融合深度残差网络和注意力机制的3D目标检测
2023-03-02赵瑞陶兆胜宫保国李庆萍吴浩
赵瑞,陶兆胜,宫保国,李庆萍,吴浩
融合深度残差网络和注意力机制的3D目标检测
赵瑞,陶兆胜,宫保国,李庆萍,吴浩
(安徽工业大学 机械工程学院,安徽 马鞍山 243032)
针对Frustum-PointNets的实例分割网络结构单一且卷积深度较深、易出现特征丢失和过拟合,检测准确率较低的问题,提出了一种改进的Frustum-PointNets网络。该网络首先构建深度残差网络并融入实例分割网络,提高特征提取能力,解决深层网络的退化问题;引入双重注意力网络以增强特征,提高分割效果;运用Log-Cosh Dice Loss解决样本不均衡,加快网络训练;使用Mish激活函数保留特征信息;最后基于Kitti和SUN RGB-D两个数据集进行实验验证本文算法的有效性。实验结果表明,本文算法相对于Frustum-PointNets,在Kitti数据集中,3D框检测精度提高了0.2%~13.0%;鸟瞰图的3D框检测精度提高了0.2%~11.3%。在SUN RGB-D数据集中,本文算法的3D框检测精度提高了0.6%~16.2%,平均检测精度(mAP)提高了4.4%。实验验证,本文算法在室外和室内场景中获得较好的目标检测及分割效果。
3D目标检测;实例分割网络;深度残差网络;双重注意力模块;Log-Cosh Dice Loss
随着深度学习理论、计算机视觉原理的发展,运用基于深度学习的计算机视觉检测技术检测目标及其空间位姿,越来越成为众多学者研究的重点领域之一[1]。目前视觉检测技术主要分为两大类:1)二维(2D)目标检测技术,其核心是使用RGB图像对目标物体进行分类和定位,核心算法主要包括:Faster-RCNN(Faster Region-based Convolutional Neural Network)[2],SSD(Single Shot MultiBox Detector)[3],Yolov4(You only look once v4)[4]等;2)三维(3D)目标检测技术,即运用点云数据确定三维空间的目标物体类别及其位姿,典型算法如AVOD(Aggregation View Object Detection)[5],UberATG-ContFuse[6],Mono3D(Monocular 3D)[7]等。
虽然2D的RGB图像具有数量众多的采样点,但存在因缺乏深度信息而无法准确定位物体间距的问题。3D点云数据拥有丰富的深度信息,且能较为准确地检测物体的空间位姿,故在智能行驶中得到广泛的应用,但其也存在远距离目标的3D点云数据稀疏且分布不均匀等缺陷。因此,如何有效运用3D点云数据检测智能车周围环境的车辆、行人以及障碍物,从而合理规划行驶路径和避障成为广大学者的重点研究方向之一。ZHOU等[8]提出一种3D目标检测网络VoxelNet,该网络首先构建voxel栅格化点云,然后引入体素特征编码编码栅格点云,最后使用区域建议网络输出检测结果。