基于随机游走和长短期记忆神经网络的知识表示学习模型的设计
2023-02-27姜晓全
姜晓全
(辽东学院 信息工程学院,辽宁 丹东 118003)
知识表示学习是将知识图谱中的实体和关系转化为一种低维稠密的向量表示形式,这种向量的表示形式本身具有强大的语义,可以被直接应用到其他任务中[1-4]。目前常见的知识表示学习模型主要基于“翻译”模型,包括TransE[5]模型及在此基础上演化而来的TransR[6]、TransH[7]和TransD[8]等模型。这一类模型的核心思想是将知识图谱中的实体和关系抽象成一个三元组(E1,R,E2),通过关系R将E1翻译成E2,即E2=E1+R,并通过训练样本不断调整E1、E2和R的表示向量,使上述等式尽可能成立。但这类模型每次只能针对某一特定的三元组进行训练,而忽略了知识图谱中其他实体和关系对三元组中实体和关系的影响,进而导致模型训练得到的实体和关系的表示向量语义不够充分,影响它在实际应用中的效果。
为解决上述问题,知识表示学习模型借鉴网络表示学习理论,通过设计随机游走算法对网络节点进行采样并形成序列样本,再利用Word2Vec等神经网络模型对序列样本进行训练学习,从而得到网络节点的表示向量[9-11]。这种方法充分考虑了网络结构对表示学习过程的影响,可有效提升表示向量的语义效果。为此,本研究基于随机游走和长短期记忆神经网络(long short-term memory,LSTM)设计了一种知识表示学习模型。
1 知识表示学习模型的设计
1.1 知识图谱网络节点的采样
1.1.1 知识图谱网络的重构
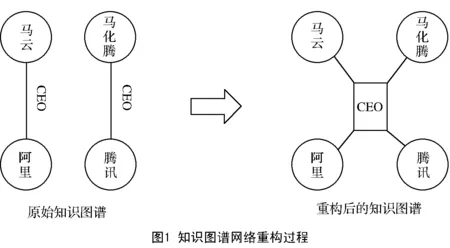
本文所建模型首先需要对知识图谱网络进行重构,目的是在不破坏原有网络结构的基础上将关系由边转化为节点,使重构后的知识图谱网络更加接近一般网络的结构。重构过程如图1所示。
1.1.2 面向重构后的知识图谱网络的随机游走策略
由于重构后的知识图谱网络包含实体和关系2种节点,并具有不同的网络结构属性,因此,本文设计2种随机游走策略。
1)当前节点为实体节点的随机游走策略(图2)
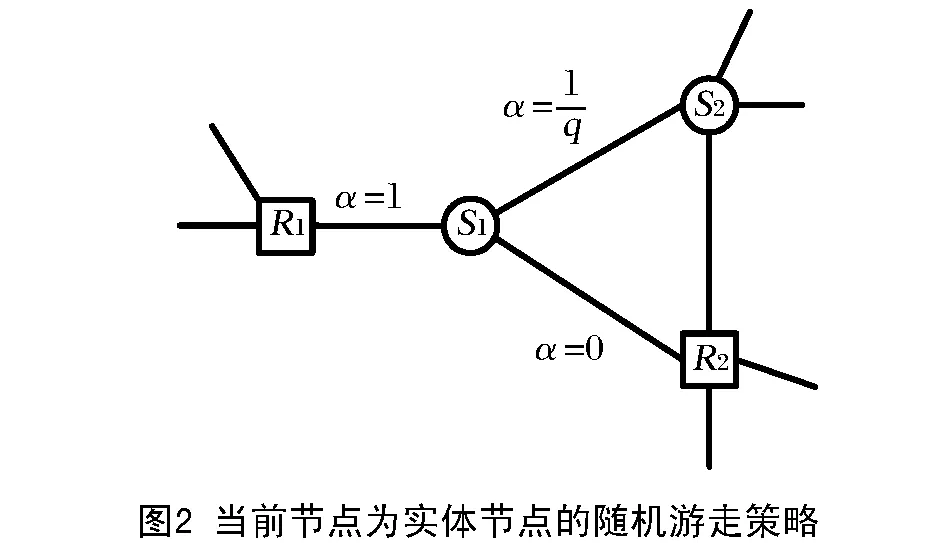
由图2可知,当前节点为实体节点S1,它的下一个节点可能为下述3种情况:
a)回到上一个关系节点,即实体节点S1回到关系节点R2;
b)选择另一个关系节点,即实体节点S1到关系节点R1;
c)选择另一个与之连接的实体节点,即实体节点S1到实体节点S2。
第1种情况在知识图谱网络的随机游走中是不允许的,因为这种游走没有任何实际意义,节点转移参数代表随机游走中从当前节点跳转到某一个节点的概率,所以节点转移参数α设置为0;第2种情况为理想情况,可将α设置为1;第3种情况并不是一种理想的情况,随机游走生成的节点序列最好是“实体-关系-实体”的形式,所以将α设置为1/q,其中q为超参数,可自行设定。本文将q设置为一个较大的值,让这种情况出现的概率减小。
