基于ALBERT的网络威胁情报命名实体识别
2023-03-04周景贤王曾琪
周景贤,王曾琪
(1.中国民航大学 科技创新研究院, 天津 300300;2.中国民航大学 计算机科学与技术学院, 天津 300300)
0 引言
网络威胁情报(Cyber Threat Intelligence,CTI)用于描述已经发生的网络攻击活动,它包含的攻击信息能够为当前网络防御提供帮助[1,2].在对时效要求非常高的网络安全防御中,人工分析CTI已远远不能满足其需求.近年来自然语言处理的发展令人瞩目,其中命名实体识别(Named Entity Recognition,NER)[3]用于对文本中具有特殊含义的词汇进行识别,将网络威胁情报分析与命名实体识别结合能够极大提升情报分析工作的效率.
目前命名实体识别方法主要有三种:基于规则和字典模板方法、基于机器学习方法以及基于深度学习的网络模型方法.基于规则和字典模板的方法[4]依赖于专家手动编写的规则,只能用于指定规则的特定领域,识别精度低,耗费人工和时间成本.基于机器学习的方法改善了特征工程方法依赖专家建立规则的状况,对人名、地名和组织三类传统实体识别精度达到80%以上[5-7].与机器学习相比,深度学习将命名实体识别定义为序列标注任务,该方法能够自动提取特征并且具有更好的泛化能力.Lample G等[8]提出将双向长短期记忆网络(Bidirectional Long-Short Term Memory,BiLSTM)与条件随机场(Conditional Random Field,CRF)结合组成BiLSTM-CRF神经网络模型.然而神经网络模型不能很好地表达字符级特征,Qiu Q等使用Word2Vec、Skip-Gram等词嵌入模型与BiLSTM-CRF结合的方法并将其应用于NER[9,10].
为了更好的理解上下文信息,并根据文本信息使单词获得动态语法和语义信息特征,学习文本中单词的多义性.Devlin J等[11]提出预训练语言模型BERT(Bidirectional Encoder Representations from Transformers),模型使用双向Transformer编码器作为特征提取器.但BERT模型参数过多,训练模型难度越来越大,时间和资源得到了很大的浪费.Lan Z等[12]提出了BERT的简化版模型ALBERT(A Lite BERT)通过优化参数来解决这个问题.
不同于通用领域的命名实体识别只对文本中人名、地名和组织进行识别,网络威胁情报需要识别多种威胁实体(例如黑客组织、恶意工具、攻击目的等)才能够得到完整的攻击链[13].但专业领域实体识别需要大量人工标注领域数据集,成本高,且识别精度低难度大.而深度学习具有自学习的特点,可通过少量标注数据集自学习实体特征而有效提取实体[14-16].在网络安全研究中虽然已有部分研究文献构建与网络安全领域相关的数据集,但都无法应用于网络威胁情报实体识别[17,18].
综上所述,针对传统词嵌入不能很好的表示单词多义性以及领域特征提取不足难以有效识别威胁实体信息问题.本文一方面融合ALBERT和BiLSTM-CRF提出一种面向网络威胁情报的命名实体识别模型;另一方面根据专业的领域知识并结合实际情况,人工收集并标注了一个网络威胁情报数据集(Cti-E)用于模型的特征学习及训练,以解决模型训练时词向量不足的问题.
1 ALBERT-BiLSTM-CRF模型
为了对网络威胁情报领域进行准确的命名实体识别,本文提出了网络威胁情报命名实体识别模型——ALBERT-BiLSTM-CRF(CTI-ALBC)模型.该模型分为四部分,从下到上分别为ALBERT层、BiLSTM层、Attention层和CRF层.
模型的输入是句子中的词,首先通过ALBERT在未标注的语料数据上进行训练,以提取结合了上下文句法和语义的特征信息,得到动态词向量.然后将词向量输入到BiLSTM对序列特征信息学习,之后Attention层对原始词向量和学习后的文本向量加权,最后通过CRF层进行校正,以得到概率最大的序列标签并输出.
模型的整体结构如图1所示.其中Attacks、began为输入的单词序列,X1,X2,…,Xn为ALBERT层输出向量,h1,h2,…,hn为BiLSTM层上下文表示向量,St为ht的向量加权值,a1,a2,…,an为注意力层的输出,0.3、0.9、0.6、0.1为模型的预测标签概率值,B-HackGro、B和O为模型预测结果的标签.
