基于深度强化学习的正交频分复用多小区蜂窝网资源分配方法
2023-03-02孙明胡良进郝冰于颖
孙明,胡良进,郝冰,于颖
基于深度强化学习的正交频分复用多小区蜂窝网资源分配方法
孙明,胡良进,郝冰,于颖
(齐齐哈尔大学 计算机与控制工程学院,黑龙江 齐齐哈尔 161006)
针对正交频分复用的多蜂窝网络系统,提出了一种基于深度强化学习的通信资源分配算法,该算法在满足资源分配高速率、低延时要求的前提下,同时产生信道分配方案和功率控制方案,从而最大化系统的能量效率。首先,在确定好基于正交频分复用的多蜂窝网络系统模型的基础上,将最大化能量效率的约束优化问题同深度Q强化学习算法进行问题映射。其次,将构建的深度Q神经网络(DQN)的多个隐藏层作为状态值函数,用以输出信道分配方案和功率控制方案,并实时与外界环境保持交互,不断迭代更新网络参数用以最大化系统能量效率。通过仿真对比实验可得,所提出的深度强化学习算法在保证低计算时延的同时,可获得接近于或高于其他算法的系统能量效率,且蜂窝网络规模越大,该算法优势越突出。
深度强化学习;正交频分复用;蜂窝网;资源分配;神经网络
无线频谱资源作为移动通信的紧缺资源,一直是移动通信技术的重要研究内容[1-2]。随着5G网络的兴起和智慧网络、绿色网络等新概念网络的提出,无线通信系统的用户越来越密集,因此最优无线资源分配也是无线网络设计和运行的基本挑战之一,尤其在面对如今数据呈爆炸式、多样化的通信系统,如何通过合理的无线资源分配方式获得高功率,同时满足低功耗、低延时的要求已成为无线通信领域研究的重要方向[3-12]。蜂窝网是采用蜂窝无线组网方式,在用户和基站之间通过无线通道连接起来,进而实现用户在区域中可实时通信。正交频分复用的多蜂窝网络系统凭借绿色网络、频率复用、小区分裂提高频谱利用效率及能够对抗多径等优势,众多研究者均在该系统模型下的无线资源分配算法进行了深入探索[5-6]。
在正交频分复用的多蜂窝网络资源分配上,不少研究者提出了基于计算密集型算法的方案,如拉格朗日松弛法、迭代分布式优化算法、启发式算法和拍卖/博弈论等理论[3-4]。虽然在处理小批量数据时这些方法有各自的优势,但随着现代无线网络用户数据的增多,其计算复杂度高、计算时间长、不易收敛性、缺乏动态的感知能力等缺点限制了这些算法的进一步应用和发展。