基于NS3-gym框架的智能干扰规避系统设计与实现
2023-02-28陈海涛龚广伟赵海涛魏急波詹德川
陈海涛,龚广伟,张 姣,赵海涛,熊 俊,魏急波,詹德川
1.国防科技大学 电子科学学院,长沙 410073
2.南京大学 人工智能学院,南京 210046
无线通信系统的信道开放性使其极易受到外界环境的恶意干扰,传统的干扰规避技术主要通过配置网络中的时、频、空等资源来实现干扰规避,包括跳频[1]、扩频[2]、传输速率自适应(rate adaptive,RA)[3-4]、波束成形(beamforming)[5-6]等。然而,当无线环境中干扰规律未知且动态变化时,这些规避策略往往难以准确识别干扰信号进行可靠干扰规避。
近年来,随着人工智能技术的快速发展,基于强化学习的智能干扰规避方法受到了业界的广泛研究。文献[7]针对跳频系统,利用强化学习技术,提出了一种基于Q 学习的认知跳频算法,在极大程度上降低了与干扰频率“碰撞”的可能性。文献[8]在DQN(deep Qlearning)算法架构下引入经验回放和基于爬山策略(policy hill-climbing,PHC)的动态ε机制,提出动态ε-DQN 智能通信抗干扰决策方法,该方法具有决策速度快,通信平均成功率高等特点。文献[9]设计了一种将信干噪比-平均意见得分(SINR-MOS)作为奖励函数的方法,首先通过强化学习获得最优的信道切换策略,然后通过应用Q 学习算法给出了两种具体的干扰规避方法,两种方法在点对点通信场景下具有较低的漏警概率和虚警概率。文献[10]提出一种基于深度强化学习的认知干扰规避方案,该方案在异构宽带频谱部分可观测的条件下表现出较强的抗干扰性能。但是,在这些基于强化学习的智能抗干扰方案中,为了达到规避干扰的目的,智能体需要与环境进行不断交互获得学习经验来优化干扰规避策略。而目前大量的研究都是基于训练生成的数据样本作为智能体的输入,数据样本并不是来自于真实的网络场景,缺乏真实性和说服力。因此,通过构建模拟的网络场景以获取数据样本作为智能体的输入成为了一种可替代的方案。NS3 作为当前最流行的网络仿真器之一[11],提供了丰富的网络模型,网络协议以及各种用于网络模拟的应用程序接口(application programming interface,API),非常适合构建各种复杂的网络场景。此外,现有的研究强化学习算法的工具包主要包括OpenAI gym[12]、DeepMind Lab[13]、RL-Glue[14]、Project Malmo[15]。其中OpenAI gym 因其工具包简单易懂,能够兼容TensorFlow、Theano、Keras 等大多数学习框架下编写的算法而受到学者们的广泛青睐。此外,OpenAI gym 无需对智能体的结构做任何假设,对所有强化学习任务都提供了接口,具有较强的可扩展性和可开发性。
为了有效研究通信网络的智能化功能实现,验证和比较强化学习算法在不同网络场景下的性能,需要构建NS3 网络仿真器到gym 的通用接口。Piotr 等人[16]提出的NS3-gym 框架为解决这一问题提供了很好的基础。NS3-gym 是一款联合NS3 和OpenAI gym 开发的用于在通信网络中进行强化学习算法研究的开源软件框架。该框架提供了NS3 和OpenAI gym 之间进行信息交互的接口,NS3中模拟的网络场景产生的状态数据作为智能体的输入,智能体学习得到的干扰规避策略作为输出,极大程度地模拟了真实网络场景下智能体与环境之间的交互过程。