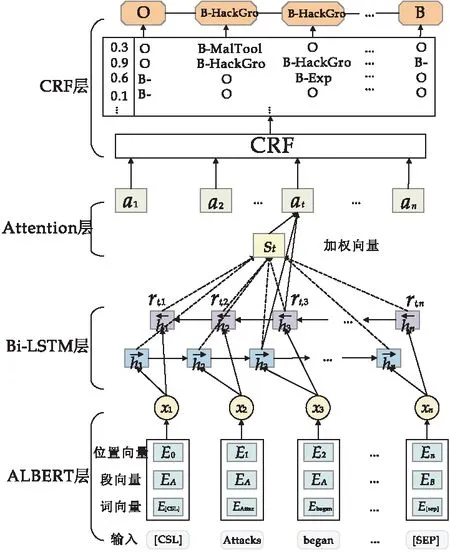
图1 ALBERT-BiLSTM-CRF模型
1.1 ALBERT预训练语言模型
词向量是将文本信息映射到一个连续的低维空间,从而获得相应的语义信息和句法特征.词向量模型是一种将抽象文本转化为可以用公式计算的向量的工具,对输入文本数据进行向量化.Word2Vec、Glove[19]、ELMo[20]等传统词嵌入模型只能表示固定词向量,无法很好地表示词的多义性.在网络威胁情报领域,同一个词语在不同的语境中常常存在不同的含义,如“蠕虫”表示为一种常见的计算机病毒,因此本文引入预训练语言模型ALBERT可以有效减少单词表达歧义.
ALBERT是精简版BERT模型,与BERT的模型构造非常相似.ALBERT预训练模型使用多层的Transformer结构并加入Attention机制,对输入的语料进行无监督学习,得到蕴含大量威胁情报领域文本信息的特征向量.该向量能够更好地理解单词的含义以及句子丰富的句法和语义信息.模型的具体结构如图2所示.
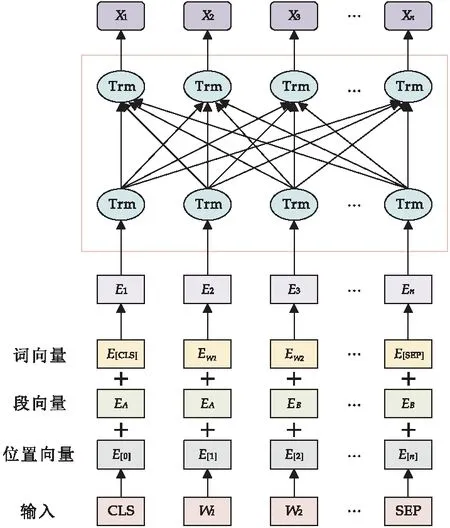
图2 ALBERT预训练语言模型
1.1.1 ALBERT输入表示
ALBERT中一个词的输入表示由三个部分组成,分别是词向量、段向量和位置向量.词向量是最重要的信息,根据维度生成一个词向量矩阵表示输入的单词,随着模型维度而改变;段向量在ALBERT中主要用于下一句预测任务,两句之间需要区分,因此开头用[CLS]符标记,在句尾加[SEP];由于Transformer模型无法记住时序,所以引入位置向量来标记位置信息.在图2中,E1,E2,…,En为字符向量表示,经过多个Transformer编码得到最后ALBERT的输出向量Xn.
1.1.2 Transformer结构
为融合单词左右两侧的上下文,ALBERT使用了一个双向转换编码器Transformer.
Transformer编码单元如图3所示,基于Self-Attention[21]对输入的文本信息编码以提取向量特征,是最重要的模块.计算公式如(1)所示:
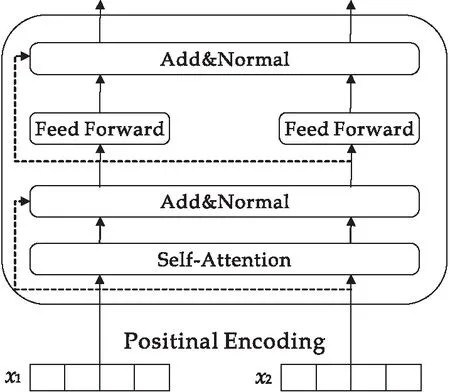
图3 Transformer编码单元
(1)
式(1)中:Q、K、V分别是查询向量、键向量和值向量,QKT用于计算Q在V上的注意力权重,最后对所有单词值向量进行加权求和.
