基于消费者多维度偏好的个性化评论排序方法研究
2023-03-02吴江宁
杨 弦, 骆 丹, 吴江宁
(1.东北财经大学 管理科学与工程学院,辽宁 大连 116025; 2.大连理工大学 经济管理学院,辽宁 大连 116024)
0 引言
随着用户生成内容这种网络信息模式的普及,越来越多的用户选择通过各种社交媒体分享购物体验、对产品和服务进行评价,以供其他用户参考。目前,各类电子商务网站积累了海量的在线评论。一方面,这些在线评论作为产品的网络口碑,可指导消费者做购买决策[1-3];另一方面,评论数量巨大,动辄几十万条,使得消费者难以通过阅读全部评论来感知商品的真实质量。由于信息严重过载,目前的电子商务网站提供了简单的评论排序功能,消费者只能选择按照如,时间、好评、点赞数等,展示顺序阅读部分评论,使之只能用不完全信息或片面信息来做决策,由此引发消费者不良的购物体验。因此,用更加科学的手段基于消费者的不同偏好,提供个性化评论排序显得尤为必要。
目前关于评论排序的研究大多是面向消费者群体、无差异化地生成非个性化的评论排序。学者们提出了多种评论排序方法。如:Ghose等[4]基于计量经济学模型提出了两种评论排序机制:一种是面向消费者,基于评论有用性进行排序;另一种是面向商家,基于评论对销量的影响进行排序。Zhang等[5]提出了一种改进的步进式优化算法,用于最大化评论排序列表与评论整体好评率之间的一致程度,最终得出一致程度最高的评论排序列表作为排序结果;Chen等[6]在上述研究的基础上,考虑了评论有用性因素,提升了排序结果的采纳程度。
随着“顾客至上”的服务理念和大数据技术的快速发展,个性化服务日渐兴盛,根据消费者个体差异化的兴趣偏好和行为习惯,“定制”生成相应的评论排序显然更加符合消费者需求,然而,目前鲜有研究关注了面向消费者个体、差异化地生成个性化评论排序的问题。消费者偏好包括很多维度,综合考虑各种维度可以更加立体地刻画消费者偏好,从而精准地生成个性化的评论排序。因此,如何从多维度挖掘消费者偏好,并将其加入评论排序模型用于生成排序结果,是本文的研究重点。
基于上述分析,本文基于消费者多维度偏好,提出了一种度量方法,用于计算评论排序的消费者偏好满意度,从而将评论排序问题转化为优化问题,优化目标是最大化期望满意度,从而得到对应的最优排序。由于该优化问题无法精确求解,本文提出了一种基于改进贪婪算法的近似求解算法。文中采用酒店团购网站上的真实数据对算法进行检验,结果表明本文提出的方法得到的产品评论排序结果具有更高的消费者偏好满意度,且对偏好变化较为敏感。
理论上,本文提出的基于消费者多维偏好的个性化评论排序方法扩展了目前评论排序方法的研究。现实中,研究结果也可帮助消费者依据个人偏好,高效、准确的了解产品网络口碑,提高消费者购买效率和满意度;同时,本文设计的排序方案对电商平台改进用户评论系统,提高用户粘性有着重要的现实指导意义。
1 最大化消费者偏好满意度的评论排序方法
1.1 消费者多维度偏好分析
全面地刻画消费者多维度偏好是进行个性化评论排序的基础,有助于消费者在海量评论中快速获取感兴趣、有价值的信息,从而做出购买决策。基于消费者阅读评论时的行为习惯以及关注的信息,本文主要考虑三个维度的消费者偏好:
(1)产品特征偏好
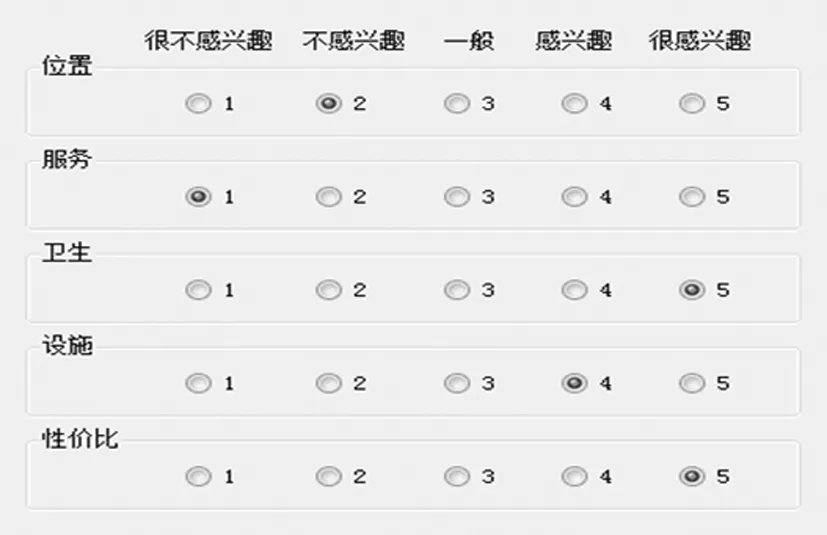