本文提出了一种基于NS3-gym 框架的智能干扰规避系统。针对不同的干扰场景,智能体利用强化学习算法与环境进行不断交互来学习得到最优的干扰规避策略,从而达到可靠通信的目的。本文在Ubuntu20.04 系统中完成了智能干扰规避系统的仿真实现,基于该系统分别对比分析了两种强化学习算法在不同干扰场景下的抗干扰性能,验证了所提系统架构的有效性,并为进一步在通信网络中研究智能抗干扰算法提供了有效的仿真平台与技术支撑。
1 NS3-gym架构分析
如图1 所示,NS3-gym 框架主要包括以下两部分:NS3 网络仿真器和gym 智能学习引擎。前者用于模拟真实的网络场景,后者则提供强化学习算法框架并统一标准化界面。此框架可以实现NS3与gym的无缝衔接,在进行网络仿真的同时能够与智能体进行实时交互。下面将具体介绍该框架的结构组成。
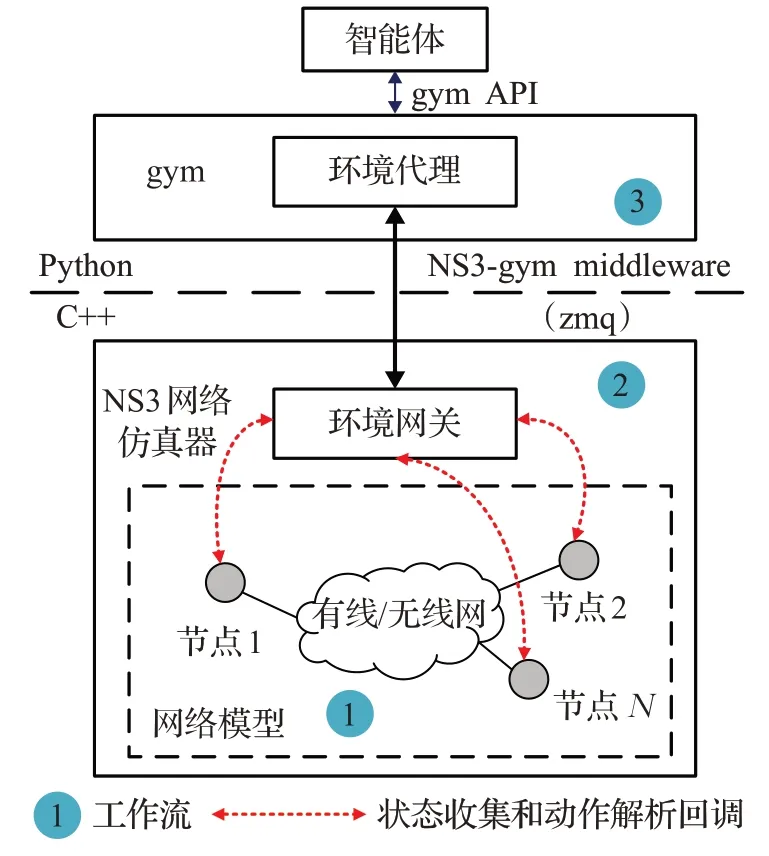
图1 NS3-gym框架的体系结构Fig.1 Architecture of NS3-gym framework
1.1 NS3网络仿真器
NS3 的基本模型如图2 所示,在NS3 模拟的虚拟网络中,网络拓扑中的节点和信道被抽象成了各种C++类,节点和信道的连接操作被抽象成不同C++对象之间的关联。通过这种抽象的概念,NS3能够模拟出各种类型的网络拓扑。

图2 NS3基本模型Fig.2 Basic model of NS3
其中节点(node)类是连接到网络的基本实体,同时也是应用程序(application)、协议栈(protocol stack)、网络设备(net device)的容器。应用程序是生成数据包(packet(s))流的用户程序,协议栈主要包括网络层面和传输层面的协议,网络设备作为基本通信子网的实体,主要功能是管理节点和连接信道对象。网络中信道的传输方式主要包括点对点、CSMA 和无线传输,在NS3中分别对应着不同的C++类。另外,NS3为用户提供了各种用于网络模拟的应用程序接口(API),在模拟脚本中用户可以调用这些API来构建自己的网络场景。
在NS3-gym框架中,NS3构建的模拟网络场景将作为与智能体交互的“环境”,一个模拟场景包括具体的网络模型以及模拟条件的改变。利用NS3 提供的通信组件与信道模型搭建出一个复杂的网络模型,并通过调度适当的事件(例如开始/停止数据发送)来触发模拟过程中某些参数或者条件的改变。
1.2 OpenAI gym
OpenAI gym是目前研究和开发强化学习算法的主流工具箱,它提供了一个API 用于智能体与环境的交互,只要所有的状态、动作、回报能够用数值表示,任何环境都可以被集成到gym中。
在gym中,最常用的两个强化学习元素就是环境和智能体,强化学习的基本思想就是学习状态和动作之间的映射关系,以使得累计奖励达到最大。如图3 所示,智能体在当前时刻t从环境接收一个状态st,at表示智能体在时刻t所采取的动作,该动作作用于当前时刻的环境。在下一时刻,智能体接收到数值回报rt+1并转移到新状态st+1。在每一时刻,智能体完成从状态到每种可能动作的选择概率之间的映射,该映射关系被称为智能体决策。强化学习反映了智能体面对环境状态的改变,如何根据其经验改变策略从而实现在长期学习过程中得到的累计回报值最大。
