基于机器学习的数据情报侦查预测研究
2023-03-04薛亚龙刘梓泞
薛亚龙,刘梓泞
(宁夏警官职业学院,宁夏 银川 750021)
随着各种多源异构数据呈指数级的迅猛增长,数据情报侦查预测中存在挖掘过拟合现象严重、因果关联效应偏差高、数据犯罪模式更迭快等突出问题,给算法时代的数据情报侦查预测带来了巨大困境。基于此,引入基于机器学习的数据情报侦查预测研究范式,不仅能够提升打击数据犯罪情势生存与态势发展的侦查效果,而且还能够增强挤压数据犯罪情势滋生的“土壤”空间,转型和创新打击数据犯罪情势的新型数据情报侦查途径,从而实现机器学习循证数据情报侦查预测的价值效果。
一、机器学习数据情报侦查预测的转型价值
机器学习数据情报侦查预测主要是通过采取支持向量机、人工神经网络等机器学习算法①参见范昊、李珊珊、热孜亚·艾海提:《机器学习算法在我国情报学研究中的应用与影响——基于CSSCI 期刊论文的视角》,载《图书情报知识》2022 年第5 期,第96-108 页。,深度挖掘多源异构数据与数据犯罪情势之间潜在的关联规则,帮助解决多源异构数据与数据犯罪小概率事件、数据犯罪情势因果解释与情报侦查预测、数据运算挖掘精度扩张与情报侦查预测级联需求等突出问题。诚然,与传统数据情报侦查预测相比较而言,机器学习数据情报侦查预测为算法时代的现代数据情报侦查提供了新的转型价值。
(一)情报预测路径:从侦查假设向客观数据转型
传统数据情报侦查预测往往始于侦查假设,主要是在侦查因果解释理论的指导下先提出侦查假设,然后采取随机抽样措施获取所需数据并进行侦查假设的验证等②参见薛亚龙、罗珂岩、马麒:《数据情报侦查的循证决策方法》,载《中国刑警学院学报》2022 年第3 期,第24-34 页。。可见,传统数据情报侦查预测是一种自上而下的逻辑论证过程。侦查假设验证主要适用于特定时空的数据犯罪情势,往往难以被应用于数据情报侦查预测的全过程。然而,机器学习数据情报侦查预测是以客观数据为开始,不再侧重于追求获取各种模糊或不确定的因果关系和反复论证的侦查假设,而是主要利用机器学习算法对多源异构数据直接进行聚类挖掘、模式识别等。这不仅能够帮助侦查人员发现和掌握数据犯罪情势的生存态势规律,而且还能够帮助其预测不同侦查中主体的发展需求。显然,机器学习数据情报侦查预测是一种以,“汇集数据—挖掘数据—构建模型—结果预测”为模式的挖掘流程。诚然,机器学习数据情报侦查预测的路径转型从根本上改变了传统数据情报侦查预测所追求的侦查因果解释。这不仅有利于能够获得更多不同数据犯罪情势之间的关联规则和强化对多源异构数据运算挖掘的可控性,而且还有利于最大限度地避免和降低侦查人员主观方面因素的影响。
(二)情报预测数据:从主观设计向全量真实转型
传统数据情报侦查预测的主要困境在于汇集数据时存在不透明、不完备、不公开等现象,部分还存在清洗集成难、规约融合复杂等突出问题。然而,机器学习数据情报侦查预测确有望能够避免和减少这些困境难题。首先,多源异构数据是“客观数据”而非“被主观设计的数据”。传统数据情报侦查预测在数据汇集方式上属于典型的主观设计,尤其在侦查因果解释理论指导下促使侦查人员所汇集的数据具有一定的选择性、目的性、裁剪性,造成这种“被主观设计的数据”严重影响了应用效果的客观性和真实性。而机器学习数据情报侦查预测所使用的多源异构数据主要是在不介入、不干预的前提下对各种数据犯罪情势生存态势的客观记录和汇集,从根本上保障了多源异构数据被汇集的客观真实。