基于上下文增强和特征提纯的小目标检测网络
2023-03-02肖进胜乐秋平杨力衡
肖进胜 赵 陶 周 剑 乐秋平 杨力衡
1(武汉大学电子信息学院 武汉 430072)
2(测绘遥感信息工程国家重点实验室(武汉大学)武汉 430079)
小目标检测作为目标检测中的难点技术,被广泛应用于自动驾驶、医学领域、无人机导航、卫星定位和工业检测等视觉任务中.近些年基于深度学习的目标检测算法发展迅猛.以YOLO(You Only Look Once)[1]和SSD(Single Shot MultiBox Detector)[2]为代表的一阶段算法直接预测出目标的位置和类别,具有较快的速度.而二阶段算法[3-4]在生成候选框的基础上再回归出目标区域,具有更高的精度.但是这些算法在检测只含有较少像素的小目标(小于32×32 像素)时表现较差,检测率甚至不到较大目标的一半.因此,小目标检测仍然具有很大的改进空间.
小目标检测效果差主要是由于网络本身的局限性以及训练数据不平衡所导致[5].为了获得较强的语义信息和较大的感受野,检测网络不断堆叠下采样层,使得小目标信息在前向传播的过程中逐渐丢失[6],限制了小目标的检测性能.特征金字塔网络(feature pyramid network,FPN)[7]将低层特征图和高层特征横向融合,可以在一定程度上缓解信息丢失的问题[1-2].然而FPN 直接融合不同层级的特征会造成语义冲突,限制多尺度特征的表达,使小目标容易淹没于冲突信息中.同时,目前主流的公开数据集中,小目标的数量远远小于较大目标,使得小目标对损失的贡献小,网络收敛的方向不断向较大目标倾斜.
针对小目标检测效果差的问题,本文提出一种上下文增强和特征提纯相结合的复合FPN 结构,该结构主要包括上下文增强模块(context augmentation module,CAM)和特征 提纯模 块(feature refinement module,FRM).同时,提出一种复制—缩小—粘贴(copy-reduce-paste)的数据增强方法,具体有3 点:
1)CAM 融合多尺度空洞卷积特征以获取丰富的上下文信息,补充检测所需信息;
2)FRM 引入通道和空间自适应融合的特征提纯机制以抑制特征中的冲突信息;
3)通过copy-reduce-paste 数据增强来提高小目标在训练过程中对损失的贡献率.
1 相关工作
1.1 现代目标检测器
目标检测是一种基础的计算机视觉任务,经过多年的发展,基于卷积神经网络(convolutional neural network,CNN)的目标检测器逐渐成为主流.RCNN[3]首先生成候选区域以匹配不同尺寸的目标,然后通过CNN 筛选候选区域.FasterR-CNN[4]将候选区域生成阶段和分类阶段结合在一起,以提高检测速度.EFPN[8]提出超分辨率FPN 结构以放大小目标的特征[9].一阶段网络SSD 将锚盒密集的布置在图像上以回归出目标框,同时充分利用不同尺度的特征,以检测较小目标.YOLOV3[1]利用特征金字塔的3 层输出分别检测大、中、小目标,明显提高小目标检测性能.RefineDet[10]引入一种新的损失函数以解决简单样本和复杂样本不平衡的问题.同时也有研究者提出基于anchor-free架构的检测器[11].尽管目标检测算法发展迅速,但是小目标检测率却一直较低.本文选用带有FPN 的YOLOV3 作为基础网络,并在此基础上做出改进.
1.2 多尺度特征融合
多尺度特征是一种提高小目标检测率的有效方法.SSD[2]首次尝试在多尺度特征上预测目标位置和类别.FPN[7]自上而下地将含有丰富语义信息的高层特征图和含有丰富几何信息的低层特征图横向融合.PANet[12]在FPN 的基础上添加了额外的自下而上的连接以更高效地传递浅层信息到高层.NAS-FPN[13]利用神经架构搜索技术搜索出了一种新的连接方式.BiFPN[14]改良了PANet 的连接方式,使其更加高效,并在连接处引入了简单的注意力机制.虽然文献[12−14]中的结构都能提升网络多尺度表达的能力,但是都忽略了不同尺度特征之间冲突信息的存在可能会阻碍性能的进一步提升,本文则充分考虑了冲突信息对检测精度的影响.
