基于类间损失和多视图融合的深度嵌入聚类
2023-03-09郭晴晴王卫卫
郭晴晴, 王卫卫
(西安电子科技大学 数学与统计学院, 西安 710126)
聚类是机器学习领域最基本的无监督学习任务, 其核心思想是基于相似性度量将相似的数据划分到同一类, 不相似的数据划分到不同类.近年来, 对聚类的研究已取得了许多成果, 如K-均值聚类(K-means)[1]、谱聚类(SC)[2]、高斯混合聚类(GMM)[3]、非负矩阵分解聚类(NMF)[4]等经典方法, 有效解决了低维数据的聚类问题.但随着数据维度的增加, 传统聚类方法面临如下问题[5]: 1) 高维空间中, 数据点之间的常用距离将趋于相等, 导致基于距离的聚类方法失效;2) 高维数据导致计算复杂代价急剧上升;3) 高维数据常会出现冗余特征且有噪声, 严重影响聚类性能.目前, 解决高维数据聚类的方法主要是对高维数据进行降维或特征变换, 先将原始高维数据映射到低维特征空间, 然后对低维特征采用传统方法进行聚类.但一些具有高度复杂非线性结构的数据聚类问题仍面临很大挑战[6].
由于深度神经网络具有强大的学习非线性变换的能力, 因此基于深度神经网络的降维方法在聚类中被广泛应用[7-12], 目前已有的方法主要分两类: 一类是两阶段法[9-11], 先利用深度神经网络提取原数据的低维特征, 然后将低维特征作为传统聚类方法的输入, 得到最终聚类结果, 但该方法不能保证提取的低维特征符合所用聚类方法对数据的假设, 聚类性能并非最优;另一类方法是单阶段法[7-8,12-13], 为保证提取的低维特征适合所用的聚类方法, 单阶段方法在训练神经网络时, 将聚类损失和特征提取损失相结合, 即用聚类方法驱动特征提取, 有效改善了特征提取和聚类的匹配度, 显著提高了聚类性能.例如, 深度嵌入聚类(deep embedding clustering, DEC)[7]将特征提取和聚类两个阶段相结合, 利用深度神经网络学习原数据的低维特征, 同时利用学习到的低维特征进行聚类.DEC中引入了一种广泛应用的聚类损失, 即软分配分布和辅助目标分布的Kullback-Leibler(KL)散度[14].但该方法存在两个不足: 首先, 它在训练时舍弃了自动编码器的解码器部分和重构损失, 未考虑到微调会扭曲特征空间, 削弱了特征表示的代表性, 从而影响聚类效果;其次, 软分配分布和辅助目标分布使特征类内尽可能靠近, 忽略了特征的类间关系.针对第一个问题, 改进DEC(IDEC)[8]结合自动编码器的重构损失和聚类损失保存局部结构, 避免了微调时对特征空间的扭曲;但第二个问题仍然被忽视.此外, 这些方法还存在很大的局限性, 即仅考虑了对单视图数据的聚类.事实上, 在许多实际聚类任务中, 数据可能来自不同领域或者不同的特征收集器, 这类数据称为多视图数据.例如, 对同一事件, 多个新闻机构、多种媒介报道的新闻就是这一事件的多视图数据;相同语义的多语言形式表示也是多视图数据.由于多视图数据的普遍性, 因此研究多视图数据的聚类具有重要意义和广泛的应用场景.多视图数据包括各视图之间的公共信息和互补信息, 其中公共信息有助于提高对研究对象共性的认识, 而互补信息则能体现多视图数据的潜在价值.多视图数据聚类要解决的关键问题是如何充分挖掘各视图之间的公共信息和互补信息, 从而最大程度地提高不同视图之间类别的一致性, 提高聚类性能.文献[15-21]提出了多种多视图聚类方法.深度典型相关分析(DCCA)[15]和深度广义典型相关分析(DGCCA)[16]将深度神经网络与典型相关分析(CCA)相结合, 以实现多视图数据的联合非线性降维, 然后对低维特征使用传统聚类方法[1-4]进行聚类, 其优点是DCCA能有效地联合提取多视图数据的低维特征, 但特征学习与聚类没有联合优化.深度多模态子空间聚类(DMSC)[18]将多视图融合技术应用到子空间聚类上, 为每个视图设计一个自动编码器学习每个视图的低维特征, 对低维特征进行空间融合, 并提出了几种基于空间融合的网络结构和融合函数.这些方法虽然在多视图聚类中取得了较好的效果, 但特征学习与聚类并没有联合优化, 属于两阶段的训练方法, 聚类性能并非最优.具有协作训练的深度嵌入多视图聚类(DEMVC)[19]是一种单阶段的多视图聚类方法, 首先通过自动编码器学习多个视图的特征表示, 然后通过协作训练促使不同视图的软分配分布最终趋于相同, 但协作训练对各视图视为相同的重要性, 因此对多视图不均衡的问题存在缺陷;同时该方法充分利用了DEC的优势, 并添加重构损失以保存局部结构, 但仍忽略了类间关系.
