一种改进YOLOv5的课堂异常行为感知检测算法
2023-03-02朱先远王松林周叶凡韩海峰
朱先远,王松林,周叶凡,韩海峰
一种改进YOLOv5的课堂异常行为感知检测算法
朱先远,王松林,周叶凡,韩海峰
(安徽商贸职业技术学院 信息与人工智能学院,安徽 芜湖 241002)
YOLOv5算法能够对异常行为进行检测,大幅度提高异常行为识别的准确率和速度。然而,其参数规模较大,GPU计算量大,不适合在资源受限的嵌入式终端上进行安装部署;同时,其对目标密集、易产生遮挡的学生课堂异常行为识别表现不佳。针对上述问题提出了融合MobileNetV3的YOLOv5算法,该算法通过改进网络结构提升了算法效率,通过小目标锚框改进了相互遮挡的多目标识识别能力。最后,在基准数据集上的实验结果表明该算法网络模型参数量优于现有的YOLOv5算法,同时该算法在课堂异常行为数据集上表现出更好的识别效果。
卷积神经网络;YOLOv5算法;异常行为检测;机器视觉
近年来,随着机器视觉技术的快速发展,利用机器视觉技术进行异常行为检测已经成为计算机视觉的研究热点。课堂中学生诸如聊天(chat)、玩手机(playphone)、吃东西(eat)和睡觉(sleep)等异常行为会导致学生学习效率下降。如果可以对这些学生的课堂异常行为进行实时检测、统计汇总,将有利于教学管理部门对课堂效果进行客观评价、反馈,有利于提升课堂质量。利用机器视觉技术对课堂异常行为检测进行研究具有重要的现实意义。
随着深度学习技术的快速发展,国内外许多学者开始研究基于机器视觉技术对异常行为进行检测[1]。文献[2]提出了一种基于YOLOv3改进网络模型的人体异常行为检测方法(YOLOv3-MSSE),利用残差模块构建多尺度特征提取网络,提升了对大目标的检测精度。文献[3]通过改进Faster R-CNN算法进行近红外夜间图像的行人检测。文献[4]针对YOLOv5在拥挤行人检测任务中漏检率高、特征融合不充分等问题,提出了CA-YOLOv5行人检测算法,采用Res2Block重建YOLOv5的主干网络,提升了网络的细粒度特征融合能力,提高了检测精度。这些改进算法一定程度上提高了检测精确,但忽略了检测精度与召回率之间的平衡问题。文献[5]用Mobilenet和Ghostnet轻量化网络替换了YOLOv4的主干特征提取网络,对监控视频中群体性异常事件进行检测,相比于YOLOv4模型,参数量明显下降,提高了检测速度。
异常行为检测属于目标检测,目前基于深度学习的目标检测算法主要可分为一阶段、两阶段两大类算法。其中两阶段算法的检测过程为先提出候选区域,再利用检测网络对候选区进行检测,这类检测的主要算法有Faster-RCNN[6]、Mask-RCNN[7],算法的特点是准确率较高、速度较慢;一阶段算法的检测过程为一次性实现目标定位与检测,这类检测主要算法有SSD[8]、YOLO[9],算法特点为检测速度快、准确率较低。YOLO算法目前已更新到YOLOv5,其检测速度非常快,是工业界应用很普遍的一种目标检测算法。
