模糊测试中的静态插桩技术
2023-03-02王明哲姜宇孙家广
王明哲 姜宇 孙家广
(清华大学软件学院 北京 100084)
大量系统软件侧重于性能,往往使用C/C++等具有底层控制能力的程序设计语言编写.然而,这些程序设计语言若存在不规范的使用,会产生数组越界、数据竞争等不安全行为,导致软件缺陷.部分缺陷会进而引发安全问题,产生任意代码执行等重大安全影响.因此,有必要识别和修复这些缺陷.
模糊测试是一种自动化的软件缺陷发现方法.不同于传统软件测试依靠人编写测试用例,模糊测试自动生成输入并以此执行程序.测试工具在程序运行时监控崩溃或超时等异常行为,从而发现异常行为背后的软件缺陷.由于构造的输入内容具有高度的随机性,能够触发开发人员难以想象的边界条件,这些条件包含了大量容易触发异常的场景.此外,自动的输入生成允许模糊测试进行动辄数千万次的测试,广泛探索程序的状态空间.
在实际的模糊测试实践中,使用静态插桩技术作为辅助已成为事实上的标准.静态插桩技术包含2个阶段;1)在源程序编译的过程中,编译器在程序的关键位点插入额外的逻辑(即桩点);2)在程序运行时桩点被触发,从而收集执行的动态信息或改变程序的行为.在模糊测试的场景下,静态插桩技术主要用于安全特性强化和导向信息收集.该技术能够显著提升软件缺陷的发现能力,加快程序状态空间的探索速度.
安全特性强化插桩旨在提升软件缺陷的发现能力.模糊测试检测软件缺陷的方法主要依赖程序崩溃等操作系统的信号机制.然而,程序中出现的不安全行为仅有少部分会触发硬件异常(例如内存保护、除零错误)且被操作系统捕获.大部分类型的缺陷,例如绝大多数的单字节缓冲区溢出和有符号数的算术溢出,均不会触发硬件的保护机制.为了解决这些问题,静态插桩在潜在的风险位点进行额外的安全检查,从而在发生问题时通知模糊测试工具.
导向信息收集插桩旨在加快程序状态空间的探索速度.模糊测试生成的输入是随机的,因此存在难以有效探索程序的状态空间的问题,且该问题在输入高度结构化的程序和具有大量逻辑的复杂系统上尤为显著.为了解决此问题,有必要引入导向信息,使得模糊测试工具侧重于探索具有更高价值的程序状态,同时高效求解复杂约束.例如,动态测试技术发现软件缺陷的前提是触发缺陷所在的代码,所以,可以引入代码覆盖,从而将模糊测试导向尚未触发的代码位点.
此外,静态插桩引入了额外的逻辑.在提升模糊测试效果的同时,静态插桩也不可避免地降低了程序的执行速度,从而影响了模糊测试的整体吞吐量.一般地,插桩的能力越强,桩点数量越多,逻辑越复杂,带来的额外开销越大.由于模糊测试的整体效果依赖于海量执行对程序状态空间的探索,在模糊测试中使用静态插桩时,应合理取舍插桩能力和测试吞吐量.
目前,静态插桩研究主要有2 类,一是提出了新的插桩特性,二是降低了已有方法的额外开销.这些工作尽管十分有效,但都局限于单一的插桩策略,缺乏对功能和性能的系统性分析和梳理.为此,本文面向模糊测试场景下静态插桩技术,从功能和性能2方面入手,系统性分析了典型的插桩技术,测量了它们的额外开销,并由此展望了插桩技术的发展趋势.
本文的主要贡献有3 方面:
1)系统性地分析了静态插桩技术.对于安全特性强化插桩,本文从程序语言规范的角度说明了缺陷的根源,并详细分析了检测技术的核心思想.对于导向信息收集插桩,本文总结了编译期的桩点部署策略,以及运行时对导向信息的利用策略.
2)测量了插桩的额外开销.本文选取了有代表性的静态插桩方案,使用典型的模糊测试项目统计了这些插桩方案的额外开销.其中,选取的插桩方案涵盖了控制流特征采集、比较操作数收集、安全特性强化3 个最常见的插桩需求.
3)分析了静态插桩技术的优势、局限和优化方向.基于分析和测量,本文结合学术界的最新工作,讨论了模糊测试场景下静态插桩技术的优化方向.
1 研究背景
1.1 模糊测试
模糊测试起源于20 世纪90 年代,其最初目的是测试UNIX 实用程序[1].在此工作中,模糊测试工具Fuzz 生成随机输入,接着将输入通过标准输入传递给目标程序,或通过终端仿真程序ptygig 传递给交互式的目标程序,与此同时,测试工具等待程序的异常信号,生成输入、执行、等待异常的过程被脚本不断重复,从而发现软件缺陷.上述过程中,测试工具无需侵入目标程序,因此被称为黑盒模糊测试.
2008 年Godefroid 等人[2]提出了白盒模糊测试.之所以被称为白盒模糊测试是因为测试工具深入观察目标程序内部,从而系统性地探索程序的状态空间.具体地,模糊测试工具SAGE 使用符号执行技术,首先收集程序执行路径上的约束,接着对约束逐个取反并使用求解器生成新的输入,从而探索不同的分支.包括SAGE 在内的大量白盒测试工作尽管对程序有系统性的探索,但受制于约束收集和求解的性能,其发现软件缺陷的效果依然十分有限.