另外,Transformer通过增加“Multi-Head”注意力机制,从两方面提高了注意力层的性能,分别是给注意力层多个“表示子空间”和扩展模型集中于不同位置的能力,如式(2)和式(3)所示,WO为附加权重矩阵:
MultiHead(Q,K,V)=
Concat(head1,…,headk)WO
(2)
(3)
此外,在Transformer中加入了残差网络和归一化层来改善退化问题:
(4)
FNN=max(0,xW1+b1)W2+b2
(5)
式(4)、(5)中:α和β是要学习的参数,μ是均值,σ是输入层的方差.
1.1.3 ALBERT改进
BERT模型可以提取更多的特征词向量,通过训练后得到非常高的精度,原因是它的模型参数很大,而且运行需要的GPU非常大且时间久.但对于词的分布式表示,往往并不需要这么高的维度.例如在网络威胁情报中使用词嵌入方法Word2Vec最多采用50或300的维度就可实现识别精度.因此ALBERT优化参数后,在有些公开数据集上训练的精度反而高于BERT[16,22],在本文第三章中也有相关对比实验.
ALBERT主要进行了三方面的改进:
(1)因式分解词嵌入参数:将词嵌入参数矩阵因式分解为两个小矩阵.先将单词向量V映射到低维空间E,再映射到高维隐藏空间H.BERT中E与H始终相等,但词向量不需要这么高的维度.通过因式分解能够将词嵌入参数从O(V×H)降低到O(V×E+E×H),当H≫E时,参数急剧减小,更高效的提升模型效率.原理如图4所示.
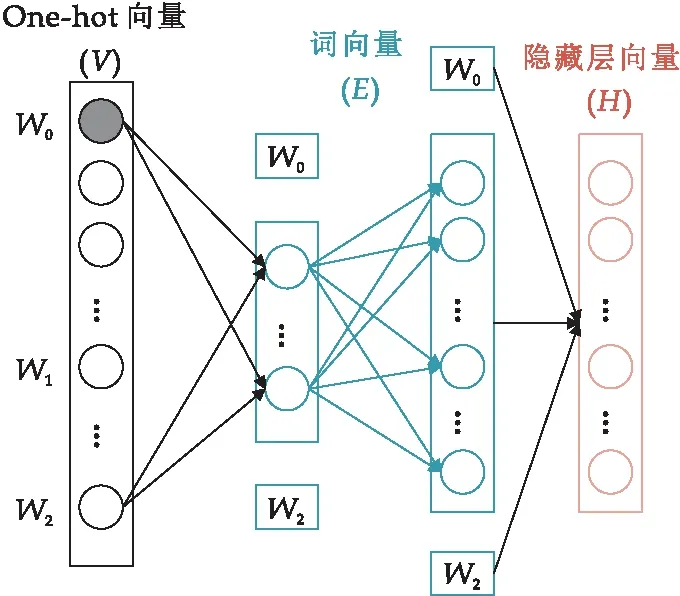
图4 因式分解词嵌入参数原理图
(2)用SOP(Sentence-order prediction)损失替换NSP(Next-sentence prediction)损失:相比NSP,SOP对于句子间语义关系的学习更加优秀.在替换为SOP损失后,模型对句子之间的连贯性更加关注,能够显著提升模型在下游编码任务中的性能.
(3)跨层参数共享:防止参数随着网络深度的加深而复杂.ALBERT采用Transformer共享全连接层和Attention层,也就是说它共享隐藏层的所有参数,Transformer采用这个方法后参数会少很多同时提升模型的训练速度.例如BERT_base隐藏层为12,ALBERT参数共享后变为一层,但各层之间参数仍相互独立.参数共享后能够有效减少模型参数量,在不显著影响模型性能的情况下提高了模型效率.参数量计算如公式(6)所示,其中L为参数层数量.
O(12×L×H×H)→O(12×H×H)
(6)
ALBERT大幅度减少模型参数也只是略微或不减少模型训练精度,能够实现轻量化的网络威胁情报命名实体识别功能,综合加强了网络威胁情报命名实体识别能力.
