基于改进降噪自编码模型的网络入侵检测
2023-03-04蔡宇航廖光忠
蔡宇航,廖光忠
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;2.武汉科技大学 智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉 430065)
0 引 言
随着文件共享、移动支付和物联网等新互联网技术的兴起,以及开放信息系统用户的增加,网络安全问题也日益突出[1],网络安全的需求不断增长。因此,网络入侵检测系统(Network Intrusion Detection System,NIDS)已成为网络安全领域的重要组成部分[2]。
针对网络系统的攻击率急剧增加,攻击者使用的策略也在不断变化。近年来随着深度学习模型的不断发展,其在大数据分析中取得了很好的效果,许多研究人员开始将深度学习技术应用于网络入侵检测模型,基于深度学习的网络入侵检测模型因此得到了广泛的研究。针对网络入侵数据所具有的时空特征,Kim等[3]构建了一个基于梯度下降优化的长短期记忆网络入侵检测模型,该模型使用长短期记忆网络保留所提取的特征之间的依赖关系,并通过卷积神经网络提取数据的空间特征,但该模型存在过拟合问题。针对网络入侵数据特征维度丰富的问题,Wang等[4]提出了一种基于堆叠去噪自编码器和极限学习机相结合的集成深度入侵检测模型,该模型通过降噪自编码器学习数据特征,然后将学习到的特征输入到极限学习机中进行进一步提取,但该模型数据挖掘能力有限,对小样本数据集的检测效果较差。针对少数类别难以检测的问题,Singla等[5]基于生成式对抗网络提出了一种对抗域自适应的入侵检测模型,该模型通过将域自适应和生成式对抗网络相结合,降低了入侵检测模型训练所需要的数据量,可以通过仅对少量的样本数据进行训练从而达到更高的准确率,但对于网络入侵数据的多分类异常检测的准确性普遍不高。为解决高维数据难以建模分析的问题,Jia等[6]提出了一种信息增益技术,对高维数据进行降维并去除冗余特征,基于信息熵来确定深度置信网络中隐藏神经元的数量和模型网络深度,但模型的泛化性能不足。