第1种随机游走策略aq(t,x)的数学表达式为
(2)
式中:t为当前节点的上一个节点,x为当前节点可以选择的下一个节点,dtx为从上一个节点t到下一个节点x的最短距离,dtx的取值只可能是{0,1,2}。
2)当前节点为关系节点的随机游走策略(图3)

由图3可知,当前节点为关系节点R。它的下一个节点可能为下述3种情况:
a)回到上一个实体节点,即关系节点R回到实体节点S1;
b)选择一个与上一个实体节点存在关系的实体节点,即关系节点R到实体节点S2;
c)选择一个与上一个实体节点不存在关系的实体节点,即关系节点R到实体节点S3。
第1种情况是不允许的,因为这种随机游走没有任何实际意义,所以α设置为0;第2种情况是理想情况,因而α设置为1;第3种情况并不是一种理想的情况,因为当前关系节点的上一个和下一个实体节点不存在连接关系,这样形成的“实体-关系-实体”序列没有意义,所以将α设置为1/p,其中p为超参数,可自行设定,本文将p设置为一个较大的值,让这种情况出现的概率减小。
第2种随机游走策略αq(t,x)的数学表达式为
(3)
1.1.3 基于MPI的节点采样优化算法的实现
本文针对知识图谱网络的特殊性,使用MPI并行计算框架,根据节点的度数动态设置节点采样次数,优化随机游走效果。该算法不仅可以增加知识图谱网络中影响力大的节点的采样次数,还具有高并行性。采样优化算法步骤如下:
1)使用MPI框架在机器上开启多个进程。
2)每个进程先计算网络中每个节点的度数,并找到最大度数。
3)每个进程针对不同度数的节点进行下列2种不同的遍历:
a)如果该节点度数大于设定的阈值,则按照最大遍历次数进行遍历;
b)如果该节点度数小于设定的阈值,则按照比例计算需要遍历的次数并进行遍历。
4)所有进程完成采样工作后汇总形成一组序列样本。
优化算法的数学表达式为
(4)
式中:Nx为x节点的采样次数,Nmax为设定的最大采样次数,Dx为x节点的度数,Dmax为网络中最大的节点度数,T为度数的阈值。
1.2 使用LSTM对序列样本进行训练
本文使用单向LSTM和双向LSTM对序列样本进行训练。相比于单向LSTM,双向LSTM更适合知识表示学习,因为知识图谱中的实体和关系并不遵从某个单一方向,这与一般的序列学习任务不同,双向LSTM可以更好地对实体和关系的序列样本进行建模,从而训练得到语义更充分的表示向量。单向LSTM和双向LSTM训练过程如图4和图5所示。
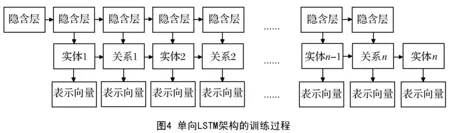
由图4可知,单向LSTM只包含一个神经网络,训练是从序列样本中的第一个节点开始,到最后一个节点结束。

