基于双层视觉及多尺度注意力融合的图像去雾
2023-03-08邬开俊丁元
邬开俊,丁元
(兰州交通大学 电子与信息工程学院,甘肃 兰州 730070)
工业发展给环境造成了影响,大气中的悬浮颗粒也逐渐增加,导致雾霾天气的发生,并且使得日常生活中得到的图像产生模糊、对比度下降等问题,因此对这类图像进行目标检测、目标识别、跟踪和分割等计算机视觉任务会变得更为复杂.以上情况使得计算机视觉的自动化和远程监控系统等应用无法正常发挥作用,因此如何提高均匀和非均匀雾霾图像的清晰度、对比度以及突出场景细节等问题具有重要的研究意义.
传统的图像去雾算法包括经典的图像增强算法,如直方图均衡化、Retinex 算法[1]等,这类算法主要通过增强雾霾图像的饱和度以及对比度来提高降质图像的质量,但实质并没有从雾霾产生的条件出发.另一类传统的图像去雾算法基于大气散射模型[2],包括基于暗通道去雾算法[3]、变分模型去雾算法[4]、自适应雾度衰减去雾算法[5]、颜色衰减去雾算法[6]等,这类算法通过先验知识估算大气散射模型参数,然后通过反演得到去雾图像,这类算法受先验知识的约束,导致鲁棒性较差.
计算机硬件包括图形处理器(Graphics Process⁃ing Unit,GPU)和张量处理器(Tensor Processing Unit,TPU)的发展,加速了计算机视觉任务的处理速度,出现了许多图像处理方面的新型算法.近年来,基于深度学习的图像去雾算法对比传统去雾算法,效果得到了很大的提升,但是仍然存在颜色退化、纹理消失和光晕失真等问题.在真实世界中,图像场景的雾霾分布并非均匀,所以图像场景中物体的退化程度也有较大差异.对于这种非均匀雾霾图像,在去雾模型的设计中应该加入相应模块,注重处理不同空间的不同雾霾浓度和不同景深的不同色彩退化问题.以上问题可以采用多尺度模型和注意力机制来解决,例如文献[7]中采用多UNet 网络分别输出不同尺度特征再进行合并的方式实现多尺度特征提取,虽然该模型通过对图像不同空间尺度特征的分层整合来实现高级和低级特征的学习,但是使用这种方法采用大量的下采样和上采样操作,模型规模大,训练和运行时间较长.
综上,本文采用了一种新的深度学习体系结构,该体系结构采用了双层视觉特征提取及多尺度注意力特征融合.该模型采用生成对抗网络(Generative Adversarial Network,GAN)[8]架构,采用UNet3+[9]和金字塔特征融合模块构成生成器来提取复杂的雾霾特征,文献[9]中证明在保障相同的编码结构的前提下,UNet3+的参数量相比UNet 更少,并且UNet3+网络结合了多尺度特征,采用新的跳跃连接方式,并利用多尺度的深度监督,可以在更少的参数条件下,产生更有效的特征图.融合自注意力多尺度金字塔特征融合模块可以有效利用UNet3+网络所提取的不同尺度的空间信息,并提出了一种自注意力机制(Self Attention,SA)的改进方法,降低像素内部的高相关性在学习中的相互干扰,加大注意力特征图对总体特征分析的影响.
1 相关工作
本篇论文研究图像去雾方法,单幅图像去雾是一个不适定问题,因为测试数据不足,不能很好地学习雾霾图像的特征,不能较好地训练模型,而且去雾模型对于图像噪声十分敏感.根据大气散射模型,雾霾图像是由大气光、场景中物体的反照率和雾霾介质的透射图来确定.去雾过程中必须预测未知的透射图和大气光值,在过去,已经提出了许多方法来完成这一预测.这种方法可分为两类,即基于先验的方法和基于学习的方法.基于先验的方法依赖从图像中人工获取先验知识,利用额外的数学补偿来构建去雾的信息;基于学习的方法则利用神经网络直接学习无雾图像和雾霾图像之间的映射关系,实现端到端的输出.