1.2 BiLSTM
LSTM(Long Short-Term Memory,LSTM)[23]是专门为处理序列数据而提出的.通过门控概念实现长时记忆,解决了长序列带来的长期依赖问题,适用于网络威胁情报领域的命名实体识别.其结构如图5所示.

图5 LSTM单元结构图
LSTM中包含三个门结构:遗忘门、输入门和输出门.计算公式如下:
it=σ(Wixxt+Wihht-1+bi)
(7)
ft=σ(Wfxxt+Wfhht-1+bf)
(8)
ot=σ(Woxxt+Wohht-1+bo)
(9)
(10)
ht=ot⊗tanh(ct)
(11)
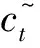

(12)
1.3 Attention层
BiLSTM在处理较长的网络威胁情报时,仍然存在语义信息丢失的问题.将BiLSTM与注意力结合,当前处理的单词与句子中的所有词对齐后,对结果进行归一化得到每个词的权重,能有效突出关键词在文本数据中的作用.引入注意矩阵A来计算当前目标向量与序列中所有向量之间的关系,将当前目标向量xt与序列中第j个向量xj进行比较,得到注意矩阵中的注意权重向量rt,j.
(13)
f(xt,xj)=Wa(xt-xj)T(xt-xj)
(14)
(15)
at=func(Wr[rt∶hj])
(16)
式(13)~(16)中:Wa是模型的权重矩阵,st为加权向量,at为注意力层的输出.
1.4 CRF层
命名实体识别任务中,BiLSTM只输出标签中得分最高的序列标签,而忽略了标签之间存在很强的依赖性.在CTI-ALBC模型中,CRF网络位于末端作为序列标记层,并输出对应的单个字符的序列标签.CRF充分考虑了句子上下文的相关性,保证了序列标注的准确性.假设输入序列为X(x1,x2,…,xn),对应的模型预测标签序列为Y(y1,y2,…,yn),那么标签Y为X的正确标签的得分为S.
(17)
Y*=argmaxS(X,Y)
(18)
2 数据标注及评估方法
2.1 数据收集
与一般领域的命名实体识别不同,网络威胁情报缺乏大规模公开可用的数据集和标注方法.因此,本文使用爬虫工具从全球多家网络安全公司、政府机构网站等开源威胁情报网站收集和分析了200多份威胁情报报告.每一份威胁情报报告均由全球知名安全公司或政府机构发布,在对报告清洗并删除了不可用的部分实体(例如页码、注释和水印等)后,由具有丰富网络安全知识的领域专家进行分析和标注,以确保标注数据集的质量.该数据集共包含65 885个单词,可用于开发和评估威胁情报领域的其他人工智能模型,比如信息提取、知识图谱等.在本文中用于威胁情报领域的命名实体识别模型评估.
2.2 数据标注
本文使用Brat Rapid Annotation Tool(Brat)来标注威胁情报,这是一种基于Web的文本标注工具,并选择了文本标注领域的行业标准标注形式BIO标注.对于威胁情报中的每个实体,将实体的第一个单词标记为“B-实体类型”,第二个及以后的单词标记为“I-实体类型”,没有实体的标记为“O”.由于pdf上有很多不规则的数据或网页广告,在标注数据之前,先对收集的数据进行预处理,删除网页上非必要的信息,然后转化为文本格式,之后对每个单词进行标记.例如“32-bit Windows executable”为恶意工具,B-MalTool和I-MalTool用于标记该词属于MalTool类别,且“B-”为第一个单词而“I-”为非第一个的单词.图6为使用Brat的标注过程,表1为威胁情报标注样本,图7为网络威胁情报数据集部分标注结果.
