数字人文视角下的网络文物信息资源知识图谱构建
2023-03-10彭博
彭 博
0 引言
“文运同国运相牵,文脉同国脉相连。”[1]文化是民族生存和发展的重要力量,各类型文化遗产是人类文明的记忆载体。中华文明历史长河中传承下来的诸多文物作为文化遗产的典型代表,是华夏儿女建立文化自信的重要基础。随着“文博热”的到来,各类媒体上有关文物的报道迅速增长,互联网中与文物有关的话题与讨论增加,数字出版与数据库的推广使得文物有关研究成果能够以更快的速度与更新颖的形式进行公布,这些处于数字化新媒体环境下的文物信息资源以快速扩张的态势在受众间广泛传播。但历史文化知识存在理解门槛,大量的文物信息资源需要历史知识的积淀才能被充分解读。绝大多数受众通常不具备相应的知识储备,如何直观全面揭示信息资源中蕴含的文物知识,帮助受众理解中华文明的璀璨瑰宝,是推广历史文化遗产知识与弘扬中华传统文化需要面对的问题。
数字人文发展为人文社科类信息资源中的知识发现和利用提供了新视角与新方法[2],在鼓励研究人员使用数字化技术对信息资源进行分析的同时,强调保持人文研究中对于事物共同性总结及特殊性分析的能力,意图从内容角度对数字化技术的应用方向进行引导[3]。依据信息资源结构特征选择能够最大程度揭示其内容的数字化技术方法,提供人文社科类信息资源利用的新路径。
综上所述,网络中涌现的大量文物信息资源具有知识分布分散、质量不一、表示不明等问题,它们与受众中存在的知识储备不足、知识理解参差等共同形成文物信息资源推广过程中的巨大阻碍。本文以数字人文视角对网络文物信息资源进行分析,发现其共性特点与个性差异,再选择相适应的数字化方法进行文物知识的发现、融合与重构以及知识图谱构建。具体来说,根据信息资源内容和结构特征获取文物知识,利用本体和语义相似性对齐文物知识,使用知识图谱表示文物知识,弥合信息资源与受众间的知识鸿沟,促进文物知识在互联网时代的传播与推广。
1 相关研究
1.1 文物信息资源研究
随着互联网发展,数据呈爆炸式增长,以往将结构化数据视为文物信息资源的观点无法适应网络及新媒体环境下文物信息资源的定义。因此,应该将广义信息资源的概念应用其中,来源丰富、形式多样与文物有关的数据都可以被视为文物信息资源。结构化、标准化的文物数据可以作为文物信息资源开发利用的根基,但文本、图像、视频等非结构化信息中蕴含的知识更易被受众接受,也更适合作为文物知识推广的载体。
