基于DRL 的IRS 辅助认知电视频谱资源优化
2023-02-27郑子滨刘明轩
杨 亮,赵 越,郑子滨,刘明轩
(福州大学 电气工程与自动化学院,福建 福州 350108)
0 引言
随着信息技术的快速发展,利用无线资源的需求在爆炸性地增长,对无线频谱资源的消耗也在不断增加[1]。认知无线电(Cognitive Radio,CR)被认为是解决频谱资源短缺的潜在方案,电视白频谱资源是第一个被考虑的频谱共享案例。通过CR 对电视白频谱资源的灵活使用,能够提高利用率。智能反射面(Intelligent Reflecting Surface,IRS)作为一种新型的人工电磁超表面,能够灵活调控电磁波的频率、幅度、相位及传播方向等特性,成为面向下一代6G 无线通信网络的新兴传输技术[2]。
将IRS 应用到CR 中,成为当下研究热点。文献[3] 研 究 了(Single Input Single Output,SISO)认知无线电系统中,通过联合控制认知发射机(Secondary Transmitter,ST)发射功率与IRS 发射波束成形来优化认知用户(Secondary User,SU)的通信速率。文献[4]研究了多输入单输出(Multi Input Single Output,MISO)认知无线电系统中引入多个IRS,通过联合优化在ST 处的波束形成与每个IRS 的反射相移矩阵提高SU 的可实现速率。虽然文献[3]、文献[4]中的IRS 优化问题可以利用凸优化理论或启发式算法来解决,但对于大规模问题[5],非凸优化技术需要对优化变量逐一迭代优化,计算复杂度较高。
本文中,认知用户SU 通过感知和理解无线电频谱环境以提供无线通信服务,引入IRS 提高频谱利用率并利用射频(Radio Frequency,RF)能量延长电池续航;采用深度强化学习(Deep Reinforcement Learning,DRL)算法将SU 与IRS 控制器当作智能体,通过状态、动作和奖励机制与动态环境进行交互,最大限度地提高认知用户吞吐量。
1 系统模型
1.1 模型描述
