个性化新闻推荐研究进展
2023-03-04都云程张仰森
周 帅,都云程,张仰森
(1.北京信息科技大学 计算机学院,北京 100101;2.北京信息科技大学 智能信息处理研究所,北京 100101)
0 引 言
随着互联网和移动终端的快速发展,人们的新闻获取来源逐渐从报纸、电视等传统媒体转向在线新闻平台。但在线新闻平台每天会产生大量文章,用户很难从中找到自己感兴趣的新闻信息。因此,个性化新闻推荐技术显得尤为重要,既能缓解信息过载,又能提升用户体验[1]。应用个性化推荐技术的在线新闻平台,如今日头条、新浪、腾讯新闻等,已经成为大众获取新闻信息的首选。
个性化推荐技术在新闻平台已得到广泛应用,但目前仍面临很大挑战。首先,新闻文章具有高度的时间敏感性,更新迭代速度较快,使得基于ID等传统推荐方法(如协同过滤算法)的有效性大大降低。其次,用户在阅读新闻时具有兴趣多样性,如何根据用户多样化的阅读记录准确把握用户兴趣,仍是亟待解决的一大难题。最后,用户兴趣是动态变化的,现有方法都是利用点击行为对用户长短期兴趣进行判断。然而,点击行为是嘈杂的,不一定能准确表明用户兴趣。因此,想要为用户提供精准的个性化推荐是具有挑战性的。
该文主要对个性化新闻推荐算法进行分析总结。首先,介绍新闻推荐的基本架构,依据新闻推荐是否使用深度学习技术,将其分为传统方法和深度学习方法,并分别对两类方法的新闻建模和用户兴趣建模进行分析;然后,介绍个性化新闻推荐应用的数据集和评价方法;最后,给出未来可能的研究方向和发展趋势。
1 个性化新闻推荐任务简介
目前,个性化新闻推荐技术已广泛应用于诸多在线新闻网站中[2]。非个性化新闻推荐方法仅基于新闻热度、编辑展示、地理信息等非个性化因素来推荐新闻文章。而个性化新闻推荐可以考虑到个人兴趣,从而提供针对每个个体的新闻服务,更好地满足用户需求。
个性化新闻推荐的模型架构如图1所示。推荐任务的核心问题是对用户和新闻建模,系统对用户兴趣和新闻信息提取越准确,推荐的准确性就越高。

图1 个性化新闻推荐模型架构
为方便用户更好地理解,以下对文章中专业术语进行说明。
新闻建模:目的是分析新闻的内容和特征,将新闻的特征用数字化的信息表示出来,是新闻推荐的基础[3]。
用户兴趣建模:旨在通过分析浏览记录等各种因素了解用户对新闻的兴趣[4]。
实体:指一类对象,是具体的事物,如人名、地名等。
冷启动问题:系统最初没有大量新闻和用户数据,在这种情况下系统如何能够做到个性化推荐,是需要解决的冷启动问题[5]。
2 个性化新闻推荐方法研究
个性化新闻推荐主要从新闻和用户角度分别提取信息,为用户推荐量身定做的新闻内容,以此提升用户体验、节省用户时间。该文主要根据是否使用深度学习方法,把个性化新闻推荐分成两类:(1)传统的新闻推荐方法;(2)基于深度学习的新闻推荐方法。
2.1 传统的新闻推荐方法
传统的新闻推荐方法和基于深度学习方法不同,深度学习方法可以自动提取用户和新闻特征,而传统新闻推荐方法往往通过手工设计构造特征。首先通过新闻建模和用户建模两部分来介绍传统推荐方法。
2.1.1 新闻建模
早期的一些新闻推荐方法将新闻文章用协同过滤信号表示(如新闻id),与被推荐新闻内容无关。1994年,Resnick P等[6]首次提出GroupLens后,协同过滤便在学术界受到了广泛关注。随后在1997年Konstan等[7]提出利用协同过滤去整合候选新闻,为用户做推荐。2007年,Abhinandan等[8]提出了Google news推荐系统的实现。上述方法虽然具有推荐个性化、自动化程度高等优点,但不足也很明显。新闻的快速更新导致模型需要不断重建,模型重建是一个既费时又费力的任务。且短时间内更新产生的大量新闻,使得每隔一段时间模型效果就会逐渐变差,导致推荐系统存在严重的冷启动。由此可见,仅基于id的新闻建模是不符合新闻推荐发展趋势的。
