新浪微博地震舆情数据库的设计与实现1
2023-03-01陈亚男熊政辉
陈亚男 薄 涛 王 洋 王 喆 高 爽 熊政辉
1)北京市地震局, 北京 100080
2)中国地震应急搜救中心, 北京 100049
3)中国地震局地球物理研究所, 北京 100081
4)联通数字科技有限公司, 北京 102600
引言
地震发生后的首要任务是准确高效地开展地震应急处置、维护正常社会秩序并保障人民生命财产安全(闪淳昌等,2012)。地震灾情舆情信息的收集是决策者制定有效应急指挥方案重要且不可替代的基础(何晶,2012;郁璟贻等,2018)。近年来,随着互联网技术的快速发展,地震发生后,社交媒体涌现出了大量的地震舆情信息,这些信息实时海量高效地反映了灾区的真实情况,为震后72 h 黄金救灾救援提供重要的应急服务支持(聂高众等,2012)。随着地震舆情在应急中受重视程度不断加深,研究者对震后社交媒体舆情数据开展了一系列的研究工作,并结合实际需求进行了综合利用,有利于应急期震后信息的获取与共享、灾情舆情的快速研判及政府的应急救援决策(褚俊秀等,2016;曹彦波等,2017a;薄涛等,2018)。在地震舆情数据获取挖掘方面,杨菁等(2014)通过对雅安地震后不同时间节点的新浪微博数据的统计分析,探索地震发生后微博舆情结构主体及其应急反应特征。王艳东等(2016)基于新浪微博文本数据,探寻不同主题下突发事件随时间的发展趋势并分析可能的影响。徐敬海等(2015)、褚俊秀等(2016)提出了基于地震应急期新浪位置微博的提取方法,分别以永善5.0 级地震、鲁甸6.5 级地震为例进行应用。曹彦波等(2017a,2017b,2018)分别对景谷6.6 级地震、九寨沟7.0 级地震、云南省通海县2 次5.0 级地震的新浪微博开放平台API 数据进行了清洗挖掘与时空演变规律分析。李亚芳等(2020)运用网络爬虫技术,对新疆伽师6.4 级地震后48 h 内发布的新浪微博文本数据进行了舆情信息分析及可视化研究。刘婉婷等(2021)基于新浪微博数据,运用网络爬虫技术,获取西藏自治区那曲市比如县6.1 级地震震后24 h 及震后7 d 的相关微博及评论,对数据进行清洗和预处理,并进行时空特征分析,实现微博舆情数据的可视化表达。刘耀辉等(2022)以2021 年云南漾濞6.4 级地震为例,基于新浪微博数据,结合热搜词条的变化趋势,研究此次地震事件中网络舆情的时空扩散特征、民众情绪反应特征及可视化结果呈现。