综上所述,为了解决网络入侵检测系统在大型网络环境中检测率低、泛化能力差的问题[7],该文提出一种基于改进降噪自编码器的网络入侵检测模型,使用降噪自编码器对数据进行特征提取,降低了对噪声扰动的敏感性,并且通过引入门控循环单元使得模型集成了时序特征的记忆能力。同时针对数据不平衡问题,对数据集中的少数类样本使用生成式对抗网络进行扩充,使得网络入侵检测数据中各类样本更加均衡,提高了模型的多分类准确率。
1 基本理论
1.1 生成式对抗网络
生成式对抗网络(Generative Adversarial Networks,GAN)是Ian Goodfellow于2014年提出的一种深度生成神经网络,通过对抗过程估计生成模型[8],可对现实世界中的数据的复杂高维分布进行建模分析与学习。GAN由两个重要模块组成:生成器G和判别器D,其中生成器G用于学习真实数据样本的潜在分布,从而生成相似数据样本;判别器D用于判断数据样本的真实性[9]。分类结果将通过损失权重更新传递回G和D。两个网络经过不断训练,直到D不再能够区分真实样本和生成样本。GAN的基本原理如图1所示。

图1 生成式对抗网络基本原理
其中,z是初始随机生成的噪声,G(z)表示生成器G试图从噪声Pz的分布中学习一个分布PG,使PG尽可能接近真实数据的分布Pdata。判别器D的作用是识别数据样本是否真实。继续调整G和D,直到D在训练期间无法区分真实数据和生成数据,从而实现了PG=Pdata的最优性。因此,定义G和D的目标函数如下:
Ez~Pz(z)[log(1-D(G(z)))]
(1)
在入侵检测领域中,相关数据集通常具有样本不均衡以及特征维度丰富的特点。其中,样本不均衡问题指的是在数据集中正常的数据样本所占比例较高,而网络攻击类别的样本占比较小,在训练入侵检测模型的时候如果不注意该问题,则容易出现模型对于网络攻击检测敏感程度较低的现象,从而降低了入侵检测的召回率[10],对入侵检测的效果造成影响。针对此问题,该文使用GAN网络数据生成技术来创建包含高度不平衡类的数据集,以减少数据不均衡对检测模型准确率的影响。
1.2 降噪自编码器
自编码器(Autoencoder,AE)是一种无监督学习算法,通过压缩输入信息,从数据中提取最具代表性的特征[11]。目的是在不丢失重要特征的情况下减少输入信息的维度,减小神经网络的开销达到特征提取的效果,其特征提取效果也决定了机器学习模型的效果。为了解决模型存在对数据无效提取的问题,研究人员对自编码器添加了一定的约束,以提高对数据集深层特征的提取效果。其中一种便是降噪自编码器(Denoising Autoencoder,DAE),通过在输入中引入随机噪声,迫使自编码器在学习过程中去除随机噪声,从而降低其对输入样本的敏感性[12],增强了隐藏层的特征学习能力,使得模型具有更加良好的鲁棒性[13]。其结构如图2所示。