本文主要考虑多视图数据聚类.在理想情况下, 对聚类友好的特征表示不仅应保证属于同一类的数据要尽可能靠近, 而且还要确保不同类的数据之间尽可能远离.但现有聚类方法仅考虑了特征表示的类内一致性, 而忽略了类间关系.因此最终学习到的特征表示不具有判别性, 从而影响聚类性能.基于此, 本文通过在DEC聚类损失的基础上引入一个新的类间损失函数, 使通过多视图特征融合网络学到的各视图的公共特征具有类间尽可能远离, 类内尽可能靠近的特点, 使其更具有判别性, 从而更适合聚类.通过与多视图特征融合网络结合, 本文提出一种基于类间损失和多视图特征融合的深度嵌入聚类方法, 不仅可保证各视图共享特征表示的类内一致性和类间判别性, 而且还针对DEMVC中协作训练存在的不足引入一种新的基于全连接层的多视图特征融合技术, 以提高训练网络的泛化能力.在多个常用数据库上的实验结果表明, 本文方法聚类性能相对于对比方法有显著提高.
1 预备知识
1.1 深度嵌入聚类

图1 DEC网络框架Fig.1 Framework of DEC network
DEC是一种单视图的深度聚类方法, 其网络结构如图1所示.首先, 使用稀疏自编码网络(sparse auto-encoder, SAE)对数据集进行预训练, 得到特征zi, 执行K-means得到初始聚类中心μj; 然后利用t分布, 计算特征zi和聚类中心μj之间的相似度:
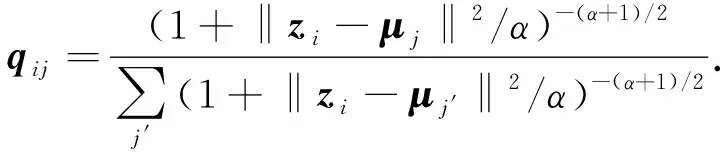
(1)
由于其可视为将样本i分配给第j类的概率, 因此也称为软分配分布.DEC还定义了一个辅助目标分布pij确定样本所属的类, 用公式表示为
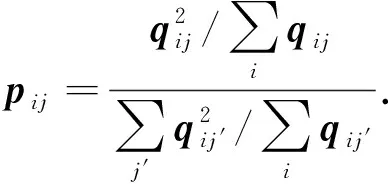
(2)
DEC进一步优化基于KL散度的聚类损失:
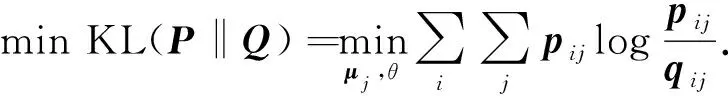
(3)
根据上述聚类损失, 用带有动量的随机梯度下降(SGD)[22]法对特征zi和聚类中心μj进行联合优化.该方法有利于把属于每一类的数据个数进行平均分配, 使类内尽可能靠近, 从而使数据在特征空间更具有可分性, 但缺点是未考虑到数据的类间关系, 导致聚类效果不稳定.
1.2 深度嵌入多视图聚类
DEMVC是一种多视图深度嵌入聚类方法, 可同时优化多视图的特征表示和聚类分配, 并根据协作训练对多视图的互补信息进行有效学习, 最终使不同视图的软分配分布趋于相同.其网络结构如图2所示.

图2 DEMVC网络框架Fig.2 Framework of DEMVC network


(4)
其中γ为非负参数.最后, 通过对上述损失函数进行优化, 微调整个网络结构达到平衡, 再对各视图的聚类结果取平均得到最终的聚类结果.协作训练旨在最大程度地实现所有视图之间的公共信息, 它将各视图视为同等重要, 因此无法解决存在多视图重要性不均衡的问题.而多视图特征融合方法则利用网络的灵活性, 将提取的特征合并为一个更具有判别力的特征, 泛化能力更强.