一些研究者提出了强化学习(RL)的算法[12-13],如Q学习是一种基于无模型的算法,通过不断与外界环境的交互,最大化目标函数值,从而获得最优功率控制方案。但传统的强化学习算法中,由于需要大量存储空间对各状态和动作进行存储,导致在面对连续状态和高维动作空间时性能表现急剧下降,尤其对于无线通信网络这样数据结构复杂且数据量巨大的对象而言并不可行。深度学习在计算机视觉、自然语言处理和其他一些应用方面取得了巨大的成功。最近的研究结果表明,深度学习由于其计算度复杂度低和低延时等特点已成为一种很有前途的解决无线通信资源问题的工具。其中,一些研究者提出了有监督的深度学习资源分配方法[8],训练数据大多通过人工蜂群算法、遗传算法、蚁群算法等传统的启发式算法生成,但训练数据的生成需要大量的计算时间,且计算复杂度较高。所以对于大型网络系统而言,有监督的深度学习算法并不是最佳选择。
因此,深度强化学习(DRL)逐渐成为一种解决复杂控制问题的热门技术[14-20],主要特点有以下三个方面:(1)DRL巧妙的将深度学习感知能力出众的特点同强化学习决策能力突出的特点相结合;(2)DRL通过反复试验的方式不断地与外界环境相互作用;(3)DRL通过反复迭代训练来最大化累积奖励,从而获得最优策略。文献[20]提出了基于深度强化学习的在线计算卸载算法,用于解决基于区块链的移动边缘计算问题。
受此启发,本文提出了一种深度Q网络(DQN)来解决全频复用多蜂窝网络的资源分配问题。在所提出的DQN算法中,同时实现了信道资源分配方案和功率控制资源分配方案,从而提高了通信系统的能源效率。在所提出的DQN算法中,每次动作后得到的环境状态为每个信道分配的功率。相比之下,动作包括信道分配方案、每个信道分配的功率以及相应的功率调整量,同时将能量效率设为奖惩值。仿真结果表明,与传统的人工蜂群算法,贪婪分配算法,随机分配算法相比[21-22],本文提出的DQN算法可以确保低计算延迟的同时,可获得接近于或高于其他方法的能量效率,且蜂窝网络规模越大,该算法优势越突出。
1 系统模型
本文所研究的通信模型是正交频分复用技术下的多蜂窝网络系统模型(图1)。该模型主要由3个基本要素组成:基站(小区)、用户和信道资源。每个小区有且仅有1个基站,位于该小区的中心,设有个基站(小区);用户则随机分布在各个小区内,每个小区内的基站均覆盖该小区的用户,设所有小区共有个用户;信道资源则表示基站和用户之间的通信方式,均为单天线系统,并且信道资源在小区内是满足正交频分复用,每个小区内的每个信道只能分配给一个用户使用,设有个信道。现已知每个信道的带宽为、噪声谱密度为0;每个用户仅将位置信息通过导频信号传输给中心控制节点,中心控制节点可采用式(1)对信道增益进行建模和估计[5]:
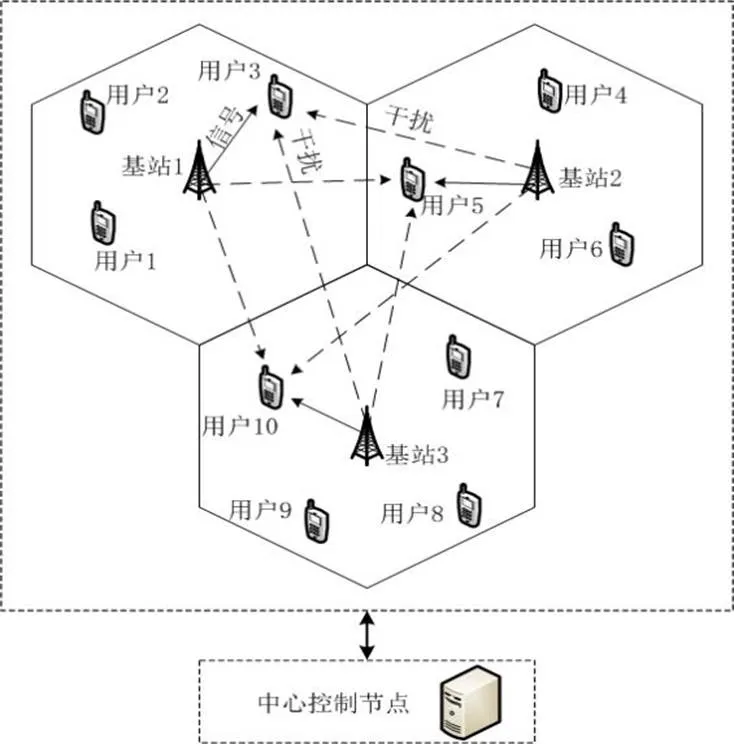
图1 集中式多小区全频复用系统模型

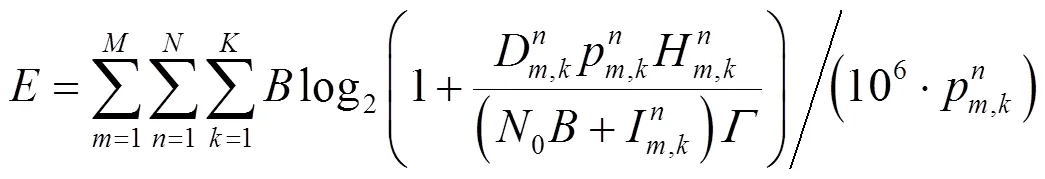
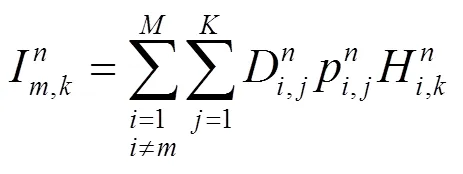
本文将优化目标表示为能量效率的期望以有效地降低能耗。与其他约束优化模型不同,为了保证全频复用的有效性,本文对信道传输所需的最低功率进行了约束,并通过考虑基站的总传输功率约束,将全频复用的多小区蜂窝网资源分配问题建模成如下的约束优化问题P1:
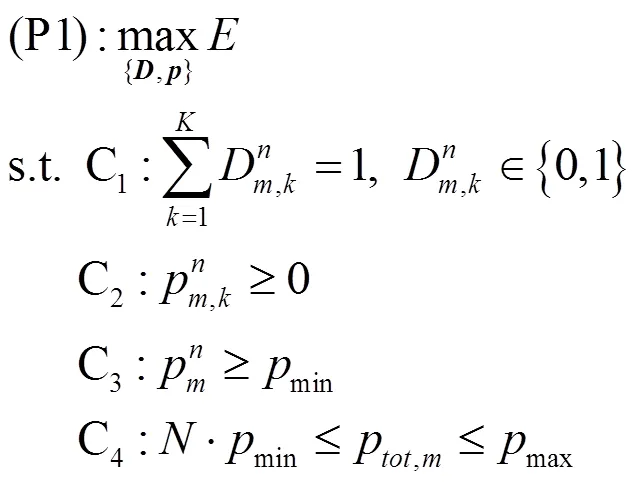
上述约束优化问题P1是一个NP-hard问题,传统方法难以通过量化进行最优方案的选择,且具有计算量大、复杂性高、计算延迟高等缺点。尤其面对本文研究的多蜂窝网络模型,具有环境信息实时变化、数据结构复杂且数据量巨大等特点,传统方法并不是最佳选择。因此本文提出了适用于环境实时动态变化、擅长处理大数据结构且低计算复杂度的深度强化学习算法来解决此约束优化问题。
2 基于深度强化学习的资源分配方法
深度强化学习是深度学习和强化学习的结合,其基本框架与强化学习基本保持一致,均包含四个基本要素:智能体的状态集合、动作集合、奖励信号及智能体的策略。利用了深度学习的感知能力,来解决策略和值函数的建模问题,然后使用误差反向传播算法来优化目标函数;同时利用了强化学习的决策能力,来定义问题和优化目标。通过设置合理奖惩机制,智能体经过神经网络的反复训练,不断的与外界动态环境保持交互,这样将深度学习的感知能力与强化学习的决策能力完美结合。最终在连续的迭代训练中,不断与外界环境交互来更新策略并接近智能体的行为目标函数,最大化奖惩值,获得最优的分配方案。因此本文提出深度强化学习算法中的深度Q神经网络(Deep Q-Network, DQN)来求解OFDM多蜂窝网络系的通信资源分配问题。
2.1 Q-Learning强化学习