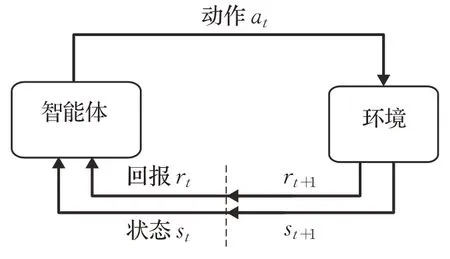
图3 强化学习Fig.3 Reinforcement learning
1.3 NS3-gym middleware
如图1 所示,NS3-gym middleware 主要负责连接NS3 网络仿真器与gym,并将状态观测值(如链路状态、队列长度等)和执行动作在NS3 和gym 之间通过zeromq(zmq)sockets 的通信机制相互传递。NS3-gym middleware 包括环境网关和环境代理两部分。前者位于NS3内部,主要负责收集网络状态信息并转化为结构化的数值数据,同时还要解析智能体传递过来的执行动作,并调用相应的回调函数;后者在gym 中负责接收传递过来的状态信息,并通过gym API传递给智能体进行学习与决策。
2 干扰规避网络场景描述与问题建模
为了研究无线通信网络中的智能干扰规避技术,构建点对点通信下的干扰规避网络场景如图4所示,系统中包括一个干扰节点和一对无线通信节点。其中干扰节点在每个时隙随机地选择干扰信道发送特定干扰功率的干扰信号,干扰功率集合设为PJ=[pj1,pj2,…,pjQ],第k个时隙干扰功率为,最大干扰功率为pmax。系统收发节点对中的发送节点的发射功率可调,并设定可调功率集合为PU={pu1,pu2,…,puL},背景噪声功率为σ2。假设发送信号为x(t),噪声为n(t),干扰信号为j(t),则接收信号y(t)可表示为:
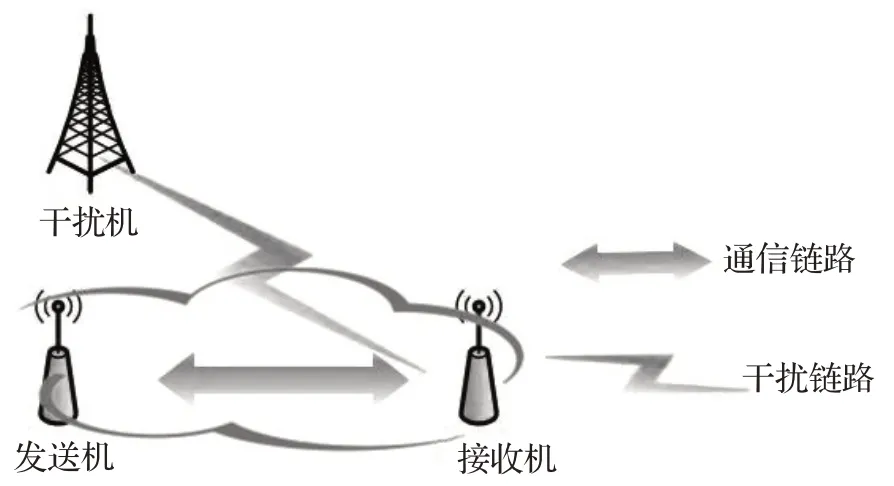
图4 点对点通信下的干扰规避网络场景Fig.4 Interference avoidance network scenario of point-to-point communications
在点对点通信网络场景中,基于信道选择和功率控制构建智能干扰规避模型,并将其建模成一个MDP(Markov decision process)过程[17]。MDP过程通常用状态、动作、转移概率和奖励这四个元素来描述,将其定义为一个四元组(S,A,ρ,R),其中状态空间S和动作空间A是离散的,MDP模型的具体元素如下:
(1)状态
定义第k个时隙的状态集为,其中表示当前时隙通信节点对选择的通信信道和发射功率,表示当前时隙干扰所占用的信道和干扰功率。,M是网络中总信道数,。状态空间记为S。
(2)动作
定义第k个时隙用户对采取的动作为,其中为第k+1 个时隙用户选择的通信信道,为第k+1 个时隙用户对采用的发射功率,动作空间大小为M×L,记为A。
(3)转移概率
在MDP过程中,下一状态是由当前动作确定,因此状态转移概率为确定值,记为ρ:S×S×A→[0,1],表示给定当前状态sk∈S下选择动作ak∈A转移到下一状态sk+1∈S的概率。
(4)奖励函数
当用户在sk状态执行动作ak时,会获得相应的奖励值Rk。定义第k个时隙的信干噪比(signal to interference plus noise ratio,SINR)为:
定义系统目标是得到最优的传输策略π,使系统的长期累计收益最大化,因此系统优化问题可以建模为:
其中γ(0<γ≤1)是折扣因子,表示未来收益对当前收益的重要程度,E[·]为求期望运算。