国内外文物信息资源研究的主要对象是结构化数据,发展历程分为4个阶段:从数字化角度进行研究[4]、从信息系统角度进行研究[5]、从元数据角度进行研究[6]和从本体角度进行研究[7]。综合看,文物信息资源研究随着数字化技术与人文研究变革而发展,经历了信息资源的数字化研究阶段、数据化研究阶段、关联化研究阶段、智慧化研究阶段,各阶段主要特征见表1。目前研究已不局限于将文物进行数字化与信息化处理,而是将文物在信息资源中进行实体化表示,利用关联数据等方法标记实体间关系,对信息资源中的文物知识进行关联与扩展,为文物知识的智慧化应用提供基础支撑,进行文物知识的深度开发利用。

表1 文物信息资源研究的4个发展阶段
1.2 数字人文作用于文物信息资源的研究
文物研究作为人文科学研究的重要组成部分,相较于文学、音乐等讲求伦理道德与人文主义的研究,更注重依据已有证据对事实进行复原,对人类历史材料进行筛选和组合后形成知识[8]。数字人文为从大量文物信息资源中挖掘知识提供了可能,也提供了依据文物有关知识进行文本分析、内容分析、时空数据分析、社会关系分析等新视角,为研究历史的演化发展提供了新的分析路径,可视化与虚拟现实等新展示形式的应用也为文物知识的推广与传播提供了新途径。
数字人文在文物信息资源研究中的另一个重要表现是“空间转向”(Spatial Turn)概念的提出[9]。空间转向是地理学与媒介及传播轨迹的融合研究,采用更广阔的视角和方法研究文明发展情况,实现了历史叙事的轴心从历时性谱系向共时性关系的转变,打破了文明间边界的局限,从关联、互动、体系等视角理解文明变迁,由此达到以横向空间维度的思考来补充和丰富纵向时间维度的内源性解释。从数字人文视角看,文物信息资源中时空数据的载体是一个数据库,而不是地图,将时空数据作为实体与文物进行关联,可以让历史学家形成新的研究问题,对文物特征的内源性进行解释。
国内数字人文的早期实践来源于古籍数字化。范佳[10]认为古籍数字化与数字人文有着紧密关联,从文本进行知识挖掘、地理信息系统的应用、可视化技术的应用和古籍语料库都是对古籍数字化的深度开发,形成了数字化统计计算技术与人文研究的良好融合。陈刚[11]认为以地理信息系统技术为支撑的“空间综合人文社会科学”是历史学与地理科学融合发展的新分支,以历史信息资源为来源,使用地理科学技术作为支撑,从数字人文视角对时间、空间、历史知识等进行挖掘与关联,以发现历史学研究新视角。数字人文在其中起到了提供数据融合框架与拓展研究视野的作用。王兆鹏等[12]指出,数字人文技术在文学、历史研究中可实现浏览检索、关联生成、数据统计、时空定位和可视化等功能,能解决研究中资料离散和时间、空间数据分离的问题,而将文史研究中的关键数据与知识进行融合与重构,可以还原历史知识全貌,为受众提供沉浸式的知识体验。