图1 产品特征偏好示例
消费者在浏览产品评论时,对于评论中所提及的产品各种特征的关注程度是有差异的,以酒店为例,商务人士会更加关注酒店所处的位置交通是否便利,而学生则会对酒店的性价比等信息更感兴趣,这种对于产品不同特征细粒度的偏好,称为产品特征偏好。关于消费者产品特征偏好挖掘的研究方法基本上都依赖于消费者的历史行为数据,主要包括评论打分信息和评论内容[7,8]两大类。这种方法会面临冷启动问题,即当消费者没有历史数据时,我们将无法挖掘其偏好,因此,本文设计了一套机制,用于直接获取消费者的产品特征偏好。
假设某产品有m个特征,对于每个特征的感兴趣程度可以用一个5维的Likert量表表示,其中1表示很不感兴趣,5表示很感兴趣,这样就可以用一个m维向量来表示消费者的产品特征偏好。例如,某消费者对于酒店5个特征(位置、服务、卫生、设施和性价比)的感兴趣程度如图1所示,可以表示为特征偏好向量PFea=(2,1,5,4,5)。
(2)评论情感偏好
现实中,消费者不仅关心评论是否谈及感兴趣的产品特征,评论是否客观、有用对其也同样重要[9],这种对一条评论喜欢或不喜欢的情感倾向,我们将其定义为评论情感偏好。目前网站通常会把点赞数多的评论排在前面,但排序靠前的评论由于被浏览的可能性更大,获得的点赞数也会相应更多,产生马太效应,使得点赞数无法客观反映消费者的评论情感偏好。评论有用性是消费者对之前评论者发布的评论是否有助于自己制定购买决策的一种主观感知,大量研究表明,评论有用性与评分星级、文本情感、评论时间间隔和评论者信息等因素相关,本文利用现有的如回归分析等方法,进行模型训练和有用性预测,得到每条评论的有用性得分,刻画消费者的评论情感偏好。
(3)评论浏览数量偏好

1.2 消费者偏好满意度度量方法
(1)单条评论的消费者偏好满意度
在计算单条评论的消费者偏好满意度之前,需要先对每条评论做以下处理:
1)挖掘评论的特征分布情况,当给定某类产品的评论信息时,其领域特征词典F={f1,f2,…,fm}可以利用特征提取方法得出,其中fi表示一类具有相似含义的特征词,每条评论可以表示为一个特征分布向量r=(rf1,rf2,…,rfm),其中rfi表示评论r中属于特征fi的特征词数;
2)评论的情感偏好满意度用有用性得分表示,现有研究大多采用对数线性回归模型,反映各影响因素和评论有用性之间的关系。由于单条评论不涉及评论浏览数量问题,无需考虑评论浏览数量偏好,所以单条评论r的消费者偏好满意度Satr为:
Satr=PSentir×M(PFea,r)=Ur×cos
(1)
其中,PSentir是评论r的情感偏好满意度,即r的有用性得分Ur;M(PFea,r)是产品特征偏好与评论r的匹配程度,用特征偏好向量与评论特征分布向量的余弦相似度表示。
(2)评论集合的消费者偏好满意度
评论集合与单条评论的消费者偏好满意度类似,计算公式如下:
SatS=PSentis×M(PFea,S)=US×cos
(2)
其中,US表示评论集合的有用性得分,取集合中所有评论有用性得分的平均值;FDS表示评论集合的特征分布向量,由集合中所有评论的特征分布向量相加得到。
(3)评论排序的消费者偏好满意度
