基于多线程通信机制的云数据库查询优化方法
2023-03-07高瑞玮徐小玲杨国平徐康镭
高瑞玮,叶 青,徐小玲,刘 雯,韩 楠,杨国平,徐康镭
(1.成都信息工程大学 软件工程学院,四川 成都 610225;2.四川省金科成地理信息技术有限公司,四川 成都 610095;3.成都安联云防保安服务有限公司,四川 成都 610095;4.四川省大数据中心,四川 成都 610096)
0 引言
随着云计算技术[1]被广泛应用于各行各业,云数据库也得到了蓬勃发展。云数据库的查询优化是大型系统实现良好查询性能的关键[2]。查询优化的目标是为给定查询找到一组具有最低延迟的执行计划。对于复杂的多表连接查询,将产生数千万个不同连接顺序的候选执行计划。如何在数千万个候选执行计划中确定一组最佳连接顺序的执行计划是查询优化中极具挑战性的问题[3]。此外,不同连接顺序能够显著影响执行计划的代价和延迟。例如,一个糟糕的连接顺序的执行计划需要花费数小时甚至数天的查询时间,而一个较好的连接顺序的执行计划仅花费ms级别的查询时间。因此,连接顺序选择被视为查询优化的重难点[4]。
云数据库的查询优化方法为启发式算法[5],往往基于专家经验,但是仍然存在局限性[6]。例如,动态规划算法需要巨大的搜索空间,花费较长的优化时间。QuickPick-1000[7]的优化时间较短,但是容易生成糟糕的连接顺序执行计划,使得查询性能下降,并且传统的查询优化方法无法从历史查询中学习经验。例如,对于相同的多表连接查询会重复生成糟糕的执行计划,进而产生较高的延迟[8]。
最近,利用人工智能技术解决查询优化取得了成功。例如,Marcus等[9]首次提出了基于强化学习的优化器Rejoin。随后Krishnan等[10]提出了利用Deep Q-network(DQN)[11]算法解决连接顺序选择。现有基于强化学习的优化器虽然能够克服传统的查询优化方法的局限性,但是仍然存在着一些缺陷:
① Rejoin和DQ等现有优化器的编码方法不包括物理运算符和执行计划的结构特征,进而无法准确地表示执行计划。物理运算符是指执行计划中单表的扫描方式和多表之间的连接方式。
② Rejoin和DQ等现有优化器并没有设计状态表示模型,无法捕捉执行计划的结构特征,进而无法为后续强化学习算法提供准确的状态表示。
③ Rejoin和DQ等现有优化器使用数据库代价估计器为执行计划估计代价,并将代价作为奖励目标。对于复杂的多表连接查询,并不能准确估计中间结果集的代价,容易出现错误的代价估计[12],进而生成次优的执行计划。
④ Neo[13]和AlphaJoin[14]等现有优化器使用价值网络为执行计划预测延迟,并将延迟作为优化目标。虽然能够避免错误的代价估计导致生成次优的执行计划,但是Neo和AlphaJoin的价值网络的预测准确性较低,并且需要高质量的历史查询样本进行训练[15]。
⑤ Neo等现有优化器使用简单的搜索策略指导连接顺序选择,并没有尝试在更大的搜索空间中进行探索,可能会降低找到最优执行计划的概率,容易陷入局部最优解。
⑥ Rejoin和DQ等现有优化器的强化学习算法的探索性较差,容易受到超参数的影响,并且训练速度较慢、收敛不稳定[16-18]。