其次,多源异构数据是“全量数据”而非“抽样数据”。多源异构数据主要是接近各种不同数据犯罪情势的全量数据,与传统数据情报侦查预测的抽样数据相比较而言,“全量数据”能够消除或降低因传统抽样数据而引起的统计误差、结果失真等异常现象。再次,多源异构数据是“厚数据”而非“浅数据”。多源异构数据不仅包括结构型数据、非结构型数据、异构型数据等传统型数据,而且还包括定类型数据、定序型数据、定比型数据等新型数据。显然,多源异构数据属于内涵丰富的“厚数据”。最后,多源异构数据是“开放数据”而非“孤岛数据”。从来源渠道和类别形态而言,多源异构数据具有很强的共享性、开放性、融合性。这不仅有利于侦查人员实现后续运算挖掘的过程重现和结果引用,而且还有利于其对多源异构数据进行运算平台设计、挖掘流程构建等,从而提升机器学习数据情报侦查预测的优质性。
(三)情报预测分法:从传统回归向机器学习转型
传统数据情报侦查预测主要是将数据犯罪情势中的因变量和自变量通过降维进行回归简化挖掘,往往存在不同侦查中主体被过度降维简化的现象,造成所获取的数据情报侦查预测存在效果偏差或结果失真等现象。然而,机器学习数据情报侦查预测能够充分发挥机器学习算法的价值优势,通过模拟侦查人员的数据情报侦查思维和认知策略,实现对多源异构数据运算挖掘的自我“训练”和“学习”,极大提升了机器学习数据情报侦查预测的精准性。同时,机器学习数据情报侦查预测还有利于侦查人员实现对数据犯罪情势中“犯罪因果推断”的预测。“反事实因果”是推断挖掘数据犯罪情势中各变量之间关联规则的重要依据,如果在数据情报侦查预测中“反事实”与“事实”两者存在明显的差异性,那么就说明数据犯罪情势中结果变量与条件变量之间存在关联规则。因此,机器学习数据情报侦查预测就能够通过机器学习算法对“全量数据”进行挖掘和构建“反事实因果”推断的关联平台,从而提升对数据犯罪情势中因变量与自变量因果关联预测的客观性。
(四)情报预测模式:从单一模式向多元融合模式转型
首先,机器学习数据情报侦查预测能够将传统的统计分析与支持向量机等机器学习算法进行融合。传统的统计分析预测模式有利于侦查人员采取线性的统计挖掘模型对侦查假设展开验证,而机器学习算法则有利于侦查人员对数据犯罪情势中具有相关性、描述性等非线性关联规则进行运算挖掘,有助于互补实现对数据犯罪情势发展规律的整体预测。其次,将大数据与小数据有机融合。侦查人员通过利用海量大数据的系列性特征来实现对数据犯罪情势的关联规则构建,更加侧重于从整体性、全局性、宏观性的预测研判。最后,将犯罪因果推断与数据关联挖掘融合。犯罪因果推断与数据关联挖掘是开展机器学习数据情报侦查预测的基础,传统数据情报侦查预测侧重于对犯罪因果推断的分析③参见王梦瑶、陈刚:《大数据时代犯罪与侦查动态发展研究》,载《山东警察学院学报》2017 年第2 期,第74-80 页。,而机器学习数据情报侦查预测不仅侧重于对数据犯罪情势的数据关联挖掘,而且还兼顾对犯罪因果推断的分析研判。
二、机器学习数据情报侦查预测的框架与模式
为增强实现机器学习数据情报侦查预测的转型价值,依据机器学习的运算优势和数据情报侦查预测的特殊价值需求,提出机器学习数据情报侦查预测的框架与模式。这不仅能够提升对多源异构数据情报运算挖掘的客观性和精准性,而且还能够消除和减少数据情报侦查预测的偏差率。
(一)机器学习数据情报侦查预测的框架