给定某产品的评论排序L=(rl1,rl2,…,rln),其中rli表示排序中的第i条评论,计算其消费者偏好满意度需引入浏览数量偏好PNum=(p1,p2,…,pn),具体计算公式如下:
(3)
其中Si表示L中前i条评论组成的评论集合,SatSi可由公式(2)计算得到。
1.3 评论排序优化模型构建
n条评论的全排列共可产生n!个评论排序,根据公式(3)可以计算出每个评论排序的消费者偏好满意度,涉及产品特征偏好、评论情感偏好和评论浏览数量偏好,使这个满意度最大化的评论排序即为最优排序,如图2所示。由此,我们就把评论排序问题转化为了最大化消费者偏好满意度的优化问题。

图2 评论排序优化模型
基于消费者多维度偏好的评论排序(Consumers’ Multidimensional Preferences based Review Ranking, CMPRR)问题:给定产品特征偏好PFea、评论情感偏好PSenti和评论浏览数量偏好PNum=(p1,p2,…,pn),以及某产品的全部评论R={r1,r2,…,rn},得出使消费者偏好期望满意度expSatL最大化的最优排序L,其数学表达如下:

s.t.Si={rl1,rl2,…,rli},i=1,2,…,n
(4)
1.4 算例
本节用一个简单的例子解释上述方法的排序过程。
已知产品特征偏好PFea=(1,2,3,5),评论浏览数量偏好PNum=(0.3,0.5,0.2),三条评论r1、r2、r3的特征分布向量和有用性得分如表1所示。
以L=(r3,r1,r2)为例,如S2={r3,r1},则:
FDS2=r3+r1=(3,4,2,0)+(0,1,2,3)=(2,5,4,3)
SatS2=US2·cos(PFea,FDS2)
=0.60

同样地,可以求得所有6个评论排序的消费者偏好期望满意度,如表2所示。由此可得,最优排序为(r1,r3,r2),对应的最优消费者偏好满意度为0.59。
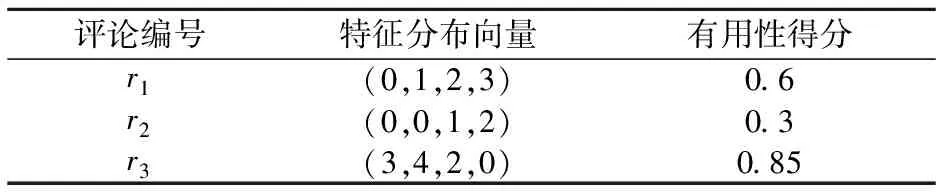
表1 三条评论的具体信息
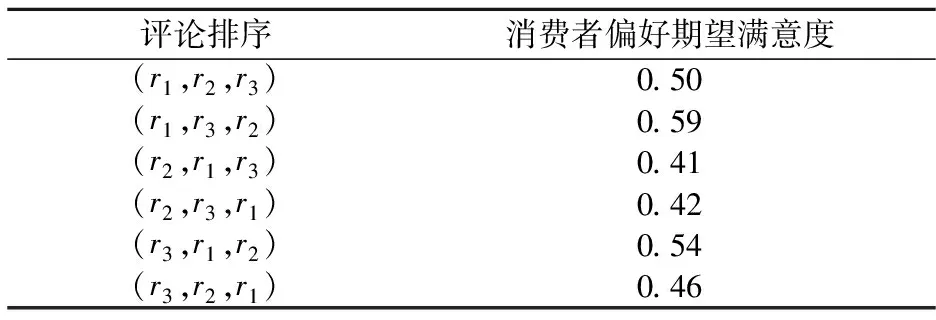
表2 各排序的期望满意度
1.5 优化模型求解算法
如第2.4节中的算例所示,解决CMPRR问题的直接方法就是列举出所有可能的评论排序,分别计算其消费者偏好期望满意度,满意度最大值对应的评论排序即为所求最优排序。对于一个有n条评论、m个特征的产品,共可以产生n!个可能的排序,那么使用枚举法精确求解的时间复杂度为O(n!*n*m),显然,当n值较大时,精确求解几乎是不可能实现的。事实上,CMPRR属于NP-hard问题,即无法找到一个能在多项式时间内解决该问题的算法,当给定一种评论排序,可以很容易地计算出其期望满意度,但是,要想找到一个取最大期望满意度的最优排序,必须考虑所有可能的排序。由此,求解CMPRR问题需要考虑采用近似算法。生成评论排序可以看作是一个逐步迭代地选取评论到排序列表中的动态过程,在每轮迭代中选取一条评论加入排序列表,经过n轮迭代就可以生成一个包含n条评论的排序列表。
