基于深度序列匹配网络的短文本实体链接算法
2023-03-07王亚男任佳星庞宇航高凯强
王亚男,任佳星,庞宇航,刘 琼,潘 娟,刘 伟,高凯强
(中国电力科学研究院有限公司,北京 100192)
0 引言
实体链接是自然语言处理的一个关键任务,主要用于翻译、对话和问答等任务的预处理过程[1]。实体链接的主要目标是解决命名实体的歧义性和多样性问题,该任务是从实体指代项对应的多个候选实体中选择意思最相近的一个实体进行链接。这些候选实体可能选自通用知识库,如维基百科、百度百科[2-3],也可能来自领域知识库,如教育知识库、军事知识库和医学知识库。其中,电力通信运行数据来源存在如下问题:① 数据格式不统一、网元链路业务命名规则不统一;② 数据结构复杂、规模庞大,需投入大量人力进行清洗校核。为了解决上述问题,本文利用短文本实体链接技术,对电力数据开展清洗校核,对相同实体进行链接对齐。以文本“楼兰变的电压等级为220 kV”为例,其中实体指代项是“楼兰变”,该实体指代项在知识库中可能存在多种表示和含义,如楼兰变电站、楼兰变速箱等,而在此处“楼兰变”真正的含义为“楼兰变电站”。从文本中可以发现实体指代项周围的单词包含很多语义,它们与实体指代项和正确的候选实体之间有着紧密联系。然而,现有工作常常忽略实体指代项与候选实体之间的关系,或者在上下文中丢失重要的实体指代项语义信息[4-5]。
现有的大部分实体链接工作都集中在处理长文本上,长文本中已经包含了许多有用的信息[6-7]。本文考虑短文本场景中的实体链接问题。如今,越来越多的网络语料库主要由短文本组成,例如新闻标题、社交媒体、搜索查询和网页片段[8-9]。由此可见,针对短文本的研究越来越重要,因此本文研究短文本实体链接任务。
选择正确的候选实体,关键取决于实体指代项和候选实体的匹配度。不同于长文本,短文本需要在实体指代项和候选实体之间进行匹配,仅需要依托短文本中的少量文字来理解其真实含义,同时没有其他额外更多的信息。本项任务的挑战包括:① 如何在文本中识别重要信息,这是选择最合适的候选实体的关键因素;② 如何对实体指代项与文本的关系进行建模,并充分获取实体指代项在文本中的语义。
鉴于此,本文提出了一种深度序列匹配网络(Deep Sequential Matching Network,DSMN),这是一种有效解决上述挑战的新型匹配模型。DSMN首先采用多粒度词嵌入方法将文本中的每个单词转换为词向量,然后使用2层深度匹配矩阵,第1层将实体指代项和文本中每个词逐一匹配,第2层分别将每个候选实体和上一层的输出依次进行匹配。