信息通信网络运行事故分析与对策
2023-03-09马凝芳高级工程师皓高级工程师张玉涛鲁陈立
马凝芳高级工程师 蒋 皓高级工程师 张玉涛 鲁陈立
(中国信息通信研究院,北京 100191)
0 引言
欧盟网络安全局发布《2021年电信安全事件》年度报告,显示2021年来自26个欧盟成员国和2个欧洲自由贸易联盟(European Free Trade Association,EFTA)国家的168起电信事故总损失为51.06亿用户小时数,相较2020年的8.41亿用户小时大幅增加[1]。2022年7月日本KDDI株式会社(KDDI Corporation,KDDI)、加拿大罗杰斯通信公司(Rogers Communications Inc.,Rogers)、美国谷歌公司(Google Inc.,Google)3家公司相继出现波及全国、历时数日的特大型信息通信网络运行事故,引起了全世界的高度关注[2]。其带来的灾难性后果充分表明人类社会对信息通信网络的依赖程度非常高。
罗丹、张治兵[3]分析国内外通信网络运行风险管理现状,并从加强顶层管理体系建设、提升监督管理要求、提升风险防范能力等方面提出风险管理的改进建议;赵松柏[4]从我国网络运行维护管理制度的演变过程出发,分析网络运行维护管理现状、管理重点与目标、影响网络稳定的因素、运维管理工作存在的不足等问题,提出优化资源、落实集约化管理,落实网络线路的优化、调整工作,研发新型保障技术,发挥政府协同管理的作用等建议;在具体技术方面,农毅杰[5]提出一种以Web为基础的网络化运营与维护信息管理体系,逐级进行深层次的故障定位,查找根源并进行处理;美国国家标准与技术研究院(National Institute of Standards and Technology,NIST)开发了一种风险管理框架,提供灵活、动态的方法用于管理高度多样化的信息系统安全风险,为信息通信网络运行安全风险管理提供参考[6]。目前国内外针对网络运行安全事故发生规律、事故原因、事故后果开展的研究较少,同时也缺少涵盖网络运维、监管、系统设计等的事故预防体系。本文从国内外网络运行安全事故出发,分析事故原因、总结事故规律,在此基础上提出预防措施和建议,提高网络运行安全水平。