由上述研究可知,现阶段震后舆情数据挖掘及舆情信息情感分析虽取得一定进展,但大多数研究者仅针对单次地震的数据开展挖掘分析,缺乏系统全面的社交媒体地震舆情数据库。从大量、不完全、有噪声、模糊、随机的社交媒体数据中提取有价值的地震舆情数据加以分析及利用具有重要意义。薄涛(2018)以2010-2018 年破坏性地震为研究对象,建立了我国大陆地区首个基于社交媒体平台的破坏性地震灾情数据库,但该数据库主要收集的是历史数据,无法对实时发生的地震自动进行数据获取与存储,在数据完备性上也与实际需求存在一定差距。为此,本文选取新浪微博移动端作为数据源,对接EQIM(Earthquake Instant Messager),建立准实时新浪微博地震舆情数据库,对2021 年1 月1 日以来我国大陆地区3.0 级及以上地震实现舆情数据的准实时获取、加工与入库,数据库的准实时功能和预处理技术提升了使用效率与数据完备度,为后续的舆情监控与灾情研判工作提供了数据支持。
1 数据获取与预处理
1.1 震后微博舆情数据准实时获取
目前常见的新浪微博地震舆情数据获取方式有微博开放平台API、网络爬虫、数据源镜像及开放数据平台,对上述方法原理及优缺点进行了梳理,如表1 所示(袁浩,2009;廉捷等,2011;刘晓娟等,2013;游翔等,2014;杨飞等,2016)。其中,作为官方途径获取数据的新浪微博开放平台API 和不受身份验证限制的网络爬虫最为常用。

表1 微博数据获取方法Table 1 Data acquisition methods of Weibo
震后对于以新浪微博为代表的社交媒体平台进行数据获取,其需求主要来自于两方面,即舆情监控与灾情研判。获取的微博数据在满足全面性和高效性的基础上,对距极震区较近区域的时空数据有较高需求,以反映舆情影响范围,因此在舆情数据精准性的要求上较高。单一的新浪微博地震舆情获取具有一定局限性,难以满足日益增长的数据需求。因此,本文通过新浪微博开放平台API 与分布式网络爬虫相结合的方式获取我国大陆地区新浪微博地震舆情数据,保证数据可高效、全面与稳定获取。