机器学习数据情报侦查预测的框架不仅能满足机器学习数据情报侦查预测转型价值的整体、全局性要求,而且还是构建机器学习数据情报侦查预测模式的支撑和保障。基于此,可将机器学习数据情报侦查预测的框架自下而上具体分为预处理和融合、流程模型构建等三个模块(见图1)。
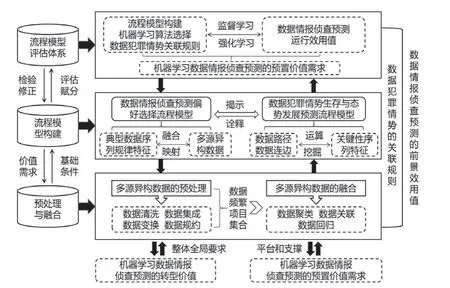
图1 机器学习数据情报侦查预测的框架图
1.预处理和融合。预处理和融合主要包括两个方面:一方面,多源异构数据的预处理。多源异构数据的预处理主要是指对多源异构数据进行数据清洗、数据集成、数据变换以及数据规约等处理,其中数据清洗主要是对多源异构数据中的异常数据和缺失数据进行处理,数据集成主要用于过滤识别多源异构数据中的冗余数据、重复数据等,数据变换主要是对各多源异构数据进行数据管理的规范化处理,而数据规约则是指对多源异构数据所进行的数据属性约减。另一方面,多源异构数据的融合。多源异构数据的融合主要是指采取数据聚类、数据关联、数据回归等机器学习算法对经过预处理后的多源异构数据进行数据频繁项目集合构建④参见张明宝、秦琪:《大数据环境下基于分工协作的情报系统构建方法研究》,载《情报杂志》2022 年第2 期,第29-34 页。。
2.流程模型构建。为了提升挖掘多源异构数据与数据犯罪情势之间潜在关联规则的精确性,可将机器学习数据情报侦查预测的流程模型构建为数据情报侦查预测偏好选择流程模型和数据犯罪情势生存与态势发展预测流程模型两部分。
一方面,数据情报侦查预测偏好选择流程模型。侦查人员借助于监督学习的机器学习算法从异构多源数据的结构属性、犯罪嫌疑人的数据心理画像、数据犯罪情势的历史规律等方面提取具有典型的规律特征,再利用数据仓库中的多源异构数据与其进行融合映射,以此来构建数据情报侦查预测的偏好选择流程模型。同时,根据案情需要更新的预置数据情报侦查预测价值需求,侦查人员可将其及时融入数据情报侦查预测偏好选择流程模型中,进而帮助其改善数据情报侦查预测的预置价值需求与数据犯罪情势发展之间的结构失衡性。
另一方面,数据犯罪情势生存与态势发展预测流程模型。侦查人员可利用机器学习算法对多源异构数据中各数据路径、数据连边、数据加权权重等进行深度挖掘,帮助其及时掌握多源异构数据的不同结构特征。将多源异构数据中不同结构特征提取出来形成机器学习运算挖掘的关键性序列特征,从而揭示不同数据犯罪情势生存与态势发展的趋势规律。同时,为增强构建数据犯罪情势生存与态势发展预测流程模型的客观性,侦查人员还可将多源异构数据的生命周期、数据犯罪情势的耗散、运算挖掘的加权权重等相关因素加入其中,帮助其构建更加具有正向同配属性关系的预测流程模型。
3.流程模型评估体系。流程模型评估体系主要是指侦查人员利用机器学习算法来评估数据情报侦查预测在实践中的运行效果,也是对机器学习算法优势与数据情报侦查预测价值需求互相融合的必要反馈。只有经过评估之后,才能够准确判断流程模型构建、机器学习算法选择、数据犯罪情势的关联规则构建等是否符合机器学习数据情报侦查预测的价值需求。诚然,流程模型评估体系的核心是利用机器学习算法在数据运算挖掘、数据模型构建等方面的运算优势,检验数据情报侦查预测偏好选择流程模型和数据犯罪情势生存与态势发展预测流程模型构建等的准确性,再利用监督学习和强化学习等机器学习算法检验评估数据情报侦查预置价值需求的合理性等。