上述研究显示,数字人文理念高度契合人文科学研究发展的新需求与新态势;计算机分析技术应用于人文学科能够极大地扩展知识覆盖范围与表现形式。国内外数字人文实践表明,数字人文在文物、文化遗产等研究中已经取得了不少成果,但也要注重人文视角在技术有关工作中的保留,要从内涵解释数据的成因,利用数据验证结论的完备程度。目前数字人文在文物信息资源中的研究仍旧存在基础数据来源不足、数据处理难度较大、分析方法中的理论驱动力较弱、结果结论缺乏辩证性的考证等问题。
2 数字人文视角下的网络文物信息资源知识图谱构建
数字人文与单纯将数字化方法应用于人文类信息资源研究的最大不同在于“人文性”的保持,最典型的就是结果的叙事性,即分析结果不是数据的堆砌而是信息资源内容的组织与延展。在构建文物信息资源知识图谱时,该问题转变为是以知识数量还是以资源内容为出发点。数字化方法进行知识图谱构建注重获取到的知识数量,而数字人文更关注其与内容的相关性,强调知识图谱是对信息资源中知识的解构与重组。这也是数字人文视角下信息资源知识图谱构建的独有特征。从定性角度对信息资源中的知识基于叙事结构进行组织,挖掘其与内容的关联关系,能为知识图谱构建过程中数字化方法的选择提供帮助。选择针对性方法进行信息资源处理,从内源性出发提升问题解决效率的关键,也是数字人文分析视角的精髓。基于此,在数字人文视角下分析网络文物信息资源特征,能提升所抽取知识与信息资源内容的相关性、知识图谱构建效果和知识图谱展示信息资源中知识全貌的能力。
2.1 数字人文视角下的网络文物信息资源特征分析框架
数字人文视角下的重要分析方法是“远读”,由弗兰科·莫莱蒂(Franco Moretti)于2000年[13]提出。远读作为一种针对人文学科的新研究设想,通过整合资料,使用统计、总结等方式对大量文本进行概括性描述,揭示研究对象的发展变化规律,侧重对文本集合特征的描述与汇总,为后续分析提供建设性意见。数字人文视角下的远读分析则是在这一思想影响基础上,直接使用计算机技术读取信息资源内容,进行基于文本的统计分析,揭示内在特征。与远读相对应的是文本近读,主要通过人工视角分析文本,作为人文研究的重要环节,近读能够充分挖掘细节特征,而数字人文视角下的近读着重于细节特征的归纳,将人文研究的感性认知发展为可解构的量化分析。
文物信息资源知识图谱构建的主要目的是梳理和汇集包含在其中的知识,将隐性知识转化为显性知识;知识图谱的完备程度决定了这项工作效果。从这一角度看,数字人文视角下的信息资源特征分析是知识图谱构建重要前置工作,通过特征分析选择有针对性的数字化方法能够提升知识抽取的效率,构建与信息资源内容关系更为紧密的知识图谱。基于此,文章首先提出了数字人文视角下的网络文物信息资源特征分析框架,利用词频、主题分析方法对信息资源中知识的载体——关键词进行统计,完成宏观视角下知识的计量分析。