2 方法设计
为改进多视图特征表示的训练方式, 并保证学到的各视图公共特征的类内一致性和类间判别性, 本文提出一种基于类间损失的深度嵌入聚类方法.本文的网络框架主要由两部分构成: 多视图融合模块和深度嵌入聚类模块.首先将不同视图的数据输入到自动编码器中, 得到多个视图的特征表示;然后借助网络的灵活性, 在编码器和解码器之间使用一层全连接网络, 组合出判别性更强的各视图的公共表示;最后将公共表示输入到聚类模块中, 这里聚类模块采用DEC中的聚类损失, 并在其原有类内关系的基础上, 添加类间损失以增强公共表示的判别性.其网络框架如图3所示.总的目标函数包括各视图数据的重构损失和聚类损失两部分, 用公式表示为
L=Lrec+λ1Lclu,
(5)
其中Lrec和Lclu分别为自编码网络的重构损失和聚类损失,λ1为权衡系数.
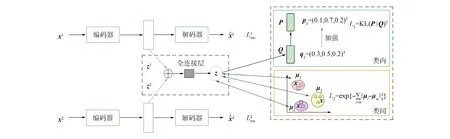
图3 本文的网络框架Fig.3 Framework of proposed network
本文以双视图数据集为例, 给定多视图数据集{x1,x2}, 其中x1,x2∈D分别是第1个视图和第2个视图的数据.可令N为每个视图的样本数, 则表示xv的第i个样本(i=1,2,…,N), 且v={1,2}.
2.1 基于全连接层的多视图融合
为利用不同视图之间的多样性, 需将多个视图的特征表示进行融合.而DEMVC的融合方法基于各视图的加权融合, 对多视图不均衡问题存在不足, 因此本文通过引入全连接层对多视图特征进行融合, 以提高训练网络的泛化能力.首先通过自动编码器对多视图数据进行训练, 得到不同视图的特征表示, 再对各视图的特征进行拼接后, 按上述方法对得到的特征表示进行融合, 最终得到各视图的公共表示.
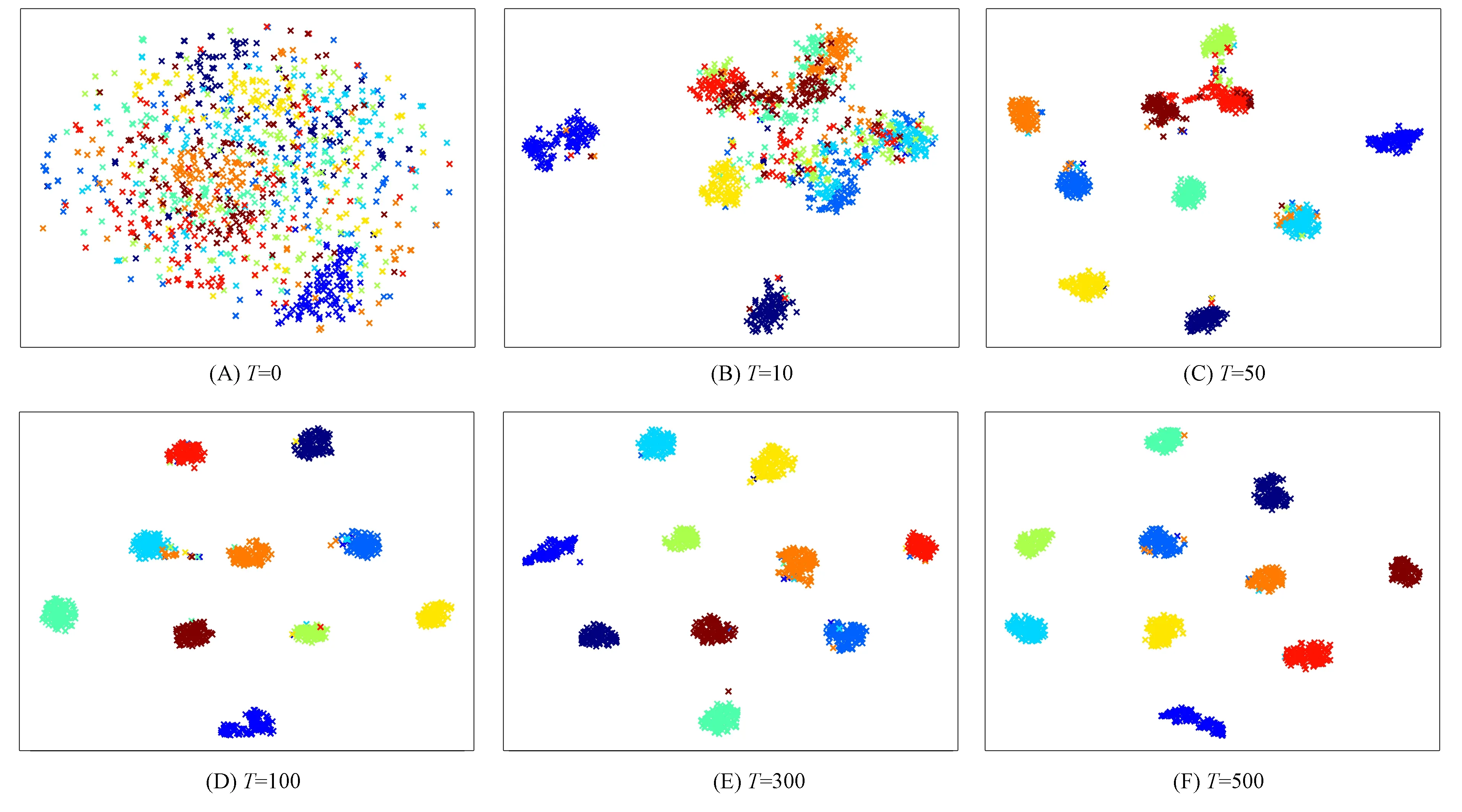
对于每个视图, 卷积自动编码器的f(v)将输入xv进行压缩得到d维的特征表示zv∈d, 即zv=f(v)(xv)∈d(d (6) 在得到各视图的特征表示后, 先将不同视图的特征进行简单拼接, 然后经过单层全连接层进行融合, 得到公共表示z=h(z1⊕z2), 其中h(·)是全连接层, ⊕表示矩阵的拼接操作.此时得到的公共表示z包含两个视图x1,x2的特征, 可为后续的聚类任务提供更多的信息, 从而达到聚类的目的. 首先考虑一般的深度嵌入聚类损失, 该损失通过软分配分布和辅助目标分布之间的KL散度进行优化.首先利用K-means对各视图的公共特征表示zi(zi是特征z的第i个样本)进行聚类, 得到初始的聚类中心μj, 然后再使用Softmax函数测量特征zi与聚类中心μj之间的相似度sij, 用公式表示为 (7) 其中ε为参数.与式(1)类似,sij也可视为将特征i分配给第j类的概率, 称为新的软分配分布.根据深度嵌入聚类方法的损失函数, 软分配分布所对应的辅助目标分布可定义为 (8) (9) 与式(3)类似, 最小化KL散度的损失函数L1主要考虑类内置信度高的特征点, 但未考虑类间关系.这里为使不同聚类中心之间的相似度尽可能小, 使用欧氏距离度量不同类中心的相似度, 并定义如下类间损失: (10) 只有当不同聚类中心之间的距离足够大时,L2才会尽可能小.