(二)机器学习数据情报侦查预测的模式
为缓解数据情报侦查预测的决策僵局和提高数据情报挖掘的差分隐私,可将机器学习数据情报侦查预测的模式自上而下构建为数据情报侦查预测偏好选择模式、数据犯罪情势生存与态势发展规律模式、数据运算挖掘选择模式三个部分(见图2)。
第一,数据情报侦查预测偏好选择模式。数据情报侦查预测偏好选择模式主要是以数据情报侦查预测的预置价值需求为切入点,依据不同数据犯罪情势之间的关联规则,识别和提取不同数据情报侦查预测的预置价值需求、时空序列矩阵、函数权重系数以及因果关联概率等数据序列特征。同时,侦查人员还可及时挖掘获取不同数据情报侦查预测的益损决策矩阵、损失规避与偏好反转、多属性权重概率等深层次的隐性目标,进而帮助其实现预测价值需求触发概率、数据情报侦查情势发展态势、情报关联规则模型构建等偏好选择的应用效果⑤参见薛亚龙、刘梓泞:《基于前景理论的数据情报侦查决策研究》,载《中国人民警察大学学报》2022 年第10 期,第5-11+18 页。。显然,数据情报侦查预测偏好选择模式重点是关注如何运算挖掘数据情报侦查预测的各种显性或潜在的预置价值需求,然后利用不同机器学习算法构建科学准确的偏好选择模式。
第二,数据犯罪情势生存与态势发展规律模式。数据犯罪情势生存与态势发展规律模式主要是以数据犯罪情势为逻辑起点,以结构型数据、非结构型数据、异构型数据等传统型数据和定类型数据、定序型数据、定比型数据等新型类数据的多源异构数据为基础,运算挖掘数据犯罪主体、数据犯罪时空、数据犯罪热点矩阵以及数据犯罪关联聚类规则和数据犯罪因果映射等数据犯罪情势的生存与态势发展规律。侦查人员借助不同机器学习算法的运算优势,深入挖掘多源异构数据与数据犯罪情势之间潜在的各种关联规则,再利用机器学习算法构建数据犯罪情势生存与态势发展的预测流程模型,从而帮助其挖掘数据犯罪情势的触发概率、数据犯罪情势的辐射蔓延以及数据犯罪情势发展的不平衡结构等发展规律。
第三,数据运算挖掘选择模式。数据运算挖掘选择模式主要是针对不同数据情报侦查预测的预置价值需求,抽象出需要运用不同机器学习算法进行解决的运算问题,进而帮助侦查人员选择和确定最佳的机器学习运算挖掘算法。首先,按照流程模型构建的框架要求选择相适应的机器学习算法。其中,无监督学习的机器学习算法包括分层聚类算法、K 均值算法、离群异值分解算法等,而监督学习的机器学习算法则主要有人工神经网络、决策树算法、贝叶斯分类算法等⑥参见商城、康沛林、刘智攀:《基于机器学习势函数的原子模拟软件的开发及应用》,载《硅酸盐学报》2023 年第2 期,第476-487 页。。其次,根据选择的机器学习算法对多源异构数据展开运算挖掘,重点挖掘数据距离、数据连边、数据路径以及数据加权权重等数据序列特征,并形成数据运算挖掘所需的数据训练集。再次,利用机器学习算法分别对数据情报侦查预测偏好选择流程、数据犯罪情势生存与态势发展预测流程以及流程模型评估等进行运算训练,直到所有运算训练全部符合机器学习数据情报侦查预测的评价指标参数为止。最后,依据机器学习对数据训练集的运算结果,构建机器学习算法的数据测试集,并将其运算结果应用于数据情报侦查预测即可。
三、机器学习数据情报侦查预测的评价指标
由于易受到多源异构数据的类别形态、机器学习算法的选取优势、数据情报侦查预测的预置价值需求等主客观条件的影响,为增强机器学习数据情报侦查预测的客观性和精确性,迫切需要构建机器学习数据情报侦查预测的评价指标。这不仅对构建机器学习数据情报侦查预测的框架与模式具有修正的检验作用,而且还对探讨机器学习数据情报侦查预测的应用方法具有验证的反馈价值。