随后,对局部介绍文物系统性知识的文学进行近读分析,分析从4个方面进行:语言特征、文本结构、内容特点和知识分布,前三部分对应文学分析中的词语、篇章、整体分析[14],第四部分探究知识在文本中的分布特征,对知识网络的分布状况进行量化分析,与其他元素建立数量、强度间的关联关系。最后将信息资源从5个方面与知识进行融合分析,总结提炼知识挖掘效率最高的关键词抽取方法,提出基于关键词的文物知识检索策略,改进文物信息资源知识抽取方法,优化知识图谱构建过程。数字人文视角下的网络文物信息资源特征分析框架如图1所示。
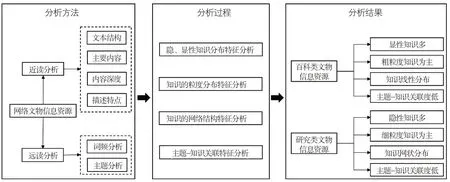
图1 数字人文视角下的网络文物信息资源特征分析框架
2.2 数字人文视角下的网络文物信息资源知识图谱构建模型
依据前文分析框架,根据创作目的与来源,网络文物信息资源分为两类:一是百度百科、网络中科普性质的文物介绍文本、博物馆展览注释、广播电视节目等受众面广、以普及文物基本知识为目的的百科类文物信息资源;二是科研论文、研究报告等面向专业研究人员,以发现新问题、提出新观点、论证新理论、挖掘新知识为目的的研究类文物信息资源。百科类文物信息资源中的知识特征如下:(1)显性知识多,如文物的作者、时间、位置等基本信息会直接说明,通常通过句法依存关系进行判断,能够发现“实体-知识-实体”的知识三元组。(2)以粗粒度知识为主,如文物的时间、位置、内容等多从整体角度进行描述,时间通常以时间段形式、位置通常以较大行政区划的模式进行描述。(3)知识网络呈现线性分布,百科类文物信息资源注重文物主要情况的描述,线性叙事,知识按一定模式进行排列。(4)主题与知识关联度不高,由于百科类文物信息资源讲求叙事性,故文本中形容文物状态的叙事性语句较多,主题中代表实体的名词比例不高。研究类文物信息资源的知识特征:(1)隐性知识较多,由于该类信息资源受众具有文物知识基础,故不会就文物常见信息进行描述。(2)以细粒度知识为主,针对文物时间、位置、形状等的描述通常表现为精确的考证结果,计量单位以现有考证的最小单位为主。(3)知识网络呈拓扑结构,层层递进,逐级深入。(4)主题与知识关联程度较高,文本主题中指代文物知识的名词性词语较多。总的来说,百科类文物信息资源中与文物知识有关的关键词会反复出现,较容易提取;而研究类文物信息资源中与文物知识有关的关键词出现频率与分布比较松散,需要先排除掉部分无关词汇后才能有效获取。