CHEN等[9]设计了一种3D目标检测网络Complex-YOLO,该网络制定复回归策略以扩展基于RGB图像的2D检测,并通过点云降维将图像检测网络应用于点云目标检测。QI等[10]提出的Frustum-PointNets运用2D目标检测器对目标分类,降低了网络对三维空间物体的学习难度,应用实例分割网络对目标逐维精准定位,缩短了搜索时间。敖建锋等[11]针对Frsutum-PointNets网络对比使用了Relu激活函数解决神经网络的梯度消失和Swish激活函数解决神经元的坏死。张耀威等[12]对Frsutum-PointNets网络利用Yolov3(You only look once v3)[13]获得二维包围框,通过扩张二维包围框提取视锥点云。HU等[14]提出了SE注意力,通过挤压特征使通道间产生相互依赖关系,提高模型性能。WOO等[15]提出CBAM注意力,利用卷积运算计算通道间的位置信息,获得空间注意力。FU等[16]提出了双重注意力模块(Dual Attention Module, DAM),该注意力不仅能捕获上下文依赖,而且能自适应的整合局部特征和全局关联。MILLETARI等[17]提出了Dice Loss,可以缓解正负样本数量不均衡。JADON[18]提出了Log-Cosh Dice Loss,不仅解决训练中正负样本不均衡,而且训练过程更加平滑。
针对Frustum-PointNets的实例分割网络结构单一且卷积深度较深、在提取特征过程中易出现特征丢失和过拟合等问题,本文构建了一种改进的残差网络(Deep Residual Network, DRNet)以提取特征,解决特征丢失、过拟合和梯度弥散等问题;在实例分割网络中引入双重注意力模块以增强前景和背景之间的分割效果;使用Log-Cosh Dice Loss替换交叉熵(Cross-Entropy)损失函数,提高对前景的挖掘能力;采用Mish[19]激活函数代替Relu激活函数,优化梯度下降程度。
1 Frustum-PointNets模型原理
Frustum-PointNets模型(图1所示)由视锥候选区域提取网络、3D实例分割网络、3D边界框预测网络构成。该模型首先融合RGB图像和稀疏点云数据,并运用Mask-RCNN[20]提取2D检测框,通过标定映射至空间点云上,获取视锥候选区域;然后使用PointNet[21]网络分割点云,区分前景和背景,即将视锥区域内的点云数据输入网络,采用实例分割网络提取特征,生成特征图,融合特征图与图像检测结果,分割前景和背景;接着将分割的特征图输入类似空间变换网络(Spatial Transformer Networks, STN)[22]的T-Net网络进行坐标变换,使视锥坐标系和相机坐标系正交;最后将坐标变换的特征图输入边界框进行预测,估算目标的类别和位姿。
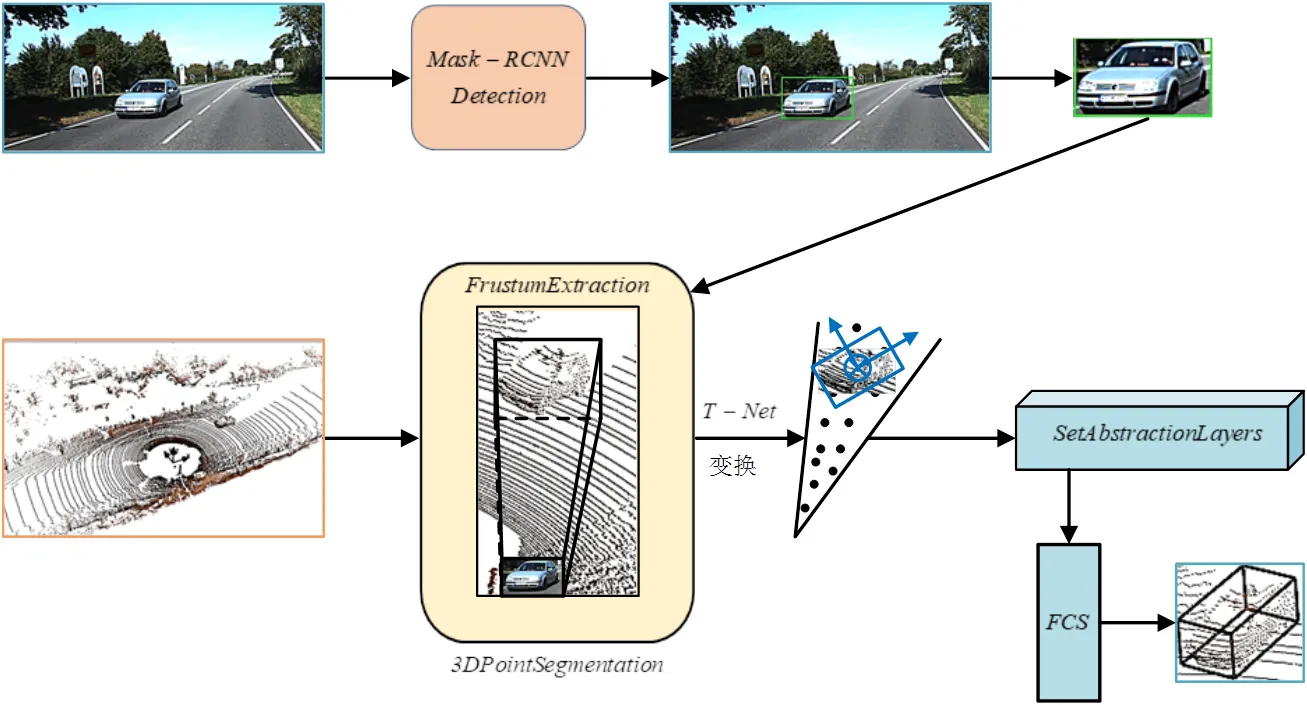
图1 Frustum-PointNets模型基本结构
2 Frustums-PointNets模型优化
2.1 特征提取网络优化
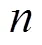
