基于自然语言处理的高校课程思政文本挖掘及可视化分析
2023-03-08马占森苗冯博辛瑞昊
冯 欣,王 苹,马占森,苗冯博*,辛瑞昊
(1.吉林化工学院 理学院,吉林 吉林 13200;2.吉林化工学院 信息与控制工程学院,吉林 吉林 133200)
习近平在2016年的全国高校思想政治工作中明确提出:“其他各门课都要守好一段渠、种好责任田,使各类课程与思想政治理论课同向同行,形成协同效应”[1]。协同效应是要求高校在育人的同时,把思想政治教育与各类课程教学相融合,让学生在实践中接受思想政治教育[2]。课程思政的提出最早是2014年由上海教育委员会提出的,并在上海部分高校进行了试验,取得了较好的试验结果,习近平的讲话为课程思政的进一步发展指明了方向。
我国高等院校是引导大学生树立正确的道德观、人生观和价值观的主要阵地,理应担当起新时代的新使命[3]。立德树人成效是检验高校工作的一切标准。近几年来,课程思政逐渐走进大众视野,也逐步走进了各大高校的教学中,高校课程思政也成为学者研究的热点之一[4]。
随着时代的发展,人工智能、大数据等新兴技术的崛起,计算机的计算性能得到了大幅度的提高以及构建了各种大规模语料库,自然语言处理技术作为人工智能的一个分支,取得了快速发展,并且被广泛应用于多个领域,尤其是教育领域[5]。习近平在国际人工智能与教育大会致贺信中强调,要高度重视人工智能在教育领域的应用,积极推动人工智能和教育深度结合,促进教育变革创新,加快发展伴随每个人一生的教育、平等面向每个人的教育、更加开放灵活的教育[6]。
基于自然语言处理技术的文本挖掘是人工智能在教育领域的成果应用之一。自然语言处理技术将数据挖掘、知识计量与聚类分析等方法结合,利用可视化分析直观展示研究问题的核心内容、热门方向和整体知识架构等信息[7]。与传统文献研究法相比,自然语言处理技术通过大数据分析和可视化技术在海量文献数据中获取重要信息,分析和展示该领域的研究进展和发展趋势,极大地提高了研究效率[8]。
本文基于自然语言处理技术,对中国知网(CNKI)在2011—2021年期间所收录的与高校课程思政相关的17 059篇文献数据进行了详细处理。通过运用知识图谱,对已有的研究成果进行综合总结和可视化分析,旨在深入洞察课程思政领域的研究热点及未来发展趋势,为研究课程思政的学者提供参考和数据支撑[9]。
一、数据收集
(一) 数据来源
本文用到的实验数据来源于中国知网(CNKI)数据库,采用中国知网的专业检索,在搜索栏内输入“SU=‘高校’*‘思政’*‘课程’OR SU=‘大学生’*‘思想政治’*‘教育’OR SU=‘思政课’*‘改革’OR SU=‘思想政治’*‘建设’”,检索时间选择2011—2021年,共检索到18 576篇相关文献。获取到的数据信息包括序号、文献名字、作者、期刊名称、发表时间、引用次数、下载次数、第一作者所在地、关键词、页数和摘要。剔除掉没有关键词的数据,剩下17 059条文献数据进行分析和统计[10]。
(二) 数据获取
本文分析了近十年中国知网中关于课程思政研究热点相关问题,由于数据量庞大,为了快速获得准确并且详细的文献信息,采用了网络爬虫算法按照制定的规则爬取所需要的文献数据信息。网络爬虫的原名称是web crawler,意思是在网页上爬行搜索资料,所以网络爬虫也叫网络蜘蛛。它可以自动浏览网页中的信息,帮助人们自动在网页中进行数据采集、下载和整理。随着大数据时代的到来,互联网中的数据也越来越多,如果只靠人们手工去进行数据收集和下载,则会大大降低收集数据的效率,所以近几年来网络爬虫的地位越来越重要[11]。目前网络爬虫最常用的工具是python,python中有网络爬虫最实用的三个框架,分别是BeautifulSoup、Selenium及Scrapy。三个框架都有各自的特色和优点,根据本文所需要的数据,采用了“BeatifulSoup+Selenium”方法进行了网络爬虫,该方法主要分为四个步骤,分别是抓取网页、解析网页信息、提取网页信息数据和数据储存。网络爬虫的具体流程如图1所示。在网络爬虫过程中,遵循了网站的robots协议,保证了网络爬虫的合法性[12]。