为此,文章提出一种从数字人文视角出发,分析信息资源特征后进行主题关键词抽取,将关键词转化为知识后构建知识图谱的方法。首先在网络中获取某一领域或主题下的文物信息资源,按内容聚类后利用统计方法进行二分类,由于百科类文物信息资源内容较为集中,故网络密度紧密的类团可判断为百科类文物信息资源集合,使用LDA[15]抽取其中的主题关键词作为检索词,同时采用TF-IDF[16]这种强调内容差异性的关键词抽取方法抽取网络密度松散类团,即研究类文物信息资源文本中的关键词,利用关键词从外部知识库中获取文物实体关系,进行命名实体识别。然后,利用文物信息资源本体与词汇相似度计算,将实体关系转换为概念层级的知识,完成文物知识的对齐。最后,分别利用实体关系与对齐后的知识构建网络文物信息资源多粒度视角下的知识图谱,对所构建知识图谱的效果进行评价,并开展多种应用,构建框架如图2所示。
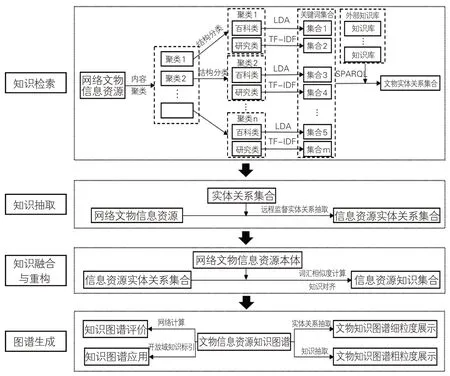
图2 网络文物信息资源知识图谱构建模型
3 “中国十大传世名画”网络信息资源知识图谱的构建与应用
实证研究选择“中国十大传世名画”信息资源作为研究对象,这是由于十大传世名画分布时间从五代十国到宋元明清,能管窥获取众多朝代的时代背景与人文风情。同时,绘画类文物信息资源在著录数据外还拥有大量的画面描述内容,在信息资源开发利用上有着广阔的视野和巨大的潜力。笔者在知网、知乎、百度百科等搜索,获取与“中国十大传世名画”有关的文物信息资源,检索时间截至2020年12月3日。共获取文物信息资源文本468篇,按句号进行分割后获得句子41,855句。
3.1 文物信息资源特征
以十大名画中的《千里江山图》为例进行文物信息资源特征分析,以验证前文中的观点。分析对象有3种:一是百度百科《千里江山图》[17]词条的全文;二是中央电视台文博探索节目《国家宝藏》[18]视频对《千里江山图》的介绍,经由视频转录成文字进行分析,按上文中的分类这两种资源属于百科类文物信息资源;三是知网数据库中论文《细究王希孟及其〈千里江山图〉》,属于研究类文物信息资源(见图3)。

图3 《千里江山图》网络文物信息资源截图
从知识角度看,以《千里江山图》流传过程为例,按照时间、收藏、位置3方面的先后顺序以及共现情况进行统计,见图4。红色代表3类都提到的知识,黄色代表《国家宝藏》节目和论文中共同提到的知识,绿色代表只在《国家宝藏》节目中出现的知识,蓝色代表只在论文中出现的知识。从图4中发现,百度百科中的知识最简略,但也能在时间视角中形成完整的文物流传链条;《国家宝藏》节目与论文中提到的知识基本相同,但论文中的有关描述更为细致与详尽。
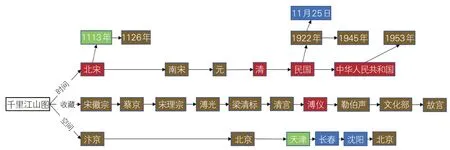
图4 《千里江山图》文本知识对比图
从内容角度看,参考内容分析法[19]对它们进行比较,百度百科文本内容较简略,文物介绍省略了大量细节,但内容较全面,篇幅较精简;《国家宝藏》是视频类节目,更注重舞台表现形式和吸引力,在文物整体信息表达上有的放矢;研究论文属于文物重要研究的介绍,篇幅长,不强调叙事性,多使用科学数据对问题进行描述,实体名词的出现种数也是最多的。