2层匹配后实现对重要信息进行编码形成匹配向量。接下来,将匹配向量通过卷积、池化层再次提炼,获得重要语义。最后,累加得到的所有匹配向量,并通过动态匹配预测函数来计算最终得分。这些操作都是为了确保文本中的每个词、实体指代项和候选实体的重要信息以最小的损失转化为匹配向量,在有限的短文本中深度获取语义,并将这些信息充分保留且用于最终分数计算。本文在复旦大学提供的4个数据集上测试了本文提出的模型,4个数据集分别为:NTF,NLPCC,HQA和CNDL[10]。在这些数据集上,DSMN展示了优异的性能。
本文的主要贡献可归纳为以下几个方面:① 提出了一种新型DSMN,深度捕获文本、实体指代项和候选实体之间的深层语义,实现短文本实体链接任务;② 在文本、实体指代项和候选实体的知识表示过程中,提出了多粒度词嵌入方法,联合字符级、词级和句子级词嵌入,多级融合可得语义丰富的词向量表示;③ 使用DSMN在4个数据集上进行了实体链接任务,并取得优异成绩。
1 研究现状
实体链接的关键在于获取语句中更多的语义,通常有2种方法来获取更多语义:一种是通过外部语料库获取更多的辅助信息;另一种是对本地信息的深入了解以获取更多与实体指代项相关的信息[11]。
Tan等[12]提出了一种新的候选实体选择方法,该方法使用整个包含实体指代项的句子而不是单独的实体指代项来搜索知识库,以获得候选实体集。通过句子检索可以取得更多的语义信息,并获得更准确的结果。向宇等[13]使用人工工作来生成特征集,然后利用这些特征来捕获实体指代项和实体的相似性。Lin等[14]寻找更多线索来选择候选实体,这些线索被视为种子实体指代项,用作实体指代项与候选实体的桥梁。Dai等[15]使用社交平台Yelp的特征信息,包括用户名、用户评论和网站评论,丰富了实体指代项相关的辅助信息,实现了实体指代项的歧义消除。因此,利用与实体指代项相关的辅助信息,可以提供实体指代项和候选实体间更加丰富的语义信息,有利于歧义消除。
另一些研究人员使用深度学习技术来研究文本的语义。Chen等[16]使用Bert模型学习语义级的词向量表示形式,联合实现指代项检测和实体链接任务。Wei等[17]使用前馈神经网络和双重固定大小的遗忘编码方法,以对句子片段及其内容进行完全编码,并将左、右文本转换为固定大小的表示形式。Mueller等[18]将句子左右分开,然后让它们分别通过门控循环单元(Gated Recurrent Unit,GRU)和注意力机制,以获得关于实体指代项和候选实体的分数。Zeng等[19]提出了一种基于双重注意力机制的长期短期记忆网络Celan,对实体指代项和候选实体表示进行准确建模。Lou等[20]提出了一种基于注意力的双线性联合学习方法来分析知识库中单词和实体之间的实体链接。Wang等[21]提出了一种基于EM约束概率传播模型进行链接。