因此,许多方法都将新闻内容加入到了新闻建模中。Anatole Gershman等[9]用TF-IDF(词频-逆向文档频率)提取新闻特征来表示新闻内容,并加入了命名实体信息来共同建模新闻。Flavius Frasincar等[10]构建了一个基于语义的个性化新闻服务框架Hermes。Hermes利用本体进行知识表示,利用自然语言处理技术进行文本内容表示。Lei Li[11]提出一种可扩展的两级个性化新闻推荐方法,该方法在进行新闻建模时加入了新闻内容、命名实体等信息。命名实体和关键字大量被推荐方法用于新闻建模中,其主要原因是新闻中的实体和关键字是新闻内容的高度浓缩,便于更准确对新闻进行建模。对于新闻内容特征的提取,在上述TF-IDF方法的基础上,后续的研究者们又提出了CF-IDF、SF-IDF、SF-IDF+、Bing-CF-IDF+等方法。也有一些研究人员将新闻id和新闻内容结合进行混合建模,在一定程度上缓解了新闻推荐的冷启动问题。
仅利用新闻内容进行推荐也存在明显不足,如缺乏新颖性、无法推荐突发新闻等。因此,除了使用新闻内容和id外,研究人员加入额外信息来辅助新闻建模,如地理位置、流行度、最近度、天气、点击率。
2.1.2 用户建模
早期的用户建模和新闻建模类似,使用用户id作为信号来表示用户特征,如上文中GroupLens和Google news提到的方法均是基于id对用户建模。然而,基于id进行用户建模的方法存在很大问题。用户点击新闻通常只占新闻总量的很小一部分,造成用户-新闻矩阵非常稀疏,不仅难以找到最近邻用户集,而且使相似度计算耗费巨大。
因此,大多数方法是利用用户的历史浏览记录,对用户兴趣进行建模。如Liu J等[12]以谷歌新闻为平台,研究开发个性化新闻推荐系统。对于登录并明确启用了Web历史记录的用户,推荐系统会根据用户过去的点击行为建立用户新闻兴趣。且该系统开发了一种贝叶斯框架,用于从用户浏览行为中预测用户当前的新闻兴趣。Florent Garcin等[13]提出将所有点击新闻的LDA特征平均聚合成一个用户向量来建模用户。考虑到用户兴趣可能随着时间变化具有多样性,有些学者将用户兴趣分为了长期兴趣和短期兴趣。Adomavicius G等[14]通过文本聚类算法得到的聚类结果建模长期兴趣,而短期兴趣使用近期点击记录进行建模。然而,当用户的新闻点击行为较稀疏时,这些方法很难准确地建模用户。因此,许多方法除了使用新闻的基本特性外,还加入了其他辅助因素。如Viana P等[15]除了通过浏览记录分析用户长短期兴趣外,还加入了地理位置等因素。Kam Fung Yeung等[16]提出利用用户年龄、性别、职业状况和社会经济等级帮助识别用户对不同类别新闻的偏好。然而,位置和职业等信息涉及到用户隐私,因此许多用户可能不会提供准确的个人信息,导致不能准确把握用户兴趣。
2.2 基于深度学习的新闻推荐方法
基于深度学习的新闻推荐方法是将新闻推荐和深度学习技术相结合,利用深度学习技术提取新闻特征和用户兴趣特征[17]。为了便于用户对每个子任务建模过程的了解,依然从新闻建模和用户建模两部分来分析基于深度学习的新闻推荐方法。
2.2.1 新闻建模
近年来,随着深度学习技术的发展,许多方法都采用了神经网络自动学习新闻表示。在深度学习应用到新闻推荐初期,一些新闻建模使用的是单种深度学习方法来提取新闻特征。如Okura等[18]使用改进的降噪自编码器从新闻文本中学习新闻表示。Zhang L等[19]将经典的Kim CNN[20]算法应用到新闻的语义特征提取中,首次将卷积神经网络(Convolutional Neural Networks,CNN)模型应用于文本特征提取。Wang X J等[21]同样利用CNN提取新闻语义特征,并且使用的是字符级CNN,可以更好地捕获不同语言特征。