1.3 数据增强
深度学习是基于数据的方法,因而对训练数据的预处理是其关键的一环.常见的数据预处理方法如旋转、变形、随机擦除、随机遮挡和光照畸变等.Stitcher[15]将4 张训练图像缩小为原图的1/4,并且将它们拼接为1 张图像来实现小目标的数据增强,同时将损失值作为反馈信号以指导数据增强的进行.YOLOV4[16]将4 张训练图像缩小为不同大小并且拼接为1 张来实现小目标的数据增强.文献[15−16]中的方式对于目标尺寸普遍很大的图像来说,会将大目标图像缩小为中等目标大小,最终提高中等目标图像的检测率.Kisantal 等人[5]采用将图像的小目标区域复制然后粘贴回原图的方式实现小目标数据增强.但这种方式只能增加小目标个数而不能增加含有小目标的图像个数,也会造成一定的不平衡.本文提出的数据增强算法则基于较大目标广泛分布于训练的各个批次的事实,保证训练平衡进行.本文算法结构图如图1 所示:
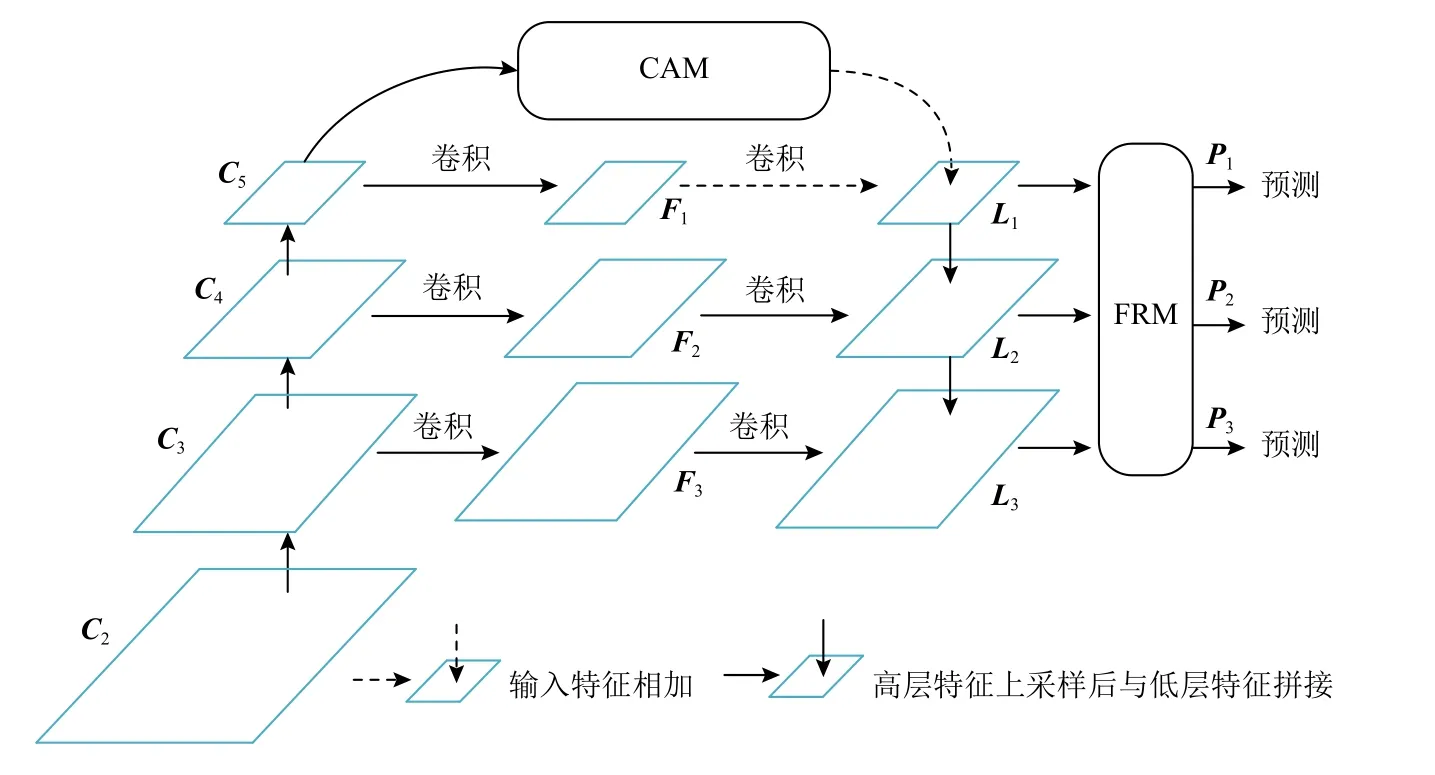
Fig.1 Overall network structure of FPN图1 FPN 总体网络结构
2 本文算法
图1 中{C2,C3,C4,C5}分别表示图像经过{4,8,16,32}倍下采样后的特征图,{C3,C4,C5}经过1 层卷积后分别生成{F1,F2,F3},其中C2由于含有大量噪声而未被使用.{L1,L2,L3}分别是{F1,F2,F3}经过FPN后的结果,{P1,P2,P3}为{L1,L2,L3}经过FRM 的输出.
CAM 启发于人类识别物体的模式.如,我们很难分辨很高天空中的小鸟,但是考虑天空作为其背景,我们就很容易分辨出,因为从我们学习到的知识中可知,在天空背景下的微小目标很有可能是小鸟,而这种背景信息,即是目标的上下文信息.因此如果目标检测网络也在图像中学习到这样的“知识”将会有助于检测小目标.
由于FPN 不同层的特征密度不同,因而含有大量的语义差异,在实现信息共享的同时也引入了很多冲突信息.因此,本文提出了FRM 用于过滤冲突信息,减少语义差异.FRM 通过将不同层间的特征自适应融合,以达到抑制层间冲突信息的目的.
针对小目标对损失贡献低的问题,提出了一种copy-reduce-paste 数据增强方法,以提高小目标对损失的贡献.