Tan[10]在算法中加入马尔可夫随机场来最大化雾霾图像的局部对比度实现去雾.He 等人[3]提出了利用暗通道先验估计来预测大气散射模型透射图的方式实现去雾,之后改进暗通道的去雾技术不断出现,比如吴迪等人[11]提出的基于暗通道的快速图像去雾方法研究,肖进胜等人[12]提出的基于天空约束暗通道先验的图像去雾以及杨红等人[13]提出的基于暗通道的遥感图像云检测算法,等等.Fattal[14]基于对图像块在RGB 颜色通道中通常呈现的一维分布,提出了一种色线法.虽然传统算法在去雾方面取得了不错的效果,但还是存在局限性较大、鲁棒性较差的问题.
Cai 等人[15]提出去雾模型DehazeNet,首次利用卷积神经网络实现图像去雾算法.Zhang 等人[16]提出利用深层网络结构估计大气散射模型中的传输图以及大气光值,进而得到无雾图像.Ren 等人[17]提出了采用多尺度卷积神经网络的去雾算法(MSCNN),可以通过不同尺度的特征融合,提高去雾后图像的质量.Yu 等人[18]提出的基于马尔可夫判别器的图像去雾算法,可以通过在判别器中对比有雾图像和去雾图像的局部一致性,提高整体一致性.Qu 等人[19]提出了增强的Pix2Pix 模型,该模型之前广泛应用于图像风格迁移领域,该方法采用了一个带有增强器模块的GAN,以获得更有质量的生成图像,同时减少模型复杂度.近年来,基于学习的方法在图像去雾领域取得了重大的发展,本文算法实现的是一种基于学习的端到端去雾,网络模型直接生成去雾图像而省去了预测透射图和大气光值的步骤,并且提高了去雾后图像的质量.
2 本文模型
2.1 生成器
算法生成器结构如图1 所示,由双层UNet3+网络模块以及融合自注意力机制[20]多尺度金字塔特征融合模块组成,下面介绍不同模块细节.
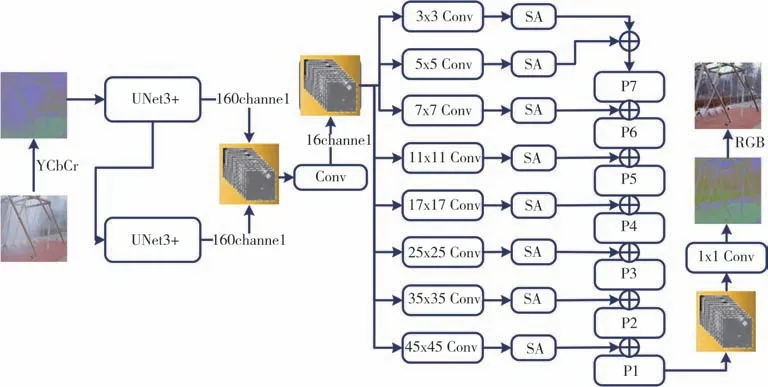
图1 生成器结构Fig.1 Generator structure
2.1.1 双层UNet3+网络模块
模块由两个级联的UNet3+网络单元组成,上一个网络单元的输出作为下一个网络单元的输入.两个UNet3+网络单元的输出合并起来提供一个320 个通道的特征图,下面的公式(1)、公式(2)描述该模块的工作方式:
式中:I1、I2分别为第1、2 个UNet 单元的输出;Ihaze为输入的YCbCr 空间雾霾图像.整个模块的输出为I,可描述为公式(3),其中⊕为按位求和.
模型将原始UNet3+网络的5 层结构增加为7层,关于UNet3+网络单元个数的选择会在之后的消融实验中介绍.下面讨论采用串联2 个7 层UNet3+网络的需求.
在图像特征分割的过程中,不同尺度的特征图展现不同的信息,低层次特征图捕捉丰富的空间信息,能够突出雾霾图像中内容的边界;而高级语义特征图则体现了内容所在的位置信息.在提取特征的过程中随着下采样和上采样操作,图像特征的传递会逐渐消减,而UNet3+网络充分利用多尺度特征,引入全尺度的跳跃连接(Skip Connection,SC)[9]结合了来自全尺度特征图的低级语义和高级语义,参数更少,并且进行深度监督(Deep Supervisions,Sup)[9],增加神经网络的深度和表征能力的同时,避免梯度消失和梯度爆炸等现象.深度监督分支还能够起到判断特征图质量好坏的作用,从全面的聚合特征图中学习层次表示.为了实现深度监督,网络中每一个解码器的输出先送入3×3 的卷积层,然后经过双线性上采样,目的是将第2、3、4、5、6、7 层得到的特征图上采样为全分辨率特征图,保证与第1 层相同,实现全尺寸监督,最后接一个Sigmoid 函数.相比采用4~5 个UNet 网络串联操作,或是UNet++网络,UNet3+网络在减少网络参数的同时也提高了计算和训练速度,还可以在特征提取的过程中产生更加具有层次和边界效应的特征图.
