一种单样本农作物病害识别方法
2023-03-07任维鑫曹新亮白宗文
任维鑫,曹新亮,白宗文
(延安大学 物理与电子信息学院,陕西 延安 716000)
0 引言
农作物发生病害会严重破坏其正常生理机能,极大减少产量,因此,农作物病害的识别、检测和预警是保证农作物产量稳定、保障农民收益的重要手段。传统的农作物病害识别主要依靠农业专家实地考察,随着人工智能尤其是深度学习的快速发展,农作物病虫害识别的相关研究也逐步进入新阶段。目前,已经有许多研究成功地将深度卷积神经网络应用到农作物病虫害识别领域[1-6],并在其数据集上取得了相对理想的准确率。虽然已经有许多研究者着手构建农作物病害数据集,但是现有数据集依然很难满足基于传统深度学习的病害识别方法对数据量的需求,无法保证模型的通用性和泛化性。究其原因,一方面农作物病害数据集与自然场景数据集不同,自然场景下的通用数据集可以借助网络等设备快速地收集与标注,但是农作物病害数据集由于其标注时需要许多专业知识,往往需要农业专家才能完成标注,这无疑会导致较高的人力物力成本;另一方面,农作物病害呈现种类多、单类样本偶发,甚至有些病害发病与地域呈现强关联性的特点,这导致构建一个巨大的、具有百亿规模的、种类丰富完备的农作物病害数据集是十分困难的。因此,从小样本检测的视角出发研究解决农作物病害识别问题的方法具有非常重要的实际应用意义。虽然已经有研究者在这方面取得了一些进展[7],但主要是基于微调的方法,这种方法在极少样本的情况下性能有所下降,且推理时需要通过微调更新模型参数。本文主要针对这一问题,开发了一种基于孪生网络的度量学习方法,以解决单样本农作物病害识别问题,该方法具有推理时需要特定病害样本量小、不用更新模型参数的优点。
1 少样本学习与对比学习
人类可以从很少的样本中学习,但机器从少样本中学习的能力与人的差距依然非常大,深度学习框架对于数据与算力有着海量的需求,在少样本任务上,最先进的深度学习方法甚至不如简单的机器学习模型。研究着重关注少样本学习中的少样本分类问题,对于少样本分类,有以VBF[8]为代表的基于生成模型的方法,寻求借助中间变量z对后验概率p(x|y)进行建模;有基于判别的方法,直接为少样本分类任务T建模后验概率p(x|y);最直接的方法就是使用任务T的数据训练神经网络模型。但是由于T的数据太少,这种方法一般容易陷入过拟合。第2种是基于度量学习[9],通过在辅助数据集DA上学习一个相似性度量S(·,·),从而迁移到任务T上。第3种是基于元学习的方法[10-11],它利用DA构造许多类似于任务T的任务,并采用跨任务训练策略提取一些可转移的模型、算法或参数。其中,Snell等[10]的方法可以看做是度量学习与元学习的结合,同时它也可以被理解为对比学习,其核心思想就是吸引正的样本对,排斥负的样本对,该方法是采样同类样本作为正样本对,不同类的作为负样本对。而另一种是基于自监督的对比学习方法[12-15],这种方法通过将每幅图像看作不同的类别,一副图像的多张数据增强图像为同一类,与其他图像以及其他图像的数据增强图像为不同类,从而构造类别标签以监督模型训练。Tian 等[16]揭示了在少样本学习任务中一个好的嵌入是非常重要的,并基于此构建了不基于元学习框架且不用微调的少样本分类基线。 Chowdhury等[17]使用一组预训练的嵌入模型作为特征提取器库,使用微调的方法达到了很好的跨域迁移少样本分类效果。Wang等[18]发现了使用交叉熵损失的监督学习模型,其迁移性能不如自监督学习模型的原因是交叉熵损失监督的模型在特征提取之后没有使用MLP进行特征映射,基于此观察,构建了迁移性能更好的监督学习模型,并在少样本分类任务上进行验证。
2 方法
2.1 任务设置
