基于上下文模型的超长哈夫曼码校正算法
2023-03-04张永兴吴睿振贾晓龙陈静静孙华锦
张永兴,吴睿振,贾晓龙,陈静静,孙华锦
(浪潮人工智能研究院有限公司,陕西 西安 710077)
0 引 言
随着大数据等前沿科学技术的快速发展,催生数据爆发式的增长,海量数据对现有的存储设备带来巨大的压力。面对持续增长的海量数据,数据压缩成为减轻服务器存储负担,降低存储成本的最有效方法。
数据压缩在不丢失有用信息的前提下,缩减数据量以减少存储空间,提高传输、存储和处理效率。无损数据压缩一般通过两种方法来实现[1]:一种是通过字典的方式实现压缩的算法,包括LZ系列算法,这类算法能实现重复数据的搜索功能;另一种是基于统计模型的压缩算法,如Huffman码、算术编码等,这类算法的核心思想是依照符号出现频率分配码长,符号出现频率越高,其对应码长就越短。
当前主流的数据压缩算法通常会把原始数据切割分块,然后对每个数据分块独立压缩编码。压缩数据通常由一系列压缩块(compressed blocks)组成,这些压缩块对应于原始数据的连续块。最常见的数据压缩算法(Gzip、Zip、Zlib等)会将原始数据块压缩编码成一种名为Deflate的压缩数据块[2]。Deflate是一种将LZ77算法和Huffman Coding结合起来的无损数据压缩协议。
LZ系列算法最早由Ziv和Lempel[3-4]在1977年和1978年的两篇论文中提出。这两篇论文构造了两个不同类型的数据压缩算法,LZ系列的核心重复数据搜索查询。基于1977年论文的数据压缩算法都称为LZ77数据压缩算法。LZ77算法是利用动态字典实现重复数据的查找:首先利用已有数据作为动态字典,通过检查字典,判断当前输入的数据是否在滑动窗口内的先前数据中出现过,随后对重复数据进行编码。
哈夫曼编码[5](Huffman coding)是由David A. Huffman于1952年提出的一种基于频率统计的变长编码。在数据压缩过程中,通过构建Huffman树来生成源符号的Huffman码。Huffman树的高度决定源符号的最长Huffman码。Deflate协议限定Huffman码长不能超过15,因此当Huffman树的高度超过限定值时,需要对Huffman树“校正”,再生成哈夫曼码。Zlib等参考软件代码里的基于二叉树搜索的校正算法,需要遍历搜索整棵Huffman树,寻找嫁接“节点”,校正流程时间消耗非常大,而且不利于硬件化实现。
1 Huffman算法原理
