基于改进YOLOv5 的露天矿山目标检测方法
2023-03-08秦晓辉黄启东常灯祥刘建胡满江徐彪谢国涛
秦晓辉 ,黄启东 ,常灯祥 ,刘建 ,胡满江 ,2,徐彪 ,2,谢国涛 ,2
(1.湖南大学 机械与运载工程学院,湖南 长沙 410082;2.湖南大学无锡智能控制研究院,江苏 无锡 214072;3.潍柴智能科技有限公司,山东 潍坊 261000)
矿产资源是工业发展的基础,而采矿业目前面临着成本高、效率低和风险大的问题.2019年中国国际矿业大会在《全球矿业发展报告2019》中指出,科技创新正在引领传统矿业转型升级,加速向绿色、安全、智能、高效方向发展[1].除了国内正在加速发展智慧矿山,国外也在稳步发展.2021 年起,世界第二大采矿业集团力拓公司计划在皮尔巴拉的Koodaideri铁矿山耗资26 亿美元打造第一个智慧矿山[2].在智慧矿山技术的组成中,自动驾驶是不可或缺的部分,但是目前针对智慧矿山自动驾驶的研究仍不成熟.
自动驾驶感知传感器主要包括毫米波雷达、激光雷达和相机.毫米波雷达分辨率低,易引发目标漏检.激光雷达在较远处点云稀疏,无法有效识别障碍物并判断类型,同时由于激光点云无法穿透扬尘,在扬尘环境下易产生误识别.而图像具有分辨率高和像素信息丰富的特点,可兼顾远处目标和扬尘的识别.同时,随着GPU 硬件的飞速发展,基于深度学习视觉目标检测已经得到了广泛应用[3-4].
基于深度学习的方法,其检测模型需要大量的应用场景数据.但智慧矿山提出以来,露天矿山方面的目标检测数据集依然比较少,针对这方面研究更是不多.齐凡[5]在露天矿山中采集了916 张图像,在这些图像中矿卡目标共有786 个,行人目标共有263个,此数据集样本较少,训练的模型泛化能力不足.齐凡[5]基于Mask R-CNN 模型修改主干网络ResNet50 的C5 层,将C5 层的3×3 卷积全部替换为空洞率为2 的空洞卷积.此方法提高了该层卷积的感受野,且矿山中的目标大多数为大中目标,因此利用此方法有效提高了检测精度.Improved Tiny-Yolov3[6]在主干网络的部分层中加入类似于ResNet的Bottleneck 和残差结构,以提高模型的学习能力,减少特征在传递时的丢失,在增加很少检测时间下提高模型的检测精度.
虽然以上学者在精度上有了一定的提升,但上述方法最快速度只有23FPS,在速度上无法满足自动驾驶30FPS 的实时性需求.目前,基于深度学习的实时目标检测已经有了很大的发展.在实际应用中使用较多的是YOLOv3[7]、YOLOv4[8]和YOLOv5[9],以上都是先通过主干网络直接提取不同层级高级特征,然后使用多级融合网络将位置信息和高级语义信息充分融合,最后利用回归的方法实现目标检测.但是,YOLO系列的模型对数据集中的小目标的检出率与大中型目标相差较大.因此,有很多学者针对该问题提出了多种解决办法,大致可以分为三种.第一种方法是从模型的检测尺度出发,模型中上层特征包含了许多细节信息,所以该方法通过额外增加浅层检测尺度达到提高小目标检测精度的目的[10-12].第二种方法是增加网络的感受野,一般使用空洞卷积来实现[13-14].第三种方法是通过注意力机制引导网络关注小目标的信息[15-17].然而这些改进方法忽略了下采样对模型检测精度的影响.
近年来一些工作对卷积网络中的下采样进行了优化,比如文献[18]认为池化下采样和步长为2 的卷积下采样会减弱卷积的平移不变性并且会产生严重的锯齿,不符合Nyquist-Shannon 采样定理.因此提出先使用步长为1,卷积核大小为3×3 的卷积来保证平移不变性,再使用固定的模糊核实现抗锯齿.论文最后发现采样该方法有更好的特征提取能力,且对噪声和翻转等有较好的适应.TResNet[19]也采用这种方法,但其在具体实现上采用PyTorch 预编译的方法加速GPU 计算,显著降低了计算成本.虽然,这些方法可以提高网络的特征提取能力,但是在矿山目标检测上并不能很好地适应,而且他们都没考虑到特征图每个点的利用率.
同时,这些学者在模型训练中的分类损失函数使用交叉熵(Cross-Entropy,CE)损失或二值交叉熵(Binary Cross-Entropy,BCE),定位损失函数采用smooth L1 范数损失或IoU(Intersection-over-Union)损失[20-21].采用解耦方式,分别对两个任务进行优化,但目标检测的最终结果由分类和定位共同决定.因此,本文以YOLOv5S 为基础网络架构,改进下采样,解耦Head 和优化损失函数,以得到高精度的实时检测模型.
本文主要贡献如下:
在露天矿山场景下采集并标注了包含乘用车辆、工程车辆、矿区运载卡车和行人的露天矿山自动驾驶数据集.
分析现有下采样方式对特征利用不平衡的原因,并使用不同的填充方式改进下采样.此外,引入attention机制使得两种特征更好地融合.
将预测Head 解耦成三个独立的分支,分别预测box、cls和obj.
探究当前损失函数的弊端并加以改进,提出使用定位与分类相互耦合的方式进行损失计算.
1 露天矿山目标检测算法设计
1.1 模型结构
实际工程应用中网络模型所部署的计算设备算力较低,为权衡速度和精度,本文基于YOLOv5 的架构,根据现有目标检测算法的缺陷以及露天矿山环境的特点,提出了如图1 所示的目标检测算法框架.该框架共由四个部分组成,分别是主干网络(Back⁃bone)、瓶颈网络(Neck)、头部网络(Head)和训练推理.1)为解决YOLOv5 及其他算法中的下采样对特征利用不平衡的问题,优化主干网络的卷积下采样结构,避免特征丢失,同时实现特征的平衡利用.因此本文使用模型的主干网络是CDDPP-CSPResNet,其在YOLOv5S 的CSPResNet[22]的基础上改进P2-P5层的卷积下采样层,具体结构将在下一小节分析.2)为充分融合高层特征和低层特征,瓶颈网络部分使用PANet[23]的特征融合方式.头部网络部分使用三个独立的分支(Trident Head,TH),这使得每个分支都可以关注自己的任务.3)多任务共享头部网络是大多数算法的选择,但由于不同任务对头部网络有不同的需求,因此本文提出了解耦的头部网络,即每个任务都有独立的头部网络.同时为了降低Head部分的卷积计算量和参数量,本文使用Bottleneck 结构减少中间层的通道数,并且利用参数R控制缩减程度,本文中R=2.
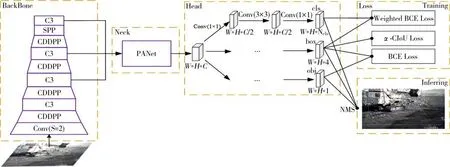
图1 模型结构Fig.1 Model structure
1.2 下采样优化
下采样是卷积神经网络在处理图像时常用的步骤.实现这个步骤一般有两种方法,分别是池化和卷积.
例如ResNet 采用池化核大小为3×3、步长为2 的池化,以及卷积核大小为3×3、步长为2 的卷积进行下采样.但这两种方法都存在对特征点利用不平衡的问题.为便于解释这一问题,本文使用一维向量作为示例.在图2 中,输入向量长度为8,为了得到下采样后长度为4 的输出向量,需要在输入向量的边缘进行零填充.由公式(1)计算可知,卷积核大小为3×3、步长为2 的卷积需要的padding 为1.而padding一般填充在输入向量的左边,即a 位置.如图3 所示,左侧填充导致对输入向量每个位置的利用次数不一致.引发该结果的原因是下采样填充位置的选择,如果把填充位置改为输入向量的右边,即b 位置,那么结果恰好相反.
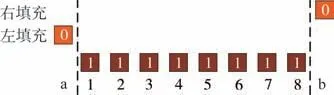
图2 不同填充方法的卷积下采样Fig.2 Convolutional downsampling with different padding methods