为了使UNet3+网络更加精确地提取图像的局部和全局信息,本算法将原始UNet3+网络的5 层结构增加为7 层,如图2 所示,图中E 代表编码、D 代表解码,7 层拼接融合形成224(7×32)通道的特征图.更多的层次可以带来更多不同尺度的特征信息.实际测试中,单独7 层UNet3+网络也可以得到不错的去雾效果,然而对于复杂的雾霾图像和不均匀雾霾图像,可能无法提取复杂的特征信息并生成相应的输出.为了解决这一问题,本算法采用的方法是增加UNet3+网络的个数进行级联,以便学习更加复杂的特征信息.随着层数的输入,单纯采用单网络架构会造成大量空间信息的丢失,而采用级联多个UNet3+网络的方式则可以减小这一问题带来的影响.每个UNet3+网络编码器下采样得到特征,解码器端将这些特征上采样到相同的高宽通道,多个生成器的组合有助于学习和保留更加复杂的空间信息.

图2 7层UNet3+网络Fig.2 7-layer UNet3+network
2.1.2 融合自注意力机制多尺度金字塔特征融合模块
由于经过级联UNet3+模块的特征图缺乏不同大小图像Patch的结构信息,所以在UNet3+模块之后加入多尺度金字塔特征融合模块.早期的金字塔结构被用来提取全局结构信息[21],本文则利用金字塔结构解决不同尺度结构信息不能直接用于生成预测图像的问题,具体原理如图3所示.

图3 特征融合示意图Fig.3 Feature fusion diagram
首先采用多个不同卷积核大小的卷积层得到对应不同空间尺度的结构信息,从而生成不同的输出映射.在模型中,不同卷积核的大小设为3、5、7、11、17、25、35、45,采用奇数卷积核可以使得输出像素周围的特征具有对称性,避免图像失真,并且采用零填充来避免边缘特征丢失.之后将金字塔卷积得到的不同尺度的特征经过SA 进入特征融合编码器进行特征融合,进一步将底层的语义信息和高层的语义信息进行结合,使得网络可以学习雾霾图像更加丰富的特征信息.经过特征编码器的特征图直接送入解码器,将特征解码为图像,得到输出图像.通过这种方式,局部和全局的信息都可以用于最终的图像重构.
使用多尺度金字塔特征融合模块的效果如图4所示,图中的矩形框选中不同大小卷积核所生成的图像部分特征,分别是3、11、25 卷积核,以展示输出特征图的细节特征.在下方的图中显示的是特征图映射为图像后的细节对比,通过多层金字塔卷积学习保留多尺度的空间信息.实验部分通过消融实验,证明该模块的有效性.

图4 3×3、11×11和25×25卷积层的特征映射Fig.4 Feature mapping of 3 × 3,11 × 11 and 25 × 25 convolution layers
对于单一雾霾图像去雾,图像内部的信息非常重要,所以本算法采用的方法是利用SA,减少对外部信息的依赖.由于传统的特征提取网络的感受野依赖卷积核的大小,所以在特征提取过程中会缺乏全局信息,丢失间隔较远像素之间的关联,而采用SA 则可以很好地解决这一问题.RGB 空间R、G、B 色之间存在高相关性,像素内部的高相关性会在学习中相互干扰,阻碍图像细节恢复.针对以上雾霾图像特征提取存在的问题,使用YCbCr 空间代替RGB 空间,减少高相关性的影响,增强注意力特征图对总体特征分析的影响,并提出改进的SA,提高对雾霾图像特征提取的有效性,具体改进方法如下:
1)为了降低像素内部的高相关性,增加图像细节恢复,数据处理阶段采用YCbCr 空间代替RGB 空间,YCbCr 颜色空间可以分割在RGB 颜色空间中难以分离的对象,进一步增强纹理细节恢复,具体方式为:
2)为了增强对雾霾图像不同雾度区域的特征捕获能力,在SA 模块中加入softmax 结构和expend 结构,通过增加模型宽度丰富细节信息,以达到对注意力模块的加强.