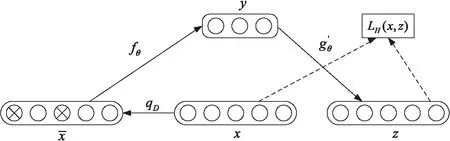
图2 降噪自编码器结构
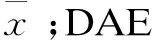
2 改进降噪自编码模型
2.1 模型结构
传统的DAE网络入侵检测模型虽然能够克服随机噪声的影响,有效地提取原始数据的特征,但每层内部的节点之间处于无连接状态,无法有效处理数据的时序传递关系,数据重构的准确性容易随着时间序列长度的增加而降低[14]。为了增强检测模型对入侵数据的特征提取的有效性,该文构建了一种GRU-DAE模型,在DAE网络架构的基础上引入门控循环单元(Gate Recurrent Unit,GRU)[15]完成编码和解码过程,在保证精度的同时提高了计算效率,也提高了模型的非线性拟合能力。
GRU结构如图3所示。
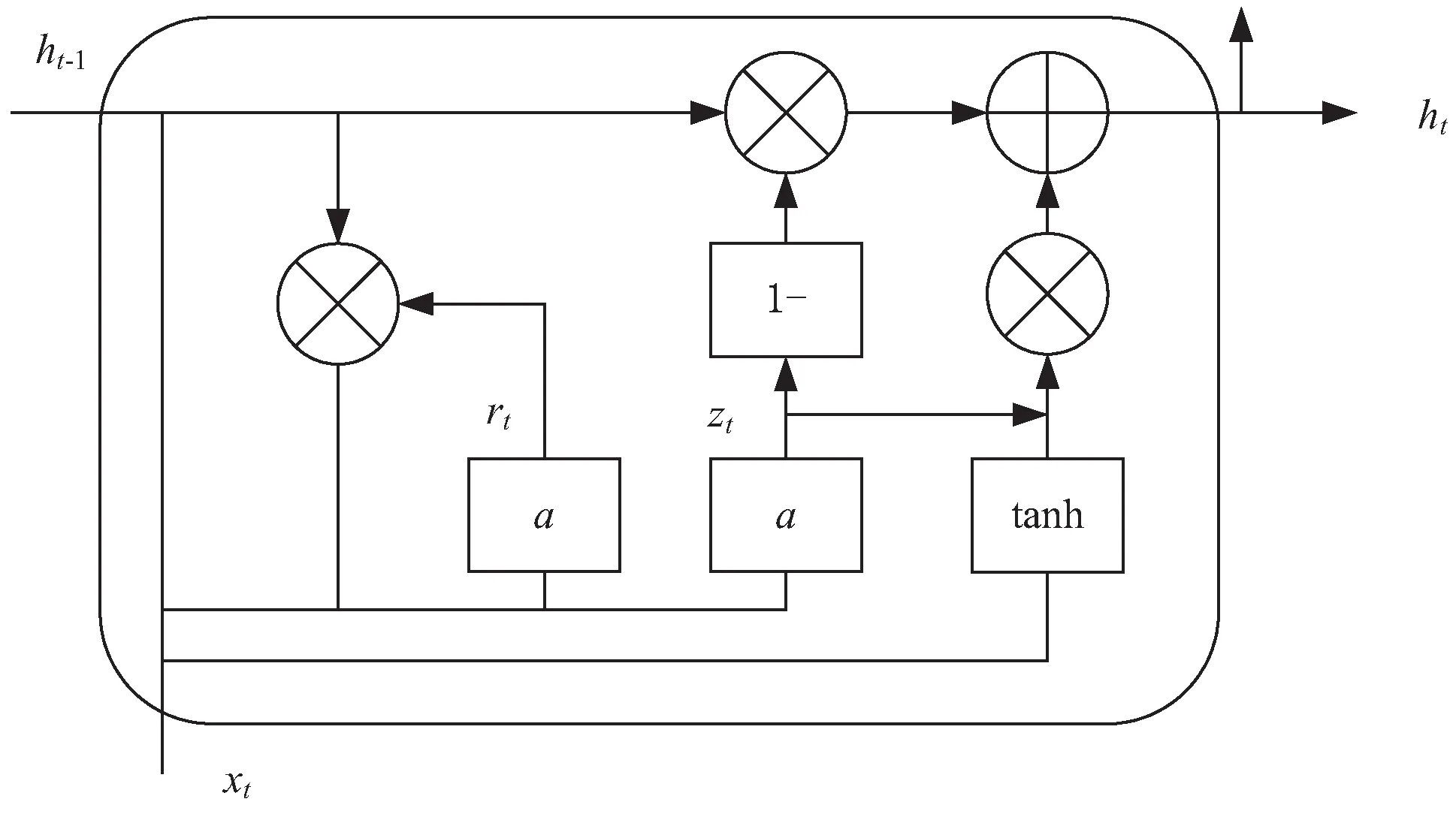
图3 GRU结构
GRU神经网络是在LSTM循环神经网络的基础上,对神经元内部的组成结构进行了优化。使用复位门和更新门替代LSTM结构中的输入门、遗忘门和输出门,显著地提升模型训练的效率。将GRU神经网络引入网络入侵检测,充分考虑网络入侵数据的时序特性,训练速度快,检测精度高。GRU神经网络的训练公式如下:
(2)
其中,xt为当前时刻的输入向量;ht和ht-1分别为当前时刻和上一时刻的状态记忆变量;rt和zt分别为重置门状态、更新门状态[16]。
该文将DAE模型的全连接层编码网络替换为GRU编码层,在网络入侵数据编解码过程中,通过GRU单元的更新门和重置门结构将前一时刻状态信息中重要的部分保留记忆,不重要的部分予以忽略,以此综合得到当前时刻的状态信息。与传统自编码模型相比,特征提取更加丰富,并且保证了时序信息传递的连贯性,避免了重要数据特征的遗漏。其改进后模型网络结构如图4所示。

图4 GRU-DAE结构