1 事故分析
为了全面掌握网络运行事故的基本特征,总结事故发生的规律,对国内外2020年11月-2022年9月发生的29起网络运行事故信息进行统计分析。
1.1 总体情况
由于我国目前无公开的官方网络运行安全事故统计数据,本文的数据来源于媒体报道。为揭示事故规律,提出针对性的预防措施,统计的信息主要包括:事故发生的时间、事故过程、事故原因、事故影响持续时间等。国内外网络运行事故,见表1、2。
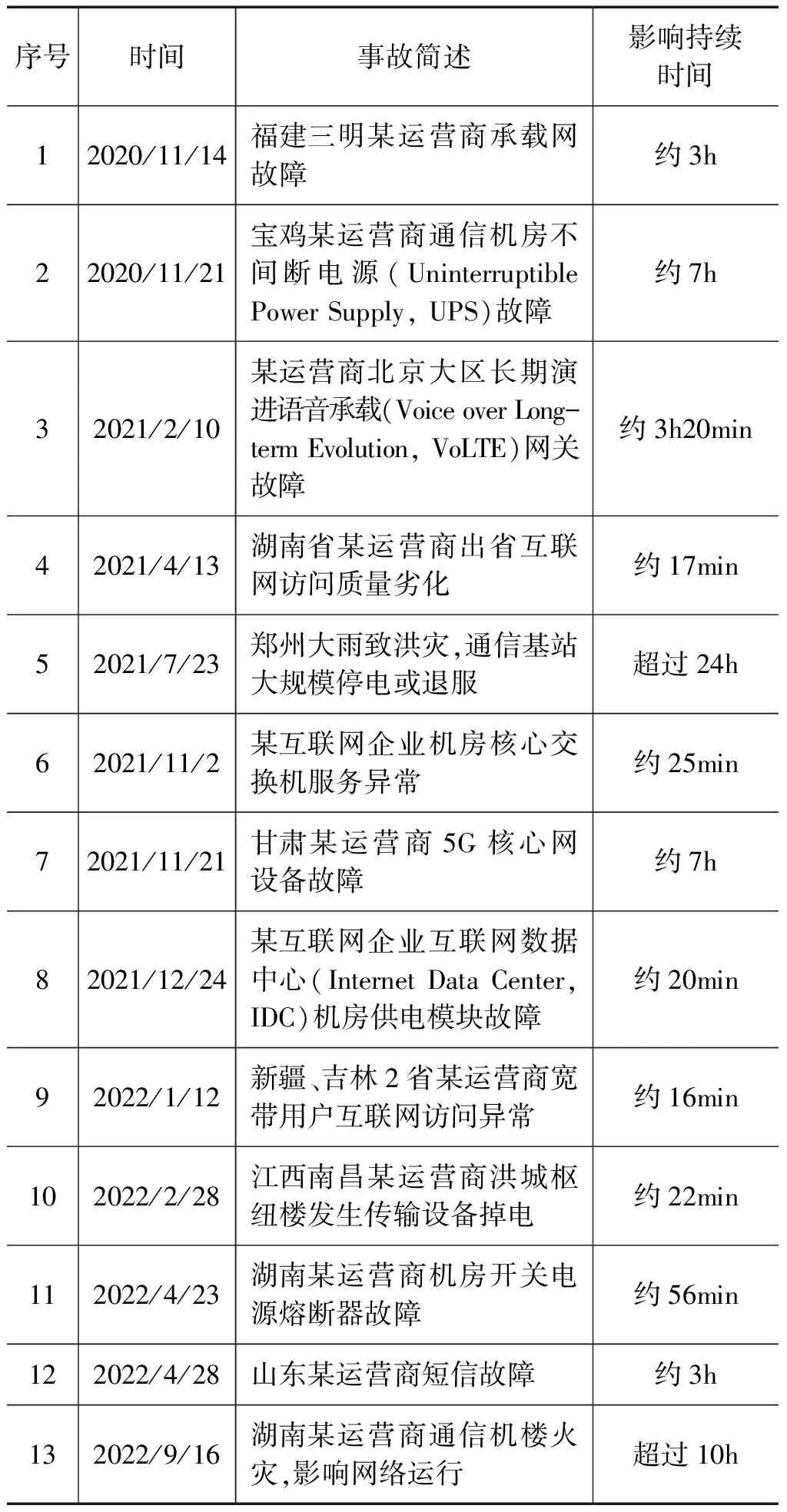
表1 国内网络运行事故
从持续时间方面分析显示,影响24h及以上的事故数量占事故总数的14%,3~24h的占比38%,1~3h的占比14%,20min~1h的占比27%,小于20min的占比7%,如图1。

图1 事故影响时间分布情况
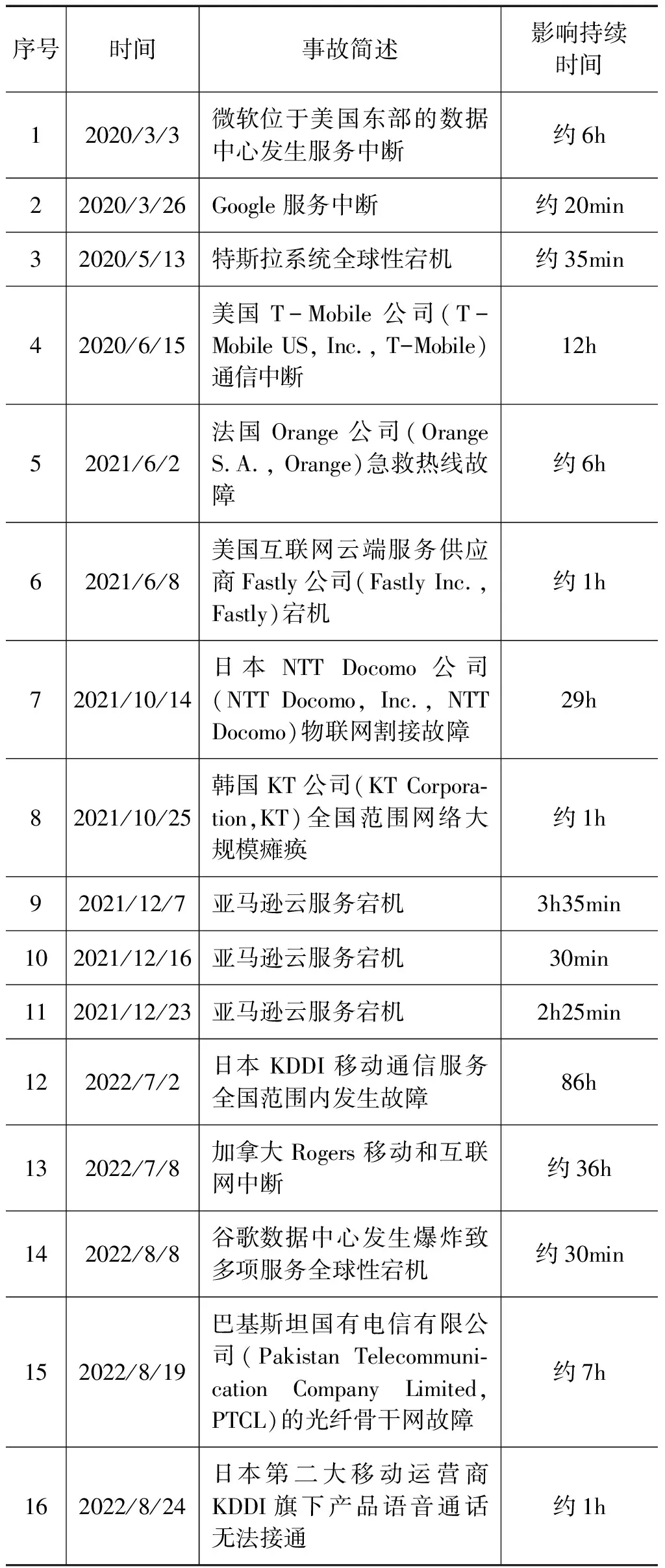
表2 国外网络运行事故
近3年,每年事故平均影响时长(事故影响总时长/事故起数)呈增长趋势。其中2022年事故平均影响时长较2021年增长了149.8%,如图2。特别需要关注的是超过3h的事故已经超过50%。
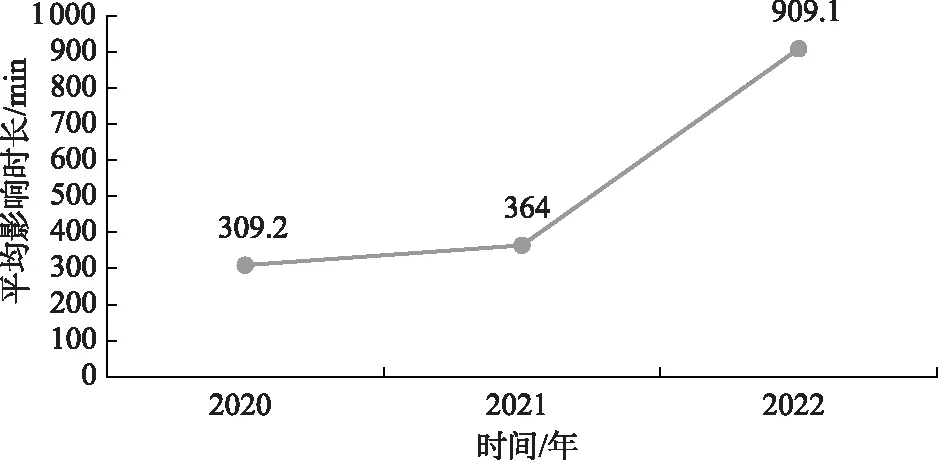
图2 近3年事故平均影响时长变化趋势
图2显示,网络运行事故持续时长增加趋势明显,主要原因在于随着网络云化的不断发展,网络运行事故原因定位和溯源难度加大,网络运维管理复杂度提高。网络脆弱性增加的趋势与后疫情时代生产、生活和学习在线上开展不断增加的实际情况产生矛盾,如果放任矛盾发展必然给社会经济发展带来不可估量的损失。