2014 年提出的AFL 是首个灰盒模糊测试工具[3].不同于高开销的白盒测试,灰盒模糊测试工具AFL使用轻量级插桩技术,统计程序的控制流特征并以此作为导向信息.具体地,程序执行轨迹的时空特征被映射到一个64KiB 的位图上.通过分析位图背后隐含的控制流特征,模糊测试工具能够识别出尚未发现的全新程序行为,从而继续深入探索.基于导向信息的灰盒模糊测试十分成功,发现了大量的软件缺陷和安全漏洞.因此,灰盒模糊测试获得了包括谷歌[4]、微软[5]、Adobe[6]在内的工业界的广泛应用.
1.2 静态插桩和模糊测试
在实际的模糊测试实践中,静态插桩已成为事实上的标准[7].例如,OSS-Fuzz[4]是谷歌发起的模糊测试持续集成服务,囊括了大量被广泛使用的基础软件项目.其中,全部的测试项目都使用了至少一种静态插桩技术.具体地,表1 显示了OSS-Fuzz 项目中启用模糊测试的771 个测试项目中静态插桩的使用情况.
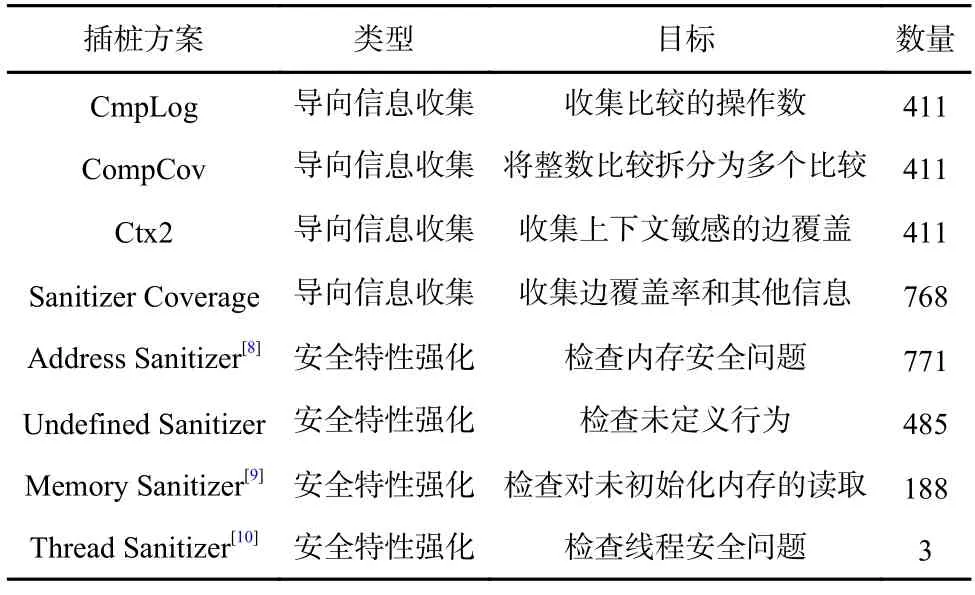
Table 1 Usage Statistics of Static Instrumentation in OSSFuzz表1 OSS-Fuzz 项目的静态插桩使用统计
观察表1 可以发现,当下模糊测试的静态插桩主要可以分为2 个类型.1)在导向信息收集方面,代码覆盖是模糊测试工具关注的核心信息.除此之外,一半多的项目也关注对比较等约束的测试效率,使用了操作数收集等方法处理.2)在安全特性强化的方面,全部的项目无一例外使用了Address Sanitizer 进行内存安全检查.大多数项目都检查了未定义行为,也有小部分项目检查了未初始化内存的访问.只有3个项目检查了线程安全问题,这主要是因为OSSFuzz 测试的软件多为基础库,其线程安全多由库的使用者维护.
1.3 插桩的基本类型
根据插桩的不同时机,插桩主要分为运行时进行的动态插桩和运行前完成的静态插桩.动态插桩在程序运行中进行,一般对内存中的机器码进行补丁;静态插桩在程序运行前进行,将原始程序插桩并生成修改后的二进制文件用于后期执行.
根据插桩能力的不同,动态插桩一般分为轻量级插桩和重量级插桩2 种类型.轻量级插桩具有较低的复杂度和执行开销.例如,LLVM[11]中的XRay在程序开头注入额外的空指令.在执行时,插桩逻辑可以将空指令替换为跳转指令,从而重定向函数的控制流并执行额外的插桩逻辑,若桩点不再需要,则可以将跳转指令回退为空指令.然而,轻量级插桩局限于对单个指令的补丁,无法提供强大的分析能力,也无法对程序逻辑进行复杂的修改.因此,在要求更强的插桩能力时,人们往往使用重量级插桩.例如,DynInst[12]对二进制程序进行复杂而全面的分析,将其抽象成从模块、函数到基本块和指令的完整体系.在程序运行时可以灵活地对体系内的对象进行高层次分析和修改,实现内存安全检查等复杂的插桩需求.
由于动态插桩的对象一般是机器码,其蕴含的语义信息远少于源码和编译器内部表示,因此难以满足模糊测试的需求.例如,内存安全检查工具为了检测栈上的缓冲区越界,需要获得栈上各个对象的内存布局.然而,上述信息在源码递降到机器码的过程中已经消失了.此外,在机器码上进行直接补丁的性能也弱于包含复杂优化的编译器,一般会带来高达数十倍的额外开销[13],大大降低了模糊测试的吞吐量.因此,当下的模糊测试一般使用基于编译器的静态插桩.