为了提升新闻建模的准确性,一些研究人员将多种深度学习技术进行结合。Wu C H等[22]提出的NPA模型,先使用CNN学习每个单词的局部上下文特征,也就是使用一个单词和其前后n个单词,通过卷积操作来共同学习这个单词的表示。然后,使用单词级别的注意力机制,为标题中的每个单词设置一个权重,这些权重体现了用户对每个单词的关注度。最后,将所有单词加权平均,得到最终的新闻表示。Wu C H等[23]提出的NAML模型在新闻建模方法上和NPA模型基本相同,但除了考虑新闻标题外,还加入了新闻分类和新闻内容。NAML使用注意力机制从新闻的每个不同的成分中学习权重,加权平均得到最终新闻表示。类似的还有An Mingxiao等[24]提出的LSTUR模型和Wu C H 等[1]提出的NRMS模型。上述文献都使用了CNN,其原因是局部上下文特征对新闻内容的建模很重要,而CNN在捕捉局部上下文特征方面十分高效。但CNN的不足之处是不能捕捉长距离的上下文特征,所以NRMS中提出一种将自注意力机制[25]应用在新闻特征提取的方法,将CNN模型进行了替换,用多头自注意力机制进行新闻特征提取。首先,用多头注意力机制提取每个词在句子中的特征,然后,使用加法注意力进行加权平均,得到新闻特征向量。虽然此方法考虑到了新闻全局特征,但会忽略局部特征。
为了弥补CNN和多头自注意力机制各自的缺点,Qi Tao等人分别在FedRec[26]和KIM[27]两个模型中提出两种解决方法。FedRec模型将新闻建模分为四层,其中第二层是CNN网络,通过捕获局部上下文来学习单词表示,第三层是多头自注意力网络。该网络可以建模不同词之间的长距离相关性来学习语境下的词表示。KIM模型中新闻语义特征提取部分则使用CNN和transformer分别提取标题的局部特征和全局特征,然后逐点累加。上述提到的新闻建模方法主要是为了捕获新闻的语义信息,可能没有意识到新闻中的实体信息和新闻以外的信息。
除了使用新闻中的语义信息外,有几种方法还使用新闻中的实体信息来增强新闻建模。Zhu Qiannan等[28]提出的DAN模型使用两个并行的CNN从新闻标题和实体中学习新闻表示。Qi Tao等[29]在HieRec模型中使用多头自注意力机制,分别对标题词嵌入和实体嵌入进行特征提取,然后使用文本注意力和实体注意力得到文本和实体的特征表示,最后加权求和得到新闻特征向量。Wang等[30]在DKN模型中提出了KCNN网络,从实体及其邻居处学习基于知识的新闻表示。Liu Danyang等[31]提出了KRED模型,使用知识图注意力网络[32],从新闻中的实体及其知识图上的邻居学习基于知识的新闻表示。KIM[27]模型中实体特征表示部分,通过图注意力网络聚合知识图谱中的邻居特征,最终表示标题中的实体特征。上述方法均加入实体信息,并利用知识图谱中实体之间的关系,将新闻之间知识层面的联系应用到新闻推荐中,能够更准确地为用户进行个性化推荐。但这种方法也存在不足之处,现有的知识库可能难以表示新闻中出现的新实体。
除了上述方法外,MM-Rec[33]模型使用视觉和语言学结合的方法,从新闻文本和图像中学习新闻的多模态表示。但由于目前没有公开的多模态新闻推荐数据集,导致该方向研究较少。还有一些方法利用用户新闻二部图或者更复杂的异构图进行新闻推荐,如GnewsRec[34]模型和GNUD[35]模型。然而,由于这些方法使用的图表是静态的,可能在准确地表示新发布的新闻方面有一些困难。
通过回顾新闻建模的各种技术方法可以发现,对新闻进行准确建模仍然是一个难点。