课堂中学生数量多且密集,课堂异常行为检测属于多目标、易遮挡检测。现有的一些目标检测模型直接用于课堂异常行为检测会存在检测精度和参数量不适用问题。本文结合课堂场景下学生异常行为感知检测问题,给出一种改进YOLOv5的算法模型,来对课堂中学生的异常行为进行检测。
1 相关工作
YOLOv5网络结构主要包括Input、Bockbone、Neck和Head 4部分。Bockbone是YOLOv5网络骨干网络,用于从输入图像中提取丰富的图像特征。Neck主要用于生成特征金字塔,增强网络模型对于不同缩放尺度对象的检测能力,从而保证网络可以识别不同尺度的同一物体。Head是网络模型的最终检测部分,不同缩放尺度的Head用于检测不同大小的对象。YOLOv5包括YOLOv5s、YOLOv5l、YOLOv5m、YOLOv5x等版本,其中YOLOv5s是深度和宽度均最小的网络,其他几种都是在YOLOv5基础上进行了加深、加宽。
MobileNet是一种轻量化的CNN模型,主要特点是采用深度可分离卷积代替普通卷积,针对每个输入通道采用不同卷积核,最后再使用点卷积进行通道融合。在ImageNet数据集上,MobileNet与VGG16的准确率几乎一样,但参数量只有其1/32,计算量只有其1/27。MobileNet最新算法为MobileNet3[10],有MobileNet V3 large和MobileNet V3 small两个版本,本文在YOLOv5s算法中融合了MobileNet V3 large算法模型的BNeck结构,Bneck具体结构示意图如1所示。在BNeck结构中先利用1×1卷积进行升维,再利用一个3×3卷积深度可分离卷积提取特征,然后再施加注意力机制调整每个通道的权重,再利用1×1卷积进行降维,最后将降维后的输出和残差边部分进行短链接求和。该结构显著的特点是引入了深度可分离卷积降低了网络的计算量,增加了轻量级注意机制调整了每个通道的权重,同时在输入和输出之间叠加了一条短连接,可以有效地避免在降低网络计算复量时出现梯度消失问题。
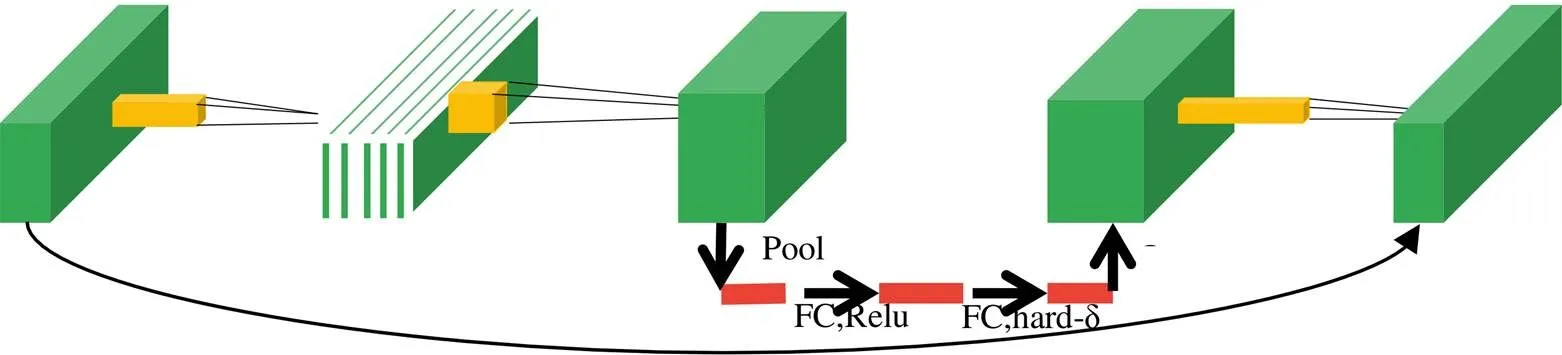
图1 Bneck结构示意图[10]
2 YOLOv5算法的改进
本文主要从YOLOv5网络结构、课堂异常行为预测框技术、损失函数三个方面进行改进。
2.1 YOLOv5网络结构改进
课堂异常行为检测系统需要部署在嵌入式监控设备中,检测课堂异常行为的网络规模不能太大。基于减小网络规模考虑,本文提出了融合MobileNet V3 large的YOLOv5算法,采用MobileNet V3 large中的BNeck结构来改进YOLOv5s 的骨干网络结构,采用深度可分离卷积代替普通卷积来减少网络参数量,改进后M-YOLOv5s网络结构如图2所示。

图2 M-YOLOv5s网络结构图
在本文给出的M-YOLOv5s网络结构中引入了5-Convs结构。5-Convs是由三个CBA和两个DCBA结构块组成,其中DCBA与CBA主要区别是把普通3*3卷积替换为深度可分离卷积。由于YOLOv5s网络需要进行多次上采样会产生大量参数,所以本文在对YOLOv5s中PANet结构改进时引入了深度可分离卷积结构,以使得网络具有更快地检测速度。深度可分离卷积将普通卷积拆分为逐通道卷积和逐点卷积两部分,假设特征图输入和输出尺寸分别为××、××,卷积核尺寸为××,则采用深度卷积参数量为××+×,采用标准卷积下的参数量为×××。显然,网络结构在引入深度可分离卷积时参数量可以大大降低。改进后的M-YOLOv5s骨干网络结构详细参数如表1所示。