基于编译器的静态插桩一般以程序的源码或编译器内部的中间表示作为输入.以编译器Clang 为例:源码首先被Clang 前端变换为LLVM 中间表示,该中间表示经由LLVM 中端,完成清理、归一化和优化;接着被LLVM 的指令选择组件变换为机器中间表示,机器中间表示被LLVM 后端进一步完成平台相关的优化和递降;最后AsmPrinter 组件将该中间表示由MC 层生成ELF 等平台相关的对象文件.在此过程中的各个环节都可以插桩.例如,可以在Clang 前端结合源码的语义信息,对程序设计语言内部的未定义行为进行捕获和检测;可以在LLVM 中端匹配和内存安全相关的指令(例如内存读写)并插入检测器,从而实现通用的内存安全强化.
2 安全特性强化插桩
2.1 内存安全检查
手动内存管理是系统程序设计中极其容易出错的环节.在系统程序中,对内存的申请、使用和释放操作均可能带来内存安全问题.本节列举3 个经典的内存安全问题.
1)内存申请.若申请的内存大小受攻击者直接控制,攻击者可以构造畸形的内存申请请求,从而使程序耗尽资源.
2)内存使用.若访问偏移量超过了内存对象的大小,则会造成经典的缓冲区溢出问题.攻击者可以依此泄漏程序中的数据,或覆盖栈帧所保存的函数返回地址,造成任意代码执行.
3)内存释放.若释放过早(或称为释放后使用,use-after-free)或释放了非malloc 返回的对象,则可能使多个内存对象重叠,使得攻击者任意控制内存对象的值.若忘记释放,则会造成内存泄漏,攻击者可以耗尽程序资源造成拒绝服务攻击.
这3 个安全问题时常不能造成程序崩溃,因此不能被模糊测试工具所发现.不能有效检测内存安全的另一个重要的原因是硬件的局限.例如,x86 的微处理器中,内存管理单元支持的最小粒度为4KiB.若越界的地址恰好在当前页内,则无法触发硬件内存保护.此外,由于系统软件注重执行效率,内存分配策略也主要侧重于降低开销而非增强安全性.例如,现代微处理器的指令集架构一般要求内存对齐,否则会造成访问下降或硬件异常.举一个简单的例子:在AArch64 下,只能以8B 的整数倍的地址访问64b整数.在构造栈布局时,编译器需要将变量对齐到合适的地址,对象间会留下空隙.若非法访问的地址恰好在2 个对象间的空隙内,则极难发现缓冲区越界的问题.
为了增强内存安全检查的有效性,引入静态插桩是一个可行的方案.从本质上讲,静态插桩实现了类似于微处理器内存管理单元的功能,但该功能基于软件实现,在牺牲性能的情况下带来了更强的检测能力.一方面,静态插桩技术允许监控程序中的每一次内存读写操作,从而检查非法的内存使用;另一方面,静态插桩可以替换程序的运行时库,从而检查对系统库中的内存申请和释放函数的调用.类似于内存管理单元,静态插桩也需要维护内存对象的元信息.下面以Address Sanitizer[8]为例,详细说明静态插桩是如何实现内存安全检查的.
为了高效地管理内存对象的元信息,Address Sanitizer 使用影子内存技术.换言之,任何地址的元信息都会被Address Sanitizer 映射到一个保留的区间.具体地,地址Addr 的元信息存储地址ShadowAddr为Addr/kScale+kOffset.其中kScale和kOffset均 为平台相关的常数:kOffset为影子内存的起始地址,在x86平台下kOffset值取0x20 000000;kScale为压缩率(即几个字节的空间共享同一个字节的元信息),例如在x86 平台下kScale值取8.压缩率越高,存储元信息所需的额外内存越少,但验证内存访问合法性的算法复杂度也可能上升.
影子内存中的每个字节有[−128,127)的取值范围.以x86 平台为例,影子内存中的每个字节负责记录8B 的程序内存的元信息.对于每个影子内存中的字节,0 表示当前影子内存所对应的8B 均可访问;负数表示当前影子内存所对应的8B 均不可访问;[1,8)表示当前影子内存所对应的内存区间的有效长度,例如3 表示前3B 均可访问.精心设计的内存布局和元信息储存方式大大简化了检查代码.假设当前内存访问满足内存对齐的要求,容易得出内存安全检查桩点逻辑.检查逻辑极其简单,只涉及少量位运算(由除法运算化简得到)和算术运算、单次内存读取、单次比较和分支运算.下面的代码显示了安全检查桩点的具体逻辑.
上述代码只是利用影子内存中的元信息进行安全检查,但元信息自身还需要维护.Address Sanitizer的基本维护策略是使用禁区和隔离区.在每个内存对象前后,Address Sanitizer 添加禁区并将其标记为不可访问,从而使数组越界等空间异常被检查到.在堆中的内存对象被释放后,Address Sanitizer 将对象加入隔离区,延缓对该地址的重用,从而提升释放后使用等时间异常被检测到的概率.为了使禁区和隔离区能够匹配当前的内存状态,Address Sanitizer 对内存对象的申请和释放进行插桩:
1)栈对象.对于当前栈帧中存储的自动变量等类型的内存对象,Address Sanitizer 修改了内存布局从而在对象间插入禁区;此外,还在函数的入口将禁区标记为不可访问,在函数退出时删除这些标记防止误报.