3)在经过以上两个操作之后,将改进的SA 模块加入模型,在降低像素内部的高相关性的同时,增强对雾霾图像不同雾度区域的特征捕获能力,具体改进后SA的结构如图5所示.
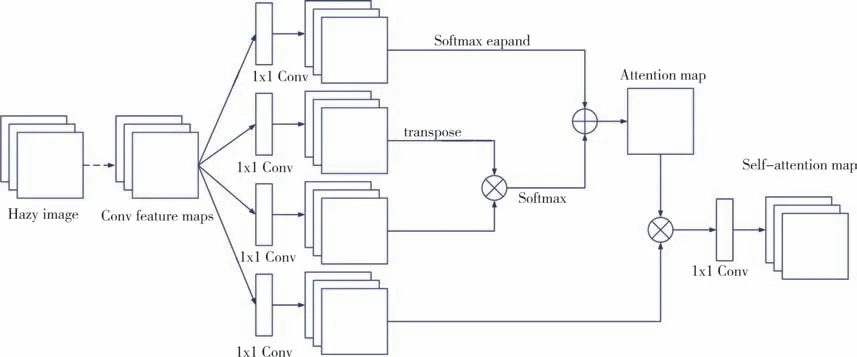
图5 改进自注意力机制结构图Fig.5 Improved self-attention mechanism structure diagram
2.2 判别器
判别器采用马尔可夫判别器,整体完全由可以学习的卷积层构成,通过对最后输出矩阵取均值输出.输出矩阵的每一位代表原图像的一个感受野,这样对于图像清晰化有一定的高细节保持.判别器整体采用4×4 的卷积核,每一个整体由一个Spectral⁃norm 层、一个4×4 的卷积层和一个LeakyReLU 激活层组成,而最后一块加入SA,通过Sigmoid 函数得到输出映射,具体结构如图6所示.

图6 判别器结构Fig.6 Discriminator structure
2.3 损失函数
在损失函数的选择上,采用可以在功能上接近人类感知的损失函数,包括对抗损失函数[22]、L2 损失函数[23]、感知损失函数[24]以及结构相似损失函数[7],通过多损失函数的组合更好地对模型进行约束.生成对抗网络损失可以描述为:
式中:D为判别器;G为生成器;x为输入的雾霾图像;y为与雾霾图像对应的清晰图像;E为计算所得到的数学期望.
L2损失函数体现了清晰图像与预测图像之间的差值平方和,可描述为:
式中:IGT为清晰图像;Ipred为预测图像.
感知损失函数设计基于VGG-19 网络,将真实的清晰图像卷积得到的特征与生成器生成的图像卷积得到的特征进行比较,使得图像的全局结构更加接近,生成的图像和目标图像通过不可训练的VGG网络传递,可描述如下:
式中:C、W、H分别为输出的通道、宽度和高度;V为非线性CNN 变换,由VGG 网络执行,对于Pool-4 层的输出,可以近似为1e-5;这一损失函数本质就是使用F2 范数计算清晰图像和预测图像通过VGG 网络处理后的平方加标准化.
结构相似性(SSIM)损失函数对应预测图像与清晰图像之间的结构差异,可描述如下:
式中:SSIM 为清晰图像与预测图像之间的结构相似性指数.
以上损失函数中,L2 损失和感知损失具有同样的形式,但是感知损失的计算空间转换到了特征空间.L2 损失和结构相似损失都是对预测图像和清晰图像的直接比较,L2损失对结构细节并不敏感,而结构相似损失重点对比图像的结构内容,所以拥有互补的性质.
最后将所有的损失函数加权组合,生成器和判别器的损失分别如下所示:
式中:A、B为变量权重,其值分别设置为A1=0.7、A2=0.5、A3=1.0、A4=1.0、B1=1.0.
3 实验与结果
3.1 数据集
为了避免其他去雾文献中只采用人工合成雾霾图像且只存在均匀雾霾的情况,本文基于VOC 数据集,采用引导滤波生成大量的不均匀雾霾数据,加入NTIRE-(2020+2021)非均匀去雾挑战数据集[25-26]、NTIRE 2018 图像去雾室外数据集(O-Haze)[27]和Dense-Haze浓厚雾霾数据集[28]进行训练和测试.