针对上述问题,提出了一种新型基于异步Soft Actor-Critic的连接查询优化器(Asynchronous Soft Actor-Critic for Join Query,ASA-Join)。ASA-Join集成了一种新的编码方法,将物理运算符和执行计划的结构特征进行编码,能够准确地表示执行计划。ASA-Join设计了状态表示模型,利用BiGRU[19]模型来捕捉执行计划的结构特征,进而能够为异步Soft Actor-Critic提供准确的状态表示。ASA-Join设计了新的奖励机制,利用多任务学习方法[20]将执行计划的延迟和代价均作为优化目标,进而使得执行计划能够反映真实的查询时间。ASA-Join利用多线程通信机制设计了异步Soft Actor-Critic算法。异步Soft Actor-Critic算法指导连接顺序选择,利用最大熵机制能够增加动作选择的随机性,进而提高智能体的探索能力,尽可能从全局上搜索最优执行计划。异步Soft Actor-Critic算法不依赖于精确的超参数调整,并且多线程通信机制能够实现异步更新,进而加快训练速度并提高收敛稳定性。在真实数据集Join Order Benchmark (JOB)[21]和TPC-H上对ASA-Join的性能进行评估。实验结果表明,ASA-Join的代价和延迟均低于现有基于强化学习的优化方法。
1 ASA-Join的整体架构
ASA-Join的整体架构如图1所示。
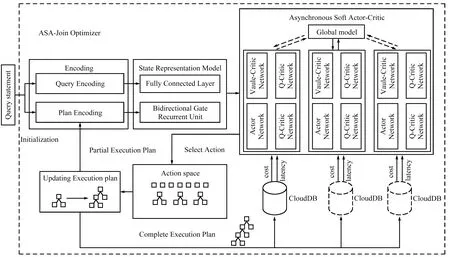
图1 ASA-Join的整体架构Fig.1 The overall framework of ASA-Join
ASA-Join主要由3个关键部分构成:编码方法、状态表示模型以及异步Soft Actor-Critic算法。
① 编码方法主要由查询语句编码Query-Encoding和执行计划编码Plan-Encoding组成。Query-Encoding主要对查询语句的连接谓词和选择谓词进行编码,Plan-Encoding主要对执行计划的结构特征和物理运算符进行编码,进而生成执行计划向量树。
② 状态表示模型主要对执行计划向量树进行序列化处理,生成执行计划向量集,并将执行计划向量集作为BiGRU模型的输入,进而BiGRU模型能够捕捉执行计划的结构特征,为异步Soft Actor-Critic提供准确的状态表示。
③ 异步Soft Actor-Critic算法包含1个Actor网络、2个Value-Critic和2个Q-Critic。Actor网络将当前执行计划状态作为输入,进而从动作空间中选择将要执行的动作,例如选择2个表进行连接,并指定扫描方式(Sequence-Scan,Index-Scan)以及连接方式(Hash-Join,Nest-Loop-Join,Merge-Join)。Value-Critic网络主要对当前执行计划状态进行评估,输出状态价值。Q-Critic网络主要对当前执行计划状态下将要执行的动作进行评估,输出动作价值。每当ASA-Join执行Actor网络选择的动作后,将更新执行计划编码,进而更新执行计划状态,使得Actor网络从动作空间中再次选择将要执行的动作,直到达到终止状态(所有表均被连接,生成完整执行计划)。