表1 M-YOLOv5s 骨干网络结构表
其中,From表示该模块来自哪一层,Number用以控制该模块的深度,Operator表示这个模块的具体操作,Con3BN后Args列的值分别表示该模块的输入通道数、输出通道数和步长信息,MobileNetV3_InvertedResidual后Args列的值分别表示该模块的输出通道数、1×1卷积升维后的通道数、卷积核大小、步长、是否加入SE注意力机制和是否使用h-swish激活函数。
2.2 课堂异常行为预测框技术改进
课堂异常行为主要体现在学生低头讲话、玩手机等,本文以学生课堂讲话(chat)、睡觉(sleep)、玩手机(playphone)和吃东西(eat)四类异常行为为例,进行课堂异常行为感知检测研究。课堂中讲话、玩手机、睡觉和吃东西等异常行为检测为小目标、易遮挡检测,为了增强改进网络M-YOLOv5s对小目标检测的适应性,本文在设置M-YOLOv5s网络初始锚框时,调整了YOLOv5网络的初始锚框值,增加了一类小目标的锚框,改进后的初始化锚框如表2所示。其中表中感受野是指卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小;通俗点说,就是图像的最终输出的每一个特征(每一个像素)到底受到原始图像哪一部分的影响。
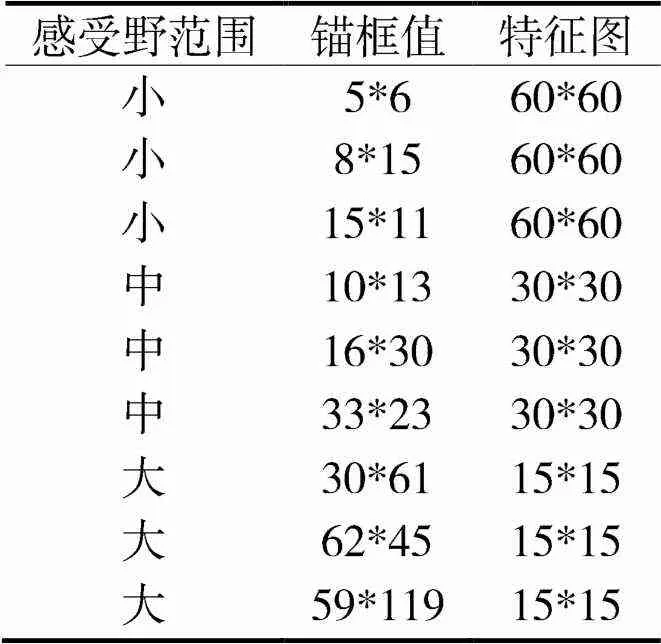
表2 M-YOLOv5s初始设定的锚框表




2.3 M-YOLOv5s损失函数改进
在网络训练过程中,各类异常行为真实值与M-YOLOv5s网络预测值之间差值就是当前网络模型的损失值。M-YOLOv5s网络通过前向传播计算得到预测框的偏移量损失、置信度损失和分类信息损失,然后再反向更新权重参数。M-YOLOv5s损失包括预测框损失、置信度损失和类别损失三部分。
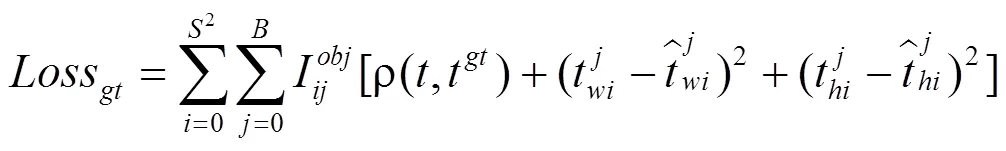


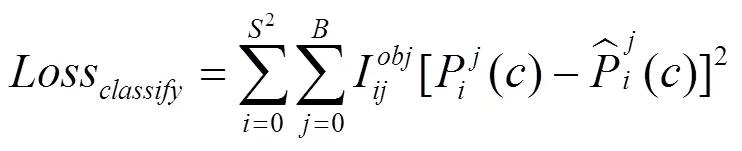
综合式(3),(4)和(5),可以得出M-YOLOv5s损失函数为式(6)。
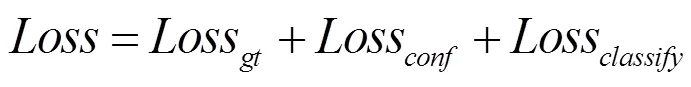
3 实验
本文实验环境:处理器为Intel(R) Core(TM)i7-9700 CPU @ 3.00GHz,显卡为NVIDIA GeForce RTX 1660Ti,6GB显卡,操作系统为Windows10 64位、深度学习框架采用PyTorch1.8.1,计算架构为CUDA11.4。为了验证M-YOLOv5s算法的改进效果,我们首先在基准数据集进行对比实验,然后就模型应用在课堂异常行为检测问题,在课堂异常行为数据集上进行对比实验。
3.1 基准数据集实验