Huffman编码[6]是一种基于数据统计的变长编码算法。哈夫曼编码已经被证明是一种编码效率最佳的变长编码方案,所以哈夫曼编码也被叫做最佳编码。当前哈夫曼编码被广泛应用于图像、视频、文本等不同类型数据压缩编码中,JPEG、JPEG2000等图像压缩格式中运用哈夫曼码编码图像数据[7-8],H263视频编解码标准[9]中使用哈夫曼码编码视频流数据,Gzip[10]、Zlib[11]等数据压缩标准都用到哈夫曼编码实现文本数据压缩。
Huffman编码算法利用符号的频率分布构建Huffman树,从而生成每个符号相对应的哈夫曼码[5]。Huffman编码算法的流程如图1所示,大体可分解为如下三个步骤:
(1)统计源符号中各个符号出现的频率,并按照频率对符号进行排序。Deflate协议中的源符号(Source symbols)是原始数据LZ77算法搜索查重后输出的待编码符号[2],包括原文字母(Literal)、匹配长度(Match length)、偏移距离(Match distance)。
(2)构建源符号的Huffman树。
(3)利用Huffman树生成Huffman码表。

图1 Huffman编码流程
Huffman编码算法的精妙之处在于,该算法完全依照各个符号的频率,合理精确地为每个符号分配码长,Huffman编码是最接近信息熵的变长编码方案。其中算法原理Huffman编码的精髓在于构建Huffman树。该文以 “abcdefghacdefghacdefhacdehadehaehaee”字符串为例,详述Huffman树的构建算法。
构建Huffman树时,需要统计各个符号出现的次数,按照出现的次数从小到大对符号进行排序。上述字符串由“a”、“b”、“c”、“d”、“e”、“f”、“g”、“h”八个符号组成,按照它们的出现次数从大到小排序如表1所示,下面详细描述Huffman树的构建流程。

表1 源符号排序序列
1.1 Huffman树构建算法
Huffman树数学形式上就是一种二叉树,文献[5]中David A. Huffman详述了Huffman树的构建过程,对源符号(节点)进行多轮迭代排序及合并,构建Huffman树。在每一轮中,会把符号序列中频率最小的两个符号合并生成一个新符号(父节点),新符号的频率为两个符号的频率相加值,同时需要将这两个符号移出符号系列。 生成 Huffman树所需的轮数与源符号数目减1。下面以表1所示符号序列为例,详述整个Huffman树构建流程:
第1轮:原始序列中最小的两个频率相加(“1”和“2”),合并为一个概率为3的节点,新序列重新排序结果为 8,7,6,5,4,3(1+2),3;