进一步地,完整执行计划将被发送给云数据库,云数据库的代价估计器和执行器分别为完整执行计划给出代价和延迟,并利用多任务学习方法将执行计划的代价和延迟均作为奖励目标。需要注意的是,收集执行计划的代价不需要运行执行计划,因此将执行计划的代价作为第1阶段的奖励目标,使得ASA-Join能够快速理解以代价作为奖励目标的云数据库优化方式。执行计划的延迟是云数据库运行执行计划的时间,难以短时间内获取,因此将执行计划的延迟作为第2阶段的奖励目标。在第1阶段训练后,ASA-Join能够生成较优的执行计划,再使用执行计划的延迟作为奖励目标进行微调,使得ASA-Join最终生成的执行计划能够反映真实的执行时间,并避免错误的代价估计导致生成次优的执行计划。
此外,在ASA-Join的训练过程中,利用多线程通信机制来异步更新Soft Actor-Critic的参数。在每个线程中均包含具有相同结构和相同参数的Soft Actor-Critic。选择任意一个线程中的Soft Actor-Critic作为全局模型,其余线程中的Soft Actor-Critic作为计算模型。计算模型主要与云数据库进行交互,获取数据样本(状态、动作和奖励等信息)来计算Soft Actor-Critic中各个网络的参数梯度,但并不用于更新计算模型,而是用于更新全局模型的参数。
2 ASA-Join的编码方法
2.1 Query-Encoding
Query-Encoding的示例如图2所示。
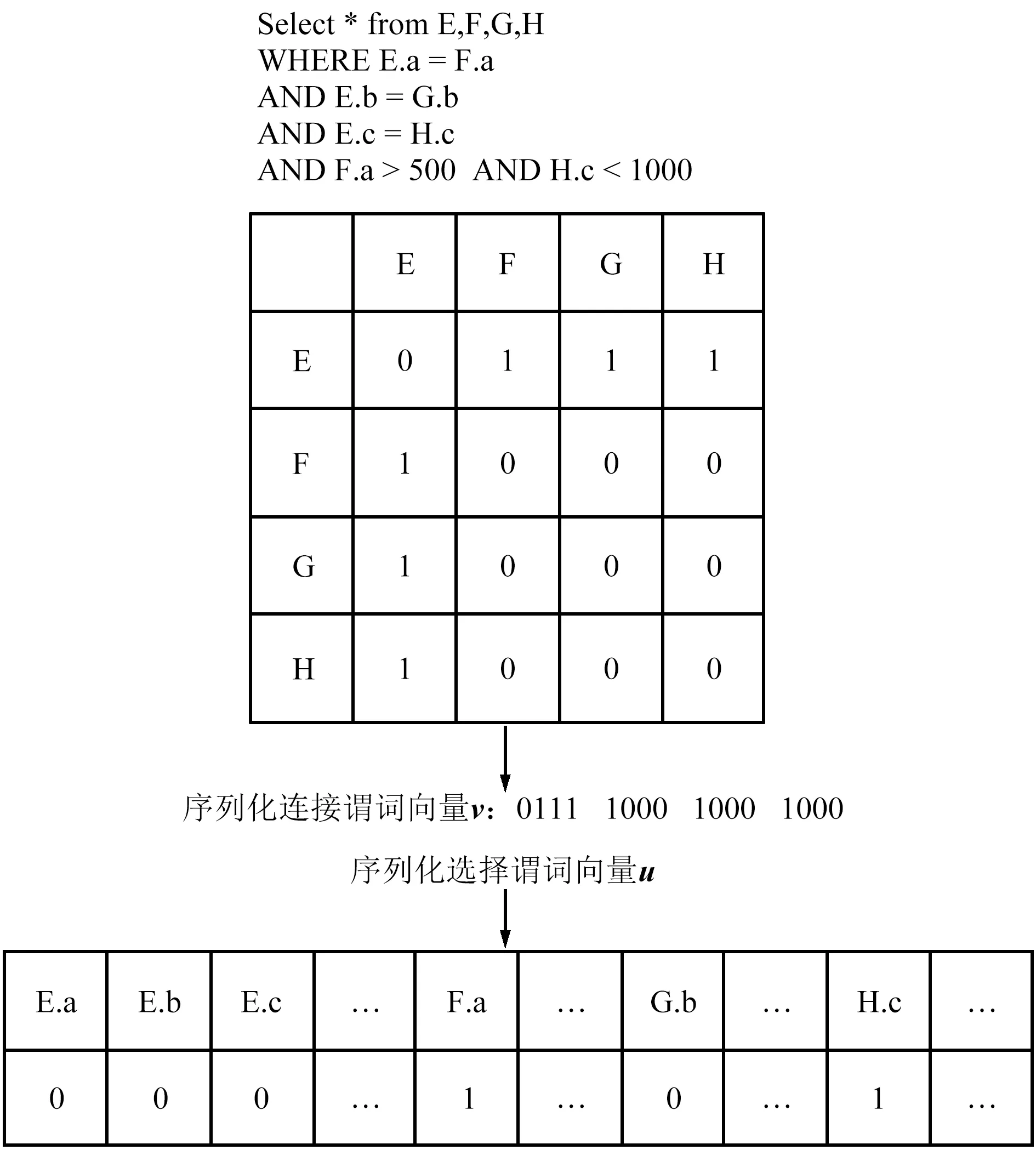
图2 Query-Encoding的示例Fig.2 Example of Query-Encoding
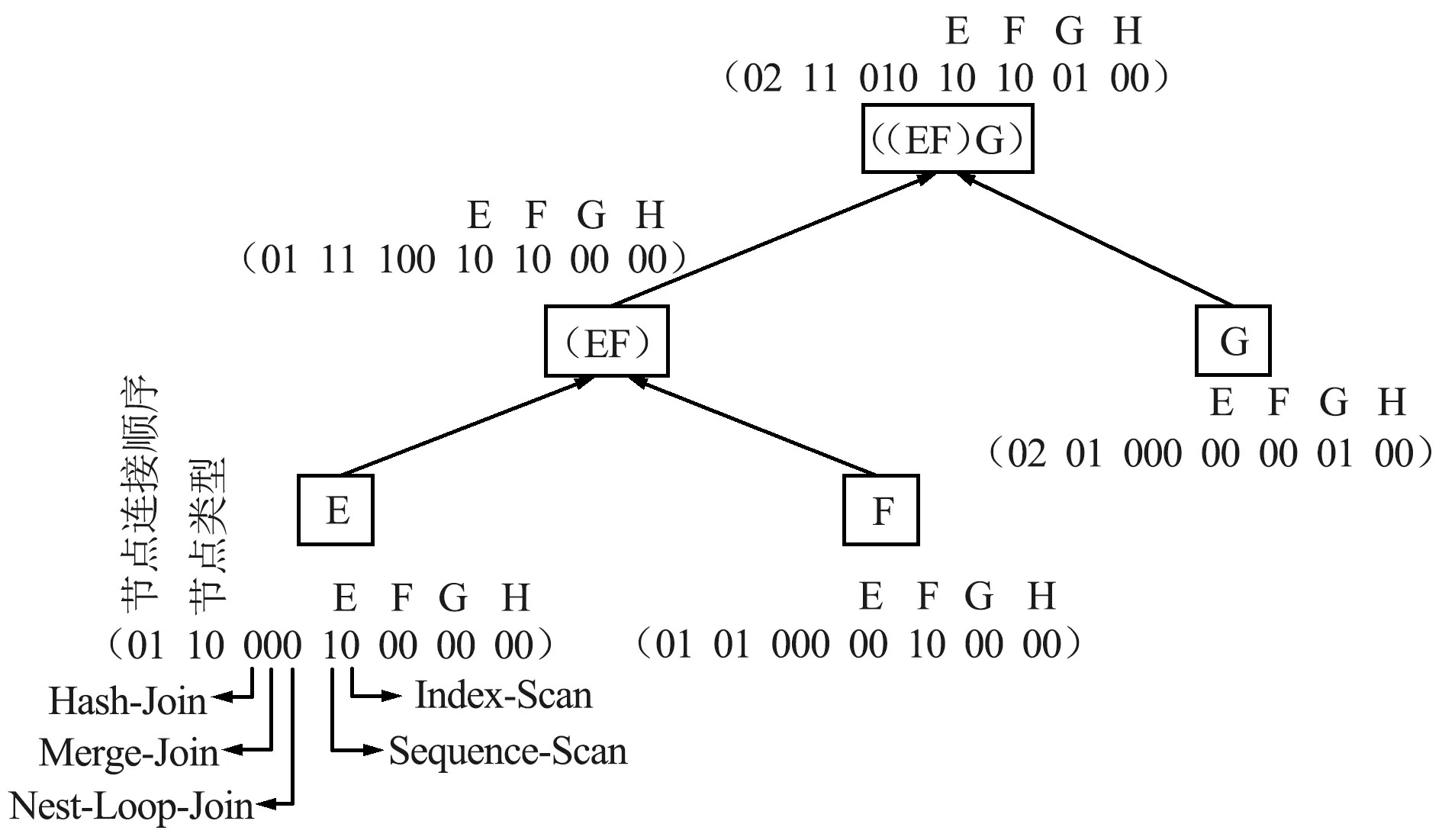
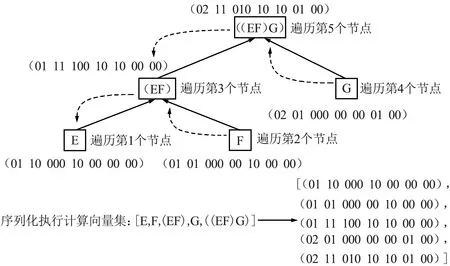
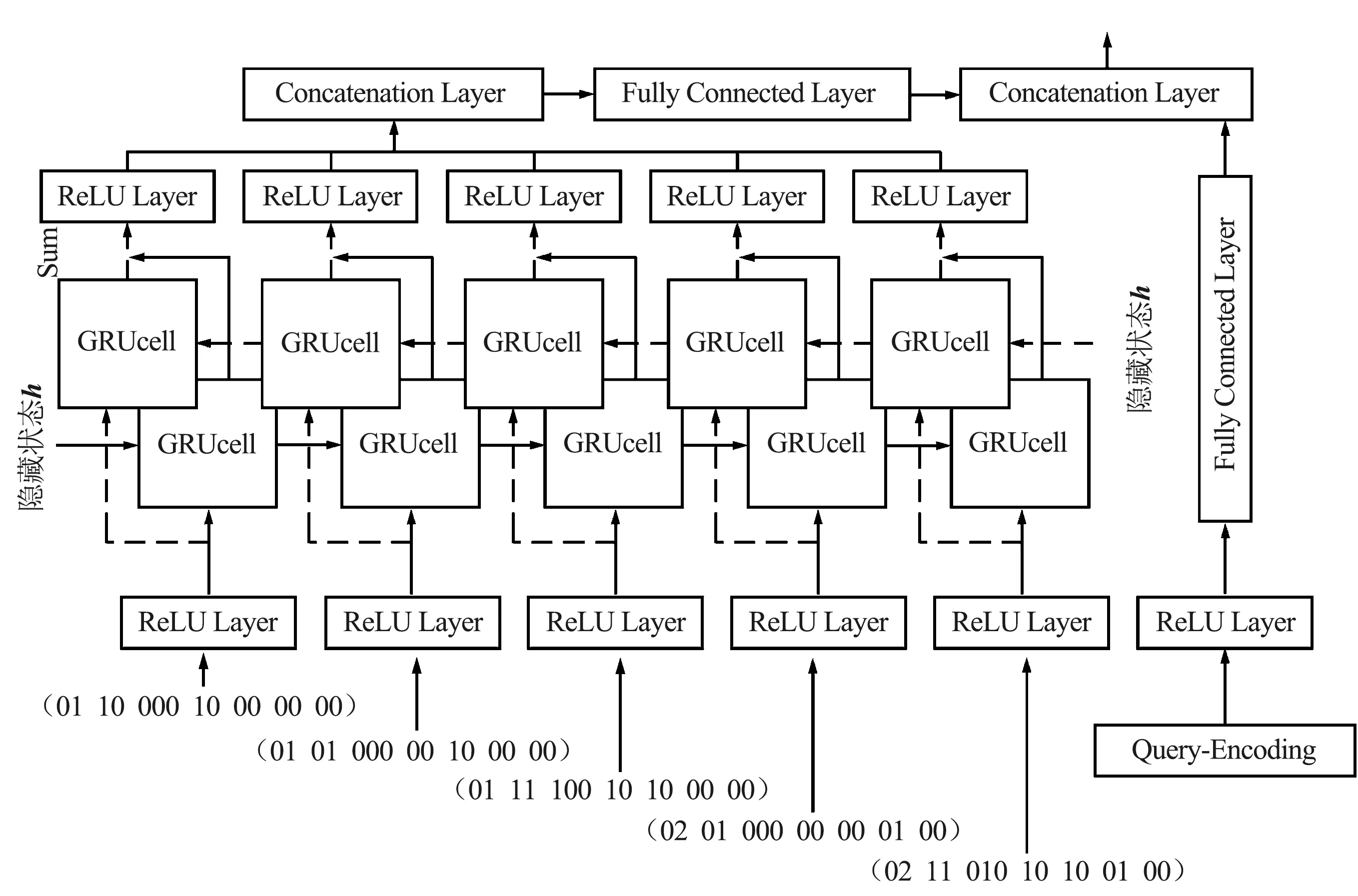
主要对查询语句的连接谓词和选择谓词进行编码。连接谓词首先使用维度为N的邻接矩阵M进行编码,其中N为云数据库中表的数量。邻接矩阵的元素Mi,j取值为0或者1,1代表第i个表与第j个表具有连接关系,0代表第i个表与第j个表无连接关系,i和j均为整数,且0 vi*(N-1)+j=Mi,j (1) 式中,vi*(N-1)+j为连接谓词向量v的第i*(N-1)+j个位置上的值。选择谓词使用独热向量进行编码,生成选择谓词向量u,独热向量的维度为云数据库中列的数量。为了便于说明Query-Encoding,给出了一个查询语句例子,如图2所示。查询语句的连接谓词为E.a=F.a,E.b=G.b,E.c=H.c,则邻接矩阵中对应位置元素的值为1,连接谓词向量v为(0111 1000 1000 1000)。查询语句的F.a列和H.c列涉及选择谓词,则选择谓词向量u中对应位置的值为1,其余位置的值为0。 Plan-Encoding将执行计划的物理运算符和结构特征进行编码。执行计划的物理运算符包括扫描方式和连接方式。