对于获取途径,微博信息读取接口与EQIM 接口对接,地震发生后,EQIM 触发,地震三要素信息推送进入微博信息读取接口,自动创建地震事件,实现微博地震舆情数据准实时获取。依据关键词检索方法,调用微博全量数据接口与地震局官方微博客户端数据接口(其中微博全量数据检索设定查询关键词为地震、震、摇、晃、摇晃、振动等,地震局官方微博评论检索包含中国地震台网中心及各省地震局官方微博ID,设定查询关键词为地震发震时间、地震发震地点等),获取震后72 h 内的微博地震舆情数据,并对地震舆情数据进行预处理和结构化加工。在获取过程中,通过分布式网络爬虫,爬取微博开放平台API 接口中无法获取的微博用户信息,并将信息存入数据库中,实现微博地震舆情数据的全量检索。数据获取流程如图1 所示,通常情况下,新浪微博地震舆情数据库在震后15 min 内完成数据的检索下载及入库工作。
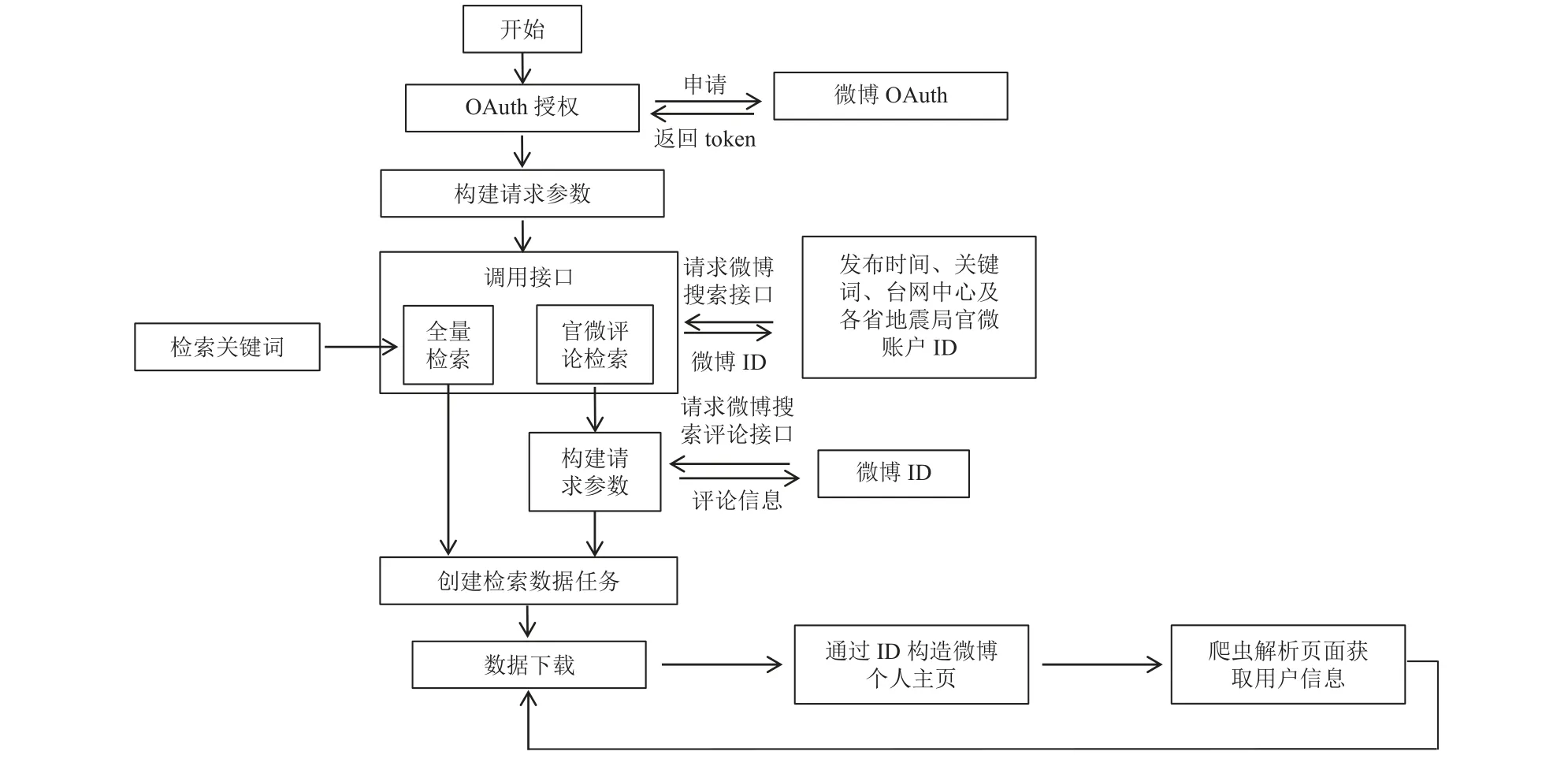
图1 新浪微博地震舆情数据获取流程Fig.1 Weibo earthquake public opinion data acquisition flowchart
1.2 数据清洗与预处理
由于微博平台具有大众化、不受时空限制、灵活度较高等特点,用户在发表微博过程中会发送如网址HTML 标签、话题标签、无用的表情符号、不相关内容等噪声数据,这些噪声数据对文本的分词和词频统计均会造成影响,因此需对下载数据中无意义的信息进行数据清洗与预处理,流程如图2 所示。在处理过程中,将微博全量数据检索与地震局官方微博检索中重合的ID 值数据自动剔除,实现重复文本数据的单一提取。对于数字、符号、无用网址、表情等无关文本内容数据,使用正则表达式进行清洗与删除,提取文本内容。对于地震相关性准确分类,由于传统方法依靠机器学习模型,通过分析字符的统计特征达到分类和识别是否与地震相关的目的,难以实现地震相关性的准确分类。因此,本文提出基于fastText 模型的地震相关性识别方法,通过预处理和词嵌入将社交媒体文本转化为多维词向量,经过隐藏层对词向量进行叠加平均,通过输出层输出特定的目标类别,流程如图3 所示。该模型在训练过程中模拟fastText 的标准3 层架构,依次使用词嵌入层、一维全局平均池化层和全连接层拼接成最终的分类模型。