2.1 上下文增强和特征提纯的特征金字塔网络
2.1.1 上下文增强模块(CAM)
目标检测需要定位信息也需要语义信息,处于FPN 最低层的L3含有较多的定位信息而缺少语义信息.FPN 自上而下的信息共享结构在通道数减少之后才进行融合,使得L3未能获取充分的语义信息.为此我们利用不同空洞卷积率的空洞卷积来获取上下文信息,并将其注入到FPN 中,以补充上下文信息.
图2(a)是CAM 的结构图.对于大小为[bs,C,H,W]的输入分别进行空洞卷积率为1,3,5 的空洞卷积[17].bs,C,H,W分别为特征图的批次大小、通道数、高和宽.由于该模块输入的尺寸较小,为了获取更多的细节特征,不宜使用大卷积,因此选用3×3 的卷积.同时为了避免引入较多的参数量,选取卷积核的个数为C/4,即首先压缩通道数为输入的1/4,然后再通过1×1 的卷积扩张通道数为C,得到3 种大小相同而感受野不同的输出,最后融合得到的特征.特征融合可采用的方式如图2(b)~(d)所示.图2(b),(c)分别为拼接融合和加权融合,即分别在通道和空间维度上直接拼接和相加.图2(d)是自适应融合方式,即通过卷积、拼接和归一化等操作将输入特征图压缩为通道为3 的空间权重,3 个通道分别与3 个输入一一对应,计算输入特征和空间权重的加权和可以将上下文信息聚合到输出中.
本文通过消融实验验证各个融合方式的有效性,实验结果如表1 所示.
由表1 可知,对于小目标来说,拼接融合所取得的增益最大,APs和ARs分别提高了1.8%和1.9%.自适应融合对中目标的提升最为明显,APm提升了2.6%.相加融合带来的提升则基本介于拼接融合和自适应融合两者之间,因此本文选择拼接融合的方式.
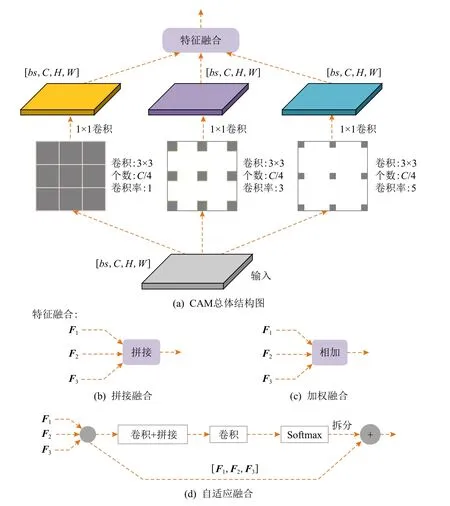
Fig.2 The structure of CAM图2 CAM 结构图
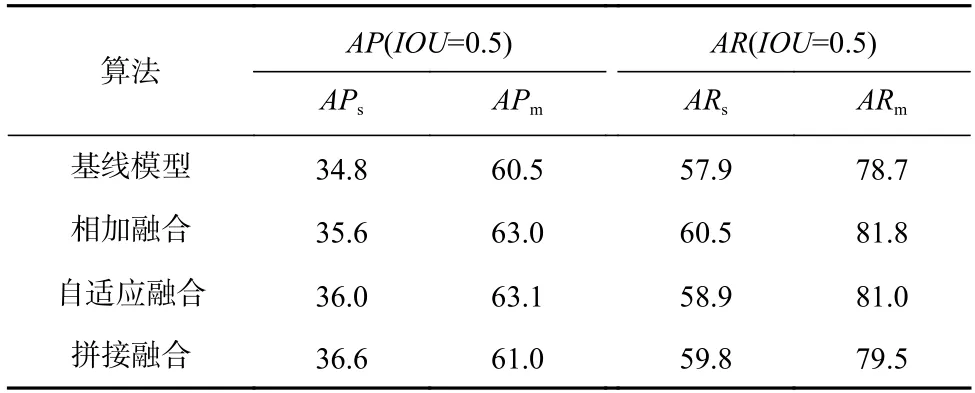
Table 1 Ablation Experimental Results of CAM表1 CAM 消融实验结果%
本文将部分特征图可视化以说明CAM 的效果,可视化结果如图3 所示.
图3(b)为CAM 输入特征图,从中可以发现在图像的目标处有微小响应,呈现为较小的“白点”.图3(c)为CAM 输出特征图,可以明显看到目标处的响应明显增强,并且响应范围更大,这是因为CAM将目标周围的上下文信息也融入特征中,使得目标处的响应更强.因此将CAM 提取的上下文信息注入网络中将有助于小目标的检测.
2.1.2 特征提纯模块(FRM)
FPN 用于融合不同尺度大小的特征,然而不同尺度的特征具有不可忽视的语义差异,将不同尺度的特征直接融合可能引入大量的冗余信息和冲突信息,降低多尺度表达的能力.为了抑制冲突信息,本文提出FRM,该模块结构如图4 所示.