2.2.2 用户建模
近年来,许多个性化新闻推荐方法都使用了深度学习技术为用户建模。
在算例1的基础上,算例2将提出的负荷频率协调控制和滑模负荷频率控制器应用于柴储混合电力系统中,对系统频率进行优化控制。算例2的系统负荷频率偏差值如图4所示。
这些方法大多是利用深度学习算法整体建模用户的兴趣表示。例如,Wu C H等[23]提出的NAML模型,以及Liu Danyang等[31]提出的KRED模型,使用的都是新闻级别的注意力机制来建立用户兴趣模型。Okura等[18]提出的EBNR模型,使用门循环单元(Gate Recurrent Unit,GRU)从用户浏览记录中学习用户兴趣表示。Wang等人在DKN[30]模型中通过一个候选感知的注意力网络从被点击新闻的表示中学习用户表示,即根据每个被点击新闻与候选新闻的相关性计算每个被点击新闻的注意权重。同样的,Saskr[36]模型、DAN[28]模型、TRKGR[37]模型都是使用候选感知的注意力网络。KIM[27]使用了一个用户新闻协同编码器,该编码器对候选新闻和点击新闻之间的交互进行建模,以协作学习候选感知的用户兴趣表示和用户感知的候选新闻表示。Qi Tao等[29]提出的HiRec模型,将用户兴趣建模分为三层结构:(1)整体用户兴趣;(2)用户对粗粒度主题的兴趣,如体育;(3)用户对精细主题的兴趣,如足球。NPA[22]使用新闻级个性化注意力网络,根据用户特征选择重要新闻,通过嵌入用户id生成查询矩阵。
还有一些方法将用户兴趣分为长期兴趣和短期兴趣。如LSTUR[24]模型,通过一个GRU网络学习短期用户兴趣,并通过用户id来建模长期用户兴趣。FedRec[26]模型通过GRU网络学习最近用户的点击行为来表示用户短期兴趣,通过多头注意力机制学习用户的长期兴趣。GNewsRec[34]使用长短期记忆网络(Long Short-Term Memory,LSTM)和候选新闻感知网络来学习用户短期兴趣,并使用两层图神经网络(Graph Neural Networks,GNN)学习长期用户表示。同时考虑用户的长期和短期兴趣,可以更好地捕捉他们的兴趣动态。但用户的兴趣具有多样性和演化性,仍然难以被全面、准确地建模。
用户行为具有噪声和稀疏性,用户兴趣是多样的、动态变化的,所以如何高效地建模用户仍然具有挑战性。
3 新闻推荐数据集
3.1 财新网中文推荐数据集
财新网数据集2014年公开,数据集包含1万用户、6 000条新闻及116 249条交互信息。数据集中有用户id、新闻id、点击时间、新闻标题、新闻内容、发布时间六部分。
3.2 Plista数据集
Plista数据集[38]由Plasta GmbH和柏林工业大学,通过收集13个德国新闻门户网站上发布的新闻文章集合进行创建。包含了14 897 978个用户、1 095 323条新闻、84 210 795次交互记录、70 353次创建以及5 154 116次更新。
3.3 Adressa数据集
Adressa数据集[39]是根据adreseavisen网站的日志在10周内构建的。其中有48 486篇新闻文章、3 083 438个用户和27 223 576个点击事件。每个点击事件包含多个属性,如会话时间、新闻标题、新闻类别和用户ID。整个数据集分为规模不同的两个版本,大版本Adressa-20M数据集和只有一周数据量的小版本Adressa-2M数据集。
3.4 Globo数据集
Globo数据集[40]是通过巴西新闻网站globo收集并建立的,最早在Kaggle竞赛上进行公开。此数据集包含大约314 000个用户、46 000篇新闻文章和300万次点击记录。每个单击记录都包含用户ID、新闻ID和会话时间等字段。提供训练好的新闻embedding,没有原始的新闻文章信息。