为了减小重构误差,模型采用梯度下降法训练。其中通过DAE提取到的特征具有一定的鲁棒性,不易受到随机噪声的影响,而且得益于GRU特有的网络结构,数据的时序特征也能够有效地被提取,保持数据间长期依赖关系,比改进前的DAE模型提取到的特征更加准确和全面。提取数据特征完成后,提取GRU-DAE模型编码的网络部分,在隐层节点后加上Softmax分类器进行分类,最终得到网络入侵检测结果。
2.2 模型训练过程
在模型训练中,利用GAN生成少数类样本,改进降噪自编码器的特征提取,Softmax的分类构建的并行化设计。整个网络入侵检测方法的设计思路如图5所示,具体步骤如下:
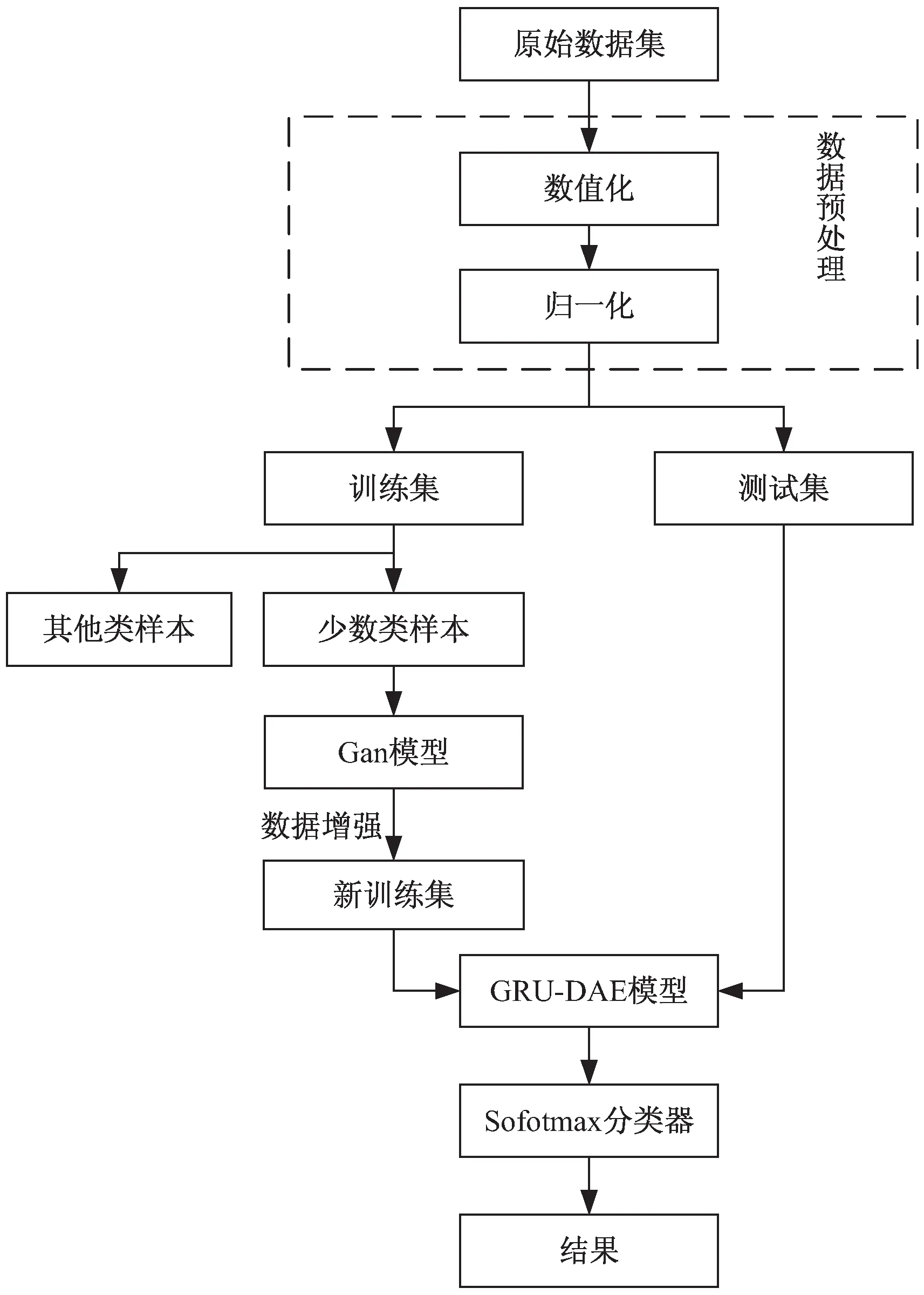
图5 基于GRU-DAE模型的网络入侵检测流程
(1) 对网络入侵数据中的字符型特征进行数值化,并对所有数据进行归一化处理,得到标准化的原始数据集,然后将其分为训练数据集和测试数据集。
(2)网络入侵数据包括正常数据和攻击数据,但一般情况下,其攻击数据量远远小于正常行为数据量,并且攻击数据也存在类别失衡。通过数据划分,将训练集分为少数类样本和其他类样本。
(3)训练数据集中少数类样本通过GAN进行数据增强。将GAN生成的新数据样本与原始数据样本整合,获得一个新的均衡训练集。
(4)使用新的训练集对GRU-DAE模型训练,用测试集对模型进行测试,实现对入侵数据的特征提取。最后对提取的特征通过Softmax分类器进行分类,得到检测结果,从而实现网络入侵异常检测。
3 实验与分析
3.1 实验环境与数据集
该文使用的实验平台为Ubuntu 18.04操作系统,硬件配置为NVIDIA RTX 2060图形处理器、32 GB内存。算法采用Python 3.6.5和TensorFlow 2.3.0实现。
用于NIDS的开放数据集并不多,大部分相关工作主要基于KDD99数据集、NSL-KDD数据集和Kyoto2006数据集进行研究。研究人员对现有数据集的评估表明,它们大多陈旧且不可靠,还有一些问题不能反映当前的攻击趋势。在最近发布的数据集中,ISCX2012数据集反映了最新的攻击。但是,由于攻击类型比UBSW-NB15数据集少,特征数量少,因此不适合作为本研究的数据集。
因此,该文使用UBSW-NB15数据集[17]进行实验,它由正常流量和9种攻击类型组成,共10种类型,其中包括Analysis、Backdoor、Shellcode和Worms少数类。表1展示了UBSW-NB15数据集中各类数据的分布情况。