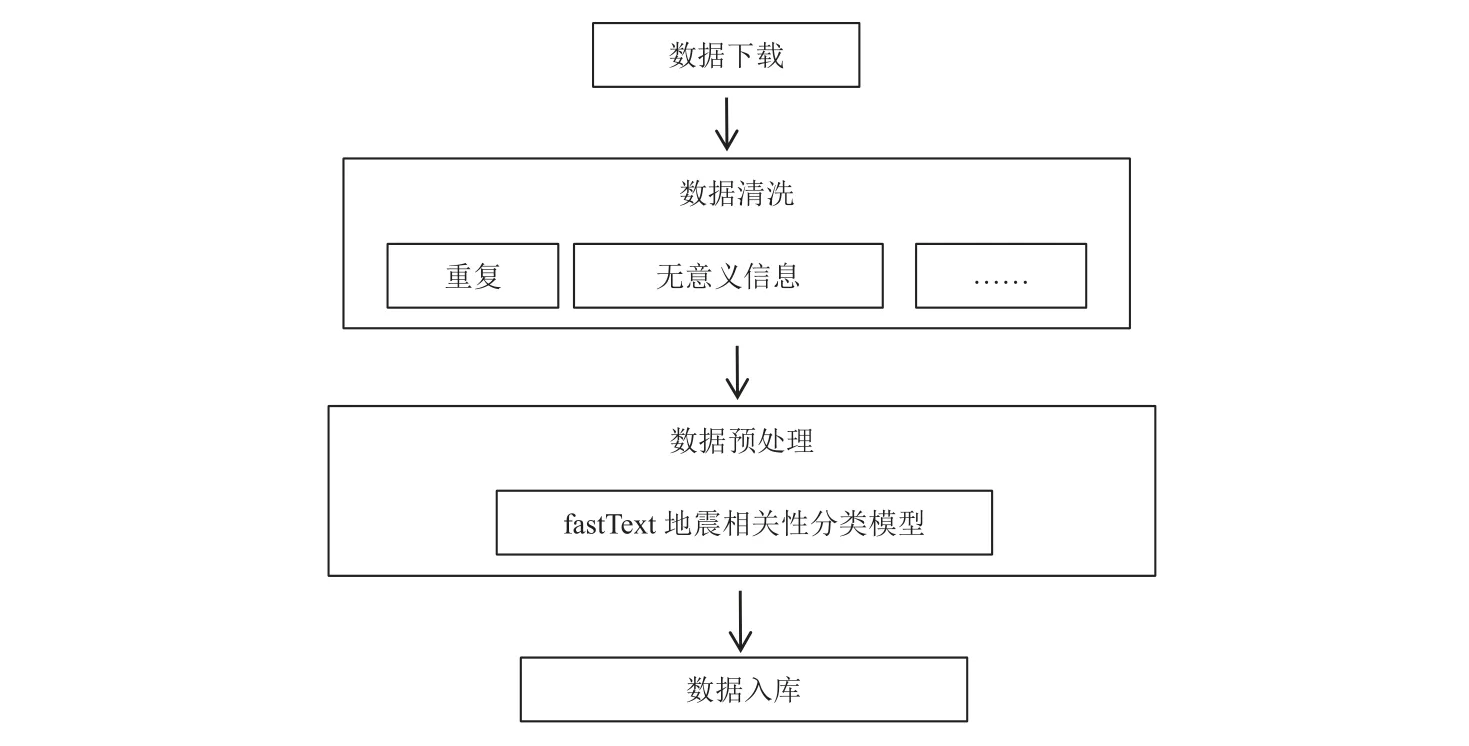
图2 数据清洗与预处理流程Fig.2 Flow chart of data cleaning and preprocessing
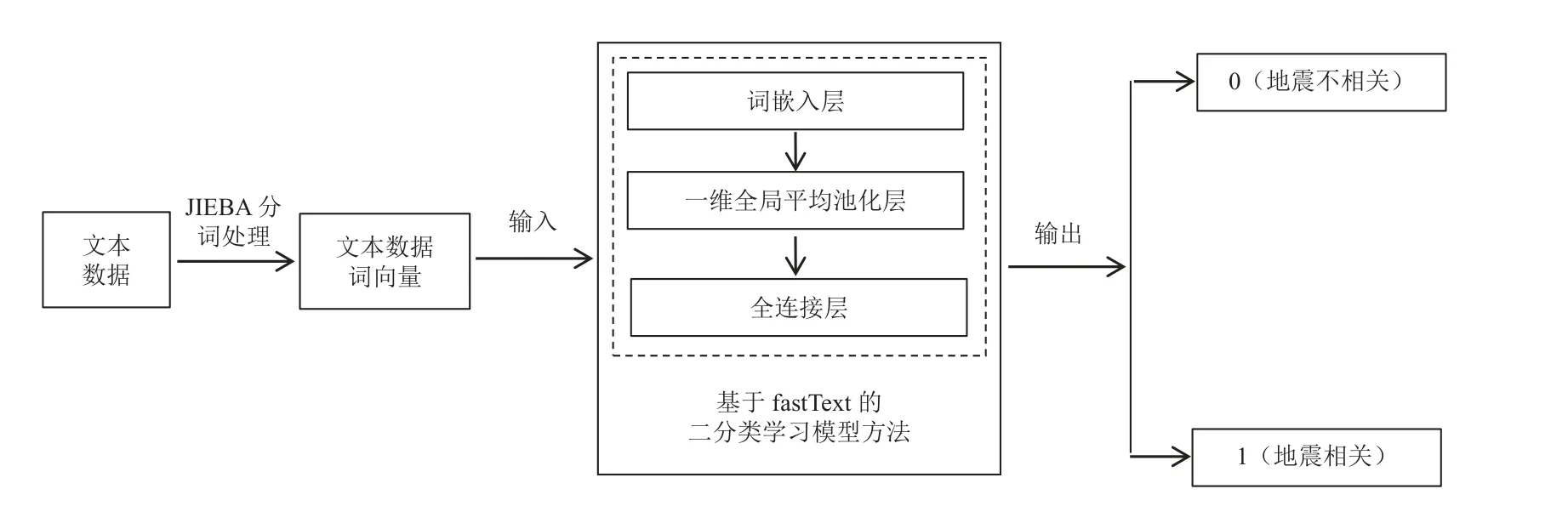
图3 基于fastText 的地震相关性二分类学习模型Fig.3 Seismic correlation dichotomous learning model based on fastText
本文训练文本数据采用薄涛(2018)建立的我国大陆地区破坏性地震社交媒体灾情数据库中的数据,随机抽取2010-2018 年12 000 条文本数据(其中训练集8 000 条,测试集4 000 条),对12 000 条数据使用python 中的JIEBA 分词进行微博文本数据分词处理操作。词向量采用预训练的中文维基百科词向量,每个词向量维度为300。基于fastText 的地震相关性分类模型方法对训练集数据进行二分类,将与地震相关的文本数据标记为1,将与地震不相关的文本数据标记为0,随后用测试集数据进行验证。
在持续不断的文本数据入库后,数据量持续增多,数据库中会有大量不相关的数据积累,因此通过更多的训练次数和更大的学习速率对文本分类模型进行持续迭代优化。提升准确率流程如图4 所示,具体方法如下:①增加每个训练用例的重复使用次数,目前fastText 在训练期间对每个训练用例仅重复使用5 次,对于8 000 条训练样例而言稍少,因此通过增加每个样例的使用次数提高模型质量;②改变模型学习速度,良好的学习率为0.1~1.0,可通过测试得到更优的学习速率,进而提高模型能力;③提升训练速度,目前几千个示例模型仅需要几秒钟,但如果数据集增大、标签增多,模型训练速度会变慢,从而考虑使用分层softmax,加快训练速度,提升模型质量。经过2021 年实际震例检测,该方法预处理的文本数据准确率为79.5%,微博文本数据预处理前后结果对比如图5 所示。通过预处理可较好地解决数据冗余问题,并自动提升数据准确性。