如图1 所示,考虑一个用IRS 辅助underlay 模式下的能量采集CR 通信系统,系统中存在一对主用户(Primary User,PU)和一对SU,PU 与SU 为单天线。在主发送端(Primary Transmitter,PT)到主接收端(Primary Receiver,PR)以及ST 到次接收端(Secondary Receiver,SR)之间配置一个具有L个反射元件的IRS 来辅助通信。PU 与SU 以时隙模式运行,假设有K个时隙,每个时隙的时间为T。PU 由电网供电,SU 可通过能量采集将RF 能量转变为电能。假设SU 具有完美感知能力,感知时间忽略不计。
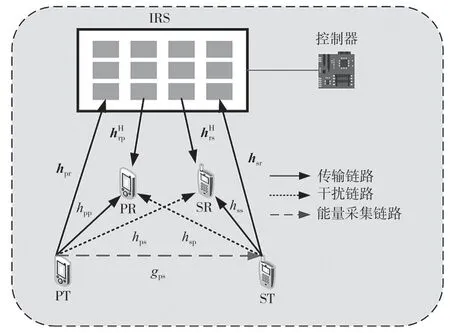
图1 通信系统模型
本文中,IRS 通过部署的反射元件调控无线信号,IRS 反射系数矩阵为Φ=diag(φ)∈CL×L,IRS反射系数向量φ定义为
式中:ai∈[0,1],i∈1,2,…,L表示IRS 第i个元件的振幅反射系数,θi∈[0,2π),i∈1,2,…,L表示IRS 第i个元件的相移反射系数。假设每个IRS 反射元件的振幅反射系数为使得信号反射最大的一个,即ai=1。
1.2 系统信道模型
对于IRS 辅助的能量采集认知通信系统,在第t个时隙中,PT 和PR 之间、PT 和IRS 之间、IRS和PR 之间、PT 和SR 之间、ST 和SR 之间、ST和IRS 之间、IRS 和SR 之间、ST 和PR 之间的基带等效信道分别表示为其中Ca×b表示所有a×b复矩阵的集合。考虑小规模衰落模型,除了能量采集链路以外,所有信道都假定为莱斯(Rician)衰落模型,且在一个时隙里信道增益保持不变。以ST与IRS 之间的信道为例
式中:β是莱斯因子,表示确定性LoS 分量;表示快衰落NLoS分量,是非视距瑞利衰落分量。为得到确定性LoS 分量,考虑IRS 为沿着方向(0,1,0)(即y 轴)放置的均匀线性阵列,故ST 与IRS 之间的确定性LoS 分量表示为
式中:vIRS与vST为导向矢量。ST为单天线,故vST为1。vIRS可表示为
式中:αAoA表示到达方位角,d表示IRS 相邻元件之间的间距,载波波长λ,令d/λ=1/2。方向向量esr由ST 与IRS 的相对位置确定,即