从词频角度看,对语料文本进行分词[20],白名单选用搜狗输入法的中国古代史词库共26,508词,分词工具选择Jieba[21]。分词后的词频分析结果如图5所示,(a)代表百度百科、(b)代表《国家宝藏》、(c)代表中国知网论文。百度百科与《国家宝藏》文本词频前20名中有7个词一致,与研究论文一致,说明文物信息资源在描述文物时具有一致的要点,代表文物广泛意义上的基础知识。从词语内容角度分析,百度百科中具有实际意义的名词有14个,占70%;《国家宝藏》文本中具有实际意义的名词11个,占55%;研究论文中具有实际意义的名词有17个,占85%,这说明科研论文在描述中使用的词汇更具有实际意义,趋向于使用名词对文物进行描述与概括,从一个侧面说明研究论文中包含的知识内容以及知识的承载效率较高。

图5 《千里江山图》词频可视化对比图
从主题角度看,选择应用最广泛的隐含狄利克雷分布模型(LDA)[22]进行主题挖掘,需要通过困惑度[23]计算得到当前文本应选择的主题数量,计算结果见图6。
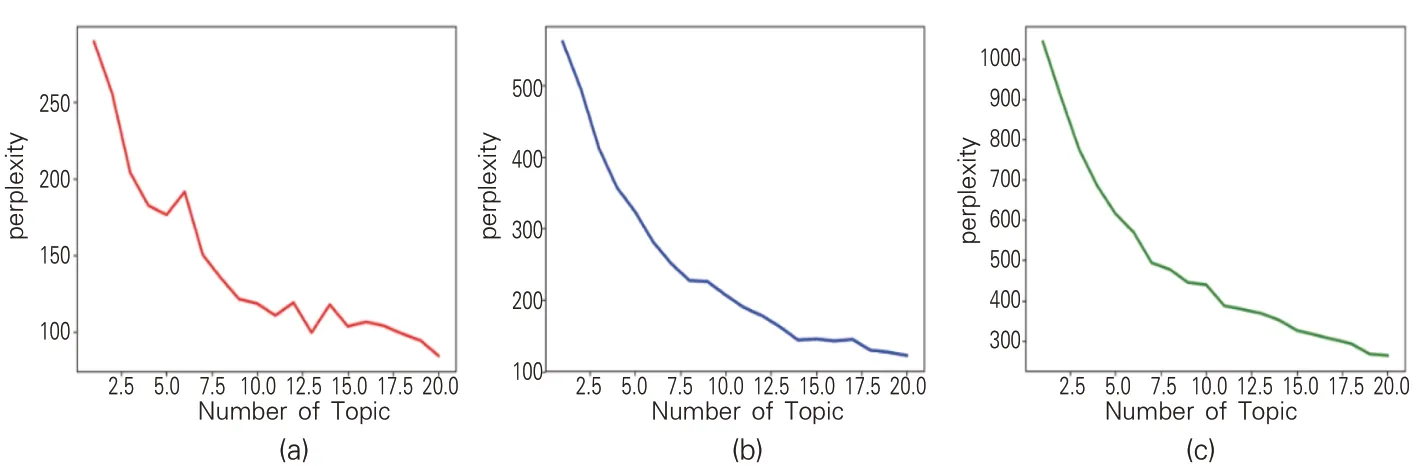
图6 《千里江山图》困惑度(1≤k≤20)变化情况
使用LDA主题模型对不同类型文物信息资源进行主题识别,模型参数取α=50/K,β=0.01,迭代次数50次,主题数选择为3,主题关键词数目选择为10[24],主题识别结果如表2所示。对比3类文本发现,相同主题下的主题关键词差异不大,《国家宝藏》是电视节目,需要突出舞台表现力,口语化词汇多,如“朕”“臣”;研究论文由于专业性质,会突出文物所在历史年代的特征,如“丰亨豫大”“太学”。
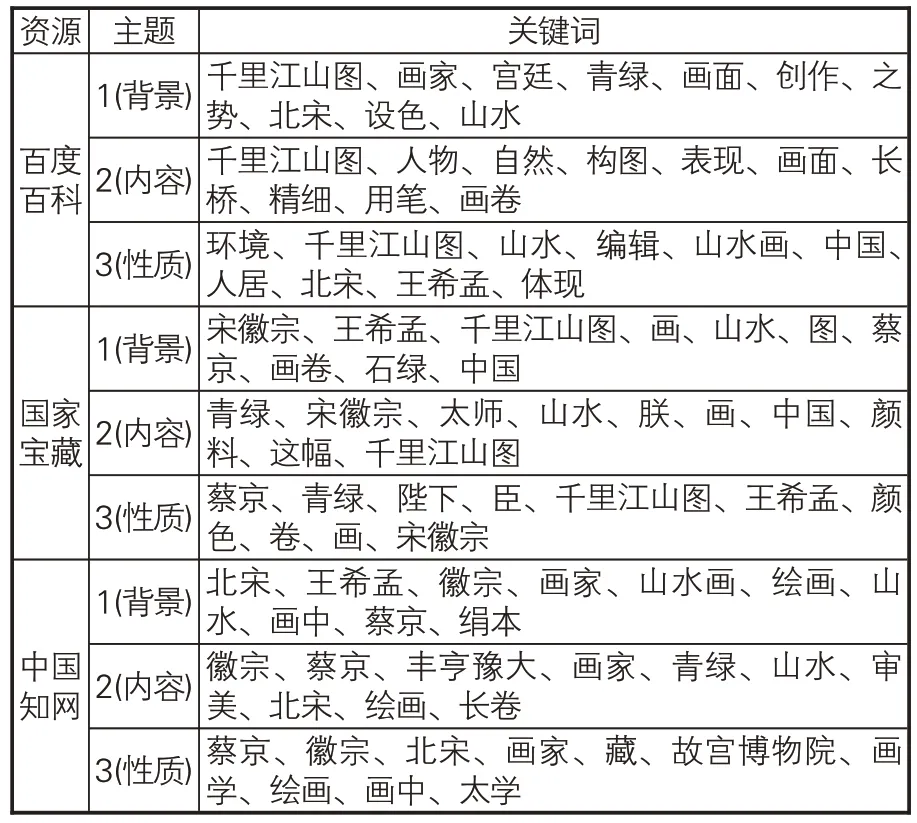
表2 《千里江山图》文物信息资源文本主题列表
综合来看,文物知识的分布会随着时间、空间变化以线性叙事形式进行,不同类型文物信息资源的区别在于知识的细粒度与扩展性。百科类文物信息资源中的浅层文物知识参照物,帮助识别文物的基础知识,也可以作为语料库,利用文档与词频间的差异,更好挖掘研究类文物信息资源中的深层知识,提高文物知识抽取效率。
3.2 文物知识检索
外部知识库发展为网络文物信息资源知识标注提供了新途径,使用大规模知识库为知识来源,以关键词为检索入口,能在获取文物著录数据的同时,获得文物描述内容中的历史知识,拓宽受众知识面,增加文物知识理解能力。首先,对信息资源聚类,利用Doc2vec获取信息资源内容,再使用K-means进行聚类,通过观察聚类结果确定聚类个数为7。随后,对7个聚类通过TF-IDF提取结构特征,使用K-means进行二分类,将聚类系数较大的类团视为百科类,利用LDA获取关键词。