对于一个密集且环境实时变化的多蜂窝网络中,通过不断地与外界环境交互是掌握收集无线通信资源最直接有效的方法。强化学习的主要目标是通过在每次动态的训练环境下最大化目标函数,进而找到最优策略。智能体通过环境反馈回的奖励信息来判断系统性能的优劣,并在不断地与环境的交互训练中提升系统的性能,最终得到最优的控制策略。

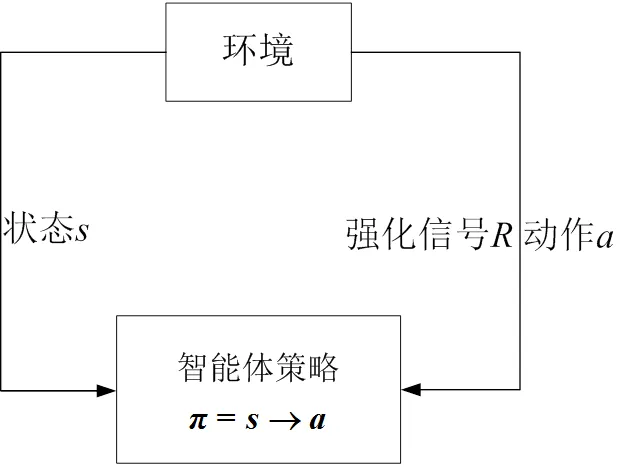
图2 强化学习基本框架

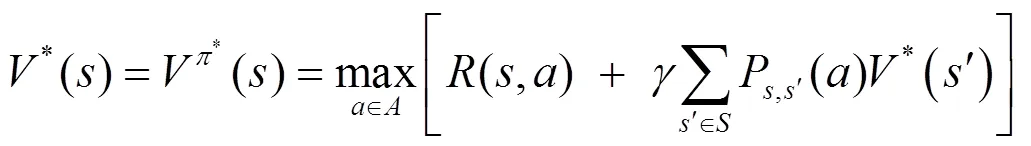
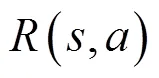

由式(6)和式(7)可得最优动作策略:
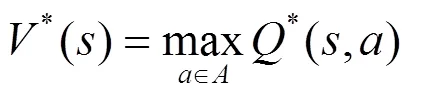
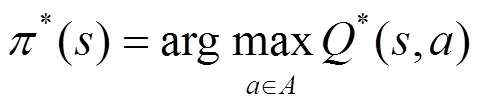
在Q学习的迭代算法中,智能体通过迭代训练逐渐接近下一状态的动作价值函数,如式(10)所示:

2.2 深度强化学习基本框架

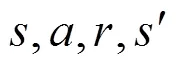
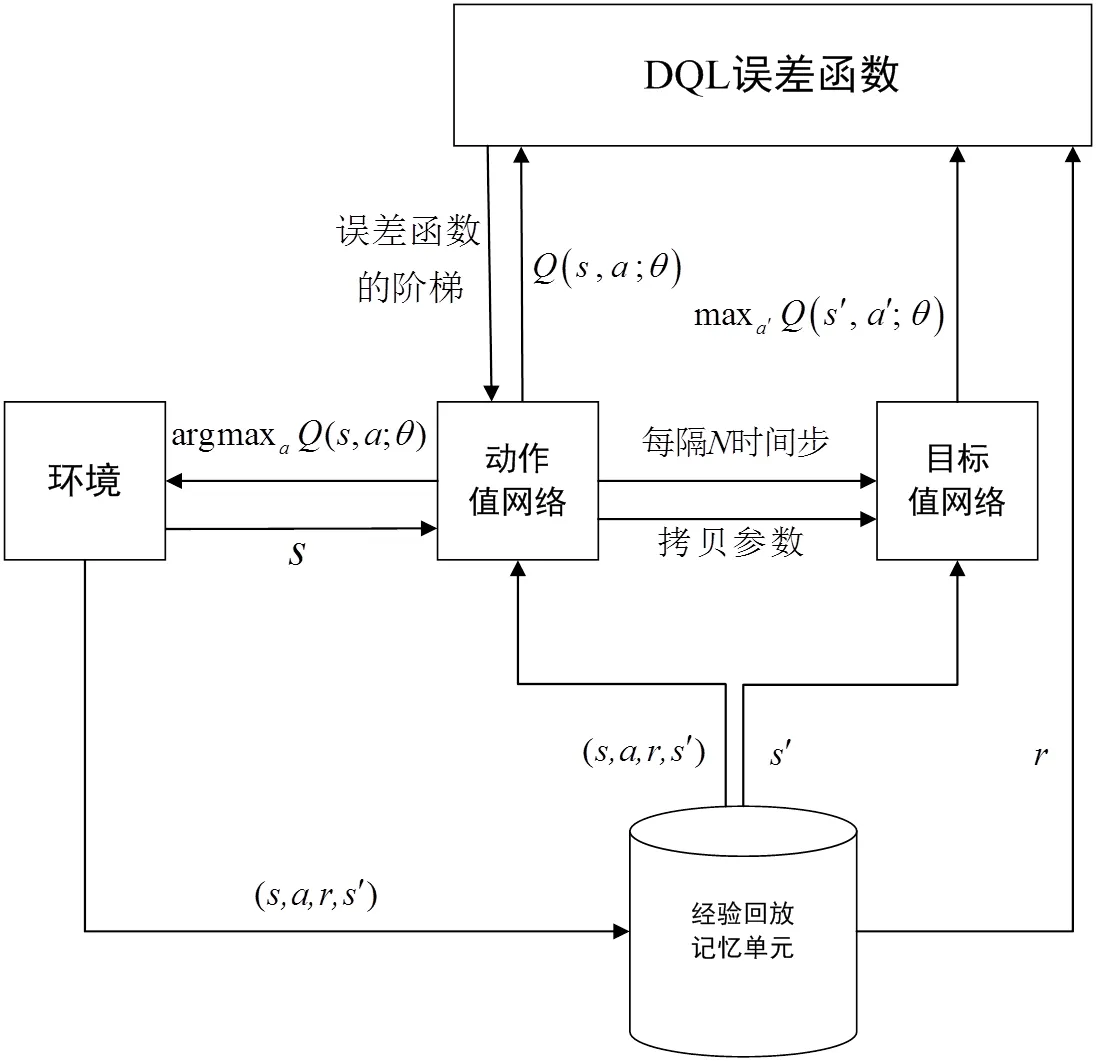
图3 深度强化学习算法基本框架
2.3 问题映射和网络模型
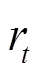

通过不断的迭代训练来对动作状态值函数进行更新,具体更新流程如下:

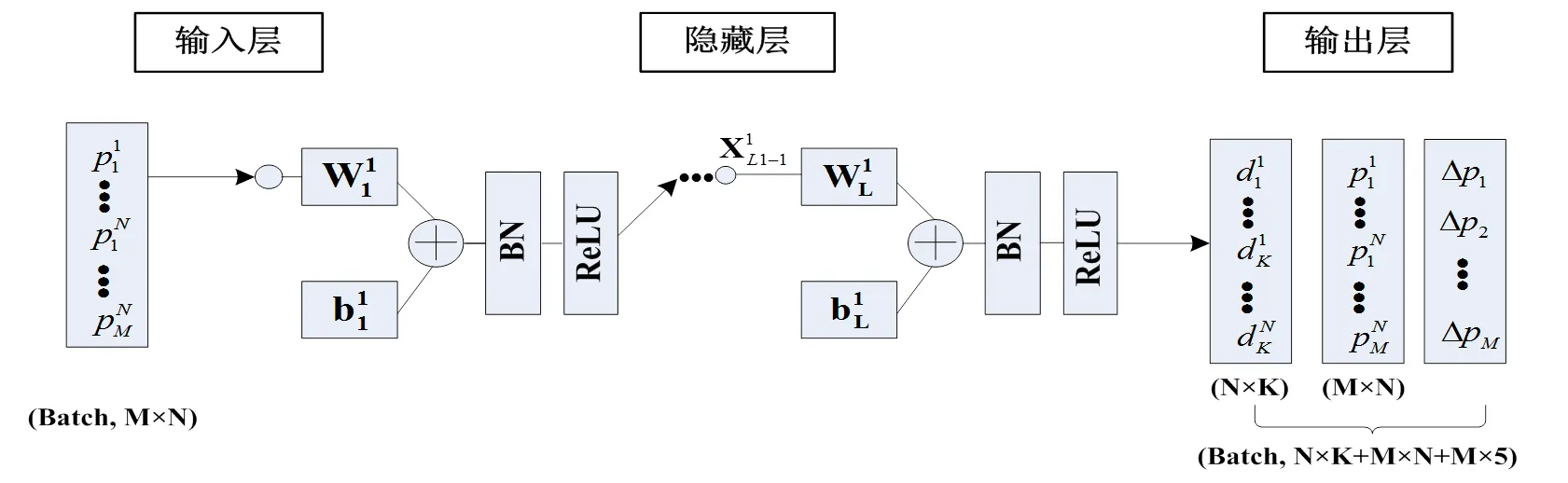
图4 神经网络结构
2.4 算法流程



为了提高数据的更新频率,同时保证训练更加平稳高效。首先,在每一个时间步获得数据后均经过神经网络的训练,更新网络参数以便为下一个动作提供更好的策略选择。其次,采用随机抽样的方式对数据进行训练,这样可以更好的应对环境实时变化的特点,减少样本之间的关联性。另外,通过强化学习的经验回放技术,减少了参数在训练中可能出现的震荡或者发散现象,使得学习训练过程更加平滑稳定。
3 仿真与分析
本节通过仿真实验对深度强化学习算法在解决无线通信的功率控制问题上进行评价和分析,其中采用文献[5]所用的噪声方差作为本节的高斯白噪声参数;采用文献[6]所用的参数作为本节仿真的阴影衰落和多径衰落,分别服从对数正态分布和指数分布。具体参数如表1所示。