(一)敏感度分析评价指标
敏感度分析评价指标主要应用于对机器学习数据情报侦查预测的结果解释,是被建立在机器学习数据情报侦查预测框架与模式的局部变量测量或局部梯度评估之中。如果侦查人员挖掘获取数据情报侦查预测的梯度值越接近关联规则的指标系数,那么所获得结果就越符合数据情报侦查预测的价值需求,并且还能解释机器学习算法中梯度函数、变量函数以及解释函数等之间的敏感度。同时,侦查人员还可引入基于贝叶斯分类器的敏感度分析评价指标。在贝叶斯分类器的敏感度分析评价指标中,解释函数与解释向量的运算维度都是相同的,且数据分类器还将多源异构数据划分为不同的挖掘变量。其中,解释向量在每个多源异构数据上都被预定义为独立的向量场,该向量场代表数据情报侦查预测的不同预置价值需求,从而帮助侦查人员解释机器学习数据情报侦查预测的运行结果。
(二)模型评价指标
模型评价指标主要包括数据情报侦查预测的查准率、查全率、灵敏率以及特效率和整体准确率所构成的混淆评价矩阵⑦参见卫安妮、赵宁、张志坚:《基于机器学习对串联排队系统等待时间的预测》,载《西南师范大学学报(自然科学版)》2022 年第12 期,第11-21 页。。在模型评价指标中,机器学习数据情报侦查预测的查准率与查全率、灵敏率与特效率均属于反向异配属性关系。为提高模型评价指标的精准性,侦查人员可将机器学习数据情报侦查预测的查全率和查准率分别设为横轴、纵轴,然后结合数据犯罪情势生存与态势发展预测流程模型的查准率与查全率、灵敏率与特效率所占比,运算机器学习数据情报侦查预测的查准率与查全率曲线,即P-R 曲线。然而,在实际的模型评价过程中,机器学习数据情报侦查预测的应变量评价指标会产生一个预测概率系数,需将其与提前预置的分类阈值进行比较。如果预测概率系数大于预置的分类阈值,那么说明所获数据情报侦查预测的结果为正例现象;反之,则属于反例现象。
(三)风险预测指数评价指标
为实现机器学习数据情报侦查预测的定性与定量评价分析,侦查人员可将风险预测指数评价指标表示为,其中Wb表示机器学习数据情报侦查预测的稳定基准值,t表示采取机器学习算法挖掘数据情报侦查预测的收敛耗时,Wtotal表示机器学习数据情报侦查预测的输出指数,M 表示机器学习数据情报侦查预测的预置价值需求。同时,为强化风险预测指数评价指标的精确性,侦查人员还可利用机器学习算法对风险预测指数评价指标的获取过程进行迭代运算,从而获得风险预测指数评价指标的加权权重系数。显然,侦查人员可根据机器学习数据情报侦查预测中存在的不同风险预测类别,通过运算风险预测指数评价指标的加权权重系数,便可获得具有精确性的风险预测指数评价指标。
(四)回归模型性能评价指标
其一,将机器学习数据情报侦查预测的阈值分为预测值和真实值两部分,并利用不同机器学习算法对选择决定系数、平均绝对误差、开方均方误差等评价系数进行运算挖掘。其二,预置性能评价指标系数。将选择决定系数的最大阈值设为1,越接近1 就说明机器学习数据情报侦查预测的质量和可信度越优。例如,支持向量回归和人工神经网络算法的选择决定系数均在0.9 以上,就说明二者的性能可信度高,且二者的MAE 值、RMSE 值等评价指标也很优越。如果在回归模型性能评价指标中MAE 值、RMSE 值的阈值偏差越小,那么就说明机器学习数据情报侦查预测的运行结果越接近于应然价值。显然,回归模型性能评价指标具有很强的拟合性。这不仅有利于增强机器学习数据情报侦查预测的精确度,而且还有利于提升其算法预测的高可信度。