同理,系数小的类团使用TF-IDF获取关键词,使用关键词阈值K=50在知识库Wikidata[25]、CNDBpedia[26]进行遍历检索,获得与关键词Keywordm有关的实体集合E={Entity1,Entity2,…,Entityn},共获取代表实体的关键词12,471个。获取关键词集合后,通过SPARQL检索在知识库中进行实体集合E={Entity1,Entity2,…,Entityn}的遍历检索,遍历次数为,得到“实体-关系-实体”的实体关系三元组44,606条,构成文物实体关系三元组集合。
3.3 文物知识抽取
获取实体关系三元组集合之后,使用图模型将三元组中的实体及属性映射为节点和边,映射过 程表示为(S,P,O)→Gi=(Vn,Em)。其中,V={S,O}、E={(S→O)},边E的标签表示为P。根据远程监督方法,以句为单位进行实体关系抽取,在一句中若出现有与S和O相同的关键词则抽取成功,最终得到标记有实体关系的句子31,024条。
3.4 文物知识融合与重构
通过检索关键词获取实体关系后,参考多种文化遗产信息资源本体,使用七步法构建文物信息资源本体,见图7。随后利用知网与同义词词林进行实体关系表征词汇的融合相似度计算[27],从语义上归纳和合并外部知识库中数量繁多的实体关系,再以文物信息资源本体中的二级概念作为特征词,将相关实体关系与本体概念进行对应,完成外部知识库中实体关系的归类合并,解决知识库远程监督方法在实体关系标注的长尾效应。最后,将实体关系与时间、位置、管理、名称、类型、内容6个网络文物信息资源本体中的一级概念进行对齐,获得对齐后的知识三元组18,349条,构成文物知识三元组集合。
3.5 文物信息资源知识图谱的构建
利用获取到的实体关系构建“中国十大传世名画”信息资源知识图谱的细粒度表示,使用知识对齐后的三元组构建知识图谱的粗粒度表示,经去重与合并后得到实体关系三元组2,516条,知识对齐后得到知识三元组2,235条。所构建知识图谱如图8所示,(a)代表知识图谱的粗粒度表示,(b)代表知识图谱的细粒度表示。从图8中可以发现,粗粒度表示的知识图谱网络密度更高,中心节点聚集紧密,更有利于进行知识全貌的分析,而细粒度表示的知识图谱中心较为分散,适合针对信息资源中某一文物进行独立分析。
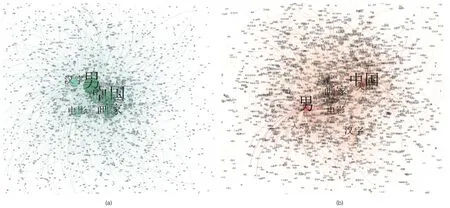
图8 “中国十大传世名画”网络文物信息资源知识图谱
3.6 文物信息资源知识图谱的应用与评价