式中:PST与PIRS分别表示ST 位置、IRS 位置。到达方位角αAoA可表示为
1.3 能量采集模型
本文时隙可分为能量采集阶段和数据传输阶段。如图2 所示,在能量采集阶段,能量采集时间为αT,α为能量采集时间因子,T表示每个时隙的时间。采集到的RF 能量可表示为
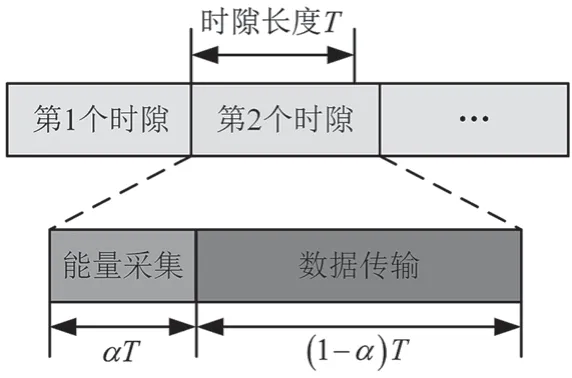
图2 时隙结构图
式中:η为能量采集效率,表示PT 在第t个时隙的发射功率,gtps表示第t个时隙的能量采集增益。当电池满电时,额外采集能量将被抛弃。假设频谱感知与电路损耗发热的能量为es,电池的最大容量为Bmax,电池电量更新公式表示为
在第t个时隙中,SU 消耗能量不超过可充电电池容量与能量采集所获得能量总和,故有
式中:B0表示ST 电池容量,为第t个时隙下ST发射功率。
1.4 信号模型
假设所有链路的信道状态信息(Channel State Information,CSI)都是完全估计和已知的,第t个时隙在PR 和SR 处的接收信号分别表示为
式中:xpt~CN(0,1)、xst~CN(0,1)分别表示PT 与ST的发射信号,wpt~CN(0,σp2)、wst~CN(0,σs2)分别表示PR 和SR 处的加性高斯白噪声(Additive Gaussian White Noise,AWGN)。
在第t个时隙,PR 接收到的信干噪比为
在第t个时隙,SR 接收到的信干噪比为
在K个时隙中,SU 总和吞吐量表示为
1.5 优化问题形成
本文研究在IRS 辅助能量采集CR 系统中,通过联合优化每个时隙中的ST 发射功率和IRS 的相移矩阵来实现SU 总吞吐量的最大化。优化问题表述为
式中:约束C1表示SU 消耗能量低于初始电池容量与能量采集之和;对PU 的服务质量(Quality of Service,QoS)要求由约束C2定义,约束C2表示PU 的信干噪比最小阈值;约束C3表示ST 发射功率限制在pmax下,约束C4定义IRS 上的L个IRS 反射元件相移。
2 基于DRL 的联合IRS 相移矩阵优化与认知用户功率分配
2.1 强化学习优化问题转换