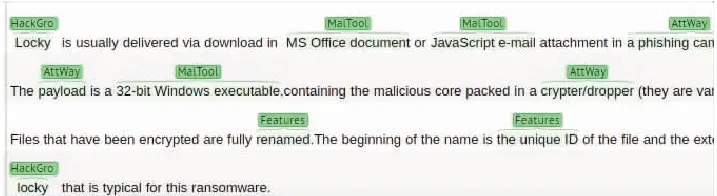
图6 Brat标注工具

表1 威胁情报标注样本

图7 网络威胁情报标注结果
2.3 数据集统计
根据网络威胁情报的特点和领域专家的经验知识,结合威胁情报标准STIX[24].本文在数据集中选择并标注了9个类别,包括黑客组织、攻击、网络安全团队、恶意工具、目的、行业、攻击方式、漏洞、特征,这些类别能够很好的描述威胁情报以及情报中蕴含的信息.这9个类别在数据集中对应的标签分别是HackGro、Att、SecResTeam、MalTool、Purp、Idus、AttWay、Exp、Features.表2为部分实体对应的标签及描述示例.
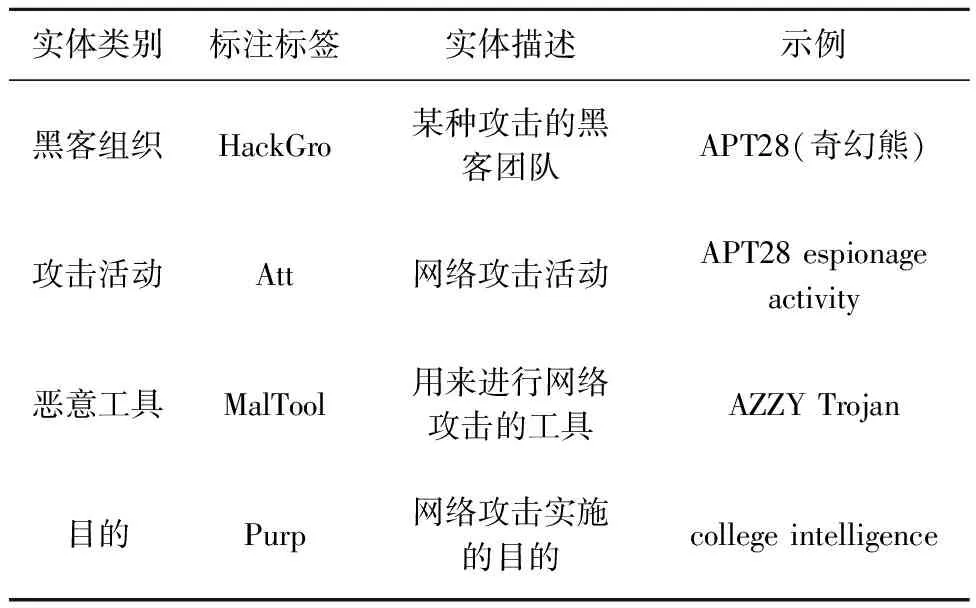
表2 部分实体对应的标签及描述示例
将本文标注数据集(Cti-E)与Honeynet数据集进行比较,后者是一个相对成熟的数据集,用于反应黑客的攻击模式,包括攻击行为、攻击时间、攻击目的等.其中Honeynet数据集中的“Entity”在本文数据集中细分为“HackGro”和“Att”,“Action”细分为“Purp”和“AttWay”,“Modifier”是一些没有意义的动词或词组,没有什么价值.本文所标注的数据集不仅在类别数量上超过Honeynet,在每个类别的实例数量上也有所增加.Honeynet数据集主要用于小范围黑客攻击的机器学习,而本文提供的数据集在此基础上进行了学习和补充,并将其用于威胁情报领域的机器学习.两个数据集中每个实体的类型和数量如图8所示.
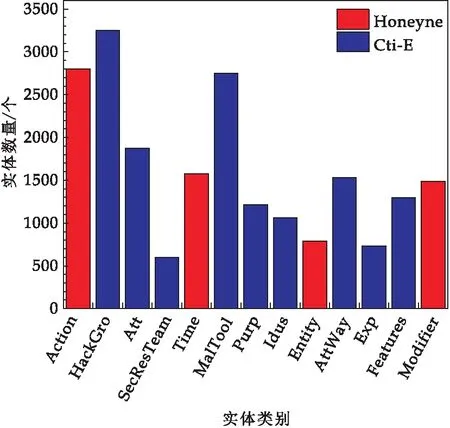
图8 两个数据集中每个实体的类型和数量
本文标注的数据集中有65 885个词汇,所有实体分为9类,共19种标签类型.其中,O标签实体51 588个,非O标签实体14 297个,带有非O标签的实体占总词汇量的21.7%.每个标签的具体数量如表3所示.