图3 左右填充位置的特征元素使用统计Fig.3 Feature element usage statistics of left and right padding positions
式中:in 是特征图输入大小;padding 是填充大小;k是卷积核大小;S是步长;out是特征图输出大小.
YOLOv5使用有缺陷的下采样方式,会使得下采样时对每个点的利用率不同.并且在矿山这一场景下,目标尺度相差很大,行人类小目标易丢失大量信息,导致网络无法同时兼顾大目标和小目标特征提取.为了保证特征图每个点都能得到同样的利用次数,可以使用不同的填充位置进行下采样,然后将多组结果进行整合.
本文提出使用两个分支实现下采样,如图4 所示.首先,每个分支经过卷积核大小为3、步长为2、padding为1的卷积下采样得到xds.
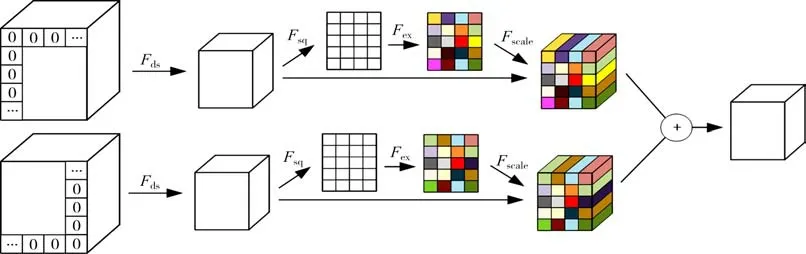
图4 不同填充位置的卷积下采样(CDDPP)结构Fig.4 Convolutional downsampling structure with different padding positions(CDDPP)
第一个填充位置是二维特征图的上面与左边,第二个分支的填充位置是二维特征图的下面和右边.xds由公式(2)计算得到.
式中:输入张量x∈RC×H×W;*表示卷积操作;卷积权重W∈R3×3×C×C;BN 和σ分别是Batch Normalization以及SiLU激活函数.
其次,由于两个分支选择不同的填充位置,下采样后会产生特征偏移,所以本文采用空间注意力机制计算每个分支特征图上各点的权重.特征图上每个空间位置的权重可由公式(3)和公式(4)计算得到.
式中:Concat是在通道上的拼接操作.
将各分支权重和对应的卷积结果相乘,并将相乘结果各元素相加,获取式(5)所示的下采样结果:
1.3 损失优化
在YOLO 系列模型中,预测cls 和box 的损失计算只针对正样本,即优化对象是一致的,但采用解耦方式分别独立计算损失.从图5 中可以看出,图中的红色预测框中大部分是矿区运载卡车,少部分是工程车辆.若按照以前的损失计算,则认为这个预测框类别是矿区运载卡车,即矿区运载卡车概率P=1,这显然是不合理的.本文参考Focal Loss[24]给不同难度样本加权的思想,提出使用IoU 对cls 损失进行加权.其中IoU 是通过预测box 与真值box 之间计算得到的.分类cls的BCE损失计算公式如式(6):