本文采用包含80个类别的COCO数据集[13]作为基准数据集,每种类别抽取数量在500至800张,训练集和验证集按照8∶2划分。对训练模型参数设置训练批次大小为16,训练迭代次数epoch为300,其他参数均采用YOLOv5官方代码提供的默认值。
在实验中,将M-YOLOv5s、YOLOv5s和MobileNet V3s三种模型在COCO数据集上对mAP、Precision和ReCall做了对比。其中mAP表示阈值分别为0.50, 0.55, 0.60, 0.65, 0.70, 0.75, 0.80, 0.85, 0.90, 0.95共10种情形的平均mAP,Precision表示算法准确度,ReCall表示算法的召回率。实验结果如表3所示,相比于YOLOv5s模型,M-YOLOv5s在对COCO数据集80个类别的检测精确性和召回率方面,mAP、Precision、ReCall值都略低。究其原因是M-YOLOv5s算法在融合了轻量化的MobileNetV3主干结构后,其识别精度、召回率都有所下降,但相比于MobileNetV3s模型,Precision值提高了0.17,Recall值提高了0.19。

表3 在VOC2007数据集上不同模型的精确度、召回率对比结果
为了对比M-YOLOv5s算法是否适合在嵌入式设备中使用,在基准数据集实验中也对三种模型的参数量(Params)和计算量(FLOPs)进行了对比实验。对比结果如表4所示,M-YOLOv5s模型的参数量、计算量相比于YOLOv5s模型已大大降低。
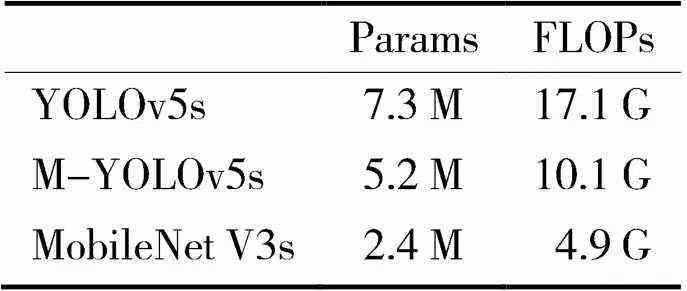
表4 在 VOC2007数据集上的不同模型的参数量和计算量对比结果
3.2 课堂异常行为数据集的生成
实验数据集的原始素材来自学生上课时教室前后两个摄像头捕获的视频。本文对捕获的视频首先转换为480*480图片。由于课堂视频画面中一般一个异常行为都会持续一段时间,所以视频转换得到的图片帧重复率高。本文对视频转换得到的图片进行再次过滤,收集到35000张图片。其中,30000张作为训练集,5000张作为测试集。采集图片样例如图3所示。为了保护图中人物隐私,本文后面所有图中出现的人物头像均已做了马赛克处理。
数据集采用VoTT工具进行标注。图4所示的是对数据集中图片标注后的效果图,标注的信息包含边界框的4个坐标点信息。对30000张图片的训练集共计标注117720个Region,其中玩手机为56617个Tag,聊天行为28052个Tag,睡觉行为31398个Tag,吃东西行为1653个Tag,每张图片上包含异常行为标记为3.93个Tag。训练批次大小为16,阈值设置为0.5,训练迭代次数epoch为300,其他参数均采用YOLOv5默认值。

图3 数据集样例图

图4 数据集VoTT标注实例图
3.3 改进算法的mAP值对比实验及结果分析
为了验证M-YOLOv5s模型的改进效果,本文在采集课堂数据集上对M-YOLOv5s模型、YOLOv5s和MobileNetV3s模型做了对比试验,经过3种不同模型训练得出的平均精度(mAP)如图5所示。

图5 不同模型的课堂异常行为检测mAP对比图