第2轮: 把第1轮生成新序列中最小的两个频率相加(“3”和“3”),合并为一个概率为6的节点,新序列重新排序结果为8,7,6(3+3),6,5,4;
第3轮: 把第2轮生成新序列中最小的两个频率相加(“4”和“5”),合并为一个概率为9的节点,新序列重新排序结果为9,8,7,6,6;
第4轮:把第3轮生成新序列中最小的两个频率相加(“6”和“6”),合并为一个概率为12的节点,新序列重新排序结果为12,9,8,7;
第5轮:把第4轮生成新序列中最小的两个频率相加(“7”和“8”),合并为一个概率为15的节点,新序列重新排序结果为15,12,9;
第6轮:把第5轮生成新序列中最小的两个频率相加(“9”和“12”),合并为一个概率为21的节点,此时序列中仅剩两个节点15,21;
第7轮:把第6轮生成最后的两个节点相加,合并为一个概率为36的根节点。
以上迭代排序及合并流程,可以用图2形象描述。
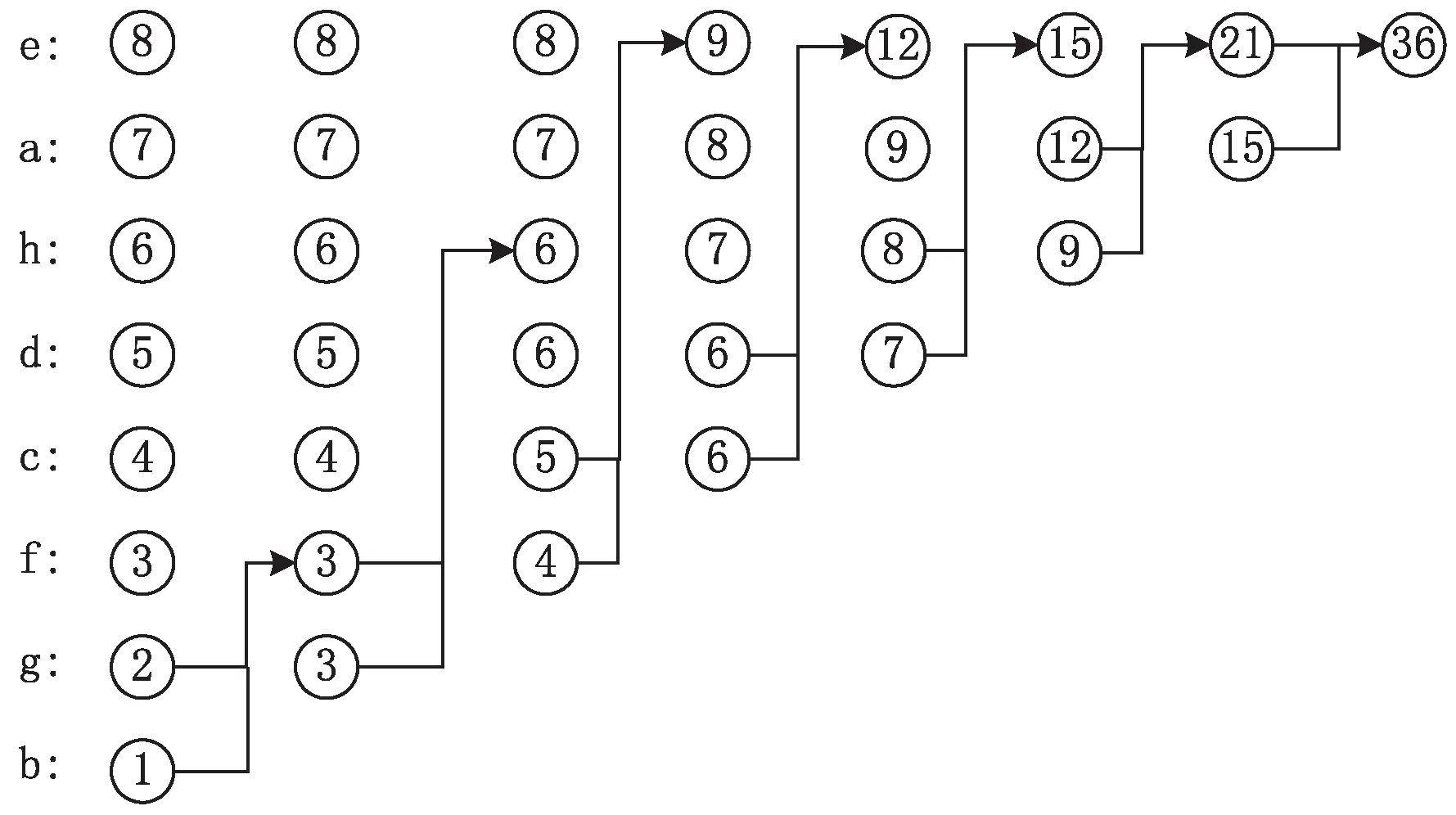
图2 源符号迭代排序流程
图2所示的迭代排序流程,就是构建Huffman树的流程,上述例子最终生成的Huffman树如图3所示。

图3 Huffman树示意图
1.2 超长Huffman码的问题
在构建Huffman树时,Huffman树的高度通常定义为Huffman树上叶子节点的最大码长。 如图3所示,Huffman树的深度为5。根据Huffman算法原理可知,Huffman树的深度与源符号的(叶子节点)的概率分布相关。
由二叉树相关理论可知[12],理论最大高度Heightmax等于二叉树的叶子节点数目Numleaf-1,即式(1):
Heightmax= Numleaf-1
(1)
当二叉树呈现出如图4所示(树上的字母(“a”- “g”)表示Huffman树的叶子节点,树上数字表示枝节点,图中右侧的数字表示每个叶子节点的码长)的树形,此时就是理论最大高度的情形。Deflate格式的编码数据块由三种类型不同的字符集构成:原文字母、匹配长度、偏移距离。Deflate协议中,需要构建两种类型的哈夫曼树:Literal & length树和Distance树。Literal & length树的源符号总数为 286,其中值0…255表示原文字母,值256表示块结束符,值257…285表示匹配长度,Distance树的源符号总数为30。因此,这两棵树的理论最大深度为285和29。Deflate协议中规定这两棵哈夫曼树的最大高度都为15[2],因此当由源符号经频率排序生成的Huffman树(该文把此阶段的Huffman树称为原树)高度超过规定最大值(15)时,需要先对原树“修整”,然后再用校正后的Huffman树生成Huffman码。Deflate协议规定Huffman码长的最大值,但是没有规定校正算法。