3 智能干扰规避仿真系统设计与实现
图5为智能干扰规避仿真系统,其中NS3模拟生成网络场景和感知环境状态信息,智能体基于网络状态信息进行学习分析得到抗干扰决策。具体实施过程为:在NS3中,干扰节点产生具体的干扰样式,如扫频干扰、贪婪随机干扰、随机干扰、跟随干扰等,通信节点对通过时分方式进行频谱感知和通信传输。通信节点对中的接收节点通过频谱感知模块感知的参数包括信道数、信道状态、干扰功率、发射功率等,并将所收集的信息进行融合之后上传至NS3 环境网关的消息队列中。gym 中的环境代理在接收到传递过来的数据后进行数据解析,这些数据将作为智能体的状态输入,智能体利用强化学习算法给出相应的规避策略。规避策略包括信道选择和发射功率控制。当学习得到干扰规避策略后,将通过NS3-gym middleware 传输到仿真网络中进行策略部署。在学习过程中,智能体与环境不断进行交互,学习干扰的变化规律,从而获得最优的通信策略。

图5 智能干扰规避系统结构Fig.5 Architecture of intelligent interference avoidance system
具体地,系统仿真实现的工作流如图1中的信息流所示,表述如下:
(1)在NS3中搭建仿真网络场景,主要包括初始化系统仿真参数,创建网络模型,设计干扰样式,配置感知节点。
(2)在仿真中实例化NS3-gym 环境网关,创建OpenGymGateway对象,并关联相应的回调函数。这些回调函数一方面用来收集网络状态信息,另一方面,当接收到智能体传过来的动作时,通过调用这些回调函数来执行。
(3)创建NS3-gym环境代理,即在gym中使用Gym::make(‘ns3-gym’)函数创建。
基于上述流程,搭建基于NS3-gym的智能干扰规避框架。智能体通过Gym::step(action)函数与NS3 进行交互,输入(2)中收集的网络状态信息,并通过强化学习算法给出下一步的动作,相应的动作会通过环境代理传递给环境网关。
3.1 网络模型创建与仿真场景配置
(1)初始化系统仿真参数
首先初始化系统仿真参数,具体的仿真参数包括节点个数、节点距离、仿真总时长、单步执行时间间隔、openGym端口号、工作频段等。
在NS3-gym 框架下有同步执行和异步执行两种步骤执行方式。同步执行即以预定的时间间隔调度(基于时间的调度方式);异步执行即由特定的事件触发执行(基于事件的调度方式),例如分组丢失。这里采取同步执行方式,设置时间间隔为0.1 s。
(2)网络模型设置
针对一个多信道的点对点无线通信场景,需要在链路层和物理层上分别配置网络中的频谱模型、传播模型、信道衰落模型、移动模型。在NS3中所有的网络模块都为用户提供了丰富的助手类,例如助手类MobilityHelper用来配置移动节点的移动模型。移动模型的设置分为两部分:初始位置分布和后续移动轨迹模型。前者定义了一个移动节点的初始坐标,后者则定义了节点的移动路径。在本文的仿真设计中,设置频谱模型为多信道频谱模型,设置传播模型为自由空间传播模型,设置信道衰落模型为Nakagami 衰落信道,设置节点为固定位置移动模型。表1 列出了网络模型配置中用到的主要函数及说明。具体的代码可参考NS-3的官方文档系统。