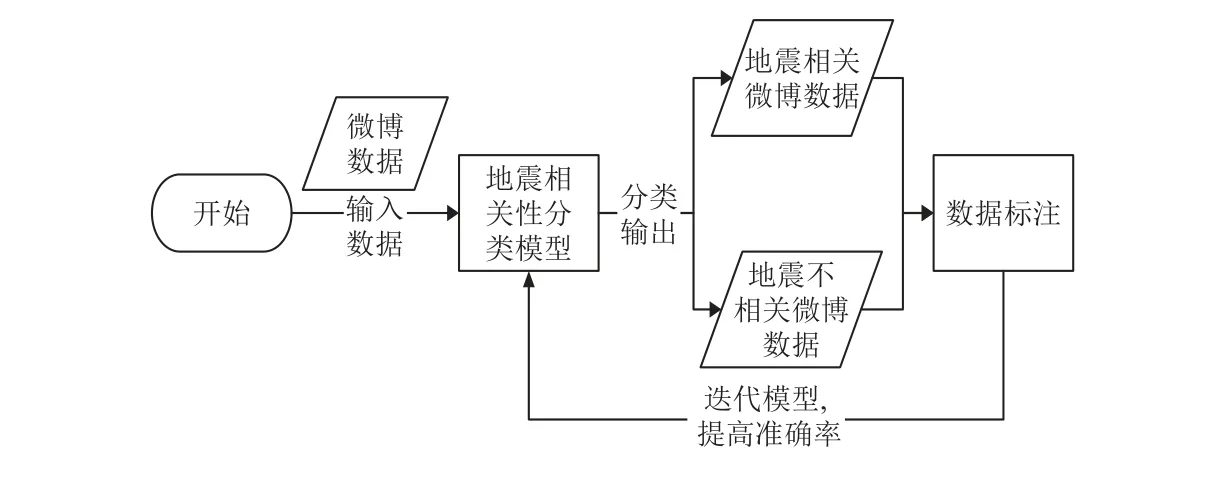
图4 迭代优化流程Fig.4 Flow chart of iterative optimization

图5 微博文本数据预处理前后结果对比Fig.5 Comparison of results before and after processing of Weibo text data
2 数据库的建立
2.1 数据库整体设计
新浪微博地震舆情数据库主要应用PostGIS 地理空间数据库与MySQL 关系型数据库分别存储GIS 数据与关系数据。在逻辑上,数据库的总体设计划分为主体数据库与元数据库,主体数据库主要包含微博评论数据、实时微博数据、地震事件数据、数量统计数据和系统运行数据,建设逻辑如图6 所示。在数据表的设计上,主要包含微博内容和用户关系两部分。数据字段包含地震事件、微博用户、微博内容等14 个字段,具体字段属性如表2 所示。其中,数据库的唯一标识为微博唯一标识码,字段名称命名依据数据库名称缩写、习惯名称与下划线组合的方式进行。
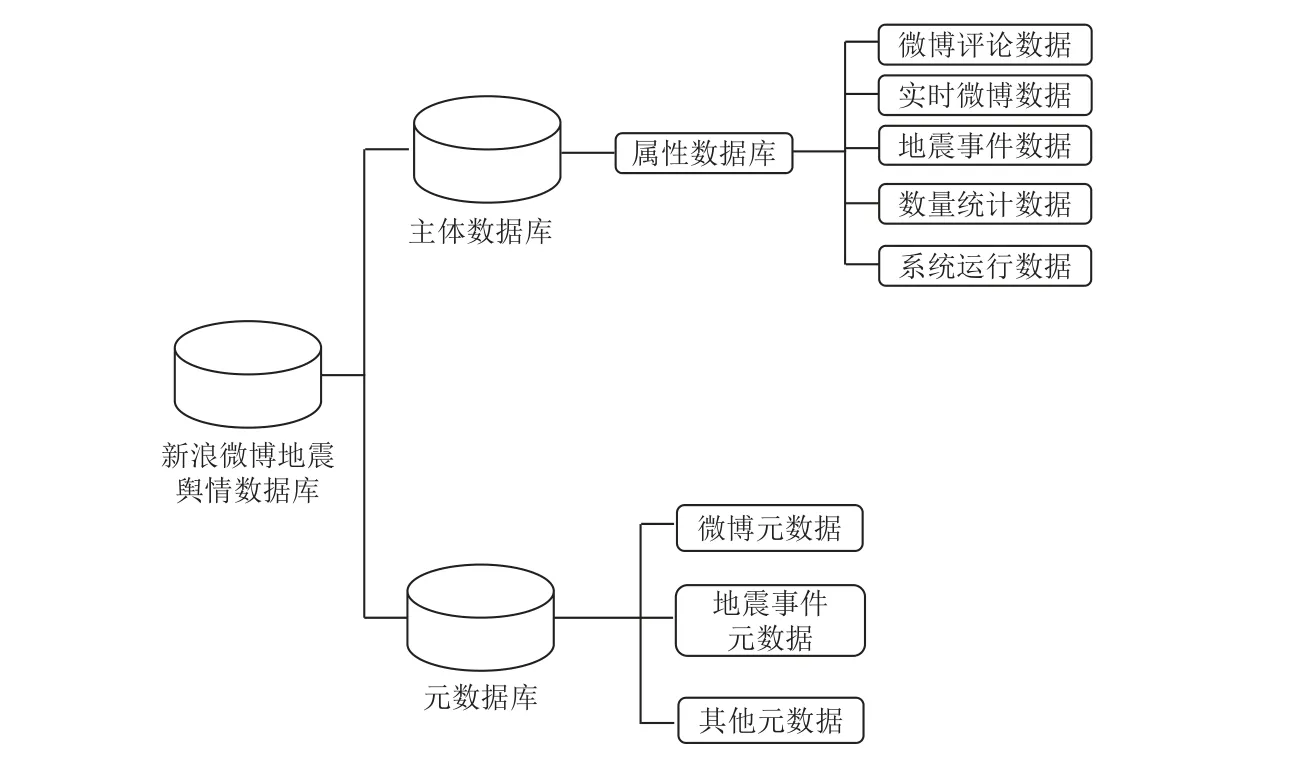
图6 新浪微博地震舆情数据库建设逻辑Fig.6 Concrete construction logic diagram of Weibo earthquake public opinion database
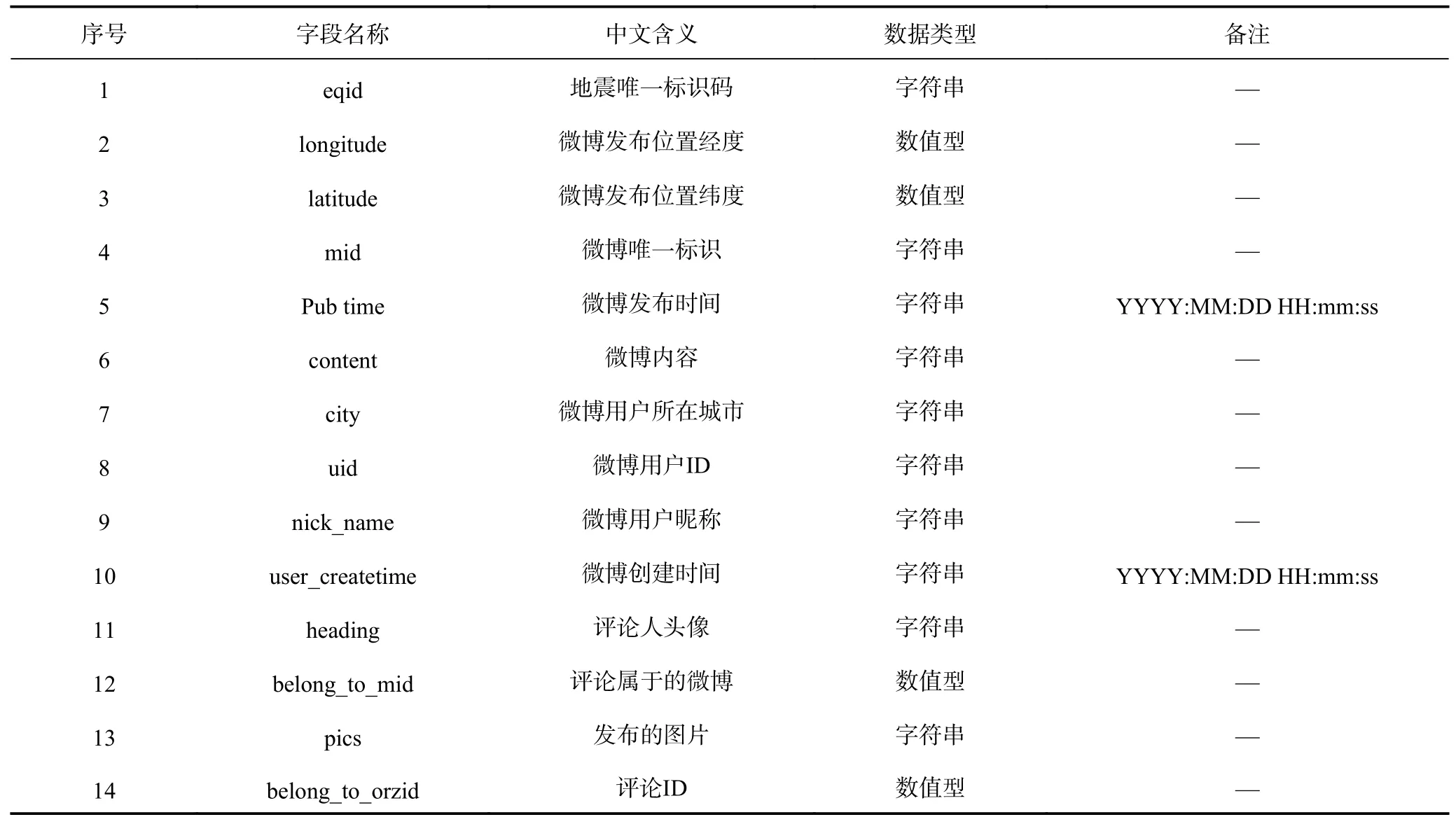
表2 新浪微博地震舆情数据库字段属性Table 2 Field attribute table of Weibo earthquake public opinion database