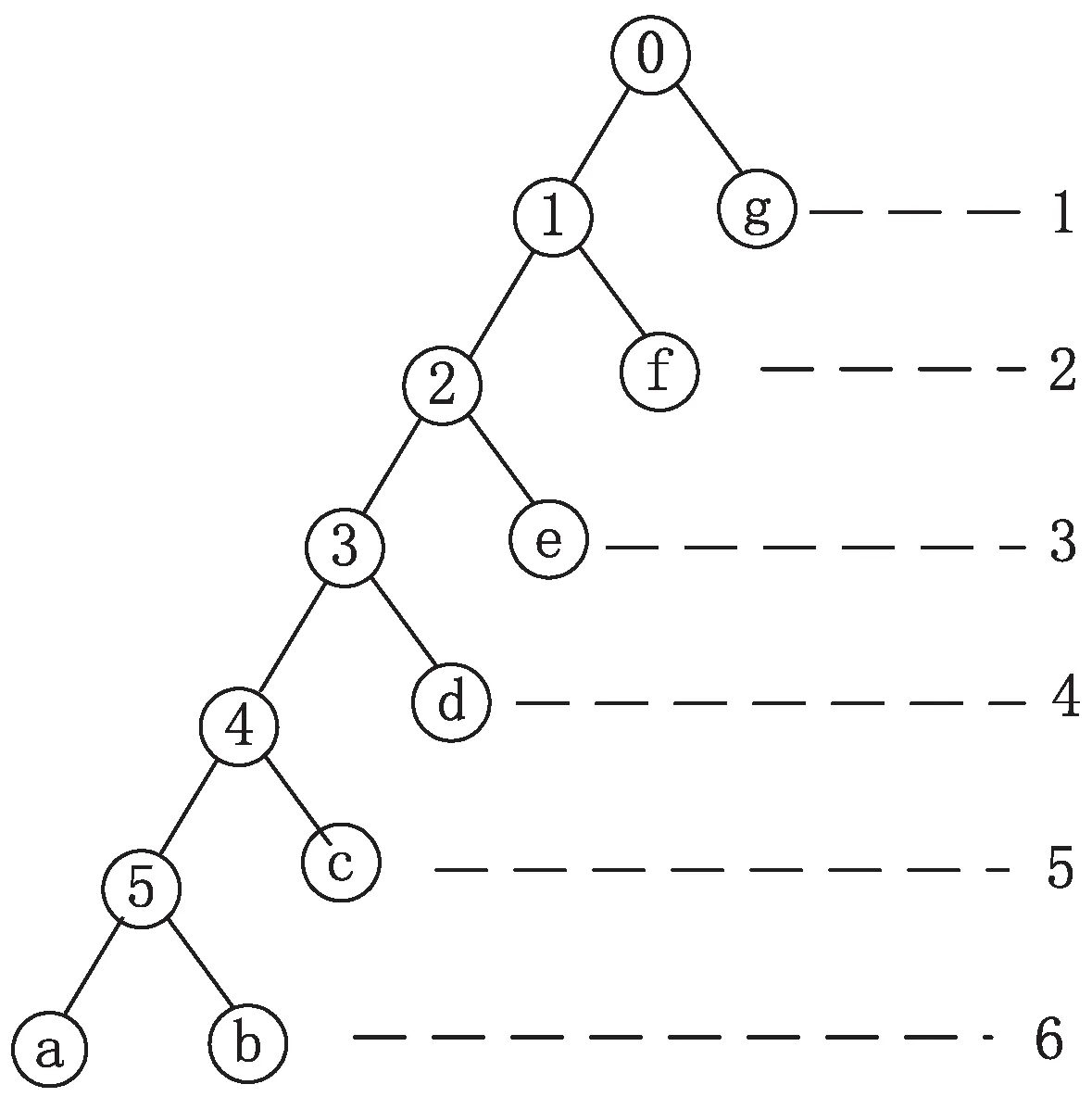
图4 Huffman树图距离
1.3 超长Huffman码校正算法
在Zlib、Gzip等压缩标准的参考代码里,使用一种基于二叉树搜索的校正方案。以图4为例,假定此树的规定最大高度为5,需要对该树上码长大于5的叶子节点进行校正。校正流程描述如下:
第1步:遍历整棵Huffman树,找到一对码长最长的兄弟叶子节点(“a”和“b”)。
第2步:遍历整棵Huffman树,找到一个比规定码长小1的叶子节点(“d”)。
第3步:把第1步中兄弟节点的一个放入父节点的位置,裁取另一个叶子(把“a”节点放入“5”节点位置,裁取“b”节点)。
第4步:把第1、2步中选取的叶子节点(“d”与“b”)组合成一对兄弟节点,它们的父节点的位置就是“d”的原位置。
上述软件校正流程如图5所示,需要遍历二叉树找到超长节点位置跟“嫁接位置”。由于二叉树无法直接通过索引寻址,需要搜寻二叉树,通过链表寻址方式找到目标节点。要想用硬件化实现上述软件校正流程,由于硬件很难实现对二叉树搜索,此外整个搜索流程耗时非常大。某些情形下,Huffman码树上超长的叶子节点可能会存在很多,以上遍历搜索流程不能并行实现处理,这会加剧校正哈夫曼码树的时间消耗,极端情形下,校正Huffman Tree的时间消耗会数倍于构建哈夫曼码树的时间消耗。如上所述,二叉树搜索的校正方案校正超长码的时间消耗较大,并且不利于硬件实现,因此十分有必要找到一种易于硬件实现的快速校正方案。
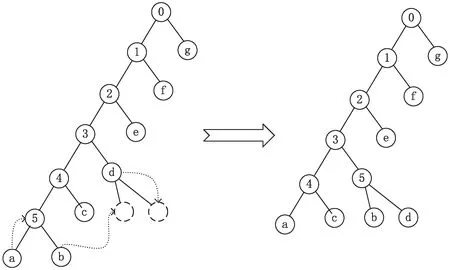
注:1.找到一对超长的兄弟节点(“a”和“b”); 2.找到嫁接位置“d”;3.把“a”节点放入“5”所示的位置;4.将“b”与“d”组成一对兄弟节点。
2 基于上下文模型的校正方案
2.1 超长Huffman码概率统计实验
由二叉树理论可知,Deflate协议中Huffman码长理论上会超过限定的最大值。为了探究超长Huffman码的发生概率,利用Zlib参考代码设计如下实验:
(1)运用Zlib代码压缩参考数据集(Silesia & Canterbury)里面每个文件,统计每个文件分块数目block-number。