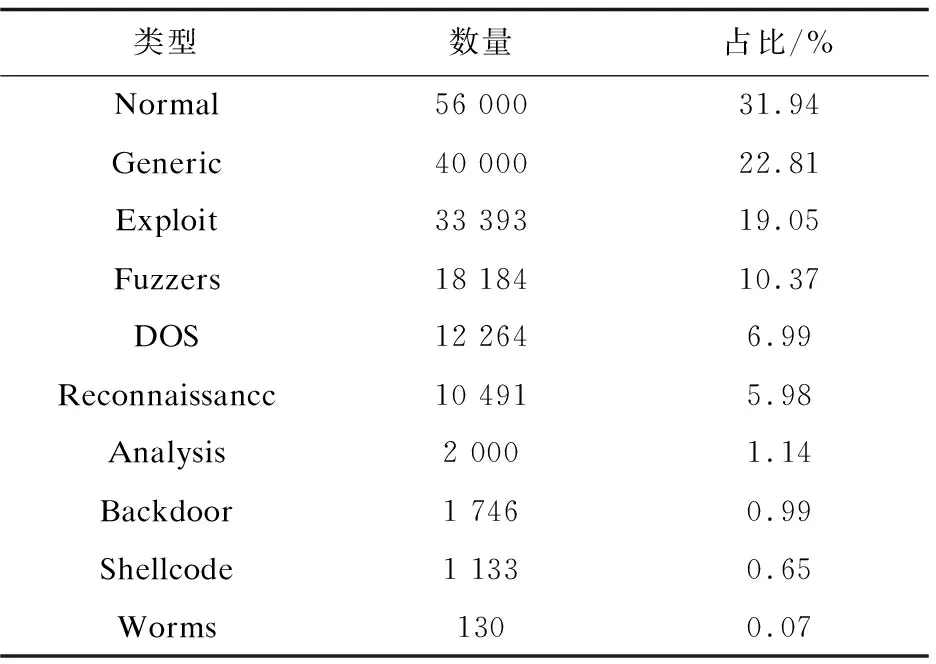
表1 UNSW-NB15数据集各类数据分布
3.2 数据预处理
网络入侵检测数据中存在连续数据和离散数据,数据中不同特征属性之间存在较大的数量差异。为了使数据集中不同类别的数据更加均衡,通常需要对数据集进行预处理。数据预处理阶段通常包括两个部分:数值化和归一化[18]。
(1)数值化:原始数据集含有不利于直接矢量化的字符串特征,为了将数据输入到网络异常检测模型中,对数据标签进行独热编码操作,将其中的字符型特征转换为数值型特征。独热编码是机器学习分类任务中一种常用的数据编码方法,它可以将原始数据中离散值转化为欧氏空间的点,从而保持各标签之间合理的特征距离[19]。例如,该文采用的数据集中proto、service、state和Attack_act包含字符型特征,例如proto属性,将其中的三个最重要的值TCP、UDP和ICMP分别映射到1、2和3,并将其余值映射到4。
(2)归一化:由于原始数据中各维度的值不一致,数据范围大不相同,这在网络入侵数据集中尤为突出,所以需要对原始数据的每一列进行归一化处理。高幅度数据具有较高的权重,这使得低幅度的数据对结果的影响很小,并且丢失了一些隐藏在原始数据集中的信息。将同一列数据归一化到[-1,1]之间。其归一化公式为:
(3)
其中,x为原始数据集的特征值,x*为归一化后的数据值,xmax和xmin分别为原始特征值的最大值和最小值。
3.3 训练数据扩充
目前使用GAN模型对网络入侵数据进行扩充大致分为两种方法:一种是整体类扩充,使用GAN对整体类别进行训练并生成相似数据,再对生成的数据进行类别识别;另外一种是类别内扩充,其区别是需要在生成数据的类别中进行训练,并生成相应类别的数据。文中实验采用类别内扩充对少数类进行数据增强,其步骤如下:
(1)从预处理后的网络入侵数据集中分离出包括Analysis、Shellcode、Backdoor和Worms四个少数攻击类的数据集。
(2)因分离出的训练数据维度数不够,根据GAN模型的输入格式要求,将128维的训练数据末位进行补0扩充,使之变成144维度,进而转换为12×12的矩阵向量。