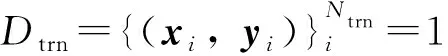
2.2 算法
2.2.1 模型与损失函数
本文所提出的框架结构如图1所示。将来自图像x的2个随机数据增强的视图xa,和xb作为孪生网络的输入。这2个视图由主干网络(使用卷积神经网络)和MLP实现的投影器组成的编码器网络f处理。编码器f在2个视图之间共享参数。MLP实现的预测器h将一个视图的输出变换到另一个视图域。分类头c作为训练辅助器的角色存在,具体地,在训练过程中,经过编码器f处理之后的2个视图的特征还会送入分类头以获得类别向量,推理时分类头将被舍弃。训练与推理的实现细节将在2.2.2节予以说明。

图1 模型架构Fig.1 Model architecture
对于相似性匹配,使用余弦相似度作为度量。具体地,将2个输入向量表示为p1=h(f(xa))和z2=f(xb),p2,z1同理。使用自监督的对比学习和基于构造监督标签与二值交叉熵的距离损失2部分进行优化。
在对比学习部分,最小化其负余弦相似度加常数项:
(1)
式中,‖·‖为l2归一化,该式值域为[0,2]。与BYOL[14]和SimSiam[15]一致,构造对称损失:
(2)
在batch维度上对每一对样本使用该公式并在batch维度上取平均值作为总损失。
和SimSiam一致,对比学习中对孪生网络的其中一支使用停止梯度操作,则将式(1)修改为:
D(p1,stopgrad(z2)),
(3)
式中,stopgrad()表示停止梯度操作,这意味着z2在这一项中被当作常数。类似地,式(2)被修改为:
(4)
从表达式看,L1损失只拉近正样本之间的距离,未能拉远正样本与负样本之间的距离,对比学习的经典方法MoCo[12]和SimCLR[13]的对比损失都有拉远正样本与负样本之间距离的能力,但MoCo引入了动量编码器组件,SimCLR需要大批量才能正常工作,对显存有极高的要求。为了使损失具有拉远正负样本之间距离的能力且不引入其他限制,本文设计了基于构造监督标签与二值交叉熵的距离损失。
为了与对比学习损失更好地兼容,基于构造监督标签与二值交叉熵的距离损失依然沿用余弦相似度作为距离度量,考虑映射函数σ,使得σ(D(·,·))的值域空间落入[0,1],简便起见,取σ为常系数0.5。
此外,设计出shuffle和equal两个组件,具体为:
z3,z4,y′=shuffle(z1,z2,y)。
(5)
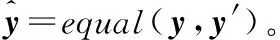
(6)
综上,基于构造监督标签与二值交叉熵的距离损失被表示为:
a=σ(D(p1,stopgrad(z4))),
(7)
(8)
b=σ(D(p2,stopgrad(z3))),
(9)
(10)
(11)
Tian 等[16]证明了使用交叉熵损失对模型进行监督学习可以学到不错的特征提取能力,因此本文设计了分类头c(图1中的虚线部分)进行辅助学习,对于分类头的设计,遵循Wang等[18]的设置,使用2层MLP做特征映射,使用一层MLP做输出,这区别于He等[19]传统卷积模型在卷积之后只使用一层MLP作为输出层的设置。其分类损失函数表达式为:
(12)
式中,CrossEntropy( )表示交叉熵损失。训练模型时使用的损失函数表示为:
L=λ1L1+λ2L2+λ3L3,
(13)
式中,λi为损失加权系数。
2.2.2 训练与推理方法:
训练过程遵循常规的有监督深度学习模型训练范式:每个epoch以批量的形式(默认批量大小为512)从DA中不放回地采样数据,经过数据增强后送入图1所示的模型,以式(13)作为损失函数,使用动量随机梯度下降法(Stochastic Grdient Descent with Momentum,SGDM)优化模型参数,迭代多个epoch(默认为100)。使用的数据增强方式包括:随机裁剪;随机改变图像亮度、对比度、饱和度、色调;随机高斯滤波;随机水平反转;随机转为灰度图。本文默认使用ResNet18[19]作为主干网络(Backbone)。训练完成之后保存模型结构和参数,作为预训练模型。