由图5可知,双向LSTM包含2个神经网络:一个网络训练时一般从序列样本第一个节点开始到最后一个节点结束;另一个网络训练时从最后一个节点开始到第一个节点结束。
2 实验与分析
2.1 评价指标
本文研究重点关注表示向量语义的充分性,因而可将知识图谱中某个实体(或关系)的实体相似(或关系相似)的召回率R作为评价指标,R的计算公式为
(5)
式中:N为排序后选择节点的总数量;Nsim为在N个节点中与当前节点具备相似性的节点的数量,N的取值可根据实际需要进行设定。
在计算召回率时,首先计算当前实体节点与所有实体节点(或当前关系节点和所有关系节点)表示向量的空间距离,然后按照距离数值大小进行排序并计算前N个节点中与当前节点具备相似性的节点所占的比例。例如,在排名前N个节点中有n个与当前节点具备相似性的节点,则当前节点的相似节点的召回率为n/N。
2.2 数据集设定
本文选择FB15K(1)FB15K数据集地址:https:∥paperswithcode.com/dataset/fb15k。和WN18(2)WN18数据集地址:https:∥paperswithcode.com/dataset/wn18。2个知识图谱作为实验的数据集。其中,FB15K是Google公司发布的知识图谱集,约包含上万个实体和上千个关系;WN18是WordNet发布的知识图谱集,约包含上千个实体和18个关系。
2.3 实验测试及结果分析
本文主要验证本文所提模型相较于TransE基准模型训练得到的表示向量是否具备更充分的语义并能有效提升训练的效率。
2.3.1 模型表示向量语义充分性测试
在FB15K和WN18 2个数据集上进行表示向量语义充分性测试,超参数p和q分别设置为10和100,召回率测试中选取排序后节点数量N设置为10,召回率测试结果如图6和图7所示。
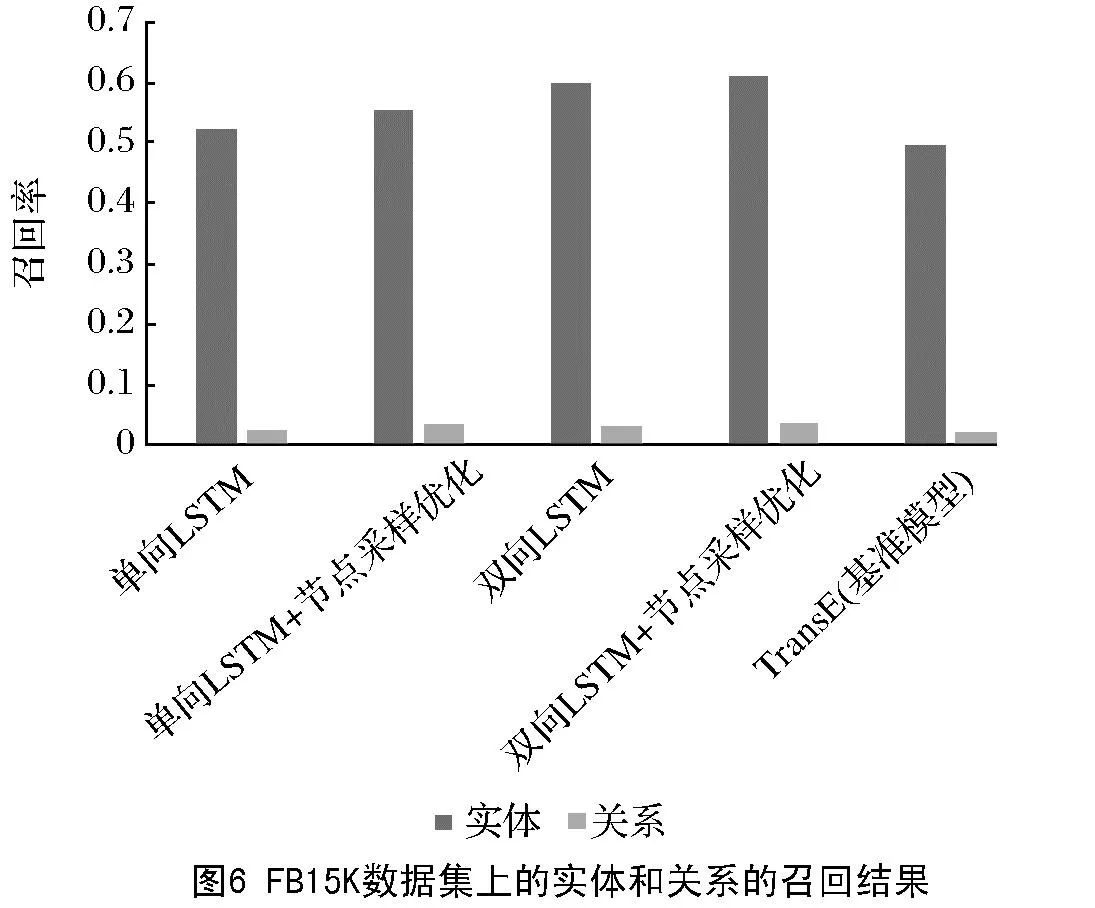
由图6和图7可知:无论是单向LSTM还是双向LSTM均取得了比基准模型TransE更好的效果;双向LSTM训练得到的表示向量相比于单向LSTM训练得到的表示向量具有更加充分的语义,这与本文之前的结论一致;应用本文所提算法,单向LSTM和双向LSTM的训练效果均得到了一定提升。
2.3.2 模型训练效率测试
本文在FB15K和WN18 2个数据集上基于MPI计算框架对单进程训练和多进程(4个进程)并行训练进行测试实验,记录训练所需时间,实验结果见表3。
由表1可知,基于MPI计算框架实现的并行训练方法相比于普通的单进程训练可极大地提升模型的训练效率。

表1 单进程训练和多进程并行训练实验结果 单位:s
3 结语
本文提出了一种基于随机游走和长短期记忆神经网络的知识表示学习模型,该模型相比于目前常见的知识表示学习模型更加关注实体和关系节点在网络中所在位置。实验结果表明,本文提出的模型不仅可以训练得到语义更充分的表示向量,并可有效提升模型训练的效率。