扫描方式使用独热向量进行编码,例如(10)表示执行计划中某个表使用Sequence-Scan,(01)表示执行计划中某个表使用Index-Scan。连接方式使用独热向量进行编码,例如(100)表示执行计划中某2个表使用Hash-Join生成中间结果集,(010)表示执行计划中某2个表使用Nest-Loop-Join生成中间结果集,(001)表示执行计划中某2个表使用Merge-Join生成中间结果集。 执行计划的结构特征包括执行计划的节点类型、节点连接顺序。执行计划的节点类型包括左表、右表和中间结果集。执行计划的节点类型使用独热向量进行编码,例如(10)表示执行计划的节点类型为左表,(01)表示执行计划的节点类型为右表,(11)表示执行计划的节点类型为中间结果集。执行计划的节点连接顺序使用2位整数进行编码,例如(01)表示第1次选择该节点进行连接或者第1次生成该节点,(02)表示第2次选择该节点进行连接或者第2次生成该节点。 进一步,Plan-Encoding将执行计划编码为执行计划向量树,执行计划向量树中每一个节点向量均由该节点的物理运算符编码、节点类型编码和节点连接顺序编码组成。需要注意的是,执行计划分为部分执行计划和完整执行计划,因此执行计划向量树中的节点数量将动态增长。为了便于说明Plan-Encoding,基于图2的查询语句给出了部分执行计划向量树。Plan-Encoding示例如图3所示,假设第1次选择E表和F表使用Hash-Join生成中间结果集(EF),并指定E表作为左表、E表扫描方式为Sequence-Scan,F表作为右表、F表扫描方式为Sequence-Scan。第2次选择表E和表G进行连接,也就是将中间结果集(EF)和表G使用Nest-Loop-Join生成中间结果集((EF)G),并指定G表作为右表、G表扫描方式为Index-Scan。 图3 Plan-Encoding示例Fig.3 Example of Plan-Encoding 准确的状态表示能够提升强化学习算法的性能。因此,ASA-Join设计了状态表示模型对连接谓词向量、选择谓词向量和执行计划向量树进行处理。对于连接谓词向量和选择谓词向量,状态表示模型使用全连接层进行处理,生成静态信息向量q,能够克服连接谓词向量和选择谓词向量的稀疏性。对于执行计划向量树,状态表示模型首先使用后序遍历算法进行序列化处理,生成执行计划向量集。为了便于说明状态表示模型使用后序遍历算法对执行计划向量树进行序列化处理的过程,基于图3中的部分执行计划向量树给出了一个例子。如图4所示,依次访问部分执行计划向量树各个节点向量,并按访问顺序将节点向量存入执行计划向量集。 图4 基于后序遍历算法处理执行计划向量树Fig.4 Processing execution plan vector tree based on post-order traversal algorithm 状态表示模型使用BiGRU模型对执行计划向量集进行处理,能够捕捉执行计划的结构特征,并生成动态信息向量p。不同结构特征的执行计划向量树可以转换为执行计划向量集。换言之,捕捉执行计划的结构特征可以转换为捕捉有序节点的上下文信息。BiGRU适合处理序列数据,即使是相当长的序列数据 (如在自然语言处理中)。