2)堆对象.Address Sanitizer 将malloc和free等内存管理函数重新实现,从而在对象间插入禁区,在内存释放后置入隔离区.同时,内存申请的上下文也被记录,用于生成开发者友好的错误报告.
3)静态对象.对于全局变量、静态变量等类型的静态对象,编译器将这些数据写入到二进制文件中.程序运行时,操作系统的动态链接器在程序运行前将这些数据映射回内存,对象的生命周期是整个进程.除了在对象间插入禁区外,为了维护静态对象的元信息,Address Sanitizer 使用构造函数完成对禁区的标记.具体地,Address Sanitizer 在编译期扫描全局变量,并将它们的源码位置、长度等信息写入到二进制的一个数组中.同时,Address Sanitizer 生成构造函数asan.module_ctor.该函数被标记为构造函数,在主程序运行前获得控制权.函数将元信息传递给运行时库所暴露的接口__asan_register_globals,从而注册全局变量.
此 外,Address Sanitizer 还截获 了memcpy、fread等系统库函数,从而对常用的外部函数进行内存访问建模和检查.
2.2 未定义行为检查
ISO C11 标准中写到,“在使用不可移植的、错误的程序结构或错误的数据时,本国际标准对其没有规定要求”[14].例如,有符号数算术运算时发生的溢出就属于未定义行为,内存安全问题也是未定义行为的子集.引入未定义行为,不光能简化编译器设计实现,还能带来额外的优化空间.
1)简化编译器设计实现.例如,在循环等性能攸关的场景下,编译器往往需要分析2 个指针是否可能指向相同的内存对象.根据语言规范,float 指针和int 指针不能指向同一处内存(即不存在别名),否则为未定义行为.基于此规范,编译器能够通过类型信息,在部分场景下直接确认不同指针不会互为别名,从而简化编译器的设计.
2)带来额外的优化空间.例如,有符号数的算术运算在主流平台下均以2 的补码形式进行.因此,若不发生溢出,a+1 >a在任何情况下均成立;若规定有符号数的算术运算溢出是未定义行为,编译器可以不考虑罕见的极端情况,从而将a+1 >a折叠成常量true.
为了检查未定义行为,可以引入静态插桩.C/C++程序设计语言规范中规定了大量的未定义行为,例如C11 标准的附录J 中就列出了近200 条未定义行为.相比于只须处理内存相关原语的内存安全检查Address Sanitizer,更广义 的未定 义行为检查Undefined Behavior Sanitizer 需要紧 密结合 程序语 义.因 此,Address Sanitizer 只须作为LLVM 中 端的一部分,而Undefined Behavior Sanitizer 需要在更靠近源码的编译器前端Clang 中进行.具体地,源码在Clang 的词法分析、语法分析和语义检查后,被变换为合法的抽象语法树;Clang 的代码生成(CodeGen)组件扫描语法树,在生成程序LLVM 中间表示的同时,根据插桩选项生成额外的未定义行为检查代码.为此,Undefined Behavior Sanitizer 需要紧密结合程序语义,并进行大量的适配.
下面的代码列出了返回有符号整数x+y的值的函数foo以及安全强化版本foo_ubsan的LLVM 中间表示.该代码进行了少量编辑,从而删除无关细节.不难发现,Clang 在代码生成时,foo函数的加法指令是add nsw,其中nsw 表示不存在有符号计算的溢出(no signed wrap).而foo_ubsan函数使用了LLVM 的内部函数llvm.sadd.with.overflow.该函数返回2 个值,一个是加法的结果i32,另一个是布尔值i1,它表示是否存在溢出.若发生溢出,则跳转到函数handler.add_overflow.该函数调用运行时库的接口__ubsan_handle_add_overflow报告错误,接着跳转到cont 恢复执行.
3 导向信息收集插桩
3.1 控制流特征采集
当下几乎所有的主流模糊测试工具均采用控制流特征作为导向信息.其中,覆盖位图是最常使用的控制流特征.覆盖位图的核心思想是压缩程序执行的时空特征到固定大小的计数器数组.首先,数组的不同元素表示不同的控制流转移,整体上反映了整体控制流转移的空间特征.例如,对于最简单的基本块覆盖而言,可以将每一个基本块都分配独立的计数器并连续存放,构成数组.其次,数组内元素的值和当前控制流转移的触发次数相关,反映了单个控制流转移的时间特征.例如,假设每个基本块计数器的取值范围在0~255 之间,那么可以将计数器的值分为8 类:1,2,3,[4,8),[8,16),[16,32),[32,128),[128,256).在分类下,每个计数器均映射到8 个特征.在某次执行中,若模糊测试工具发现了先前从未发现过的特征,则认为当前执行的输入较为新颖,需要保存以供后续探索;否则,认为当前执行没有意义,可以直接丢弃.
下面的代码总结了模糊测试工具AFL[3]的覆盖率处理算法.函数checkCoverage接受数组长度N、覆盖位图C和未知覆盖位图U.checkCoverage的第1 个循环利用预先编制的查找表TO_BITMAP,将每个计数器的值映射到8 个不同的特征中,并以位图的形式存放.换言之,当计数器为零时,转换后的位图也为0,说明没有任何特征;当计数器为非零时,转换后的位图的8 位中有且只有一个位被置为1,置位的位置取决于分类结果.checkCoverage的第2 个循环扫描当前覆盖和全局的未知覆盖位图.若当前覆盖的特征在全局的未知覆盖特征中出现,说明当前执行是有价值的,需要判断执行的价值等级.若当前计数器是首次发现(即未知覆盖全部被置位),说明当前执行发现了新覆盖,将返回值设置为2;否则,说明当前执行发现了已经覆盖计数器的不同计数模式,将返回值设置为1,表示发现了新路径.