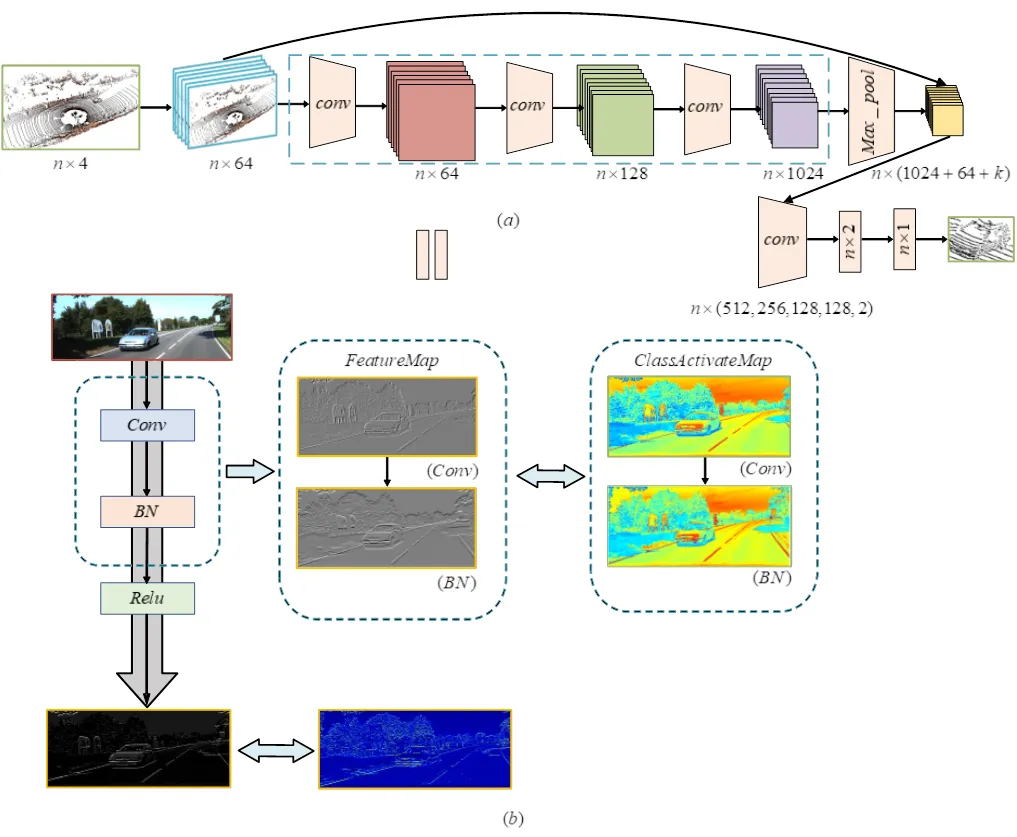
图2 3D实例分割模块结构
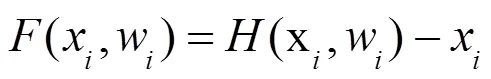
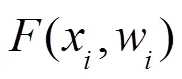

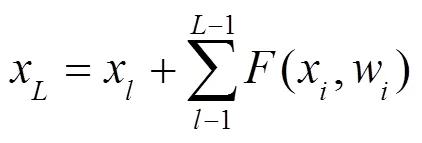

类激活热力图通过对特征图逐通道加权运算,判断目标物体的特征对输出特征图的贡献度。为此,本文分别采用类激活热力图(如图2(b)和图3(b)所示)分析经卷积运算和残差运算后,图像的哪些特征对模型的最终输出特征贡献度较大。由图2(b)可知,卷积运算和批量归一化运算关注车辆的前保险杠、进气格栅和背景,且在实例分割模块输出的特征图的类激活热力图中,车辆的前保险杠和进格气栅的轮廓结构较清晰,而其余车身轮廓结构与背景环境轮廓几乎浑然一体。上述现象表明Frustum-PointNets的实例分割模块所输出的特征图只关注车辆的前保险杠和进气格栅。由图3(b)可知,虽然Mish运算只注重车辆的前发动机罩和车顶。但卷积运算后,残差模块提取了车辆的前保险杠、进气栅、车顶和后翼子板等特征。在残差输出的特征图的类激活热力图中,车辆的车身轮廓结构清晰,说明本文提出的残差模块能较好地提取车辆的纹理结构特征。

图3 本文改进的残差模块结构
2.2 双重注意力网络优化
3D实例分割网络在特征提取过程中,因浅层神经网络的感受野较窄,故提取的特征纹理细节较丰富,但缺乏语义鉴别能力;深层神经网络的感受野较宽,对姿态、形变及光照等更具有鲁棒性,有利于语义鉴别,但易丢失特征纹理细节。因此,本文引入双重注意力网络(Dual Attention Network, DANet)对不同的特征设置不同的权重,有选择性地增强目标特征信息,抑制无关特征信息,提升分割效果。
双重注意力网络运用自注意力机制捕获空间维度和通道维度的特征信息,自适应地抓取局部特征之间的全局依赖关系,增强特征表达,提高分割准确性。DANet由位置注意力模块和通道注意力模块构成,位置注意力模块关注不同特征间的相似关系,得到不同特征之间的依赖关系,通道注意力模块关注不同特征图间的相似关系,得到不同特征图之间的依赖关系,通道即特征图。双重注意力网络首先计算空间域和通道域之间的特征联系,然后融合两模块的输出特征信息,提高特征表达能力。
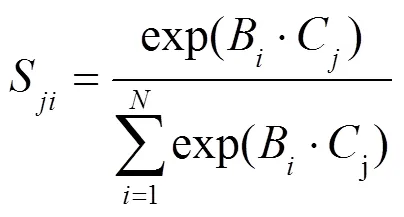


图4 位置注意力模块结构图
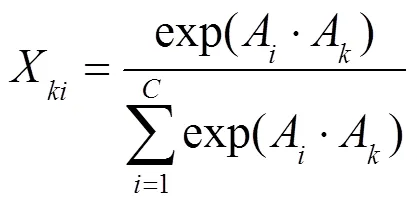


图5 通道注意力模块结构图

图6 改进的3D实例分割网络结构
2.3 损失函数优化
在Frustum-PointNets的分割网络对目标点云进行前景和背景分割时,因其前景点云的数量相对于背景点云的数量少,从而导致前景点云样本和背景点云样本分布不均衡,降低了实例分割网络的分割能力,影响检测效果。为了解决样本分布不均衡的问题和提高模型的准确性,本文引入度量集合间相似度的函数Log-Cosh Dice Loss:



图7 损失函数图
Frustum-PointNets的损失函数Cross-Entropy和本文算法的损失函数Log-Cosh Dice Loss在训练过程中的损失函数值分别如图7(a),(b)所示。由图7可知,训练迭代200轮后,Cross-Entropy函数和Log-Cosh Dice Loss函数的损失值都趋于收敛。但Cross-Entropy的损失值趋于0.18但波动较大,而Log-Cosh Dice Loss损失值趋于0.003且波动幅值小。图8为Frustum-PointNets和本文算法的损失函数拟合曲线对比图,Loss Value1为本文算法的损失值,Loss Value2为Frustum-PointNets的损失值。通过对比可知,Frustum-PointNets的损失值分布散乱,而本文算法的Log-Cosh Dice Loss在训练开始时,梯度下降较快,收敛更加迅速,在训练过程中损失值聚集且波动小,训练稳定。

图8 损失函数拟合图
2.4 激活函数优化
当特征矩阵输入Frustum-PointNets的3D实例分割网络所运用的Relu激活函数中计算梯度时,负值特征被抑制激活,导致无法继续学习,且该激活函数在0点不平滑,影响梯度下降。针对上述问题,本文运用Mish激活函数实现计算负值特征时具有较小的负梯度,以便在后续卷积计算中激活特征值,获取更多特征信息,提高梯度下降速度:
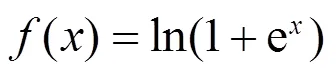

3 实验结果及分析
3.1 实验环境
本文实验使用数据集为KITTI数据集和SUN RGB-D数据集。KITTI数据集为自动驾驶领域数据集,本实验使用汽车(Car)、行人(Pedestrian)、骑车人(Cyclist)3个类别进行验证,每个类别根据不同程度的遮挡,又细分为简单(Easy)、中等(Moderate)、困难(Hard)三个等级。训练数据集中包含7481张图片及雷达数据,验证集有3597张图片及雷达数据。SUN RGB-D数据集为室内场景数据集,本实验运用bed、table、sofa、chair、toilet、desk、dresser、night_stand、bookshelf、bathtub10个类别进行实验对比。训练数据集包含4150张图片及雷达数据,验证集有1623张图片及雷达数据。实验的点云数量为2048,训练迭代为200轮,Batch为14,学习率为0.001,优化器为Adam。实验平台配置为:I7-10700K、RTX2070S、Tensorflow1.15、Windows10、CUDA10.0。
3.2 Frustum-PointNets结果分析