O-Haze 数据集包含35 张图像用于训练,5 张图像用于测试;NTIRE-(2020+2021)数据集包含45 张图像用于训练,15 张图像用于测试;人工基于VOC数据集合成数据集,这个数据集包含2 000 张图像,用于预训练网络权值,图7 展示了部分合成的不均匀雾霾图像.Dense-Haze 数据集是其中最具有挑战性的,很多先进的去雾算法在这个数据集中的表现都欠佳,虽然本算法在该数据集上的性能相比其他数据集而言较差,但是定量比较指数优于所对比的先进算法,从定性的比较可以看出,由于Dense-Haze数据集场景的雾霾十分稠密,所以很多方法几乎不能有效生成清晰图像,但本算法可以实现有效去雾,表现出场景中的细节,但是仍然存在一定的色差问题,与实际清晰图像存在一定的差异.人工合成数据集主要用于迁移学习中对网络的参数进行预训练,其他标准数据集均在训练数据集进行训练,在测试数据集进行测试.由于标准数据集中的图像数量较少,因此在训练过程中采用了随机角度翻转、随机裁剪、水平翻转、垂直翻转等数据增强方法.

图7 部分合成不均匀雾霾图像Fig.7 Partially synthesized uneven hazy images
3.2 训练细节
训练使用Adam优化器[29],初始的生成器和判别器学习率均为0.000 1.采用人工合成数据集对网络进行预训练,在对标准数据集进行训练之前,采用迁移学习的方式将预训练权重载入网络模型.标准数据集中图像大小为1 600×1 200×3,导致训练出现GPU 显存不足,因此采用双三次插值算法将图像大小调整为512×512×3.而文献[30]提出,雾霾图像在YCrCb 空间相较于RGB 空间对去雾过程的影响更小,特别是对于Cr、Cb 两个色度通道,因此将图像由RGB 空间转换到YCbCr 空间进行训练,提高色彩恢复效果.通过实验测试,最终确定预训练过程一共进行20 轮,标准数据集训练一共进行500 轮,500 轮之后损失不再有明显降低.其中前300 轮采用初始学习率,后200轮每100轮生成器学习率降为原来的一半,提高网络收敛性.
3.3 实验结果对比
本小节对本论文模型和引用文献中其他算法模型的结果进行比较,将所有测试图像的大小转换为512×512×3,定量的评价采用峰值信噪比(PSNR)[31]和结构相似性(SSIM)[32]进行度量.测试以人工合成数据集、O-Haze 数据集、NTIRE-(2020+2021)数据集以及Dense-Haze 数据集的测试集为标准,对比算法的介绍如表1所示.

表1 对比算法详情Tab.1 Comparison algorithm details
3.3.1 人工合成数据集测试
为了验证提出算法模型去雾的有效性,该测试环节选用CVPR’16[4]、BPPNET[7]、CVPRW’18[21]、CGAN[33]进行对比实验.从表2 的定量比较中可以看出模型平均PSNR 和SSIM 分别为30.31、0.958,且均优于所对比的先进算法.对测试数据的定性比较如图8 所示,可以看出本文模型去雾之后的结果更加符合人眼的视觉体验,包括灯光、物品细节以及清晰度,而其他算法在去雾效果上明显存在缺陷,无论是灯光的观感还是细节的恢复.但由于人工合成数据集主要作用是迁移学习而预训练网络权重,因此其对比试验不是本次实验的重点.