为了收集覆盖位图,模糊测试工具往往使用静态插桩.下面以x86-64 平台下的afl-gcc 为例,说明覆盖率的收集方式.在构建待测程序时,afl-gcc 包裹了系统编译器gcc,从而执行额外的操作.若当前gcc 调用的目标是编译源文件,afl-gcc 编辑对系统编译器gcc 的调用参数,使得gcc 在生成对象文件时使用afl-as作为汇编器.afl-as 是带有插桩功能的汇编器,它接受gcc 生成的汇编文件进行插桩,之后交给系统汇编器as 生成对象文件.afl-as 对汇编文件进行模式匹配,识别基本块的起始标签,并插入桩点代码.修改后的汇编文件调用系统的原始汇编器as 生成对象文件.桩点代码的主要逻辑是创建栈帧,备份寄存器,接着跳转到__afl_maybe_log函数中.其中,COMPILE_RANDOM是afl-as 生成的随机数,被用作当前基本块的标号.具体的桩点汇编代码为:
核心函数__afl_maybe_log完全由汇编写成,在此给出它的伪代码以便读者理解.__afl_maybe_log首先备份上下文save_flags,然后判断存储于共享内存的覆盖位图是否完成初始化.若是首次执行桩点,没有完成覆盖位图的初始化,则尝试使用shmat 函数加载模糊测试工具所分享的共享内存;接着是核心的控制流到位图的映射环节,该环节计算了当前控制流所对应的计数器索引index,并维护了上一基本块标号__afl_prev_loc;最后__afl_prev_loc在退出前恢复了保存的上下文.不难发现,该映射本质上将上一基本块标号prev和当前基本块标号curr映射到 (prev>>1) ^curr的计数器上,抽象了控制流的空间特征.对时空特征进行抽象的代码如下:
3.2 比较操作数收集
仅收集控制流特征不能高效地探索程序的状态空间.这是因为控制流特征只能反馈是否通过了某个复杂约束,却不能辅助对复杂约束的求解.以颜色管理库项目LCMS 为例,其输入是国际色彩联盟提出的ICC 描述文件,该文件以ASCII 字符串acsp 作为开头.LCMS 在执行之始就验证输入文件是否为有效的ICC 描述文件,且代码为:
#definecmsMagicNumber0x61637370//'acsp'
代码读入输入的前4 个字节到Header.magic中,并转换到大端序,判断转换后的值是否和cmsMagic-Number相等,若不相同则调用cmsSignalError函数报错.显然,测试程序实际逻辑的前提是构造有效的文件头.然而,若只收集程序控制流特征,则几乎不可能构造有效的文件头.这是因为程序的控制流特征只能反馈该约束是否通过,不能在约束尚未解决前提供任何的导向信息.在缺乏导向信息的情况下,模糊测试工具只能随机地生成输入,而恰好能构造原始输入的概率低至2−32.因此,对复杂约束进行求解来提供导向信息对模糊测试意义重大.
整数比较是程序的一类主要复杂约束.除了LCMS的例子中if-else 的例子外,整数比较还包括switch-case语句.以Clang 内置的SanitizerCoverage 为例,Sanitizer-Coverage 首先扫描程序中的所有指令,若发现表示整数比较的icmp 指令,则执行控制流分析,从而跳过执行频次高且无意义的循环控制条件;接着判断比较操作数的长度是否为常量,以此选择合适的回调函数,并最终创建对回调函数的调用.若发现表示分支选择的switch 指令,则为其创建常量数组,从而存储数据类型、选择数量等元信息以及case 中的值;最后该常量数组和当前switch 值会被作为参数调用回调函数.
下面的代码列出了典型的回调函数原型.trace_cmp1是对两端是变量的单字节比较的回调.trace_const_cmp4 是对一端是常量的4B 比较的回调,其中参数const是常量,variable是变量.trace_swith是对switch 的回调,其中参数val 是转换为uint64_t 的条件变量,参数cases指向元信息.通过实现下列函数,模糊测试工具可以收集并利用执行过程中的比较信息.
除整数比较外,缓冲区比较也是程序中的一类主要约束.这些比较大多由C 标准库提供,例如strcmp等字符串比较函数,或memcmp等缓冲区比较函数.此外,C++标准库的部分函数,例如GNU libstdc++内部的std::__cxx11::basic_string::compare 也可能被STL 头文件所引用.对于此类函数静态插桩的常用方法是使用链接器特性.例如在Linux 下,系统的C 运行时库将memcmp等函数标记为弱符号,从而允许用户重载并优化memcmp等函数.基于上述机制,libFuzzer 重新定义了需要插桩的缓冲区比较函数.在链接时,重定义的强符号比系统的C 运行时库有更高的优先级,因而能替换原程序对系统库函数的调用.除了截获比较函数,模糊测试工具在运行时也需要调用被截获函数自身.为了获取原始符号,libFuzzer 在运行时通过系统的动态链接器提供的dlsym和dlvsym函数,动态获取原始函数的指针.
基于对整数和缓冲区比较的插桩,模糊测试能够追踪到控制流变化外的比较操作数,从而辅助对复杂约束的求解.例如,libFuzzer 通过2 种方式利用比较操作数,从而提升模糊测试效果.