表1 蜂窝网络仿真参数
本文分别在两种不同规模的蜂窝网络下仿真比较了各算法的能量效率及计算延时。蜂窝网络规模如表2所示。

表2 蜂窝网络规模
本文通过Pytorch来实现提出的算法,由表1中的基站数()、移动用户数()和信道资源数(),通过反复实验确定了×180(FC-BN-ReLU)120(FC-BN-ReLU)80(FC-BN-ReLU)×+×+5×的神经网络结构。本文在进行深度强化学习训练时,由反复实验确定了经验池大小为64,太大会导致无用的经验加入到训练中,太小会导致学习效果不充分,仿真时采用随机抽样从经验池中获取状态转换信息,为防止过度拟合,并获取更多的有效经验。训练共设置6000局,每局迭代次数为200次。
在能量效率方面,如图5, 6所示,将本文提出的基于深度强化学习的功率控制方案和传统的人工蜂群算法[21],贪婪信道分配+WWMSE功率控制算法及随机信道分配+WWMSE功率控制算法[22]进行了对比分析。
图5为#1蜂窝网规模下各算法在不同信道数下的能量效率对比,是选用50组未训练过的信道增益H作为外部环境变量,分别进行预测,取其50组能量效率的平均值。结果显示,当信道数N大于12时,DQN算法开始优于人工蜂群,且随信道数的增加,DQN算法的优势越来越明显。由图6可知,当蜂窝网规模扩大为#2规模后,小区数量和用户数量均明显增多,本文提出的DQN算法获得的能量效率无论是在信道数为4还是信道数为16时,均远高于其他传统算法的能量效率。由上述分析可知深度强化学习算法在无线通信资源较多的情况下,其资源分配优势非常明显,能显著提高传统资源分配算法的能量效率。

图5 #1蜂窝网规模下各算法在不同信道数下的能量效率

图6 #2蜂窝网规模下各算法在不同信道数下的能量效率
在计算延时方面,如图7所示,本文提出的DQN信道分配和功率控制算法所耗费为的计算时延仅为10-3秒数量级左右,计算速度高于其他算法。同时,由表3各算法的理论计算复杂度分析可知,迭代次数是影响人工蜂群算法、Greedy/Random -CA+WMMSE-PC算法计算复杂度的一个重要因素,因而也是增加算法计算时延的主要原因。所提出的深度强化学习能够按批进行在线推断,其计算时延主要由矩阵相乘产生。与人工蜂群算法、Greedy/Random-CA+WMMSE-PC的复杂迭代计算相比,矩阵相乘调用了高度优化的BLAS(basic linear algebra subroutine),使得矩阵相乘具有远高于迭代运算的计算效率。故DQN在资源分配方面反应更迅速,且在信道数较多时,能得到更高的能量效率。