图1 网络爬虫具体流程
二、实验原理
文本挖掘也叫文本数据挖掘,类似于文字分析,即文本处理中生成高质量信息。自然语言处理(NLP)可以进行文本挖掘,也是目前海量数据展现的一种常见的方法[13]。由于文献数据有一定的复杂性与全面性,需要基于人工智能实线文献数据文本挖掘,才可以充分了解课程思政的发展情况,并预测未来研究的热点。本文基于自然语言处理技术,采用TF-IDF算法提取文献摘要中的主题词,然后利用jieba分词技术对文献数据信息进行切分,最后采用K-means聚类算法进行分析,为学者提供相关数据进行参考,便于针对性解决课程思政的一系列问题。基于自然语言处理技术的课程思政文献数据挖掘流程如图2所示。
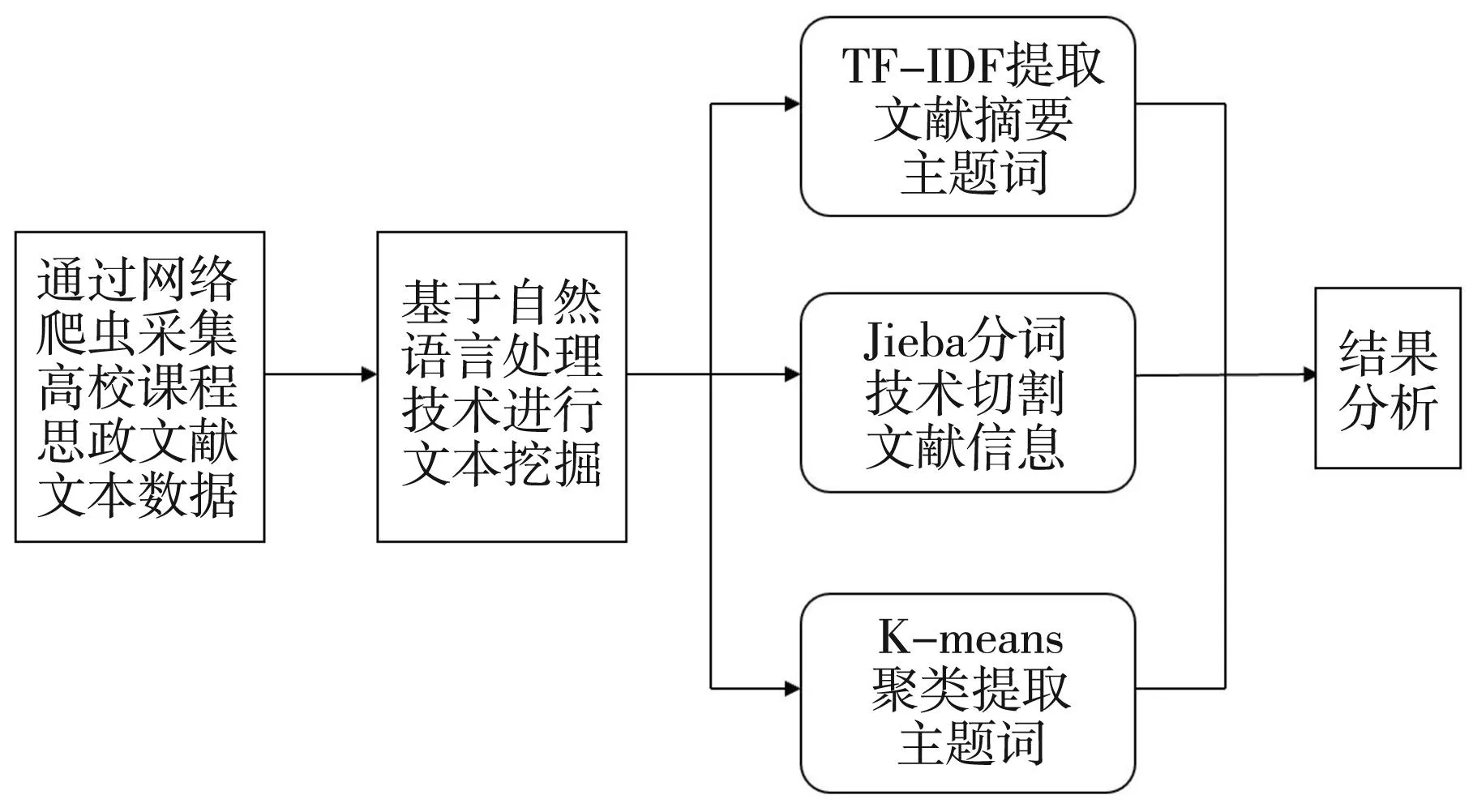
图2 文献数据挖掘流程图
(一) 基于TF-IDF算法提取摘要主题词
文献摘要是对整篇文章进行总结概括,简明扼要地说明文章研究目的、研究方法和研究结论。本小节采用TF-IDF算法进行文本挖掘,提取文献摘要的主题词。其中TF是词频表示一个给定的词语t在这篇给定的文档d中出现的频率,TF越高,表示词语t对文档d来说越重要,TF值低则相反。IDF是逆向文档频率,包含词语t的文档越少,则IDF越大,说明词语t对于文档区分具有很好的能力。TF-IDF算法进行文本挖掘流程如图3所示。