从M-YOLOv5s模型、YOLOv5s模型和MobileNet V3s模型对课堂异常行为检测的mAP结果可以发现,在对玩手机playphone、聊天chat和睡觉sleep三种课堂异常行为检测时,M-YOLOv5s模型、YOLOv5s模型相比MobileNetV3s模型检测结果的mAP值表现较好,M-YOLOv5s模型在融入MobileNetV3的BNeck结构后mAP值并没有明显下降。究其原因,是因为学生在课堂上的玩手机、聊天和睡觉这类行为特征明显、易识别,影响课堂异常行为识别效果主要是因为有些后排的学生发出的异常行为目标较小或者被遮挡造成无法检测。M-YOLOv5s算法模型针对小目标、易遮挡造成无法检测问题,调整了YOLOv5网络的初始锚框值,增加了一类小目标的锚框来增强算法对小目标的识别效果,同时,使用DIoU-NMS算法[12]替换YOLOv5的NMS算法,减少了被遮挡的异常行为被漏检情况发生。另外,从对比试验还发现,三种网络模型对课堂eat行为感知检测都比较低,经过分析发现,本文抽取的课堂监控视频中很少有学生吃东西的画面,导致实验数据集中30000张图片标记出来的eat类Tag仅为1653个,平均每张照片的eat类标注太少,吃东西类异常行为在整个数据集中分布不平衡,影响了算法模型训练导致。图6是M-YOLOv5s模型检测课堂异常行为的结果示意图,可以看到M-YOLOv5s模型可以对课堂异常行为做出有效判断。

图6 M-YOLOv5s模型检测课堂 异常行为的结果示意图
3.4 改进算法的综合参数对比实验及结果分析
对比M-YOLOv5s模型、YOLOv5s模型和MobileNetV3s模型的综合参数,对比结果如表5所示。相比于MobileNet V3s网络,参数量提升一倍左右,但是召回率明显从0.71大幅上升为0.91,对所有类别的课堂异常行为检测的查准率从0.51提升到0.73。相比于YOLOv5s网络,在保证了召回率、查准率不明显下降情况下,参数量、计算量都有大幅度降低,这对于适配嵌入式终端更具有重要意义。
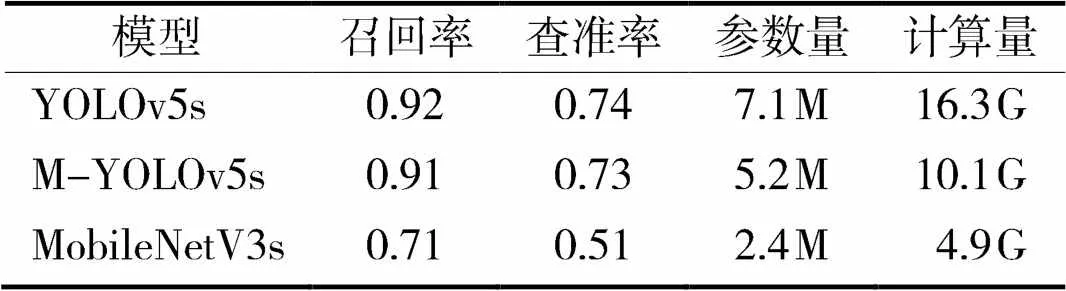
表5 M-YOLOv5s模型和YOLOv5s模型的综合参数对比表
4 结论
在进行课堂异常行为感知检测时,由于现有的YOLOv5s算法模型部署在教室监控设备上,存在网络模型参数量、计算量较大问题,本文针对课堂异常行为检测问题,对YOLOv5s算法进行了改进,给出一种M-YOLOv5s检测算法,该算法融合了MobileNet V3 large的骨干网络BNeck结构,降低了网路模型参数量。同时,M-YOLOv5s算法结合课堂异常行为属于易遮挡的小目标特点,在初始化锚框中增加了一组小目标锚框,并对YOLOv5s的损失函数做了改进,减少了算法在对小目标检测的遗漏问题。实验结果表明,改进后的M-YOLOv5s算法在不损失平均精度的情况下,网络模型更轻量化,更适合部署在嵌入式终端等资源受限设备。
[1] 徐涛,田崇阳,刘才华. 基于深度学习的人群异常行为检测综述[J]. 计算机科学,2021, 48(09): 125-134.