表1 网络模型配置涉及的主要函数列表Table 1 Main function list involved in network model configuration
(3)干扰样式生成
为了验证智能干扰规避系统的功能,本文以扫频干扰为例,利用NS3 中的WaveformGenerator 类来生成相应的干扰。扫频干扰是一种周期性干扰模式,在每个时隙中依次采用干扰功率集合Pj中的干扰功率以一定的干扰样式周期性地干扰m个信道,其中总信道数M为m的整数倍,当一个扫频周期结束之后,继续重复上一个周期的干扰策略。在本例中,网络中总信道数M=6,扫频干扰周期T=6,每个周期内的干扰信道样式为[1;2;3;4;5;6],干扰功率集合Pj=[0.002,0.004,0.006,0.008,0.010,0.012],单位为W。
在网络模拟过程中,需要根据设置的扫频干扰图案在特定的时间点发送干扰,并干扰相应的信道,故需要调用NS3中的Schedule()函数。Schedule()函数有三个参数,第一个参数是延迟时间,表示在调用Schedule()函数后延迟多少时间开始执行其他动作。第二个参数是一个函数指针,NS3在延迟时间到期后会立即调用这个指针所指向的函数(即回调函数)。第三个参数是回调函数形参,Schedule()函数最多同时支持6 个回调函数形参。根据设置的扫频干扰图案,当信道标识为1时(即occupied=1),表示信道被干扰,调用Schedule()函数,Schedule()函数在延迟一段预设的时间后就会调用WaveformGenerator::Start来产生并发送干扰。表2列出了干扰样式生成中用到的主要函数及说明。

表2 干扰样式生成中涉及的主要函数列表Table 2 Main function list involved in interference pattern generation
(4)感知节点配置
为了感知环境信息,NS3将接收节点创建为感知节点,并利用助手类SpectrumAnalyzerHelper对感知节点进行配置。首先利用NetDeviceContainer spectrumAnalyzers创建频谱分析器这一网络设备,频谱分析器可以扫描整个频段中的所有信道,并获取被干扰信道的干扰功率谱密度,通过计算可以得到干扰功率大小。然后,通过spectrumAnalyzerHelper.SetPhyAttribute()函数设置输入信号的解析时间和噪声功率谱密度。最后通过spectrumAnalyzerHelper.Install(sensingNode)为感知节点安装频谱分析器。
3.2 配置环境网关
为了将NS3 网络仿真中的状态参数转变为智能体的输入参数,需要以下两个步骤:
(1)创建OpenGymGateway对象。
(2)关联下列代码中的回调函数,这些函数都定义在环境网关中。

其中GetObservationSpace()函数定义了观察空间,GetActionSpace()函数定义了动作空间,其功能是分别将观察和动作编码为具体的数值。这两个空间函数都是在环境初始化的时候创建的,并在初始化阶段由环境网关发送给环境代理。GetReward()函数是获取上一步得到的奖励。GetGameOver()函数用来检测是否达到预设的结束条件。GetExtraInfo()函数用来获取与当前状态相关的其他信息。
3.3 配置环境代理