因此通过最小化该损失可使不同类中心之间的距离尽可能远, 从而有助于提高特征的判别性.如图3右下角橙色虚线框所示, 在损失L2的作用下, 不同类之间的聚类中心彼此远离, 同时使属于某一类的特征表示趋于靠近该类的聚类中心, 从而不同类的特征表示互相远离, 学习到的特征表示更具有判别性. 因此, 结合特征的类内关系和类间关系, 可将聚类损失表示为 Lclu=L1+λ0L2, (11) 其中λ0为非负参数. 模型训练包括两个阶段: 初始化阶段和微调阶段.首先, 初始化阶段对所有视图的自动编码器最小化式(6), 然后通过最小化式(5)微调所有视图的自动编码器、聚类分配和聚类中心;最后当微调阶段结束时, 基于软分配sij, 分配给xi的标签ui可由下式计算: (12) 模型训练过程如下. 算法1基于类间损失和多视图融合的深度嵌入聚类优化算法. 输出: 聚类标签; 步骤2) 基于多视图特征融合方法, 将各视图的特征表示输入到全连接层得到公共表示zi; 步骤3) 基于K-means聚类算法得到特征的初始聚类中心μj; 步骤4) 基于Adam优化器优化目标函数(5)直至收敛; 步骤5) 基于sij每行最大值的索引进行样本聚类中心(式(12))获取标签. 为验证本文方法的有效性, 采用不同类型的多视图数据集进行实验验证, 选择MNIST[23],Fashion-MNIST[24]和USPS三个手写数字数据集, COIL20[25],COIL100[26]两个物体数据集以及Yale_32[27],ORL_32[28]两个人脸数据集构造多视图数据集.这些单视图数据集的信息列于表1. 表1 单视图数据集信息 构造多视图数据集的方法有3种: 1) 对原始数据集进行不同类型的数据增强获得不同视图的样本;2) 使用不同的数据集作为不同的视图;3) 使用原始数据集的不同部分构造不同的视图.下面分别介绍本文使用上述方法构造出的9个多视图数据集. 数据集Nosiy-RotatingMNIST: 该多视图数据集由第一种构造方法得到, 它使用数据集MNIST生成两个视图的数据集.根据DGCCA, 首先以[-π/4,π/4]的角度对图像随机旋转, 将生成的图像作为第一个视图的样本.然后对第一个视图的每张图像, 从原始数据集中随机选取一张具有相同类别的图像, 在每个像素点上加入从[0,1]均匀采样的独立随机噪声, 得到对应的第二个视图的样本.数据集Nosiy-RotatingCOIL20,Nosiy-RotatingCOIL100,Nosiy-RotatingYale32,Nosiy-RotatingORL32: 这4个多视图数据集的构造方法与数据集Nosiy-RotatingMNIST的构造方法类似.数据集MNIST-USPS: 该多视图数据集由第二种构造方法得到, 它将USPS和MNIST分别作为两个视图, 并从每个视图中随机选择分布在10个数字上的5 000个样本.数据集Fashion-10K: 该多视图数据集由第三种构造方法得到, 由数据集Fashion-MNIST生成, 其中10 000张图像作为测试集.