因此,对于执行计划向量树,BiGRU能够自动学习执行计划的结构特征,进而给出执行计划的准确表示。对于执行计划向量集,BiGRU依次处理执行计划向量集中每个节点向量,进而捕捉执行计划中节点之间的上下文信息。当 BiGRU 处理当前节点向量时,BiGRU 可以同时记住前一个节点以及后一个节点的关键信息,例如结构特征。即使 BiGRU 处理最后一个节点向量,仍然可以记住第1个节点向量包含的结构信息,进而捕捉整个执行计划向量树的结构特征。状态表示模型将静态信息向量q和动态信息向量p进行级联,最终生成执行计划状态向量s。基于图4中的例子,状态表示模型的工作原理如图5所示。 图5 状态表示模型的工作机制Fig.5 Working mechanism of the state representation model 现有强化学习算法通常存在3类问题: ① 探索能力、健壮性较差; ② 依赖于精确的超参数设置; ③ 训练速度较慢、收敛不稳定。 为了ASA-Join更好地指导连接顺序选择,提出了异步Soft Actor-Critic算法。异步Soft Actor-Critic算法利用最大熵机制能够增加策略的随机性,并鼓励智能体选择从未尝试的动作,进而更全面地评估各个动作的价值。最大熵机制能够增加智能体的探索能力并提高算法的健壮性。此外,利用多线程通信机制实现异步更新,能够加快训练速度,并且使用基于当前策略的数据样本计算参数梯度,能够提高训练效果和收敛稳定性。异步Soft Actor-Critic算法步骤如算法1所示。 算法1:异步Soft Actor-Critic算法 输入:Actor网络的初始参数WA,Value-Critic网络的初始参数WV,Q-Critic网络的初始参数WQ 1. CreateThreads(); 2. Allocation(); 3. SelectGlobalModel(); 6. SetT=0,T最大值为Tmax; 7. Sett=1,t的最大间隔值为tmax; 8. WHILE (T 11. Resettstart=t; 12.st=GetState(); 13.FOReach episodeDO 14. 计算模型中Actor网络根据st选择动作at; 15.st+1=ChangeState(st,at); 16. IF (st表示完整执行计划状态){ 17.r(st,at)=costorlatency; 18. } 19.ELSE{ 21. } 25.t=t+1,T=T+1; 26.IF(t-tstart=tmax){ 29.ENDFOR 异步Soft Actor-Critic算法主要包含如下操作: ⑤ 算法第25~28行分别更新线程计数器和全局计数器的计数值t,T。如果间隔计数值等于tmax, 将计算模型中的参数梯度传递到全局模型中来更新全局模型的参数。 实验数据集为JOB和TPC-H数据集。JOB数据集是基于电影数据集IMDB的查询语句集合,包括33个查询模板和113个复杂的多表连接查询语句,其中多表连接查询语句平均包含9个连接谓词,最多包含17个连接谓词。所有的查询语句真实地反映了电影爱好者的问题。