为方便数据查询与管理,采用阿里云平台,建立了Web 端新浪微博地震舆情数据库及管理平台(图7),设计了快速查询、精准查询及数据下载模块。其中,快速查询模块基于时间与震级进行标签式快速检索;精准查询模块基于发震日期、经纬度、震级、发震地点、震源深度等多维参数进行精准检索;数据下载模块中的数据通过JSON 格式请求调用,具体数据列表可进行Excel 下载,下载结果包括地震事件名称、发震时间、发震位置、经纬度、震级、抓取的微博数据等。
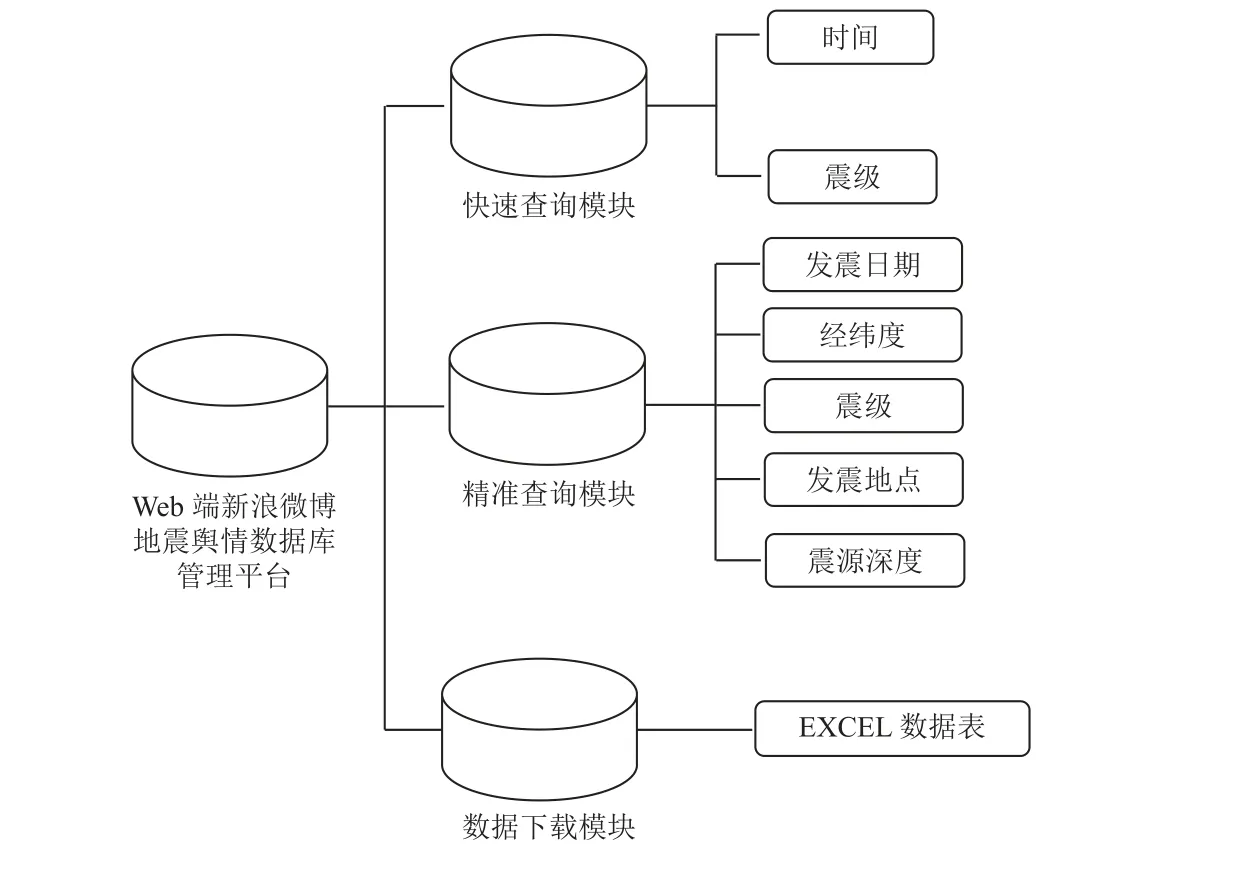
图7 Web 端新浪微博地震舆情数据库管理平台设计架构Fig.7 Design framework of Weibo earthquake public opinion database management platform on Web
2.2 数据库构建
一般情况下,当地震震级MS为3.0 级及以上时,一般人群可感受到地震的发生,故中国地震台网中心对我国大陆地区3.0 级及以上的地震实现了微博信息的自动推送,因此,本文研究对象为我国大陆地区3.0级及以上地震。通过对2021 年1 月1 日至2022 年3 月31 日我国大陆地区3.0 级及以上地震的新浪微博舆情数据进行抓取与预处理后,入库至搭建完成的新浪微博地震舆情数据库中,共包含447 次地震,共获得732 949 条地震舆情数据,如表3 所示。新浪微博地震舆情数据库使用界面如图8、图9 所示,地震发生后下载的新浪微博地震舆情事例如图10 所示。
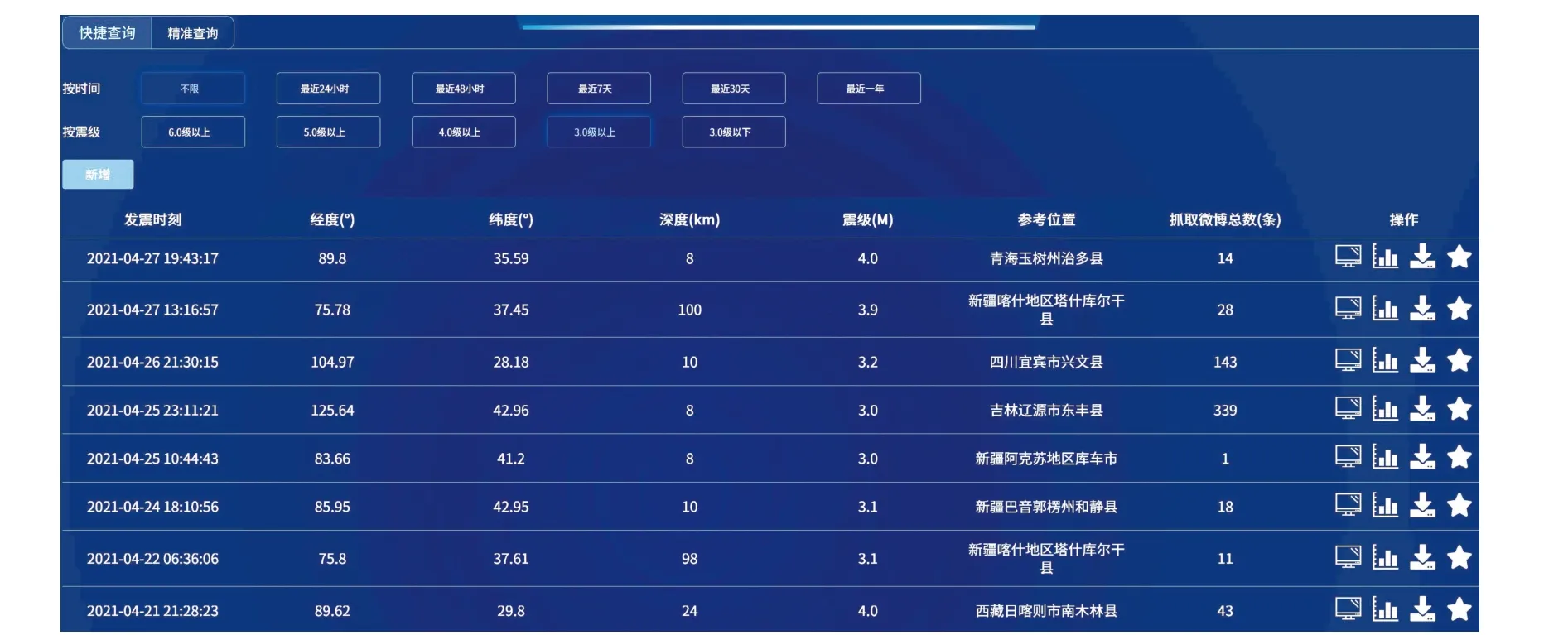
图8 新浪微博地震舆情数据库快速查询界面Fig.8 Quick query interface of Weibo earthquake public opinion database

图9 新浪微博地震舆情数据库精准查询界面Fig.9 Accurate query interface of Weibo earthquake public opinion database

图10 单次地震新浪微博地震舆情示例Fig.10 Weibo earthquake public opinion case excel display chart for a single earthquake
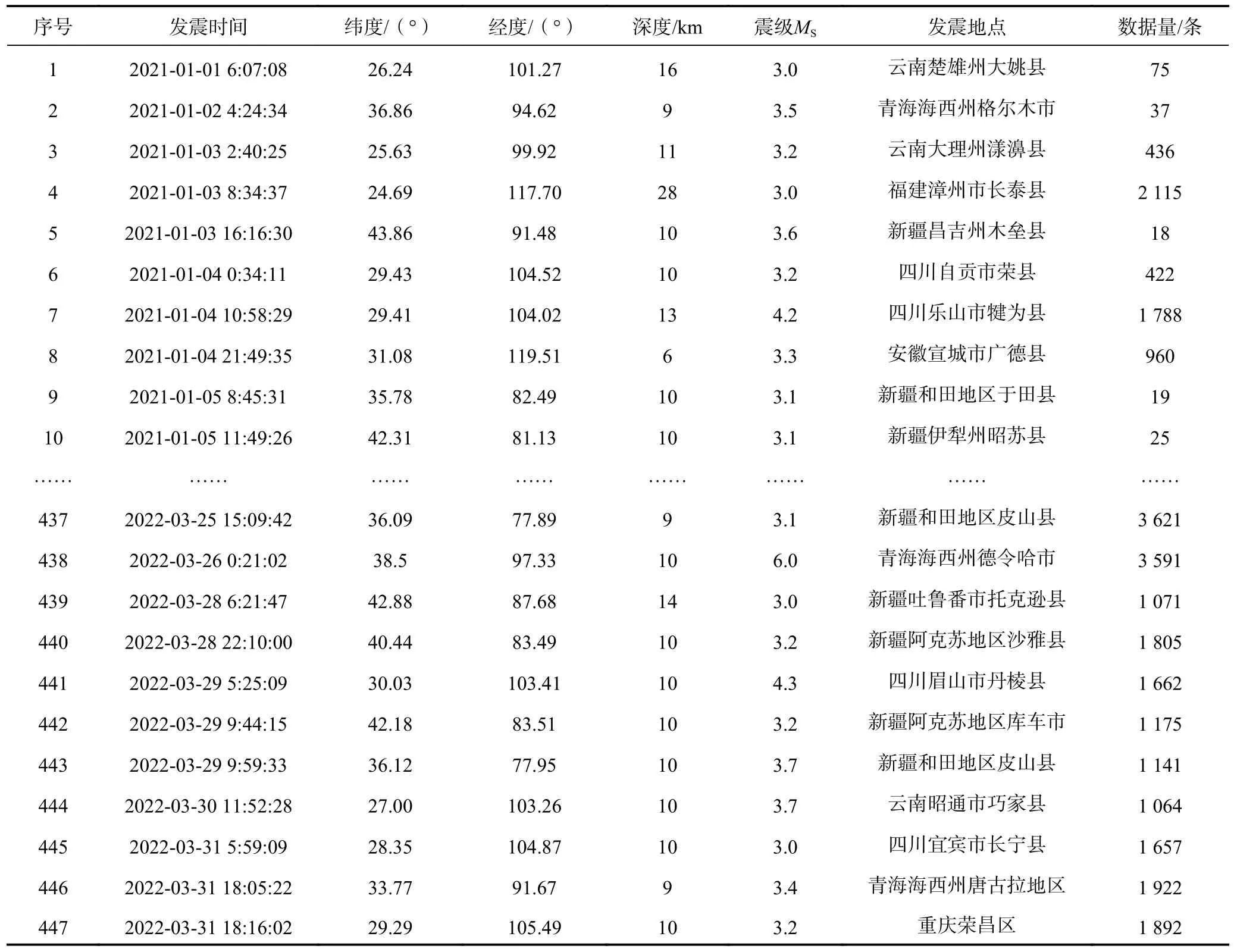