图3 TF-IDF算法流程图
(二) 基于jieba分词技术切割文献信息
为了提升结果的准确度,实现对课程思政相关文献精准分析,本小节将利用jieba分词技术结合TF-IDF算法对文献信息进行切割,进一步扩充文献主题词。Jieba分词技术是一个针对文本挖掘的分词精度高、速度快的中文分词模块。Jieba分词在语料库的辅助下,通过规则与统计相结合的方法,利用前缀词典实现文本扫描,生成不同的可能出现的词组组合,通过寻找最大概率的组合找出词频最高的切分组合。Jieba分词切割文献信息流程如图4所示。

图4 jieba分词流程图
(三) 基于K-means聚类提取文本主题词
文本聚类是文本挖掘最关键的一步,文本聚类是把相似的对象分成不同组别或者不同的子集,让同一个组别或者子集的成员对象有着相同的属性。K-means聚类算法是比较常用的聚类算法,它把n个点划分到k个聚类中,使每个点都属于离他最近的均值即聚类中心对应的聚类,来作为聚类的标准。K-means聚类算法提取文本主题词流程图如图5所示。
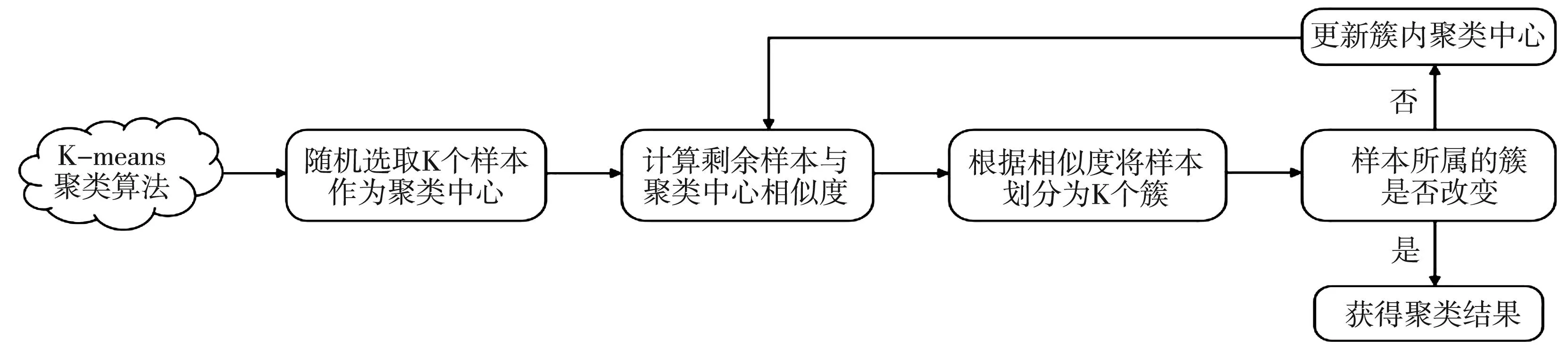
图5 K-means聚类算法流程图
三、结果分析
(一) 课程思政研究主题分类明确
通过自然语言处理的TF-IDF算法、jieba分词和K-means聚类得到了关于课程思政的3 789个主题词。根据各主题词出现的次数进行排序,选取了出现次数最多的50个主题词进行统计分析,计算各主题词的平均TF-IDF值和标注各主题词的研究类型,分别将主题词标注为研究对象O、研究内容T和研究方法M。标注主题词时剔除了7个有相同意义或研究类型模糊的主题词,剩余43个主题词进行统计分析。主题词分析结果见表1。