[2] 张红民,李萍萍,房晓冰,等. 改进YOLOv3网络模型的人体异常行为检测方法[J]. 计算机科学,2022, 49(04): 233-238.
[3] 胡均平,孙希. 基于改进Faster R-CNN的近红外夜间行人检测方法[J]. 传感器与微系统,2021, 40(08):126-129.
[4] 陈一潇,阿里甫·库尔班,林文龙,等. 面向拥挤行人检测的CA-YOLOv5[J]. 计算机工程与应用,2022, 58(09): 238-245.
[5] 施新凯. 基于监控视频的群体性异常事件检测研究[D]. 北京:中国人民公安大学,2022.
[6] REN S Q, HE K M, GIRSHICK R B, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[7] HE K M, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 42(2): 386 - 397.
[8] LIU W, ANGUELOV D, ERHAN D, et al. Ssd: single shot multibox detector[C]//European Conference on Computer Vision, Springer, Cham, 2016: 21-37.
[9] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779-788.
[10] HOWARD A, SANDLER M, CHU G, et al. Searching for MobileNetV3[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019: 1314-1324.
[11] 杨永波,李栋. 改进YOLOv5的轻量级安全帽佩戴检测算法[J]. 计算机工程与应用,2022, 58(09): 201-207.
[12] GONG M, WANG D, ZHAO X, et al. A review of non-maximum suppression algorithms for deep learning target detection[C]// Seventh Symposium on Novel Photoelectronic Detection Technology and Application 2020, 2021.
[13] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]//European Conference on Computer Vision, Springer International Publishing, 2014: 740-755.
An improved classroom abnormal behavior detection algorithm based on YOLOv5
ZHU Xian-yuan,WANG Song-lin,ZHOU Ye-fan,HAN Hai-feng
(School of Information and Artificial Intelligence, Anhui Business College, Anhui Wuhu 241002, China)
The detection of classroom abnormal behavior is the prerequisite for the portrait of students' class state. For example, the existing YOLOV5s network sensing detection effect is good, but the parameter scale is large, so it is not suitable for embedded terminals. At the same time, the recognition of classroom abnormal behavior belongs to multi-objective and easy occlusion recognition. To solve the above problems, an improved network model M-YOLOv5s is given. Experiments show that M-YOLOV5s network model has the same average accuracy as YOLOV5s in classroom abnormal behavior perception, but the amount of parameters, calculation and model size of the network model have decreased significantly, which is suitable for installation and deployment on embedded terminals.
convolutional neural network;YOLOv5 algorithm;abnormal behavior detection;machine vision
2022-07-09
安徽省教育厅自然科学研究重点项目(KJ2020A1081,KJ2021A1483);安徽省质量工程项目(2020zyq29);安徽商贸职业技术学院自然科学重点项目(2022KZZ05)
朱先远(1981-),男,安徽六安人,讲师,硕士,主要从事人工智能、物联网研究,865752942@qq.com。
TP391.41
A
1007-984X(2023)01-0046-07