表3 部分地震舆情数据(2021 年1 月1 日至2022 年3 月31 日)Table 3 List of earthquake public opinion data catalogue (From January 1, 2021 to March 31, 2022)
3 分析与讨论
对社交媒体新浪微博地震舆情数据库中的舆情数据进行初步研究分析,得出以下结论:
(1)在时间特征方面,震后舆情信息峰值一般出现在震后2~3 h,随后关注度会逐渐降低(图11);地震舆情信息时间曲线受昼夜变化影响,峰值会出现延后现象,且曲线多呈连续U 形。在空间特征方面,对发震地为云南、四川等地的地震频次及地震微博数据量进行对比,结果表明小震发生频次高,但获取的微博数据量小,即舆情热度低;大震发生频次低,但获取的微博数据量大,即舆情热度高,说明破坏性地震在社交媒体上获得关注度较高,此类地震发生时应做好舆情管理工作(图12)。在数据方面,新浪微博地震舆情数据库中存在部分数据抓取量为0 的地震,主要位于新疆和西藏,这可能是因为该次地震发生在无人区或荒无人烟的地方,地震影响小,公众关注度低,也可能因震级过小未引起公众关注。
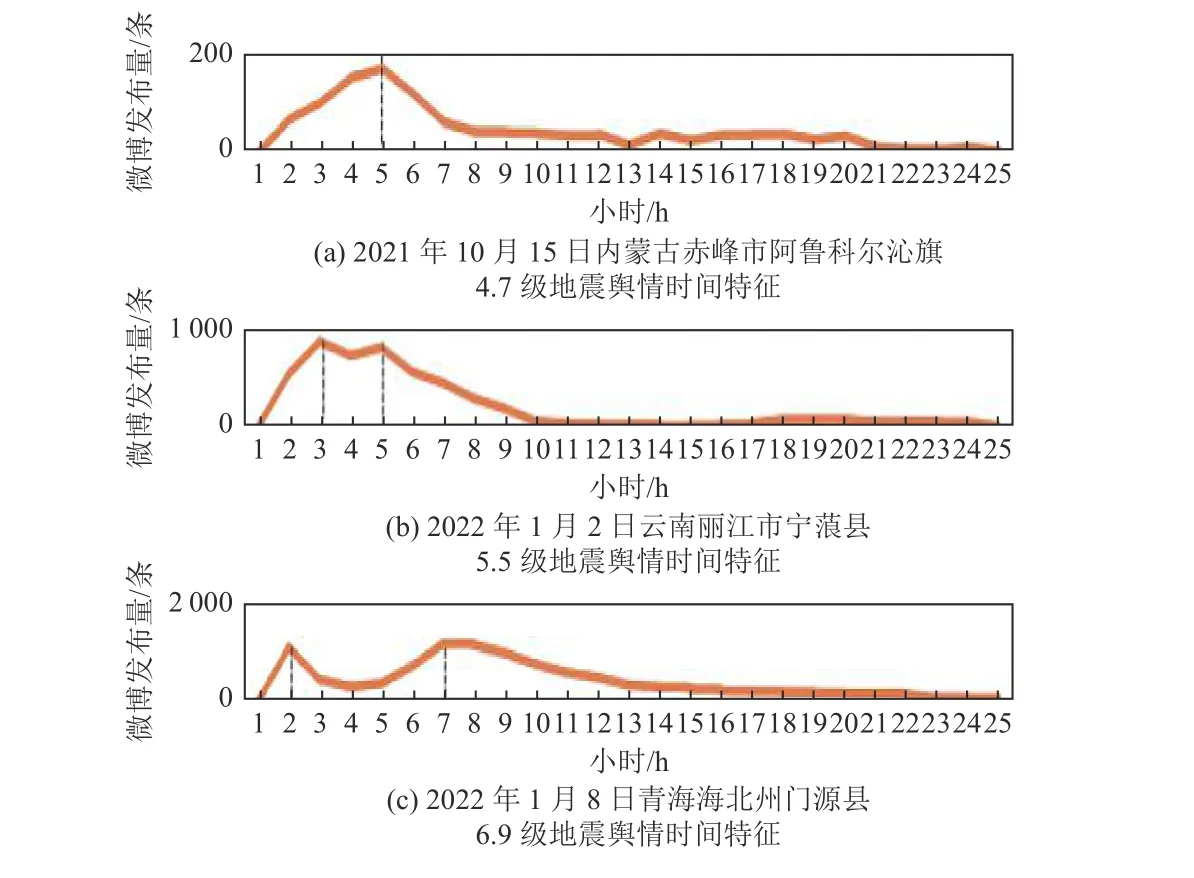
图11 地震舆情时间特征分布示例Fig.11 Example of time feature distribution of earthquake public opinion
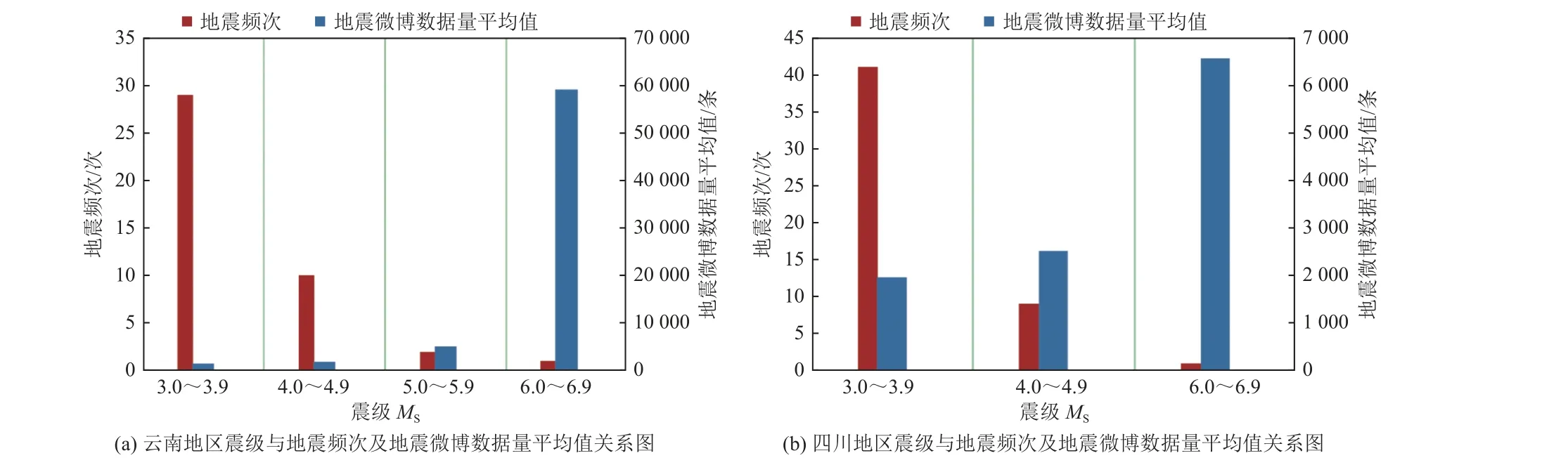
图12 云南、四川地区震级与地震频次及单次地震微博发布量关系Fig.12 Relationship between magnitude,frequency of earthquakes and Weibo release of single earthquake in Yunnan and Sichuan