(3)通过在生成模型中引入范围在[-1,1]的144维的随机噪声,将GAN生成的新数据样本与原始数据样本进行混合,从而训练判别器。
(4)根据实验选择合适的迭代次数,分别对判别模型和生成模型进行训练迭代,当判别模型和生成模型的判别结果分别达到最优和最差时,固定其模型参数,不断迭代该过程,直至GAN模型平衡。
(5)将扩充的样本重组为144维的特征向量,取前128维作为扩充样本的特征,并将扩充样本与原始训练数据进行混合,得到新的训练数据集。
3.4 评价指标
该文基于混淆矩阵来测量结果。其由四种数值组成:真正例(True Positive,TP)、真负例(True Negative,TN)、假正例(False Positive,FP)、假负例(False Negative,FN),混淆矩阵的定义如表2所示。

表2 混淆矩阵定义
实验性能评估准确率、精确率、召回率和F1分数。其公式如下:
(4)
(5)
(6)
(7)
其中,准确率是一个最直观地表示模型的性能的评价指标,但是当数据类别不平衡时,需要补充指标F1分数,即精确率和召回率的调和均值。F1分数是一个重要的性能评估因素,因为它可以准确地评估模型在使用不平衡数据时的性能[20]。因此,该文以准确率、精确率、召回率和F1分数作为指标。
3.5 实验过程及结果
该文使用GAN对攻击类Analysis、Backdoor、Shellcode和Worms进行样本扩充。GAN的初始参数包括batch-size设置为20,epoch为100,学习率为0.000 2,其中对少数类数目扩充为10 000。
实验过程中,该文分别选用迭代次数为50、200、400、600和800进行GAN训练,实验结果如图6所示。当迭代次数为400时,其准确率基本达到最高。迭代次数超过400次后随着迭代次数的增加,各类的检测准确率没有显著提高。综合检测准确率和时间成本考虑,文中GAN的迭代次数选择400次。

图6 不同迭代次数下模型的检测准确率
由于GRU特殊的网络结构,GRU-DAE编码网络的隐藏层数的选择受批训练大小的限制。该文对隐藏层数选择10、20、30、40、50、60这6个值进行对比实验,并对每个取值重复5次平均实验,得到训练集中准确率、召回率和F1分数随隐藏层数的数值变化情况,如图7所示。

图7 不同隐藏层数量下的模型性能