3.5 Yahoo数据集
它包含14 180篇新闻文章和34 022次点击事件。每篇新闻文章都由单词id表示,不提供原始新闻文本。此数据集中的用户数量未知,因为没有用户ID。
3.6 MIND数据集
MIND[41]由微软新闻的用户点击日志构建而成,包含100万用户和超过16万篇英文新闻文章,每篇文章都有丰富的标题、分类、正文等文本内容。MIND数据集中提取新闻中的实体,并从WikiData中提取这些实体的知识三元组。

表1 公开新闻推荐数据集统计信息
4 评价指标
随着新闻推荐领域的不断发展,评价指标也在不断完善,目前有诸多指标可以定量地评估新闻推荐系统的性能。
4.1 AUC
对于将新闻推荐任务视为分类问题的方法,曲线下面积(Area Under Curve,AUC)评分是一种广泛使用的度量指标。随机抽出一对样本(一个正样本,一个负样本),然后用训练得到的分类器对这两个样本进行预测,预测得到正样本的概率大于负样本的概率。
计算公式如下:
(1)
I(Rank(Np),Rank(Nn))=
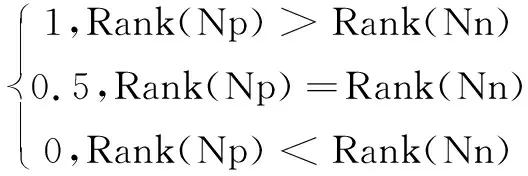
(2)
其中,Np和Nn分别是正样本和负样本的数量;Rank(Npi)是第i个正样本的分数排名,Rank(Nnj)是第j个负样本的分数排名。
4.2 精确率,召回率,F1
另一组流行的评价标准是精确率(Precision)、召回率(Recall)和F1。精确率:又称为查准率,即正确预测为正的占全部预测为正的比例[42]。召回率:又称为查全率,即正确预测为正的占全部实际为正的比例。F1:精确率和召回率的加权调和平均。
计算公式如下:
(3)
(4)
(5)
其中,TP是预测为正确的正样本的数量,FP是预测为错误的正样本的数量,FN是预测为错误的负样本的数量。
4.3 MRR

计算公式如下:
(6)
其中,Rank(i)表示第i个样本在推荐结果列表中出现的位置,如果没出现,Rank(i)为正无穷。
4.4 nDCG
nDCG称为归一化折损累计增益。其目的是希望得到的排序列表,质量越高越好。如果将更相关的排到越前面,那么计算得到的nDCG越高[43]。
应用于排名前K的推荐列表,计算公式如下:
(7)
其中,ri表示是否为正样本,是就取1,否则取0。
上述是常用的新闻推荐算法评价指标。在实际应用中,通常使用两个或两个以上来共同评价推荐效果。
5 新闻和用户兴趣建模方法推荐效果对比
该文以MIND数据集为标准对推荐效果进行分析评价。NAML、LSTUR和NRMS是比较经典的基于深度学习的新闻推荐模型,这三个模型均使用两段式的建模方式,新闻建模和用户建模部分可以很方便地使用其他方法进行替换,便于接下来的对比实验。
首先,对三个模型在MIND数据集上进行了对比实验。从表2可以看出,NRMS的推荐效果最好。NRMS利用多头自注意力机制捕捉词与词之间的关联来学习新闻表示,并捕捉点击的新闻文章之间的交互来学习用户表示。结果表明,多头自注意力机制等先进的NLP模型可以有效地提高对新闻内容的理解和用户兴趣的建模。LSTUR的性能也很强大。LSTUR可以通过GRU网络模拟用户近期点击新闻的短期兴趣,也可以通过整个新闻点击历史来模拟用户的长期兴趣。结果表明,适当的用户兴趣建模对新闻推荐也很重要。

表2 三种基于深度学习的经典新闻推荐模型对比
然后,将NAML、LSTUR、NRMS三种新闻推荐方法,用不同的新闻建模方法来替换原有的新闻建模方法。由表3可以看出,深度学习的新闻建模方法(如CNN、Self-Att和LSTM)明显优于LDA、TF-IDF等传统新闻建模方法。原因是对新闻进行表示时,深度学习模型可以更好地捕获上下文信息。此外,将两种深度学习方法有效结合可以进行互补,进而提高推荐效果。