(2)Zlib代码中包含校正超长Huffman码的函数接口,通过统计调用校正接口的次数来统计超长Huffman块的数目ultra-block-number。
(3)超长码的发生概率计算方法如式(2):
(2)
上述超长码概率统计实验数据如表2所示,最后计算得超长Huffman码的平均发生概率为35.5%,由此说明超长Huffman码的出现频率比较高。所以,有必要找到一种快速校正哈夫曼码树的硬件方案。
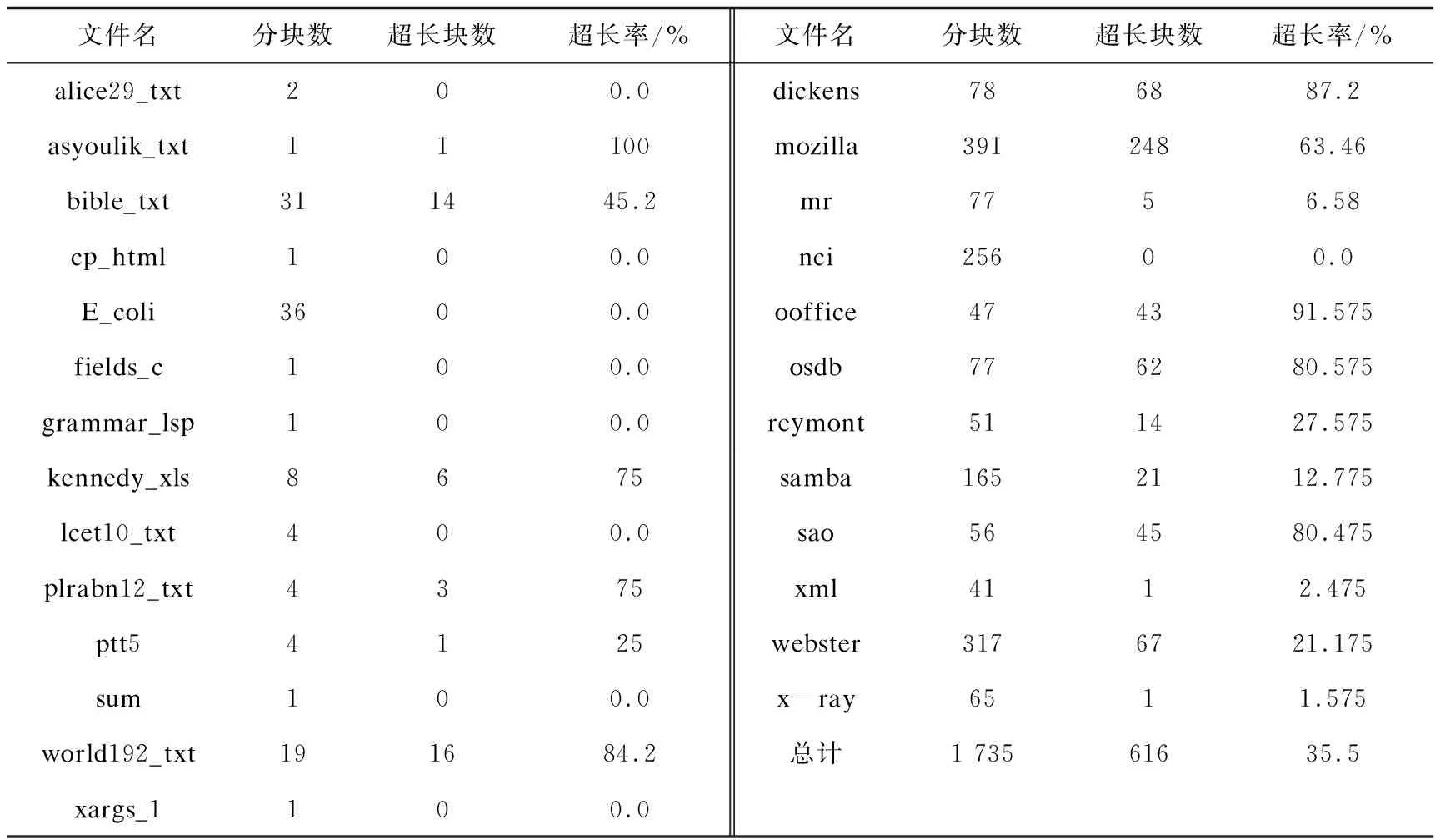
表2 参考数据集超长Huffman频率统计
2.2 上下文间Huffman码表相似性实验
上下文模型是利用上文与下文之间的相似性构建的算法模型。在数据压缩编码中,上下文模型有广泛的应用:H264、HEVC等视频编解码标准中采用的CAVLC、CABAC两种熵编码方案都是基于上下文模型构建[13-14];LZ77算法为了搜索重复数据构建的字典也是一种上下文模型。
假设上下文之间的哈夫曼码表具有很高的“相似性”,可以利用上文中的正常哈夫曼码表来对下文的源符号(source symbol)进行编码,从而规避超长的哈夫曼码树,实现“校正”超高哈夫曼码树的功能。
上述校正方案成立的假设条件是上下文之间的哈夫曼码表具有很高的“相似性”,为了测试上下文之间的哈夫曼码表具有很高的相似性,设计如下实验,利用PSNR(峰值信噪比,Peak Signal to Noise Ratio)指标评价上下文间哈夫曼码表的相似性。
在图像视频领域,PSNR是一种评价图像质量的客观标准。图像(视频)压缩领域通常为有损压缩,即编解码后的影像会跟原始影像不同,编解码领域一般采用PSNR值作为衡量编解码算法的性能指标[12]。PSNR[15]的计算方法如公式(3):
(3)
式中,Peak为像素的最大值,Peak值与像素的bit数n有关:Peak=2n-1。
MSE为原始影像与编解码后影像之间的均方差,MSE的计算方法如公式(4):
(4)
式中,N为图像中像素的数目,P为像素值。所以,PSNR也可用公式(5)计算:
(5)
PSNR不仅是一种评价图像质量的指标,也是一种判断图像相似性的指标。事实上从公式的内容看,PSNR就是通过计算两幅图像(原始图像与处理后图像)之间的差异性来评价图像质量的。HEVC、VP9等视频编解码标准用PSNR作为评价视频中前后帧相似性的指标[13-14〗,PSNR值越大,相似性越高。在本实验中,利用PSNR指标衡量前后两个数据块的Huffman树的相似性计算。