目前,在实体链接任务中使用深度学习方法是一个热门的研究课题。本文通过提出的DSMN实体链接模型,利用多粒度全方位词嵌入表示并结合了深度序列匹配矩阵,挖掘隐藏在表面下的深层语义关系,实验获得了鲁棒而有效的实体链接结果。
2 DSMN
2.1 总体架构概述
本文提出一种DSMN,如图1所示。
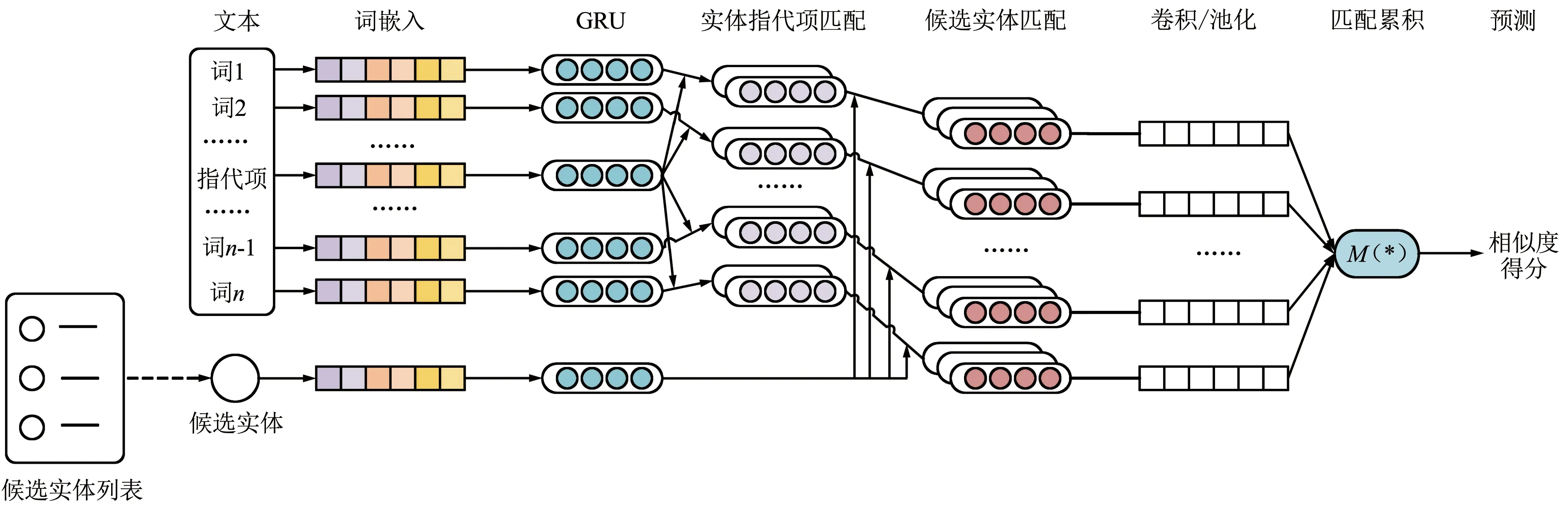
图1 DSMN架构Fig.1 Diagram for DSMN structure
DSMN首先通过多粒度词嵌入生成对应的词向量;然后,将词向量通过词-实体指代项深度序列匹配层,形成词-实体指代项对,再通过候选实体和词-实体指代项对深度序列匹配层,形成词、实体指代项和候选实体三者的深度匹配向量;接下来是卷积池化层,在本层通过卷积池化操作提取文本中包含的重要信息,并将其编码得到一个匹配向量;随后通过GRU单元序列累加得到多个匹配向量;最终将得到的隐藏层状态输入最后的预测层去动态计算最终的匹配得分。后文会给出具体描述。
2.2 多粒度词嵌入
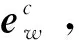
对于句子s中的词w,使用卷积网络[22]进行字符级向量表示,对斯坦福大学的GloVe词嵌入工具进行微调[23]得到词级向量表示,以及微调Bert嵌入工具[24]得到句子级向量表示。通过将这3个粒度的词向量串联起来,可以获得最终的词向量表示形式:
(1)
式中,⊕表示串联操作。文本中的词、实体指代项和候选实体都是通过相同的向量化操作得到对应的词向量。文本中的词w、实体指代项m和候选实体c的词向量表示分别采用如下形式:w对应ew,m对应em和c对应ec,并且ew,em,ec∈Rd,d表示词向量的维数。通过上述操作,得到了多粒度词嵌入表示{vt}。随后通过一个GRU单元进一步整合编码,并获得记录重要语义的隐藏单元{ht}:
(2)
式中,zi和ri分别为更新门和重置门;σ(·)表示Sigmoid函数;Wz,Wr,Wh,Uz,Ur,Uh是参数;ew,ec,em是分别来自hw,t,hc,t,hm,t的隐藏向量。
2.3 深度序列匹配
构建深度序列匹配相似度矩阵Mf∈Rd×d(f=1,2),分2步开展,首先进行词和实体指代项之间的深度序列匹配,M1表示w和m之间的相似度,然后进行候选实体和词-实体指代项对之间的深度序列匹配,M2表示c和M1之间的相似度。其中∀d,d维的M1,M2矩阵定义如下:
(3)
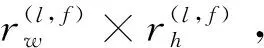
(4)
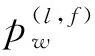
(5)
2.4 匹配积累
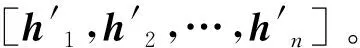
2.5 动态平均预测
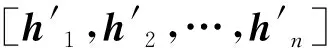
(6)
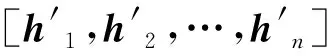
最后,采用交叉熵损失函数来取得更优化的g(s,m,c)函数,定义如下:
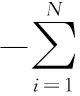
(7)
2.6 候选实体配对
在实体链接任务中,从候选实体列表中为文本中实体指代项选择一个正确的实体进行链接。使用百度百科和CN-DBpedia[25]作为实体知识库,其中包含超过1 000万个实体。从实体知识库中检索候选实体列表,并使用词匹配方法生成候选实体。每次在DSMN模型中输入一个候选实体时,都会输出一个候选实体和实体指代项的匹配分值,因此候选实体列表中的每个候选者都有一个对应的匹配分数,最终选择具有最高分值的候选实体作为实体指代项的正确实体。匹配正确实体和实体指代项可以消除歧义,便于机器理解文本含义。
3 实验
介绍了实体链接任务的实验设置和性能表现。本文设计的模型是使用Keras[26]和Tensorflow[27]库实现的。
3.1 实验设置
数据集:选择复旦大学的数据集[2]进行实体链接任务,该数据集由NLPCC,NTF,HQA和CNDL四个不同的数据集构建。NLPCC数据集由3 849个搜索查询样本组成;NTF由1 299个新闻标题组成;HQA由486个问答查询组成;CNDL由343个中文日常用语组成。实验过程重建这些数据集,每个样本都包含一个实体指代项,并由2名志愿者手动检查。数据集统计表如表1所示。
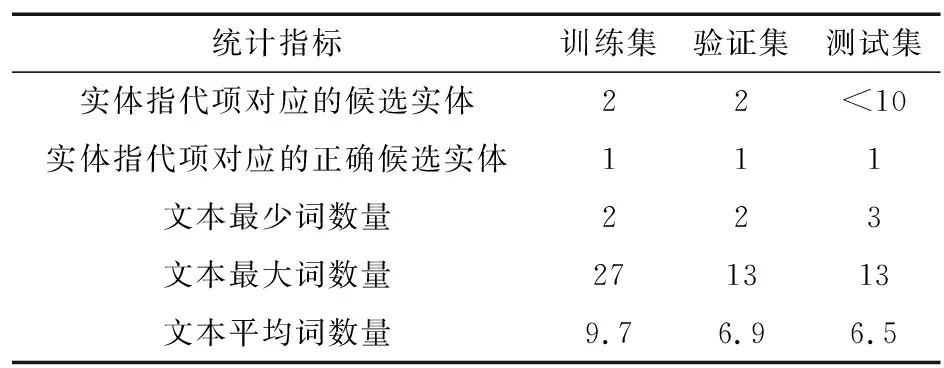
表1 数据集统计表Tab.1 Datasets statistics
从表1可以看出,这4个数据集的文本的平均词数量都是符合短文本的特征。设置每个短文本都包含一个实体指代项,可以看出候选实体列表中至少包含一个正确的候选实体。实体知识库来自百度百科和CN-DBpedia,这2个数据库的特点是数量多、质量低。