四、机器学习数据情报侦查预测的应用方法
机器学习数据情报侦查预测的实质是通过机器学习算法挖掘多源异构数据与数据犯罪情势之间潜在的各种关联规则,帮助侦查人员精准掌握数据犯罪情势生存与态势发展的趋势规律,从而实现机器学习算法引导数据情报侦查预测的一种新型数据情报侦查方法。这不仅能够帮助侦查人员降低对多源异构数据情报挖掘研判的过拟合现象,增强挖掘数据犯罪情势关联数理关系的精确性,而且还能够帮助其降低数据情报侦查预测的偏差率和提升机器学习循证数据情报侦查预测的鲁棒性,创新和拓展打击数据犯罪情势的全链条侦查模式。
(一)深度神经网络算法
深度神经网络算法主要是依据不同数据的层次序列特征,运算挖掘各数据个体所对应神经网络模型的加权权重和阈值指标,从而获得两者之间亲和浓度的一种机器学习算法⑧参见刘继承、吴昊、王文伟,等:《结合深度神经网络的特征选择算法研究》,载《武汉理工大学学报(信息与管理工程版)》2023 年第1 期,第49-53+60 页。。
首先,获取数据惯性权值和形成预测抗体群。侦查人员需利用粒子群的更新运算方式预置多源异构数据的数据惯性权值和数据情报侦查预测的粒子维度,形成数据情报侦查预测的抗体群。其次,计算预测亲和浓度。采取预测删除和预测增值的方式对预测抗体群进行迭代处理,再利用粒子群优化算法挖掘获取不同数据情报侦查预测的亲和浓度。再次,高变异克隆处理。侦查人员可采用抗体复制和高亲和力的方法对数据情报侦查预测的粒子个体进行高维变异处理,再利用人工免疫算法对其变异程度的系数进行运算挖掘,进而获取不同数据情报侦查预测的正负高斯函数。最后,获取最佳预测效益值。对不同数据情报侦查预测的正负高斯函数进行全局性的搜索和降维排序,如果输出的结果为全局性最佳数据情报侦查预测,那么结束运算;反之,则需要从重新计算预测亲和浓度,直至所有多源异构数据被迭代运算结束为止。显然,深度神经网络算法不仅能够帮助侦查人员充分挖掘不同多源异构数据的数据惯性权值,而且还能够帮助其快速获取不同数据情报侦查预测的前景效益值,从而提升机器学习数据情报侦查预测的收敛速度。
(二)融合蚁群算法
融合蚁群算法主要是通过选取确定需要进行挖掘的目标数据,利用数据主成分算法对目标数据进行数据区域属性的关联聚类,进而挖掘获取不同目标数据之间关联规则的一种分布式机器学习算法。
第一,构建数据仓库。先对各种多源异构数据采取数据集成和数据规约等预处理,根据数据频繁项目的聚类属性将其存储到数据仓库中。第二,数据主成分运算。侦查人员可利用SPSS 软件对数据仓库中不同目标数据进行数据主成分挖掘分析,重点关注重复数据、冗余数据、离群数据等异常数据的成分构成⑨参见张怡平、金文玲、董晨昱,等:《用于高维时序数据预测的非同步尺度主成分分析》,载《山西大学学报(自然科学版)》2023 年第2 期,第321-325 页。。鉴于不同多源数据在类别形态等方面的差异性,侦查人员需将其进行融合转换,使其形成统一标准的数据规约格式,然后再采取数据主成分的运算挖掘。第三,测算关联目标路径阈值。侦查人员需先构建一个多源异构数据与数据犯罪情势之间的关联规则库,以其坐标中心为数据情报侦查预测的关联目标,挖掘不同多源异构数据与关联目标之间的路径阈值。