Deflate中Huffman码长用4bit数字标识,即公式(5)中n取值为4;公式(5)可以转换成公式(6):
(6)
Deflate协议中Literal & length的符号数目为286,Distance的符号数目为30;所以两种Huffman码表的均方差公式分别如下:

literal_cl1[i])2
(7)
式(7)为Literal & length码表均方差公式,其中literal_cl1[]为上文码表,literal_cl2[]为下文码表;
式(8)为Distance码表的均方差公式,其中dist_cl1[]为上文码表,dist_cl2[]为下文码表。
运用公式(6)~(8)统计计算测试集中上下文之间两种Huffman码表的相似性(PSNR)数据。图6为测试数据集中三种典型文件数据的上下文之间的PSNR数值分布图。“bible”、“mr”、“cp.html”分别代表文本、图像、网页三种最常见的格式文件:其中“bible”是一个文本数据[16],“mr”是一张医疗诊断照片[17],“cp.html”是一个html格式网页文件[16]。
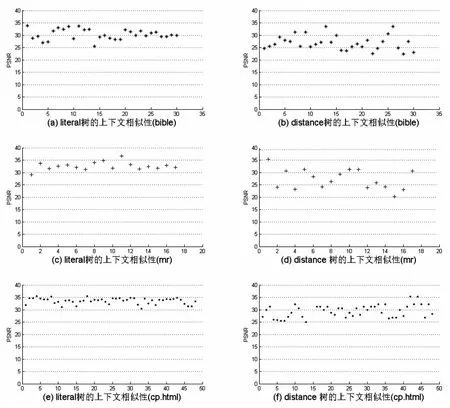
图6 上下文之间Huffman码表相似性(PSNR)散点图
图中第1列为上下文之间Literal-Huffman码表的相似数据,PSNR的值总体大于30。第2列为上下文之间Distance-Huffman码表的相似数据,PSNR的值总体大于30。说明两种Huffman树的上下文间的相似性比较高。
统计并计算图6每个子图中PSNR数据的中值,评估上下文之间总体PSNR取值,计算结果见表3。
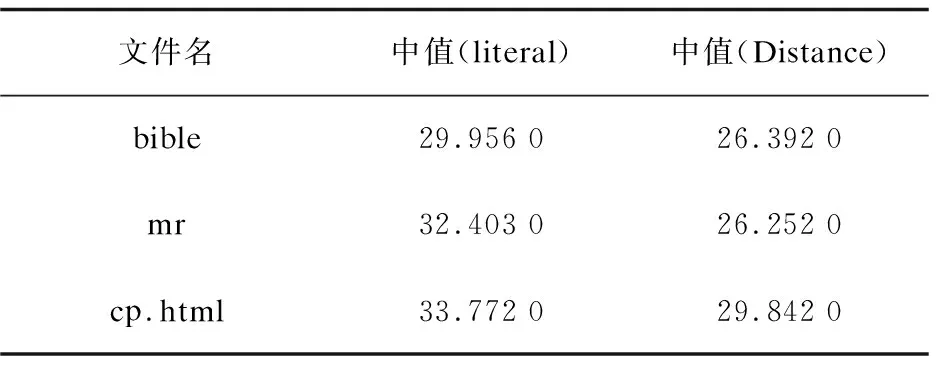
表3 Huffman码表上下文间PSNR统计值(中值)
之所以统计计算中值,而不是均值,是因为块间的Huffman码表如果完全一致,其MSE的值为0,PSNR取值无穷大,均值也无穷大。
由图6以及表3可以看出,对于Literal类型的Huffman码表,三个文件的上下文之间的PSNR中值分别为29.956 0(bible)、32.403 0(mr)、33.772 0(cp.html)。可以认为Literal类型码表PSNR总体取值在30以上。对于Distance类型的Huffman码表,三个文件的上下文之间的PSNR中值分别为26.392 0(bible)、26.252 0(mr)、29.842 0(cp.html)。由此可以认为总体取值在25以上。通常采用以下PSNR经验阈值来评定相似性[9,13-14]:PSNR如果大于35,接近一致;PSNR如果大于25,高度一致。PSNR如果小于15,相似性较低。因此可以认定,上下文之间的两种哈夫曼码表都具有很高的相似性,即上下文之间哈夫曼码表具有高度相似性的假设成立。