基于这种思想,用于精确求解的枚举算法就相当于在每轮迭代中不做筛选,而是保留所有可能的情况。为直观理解,图3(1)以4条评论(分别用a、b、c、d表示)为例,形象生动地演示了这个过程:在首轮迭代中,共有4条评论可供选择,形成分别以a、b、c、d为起点的4个分支,每个分支在第二轮迭代中又有3条评论可供选择,依次类推,最后会产生4! = 24个分支,即24个评论排序,最大消费者偏好满意度对应的评论排序即为所求结果。然而,如果在生成所有排序列表后再分别计算其各自的消费者偏好满意度,会导致计算冗余。
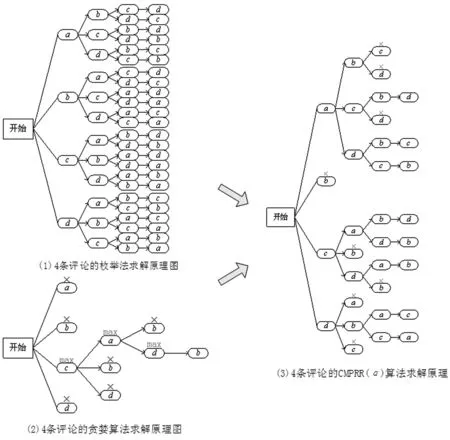
图3 4条评论的算法求解原理图
由于CMPRR问题的优化目标是求最大消费者偏好满意度,且后续满意度的取值是依赖于前续满意度的,因此我们有理由猜想在每轮迭代中使当前满意度取最大值的评论有助于生成所求最优评论,这就是在求解NP-hard问题时的经典算法—贪婪算法。图3(2)仍然以a、b、c、d4条评论为例,演示了贪婪算法的求解原理:在每轮迭代中,只保留使当前满意度取最大值的评论(图中用“max”进行了标注),用于后续生成排序列表,其余评论则舍弃不再参与后续迭代过程(图4中用“×”表示),最终只会产生一个评论排序(c,a,d,b)。

因此,本文综合考虑了以上两种算法的优缺点,提出一个“折中”的算法用于解决上述CMPRR问题,记作CMPRR(α)。该算法的思想是,在每轮迭代中设置一个消费者偏好满意度的阈值,当前评论的满意度取值大于该阈值,就将这条评论保留下来继续参与后续迭代过程,直到n轮迭代后生成若干完整的排序列表,取其中的最大满意度值对应的评论排序作为结果输出。其中,阈值的设定值由参数α控制。仍然以4条评论为例,采用CMPRR(α)算法进行求解的原理如图3(3)所示,其中,“√”表示在本轮迭代中该条评论的满意度取值大于阈值,予以保留用于继续生成排序列表;“×”则表示该条评论的满意度没有达到阈值,舍弃不再参与后续迭代过程。CMPRR(α)算法最终生成的排序数介于枚举法和贪婪算法之间,综合考虑了算法精度和效率,力求达到平衡状态。

2 算法检验
2.1 数据及预处理
本文选择了酒店作为研究对象,研究中使用到的数据来自美团网。实验前,我们收集了美团网上截至2018年5月的某市所有酒店(1760家)的全部评论数据(79781条),主要包括评分星级、评论文本、评论时间、评论者ID、评论者会员等级、评论者实名情况和评论点赞数等字段。在数据预处理阶段,我们主要做了两项工作,一是从上述评论文本数据中提取出了332个高频特征词,分为位置、房间、服务、性价比和口碑五类特征[11],基于形成的酒店领域特征词典,将每条评论表示成一个特征分布向量;二是基于评论有用性的影响因素,构建了对数线性回归模型,用于预测每条评论的有用性得分。
2.2 算法参数分析
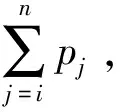
在实验中,我们随机地生成消费者偏好、选取评论集,以0.05为间隔取了α从0到1的所有取值进行实验,记录了不同α取值下的消费者偏好期望满意度和算法耗时,并计算了二者的变化值比率。实验结果如图4所示,可见当α=0.85时,每增加耗时一单位,得到的有效性提升最大。所以,后续所有实验中α的取值均设定为0.85。
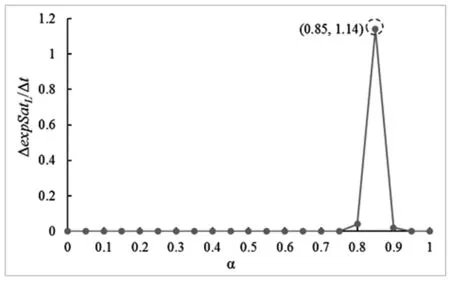
图4 参数α的实验结果
2.3 算法有效性评估