环境代理从gym 中继承了Ns3GymEnv 类,因此可以通过gym API 对其进行访问。在gym 中使用函数Gym::make(‘ns3-gym’)即可创建环境代理。环境代理是NS3与智能体之间进行交互的中间桥梁,一方面,环境代理通过与NS3中的环境网关进行交互获取网络中的状态信息,并通过gymAPI传递给智能体进行学习与决策;另一方面,环境代理将智能体下发的动作转化为相应的信息,并通过zmq的通信机制将信息传递给环境网关。
3.4 NS3-gym仿真运行流程
图6 展示了NS3-gym 仿真环境创建过程。首先在当前目录下运行已有的Python 脚本,在Python 脚本中使用Gym::make(‘ns3-gym’)创建环境代理。接下来环境代理会运行一个位于当前工作目录下的NS3 的模拟脚本,建立zmq 连接,并等待NS3 发送过来的环境初始化指令。一旦收到指令,环境代理便返回一个环境对象env.object,里面记录了当前的环境变量以及数据格式等相关信息。在运行的NS3模拟脚本中,会分别创建环境网关和相应的网络模型并进行初始化配置,初始化结束后由环境网关发送初始化指令给环境代理。
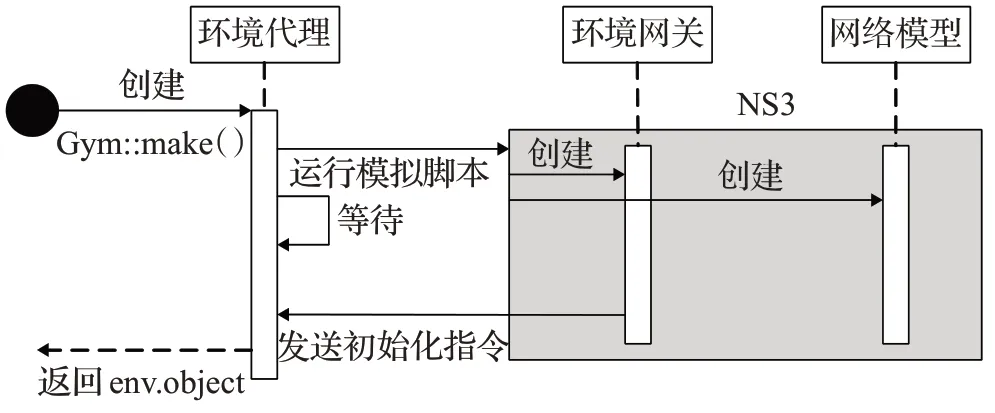
图6 NS3-gym仿真环境创建过程Fig.6 Implementation of NS3-gym simulation environment
智能体与NS3之间的交互过程通过Gym::step(action)实现,如图7所示,具体流程为:智能体基于当前的状态和策略给出相应的动作(action),并由环境代理将动作下发给环境网关。环境网关解析当前动作并执行,当前动作作用于当前网络场景从而得到下一个状态。当该动作执行步骤结束后环境网关会收到一个完成指令,环境网关通过调用回调函数来收集当前的环境状态(state)信息,包括:
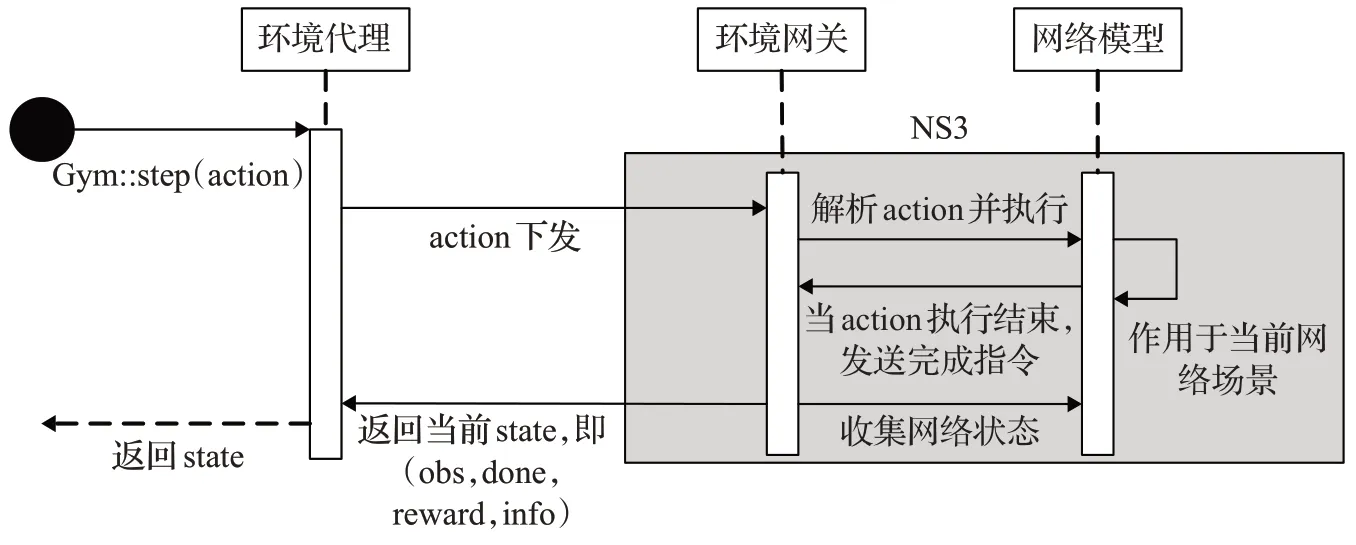
图7 智能体与NS3的交互过程Fig.7 Interaction between Agent and NS3
(1)observation:收集模拟中观察到的变量和参数值,这里主要是信道数、信道状态、干扰功率、发射功率。
(2)done:bool 类型的值,用来判断是否达到预定的结束条件。
(3)reward:获取上一步得到的奖励。
(4)info:获取与当前状态相关的其他信息。
4 仿真结果及分析
4.1 干扰样式生成与分析
本节首先生成扫频干扰、贪婪随机策略干扰、跟随式干扰、随机干扰四种典型的干扰样式,并构建相应的干扰场景,对比分析两种强化学习算法在这四种干扰场景下的性能。具体的仿真参数如表3所示。
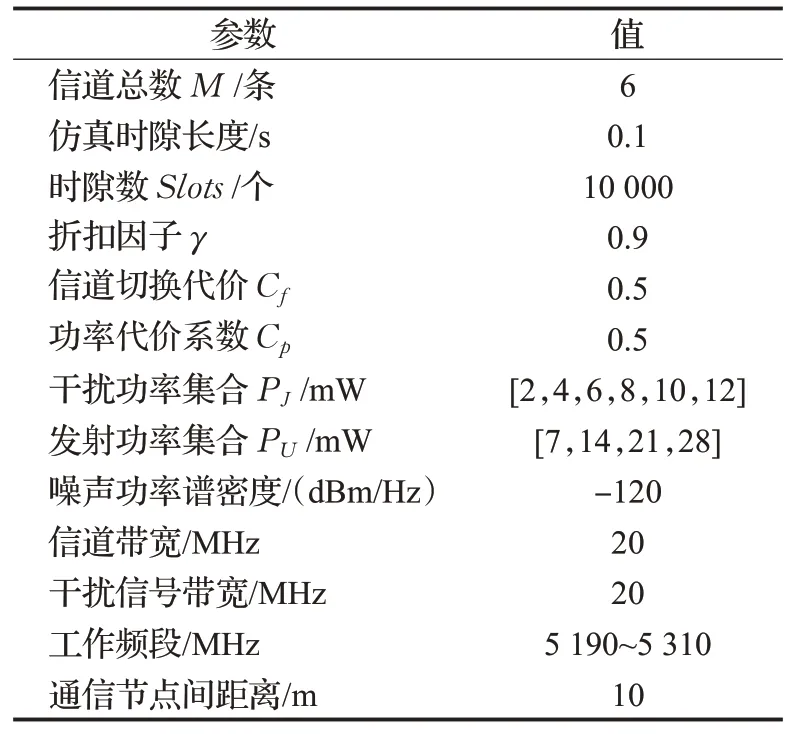
表3 系统仿真参数Table 3 System simulation parameters