图4(a)为接在FPN 第2 层后的FRM 结构图.从图(4)可看出,X1,X2,X3(FPN 的3 层输出)为该模块的输入,首先将X1,X2,X33 个输入缩放到同一大小,分别为R1,R2,R3,然后再利用拼接和卷积操作将所有输入特征的通道数压缩为3,随后接上并联的通道提纯模块和空间提纯模块.
通道提纯模块的具体结构如图4(b)所示,为了计算通道注意力,采用平均池化和最大池化相结合的方式来聚合图像的全局空间信息.用Xm表示FRM的第m(m∈{1,2,3})层输入特征图,其输出可表示为其中RS表示resize 函数,在式(1)中将X1和X3特征缩放到和X2同一尺度.α,β,γ为通道自适应权重,其尺度为1×1×1.经过归一化的 α,β,γ 代表3 个输入的相对权重,这3 个值越大表示具有更大的响应,将它们与输入相乘,响应大的输入将被放大,响应小的输入将被抑制,以此将更加有用的信息增强而抑制不重要的噪声.α,β,γ可表示为

Fig.3 Context information augmentation effect diagrams图3 上下文信息增强效果图
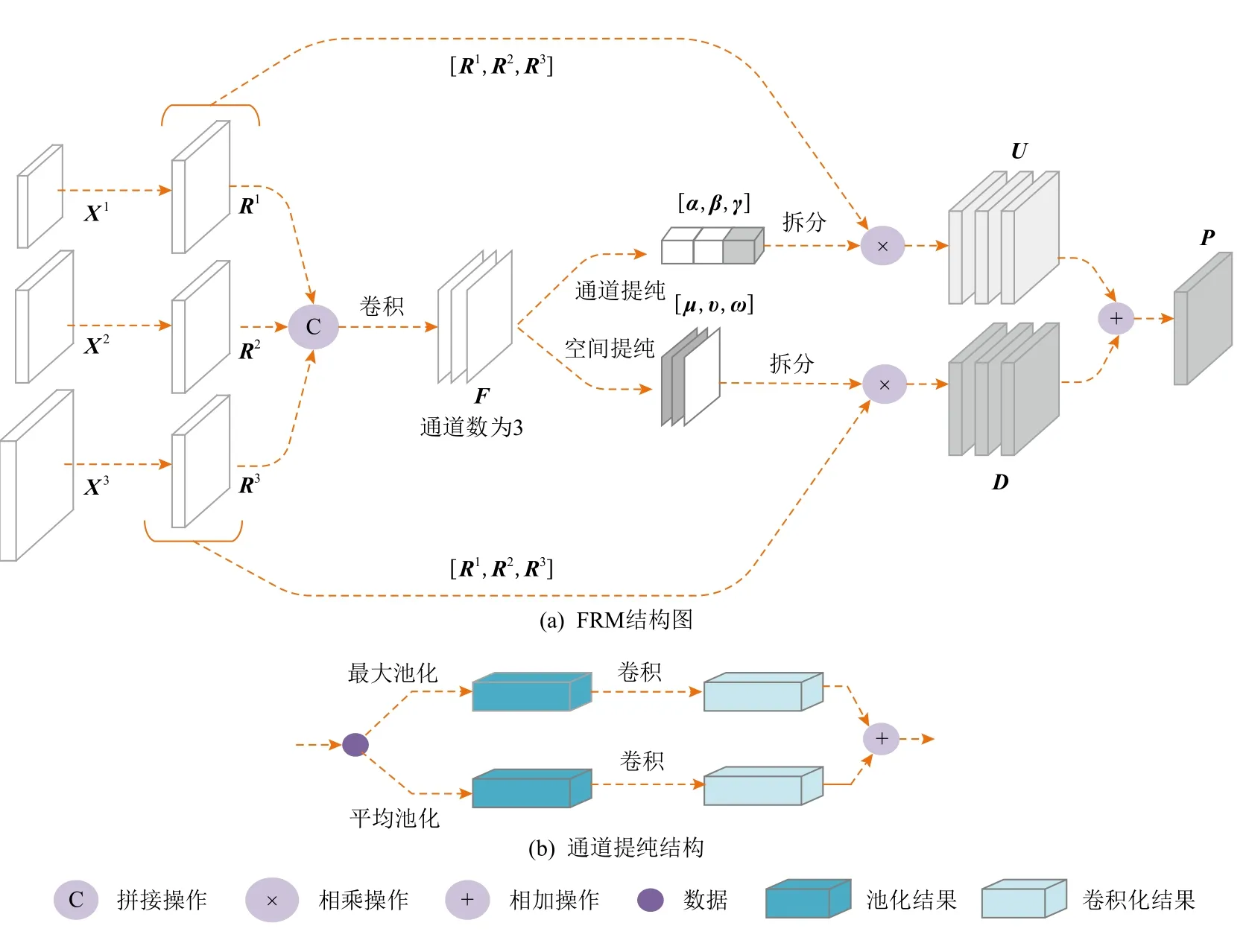
Fig.4 The structure of FRM图4 FRM 结构
其中F为图4(a)中标识的特征图,AvgPool和MaxPool分别为平均池化和最大池化操作.