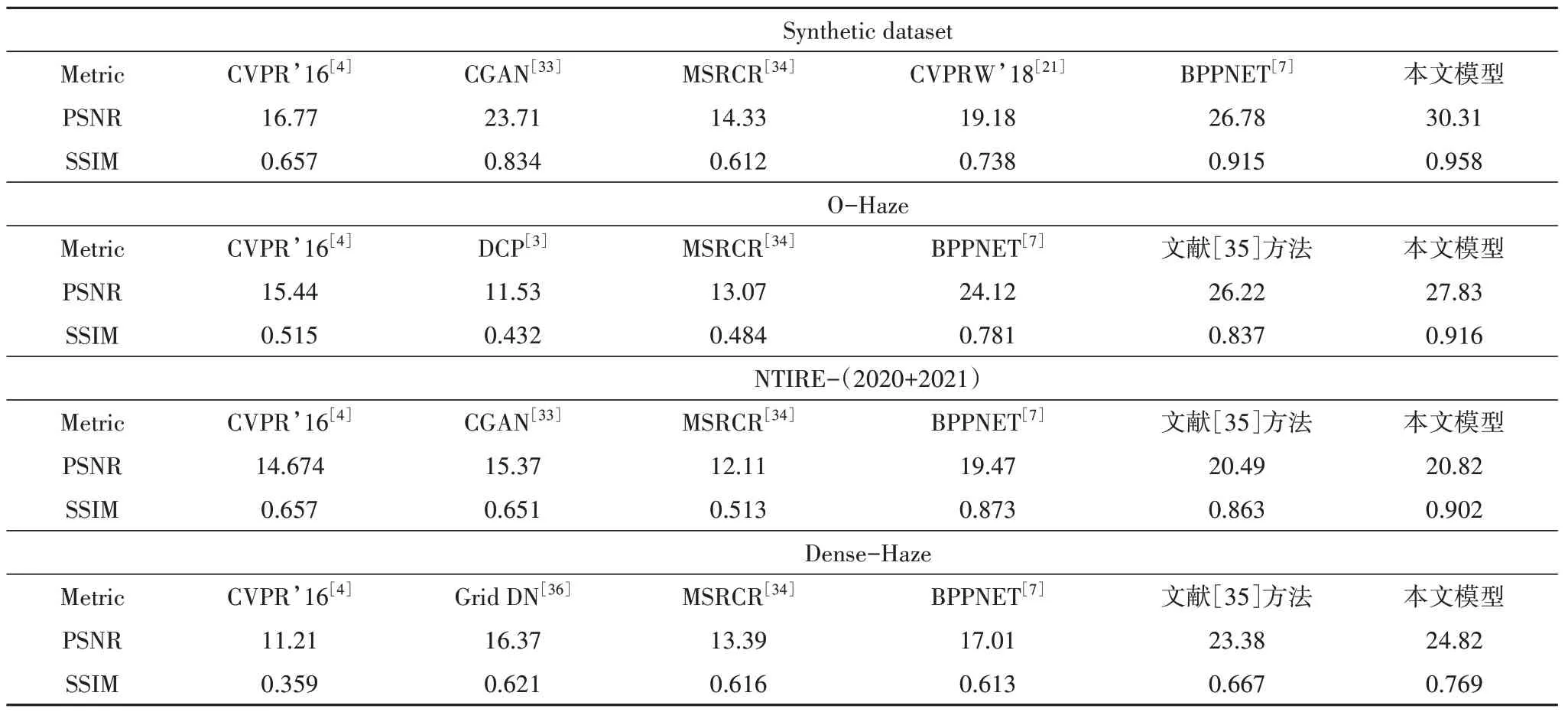
表2 测试集上进行的定量分析结果Tab.2 Quantitative analysis results on test datasets

图8 人工合成数据集上,将各种模型与本文模型进行定性比较Fig.8 Qualitative comparison of various models with this model on synthetic dataset
3.3.2 标准数据集测试
标准数据集测试主要针对O-Haze 数据集、NTIRE-(2020+2021)数据集以及Dense-Haze数据集的测试集.选用传统方法DCP[3]、CVPR’16[4]、MSRCR[34]和基于深度学习的方法BPPNET[7]、CVPRW’18[21]、文献[35]方法、Grid DN[36]网络模型进行对比.
O-Haze:本文模型在测试数据集上的平均PSNR和SSIM 分别为27.83、0.916.从表2可以看出本模型的PSNR 和SSIM 指数优于其他对比的先进算法.由于I-Haze 数据集属于室内雾气图像且难度低于O-Haze 数据集,因此本次测试没有进行该数据集的测试.实验在O-Haze 数据集上的定性比较如图9所示.
NTIRE-(2020+2021):本文模型在测试数据集上的平均PSNR 和SSIM 分别为20.82、0.902,从表2可以看出本文模型在PSNR 和SSIM 指数方面优于对比的其他先进算法.实验在该数据集上的定性比较如图9所示.