在KITTI数据集中,Frustum-PointNets和本文算法的3D框预测结果对比如图9所示,左图为图像的3D框预测结果,右图为点云3D框预测结果,图中绿色框为真值框(Ground-truth),红色框为预测框(Prediction)。由图9(a)可知,Frustum-PointNets和本文算法对汽车类别的位置和大小预测都较为准确,但Frustum-PointNets预测的航向角偏差较大,而本文算法预测的航向角较小,能更好地准确预测汽车的行驶方向。由图9(b)和图9(c)可知,Frustum-PointNets和本文算法都较为准确地预测了骑车人和行人的位置、大小和方向,但本文算法相对于Frustum-PointNets,对骑车人和行人的预测准确度更高。实验结果表明,本文算法相比于原Frustum-PointNets在室外真实场景中,能获得较为良好的检测效果。
为了验证模型性能的提升程度,本文采用模型检测精度(AP)与3DOP、MV3D、MLOD和Frustum-PointNets等算法进行对比实验,设置Car类别的IOU阈值为0.7,Pedestrian和Cyslist类别的IOU阈值为0.5,表1为KITTI数据集下不同算法的3D框检测的检测精度对比效果。
从表1可知,与Frustum-PointNets相比,本文算法除了Cyclist类别下的Easy检测精度略低之外,整体的检测精度都有不同的程度的提升。Car类别的Easy、Moderate、Hard分别提高了5.6%、2.7%、1.8%;Pedestrian类别的Easy、Moderate、Hard分别提高了2%、2%、13%;Cyclist类别的Moderate、Hard分别提高了0.5%、0.2%,但Easy降低了0.9%;与3DOP(3D Object Proposals)算法[23],MV3D(Multi-View 3D Object Detection Network)[24]的Car类别相比,Easy最低提高了6.9%,最高提高了1062%,Moderate最低提高了11.8%,最高提高了1273.2%,Hard最低提高了12.2%,最高提高了1447.6%。
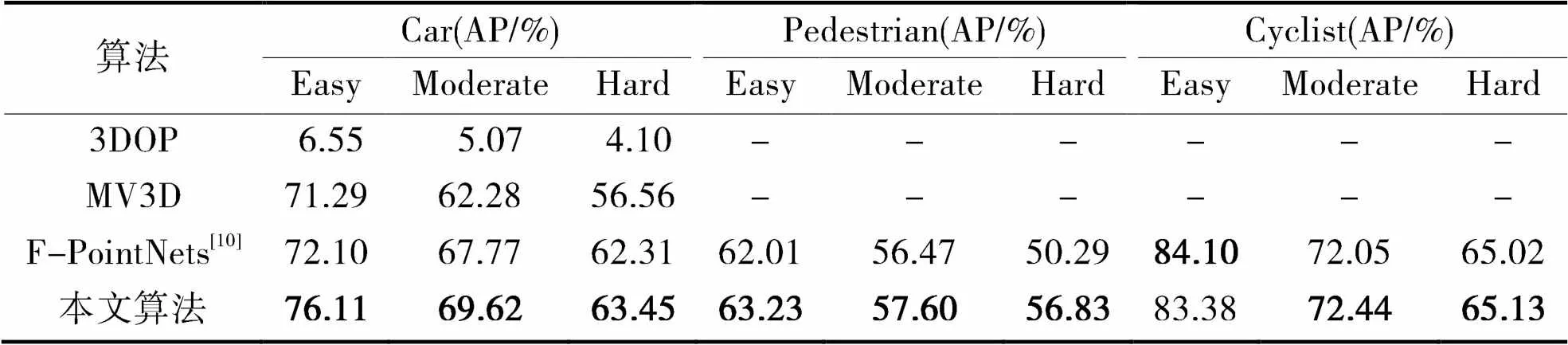
表1 3D框检测精度对比
注:粗体表示最优值
表2为不同算法的鸟瞰图3D框检测精度对比表,与Frustum-PointNets相比,除了Cyclist类别下Easy等级检测精度略低,整体的检测精度都有提升。Car类别的Easy、Moderate、Hard分别提高了3%、1.7%、1.2%;Pedestrian类别的Easy、Moderate、Hard分别提高了0.3%、11.3%、1.2%;Cyclist类别的Moderate、Hard分别提高了0.5%、0.2%,但Easy降低了0.6%。同时与MV3D相比,Car类别的Easy相比降低了2.8%,但与3DOP相比提高了566.1%,Moderate最低提高了8.2%,最高提高了790.2%,Hard最低提高了0.7%,最高提高了916.3%。

表2 鸟瞰图的3D框检测精度对比
注:粗体表示最优值
本文在分割网络中融入了多个优化算法,为了验证每个优化算法对模型的影响程度,对每个优化算法分别进行实验分析,实验结果如表3所示。从表3的训练集和测试集可知,相对于Frustum-PointNets,融入Mish激活函数,准确率分别提升了0.08%, 0.05%;引入Log-Cosh Dice Loss分割准确率分别提升了0.16%, 0.15%;应用DRNet,分割准确率分别提高了0.94%, 0.89%;加入DANet,分割准确率分别提高了1.41%, 1.4%;当融合所有优化方法时,分割准确率分别提高了1.53%, 1.5%,准确率提升最高。