本文将IRS 辅助能量采集认知通信建模为马尔可夫决策过程(Markov Decision Process,MDP),由四元组(st,at,Rt,st+1)表示。智能体通过不断地与环境交互,利用反馈来学习策略以最大化累积奖励。下面定义基于DRL 算法的关键元素,包括状态空间、动作空间、状态转移函数及奖励函数。
S表示为状态空间,st∈S表示智能体在第t个时隙从环境观测到的状态,定义为
at-1包括ST 发射功率、IRS 相移矩阵。Bt为当前时隙ST 电池容量信息,Et-1为上一个时隙采集能量值。htc为第t个时隙中的信道状态信息。
A为动作空间。本文将ST 发射功率离散为M个功率层级,即atp∈{p1,p2,…,pM}。将IRS 的反射元件的相位设置为有一定关联的整体。当IRS 相移矩阵的动作空间大小为5 时,设置为
故第t个时隙智能体采取的动作at∈A可定义为
状态转移函数:Pr(st+1|st,at)∈[0,1]是转移概率矩阵,表示当智能体选择动作at时的状态转移概率。
奖励函数表示为
智能体每个时间步长上的奖励通过折扣累积Rt构成智能体长期回报。累积奖励可表示为
式中:γ∈[0,1]表示折扣系数,策略π(st,at)表示在状态st之上选择一个动作at的概率分布。
2.2 基于残差网络的DDQN 优化算法框架
基于残差网络的DDQN 优化算法框架如图3所示,残差块包含一个跳跃连接与残差映射。跳跃连接将输入直接添加到残差映射上,形成“shortcut”路径,使得信息能直接传递到后续层,而不受梯度消失影响。
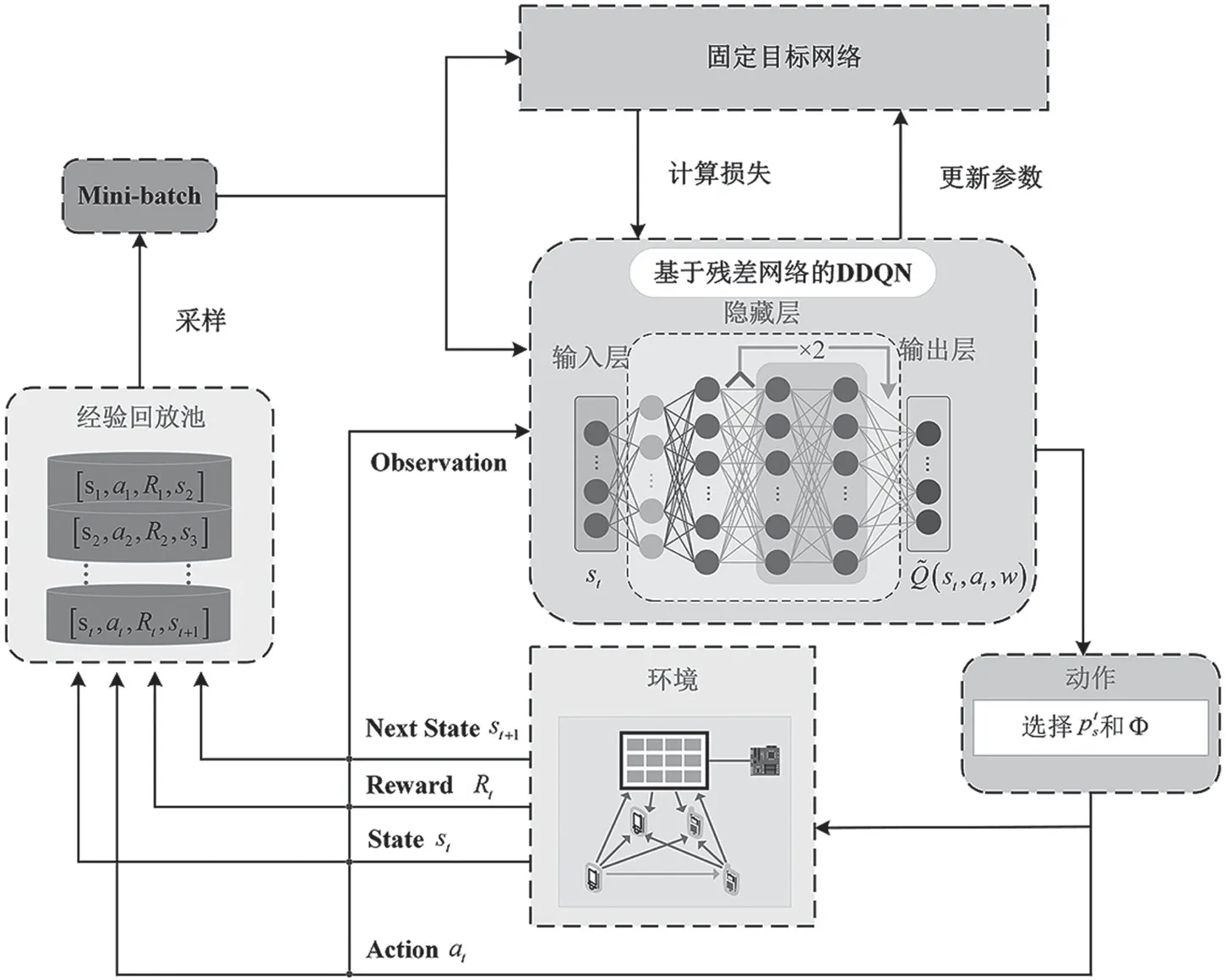
图3 基于残差网络的DDQN 算法框架图
图3 中,决策网络用于训练,本文采用ε-greedy策略实现探索和开发的权衡,表示为
式中:p∈[0,1]表示随机生成的概率。ε给定初始值,并以ξ∈(0,1]的速度递减下降,直到下界。本文中,DDQN 将决策网络和目标网络的计算解耦,先在决策网络中找出最大Q值对应的动作at,再利用动作at在目标网络中计算目标Q值,可表示为
式中:表示决策网络参数,表示目标网络参数。两个网络的结构相同,决策网络不断更新w^,目标网络则通过一定时间步nδ来更新。通过让两个独立网络的损失函数最小化实现决策网络参数更新,损失函数可表示为