空间提纯模块利用softmax 函数将特征图在空间上归一化,得到特征图中某点关于其他所有位置的相对权重,然后将其与输入分别相乘.其输出可表示为
(x,y)表示特征图的空间坐标.µ,ν,ω为空间自适应权重,目标区域的响应较大,将会获得更大的权重,反之背景区域获得的权重较小.µ,ν,ω与输入具有相同的空间大小,因此将它们和输入直接相乘可以达到将目标特征放大和背景噪声抑制的目的.µ,ν,ω可由式(4)表示.
softmax 函数用于归一化特征参数以提高模型的泛化能力.那么此模块的总输出为
FPN 所有层的特征都在自适应权重的引导下融合,融合的结果作为整个网络的输出.
为更加直观地说明特征提纯模块的作用,图5 展示了部分可视化的特征图.由于小目标的检测由FPN的最低层主导,因此我们仅可视化了最低层的特征.图5 中F3,L3,P3分别对应图1 中的标签F3,L3,P3.
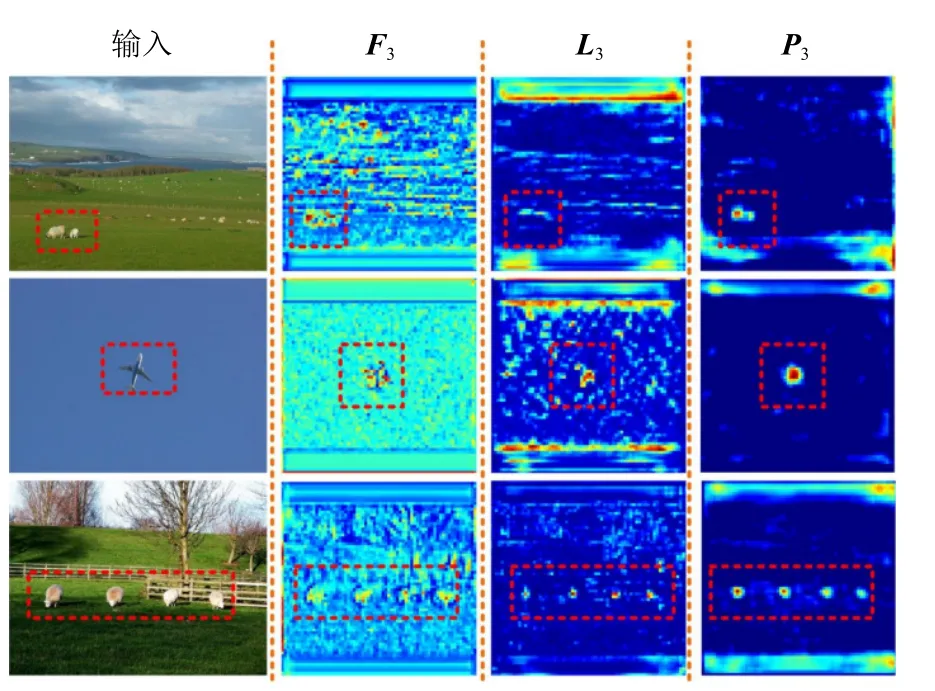
Fig.5 Visualization results of FRM图5 FRM 可视化结果
由图5 可知,F3特征可大致定位目标位置,但是包含较多背景噪声,具有较大误检的可能.L3相比于F3,背景信息明显减少,这是FPN 融合高层信息的结果.高层信息更加关注于物体的抽象信息而不关注背景信息,因此背景信息会被中和.但是由于特征的细腻度不同,引入了冲突信息,使得目标的响应被削弱.而P3的目标特征被强化,并且目标和背景之间的边界更加明显.由可视化分析可知,本文提出的FRM可减少干扰小目标的冲突信息,提高判别性,以此提高小目标的检测率.
2.2 copy-reduce-paste 数据增强
当前主流的公开数据集中,小目标的数量或包含小目标的图片数量远远小于较大目标的,如VOC数据集,统计情况如表2 所示.同时,如图6(a)所示,小目标产生的正样本数量远远小于较大目标的,因而小目标对损失的贡献率远远小于较大目标的,使得网络收敛的方向不断向较大目标倾斜.
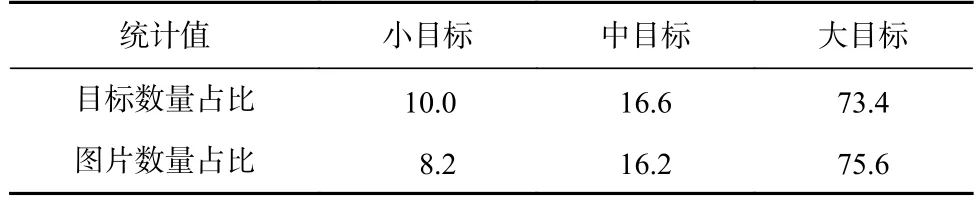
Table 2 Statistical Results of Target Size on VOC Datebase表2 VOC 数据集目标尺寸统计结果%
为了缓解这个问题,我们在训练过程中复制、缩小、粘贴图像中的目标,以增加小目标产生的正样本数量以及对损失的贡献值,使得训练更为平衡.数据增强效果如图6(b)和图6(c)所示.