从图7可以得出,当隐藏层数为40时表现出较好的性能,即使增加隐藏层数量,性能也没有得到较高提升,相反隐藏层数过多会使模型结构过于复杂,不仅会使时间成本过高,而且可能会降低模型的检测性能。因此,综合考虑模型性能和时间成本,选取40为隐藏层数的最优取值。
为了更好地体现该模型在少数类的检测效果,该文对比了传统的LeNet、AlexNet、GoogleNet和LSTM模型在Analysis、Backdoor、Shellcode和Worms类上的各项指标,对各模型均进行5次重复实验并取其平均值,实验结果如表3所示。实验证明,通过GAN对少数类样本进行扩充,提高少数攻击类的占比,使少数攻击类样本能够充分被分类器学习,其检测率得到了明显提高。
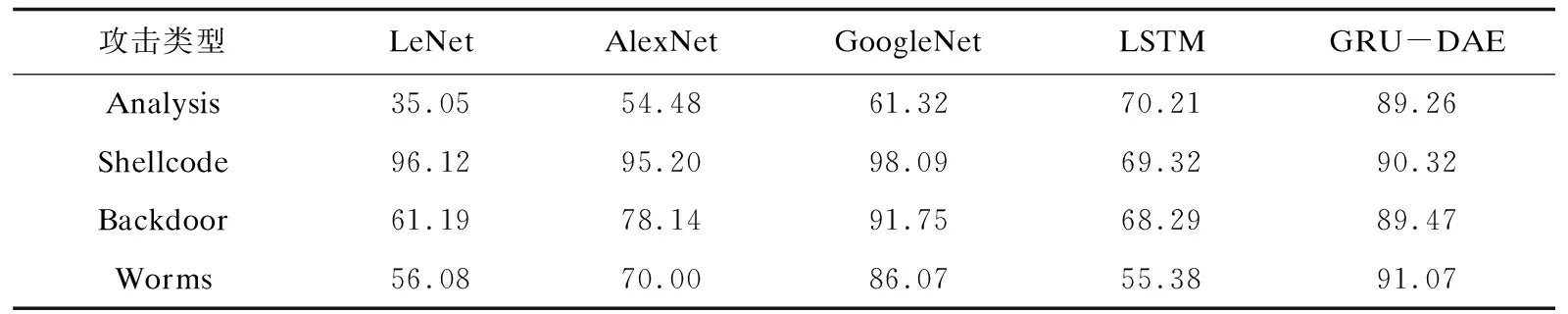
表3 少数类别数据检测率对比 %
为了更好地分析GRU-DAE异常检测模型的性能,该文分别使用决策树、随机森林、GRU-RNN和CNN-BiLSTM这4种网络入侵检测模型基于相同数据集进行对比实验,对各模型均进行5次重复实验并记录平均值,实验结果对比如表4所示。与传统网络入侵检测模型相比,GRU-DAE在UNSW-NB15数据集上的检测效果更优,验证了该模型在网络入侵检测上具有较高的整体类别检测率。
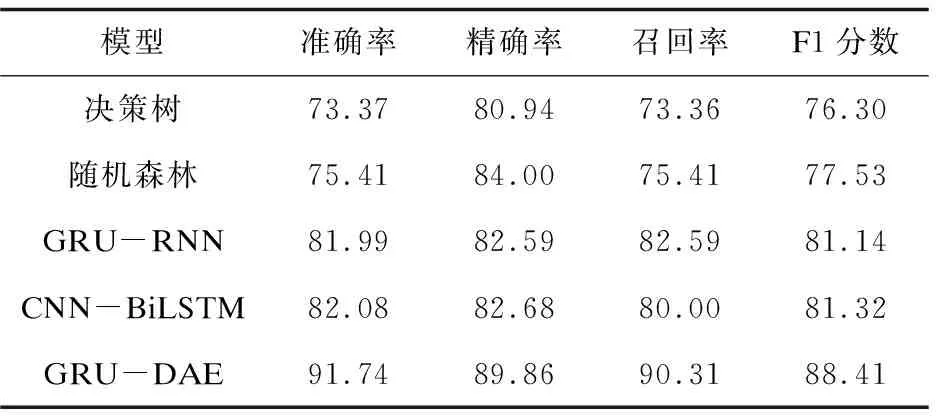
表4 各模型实验结果对比 %
从以上对比实验结果可以看出,在处理样本不平衡的入侵检测数据时,GRU-DAE模型不仅对少数攻击类取得了较高的检测率,而且在整体检测性能上相较于传统方法也具有一定的优势。
4 结束语
该文提出了一种融合生成式对抗网络、降噪自编码器与门控循环单元的入侵检测方法。针对网络入侵数据不均衡问题,采用生成式对抗神经网络对少数类样本数据进行扩充,降低数据的不平衡程度,提高少数攻击类的占比,使少数攻击类样本能够充分被分类器学习,提高了对少数类的检测率。同时提出了一种改进降噪自编码器的网络入侵模型,通过融入门控循环单元,使得模型在具有一定的鲁棒性、不易受到随机噪声影响的同时,对网络入侵数据的时序特征也能够有效地提取,实现了对数据间长期依赖关系的有效记忆,相较于传统的网络入侵检测模型,具有更高的检测性能。在今后的研究工作中,将基于该模型对物联网环境中的正常数据和攻击数据进行处理与分析,进一步验证该方法对于物联网领域网络入侵检测任务的适用性和有效性。