电影数据集IMDB包含3.6 GB非均匀分布数据和21个表,其中表cast_info和movie_info分别包含3 000万行记录和1 500万行记录。TPC-H数据集是基于供货业务数据集的查询语句集合,包括22个查询语句。供货业务数据集由DBGen工具模拟生成,包含4.0 GB数据和8个表。 实验硬件环境为具有12核24线程的CPU、NVIDIA 3090GTX显卡、64 GB内存和2 TB硬盘的戴尔服务器。实验软件环境为OpenAI-gym强化学习交互环境库、RLlib强化学习算法库、Tensorflow2.0。 实验所用云数据库为华为云数据库Relational Database Service(RDS) for PostgreSQL、阿里云数据库RDS for PostgreSQL和云数据库GuassDB[22]。RDS for PostgreSQL,RDS for PostgreSQL和GuassDB的代价估计器和执行器为执行计划提供代价和延迟。 为了便于直观地比较ASA-Join与现有基于强化学习的优化器的性能差异,使用相对代价 (Relative Cost,RC)和相对延迟 (Relative Latency,RL)作为评估指标。RC计算如下: (2) 式中,cost(qi)表示ASA-Join或现有基于强化学习的优化器为第i条查询语句生成相应执行计划的代价;n为JOB数据集或TPC-H数据集中查询语句的数量;costdp(qi)表示动态规划方法为第i条查询语句生成相应执行计划的代价。RL计算如下: (3) 式中,latency(qi)表示ASA-Join或现有基于强化学习的优化器为第i条查询语句生成相应执行计划的延迟;latencydp(qi)表示动态规划方法为第i条查询语句生成相应执行计划的延迟。 基于不同云数据库的JOB数据集的代价评估如图6所示。 图6 基于不同云数据库的JOB数据集的代价评估Fig.6 Cost evaluation of JOB datasets based on different cloud databases 基于RDS for PostgreSQL构建ASA-Join和现有基于强化学习的优化器如图6(a)所示。在JOB数据集上,ASA-Join的相对代价低于现有基于强化学习的优化器如Rejoin,DQ,Neo和AlphaJoin,这表明ASA-Join能够生成以代价为优化目标的最优执行计划。主要原因在于,相比Rejoin和DQ,ASA-Join能够捕捉执行计划的结构特征并提供执行计划的准确表示,进而可以提高后续异步Soft Actor-Critic算法的性能;相比Neo和AlphaJoin,ASA-Join的异步Soft Actor-Critic算法能够增加策略的随机性以及提高智能体的探索能力,避免陷入局部最优解,尽可能生成最优执行计划。现有基于强化学习的优化器的相对代价均低于传统优化方法QP(QuickPick-1000),这表明利用强化学习能够更好地指导连接顺序选择,进而生成更低代价的执行计划。如图6(a)和(b)所示,分别基于RDS for PostgreSQL,GuassDB构建ASA-Join和现有基于强化学习的优化器。在JOB数据集上,ASA-Join的相对代价低于现有基于强化学习的优化器。