表3 不同新闻表示模型对比
从表3可以看出,LSTM对新闻特征的提取效果相对不错。为了方便实验,下面选择性能较好的LSTM作为新闻建模方法,控制新闻建模方法不变,使用其他方法分别作为用户建模方法进行对比。如表4所示,深度学习用户建模方法的表现均优于Average。LSTUR的推荐效果优于Attention和GRU方法,原因在于LSTUR可以使用不同时间段的行为对长期和短期用户兴趣进行建模。Self-Att可以对用户历史行为之间的长距离关联进行建模,从而更好地进行用户建模,也可以实现较好的推荐效果。
由以上分析可知,基于深度学习的方法明显优于传统方法。但通过表4可以发现,基于深度学习方法的AUC值只有60多,nDCG@10值仅有40左右。由此可见,新闻推荐仍有很大的提升空间及很重要的研究价值。未来几年基于深度学习的新闻推荐方法无论在学术界还是工业界都将是研究热点之一。

表4 不同用户兴趣表示模型对比
6 未来研究方向
在近些年,随着自然语言处理技术的发展和深度学习在新闻推荐领域的应用,新闻推荐建模从最初复杂、耗时耗力的手工构造特征,到现在使用深度学习技术方便、快捷地进行自动提取,已然取得了很大的进步。但由于新闻的时效性及用户兴趣的多样性、动态性,仍很难精准地对新闻和用户兴趣进行建模。通过总结新闻推荐的发展历史和研究进展,认为以下几点可能是未来值得研究的方向。
6.1 基于多模态的新闻推荐
由于缺乏多模态新闻推荐数据集的缘故,以往的新闻推荐算法,基本都是在文本数据集上开展工作。但在实际应用中,新闻通常包含大量图片、视频等多模态信息。用户点击新闻不仅仅是对新闻标题和内容感兴趣,还可能是被新闻图片所吸引。因此,图像在表示新闻和预测用户行为方面十分有用。在未来的研究工作中,亟待把多模态信息加入到新闻推荐任务中,用来对新闻文本内容进行补充,以此得到更精准的新闻建模。并且微软亚洲研究院公开消息称,多模态新闻数据集将在不久后发布。
6.2 对新闻进行风险分析
在线新闻平台发展迅速,每天会产生大量新闻信息,有些可能是政治敏感、暴力血腥,会潜移默化地影响人们的思维。希望未来可以设计一个统一的模型,对平台新闻进行风险分析,识别新闻对社会的影响。这将有助于避免个性化新闻推荐的风险行为,提升用户网络阅读体验。
6.3 推荐的多样性
新闻推荐的多样性对用户体验有很大影响。用户兴趣通常是多样的,但现有大多新闻推荐算法通常是对用户兴趣进行统一建模,这不利于对用户推荐多样化的新闻内容。未来的研究可以将用户兴趣进行更细粒度的提取,对新闻进行类别分析,总结用户对每种类别的喜爱程度,并权衡准确度和多样性的比重,为用户推荐既多元化又符合兴趣的新闻内容。
6.4 基于知识图谱和图神经网络的新闻推荐
知识图谱本质上是一种由实体和关系组成的语义网络,实体表示现实世界中存在的事物,实体间的边则表示两个事物之间的联系。一些大型的知识图谱,如维基数据等包含现实世界的大量数据信息。现有基于知识图谱的新闻推荐方法大多只是对知识图谱进行简单利用,如仅使用知识图谱中实体或者对实体和邻居实体进行简单相加,并没有真正利用到关系信息。所以未来可以考虑用图神经网络对知识图谱中大量的实体关系信息进行聚合,学习更准确的新闻表示模型。
7 结束语
从新闻推荐的研究进展中可以看出,个性化新闻推荐一直是国内外研究热点。其中基于深度学习的新闻推荐正在逐渐替代传统方法并占据主流地位。虽然新闻推荐发展迅速,但仍存在许多挑战和有待解决的问题。因此,未来如何通过深度学习和自然语言处理技术准确的建模新闻内容和用户兴趣,将是一项长久的挑战。