Fig.6 Data augmentation examples图6 数据增强示例
图6(b),图6(c)是粘贴1 次的结果示例,实线框是原有的目标,虚线框为粘贴的目标.首先复制大目标图像块,然后对图像块进行缩小,最后粘贴到原图的不同位置.我们提出的数据增强方法并没有直接复制小目标图像区域粘贴到不同位置,这是考虑到数据集中含有小目标的图像数量较少,如果仅仅复制粘贴小目标,在很多批次中小目标对损失的贡献仍然很低.此外,我们研究了粘贴次数对小目标检测性能的影响,实验结果如表3 所示.
从表3 中可知,随着粘贴次数的增加,小目标的检测率逐渐减小,甚至会造成低于基线模型的情况.这可能是由于随着粘贴次数的增加,逐渐破坏了原始数据的分布,使得在测试集的表现较差.在粘贴1 次时,APs提高了2.5%,ARs提高了1.9%,同时中目标的检测率也略有提升,结果表明粘贴1 个目标是最佳的设定.
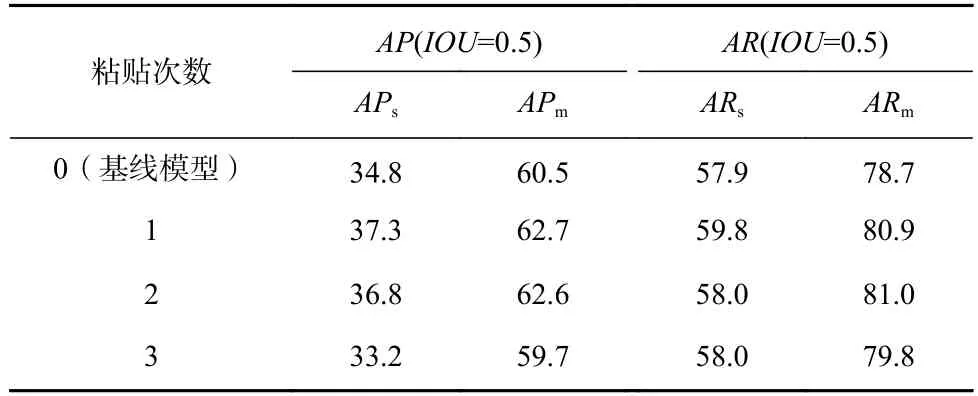
Table 3 Ablation Experimental Results of Data Augmentation表3 数据增强消融实验结果%
3 实 验
3.1 训练设置
本文实验在VOC 和TinyPerson 两种数据集[18]上进行.VOC 有22 136 张训练图像和4 952 张测试图像,共20 个类别.TinyPerson 数据集包含2 个类别,798 张训练图片和816 张测试图片,其场景多为远距离大背景下的图像,所标注目标的平均大小为18 像素,是一个真正意义上的小目标数据集.
本文所使用的评估指标为:
精度(precision,P),用来检测结果中相关类别占总结果的比重;
召回率(recall,R),用来检测结果中相关类别占总类别的比重.由P-R曲线可计算所有大、中、小目标平均检测精度的均值(mAP):
其中N为测试集总数,P(n)表示n张图像的精确度,∆r(n)表示从n−1 增加到n时召回率的变化量,k为类别数.同时,使用下标s,m,l 分别表示在小尺度、中尺度和大尺度目标上的性能.本文所有的实验在同样的软件和硬件条件下进行(pytorch[19]框架,Intel Core i7-5820k CPU@3.30 GHz 处理器,16 GB 内 存,GeForce GTX TITAN 显卡).
图7 为训练时的损失变化曲线,我们采用SGD优化器训练50 轮次(前2 个轮次预热),批次设定为8,学习率初始值为 0.000 1,训练的损失值平滑下降.部分特征可视化结果如图8 所示.

Fig.7 The curve of loss图7 损失曲线

Fig.8 Visualization results of feature maps in training图8 训练特征图可视化效果
如图8 所示,图8(b)为浅层特征,网络更关注物体的纹理信息.图8(c)为深层特征,图像的信息逐渐抽象,网络更关注物体的高层语义信息.
3.2 实验结果
为验证本文算法在小目标检测上的有效性,本文在TinyPerson 和VOC 数据集上分别进行了实验.
本文复现了4 种算法在TinyPerson 数据集上的检测结果,由于该数据集几乎全是小目标,因此只进行APs指标的对比,对比结果如表4 所示.
由表4 可知,本文算法在该数据集上的APs达到55.1%.相比YOLOV5 和DSFD 算法,本文算法分别有0.8%和3.5%的提升,而相比于AL-MDN 和MaskRCNN 则分别高出21%和12.6%.