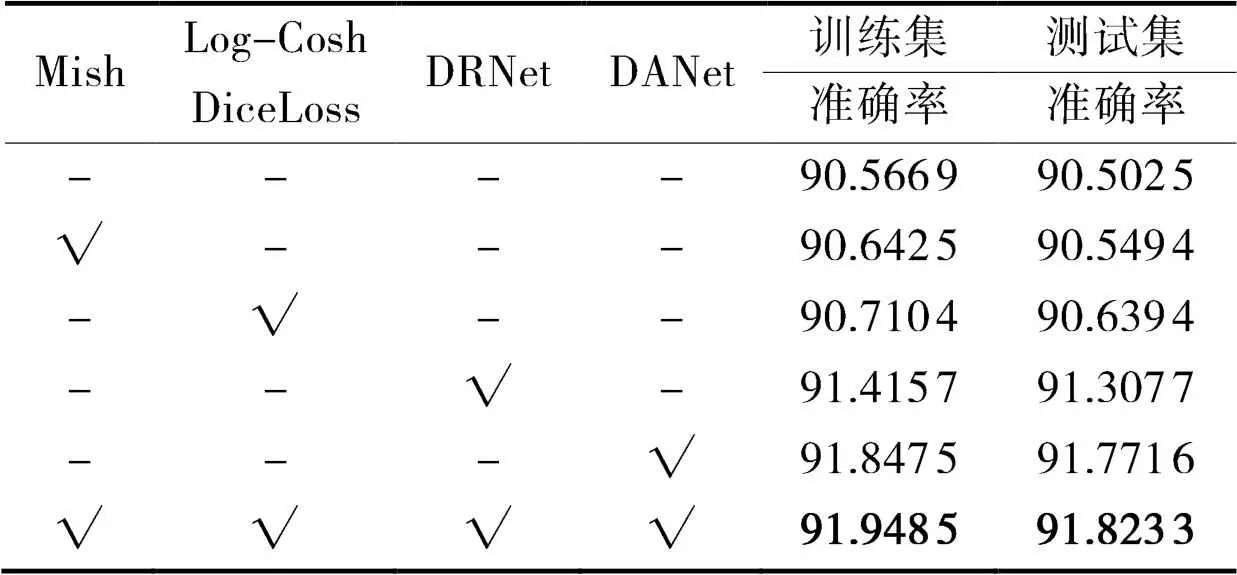
表3 分割准确率对比 %
注:√表示使用,粗体表示最优值
在SUN RGB-D数据集中,Frustum-PointNets和本文算法的3D框预测对比如图10所示,图中绿色框为真值框,红色框为预测框。由图10(a)可知,Frustum-PointNets算法和本文算法都较好地预测了chair、soft和table的尺寸、位置及方向,但Frustum-PointNets对bookshelf的尺寸、位置及方向的预测偏差大,本文算法虽然对尺寸预测有偏差,但较为准确地预测了位置及方向。Frustum-PointNets和本文算法预测图像底部的sofa、table(如图10(b)所示)误差明显,但在预测黑框部分的sofa、table时,Frustum-PointNets无法准确预测sofa且table偏差较大,而本文算法准确地预测soft和table的尺寸、位置及方向。在图10(c)中,Frustum-PointNets错误地预测黑框的night_stand和soft的尺寸、位置及方向,本文算法虽然对night_stand的尺寸、位置及方向有预测误差,但较为准确的预测了soft的尺寸、位置及方向。
通过上述对比可知,本文算法能较为准确地预测chair、soft和table的摆放位置、尺寸和朝向,而Frustum-PointNets的预测结果出现了包围框尺寸过大、包围框尺寸过小、位置估计错误和方向偏差过大等问题。实验结果表明,本文算法较Frustum-PointNets在预测室内场景的障碍物时,也能获得较好的预测效果。
模型检测精度如表4所示,本文算法与Frustum-PointNets相比,除了bathtub、chair、nightstand类别的检测精度略低外,其余7个类别均有不同程度的提升。本文算法在bed、bookshelf、desk、dresser、sofa、table、toilet中检测精度分别提高了14.3%、16.2%、2.7%、0.6%、8.1%、5.1%、14.1%,但在bathtub、chair、nightstand中则分别降低了0.8%、1.5%、5.4%。本文算法和DSS[25]、2d-driven[26]算法相比,在部分类别中的检测精度具有一定的优势。本文算法相对于DSS,在bathtub、bookshelf、desk、dresser、nightstand、sofa中检测精度分别提高了13.1%、255.5%、162.4%、740.6%、347.4%、1.9%,在bed、chair、table、toilet中检测精度分别降低了26.0%、16.2%、10.3%、38.3%;相对于2d-driven,在bathtub、bed、bookshelf、chair、desk、dresser、nightstand、sofa、table中检测精度分别提高了14.9%、7.0%、34.7%、6.2%、92.8%、107.7%、64.4%、8.1%、21.9%,在toilet中检测精度降低了39.4%。总体的平均检测精度(mAP)本文算法提高了4.4%~25.2%。