以2022年7月日本KDDI网络运行事故为例,事故由核心路由器割接过程中突发通信中断事故导致全日本范围内手机用户无法正常拨打电话、收发短信。约3 915万用户受影响,相当于日本人口的1/3左右;事故还波及了固网用户、大批政企互联网/物联网业务和基础设施;还致日本204处气象观测系统无法传送资讯;部分银行的自动取款机、公交系统乘车卡、丰田等车企的部分车联网服务无法使用;铁路货运的物流信息系统也受到影响,引发物流迟滞,邮件和包裹投递延误。事故持续超过3天,严重影响了日本国内正常的社会生活秩序。
1.2 事故原因分析
造成信息通信网络运行安全事故的原因可以分为3大类,即环境因素、系统(网络)因素和人为因素,其中环境因素包含极端天气、外部施工挖断光缆、火灾等;系统(网络)因素包含网络架构冗余失效、网络设备硬件故障、网络设备软件故障、动环设备故障、线路设施故障等;人为因素包含割接升级操作不当、配置错误等。
通过对29起网络运行事故进行分析,发现系统(网络)因素是导致网络运行事故的主要原因,占比为61%,而人为因素占比为32%,环境因素占比为7%,如图3。
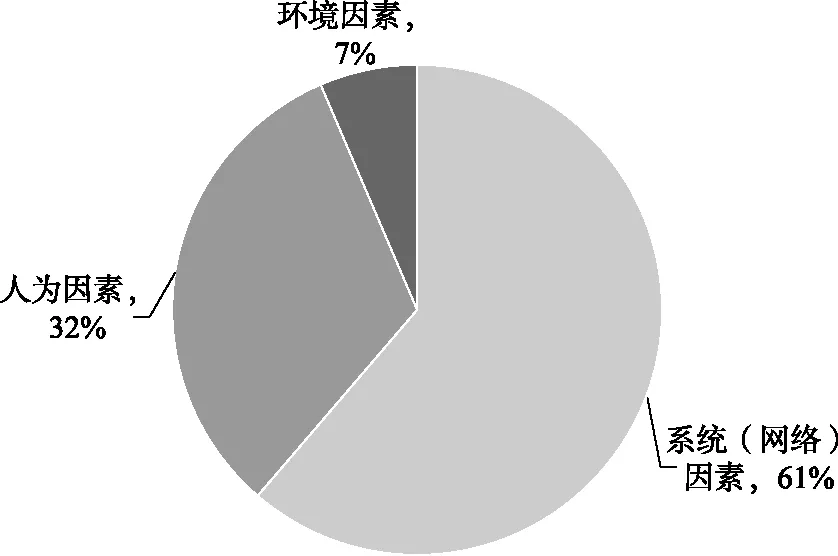
图3 事故原因占比情况
实践中,网络运行事故通常是多因素共同引发的,如长时间降雨可能导致供电基础设施损坏、用电设备短路或通信电缆被洪水冲断等,造成设备断电或传输中断,最终引发网络运行事故。
图4显示,割接升级、动力系统故障及网络设备软件故障为引发事故的主要因素,可占事故总数的66%。因此在系统设计、日常维护等工作中应重点关注动环系统和网络设备软件的运行情况,必要时部署自动化的监测设备,实时监控设备运行状况,预防事故发生。
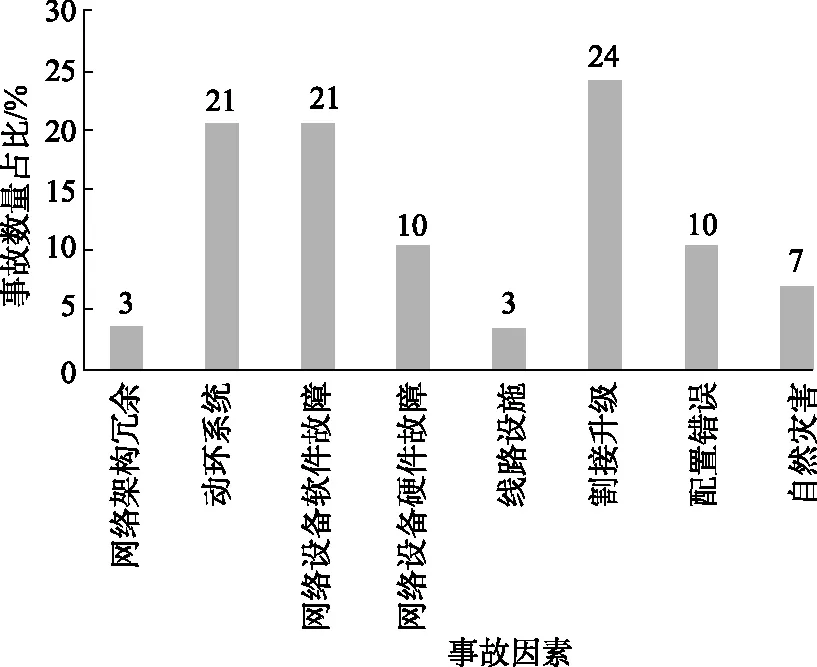
图4 事故因素占比情况
在影响时长方面,根据事故因素分类计算事故总数和总影响时长,得到事故因素平均影响时长,如图5。在统计范围内,割接升级平均影响时长最大,达到了1 336min;其次为自然灾害因素,平均影响时长为1 213min;网络设备软件故障因素为897min;网络设备硬件故障的平均影响时长最小为87min。
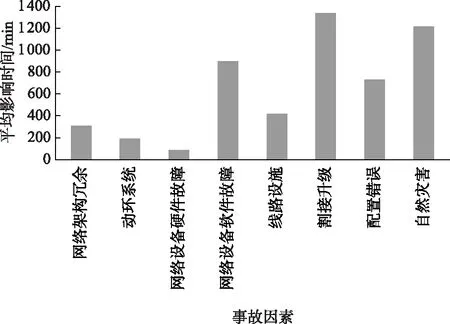
图5 事故因素平均影响时长