1)自动字典构造.对于长度为4B 和8B 的整数比较和长度为2B 及以上的缓冲区比较,libFuzzer 将比较的操作数加入字典中.在生成随机输入时,可以根据字典中的记录项直接替换部分原始输入,或在原始输入中插入部分字典记录项.这种策略对于简易的常量比较有非常好的求解效果.
2)比较特征提取.当开启值特征采集功能时,libFuzzer 将比较操作转化为特征位图,从而使先前应用于控制流特征的导向算法能够应用于比较中.具体地,libFuzzer 首先度量比较操作数间的距离:对于整形比较,计算两数的海明距离和数值差异;对于缓冲区比较,则计算2 个缓冲区前缀的海明距离.接着,libFuzzer 计算操作数距离和比较操作的机器码地址的哈希,该哈希值被对应到特征位图中的某个位.libFuzzer 将该位置设为1,从而使执行完毕后的位图分析逻辑能够检测到比较后的变化,并最终保留具有新颖比较特征的输入文件用于后续探索.
4 静态插桩的额外开销
在模糊测试的实践中,静态插桩的能力会受到实际因素的制约.首先,不同的插桩类型可能会互相冲突.例如,Address Sanitizer 和Memory Sanitizer 同时使用影子内存技术管理内存对象的元信息,由于内存布局不能互相兼容,二者不能同时打开.此问题较容易规避,例如,可以使用强化了不同安全特性的二进制执行相同的输入.此外,更重要的是,静态插桩后的程序执行变慢,其额外开销严重影响了模糊测试效果.当下的主流模糊测试技术无一例外地使用随机输入生成的策略.因此,对程序状态空间的探索离不开海量的输入执行.然而,越是复杂的插桩特性往往需要引入更多的桩点,且每个桩点需要执行更多的逻辑.重量级插桩会显著降低程序执行速度,降低模糊测试的整体吞吐量,进而影响整体测试效果.由于额外开销是由桩点的额外逻辑带来的,本身是不可避免的.为了指导模糊测试实践中的静态插桩选择,本文测量了不同类型插桩、相同类型插桩下实现的额外开销.
实验中待测项目全部选取自FuzzBench[15].Fuzz-Bench 是谷歌发起的模糊测试工具评测平台,平台中包含了大量被广泛使用的开源软件.这些开源软件有着截然不同的功能,且均为应用模糊测试的实际项目,因此具有高度的代表性.除非插桩方式有特殊要求,本文使用完全相同的编译器版本Clang 14.0.6和编译器优化参数O2 构造二进制,从而保证相同的测试基线.
实验的测量方法是在相同测试集的重复实验.由于模糊测试具有随机性,生成的输入文件也不完全一致,因此直接测量模糊测试的执行次数会受到随机性的影响.为了控制变量,对于每个项目,本文均选取某次模糊测试中保存的输入文件作为测试集;对于每个插桩方式,本文使用Linux 社区的perf tools工具集,用于精确的性能分析和测量.测量环境的微处理器为AMD EPYC 7742,内存为256 GB,内核版本为Linux 5.4.
实验的测量结果使用未插桩的原始二进制进行标准化.对于各个插桩方式的测量值,本文呈现其测量读数除以原始二进制的测量值的标准化结果,从而排除不同项目的差异.例如,当测量执行时间时,1.0 表示执行时间和原始二进制相同,数值越高,表示插桩的额外开销越大.
4.1 整体评估
图1 呈现了不同插桩方法下各个插桩程序的执行时间分布.数据经过归一化处理,其中横线表示原始程序的执行时间,即100%.为了提升表述的简明性,图1 中 将Sanitizer Coverage 简称为SanCov.由 于Sanitizer Coverage 具有不同的子功能,在此将一般模糊测试中使用的开启全部功能的版本称为SanCov-All;为了对比纯控制流信息下的不同采集方式,将Sanitizer Coverage 中只收集控制流信息的版本称为SanCov-Edge,从而和4.2 节的方法一致.此外,对于安全特性强化的插桩模式,将Address Sanitizer 简称为ASan,将Memory Sanitizer 简称为MSan,将Undefined Behavior Sanitizer 简称为UBSan.
从图1 中可以看出,各个插桩模式对程序执行速度均有显著的影响.其中,影响最小的是SanCov-Edge,平均会带来26%的额外执行时间;影响最大的是SanCov-All,Sancov-All 包含了边覆盖率、比较操作数收集等丰富功能;此外,ASan 也会带来146%~230%的额外执行时间.
由于图1 呈现的是不同项目的执行时间分布,还可以发现其更为宏观的特征.其中,SanCov-All 和UBSan 的执行时间差别较大,标准差分别为171%和213%.例如,SanCov-All 会带来10%~577%的额外执行时间;UBSan 也会带来8%~803%的额外执行时间.需要说明的是,图1 中的分布是使用核密度估计方法得到的宏观趋势,出现小于100%的值属于正常现象.
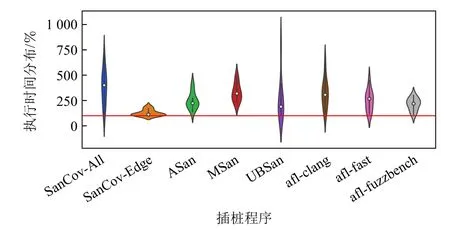
Fig.1 Execution duration distribution of instrumented programs图1 插桩程序的执行时间分布
4.2 导向信息收集的额外开销
本文将测试工具AFL 内置的导向信息收集插桩模式进行单独比较.通过将 AFL 作为唯一的模糊测试工具,能够避免不同测试工具所需的不同信息和不同信息的处理方式带来的影响.AFL 自身提供了afl-clang 和afl-fast 插桩工具.对于afl-fast 模式,由于兼容性问题,本文修改了插桩引擎代码,使其能够适配于LLVM 的新版PassManager 组件.此外,本文还选取了谷歌FuzzBench 平台上适配AFL 的插桩模式,记为afl-fuzzbench.