(2)2021 年5 月21 日云南漾濞发生6.4 级地震,为前-主-余型地震,余震频发,在新浪微博地震舆情数据库中第一次出现地震舆情信息被划分到前震、主震及余震的多次地震事件中,实时统计到的主震舆情数据为11 960 条。经后期统计发现,此次地震事件实际共获取舆情数据59 159 条。对舆情数据进行挖掘分析时,时空特征分析等具有一定难度,云南漾濞地震发生后,笔者所在研究团队及时进行了数据获取策略变更,将同一发震地区震后72 h 内的舆情信息全部归置到首次地震发生时的地震舆情信息中,如果此次地震为前主余型,人工将记录至前震的地震舆情数据修改至主震地震舆情数据中。经查,数据获取策略变更后,本数据库中涉及的震后72 h 内余震舆情数据均实现了归集。
(3)新浪微博地震舆情数据库可提升的方面包括:①数据来源单一,仅涉及新浪微博的结构化文本数据,对非结构化的图片和视频数据并未涉及;②随着我国相关法律的实施,微博对位置信息的获取进行了技术限制,本数据库在架构设计时虽设计了微博发布位置的信息提取功能,但今后本数据库的位置微博获取将受到一定影响,影响程度有待进一步评估。
4 结论
社交媒体作为大数据收集、存储与传播的新途径,越来越受到重视。本文在已有研究的基础上,采用新浪微博移动端为数据源,使用关联数据库管理系统MySQL,收集并建立了我国大陆地区3.0 级及以上地震准实时新浪微博地震舆情数据库。该数据库中获取了2021 年1 月1 日至2022 年3 月31 日我国大陆地区有地震舆情的3.0 级及以上地震共447 次,共获得地震舆情数据732 949 条。通过研究实现了微博信息读取接口与EQIM 接口的对接及新浪微博地震舆情数据的准实时抓取,通过分布式爬虫与新浪微博开放平台API 接口相结合的方式高效、全面、稳定地获取了我国大陆地区震后地震舆情数据。采用fastText 模型的地震相关性识别方法开展数据相关性分析,数据准确率为79.5%。建立了Web 端新浪微博地震舆情数据库及管理平台,实现了数据下载、快速查询及精确查询,方便数据查询与管理。通过对数据库中的数据进行时空分析,发现新浪微博地震舆情数据库中的舆情数据较丰富完备,对使用过程中发现的问题进行及时修正,可使舆情数据满足研究工作需求,新浪微博地震舆情数据库的建立为今后社交媒体地震舆情数据挖掘提供了参考,将进一步提升挖掘的深度与广度,提升继续学习的准确率,拓宽数据库来源并在深度学习方面进行完善。