实验过程将数据集随机划分为训练集80%、验证集10%和测试集10%。表1显示了数据集的统计信息。在训练和验证集中,将正负候选实体之比设为1∶1。在测试集中,候选实体包含1个正确候选实体,少于9个错误候选实体。从表中可以看出实验数据集适合短文本语料特征。
单词分词:为适应中文语言的特殊性,通过分词可以将文本切割成词组,以词组为基本语义单元进行处理。本文比较了4种不同的分词工具,在其中一个数据集上测试其分词性能,工具包括Jieba,SnowNLP,NlPIR,THULAC。结果表明,Jieba具有最好的性能,因此选择Jieba来分词。
3.2 对比实验
对比实验选择了7种方法与PUNER的性能进行比较。前4种是传统的深度学习方法,分别是LSTM[28],BiLSTM[29],GRU[30]和BiGRU[31],后3种方法分别是:Random Walk (RW)算法通过在知识图上随机游走来解决实体链接任务,在多个数据集上都有很好的性能[6];Fast Entity Linker(FEL)是一种经典的短文本实体链接方法,它将实体指代项作为文本的质心,并计算实体和上下文之间的相关性[32];Baidu Entity Annotation (BEA)是由百度提供的API服务,在中文短文本实体链接方面表现良好[33]。本文重新实现以上7种对比方法,并在复旦大学的4个数据集上对其进行测试。
3.3 实验结果
本实验的关键评价指标是F1值(F1-Measure),F1值是精确率(Precision)和召回率(Recall)的调和平均指标,是平衡准确率和召回率影响的综合指标。公式如下:
(8)
式中,精确率是指对给定数据集,分类正确样本个数和总样本数的比值。召回率是指用来说明分类器中判定为真的正例占总正例的比率。
表2给出了在复旦大学数据集上的实体链接评估结果。从表中可以看出,传统的神经网络LSTM,BiLSTM,GRU和BiGRU的效果较差;且当上下文不足时,经典的全局实体链接方法RW表现也非常不佳;短文本链接方法FEL和BEA在一定程度上性能有所提升,但是本文提出的DSMN充分利用了实体指代项和词以及候选实体之间的关系,并多粒度地获取了语义向量,取得了最优秀的性能效果。
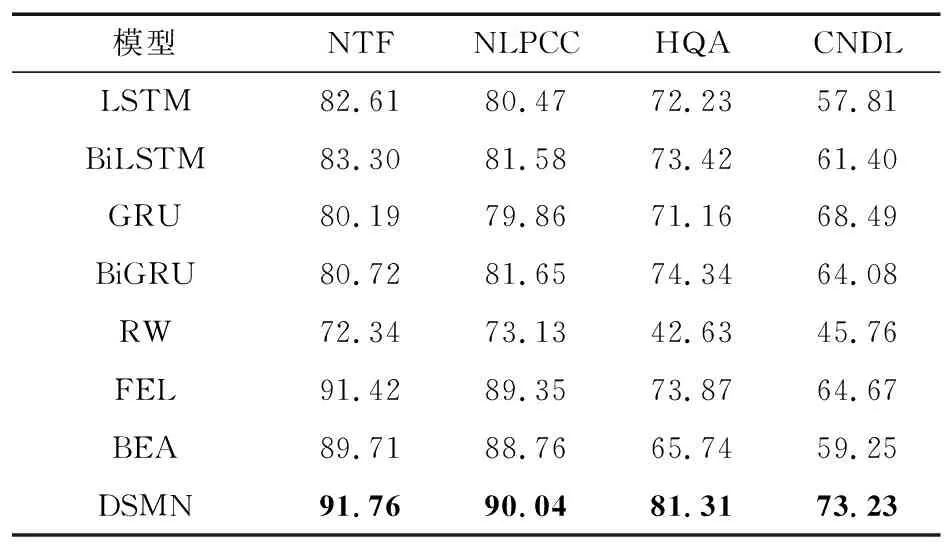
表2 在数据集上的评估Tab.2 Evaluation on datasets