先将该测试集作为第一个视图的样本, 再对每个样本, 从该集合中随机选择一个具有相同标签的样本, 以构造第二个或第三个视图, 每个样本的不同视图是同一类别的不同样本.因此该数据集有双视图和三视图两个版本, 以在名称最后添加“_2view”和“_3view”进行区分.数据集MNIST-10K_3view: 该多视图数据集由数据集MNIST生成, 同理, 将MNIST的测试集作为第一个视图, 而第二和第三个视图的构造方法与Fashion-10K的构造方法相同, 后缀“_3view”表示三视图版本. 选取两个常用的聚类评价指标: 聚类准确度(accuracy, ACC)和标准化互信息(normalized mutual information, NMI)[29].这两个评价指标从两方面对聚类结果进行评估, 其值越高表明聚类效果越好.ACC表示聚类结果的正确率, 计算公式为 (13) 其中li为第i个数据的真实标签,ci为模型产生的第i个预测标签,m(ci)为映射函数, 最佳的映射可使用Hungarian算法[30]求解.NMI计算相同数据的两个标签之间相似性的标准化度量, 计算公式为 NMI=I(l;c)/max{H(l),H(c)}, (14) 其中l和c分别表示聚类结果的标签和真实标签,I(l;c)表示l和c之间的互信息,H(l)和H(c)分别为l和c的信息熵. 为证明本文方法的有效性, 设置对比实验分别验证本文方法在手写数字数据集、物体和人脸数据集上的有效性.本文方法在物体、人脸数据集和手写数字数据集上与其他各方法的聚类性能对比结果列于表2和表3.表2列出了双视图的物体数据集和人脸数据集用多视图深度聚类方法的实验结果, 主要比较了各方法在物体和人脸数据集上的聚类结果, 所有结果均为运行3次取平均得到.表3列出了双视图和三视图的手写数字数据集用多视图深度聚类方法的实验结果, 主要比较了各方法在两个视图版本的手写数字数据集上的聚类结果, 其中*表示精度值摘自文献[16]和文献[29].由于K-means聚类中心的影响, 运行结果均为运行3次取平均得到. 表2 不同方法在物体数据集和人脸数据集上的聚类性能对比 表3 不同方法在手写数据集上的聚类性能对比 由表2和表3可见: 首先, 本文方法的聚类结果在大部分数据集上均优于其他方法;其次, 在数据集的类型上, 手写数字数据集的聚类结果虽提升较小, 但总体水平高, 而由于物体数据集和人脸数据集的聚类难度偏高, 聚类结果提升相对较大;最后, 在数据集的视图个数上, 3个视图数据集的结果均优于两个视图数据集的结果.实验结果表明, 本文方法能有效地从多视图中提取到更具有判别性的特征, 同时也验证了该方法在多视图聚类中的有效性. 为验证本文方法各模块的有效性, 实验对比多视图特征融合下的重构损失Lrec和平均融合下的重构损失Lrec及聚类损失Lclu中的L1和L2的影响.数据集Nosiy-Rotating的消融实验结果列于表4, 其中“√”表示带有该模块的方法.由表4可见: 一方面, 当仅使用重构损失Lrec时, 采用多视图特征融合的本文方法显然比平均融合的DEMVC方法的聚类性能高;另一方面, 总的损失函数仅有Lrec或L1的ACC值小于0.95, 同时损失函数不包含与包含L2相比, 聚类效果约提升了1%.