如图8 所示,在NS3 中生成四种典型的干扰样式。为了便于分析,将整个工作频段划分为M个频率互不重叠的通信子信道(M=6)。图中,横坐标表示时隙,纵坐标表示信道,实心色块代表当前时隙存在干扰的信道,颜色深浅代表干扰功率的大小,颜色越深代表功率越大,白色代表当前时隙无干扰且不被占用的通信信道。其中图8(a)为扫频干扰,扫频周期T=6,每个时隙存在m=1 个干扰信道的扫频干扰。图8(b)为贪婪概率为ε=0.2 的贪婪随机策略干扰,贪婪随机策略干扰是指在每个时隙中随机选择干扰信道,使用P0=1-ε的概率选择相同干扰信道,使用P1=ε的概率随机选择新信道。假设每个时隙生成一个(0,1)的随机数,如果这个随机数小于ε,则重新随机选择一个干扰信道,如果这个随机数大于ε,则继续干扰原信道。图8(c)为跟随式干扰,跟随式干扰是根据正在进行通信的信道来选择干扰策略,即干扰直接跟随上一时隙通信所采用的信道。例如:当前一个时隙选取f1信道进行通信时,则后一个时隙就干扰f1信道。图8(d)为随机干扰,即每个时隙随机干扰某个信道。
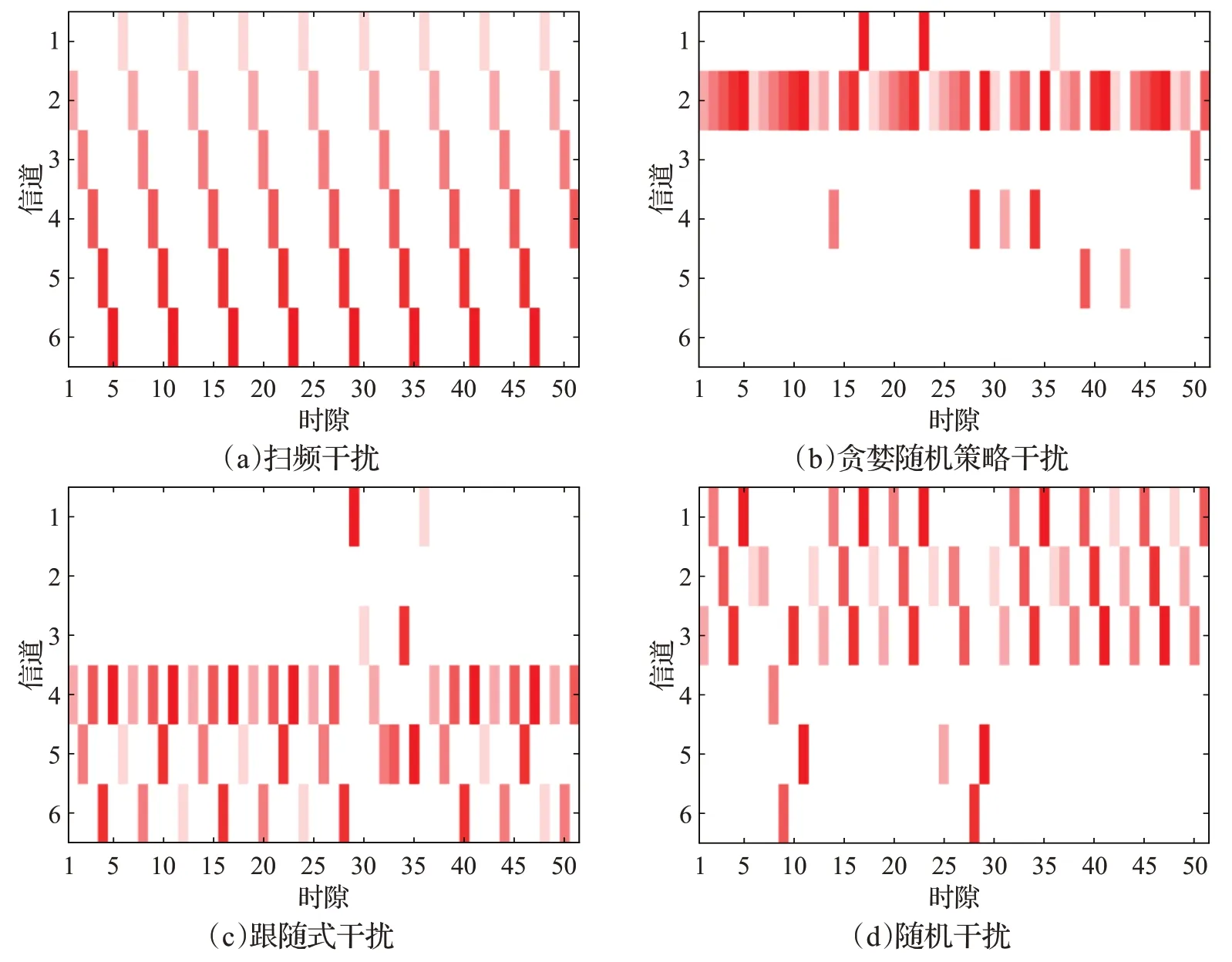
图8 NS3中生成的四种典型的干扰样式Fig.8 Four typical interference patterns generated by NS3
4.2 强化学习算法性能分析
针对四种典型的干扰场景,本文分别采用了Q学习算法[18]、WoLF-PHC 算法[19]进行学习与决策。Q 学习算法是一种基于价值迭代的强化学习算法,该算法的主要思想就是将“状态”和“动作”构建成一张Q表格(Q-table),然后根据Q值来选取能够获得最大收益的动作。WoLFPHC 算法是一种典型的策略梯度强化学习算法,其中“策略爬山法”(PHC)是一种适用于混合策略的梯度下降学习算法,通过引入“赢或快学习”(win or learn fast,WoLF)规则,即使用可变的学习率,在赢时减慢学习速率(让智能体有更多时间适应它的策略),而在输时快速学习(对当前策略进行大幅调整),从而增强Agent适应环境的能力。WoLF 规则的引入保证了WoLF-PHC 算法的收敛性。
本文研究了这两种算法在不同干扰场景下的收敛性,并进行了性能评估。本文的系统目标是最优传输策略π,使系统的长期累计收益最大,累计收益越大表示每次策略选择得越好,通信过程受干扰的影响越小。本文仿真的总时隙数为10 000个,在仿真过程中,每50个时隙内累计并统计一次奖励值,即累计奖励值。
如图9 所示,当经历一段时间后,WoLF-PHC 算法的累计奖励值都能够趋于稳定,可见算法具有收敛性。WoLF-PHC 算法在扫频干扰和贪婪随机策略干扰的场景下性能较好,在随机干扰的场景下性能最差。这是因为扫频干扰具有周期性,且每个时隙只干扰一个信道,干扰规律简单。而贪婪随机策略干扰在下一个时隙使用P0=1-ε(P0=0.8)的概率选择相同的干扰信道,使用P1=ε(P1=0.2)的概率随机选择新信道,因此贪婪随机策略干扰总是倾向于占用相同的干扰信道。对于这两种干扰场景,智能体能够很容易地做出正确决策并规避干扰。但对于随机干扰来说,下一个时隙干扰信道是随机生成的,干扰规律复杂且不易学习,算法性能也相应较差。如图10所示,当算法达到收敛后,Q学习算法的性能与WoLF-PHC算法性能相近,在扫频干扰和贪婪随机策略干扰的场景下性能较好,在随机干扰的场景下性能最差。值得注意的是,相较于Q 学习,WoLF-PHC 算法能够快速达到收敛,这表明该算法能够快速地学习干扰规律并迅速适应环境,采取最优策略完成通信。而针对随机干扰来说Q学习算法最终不能达到收敛,这是由于Q 学习算法采用的是恒定的学习率,收敛速度慢,不适用于干扰动态变化过快的场景。
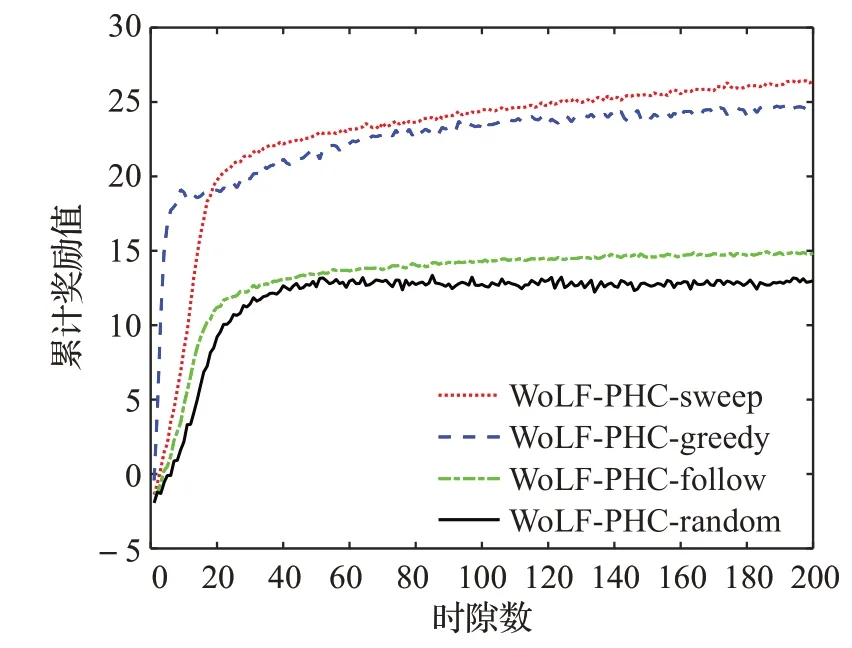