表3评估了模型变形的结果。模型做了如下变化:DSMNELMo表示在多粒度词嵌入阶段将Bert替换成ELMo[34]进行句子嵌入式表示;DSMNBiLSTM表示在整合多粒度词嵌入编码阶段将GRU替换成BiLSTM进行向量化表示;DSMNonlyM1指在深度序列匹配阶段只采用词和实体指代项之间的M1矩阵进行深度序列匹配;DSMNatt-表示在动态平均预测阶段不采用注意力机制。从实验结果可以看到,在整合编码阶段替换GRU(DSMNBiLSTM)和预测阶段时取消注意力机制(DSMNatt-)对模型的性能影响不大,而在多粒度词嵌入阶段替换bert(DSMNELMo)以及在深度序列匹配阶段只采用一个M1匹配矩阵(DSMNonlyM1)对性能影响较大。由此可见,Bert和匹配矩阵对性能影响很大,是模型的关键模块,可以深度提取语义。而DSMN通过多粒度深度获取句子语义,再联合挖掘候选实体与文本和实体指代项之间的密切关系,最终取得了最优性能。
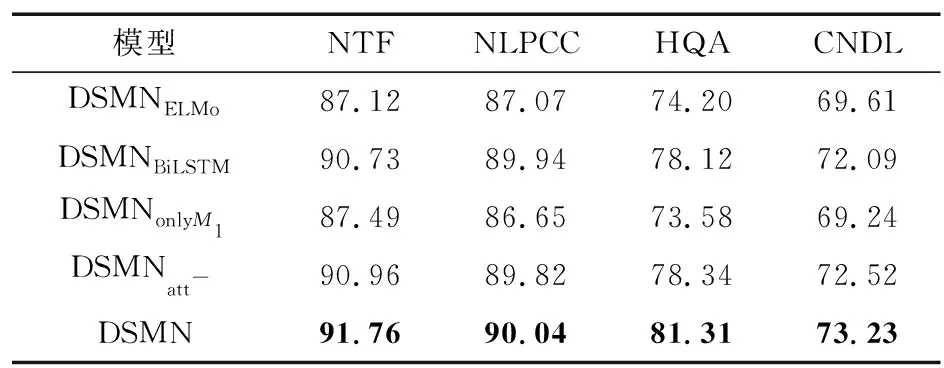
表3 模型变形的评估结果Tab.3 Evaluation results of model variation
此外,实验了当变化DSMN中低秩神经张量网络的秩大小时对训练时间成本的影响。本实验在6核12线程 32 GB内存CPU上进行。整合4个数据集的数据一起训练,在秩大小等于3时可以实现最佳性能。对于一次迭代,具有不同等级大小的DSMN的训练时间成本如图2所示。从图2可以看出,训练的时间成本几乎随秩数量增加线性增加。 这是因为低秩神经张量网络的参数数目随秩大小线性增加。
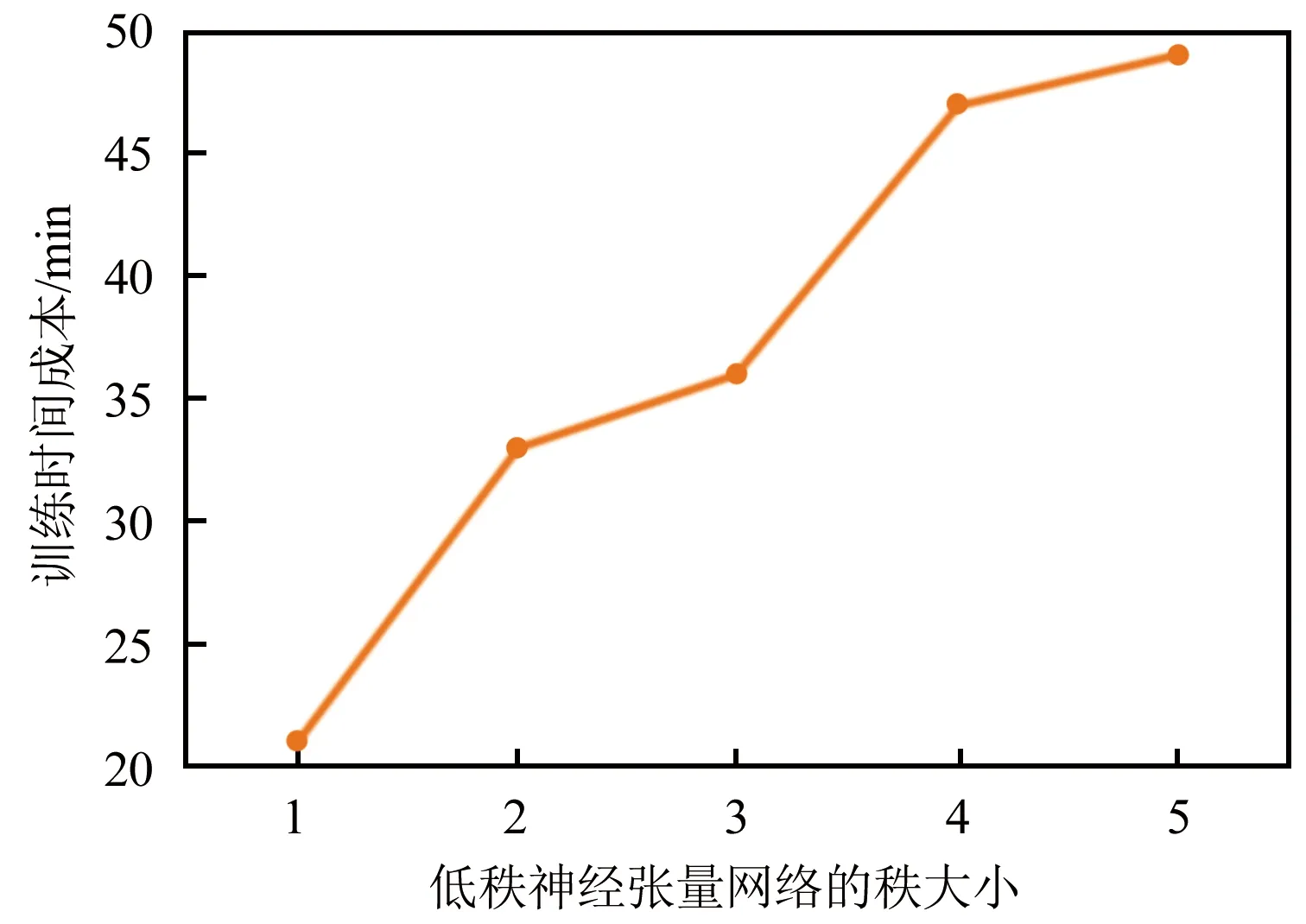
图2 DSMN不同秩大小的训练时间成本Fig.2 Training time costs of DSMN with different ranks
DSMN进一步证明了多粒度词嵌入和匹配矩阵的策略合理,从而深度提取了实体指代项、文本中词和候选实体之间的关系。此外,DSMN模型结构可完美挖掘潜在的短文本语义信息。作为内部数据,电力通信数据涉及敏感信息,因此本文选择了4个不同类型和规模尺度的数据集来尽可能展示模型的鲁棒性,在一定程度上保证了模型应用在电力通信数据时的有效性。综上所述,本文提出的DSMN模型展示了卓越的性能。
4 结束语
本文提出了一种新的深度序列匹配模型用于短文本实体链接任务,实现电力通信运行数据的实体链接和清洗校核。DSMN模型更加关注文本中单词、实体指代项和候选信息之间的关系。它使用多粒度词嵌入结合深度序列匹配对来充分提取文本中的重要信息,并挖掘了表面形式下的内在语义关系。最终,在4个公开数据集上的实验结果表明该模型具有出色的性能。将来,计划研究如何对短文本出现多个未知词或包含多个实体指代项的情况进行建模。