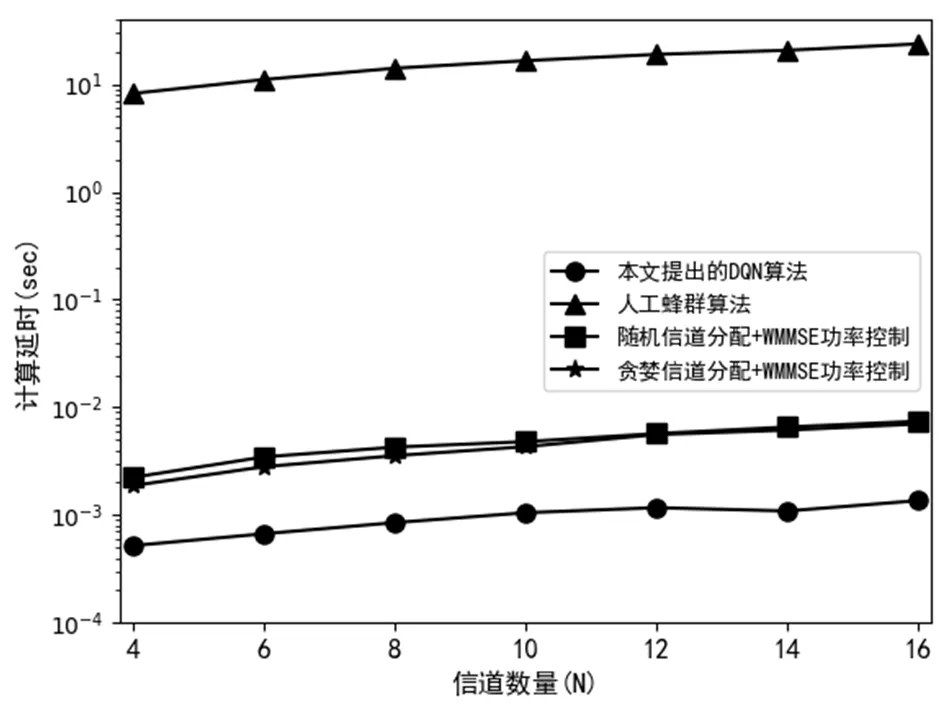
图7 各算法的计算时延

表3 各算法的理论计算复杂度
注:DQN-hidden1是DQN第一个全连接隐层的神经元数量、CA-hidden1是ULDNN-CA第一个全连接隐层的神经元数量、foods是人工蜂群的蜜源总数、是人工蜂群或WMMSE的迭代次数
4 结束语
为了提高新一代蜂窝网络的能量效率,同时减少计算延时,本文提出了一种基于深度强化学习的蜂窝网络资源分配方法,通过对信道分配和功率控制的神经网络进行深度强化学习,最终得到最佳资源分配方案,最大化系统的能量效率。仿真结果表明,在正交频分复用的多蜂窝网络模型下,本文提出的基于深度强化学习的资源分配方法在保证较低计算时延和低功耗的同时,能够找到优于传统算法的无线通信资源分配方案,且蜂窝网络规模越大,该算法优势越突出。
[1] HE X M, WANG K, HUANG H W, et al. Green resource allocation based on deep reinforcement learning in content-centric IoT[J]. IEEE Transactions on Emerging Topics in Computing, 2020, 8(3): 781-796.
[2] 孙明,曹伟,李大辉,等. 保证公平的最大化OFDMA系统容量策略[J]. 控制与决策,2020, 35(05): 1175-1182.
[3] 汪照,李有明,陈斌,等. 基于鱼群算法的OFDMA自适应资源分配[J]. 物理学报,2013, 62(12): 509-515.
[4] TAKSHI H, DOGAN G, ARSLAN H. Joint optimization of device to device resource and power allocation based on genetic algorithm[J]. IEEE Access, 2018, 6: 21173-21183.