为了评估本文中提出的算法的有效性,我们与其他3个相关算法进行了比较:首先,CMPRR问题作为一个NP-hard问题,可以使用多种经典的启发式算法进行求解,我们选取了其中最著名的贪婪算法作为代表,记为Greedy;第二个算法为随机算法,即从随机生成的1000个排序中选取使消费者偏好期望满意度取最大值的排序作为最优排序,记为Random;除此之外,我们还选取了美团网上的默认排序,记为Default。
在实验中,消费者偏好随机生成的,而评论数分别取20到110(以10条为间隔)用于随机选取10个评论集,基于给定的消费者多维度偏好和评论集,计算出每种算法生成结果的满意度值。我们取各算法与本文算法的比值作为评估标准,如果该比值大于1则说明该算法优于本文算法;反之亦然。

图5 各算法的相对有效性
根据图5中的实验结果,可以分析得出以下三点结论:
(1)其他算法的相对期望满意度均小于1,说明本文提出的CMPRR(0.85)算法与其他算法相比,可以最好地满足消费者的多维度偏好,有效性最佳;
(2)随着评论数量上升,其他三种算法的相对期望满意度呈现较为明显的下降趋势,说明CMPRR(0.85)算法的优越性在评论数量较大时更加明显,这也说明在评论数量较大时本文提出的算法仍然可以求得较为精确的结果;
(3)美团网上的默认排序表现最差,体现在相对期望满意度最低且波动较大,这也验证了本文研究结果在实际应用中的有效性和必要性。
3 算法敏感度评估
本文进一步进行了算法敏感度实验,验证算法对于不同的消费者产品特征偏好是否敏感。首先,随机生成55=3125个消费者产品特征偏好向量,基于随机选取的评论集,计算各产品特征偏好向量对应的排序结果;然后,计算各偏好向量之间的相似度(Pref_sim)以及各排序结果之间的相关性(Rank_cor);最后,对Pref_sim和Rank_cor两变量进行Pearson相关性检验。实验结果如表3所示,两变量之间的Pearson相关系数为0.433,两变量显著正相关,排序结果对消费者产品特征偏好较敏感,当偏好差异大时,排序结果差异也较大;反之亦然。
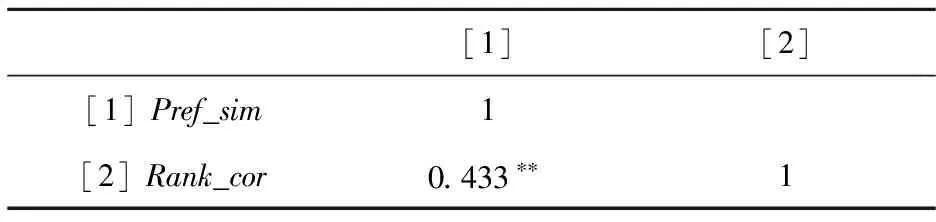
表3 两变量的Pearson相关性
4 结论
为了更好的应对评论信息过载,并满足消费者对个性化服务的需求,本文提出了基于消费者多维度偏好的评论排序问题(CMPRR),该问题的目标是找到使消费者偏好期望满意度取最大值的最优排序,由于该优化问题的复杂性,我们提出了近似求解算法CMPRR(α)。基于美团网酒店的真实数据进行了大量实验,实验结果表明本文提出的算法与其他方法相比有效性最佳,且对作为算法输入的消费者产品特征偏好较为敏感。研究结果不仅可以帮助消费者基于个人偏好,快速并精确地了解产品的在线口碑,提高决策效率;同时对电商平台获取消费者多维度偏好、改进评论系统,提高用户粘性,有着重要的现实指导意义。
本文的研究尚存一些不足。目前本研究仅选取了美团网上的酒店作为实验对象,为了充分验证本文提出的评论排序方法的普适性, 在未来的研究中可将该方法应用与更多平台的其他类型产品数据, 如零售平台上或第三方点评网站的商品评论排序等。此外,随着评论数量的增加,本文提出的优化模型求解算法的耗时增长较快,后续可以考虑使用其他的启发式算法求解这个NP-hard问题,比如模拟退火算法、遗传算法等,通过大量实验,探究本文提出的近似求解算法与其他算法的耗时对比情况。