2.3 基于上下文模型快速校正超长Huffman码方案
基于上下文模型设计了一种快速校正超长Huffman码的硬件方案(如图7所示),在常规Deflate编码方案中添加一组参考Huffman码表(该文采用的上下文模型)。参考Huffman码表用来保存最新的常规的Huffman码表,当发现哈夫曼树超长时,会直接运用参考Huffman码表编码源数据,编码流程中会对参考Huffman码表更新。
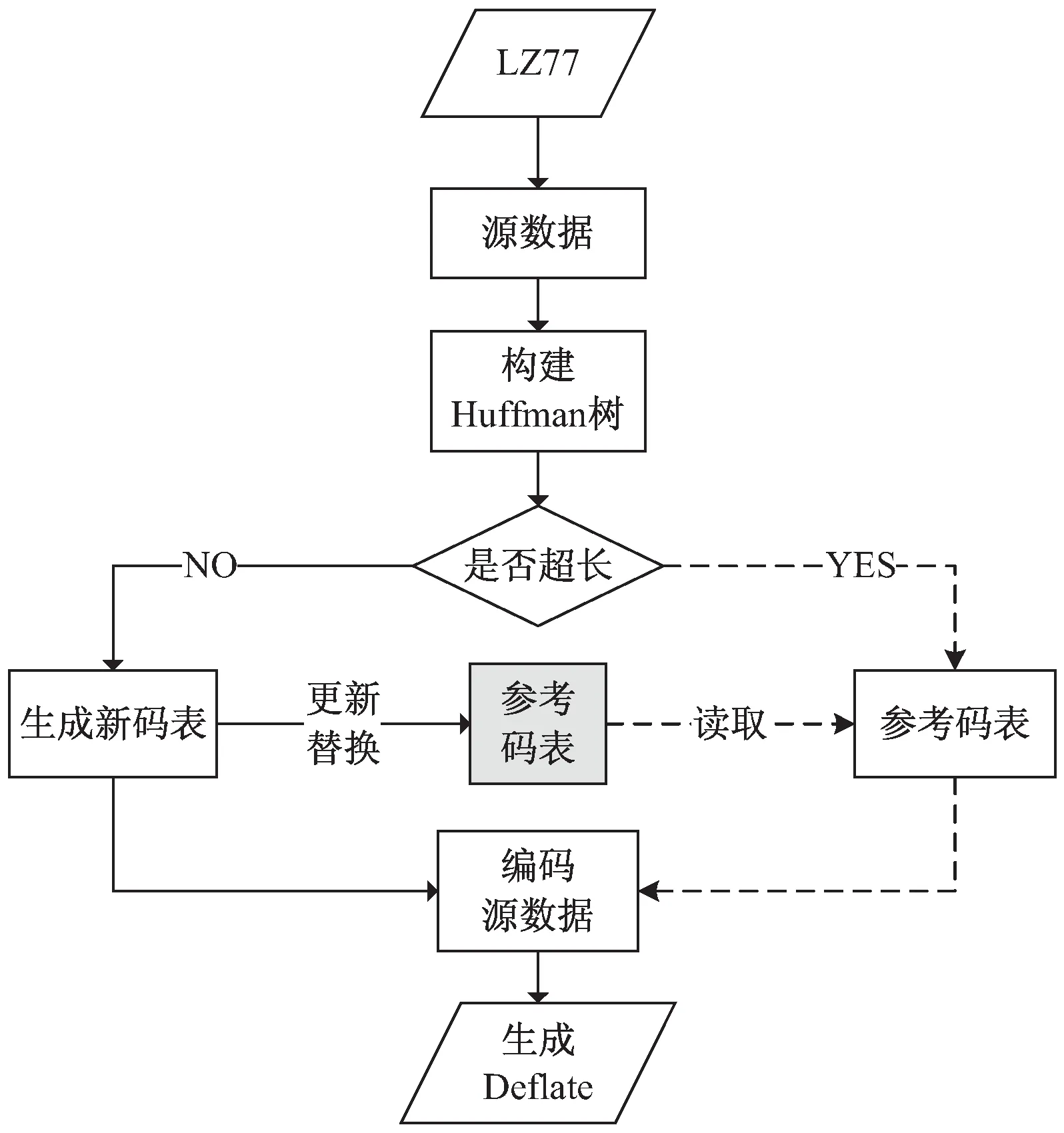
图7 基于上下文模型校正超长Huffman码流程
第1步:Deflate模块对LZ77输出的源数据进行统计排序,并构建Huffman树。
第2步:Huffman树构建完成后,判断Huffman树的最大节点深度是否超出限定值。
如果原树的高度不超过限定值,此时不需要校正Huffman树,执行常规编码流程(第3步)。
如果原树高度超出限定值,此时需要执行校正流程(第4步)。
第3步:常规流程,如前文所述。利用Huffman树生成常规Huffman码表,并利用Huffman码表编码源数据。同时会利用参考Huffman码表记录常规Huffman码表,即用本次生成的码表刷新(写)参考码表的数值,伪代码算法1。参考码表会参与下文中超长Huffman码的校正。
算法1:Huffman码表参考算法。
for index = 0 : max_symbol
Ref-Huff-table [index].length ← Huff-table [index].length
Ref-Huff-table [index].code ← Huff-table [index].code
end
第4步:校正流程(图),利用参考Huffman码表实现校正功能:直接用参考Huffman码表编码源数据,即当前块数据采用与上一个块相同的Huffman码表进行数据编码。校正流程中无需更新参考码表。
如上所述,在校正流程中,直接利用上文中已生成的常规Huffman码表编码下文的源数据,因此该校正方案会将校正Huffman树的时间消耗降为零,可以提高Deflate的压缩效率。
3 上下文模型校正方案的测试实验