第四,预设数据蚁群系数阈值。为提升融合蚁群算法挖掘数据情报侦查预测的精确性,需将数据蚁群系数a 和b 的阈值区间设定为[0,1]。第五,获取预测选择概率。侦查人员需将多源异构数据的亲和浓度设为1,利用蚁群算法中蚂蚁觅食的原理挖掘最佳数据情报侦查预测的选择概率⑩参见圣文顺、徐爱萍、徐刘晶:《基于蚁群算法与遗传算法的TSP 路径规划仿真》,载《计算机仿真》2022 年第12期,第398-402+412 页。,增强机器学习数据情报侦查预测运行效果的正向同配属性。第六,预测评估与修正。侦查人员可利用XpertRule Miner 软件对获取的数据情报侦查预测结果进行评估与修正,如果结果为正向同配属性关系,那么就说明符合机器学习数据情报侦查预测的价值需求;反之,则需返回至第二步重新运算挖掘,直至所有多源异构数据被迭代运算结束为止。
(三)AHP 权重决策树算法
AHP 权重决策树算法主要是依据不同数据迭代运算关联的决策树结构性规则,通过运算分析不同数据之间的关联挖掘矩阵,从而获取全局最佳数据决策优解的一种权向量机器学习算法⑪参见高虹雷、门昌骞、王文剑:《多核贝叶斯优化的模型决策树算法》,载《国防科技大学学报》2022 年第3 期,第67-76 页。。
第一,预置预测层次目标。侦查人员需将机器学习数据情报侦查预测的预置价值需求进行目标分解,使其形成数据情报侦查预测的层次目标。第二,构建预测层级体系。为使运算挖掘结果与预测的层次目标具有正向同配的属性关系,依据多源异构数据与数据犯罪情势之间的关联规则,需将预测的层次目标再分解为不同的层级体系。第三,构建预测的挖掘矩阵。依据数据情报侦查预测层次目标和层级体系的不同价值作用,侦查人员需将两者进行分别评价赋分,并构建以多源异构数据为核心的数据情报侦查预测挖掘矩阵。第四,优化AHP 权重参数。在对多源异构数据进行决策树生成和决策树修剪过程中⑫参见于安池、储茂祥、杨永辉,等:《具有强化学习策略的决策树算法》,载《合肥工业大学学报(自然科学版)》2021 年第5 期,第616-620 页。,往往会出现数据情报侦查预测的局部最优解现象。第五,获取预测的判断矩阵。依据优化后的AHP 权重参数,侦查人员可利用函数公式对不同多源异构数据进行聚类挖掘,进而获取不同数据情报侦查预测的判断矩阵。第六,检验和优化预测结果。一方面,检验数据情报侦查预测结果与其预置价值需求之间的关系,重点检验两者是否存在正向同配属性关系;另一方面,将数据情报侦查预测结果与数据犯罪情势关联规则、数据情报侦查预测判断矩阵等进行比较,如果存在局部偏差或全局差异,那么就需要及时进行修正和优化。
(四)图卷积网络多源算法
图卷积网络多源算法主要是通过对多源异构数据中不同数据节点相似度进行卷积运算挖掘的一种网络机器学习算法,具有运算鲁棒性强、挖掘收敛速度快等价值优势。
第一,数据预处理。侦查人员需先对多源异构数据采取数据集成和数据规约等预处理,使其形成数据频繁项目集合的标准RDF 格式。第二,构建数据运算挖掘拓扑图。以数据频繁项目集合的标准RDF 格式为基础,侦查人员可利用多源稀疏数据矩阵来挖掘多源异构数据中不同数据节点之间的加权权重系数,进而构建具有正向型属性的数据运算挖掘拓扑图。第三,计算数据实例化张量。对已构建的多源异构数据运算挖掘拓扑图采取实例化张量计算,计算重点包括数据节点相似度、数据节点矩阵、数据节点标签等。