表3 每个标签的具体数量
2.4 评估方法
本文采用准确率(P)、召回率(R)和F1分数作为衡量识别性能的指标.具体评估指标的计算公式如下:
(19)
(20)
(21)
3 实验结果与分析
3.1 实验设计及参数
模型CTI-ALBC流程如图9所示.首先使用爬虫工具爬取威胁情报,然后进行数据清洗,将不需要的信息删除整理,形成所需的威胁情报数据集.接着使用专业知识对数据集实体标注,共分为9类.为了保证训练数据和测试数据的分布近似匹配,随机选择原始文本的70%作为训练集,15%作为验证集,15%作为测试集.之后将通过ALBERT模型后得到的预训练字符向量输入BiLSTM和CRF模型最后输出最佳预测标签.
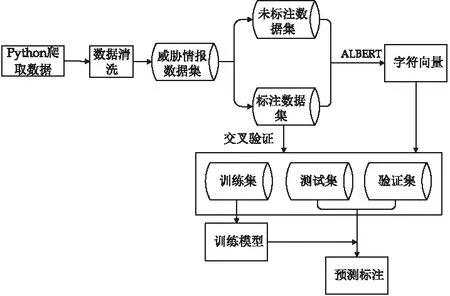
图9 模型CTI-ALBC实验流程
在模型的实验参数上,采用了ALBERT预训练语言模型,它包含12层、768个隐藏维度、12个注意力头和12 M参数.此外,使用Adam作为模型优化器,最大序列长度设置为128,隐藏单元的数量设置为128,学习率设置为0.001,Dropout设置为0.5,Clip设置为5,Batch_size大小为32.模型算法训练过程在算法1中给出.

算法1 模型训练输入 X=(x1,x2,…,xn)输出 Y=(y1,y2,…,yn)1 for each epoch do2 for each batch do3 参数初始化;4 ALBERT模型正向传递字符级特征;5 BiLSTM-CRF模型前向传递和自动学习以提取特征;6 前向状态的前向传递;7 后向状态的正向传递;8 CRF向前和向后传递并计算序列的全局似然概率;9 BiLSTM-CRF模型反向传递;10 正向状态的反向传递;11 后向状态的后向传递;12 更新参数;13 end for14 end for
3.2 实验环境
本实验所采用的环境如表4所示.

表4 实验环境
3.3 实验结果
为了验证本文提出的CTI-ALBC模型在威胁情报领域命名实体识别上具有更优的性能,在本文自标注数据集上进行实验.同样的条件下对比模型均使用传统Word2Vec嵌入方法,而本文的联合模型使用BERT方法.为减少实验结果误差,将每个实验重复6次并计算平均值,实验结果如表5所示.从表5可以看出,对于P、R、F1和参数量,本文提出的模型取得了最好的结果.
从表5还可以看到,基于Word2Vec算法的模型与BERT-finetuning模型性能持平,但是基于BERT预训练的联合模型与其相比,所有指标都有显著的提高.其中,BERT-CRF模型比CRF模型的准确率,召回率和F1值分别提高了7.67%,15.96%和11.79%;BERT-LSTM-CRF模型在LSTM-CRF模型的基础上准确率提高了5.49%,召回率提高了3.68%,F1评分提高了4.61%;BERT-BiLSTM-CRF模型平均比BiLSTM-CRF模型的准确率高6.22%,召回率高6.15%,F1值高6.18%;ALBERT-BiLSTM-CRF模型的性能与BERT-BiLSTM-CRF模型几乎相同,但F1值相对较高,且空间利用更小.