上文中提出一种基于上下文模型的校正方案,该方案具有校正效率快的优点,同时还需要获取该方案的数据压缩性能(压缩比,Ratio)。为此,实验中选用常见的两个压缩测试数据集Canterbury和Silesia[16-18]测试评估上下文校正方案的压缩性能。这两组测试数据集既有文本、图像、网页等传统类型的数据文件,也包含数据库、多媒体、程序文件等新型数据文件。运用两种方案(上下文模型与二叉树搜索方案)压缩数据集内的所有文件(表2中所示的不存超长块的文件无需再测试),通过对比两种方案的压缩比,评估上下文模型校正方案的性能。表4为测试实验的数据统计。
表4对比两种校正方案的压缩性能。第1列(文件名)与第2列(Size)表示测试集内文件名及其文件大小;第3列为运用软件算法压缩文件得到的压缩比(Ratio);第4列用上下文模型方案压缩得到各个测试文件的压缩比;第5列(Delta)代表两种方案之间的压缩比差值(第4列数字减去第2列数字);第6列(Delta-rate)的数据含义为该方案与软件方案相比,压缩比的增长率(Delta/Ratio软件);最后一行的数据为总体数据的均值。
由第5列、第6列的数据可以直观看出,与软件方案相比,上下文校正方案对于压缩性影响非常小:压缩比仅仅下降0.009 4,下降的百分率为0.372%。如果从压缩比较评估,设计的基于上下文模型的校正方案对于压缩性能的影响几乎忽略不计。在基于上下文模型的校正方案中,规避掉超长Huffman码,直接使用参考码表参与Deflate编码,与软件校正方案相比,上下文校正方案省去“搜索”、“嫁接”等环节,因此该方案的校正时间为零。此外软件方案“搜索”、“嫁接”等子流程,不易用硬件实现,而基于上下文模型的校正方案易于硬件化实现。
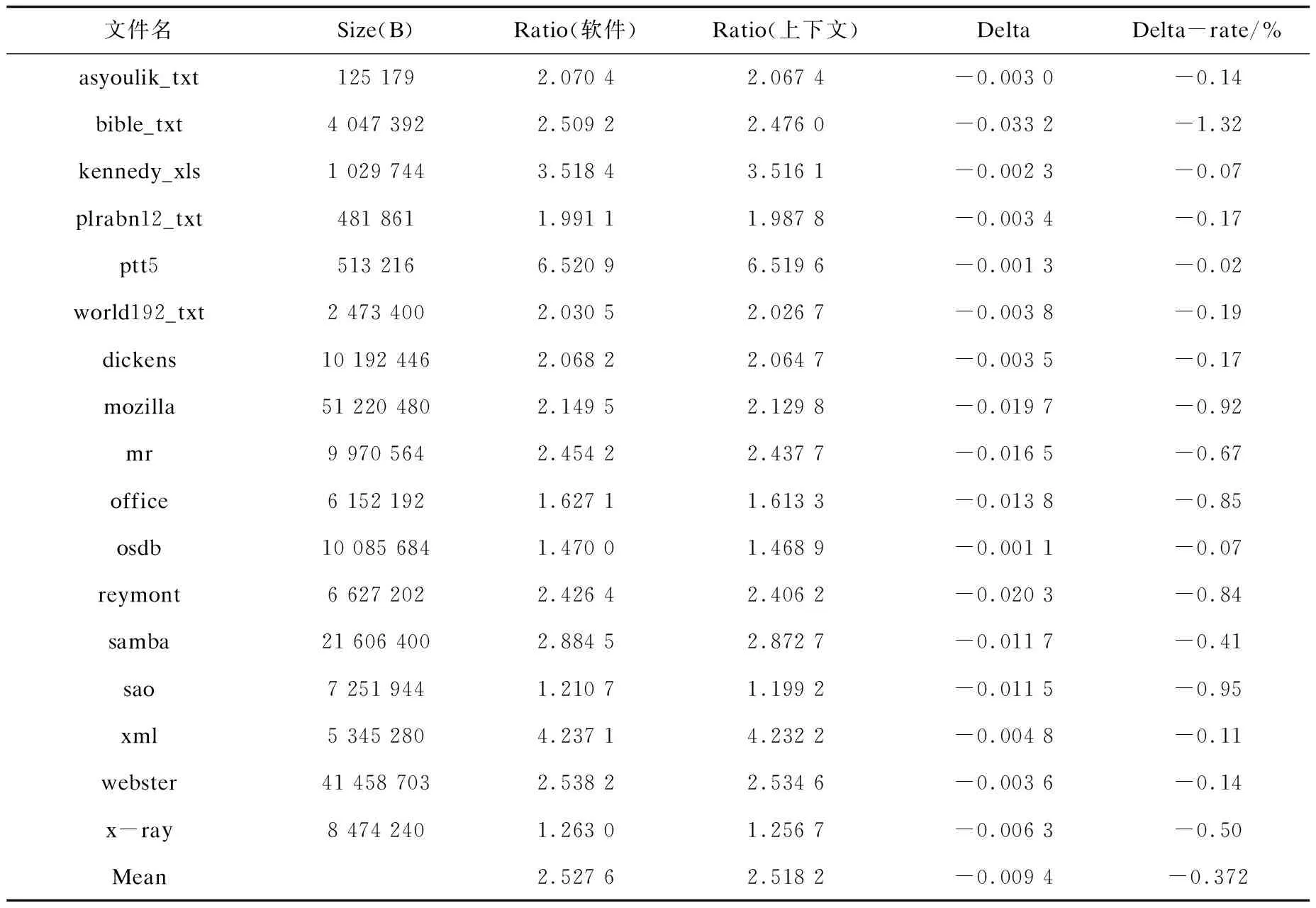
表4 两种校正方案的压缩对比
4 结束语
提出一种基于上下文模型校正超长Huffman码的方案,方案会利用参考Huffman码表保存上文中生成的Huffman码表,参考Huffman码表会用于编码下文的存在超长Huffman码的数据块。论文中所述基于上下文模型的校正方案可以快速实现对超长Huffman码的校正,并且易于通过硬件电路实现。与此同时,相对Zlib等软件代码中校正方案,将该校正方案用于数据压缩,测试数据的整体压缩比下降仅为0.009 4,下降率仅仅为0.372%,由此可以认为数据的压缩效果几乎没有区别。综上,基于上下文模型校正超长Huffman码的方案是一种快速的硬件校正方案。