第四,构建图卷积网络多源算法模型。为避免出现局部最优解、数据过拟合等异常现象,侦查人员选取LeakyRelu 算法对多源异构数据进行非线性运算挖掘,再利用Softmax 函数公式对其进行图卷积网络多源算法模型构建,进而提升图卷积网络多源算法挖掘的客观性。第五,构建数据训练集。依据多源异构数据实例化张量的计算结果,将其输入到已构建的图卷积网络多源算法模型中,并以其相邻矩阵和特征矩阵为主要依据构建数据频繁项目聚类集,所获结果即为所需的数据训练集。第六,运算数据测试集。依据数据情报侦查预测的相邻矩阵和特征矩阵结果,侦查人员需要将各种多源异构数据分别代入数据测试集进行运算挖掘,重点挖掘不同多源异构数据与数据犯罪情势之间潜在的关联规则,输出结果即为数据情报侦查预测的挖掘结果。
(五)量子机器进化算法
量子机器进化算法主要是利用量子比特算法挖掘分析不同多源异构数据之间的概率幅阈值,使其相互之间能够被快速地叠加融合,从而解决关联规则构建复杂、模糊优势关系差值少等的一种综合性机器学习算法。
(六)异构传感融合目标算法
异构传感融合目标算法主要是通过提取数据空间特征、数据阈值变换特征等多源异构数据的目标序列特征,从而挖掘和揭示不同多源异构数据目标特征本质属性的一种融合性机器学习算法。
首先,多源异构数据融合。多源异构数据融合包括多源异构数据的目标特性融合和目标状态融合两部分⑬参见赵春霞、赵营颖、宋学坤:《基于频繁项集的多源异构数据并行聚类算法》,载《济南大学学报(自然科学版)》2022 年第4 期,第440-443+451 页。,侦查人员需先采取数据集成和数据规约等数据预处理技术对多源异构数据进行数据清洗,再利用数据传感跟踪技术挖掘不同多源异构数据之间的目标特性和目标状态,并将两者按照数据传感跟踪关联规则进行交互融合⑭参见刘运:《基于循环神经网络的多源异构大数据融合模型构建》,载《内蒙古民族大学学报(自然科学版)》2021 年第3 期,第204-210 页。。其次,提取数据目标序列特征。侦查人员可采取直方图频谱、傅里叶频谱、图像灰度频谱等数据目标特征技术,运算挖掘不同多源异构数据之间的数据识别目标特征和数据阈值变换特征等数据目标序列特征⑮参见隗寒冰、白林:《基于多源异构信息融合的智能汽车目标检测算法》,载《重庆交通大学学报(自然科学版)》2021 年第8 期,第140-149 页。,促使每一个不同数据目标序列特征都至少包含一个与其他数据目标序列特征存在本质差异的描述属性。再次,计算数据情报侦查预测权重概率。侦查人员可采取目标冲突阈值来对不同数据情报侦查预测的权重概率进行检验评估,如果二者之间的权重概率目标冲突阈值差异较大,那么差异较大的一方为最佳数据情报侦查预测;如果二者之间权重概率的目标冲突阈值相同或接近,那么则需采取关联聚类的权重冲突融合处理即可。最后,数据情报侦查预测修正。为确保数据情报侦查预测结果的精确性,必然需要对其进行反复的检验和修正。侦查人员对利用异构传感融合目标算法挖掘获取的不同数据情报侦查预测经过运行检验,重点对多源异构数据融合、数据目标序列特征挖掘、数据情报侦查预测权重概率等进行检验和修正,进而确保机器学习数据情报侦查预测的客观性和准确性。因此,异构传感融合目标算法不仅能够帮助侦查人员缩短机器学习数据情报侦查预测预置价值与运行效果之间的差异性,而且还能够全面提升机器学习数据情报侦查预测的精确性和鲁棒性。