构建“中国十大传世名画”信息资源知识图谱后,在开放领域进行知识图谱构建及应用研究。以故宫博物院网站《千里江山图》介绍页面为例,如图9所示,在获取网页文本后,通过关键词匹配“中国十大传世名画”信息资源知识图谱后自动进行实体关系抽取、文物知识抽取以及命名实体识别,共获取到实体及属性10个、关联知识11条,所识别实体在外部知识库中进行映射,通过与外部知识库的实体链接为接下来的文物知识开发与利用,以及较全面解读网页中的文物实体与文物知识结构提供了数据基础。

图9 “中国十大传世名画”知识图谱应用示例
为对数字人文视角下构建的“中国十大传世名画”信息资源知识图谱进行评价,从多个关键词阈值角度以知识三元组数量和知识网络密度与单一方法构建的知识图谱进行比较。从表3发现,在不同关键词阈值下,文章所构知识图谱的知识三元组数量稳定增加,说明本文构建方法能够及时扩充知识图谱规模,具有扩展性。网络视角下的另外3种分析指标随着阈值增加而稳定增加,知识图谱中的知识网络稳定扩展、密度增大,说明采用文章方法构建的知识图谱在保证数量的同时知识关联度较紧密。与其他方法相比,文章方法是唯一随着知识图谱规模扩大,在3种网络计量指标中均保持稳定增长的方法,说明所构建知识图谱在数量和质量上的表现均较好。单一关键词抽取方法中基于主题的关键词抽取方法如LDA、LSI等获得的知识三元组数量较少,但构建的知识图谱从网络角度看较密集。而基于统计的关键词抽取方法TF-IDF获得知识三元组数量较多但网络比较松散,说明与主要内容有关的知识较少。同时,语料库的不同对方法有显著影响,混合不同类型信息资源语料后构建的知识图谱,知识三元组数量下降但网络密度升高。文章方法融合两类关键词抽取方法在不同类型文物信息资源知识抽取中的优势,既保证抽取知识的数量,又使所抽取知识与信息资源主题紧密相关,是能揭示信息资源中文物知识全貌的知识图谱构建方法。
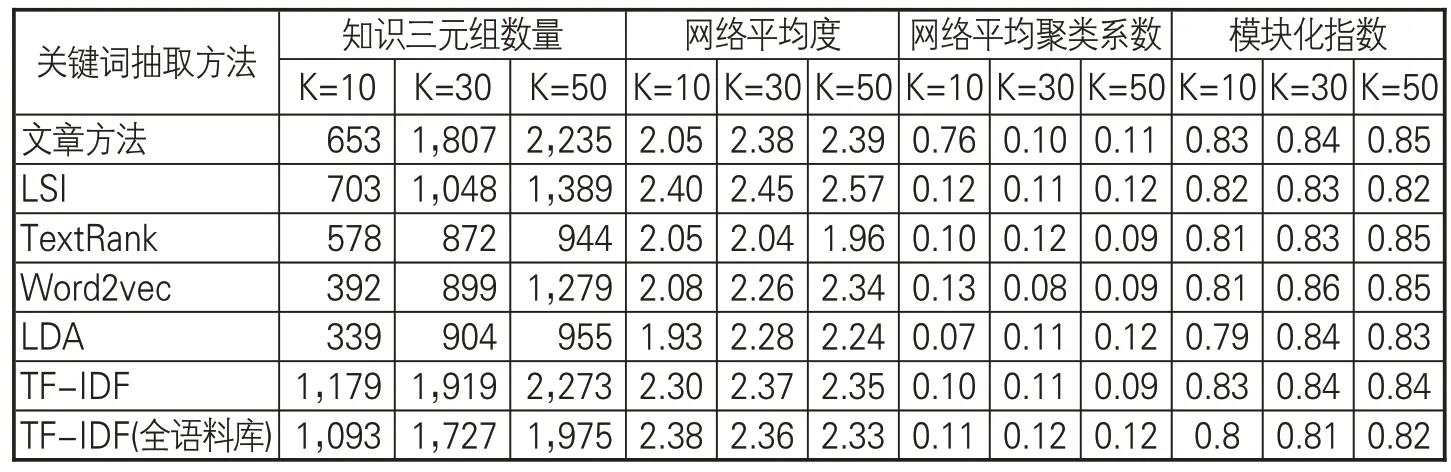
表3 不同方法构建知识图谱对比表
4 结语
数字人文为人文社科类信息资源分析提供了新视角。通过解读信息资源的内容与结构特征,选择有针对性的数字化方法进行知识层面的计算与挖掘,更新与改进数字方法在人文社科类信息资源中的应用,是数字人文赋予人文社科研究的新视角。笔者以网络文物信息资源中文物知识分布特征为切入点,通过近读分析其中可能存在的普遍特点,而后借助统计方法进行验证,并在融合维度下确定符合信息资源特征的知识抽取方法,利用关键词与外部知识库构建知识图谱。在面向开放领域的知识图谱构建实验中,文章方法能够融合单一方法的优势,在提升知识抽取数量的同时保持与信息资源主要内容的相关性,并在应用示例中取得了较好的效果。在下一步研究中,将进一步扩充数据规模并完善相关本体,扩展知识图谱自动构建方法的应用范围,探索数字人文在网络文物信息资源知识有关研究中的深入应用。