割接升级是系统的变更升级环节,操作复杂、风险较大,在实际操作中建议各网络运营者制定严格的操作流程、经过多次测试验证,并制定详尽的应急预案后再进行正式操作。操作中应严格监测系统各参数变化情况,发现异常及时应对,适时启动应急预案严防事故进一步扩大。
2 事故特征分析
信息通信网络作为经济社会发展的重要基础设施,其重要性与日俱增。目前随着传统通信技术(Communication Technology,CT)与信息技术(Information Technology,IT)融合发展,信息通信网络运行安全面临新的挑战,通信网络运行安全事故也出现了新的特征。
(1)网络结构变化导致网络运行风险增加。当前通信网络广泛应用网络功能虚拟化(Network Functions Virtualization,NFV)、网络服务化结构(Service-based Architecture,SBA)等新技术,通过分层解耦实现网络功能服务自动化管理,增强网络的灵活性和可扩展性;但是由于涉及厂家、平台众多,跨层关联紧密,发生故障极易由点及面,网络容灾保护方式由传统的网元级上升到机房(Data Center,DC)级、大区级,甚至各张网之间、网络与云资源之间,保证容灾生效的同时还要考虑信令冲击、业务均衡等诸多问题,单一故障极有可能带来严重并发症。日本KDDI事故成因与甘肃5G事故类似,因出现局部单点故障,用户注册失败导致服务器资源消耗增加,网络性能下降进一步引发注册用户数的激增,造成数据库同步失败,最终发生网络整体瘫痪。与传统的CT网络不同,IT提供的是“尽力而为”的服务,其基础资源复用率更高,导致发生网络故障时更容易从点扩散到面,形成连锁反应,造成大规模的网络运行事故。
(2)故障原因日益复杂化、隐蔽化,导致故障排除所需时间增加。网络云化的技术特征决定了网络运行事故原因定位和溯源难度加大,网络运维管理复杂度提高[7]。日本KDDI事故处理经历了倒回、处理信令拥塞、应对高负荷冲击、网元不同步等多个环节。运营商在如此复杂的环境中进行大量变更操作,很难做到在制定方案时遍历所有的业务和服务场景。一旦发生事故,经常由于预案不充分,经验不丰富,错失遏制事态发展的机会,导致事故影响面不断扩大。