图9 WoLF-PHC算法在不同干扰场景下性能Fig.9 Performance of WoLF-PHC algorithm in different interference scenarios
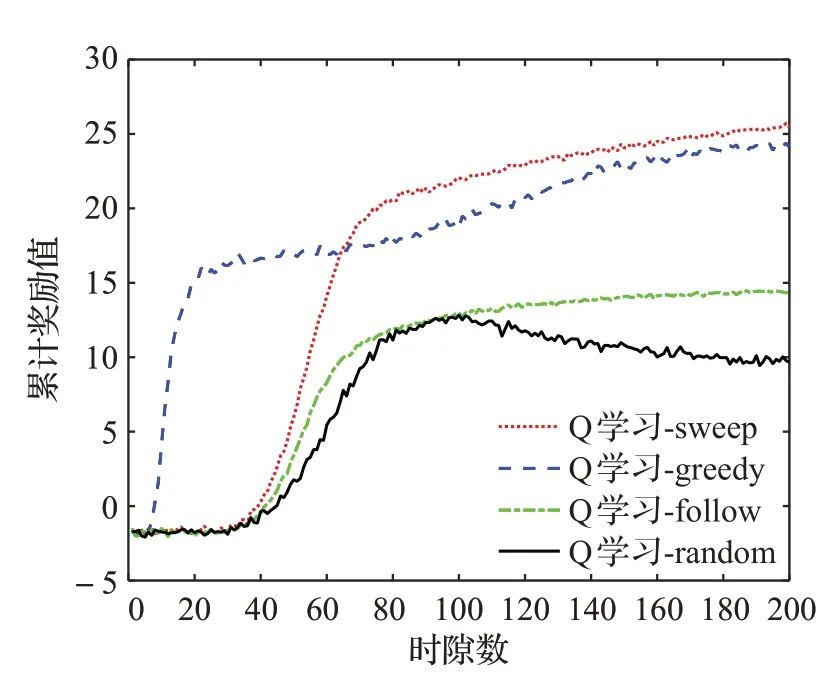
图10 Q学习算法在不同干扰场景下性能Fig.10 Performance of Q-learning algorithm in different interference scenarios
图11、图12 分别是WoLF-PHC 算法和Q 学习算法在扫频干扰场景下的通信策略图,分别对比了两种算法在初始阶段和收敛阶段的传输策略。图中,红色方块代表当前时隙存在干扰的信道,颜色越深代表干扰功率越大,绿色方块代表强化学习算法选择的通信信道,颜色越深代表发送功率越大,黑色方块代表通信信道与干扰信道重叠,此时通信信道被干扰。对于WoLF-PHC算法来说,当算法达到收敛时能够很好地规避干扰,而且能实现较小的信道切换代价和功率切换代价。对于Q学习算法来说,当算法收敛时,也能比较好地规避干扰,但是相比于WoLF-PFC算法,Q学习算法的信道切换代价更大。
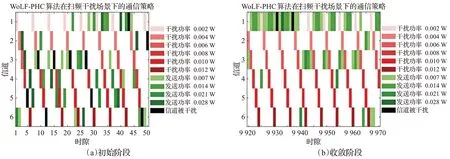
图11 WoLF-PHC在扫频干扰场景下的通信策略Fig.11 Communication strategy of WoLF-PHC algorithm in sweep interference scenario
如表4所示,统计了WoLF-PHC算法和Q学习算法在不同干扰场景下的通信成功率,两种算法的通信成功率都随着干扰规律的复杂度增加而下降。在扫频干扰模式下,通过智能干扰规避策略学习得到的通信成功率最高,而针对随机干扰模式学习得到的通信成功率最低。在扫频干扰和贪婪随机策略干扰场景下,WoLF-PHC算法的通信成功率高于Q 学习的通信成功率。在跟随干扰和随机干扰场景下,两种算法的通信成功率接近。
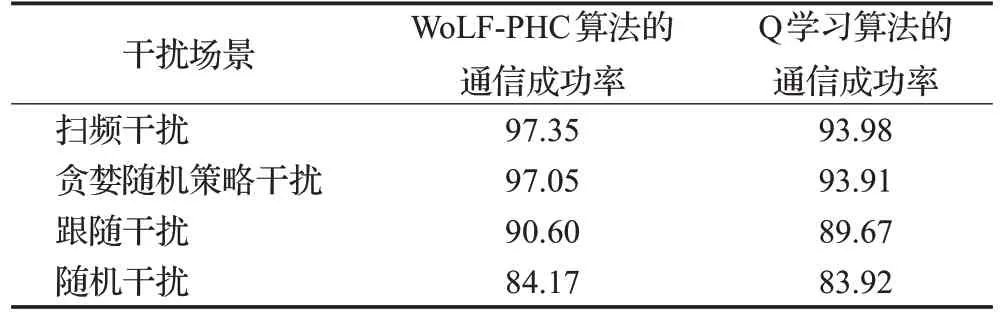
表4 WoLF-PHC算法和Q学习算法在不同干扰场景下的通信成功率Table 4 Communication success rate of WoLF-PHC algorithm and Q-learning algorithm in different interference scenarios 单位:%
5 结束语
本文提出了一种基于NS3-gym 框架的智能干扰规避系统。在该系统中,NS3中生成基本的干扰规避网络模型并感知环境频谱信息作为状态输入,智能体利用强化学习算法学习得到最优的干扰规避策略,并通过NS3-gym middleware 返回到仿真网络中进行资源配置。为了验证无线通信网络中的智能干扰规避策略,对点对点通信系统中的干扰规避问题进行了数学建模和智能干扰规避仿真系统设计。仿真实验构建了四种不同的干扰场景,基于Q 学习和Wolf-PHC 两种强化学习算法对智能干扰规避策略进行了实现,并对得到的系统抗干扰性能进行了对比与分析。本文所提出的智能干扰规避系统为验证通信网络的智能化功能实现,以及为进一步在通信网络中研究和对比智能抗干扰算法提供了有效的仿真平台与技术支撑。