图9 NTIRE-(2020+2021)数据集和O-Haze数据集上,将各种模型与本文模型进行定性比较Fig.9 Qualitative comparison of various models with this model on NTIRE-(2020+2021)dataset and O-Haze datasets
Dense-Haze:该数据是所测试数据集中最具有挑战性的,与O-Haze 数据集和NTIRE-(2020+2021)数据集相比,由于不均匀稠密雾霾导致大多数先进的去雾方法在这个数据上的表现都不尽如人意,有的效果甚至很糟糕.本文方法在该数据集上表现虽然弱于O-Haze 数据集和NTIRE-(2020+2021)数据集,但是从表2 可以看出,PSNR 和SSIM 平均值仍然优于所对比的其他先进算法.实验在该数据集上的定性比较如图10 所示,增强之后图像的细节清晰度低于O-Haze 数据集和NTIRE-(2020+2021)数据集,但相比于其他算法,只有文献[35]网络的结果与本算法接近,但是从图像中的细节表现可以看出,本算法在一些场景的细节以及色差控制方面要好于文献[35]网络.

图10 Dense-Haze数据集上,将各种模型与本文模型进行定性比较Fig.10 Qualitative comparison of various models with this model on Dense-Haze dataset
3.4 消融实验
为了验证模型中不同模块在实际去雾表现中的有效性,使用NTIRE 和O-Haze 数据集进行消融实验.通过以下不同模型进行消融实验:1)首先考虑不同UNet3+网络模块对于去雾结果的影响,模型A 表示采用一个UNet3+网络,模型B 表示采用三个UNet3+网络;2)考虑融合自注意力机制多尺度金字塔卷积特征融合模块的存在对于模型结果的影响,模型C 表示去除该模块;3)考虑预训练数据集对于模型结果的影响,模型D 表示取消加载预训练权重;4)考虑改进SA 对模型结果的影响,模型E 表示采用原始SA 方法;5)考虑使用YCbCr 空间进行训练对结果的影响,模型F表示采用RGB 空间训练网络.定量比较、定性比较结果如表3和图11所示.

图11 消融实验定性比较Fig.11 Qualitative comparison of ablation experiments

表3 消融实验的定量分析结果Tab.3 Quantitative analysis results of ablation experiment
从结果对比可以很明显看到:1)减少UNet3+模块的数量会降低性能,而增加模块数量并不能带来较大的性能提升,所以2 个UNet3+模块是最终的选择;2)删除金字塔卷积特征融合模块会使性能严重降低,图像产生模糊不清的情况,细节恢复较差;3)从定量比较中可以看出预训练权值能有效提高网络的PSNR 指数和SSIM 指数,从定性比较中也可以看出不加载预训练权重的情况下也出现了色差问题;4)采用原始SA 得到的结果与改进SA 在视觉效果上十分接近,但从定量比较仍然可以看出改进SA 所得到的评价参数值更高;5)采用RGB空间训练网络,在NTIRE 数据集上,SSIM 指数与采用YCrCb 空间训练网络的结果持平,但PSNR 指数相较于YCrCb空间训练网络在测试数据集上都有明显的下降,定性比较中可以看出采用RGB空间所得到的清晰图像色彩更为深沉,视觉效果差距不大.上述消融实验表明,网络设计过程中考虑的每个因素在网络最终性能中都起着至关重要的作用.
4 结论
本文所提出的基于双层视觉及多尺度注意力融合的图像去雾算法,可以实现端到端的去雾,并且通过实验证明了算法在去雾任务中的强大能力,适用于室内、室外、密集和不均匀雾霾图像去雾等多种情况.算法针对雾霾图像的特点改进了自注意力机制结构,证明了改进的有效性.实验中采用的标准数据集规模较小,但仍取得了良好的效果,证明算法在小规模数据集上的显著优势.通过测试可以看出算法在所测试的数据集中的表现都超过了所对比的其他先进算法,在Dense-Haze 数据集上的峰值信噪比和结构相似性指数分别达到24.82 和0.769.实验还采用了大规模数据集来预训练网络权重,证明了预训练网络参数在图像去雾领域的有效性.算法存在的不足主要体现在稠密雾霾图像去雾后存在的色差问题,未来可以加入色彩恢复相关损失函数或者归一化方法来提高模型对于色差的控制力度,来达到更好的效果.