(3)既有运维方式逐渐不能满足信息技术网络的发展要求。随着网络发展和演进,传统以人工为主的运维方式已经无法适应网络不断增加导致的运维复杂性、参数配置更加灵活等新型挑战[8]。网络系统中存在多个厂家专业设备,网络调整密集,对维护人员综合技能要求不断提高。加之核心网网元大多部署在省级或大区级,网络集中管理需要跨专业、跨部门、跨地域、跨厂家协同,应急处置和指挥调度难度倍增。
3 事故预防建议
(1)完善制度标准,提升网络健壮性。预防信息通信网络运行安全事故关键是从本质安全的角度出发,优化系统设计提升网络健壮性。通过网络架构保护、冗余设计等手段,预防环境因素、系统(网络)因素和人为因素引发事故。要进一步完善网络架构保护的相关技术标准,从冗余要求、运维管理和运行环境支撑3个方面完善相关标准体系。
(2)强化技术手段,预防信令风暴。针对易引起网络瘫痪的信令风暴,事故预防工作一是优化网络结构,控制大区/网元规模,降低信令风暴影响范围;二是提升网络设备抗冲击的能力,完善过载保护机制;三是做好无线网、核心网中信令处理网元的数据备份,避免因容灾倒换引发信令风暴;四是建立多维度流量分析和监控体系,在接入类、信令类网元中分级部署流量控制系统,提高流量精细化管理能力。
(3)落实风险评估,提升网络运行安全水平。风险是事故的根本原因,未遂事故是事故的前兆,控制风险、重视未遂事故对事故预防具有举足轻重的作用[9]。因此,应落实风险分级管控和隐患排查治理双重预防控制机制,加强信息通信设施风险评估管理,识别和控制网络设备软件、网络设备硬件、动力系统中存在的风险,防止风险转化为隐患,将隐患排除在事故发生之前。
主要工作内容包括:明确风险评估的组织形式、评估内容、评估结果的使用等关键要求;落实风险评估制度,建立风险和隐患清单;定期组织评估,识别分析系统中存在的风险(如数据库服务能力风险、应急策略风险、系统升级风险等),在此基础上制定风险控制措施(如倒换演练、应急演练的实施要求)等。