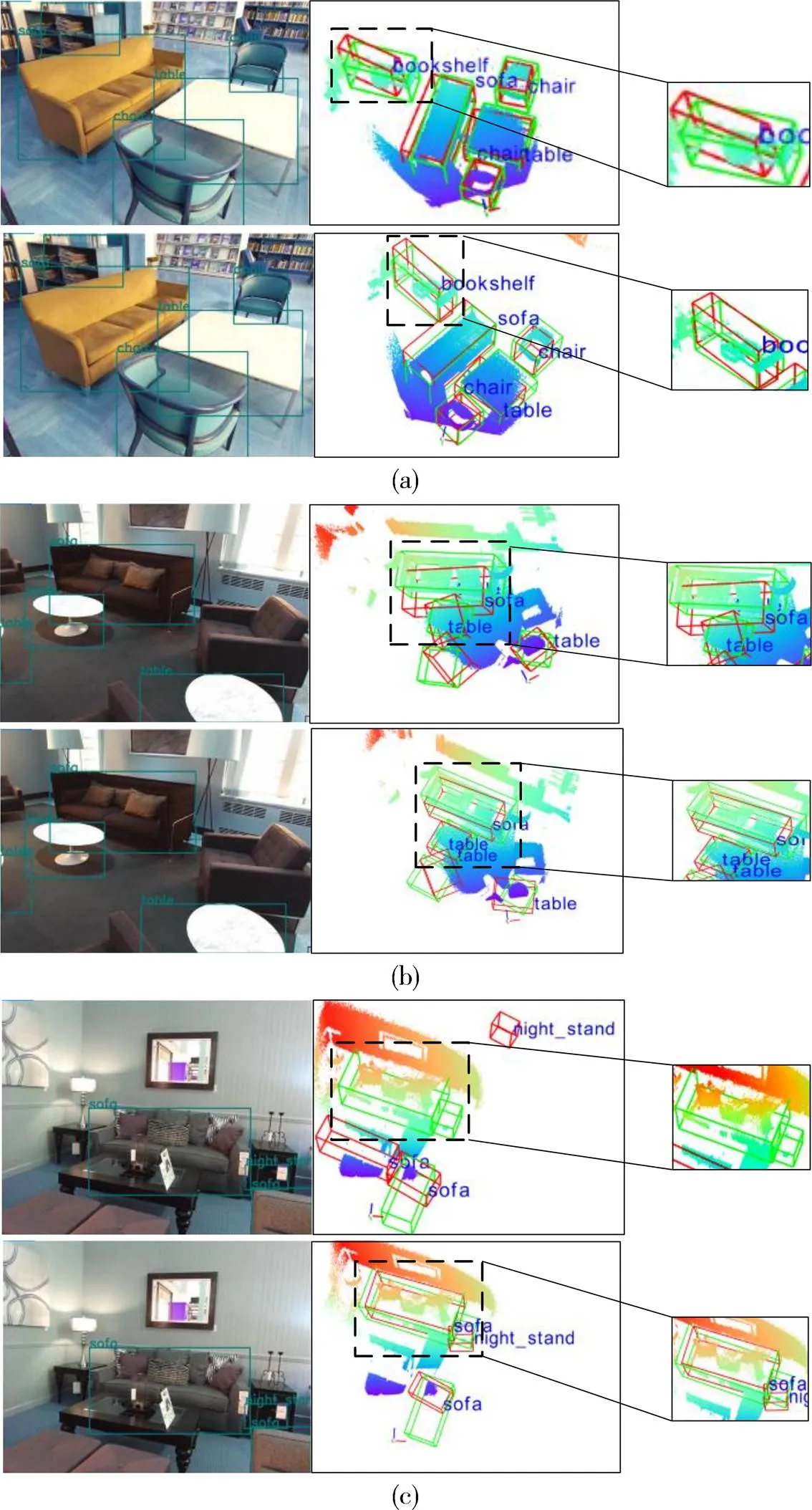
图10 Frustum-PointNets和本文算法的预测框对比图

表4 3D框检测精度对比
注:粗体表示最优值
分割准确率对比如表5所示,本文算法除了Mish激活函数在训练集的准确率略低以外,其余的优化方法对准确率都有一定程度的提高。从表5的训练集和测试集可知,相对Frustum-PointNets,融入Mish在测试集中准确率提高了0.05%,在训练集中降低了0.07%;引入Log-Cosh Dice Loss,分割准确率分别提高了0.27%、0.56%;应用 DRNet,分割准确率分别提高了0.45%、0.46%;加入DANet,分割准确率分别提高了0.75%、0.99%;当融合所有优化方法时,分割准确率分别提高了2%、2.4%,分割准确率提升最高。

表5 分割准确率对比%
注:√表示使用,粗体表示最优值
4 结束语
针对Frustum-PointNets检测3D目标准确率较低的问题,本文算法构建了一种改进的深度残差网络作为特征提取网络提取点云特征,引入双重注意力网络分割目标,使用Log-Cosh Dice Loss提高正负样本均衡,加快训练,使用Mish激活函数保留特征信息。实验结果表明,在KITTI数据集和SUN RGB-D数据集中,与其他3D目标检测网络相比,本文算法的分割准确率较高。因在提取特征过程中,存在背景干扰,室内场景较为复杂,点云重叠交错等因素,导致3D框检测精度在少数类别的部分检测项中有所降低,影响了网络分割。因此,后续研究将加强网络对于前景的挖掘和对于复杂场景的点云分割,进一步提高3D框检测精度。
[1] 徐晨,倪蓉蓉,赵耀. 融合稀疏点云补全的3D目标检测算法[J]. 图学学报,2021, 42(01): 37-43.
[2] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149.
[3] LIU W, ANGUELOV D, ERHAN D, et al. Ssd: single shot multibox detector[C]//European Conference on Computer Vision. Springer, Cham, 2016: 21-37.
[4] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. Yolov4: optimal speed and accuracy of object detection[C]//arXiv: Computer Vision and Pattern Recognition 2020, 2020: 1-17.