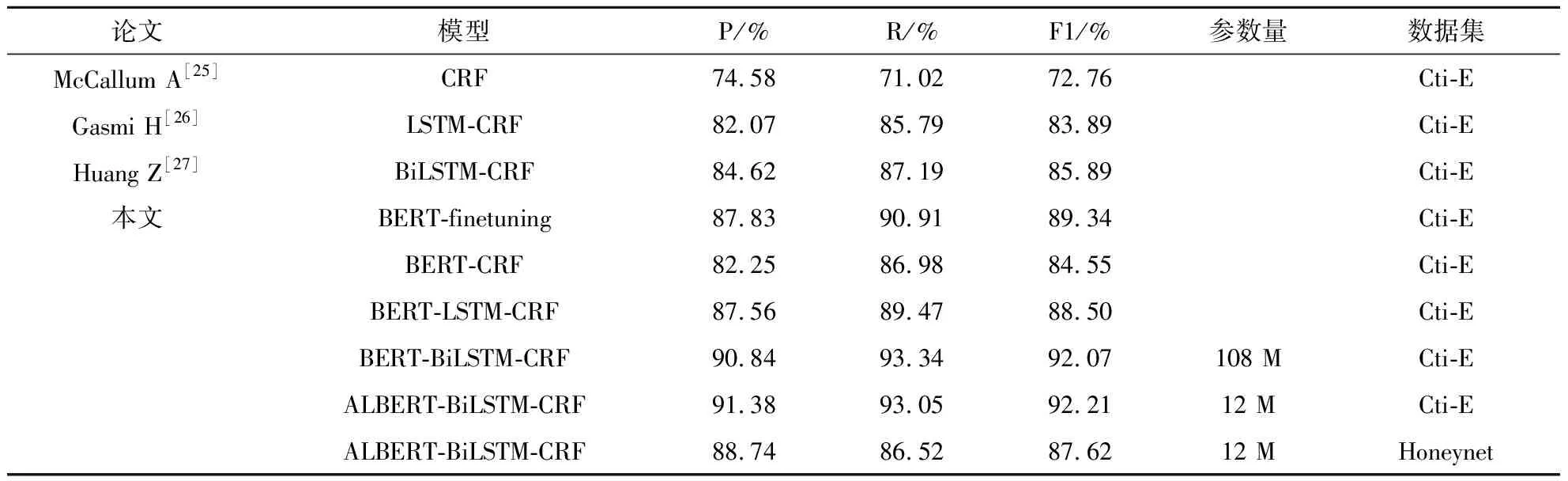
表5 不同模型命名实体识别结果
可以看出,对比传统模型,嵌入BERT模型后,在准确率,召回率和F1值上分别有不同程度的提高.这是因为网络威胁情报中有些实体需要根据上下文来判断语义信息,而使用动态词向量方法处理文本可以得到更深层次的语义表示,提取的词向量包含更多的语义信息.这表明本文提出的模型可以识别网络威胁领域的特殊词汇且效果更好.
另外还将数据集Honeynet在CTI-ALBC模型上进行实验,实验结果表明本文自标注的数据集在算法模型上有更好的表现.这是因为本文所标注数据集在实体类型和实体数量方面都高于数据集Honeynet,数据量更丰富、实体边界更加清晰.
针对网络威胁情报命名实体识别模型在训练上的时间和内存开销问题.在表6中,本文通过调整层数和隐藏维度来对比在不同情况下BERT和ALBERT两种模型的时间和内存开销以及识别准确率.
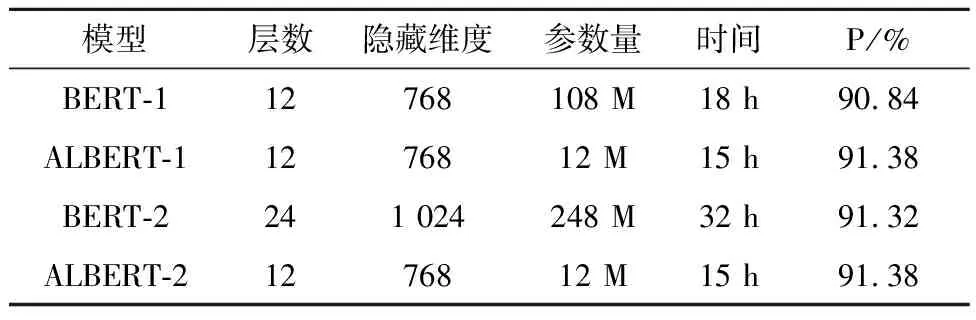
表6 BERT与ALBERT内存及时间消耗对比
从表6可以看出,在层数和隐藏维度相同的情况下,ALBERT在内存开销和识别准确度上都明显优于BERT,在时间开销上略微优于BERT;在层数、隐藏维度减半的情况下,ALBERT内存和时间开销大幅度降低,同时识别准确率与BERT基本持平.由此可知,ALBERT利用有限的时间和空间资源可以达到与BERT正常工作状态相同的识别效率,更适用于网络威胁情报领域日益递增的情报数据和分析工作.