(4)加强人员培训,提高运维人员工作技能。高水平的运维人员是通信网络安全运行的重要保障,提升运维人员能力,预防参数配置错误等人为操作引发的事故,也有利于及时发现系统中的风险和隐患。因此应加强运维人员培训,定期组织知识技能比赛等,使运维人员熟练掌握各项操作技能,提升知识水平,完善运维能力。
(5)构建应急体系,强化事故处置能力。为降低网络运行事故影响,建议各相关企业制定信令风暴等故障的监测制度、完善监测方法,尽早预警,人员提前介入,迅速排除故障;其次,制定多项流量控制应急预案,在事故发展的不同阶段都能有效介入,控制影响范围,逐步排除故障。各项专项应急预案应明确应急组织形式、人员构成、应急处置流程等内容,保障各项应急资源配备。定期组织人员进行应急演练,使工作人员熟悉应急处置流程和在应急活动中的任务分工。做到在事故发生后第一时间进行处置,防止事故后果扩大。
(6)推进技术研发,完善事故溯源机制。我国拥有世界上规模最大的信息通信网络,且网络系统结构复杂,相应的事故隐患存在的可能性较大,事故发生后,发展演化过程复杂,为事故原因排查和事故调查带来挑战。建议加强技术研究,完善事故监测和记录的手段,准确完整地记录事故发生、发展、排除全过程,提升事故溯源分析能力。将事故发生、处置的经验做法梳理转化为事故预防的经验,促进行业技术水平提升。
4 结论
当前,信息通信网络逐渐成为一项重要的社会基础设施,为其他各行业的发展提供支撑,起到“一业带百业”的作用。本文通过分析近3年国内外发生的网络运行安全事故,并总结事故规律,得到以下结论:
(1)网络技术跃迁给网络运行安全带来新的挑战,事故影响时长出现逐年增长的趋势。建议从网络架构保护、网络运行维护、运行环境防护3方面采取措施予以应对。
(2)网络运行事故具有定位难、处置难、持续时间长的特点,建议构建高效的应急管理体系,推进故障记录、事故溯源等技术手段,降低事故影响。
(3)系统割接升级引发的事故平均影响时长最大。建议充分发挥主观能动性,提升一线操作人员的工作技能,提供多场景模拟实操环境,强化人员工作能力,同时优化系统设计提升网络健壮性,预防事故发生。