[5] KU J, MOZIFIAN M, LEE J, et al. Joint 3D proposal generation and object detection from view aggregation[C]//2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018: 1-8.
[6] LIANG M, YANG B, WANG S, et al. Deep continuous fusion for multi-sensor 3D object detection[C]//Proceedings of the European Conference on Computer Vision (ECCV), 2018: 641-656.
[7] CHEN X, KUNDU K, ZHANG Z, et al. Monocular 3D object detection for autonomous driving[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 2147-2156.
[8] ZHOU Y, TUZEL O. Voxelnet: end-to-end learning for point cloud based 3D object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 4490-4499.
[9] CHEN X, MA H, WAN J, et al. Multi-view 3D object detection network for autonomous driving[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1907-1915.
[10] QI C R, LIU W, WU C, et al. Frustum pointnets for 3D object detection from RGB-D data[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 918-927.
[11] 敖建锋,苏泽锴,刘传立,等. 基于点云深度学习的3D目标检测[J]. 激光与红外,2020, 50(10): 1276-1282.
[12] 张耀威,卞春江,周海,等. 基于图像与点云的三维障碍物检测[J]. 计算机工程与设计,2020, 41(4): 5.
[13] REDMON J, FARHADI A. Yolov3: an incremental improvement[J]. arXiv: Computer Vision and Pattern Recognition, 2018.
[14] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 7132-7141.
[15] WOO S, PARK J, LEE J Y, et al. Cbam: convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision (ECCV), 2018: 3-19.
[16] FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 3146-3154.
[17] MILLETARI F, NAVAB N, AHMADI S A. V-net: fully convolutional neural networks for volumetric medical image segmentation[C]//2016 Fourth International Conference on 3D Vision (3DV), 2016: 565-571.
[18] JADON S. A survey of loss functions for semantic segmentation[C]//2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), 2020: 1-7.
[19] MISRA D. Mish: a self regularized non-monotonic activation function[J]. arXiv: Computer Vision and Pattern Recognition, 2019: 1-14.
[20] HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision, 2017: 2961-2969.
[21] QI C R, SU H, MO K, et al. Pointnet: deep learning on point sets for 3D classification and segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 652-660.
[22] JADERBERG M, SIMONYAN K, ZISSERMAN A. Spatial transformer networks[J]. Advances in Neural Information Processing Systems, 2015: 28.
[23] CHEN X, KUNDU K, ZHU Y, et al. 3D object proposals using stereo imagery for accurate object class detection[J]. IEEE transactions on Pattern Analysis and Machine Intelligence, 2017, 40(5): 1259-1272.
[24] CHEN X, MA H, WAN J, et al. Multi-view 3D object detection network for autonomous driving[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1907-1915.
[25] SONG S, XIAO J. Deep sliding shapes for amodal 3D object detection in RGB-D images[C]//Proceedings of the IEEE conference on computer vision and Pattern Recognition, 2016: 808-816.
[26] LAHOUD J, GHANEM B. 2D-driven 3D object detection in RGB-D images[C]//Proceedings of the IEEE International Conference on Computer Vision, 2017: 4622-4630.
3D object detection based on depth residual network and attention mechanism
ZHAO Rui,TAO Zhao-sheng,GONG Bao-guo,LI Qing-ping,WU Hao
(School of Mechanical Engineering, Anhui University of Technology, Anhui Maanshan 243032, China)
For the example of Frostum-PointNets has a single split network structure, deep convolution depth, and is prone to feature loss and overfitting, and the detection accuracy is low. This paper proposes an improved Frostum-PointNets network. The network first constructs a deep residual network and integrates it into the instance segmentation network to improve the feature extraction ability and solve the degradation problem of the deep network. Introduction of dual attention modules to enhance features and improve the effect of segmentation; Log-Cosh Dice Loss is used to solve sample imbalance and speed up network training; Use the Mish activation function to preserve feature information; Finally, based on the two datasets of Kitti and SUN RGB-D, the effectiveness of the proposed algorithm is experimentally verified. Experimental results show that compared with Frostum-PointNets, the accuracy of 3D frame detection is improved by 0.2%-13% in Kitti dataset. The accuracy of 3D frame detection of aerial view is improved by 0.2% to 11.3%. In the SUN RGB-D dataset, the detection accuracy of the 3D frame of the proposed algorithm is improved by 0.6%-16.2%, and the average detection accuracy (mAP) is increased by 4.4%. Experimental results show that the proposed algorithm obtains better object detection and segmentation effects in outdoor and indoor scenarios.
3D object detection;instance segmentation network;deep residual networks;dual attention module;Log-Cosh Dice Loss
2022-08-18
安徽省自然科学基金面上项目(2108085ME166);安徽高校自然科学研究项目重点项目(KJ2021A0408)
赵瑞(1996-),男,安徽合肥人,硕士,主要从事机器视觉应用研究,1754714821@qq.com。
TP391
A
1007-984X(2023)01-0031-11