其中,AlphaJoin的相对代价最接近ASA-Join,传统优化QP的相对代价最大。 基于不同云数据库的TPC-H数据集的代价评估如图7所示, 在不同云数据库的TPC-H数据集上,ASA-Join均能够生成更好的执行计划(以代价为优化目标),这表明ASA-Join能够适应不同的云数据库,并不依赖于特定云数据库,具有较高的通用性。在代价评估方面,ASA-Join始终优于现有基于强化学习的优化器和传统的优化方法。 图7 基于不同云数据库的TPC-H数据集的代价评估Fig.7 Cost evaluation of TPC-H datasets based on different cloud databases 基于不同云数据库的JOB数据集的延迟评估如图8所示。 图8 基于不同云数据库的JOB数据集的延迟评估Fig.8 Latency evaluation of JOB datasets based on different cloud databases 可以看出,在不同云数据库的JOB数据集上,ASA-Join的相对延迟均最低,并且ASA-Join的相对延迟分别为0.60(基于RDS for PostgreSQL),0.61(基于GuassDB)和0.63(基于RDS for PostgreSQL)。在延迟评估方面,ASA-Join优于现有基于强化学习的优化器和传统的优化方法。主要原因在于,ASA-Join的奖励机制基于多任务学习思想,将延迟和代价均作为优化目标。换言之,ASA-Join既可以学习以代价作为奖励的策略,也可以学习以延迟为奖励的策略,能够克服错误的代价估计和基数估计,使得生成的执行计划反映真实查询时间。此外,ASA-Join的异步Soft Actor-Critic算法能够加快训练速度、提高收敛稳定性,进而提高ASA-Join的训练效果。在RDS for PostgreSQL上,ASA-Join的相对延迟分别比Rejoin(相对延迟为1.20)低50.0%,比DQ(相对延迟为1.15)低47.8%,比Neo(相对延迟为0.80)低25.0%,比AlphaJoin(相对延迟为0.72)低16.7%。在GuassDB上,ASA-Join的相对延迟分别比Rejoin(相对延迟为1.12)低45.5%,比DQ(相对延迟为1.17)低48.7%,比Neo(相对延迟为0.78)低21.8%,比AlphaJoin(相对延迟为0.70)低12.9%。在RDS for PostgreSQL上,ASA-Join的相对延迟分别比Rejoin(相对延迟为1.18)低46.6%,比DQ(相对延迟为1.19)低47.1%,比Neo(相对延迟为0.82)低23.2%,比AlphaJoin(相对延迟为0.74)低14.9%。在JOB数据集上,ASA-Join的相对延迟与其他优化方法的差距较大,主要原因是JOB数据集中的查询语句均为复杂的多表连接查询,平均包含9个以上的连接谓词,使得候选执行计划的结构复杂多变。ASA-Join的编码方法能够准确表示执行计划,并且利用BiGRU模型能够捕捉执行计划的结构特征,为异步Soft Actor-Critic提供准确的状态表示,进而使异步Soft Actor-Critic能够更好地指导多表连接顺序选择,ASA-Join生成更好的执行计划(以延迟为优化目标)。 