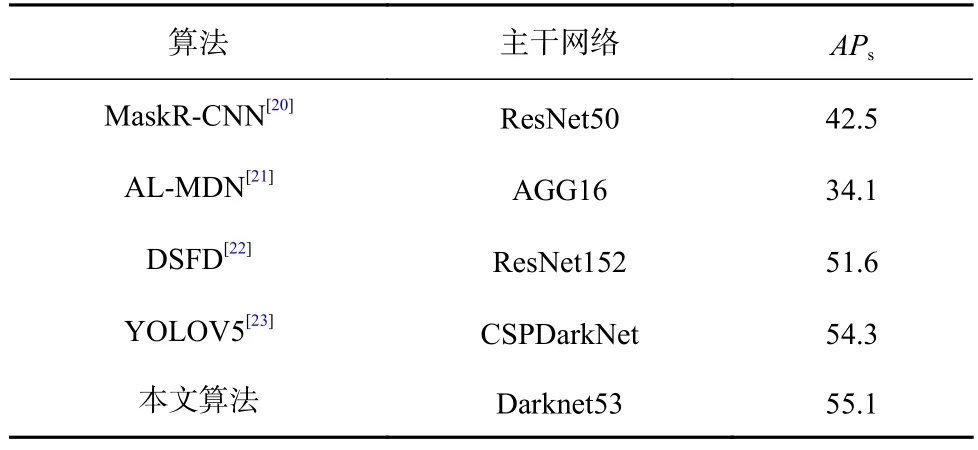
Table 4 Detection Results on TinyPerson Dataset表4 TinyPerson 数据集上的检测结果%
本文复现了3 种较为前沿的目标检测算法在VOC 上的结果,并且比较这些算法在小目标、中目标上的AP和AR,实验结果如表5 所示:
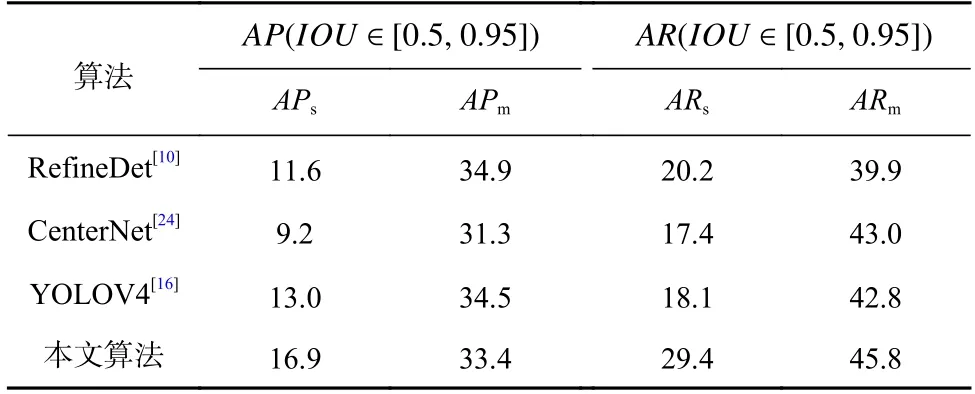
Table 5 Results of Small Targets Detection on VOC Dataset表5 VOC 数据集上的小目标检测结果%
由表5 可知,本文算法相比于YOLOV4,APs高3.9%,ARs高11.3%;相比于RefineDet,APs高5.3%,ARs高9.2%;而相比于CenterNet,本文算法的APs和ARs分别具有7.7%和12.0%的优势.不难发现,本文算法在小目标的召回率上具有较大优势,说明本文算法具有较强的小目标查找能力.
将本文算法和近几年的一阶段算法和二阶段算法在VOC 数据集上的mAP进行对比,对比结果如表6所示.
由表6 可知,与一阶段算法相比,本文算法比PFPNet 的mAP高1.3%,具有最好的表现.与二阶段算法相比,本文算法优于大部分的二阶段算法,但比IPG-Net 的mAP低1.2%,这主要是由于本文算法的主干网络性能较差以及输入图像大小较小.如果本文采用多尺度测试的方法,则在VOC 数据集上的检测率可达到85.1%,高于所有的对比算法.