如表2 所示,这3 种模式中,只有afl-clang 使用汇编作为插桩对象,其他模式使用LLVM 中间表示;只有afl-fast 将桩点逻辑内联于程序的原始LLVM 中间表示,其他模式均在桩点处插入对外部运行时函数的调用指令.
图2 显示了AFL 插桩下不同程序的标准化执行时间.图中横线为原始程序的执行时间,即100%.从整体上看,afl-clang 的性能较差,额外开销为219%;afl-fuzzbench 的性能较好,额外开销为112%.afl-clang性能差的原因是基于汇编的插桩模式,即只是使用基本的模式匹配识别基本块,并未对原始程序的寄存器使用情况进行分析,因此需要保存全部寄存器等大量的上下文,存在大量的额外操作.afl-fast 基于LLVM 中间表示,上下文管理由LLVM 后端在生成机器码时自动完成,且高度优化.然而,afl-fast 模式将计数器更新逻辑置于程序内部,会带来可观代码膨胀.以harfbuzz 项目为例,其在afl-fuzzbench 模式下的二进制大小为1.23MB,但是在afl-fast 模式下的二进制大下为2.81MB,相差1.28 倍.代码膨胀会增加微处理器的缓存压力和前端解码器压力,因而影响程序执行速度.afl-fuzzbench 使用基于回调函数的方法,尽管该方法需要增强函数调用和返回的成本,但是现代微处理器的前端能够良好地预测执行流的切换,因而较小影响.

Table 2 Comparison of AFL’s Instrumentation Modes表2 AFL 的插桩模式对比
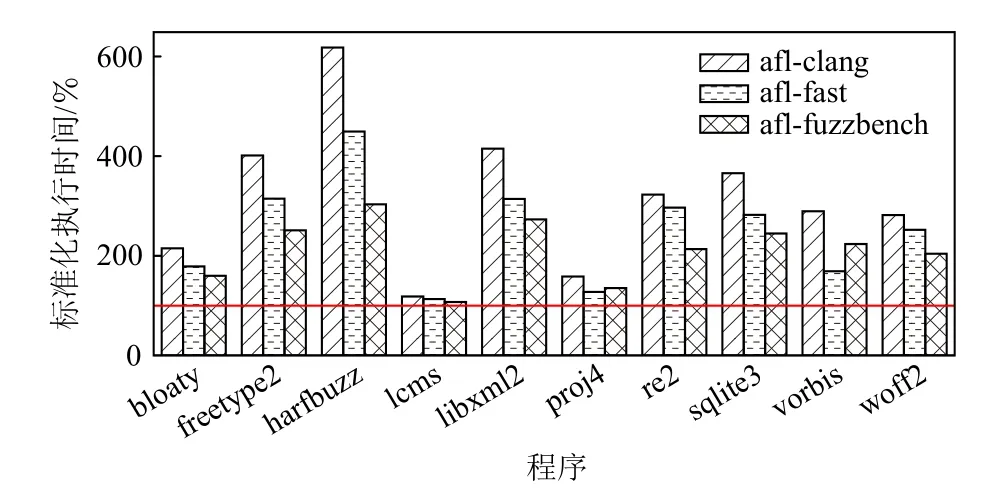
Fig.2 Execution duration of programs under AFL instrumentation图2 AFL 插桩下的程序执行时间
此外,尽管是相同的测试工具、相同的待测程序、相似的反馈信息,但不同插桩模式下程序的性能差异极大.例如,harfbuzz 在afl-clang,afl-fast 和afl-fuzzbench插桩模式下,执行速度分别为原始程序的618%,449%和303%.
图3 进一步对比了Sanitizer Coverage 不同模式下的插桩成本.其中,SanCov-Edge 表示只统计最基本的控制流信息,而SanCov-All 表示还开启比较操作数记录功能.图3 中的数据经过归一化处理,其中横线为原始程序的执行时间100%.
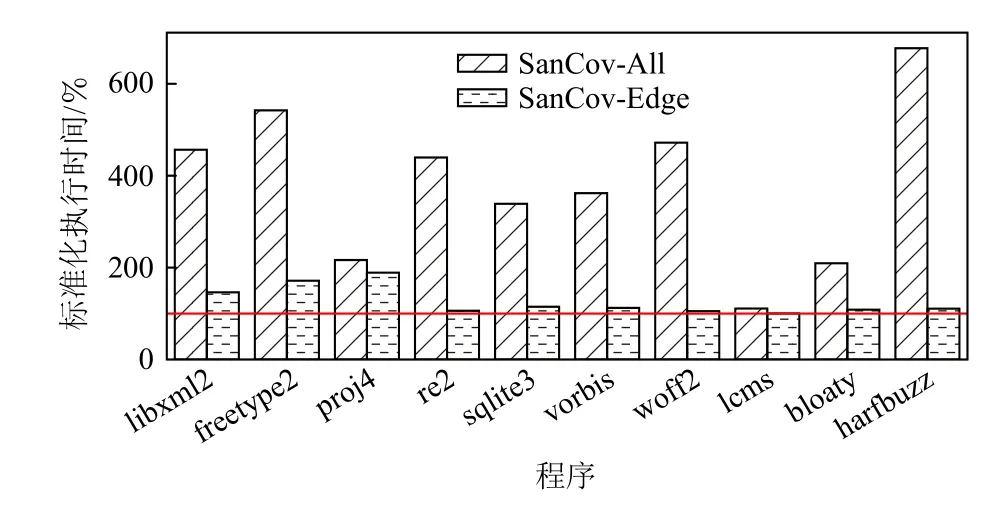
Fig.3 Execution duration of programs under Sanitizer Coverage instrumentation图3 Sanitizer Coverage 插桩下的程序执行时间
对比图3 中的SanCov-Edge 和SanCov-All 可以发现,丰富的比较操作数信息严重拖慢了程序的执行速度.其中,最原始的SanCov-Edge 模式只会带来0%~89%的额外开销.然而,一旦开启了对比较操作数的追踪,SanCov-All 模式的额外开销便突增到11%~577%.