表1 主题词分析结果
从表中可以看出课程思政、高校、大学生、思政课等等主题词,不仅出现次数多,而且平均TF-IDF值也是比较高的,说明这些主题词是学者研究课程思政的热点方向。
(二) 课程思政研究内容侧重不同
本文利用自然语言处理中的K-means聚类算法对研究内容主题词进行分析,将主题词分为三个主要类别并得到了以研究内容为聚类中心的3个簇,聚类中心分别为课程(477)、思想(222)、大学生(36)。三个主题的文献数量近十年的变化趋势如图6所示,图中横纵标代表年份,纵坐标代表该主题词在文献中出现的次数。

图6 文献主题词年度分布图
从课程思政研究内容来看,课程思政研究的主题词可以划分为三个主要类别:课程、思想和大学生。在过去十年中,这三个主题词的研究文献数量呈现持续增长的趋势。特别是在2020年至2021年期间,这三个主题的文献发表数量有显著增加。课程思政研究文献的数量在2014年迅速提升,这可能与上海市教育委员会在该年正式推出课程思政试验有关。这一试验在上海一些高校中开展并取得良好的成效,这使得课程思政成为研究的热点,促使相关文献产出量快速增加。这表明课程思政已经成为教育界的一个热门研究领域,并且有望在未来继续发展和探索。
(三) 课程思政研究对象分类合理
本小节对文献主题词的研究对象进行分析总结,总结结果如图7所示。

图7 研究对象词频统计
图7中横坐标文献主题词,纵坐标代表每个主题词在文献中出现的次数。根据对文献研究对象进行分析可知,大学生是课程思政的主要研究对象,反映了我国对青年大学生思想政治教育的重视程度。课程思政正在逐渐渗透到各大高校,在传授专业课程的同时,也向大学生传授思想政治教育。课程思政已成为大学教育中不可或缺的组成部分。
(四) 课程思政研究机构逐步扩大
对文献数据的核心机构进行整理和总结,发表文献数量排名前30的机构见表2。

表2 发表文献核心机构
通过对文献数据核心机构的整理和总结可知,本科高校是课程思政研究的主要机构,拥有丰富的研究经验和优势条件。相比之下,专科和技术院校在课程思政研究方面的贡献相对较低,需要加强对课程思政教育研究与教学的关注和支持。
(五) 课程思政研究热点循序渐进
研究热点是一段时间内该研究领域的焦点,学者共同探讨的话题。分析研究热点的方法有很多,目前比较常用的有科学计量方法Citespace软件、共词分析方法、聚类分析和多尺度分析。传统的聚类分析,是使用关键词进行聚类,再根据聚类结果分析研究热点领域,这样分析的研究热点是以标签为代表的聚类端点,缺少研究内容和研究对象的相关分析。本文将对研究内容(T)和研究对象(O)进行相关分析,热力图如图8所示,从图中可以看出,课程思政主要围绕高校大学生开展,研究热点内容是思想政治教育。课程思政是中国高校独有的教育理念,是新时代思想政治教育发展的前进方向。跟传统的思想政治教育相比,课程思政全方位对高校大学生进行教育,让思想政治教育与专业课程同向同行。

图8 研究对象(O)和研究内容(T)热力图
四、结束语
本文借助自然语言处理技术和数据可视化,对课程思政研究领域的文献进行总结和可视化分析,以课程思政2011—2021年17 059篇文献数据作为样本,从发表时间、核心机构、主要研究对象和高频主题词进行统计分析,探究课程思政的研究热点和发展趋势。通过对课程思政的定量分析,可以得知从2014年提出课程思政这一概念,就受到了学术界的高度关注。我国课程思政主要针对的研究对象是大学生,课程思政的研究也已经从理论探讨逐渐转向专业课程教学实践,表明课程思政和各类专业课教学正在协同发展。从研究机构分析来看,课程思政的研究机构主要集中在本科高校,未来需要加强高职院校课程思政的研究与教学。综上所述,课程思政作为一项重要的教育理念和实践,受到了广泛的关注,并在大学生思想政治教育和专业课程教学中发挥着积极的作用。未来的研究需要更多地关注高职院校的课程思政实践,推动思政教育全面发展。