本文利用CTI-ALBC模型识别各类网络威胁情报实体的实验结果如表7所示.表7显示了每个类别的P、R和F1值.
从表7和图10中可以看出,对于每个类别的实体,可以发现实体类别“HackGro”、“Att”、“AttWay”、“Exp”、“Features”具有更好的识别效果.对于实体类别“SecResTeam”、“MalTool”、“Purp”,较低的召回率是其F1分数不理想的原因,这些实体没有特定的词汇形式,且大部分是不同的,低重复率不利于深度学习.在未来的工作中,可以考虑改变这些类型实体的定义,以便更清楚的确定这些实体的类型.

表7 不同类型命名实体识别结果

图10 9类实体在不同模型上的F1
3.4 数据集大小影响
图11显示了不同数据集大小对本文提出的模型的影响.从图11可以看出,数据集的大小对实体识别的结果有很大的影响.随着网络威胁情报数据的增加,识别准确率大大提高,但当网络安全数据超过一定阈值时,识别准确率随着数据集的进一步增加而趋于稳定.这一现象与本文自标注的数据集数量相一致,即本文提出的模型可以有效地处理不同规模的数据集,并显著提高识别能力.
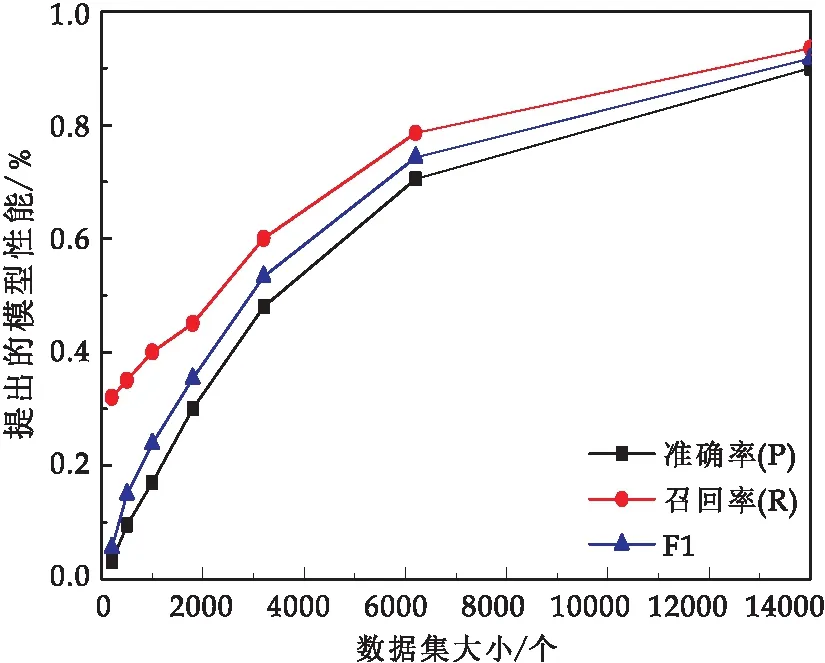
图11 模型在不同数据集下的性能
4 结论
针对网络威胁情报实体识别任务,本文在ALBERT和BiLSTM-CRF的基础上,提出一种改进的网络威胁情报命名实体识别模型——CTI-ALBC模型.该模型使用ALBERT预训练模型来提取领域特征词向量,而不是传统的静态词向量模型,使下一层得到更多可学习的特征,然后输入到BiLSTM模型中进行特征提取,最后通过CRF模型输出网络威胁情报中黑客组织、攻击、网络安全团队等实体及其标注标签.
在网络威胁情报语料数据集上的实验表明,CTI-ALBC模型的评价指标明显优于其他传统模型,准确率和召回率分别为91.38%、93.05%,F1值为92.21%.在实现BERT模型同等准确率情况下,本模型时间开销降低53.1%,空间开销降低95.2%,可有效应用于网络威胁情报领域的命名实体识别任务.下一步的研究工作将继续对各种实体进行标注,并扩展实体实验数据集,使模型在所有实体的识别上都能取得更好的效果.