图5 预测框中有不同的目标Fig.5 There are different objects in the prediction
式中:类别真值y∈{0,1};模型正确预测概率p∈[0,1].
权值可由公式(7)计算得到,IoU 与权重的对应关系如图6所示.

图6 IoU和权重对应关系Fig.6 Correspondence between IoU and weight
公式(7)中的IoU 采用α-CIoU[25]计算,计算公式为:
式中:ρ(b,bgt)是两个框中心点的欧氏距离;c是两个框最小闭包矩形的对角线距离.
最后,分类cls 的加权损失(α-CIoU Weighted BCE Loss,WBL)如式(11):
2 露天矿山数据集构建
本文采集了矿区运载卡车的前视角相机在露天矿山的RGB 图像,图像分辨率为1 280×720.数据集共有12 012 张图像,包含4 个类别,分别是乘用车辆(Car)、工程车辆(Engineering Vehicle,EV)、矿区运载卡车(Mining Truck,MT)和行人(Pedestrian).图7展示了4 个类别的示例.该数据集共有32 476 个矩形框,每个类别的矩形框的统计如图8 所示.与其他自动驾驶数据集一样,为丰富数据集多样性,本文采集了白天和晚上两个不同光照强度的场景.

图7 不同类别的示例Fig.7 Examples of categories
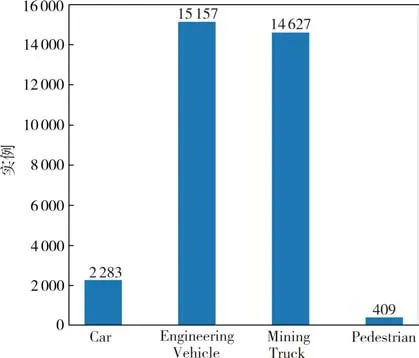
图8 数据集不同类别的实例分布Fig.8 Instance distribution of different categories
3 试验验证
3.1 训练环境和方法
本文将数据集按照7∶1∶2 比例划分为训练集、验证集和测试集.模型训练设备的GPU 是NVIDIA Geforce Titan X×4,CUDA 10.1,Pytorch 1.7,部署设备GPU是NVIDIA Geforce 1050Ti.
在所有的试验中,模型的输入分辨率为640×640,使用Warm Up 和余弦退火的学习率衰减,初 始学习率为0.01,优化器为SGD(Stochastic Gradient Descent).试验中还使用了mosaic、随机水平翻转、随机缩放平移和色彩抖动的数据增强方法.
3.2 消融试验
在第1 节中本文对YOLOv5 所使用的定位损失函数和分类损失函数分别进行了替换和改进.除此之外,本文还提出了基于YOLOv5S 的改进结构,包括对下采样和Head 的算法结构改进.为此,本文开展了下列试验,以验证所提出的改进方法对模型性能的影响.
3.2.1 损失函数
从表1 中可以看出,在YOLOv5S 基础上将原来的CIoU 替换成α-CIoU,可以增加0.9%AP 和1%AP50,且在推理成本上无任何的额外增长.同时,把原来的BCE分类损失替换成WBL,AP还可以增加6.5%,AP50增加4%.