比较操作数处理背后的巨大开销可以从2 方面来解释.首先,比较操作广泛存在于程序中.以出现最大额外开销的harfbuzz 为例,插桩后的程序中有近11 000 个计数器桩点,此外还有5 000 余个数值比较桩点和70 余个缓冲区比较桩点.虽然比较操作的桩点少于控制流桩点,但其量级却近似.此外,对比较操作收集的插桩逻辑远比控制流特征的收集复杂.以模糊测试工具libFuzzer 为例,它的控制流插桩只须对固定位置的计数器做简单的自增操作;然而对于比较操作,它却需要以不同方式度量操作数的距离,计算当前比较的哈希,更新全局特征,还需要将操作数拷贝并编入字典.显然,复杂的桩点逻辑会给开启比较操作数导向的模糊测试工具带来巨大的额外开销.
4.3 安全特性强化的额外开销
图4 显示了OSS-Fuzz 项目中最流行的3 类安全特性强化插桩给不同待测程序带来的额外开销.需要注意的是,由于MSan 可能的误报,导致bloaty 项目不能正常编译,且sqlite3 项目不能正常执行.因此,本文剔除了上述不能正常评估的实验项.
从图4 可以看出,从整体上:内存安全检查ASan会带来146%额外开销;未初始化内存读取检查MSan会带来231%的额外开销;未定义行为检查UBSan 会带来162%的额外开销.此外,不同项目和不同插桩方式的额外开销波动剧烈,并无显著规律,这是由插桩自身和程序自身的固有特性决定的.例如,在检测未定义行为的UBSan 中,大量的桩点都针对整数和指针运算.因此,对于具有大量算术运算的压缩/解压缩类型的算法类程序(例如woff2 和vorbis),UBSan具有巨大的额外开销.类似地,ASan 对内存的读写都需要插桩,而MSan 对内存的读写和值的传播都需要插桩.综上,对于内存操作较为频繁的程序会在ASan 和MSan 插桩模式下有较大的额外开销.
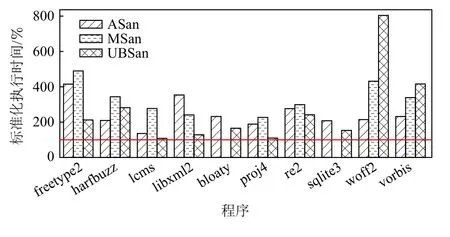
Fig.4 Execution duration of programs under safety enhancement instrumentation图4 安全特性强化插桩下的程序执行时间
5 静态插桩的优化方向
5.1 基于硬件特性的优化
现代微处理器往往会提供不同的优化指令集.一方面,可以利用硬件特性加速静态插桩.例如,在收集控制流特征时精简插桩指令或加速分析[16].此外,还可以使用新的指令集架构加速内存安全检查[17-20].另一方面,可以利用硬件特性直接记录程序的控制流行为[21-23].虽然硬件本身能够以较低的成本收集程序行为,但在模糊测试上尚存在信息处理较慢的挑战[24].
5.2 基于程序分析的优化
利用编译器强大的静态分析能力可以减小插桩复杂度.例如,可以通过控制流分析减少控制流插桩的桩点数量[25],或是生成元信息从而辅助运行时的桩点删减[26-27],或是增强对动态场景下覆盖率到源码的映射精度[28-29].
此外,运行时的动态分析信息也可以辅助模糊测试.例如,可以通过引入模糊测试前的试运行步骤删除无关的安全检查[30-31],还可以交替进行编译和运行,从而实现灵活的插桩调整[32].
6 结语
模糊测试是一种自动化的软件缺陷发现方法,其实际应用往往伴随着静态插桩技术.本文介绍了模糊测试以及模糊测试背景下的静态插桩技术,统计了实际模糊测试中各类静态插桩技术的使用情况.针对内存安全检查、未定义行为检查、控制流特征采集、比较操作数收集这4 类具有代表性的静态插桩技术,本文分析了其设计思想和实现技巧,对开发动态分析工具有参考意义.除了分析插桩的功能,本文还统计了不同插桩模式的额外开销并分析了额外开销背后的原因.基于上述内容,本文最后给出了静态插桩的两大优化方向,即利用硬件特性和程序分析极速执行或提升程度.
作者贡献声明:王明哲负责完成实验并撰写论文;姜宇提出了文章思路和实验方案;孙家广提出指导意见并修改论文.
