩下的种群是作为加入者,意识到有危险麻雀的比重SD=0.1。 表1 基准测试函数 为克服算法的偶然性误差,对每个测试函数,每个算法分别独立运行30 次,图1到7 为本文所提的改进算法(EOBL-SSA)与基本麻雀搜索算法(SSA)的进化曲线对比。算法性能分析如表2所示。 图1到图7表明,对于求解不同测试函数,EOBL-SSA算法比SSA算法表现出更好的收敛性。由图1、2、3可以看出,EOBL-SSA算法在单峰测试函数F1、F2、F3上的收敛速度明显优于SSA算法。对于函数F4,该算法相比SSA算法log值更低,表明寻优精度较高。由图5到7可以看出,F5、F6、F7均经过约10次迭代收敛到最优值,收敛速度优于SSA算法。通过对 F1到 F 7测试函数收敛曲线分析,所提出的EOBL-SSA相比SSA在求解复杂问题问题时具有较快的收敛速度和全局搜索能力。 图1 F1测试函数寻优对比曲线 图2 F2测试函数寻优对比曲线 图3 F3测试函数寻优对比曲线 图4 F7测试函数寻优对比曲线 表2 算法性能结果 表2中,平均结果、标准差、平均迭代次数、最小迭代次数反映了SSA 和EOBL-SSA 对测试函数 F1到F7所求解的质量,可得出改进的算法普遍优于原算法,特别是针对测试函数F1 、F2 、F3 、F4。标准差反映出算法的稳定性,对于函数F1 、F2 、F3 、F4,EOBL-SSA 均有较明显优势。而对于F5、F6、F7而言,30 次测试SSA算法均陷入一个局部极值,从而标准差极小,这并不能说明算法性能优越,而属于“早熟”现象。平均迭代次数与最小迭代次数可综合体现算法的寻优速度,对于函数F1至F7,EOBL-SSA平均迭代次数与最小迭代次数均小于SSA,表明EOBL-SSA在收敛速度上快于SSA。对于多峰函数F5至F7,SSA与EOBL-SSA 优化效果差别不大。但总体来说,从平均值和标准差两个指标来看,EOBL-SSA 的值更小,表明EOBL-SSA全局寻优能力比SSA 更强,稳定性更高,是一种更为高效的算法。以上分析表明基于精英反向学习的麻雀搜索算法在寻优精度和收敛速度方面均有所提高。究其原因,主要源于精英反向学习保持了种群多样性,同时充分利用精英麻雀的特征信息,加快了算法收敛速度与收敛精度。 本文针对基本麻雀搜索算法存在的收敛速度慢、易陷入局部极值的缺点,在基本SSA算法基础上,引入精英反向学习策略,构成基于精英反向学习的麻雀搜索算法,优化迭代种群,通过构建精英麻雀群体,充分利用麻雀的有效信息,增加种群多样性。并通过使用7个基本测试函数的仿真测试实验,验证了该算法在收敛精度、求解速度、跳出局部最优方面相较于原算法表现出了更为出色的性能,证实了该算法的有效性。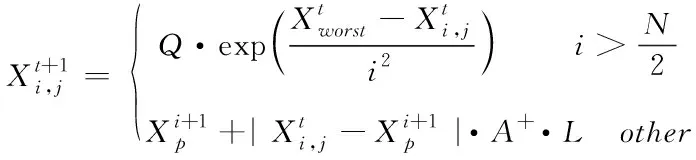

3 精英反向学习策略麻雀搜索算法
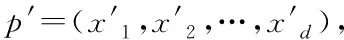
4 实验结果与分析
4.1 测试函数与实验参数的设置

4.2 EOBL-SSA 与 SSA 仿真结果比较
5 结论