因此, 聚类精度会随着损失的逐渐增加而增加, 表明损失函数中的每个损失对最终的聚类性能都很重要. 为进一步验证类间损失的有效性, 采用t-SNE可视化方法对DEMVC方法的嵌入进行二维降维与可视化.利用Python环境下sklearn工具包中的manifold.TSNE 函数进行降维(降至二维), 并用matplotlib工具包中的pyplot.plot进行绘图, 实验结果如图4所示(不同颜色表示不同的数据聚集).由图4可见, 在数据集Nosiy-RotatingMNIST上, 与DEMVC方法进行对比, 本文方法使不同类之间的样本更易区分, 即聚集更明显且易划分. 表4 数据集Nosiy-Rotating的消融实验结果 图4 数据集Nosiy-Rotating上不同方法的t-SNE对比Fig.4 t-SNE comparison of different methods on Nosiy-Rotating dataset 为进一步验证本文方法的收敛性, 本文可视化随着迭代次数特征表示的t-SNE图和随着迭代次数增加的聚类性能曲线图分别如图5和图6所示. 图5 数据集Nosiy-Rotating随着迭代次数增加的t-SNEFig.5 t-SNE increasing with number of iterations on Nosiy-Rotating dataset 由图5可见, 随着迭代次数的增加, 类内的数据点逐渐靠近, 不同类的数据点逐渐远离, 同时不同类的分类边界更清晰, 当T=100时基本稳定.由图6可见, 聚类指标ACC和NMI随着迭代次数的增加趋于稳定.实验结果验证了本文方法最终达到收敛, 同时由于数据集较大, 本文方法存在运行时间较长等不足. 图6 数据集Nosiy-Rotating的聚类性能指标变化曲线Fig.6 Variation curves of clustering performance index on Nosiy-Rotating dataset 综上所述, 为有效解决实际应用中的多视图聚类问题, 本文提出了一种基于类间损失和多视图融合的深度嵌入聚类方法.首先, 通过自动编码器对多视图数据进行训练, 得到不同视图的特征表示;然后, 利用全连接层对各视图的特征进行融合, 再根据公共表示得到改进的软分配分布和辅助目标分布;最后, 基于类间损失和软分配分布及辅助目标分布之间的KL散度对公共表示和聚类分配进行联合训练, 进而得到聚类结果.实验结果表明, 该方法在多个多视图数据集上的聚类精度均效果良好.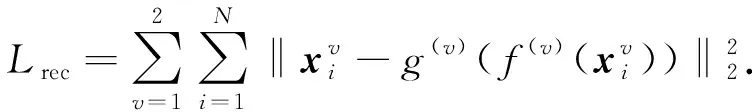
2.2 基于类间损失的深度嵌入聚类

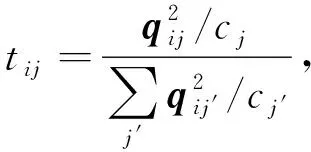
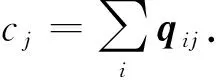


2.3 模型训练


3 实验与分析
3.1 实验数据集

3.2 实验设置

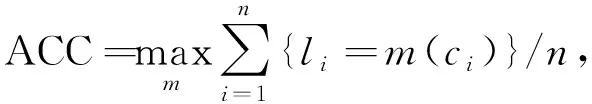
3.3 聚类性能对比


3.4 消融实验


3.5 收敛性分析