[5] 孙明,王淑梅,郭媛,等. 基于深度无监督学习的多小区蜂窝网资源分配方法[J]. 控制与决策,2022, 37(09): 2333-2342.
[6] 周凡,王鸿,宋荣方. 密集异构蜂窝网络中基于深度强化学习的下行链路功率分配算法[J]. 南京邮电大学学报(自然科学版),2021, 41(02): 12-19.
[7] LIANG F, SHEN C, YU W, et al. Towards optimal power control via ensembling deep neural networks[J]. IEEE Transactions on Communications, 2020, 68(3): 1760-1776.
[8] LEE W, KIM M, CHO D. Transmit power control using deep neural network for underlay device-to-device communication[J]. IEEE Wireless Communications Letters, 2019, 8(1): 141-144.
[9] LIU D, SUN C J, YANG C Y, et al. Optimizing wireless systems using unsupervised and reinforced-unsupervised deep learning[J]. IEEE Network, 2020, 34(4): 270-277.
[10] AHMED K I, TABASSUM H, HOSSAIN E. Deep learning for radio resource allocation in multi-cell networks[J]. IEEE Network, 2019, 33(6): 188-195.
[11] SUN M, LEE K Y, XU Y Q, et al. Hysteretic noisy chaotic neural networks for resource allocation in OFDMA system[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(2): 273-285.