推理流程为:加载预训练模型,删掉分类头,剩余部分作为相似性度量器S(·,·), 此时,该孪生网络的输入为一对图像,输出为这一对图像之间的余弦相似度,范围为[-1,1],相似度越接近1,表明2个图像之间越相似。将Dtrn作为支持图像集Su,将Dtst中的图像作为查询图像q,于是,任意Dtst中的图像的类别为:
(14)
即:将支持图像集中与查询图像q相似度最高的图像s对应的类别分配给q。
3 实验
3.1 数据集
本文使用AI Challenger 2018病虫害分类数据集[20]作为DA,它是由上海新客科技为竞赛提供的农作物叶子图像数据集:标注图片5万张,包含10种植物(苹果、樱桃、葡萄、柑桔、桃、草莓、番茄、辣椒、玉米和马铃薯)的27种病害,合计61个分类(按“物种-病害-程度”分)。其中与苹果有关的类别有:苹果健康、苹果黑星病一般、苹果黑星病严重、苹果灰斑病、苹果雪松锈病一般以及苹果雪松锈病严重。
本文从周敏敏[21]创建的苹果叶片数据集中采样DT。该苹果叶片病理数据集数据集由西北农林科技大学制作,分别在西北农林科技大学白水苹果试验站、洛川苹果试验站和庆城苹果试验站进行采集。数据集主要在晴天光线良好的条件下获取,部分图像在阴雨天进行采集,不同的采集条件进一步增强了数据集的多样性。数据集包括斑点落叶病、褐斑病、花叶病、灰斑病以及锈病等5种常见的苹果叶面病理图像数据,数量分别为:斑点落叶病5 343张,褐斑病5 655 张, 灰斑病 4 810 张,花叶病 4 875 张, 锈病 5 694 张。采样方法为:每类随机采样1张作为Dtrn,剩余图像中选取与Dtrn的拍摄场景一致的11 727张图像作为Dtst,共同构成DT。其样例如图2所示。

图2 苹果病害样例Fig.2 Sample images of apple diseases
3.2 试验
本文使用模型在下游特定任务T的测试集Dtst上的准确率作为衡量方法性能的指标。
构建比较基线:在DA上使用交叉熵损失监督与本方法相同的主干网络进行训练获得预训练模型。
不微调的基线(基线1):加载预训练模型后删掉分类头,将其作为图像到向量的编码器,得到编码向量后,使用欧几里得距离作为距离度量,其分类方式为:
(15)
式中,‖·,·‖表示2个向量之间的欧几里得距离,值域为[0,+∞],越接近0表示2个向量越相似。
微调的基线(基线2):加载预训练模型后修改分类头使之适应任务T,在Dtrn上使用微调的方法更新7个批次,批量大小为5,将此分类模型作为微调法[7]的比较基线。
与之类似,本文算法在Dtrn上使用微调的方法更新7个批次(批量大小为5)之后再执行推理,作为本文算法使用微调法获得的结果。
本文所提算法的结果及消融试验如表1所示。

表1 算法结果及消融试验Tab.1 Algorithm results and ablation test 单位:%
在以上试验中,对于式(7)中的加权系数,均使用1。
4 结束语
本文提出了一种基于孪生网络的度量模型,并使用对比学习损失,基于构造监督标签与二值交叉熵的距离损失,交叉熵损失联合训练,经过测试检验,在单样本农作物病害识别任务上取得了很好的性能,具有对特定任务的数据需求量少、不用在特定任务上重新训练的优点,具有实际应用的潜力。但本文方法依然无法识别出与任务T相关但未在Dtrn中出现的类别,下一步将致力于研究开放世界的少样本农作物病害识别问题。