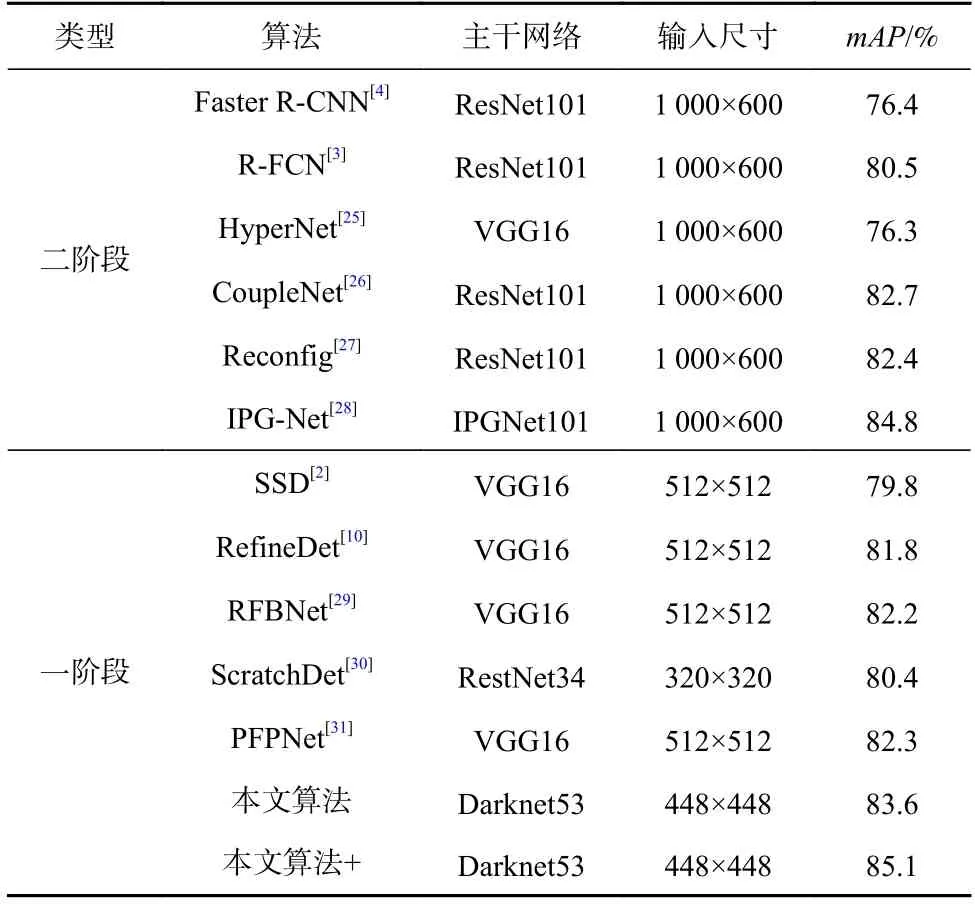
Table 6 Experimental Results on VOC Dataset (IOU=0.5)表6 VOC 数据集上的实验结果(IOU=0.5)
本文算法对小目标的检测具有较大优势,不管是总体检测效果还是小目标的检测率、召回率都表现良好,优于大多数检测算法.
3.3 消融实验
本文以消融实验验证每个模块的贡献.通过逐个添加数据增强方法、CAM 和FRM 到基线模型YOLOV3中,得出实验结果如表7 所示:
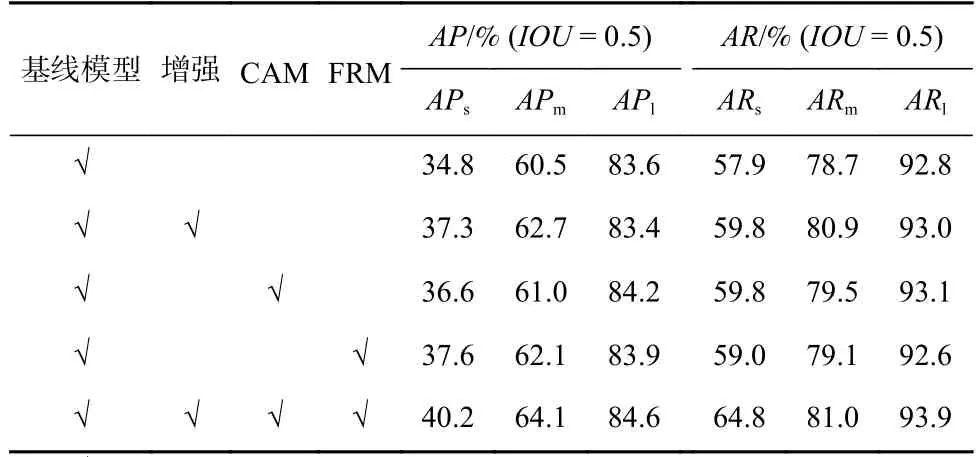
Table 7 Ablation Experimental Results表7 消融实验结果
总体来说,本文提出的算法可显著提高目标检测率,尤其是小目标和中等目标的检测率,这也符合本文算法的初衷.如表7 所示,APs提升5.4%,APm提升3.6%,而APl提升1.0%.同时对于不同尺度目标的召回率也有不同程度的提升.具体来说,ARs提升6.9%,ARm提升1.3%,ARl提升1.1%.
copy-reduce-paste 数据增强方法将APs和APm分别提高2.5%和2.2%.而APl略有下降.由此可知,该方法可有效提高小目标检测率.
CAM 分别提高小目标的APs和ARs1.8%和0.6%.证实了补充上下文信息对于小目标检测的重要性.
FRM 将APs和APm分别提高2.8%和1.6%,而APl基本持平.由此可见,FRM 可滤除特征的冲突信息,提高较小目标特征的判别性.
4 总结
小目标特征模糊,能够提取的特征少,是目标检测领域的难点.为了解决小目标特征消散的问题,本文引入CAM,通过不同空洞卷积率的空洞卷积提取上下文信息,以补充小目标的上下文信息.由于小目标容易淹没在冲突信息中,本文提出FRM,该模块结合通道和空间自适应融合来抑制冲突信息,提高特征的判别性.同时,提出一种copy-reduce-paste 的小目标增强方法来提高小目标对损失函数的贡献,使得训练更加平衡.通过实验结果可知,本文提出的小目标检测网络在TinyPerson 和VOC 数据集上均表现良好,优于大多数的目标检测算法.
致谢感谢武汉大学超级计算中心对本文的数值计算提供的支持.
作者贡献声明:肖进胜和赵陶设计网络并实践;肖进胜和周剑负责论文撰写;乐秋平和杨力衡提供数据支持和文章的润色