[12] FENG C W, HUANG L F, YE P Z, et al. A Q-learning-based heterogeneous wireless network selection algorithm[J]. Journal of Computers, 2014, 24(4): 80-88.
[13] SHAO G, WU W Q, YIN L, et al. A network selection method based on Q-Learning in power wireless communication system[J]. Journal of Physics: Conference Series, 2019, 1302(2): 022100.
[14] CHALLITA U, DONG L, SAAD W. Proactive resource management for LTE in unlicensed spectrum: a deep learning perspective[J]. IEEE Transactions on Wireless Communications, 2018, 17(7): 4674-4689.
[15] LI X J, FANG J, CHENG W, et al. Intelligent power control for spectrum sharing in cognitive radios: a deep reinforcement learning approach[J]. IEEE Access, 2018, 6: 25463-25473.
[16] YE H, LI G Y, JUANG B F. Deep reinforcement learning based resource allocation for V2V communications[J]. IEEE Transactions on Vehicular Technology, 2019, 68(4): 3163-3173.
[17] CHOWDHURY A, RAUT S A, NARMAN H S. DA-DRLS: Drift adaptive deep reinforcement learning based scheduling for IoT resource management[J]. Journal of Network and Computer Applications, 2019, 138: 51-65.
[18] SUN M, JIN Y H, WANG S M, et al. Joint deep reinforcement learning and unsupervised learning for channel selection and power control in D2D networks[J]. Entropy, 2022, 12(24): 1722.
[19] 廖晓闽,严少虎,石嘉,等. 基于深度强化学习的蜂窝网资源分配算法[J]. 通信学报,2019, 40(02): 11-18.
[20] QIU X Y, LIU L B, CHEN W H, et al. Online deep reinforcement learning for computation offloading in blockchain-empowered mobile edge computing[J]. IEEE Transactions on Vehicular Technology, 2019, 68(8): 8050-8062.
[21] SHARMA N, ANPALAGAN A. Bee colony optimization aided adaptive resource allocation in OFDMA systems with proportional rate constraints[J]. Wireless Networks, 2014, 20(7): 1699-1713.
[22] SHI Q J, RAZAVIYAYN M, LUO Z Q, et al. An iteratively weighted MMSE approach to distributed sum-utility maximization for a MIMO interfering broadcast channel[J]. IEEE Transactions on Signal Processing: A publication of the IEEE Signal Processing Society, 2011, 59(9): 4331-4340.
[23] HE K M, ZHANG X Y, REN S Q, et al. Delving deep into rectifiers: surpassing human-level performance on imagenet classification[C]//2015 International Conference on Computer Vision, 2015: 1026-1034.
Resource allocation method for orthogonal frequency division multiplexing multi-cell cellular networks based on deep reinforcement learning
SUN Ming,HU Liang-jin,HAO Bing,YU Ying
(College of Computer and Control Engineering, Qiqihar University, Heilongjiang Qiqihar 161006, China)
This paper proposes a resource allocation method for orthogonal frequency division multiplexing(OFDM) multi-cell cellular networks based on deep reinforcement , which generates both channel allocation schemes and power control schemes to maximize the energy efficiency of the system while satisfying the high speed and low latency requirements for resource allocation. First, the constrained optimization problem of maximizing the energy efficiency of the system is mapped to a deep Q reinforcement learning algorithm based on a model of an orthogonal frequency division multiplexing multicellular network system. Second, multiple hidden layers of the constructed deep Q neural network (DQN) are used as state value functions to output channel allocation schemes and power control schemes, and interact with the external environment in real time to continuously iteratively update the network parameters to maximize the system energy efficiency. Finally, by comparing the simulation experiments, the proposed deep reinforcement learning algorithm can obtain a system energy efficiency close to or higher than the other algorithms while ensuring the low computing delay, and the larger the cellular network scale, the more prominent the advantages of the algorithm are.
deep reinforcement learning;OFDM;cellular networks;resource allocation;neural network
2022-09-06
黑龙江省自然科学基金(LH2019F038);黑龙江省省属高等学校基本科研业务费科研项目(135509114)
孙明(1979-),男,山东海阳人,教授,博士,主要从事深度学习研究,snogisunming@163.com。
TP181
A
1007-984X(2023)01-0005-08