表1 不同改进方法的检测精度Tab.1 Accuracy of different improved methods
3.2.2 下采样
本文把YOLOv5S 主干网络中的4 个下采样模块替换成CDDPP,替换后模型的计算量相对于YO⁃LOv5S 增加了1.65G MACs,参数量增加了1.53 M.表1 的试验结果表明,模型使用CDDPP 替换下采样后,AP 进一步提升1%,AP50提升0.4%.为了继续验证CDDPP结构的有效性,本文还做了对照试验.对照试验保持CDDPP 的结构,只修改两个分支的填充方式,保证有相同的填充方式.从表2 中可以看出,对照试验对原模型也有一定的提升,且在此基础上使用不用填充方式可再提升0.5%AP.
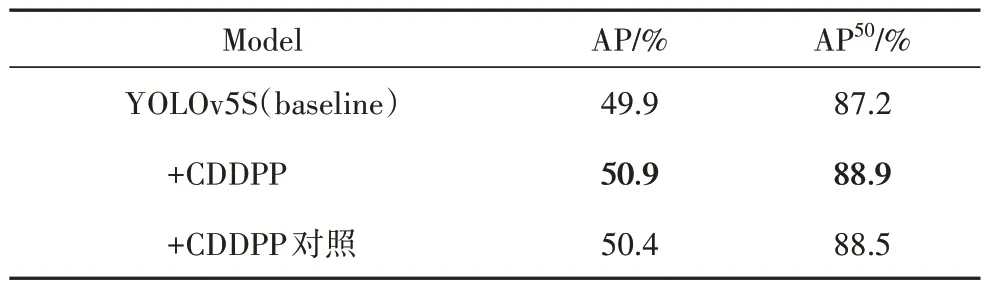
表2 CDDPP消融实验Tab.2 Ablation experiment of CDDPP
从表3 可以看出,行人(Pedestrian)类小目标相较于没有CDDPP 结构的模型提升了1.8%,其他类目标都有小幅度提升.
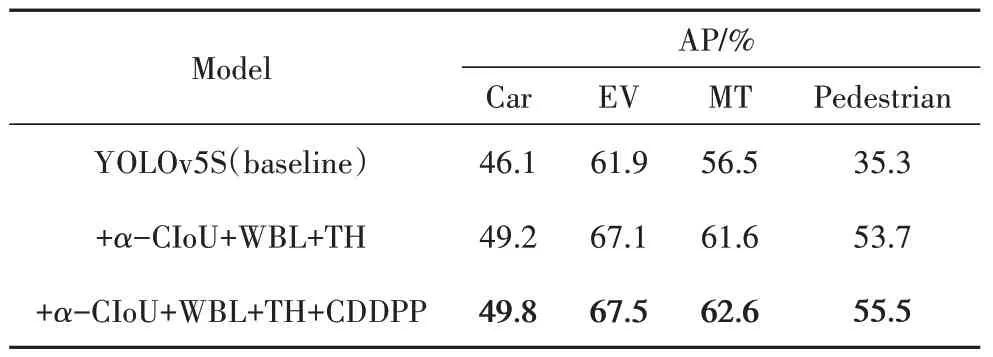
表3 不同类别的检测精度Tab.3 Accuracy of different categories
3.2.3 检测速度
表4 展示了改进后的模型在部署设备上的计算速度是40FPS,依然可以达到实时的检测速度.同时,与YOLOv5的大模型L相比,速度提升约4.5倍.

表4 不同模型的检测速度Tab.4 Inference speed of different models
本文将所有改进点集成到同一模型上,得到了增强型实时检测模型,并命名为YOLOv5s-Enhanced.表5 是该模型与目前的先进模型的对比,可以看出在精度和速度上,YOLOv5s-Enhanced 依然具有明显的优势.

表5 YOLOv5s-Enhanced与先进模型的对比Tab.5 Comparison between YOLOv5s-Enhanced and ad⁃vanced models
4 结论
针对当前矿山无人驾驶落地方案中难以识别障碍物类型以及准确识别远距离障碍物的问题,本文提出了基于深度学习的视觉目标检测方法.并针对矿山场景下目标尺度跨度大的特殊性,提出了CDDPP 下采样方法,它使用不同的填充方法和空间注意力模块解决传统下采样丢失特征的问题.同时,改进预测Head,让每个分支专注自身任务.并且优化分类和定位损失计算方法,耦合定位和分类任务.试验结果表明,本文的方法在精度方面优于YO⁃LOv5S 和YOLOv5L 模型,且速度依然满足实际应用需求.虽然,本文提出的方法可以显著提高模型检测精度,且在部署设备上实现实时检测.但当前的工作仍不完善,后续将在恶劣天气下的露天矿山中继续测试和优化.