基于不同云数据库的TPC-H数据集的延迟评估如图9所示。可以看出,在不同云数据库的TPC-H数据集上,ASA-Join的相对延迟也低于现有基于强化学习的优化器和传统的优化方法。在TPC-H数据集上,ASA-Join的相对延迟与其他优化方法的差距并不是很大,主要原因是TPC-H数据集中查询语句包含的连接谓词的数量较少,现有基于强化学习的优化器均能够较好地指导连接顺序选择,而ASA-Join更擅长处理复杂的多表连接查询。 图9 基于不同云数据库的TPC-H数据集的延迟评估Fig.9 Latency evaluation of TPC-H datasets based on different cloud databases 本文针对云数据库的启发式查询优化方法和现有基于强化学习的优化器存在的缺陷,提出了新型基于异步Soft Actor-Critic的连接查询优化器。首先,ASA-Join集成了新的编码方法,包括Query-Encoding和Plan-Encoding,能够准确表示执行计划。其次,ASA-Join设计了状态表示模型来捕捉执行计划的结构特征,进而提供准确的状态表示,使得异步Soft Actor-Critic能更好地指导连接顺序选择。再者,ASA-Join利用多线程通信机制设计了异步Soft Actor-Critic算法。异步Soft Actor-Critic利用最大熵机制增加智能体的探索能力,使得智能体能够探索更多从未尝试的动作,并且多线程通信机制能够实现异步更新,进而加快训练速度以及提高收敛稳定性。此外,ASA-Join将执行计划的代价和延迟均作为奖励目标,使得生成的执行计划能够反映真实的查询时间。 未来的工作将着重探究云数据库模式的频繁改变对基于强化学习的优化器的影响,并基于ASA-Join进一步研究新的优化器如何适应工作负载的变化。2.2 Plan-Encoding
3 ASA-Join的状态表示模型
4 ASA-Join的异步Soft Actor-Critic
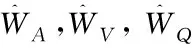
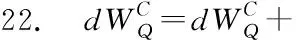
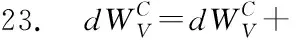
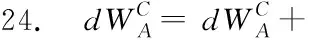
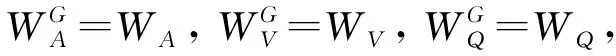
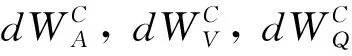

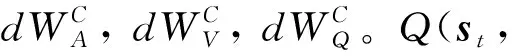
5 ASA-Join的实验评估
5.1 实验设置
5.2 实验评估指标
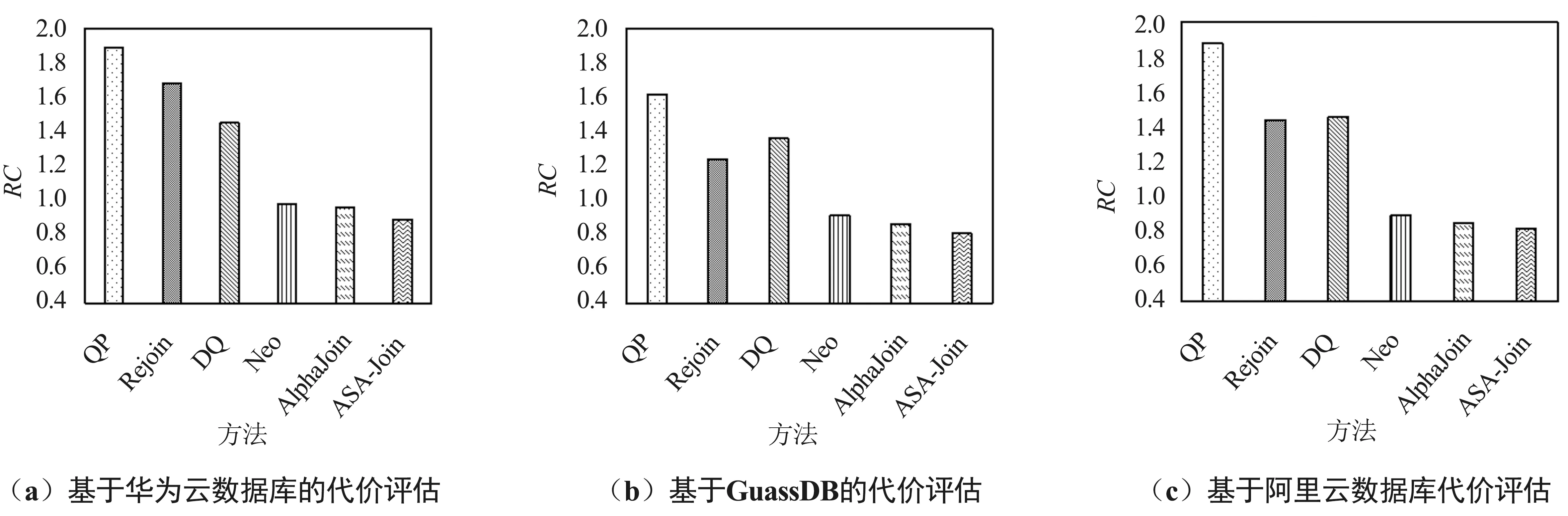
5.3 ASA-Join的相对代价评估

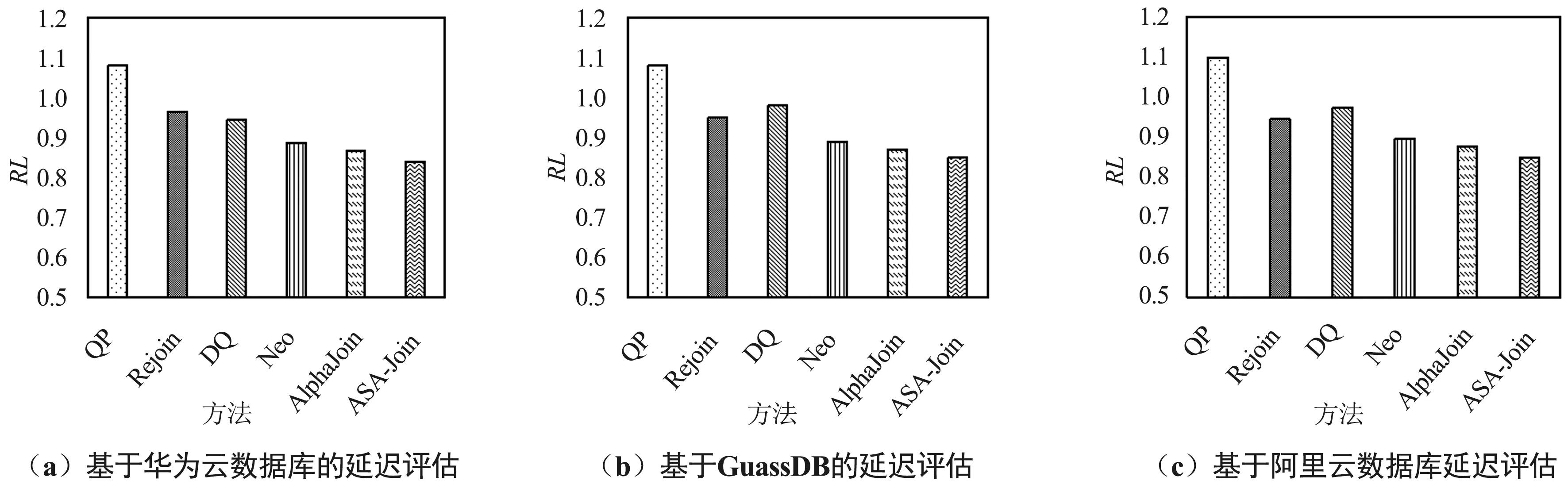
5.4 ASA-Join的相对延迟评估

6 结束语