参数的更新公式为
具体的算法流程如下所示。
基于残差网络的DDQN 资源优化算法
输入:C条通信链路信道增益的实部与虚部,电池电量,上一时隙采集的能量,IRS 相移矩阵虚部与实部,ST 发射功率
输出:智能体最优动作at={pst,Φt}
初始化:经验回放池M的容量Dm,决策网络参数,目标网络参数,ST 电池初始容量B0,IRS相移矩阵Φ,ST 发射功率ps,PT 发射功率pp,小批量训练数据大小D,C条通信链路信道增益
步骤1 for each episode do
步骤2 初始化状态s1
步骤3 for each steptdo
步骤4 输入st到DDQN 中获得状态动作值函数(st,at;w),at∈A;
步骤5 依据ε-greedy策略选取动作
步骤6 获得立刻奖励Rt和下一时刻的状态
步骤7 将经验元组存入经验回放池M中,M←(st,at,Rt,st+1)
步骤8 建立训练决策网络的损失函数
步骤9 if |M|≥D
步骤10 从M中随机取出D个小批量经验元组(si,ai,Ri,si+1)
步骤11 根据式(22)计算D个经验元组下目标网络输出值
步骤12 根据式(23)建立损失函数,训练决策网络参数
步骤13 执行梯度下降,使得预测值与目标值之间的误差达到最小
步骤14 根据式(24)更新决策网络权重参数
步骤15 iftmodnδ=0
步骤16 决策网络参数赋值给目标网络参数:←w
步骤17 end if
步骤18 end if
步骤19 end for
步骤20 end for
3 仿真结果与讨论
本节给出了数值模拟结果来评估所提方案的有效性。本文建立一个三维坐标系,如图4 所示。坐标系默认单位是米(m)。IRS 位置坐标为(0,50,2),PT 与PR 坐标为(50,0,0)、(1,24,0),ST 与SR 的坐标为(50,100,0)、(1,74,0)。IRS 反射元件的数量L=4,PT 发射功率Pp=2 W,能量采集增益gps=0.6。详细参数在表2 中给出。
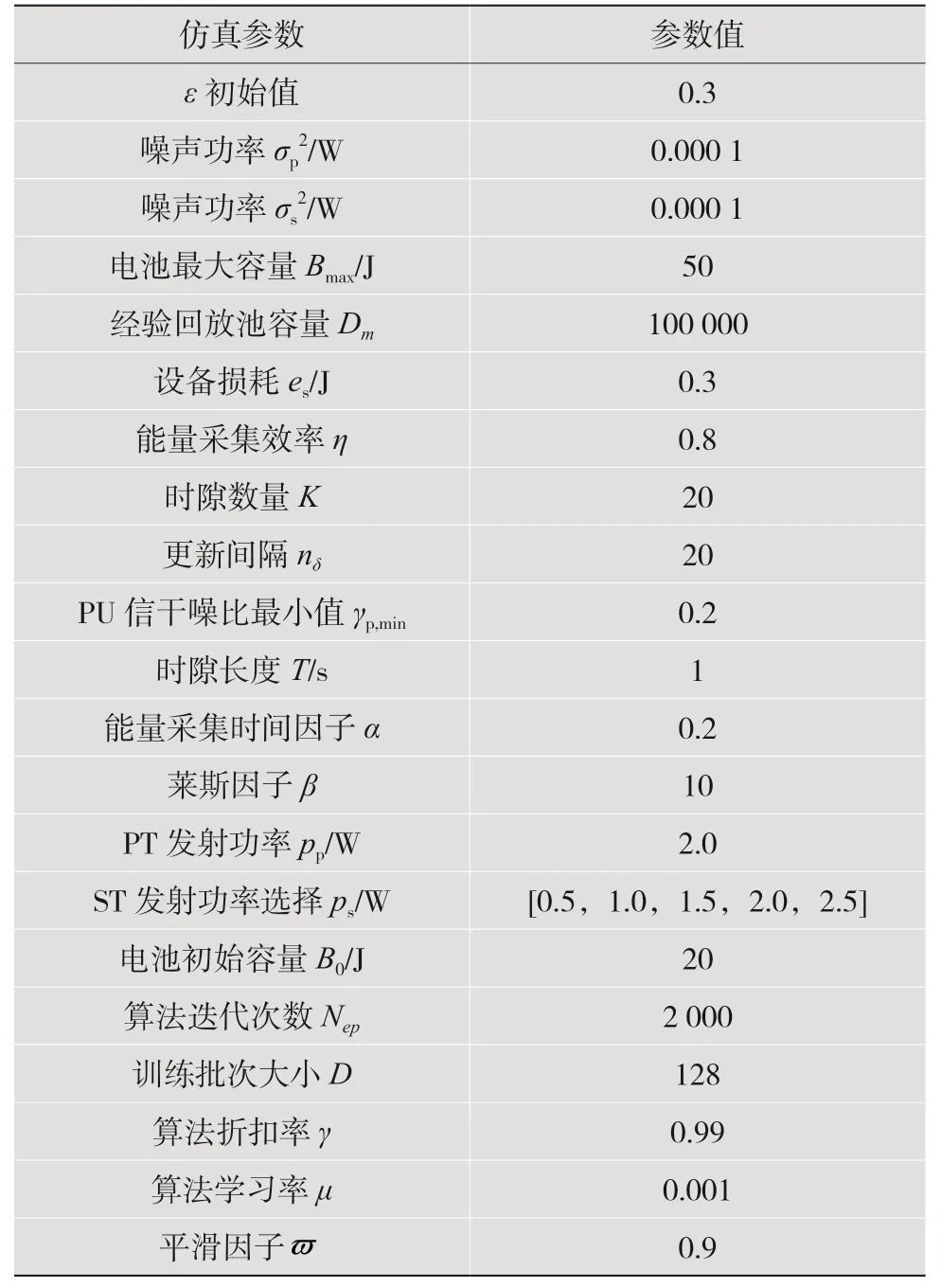
表2 资源优化算法仿真参数设置
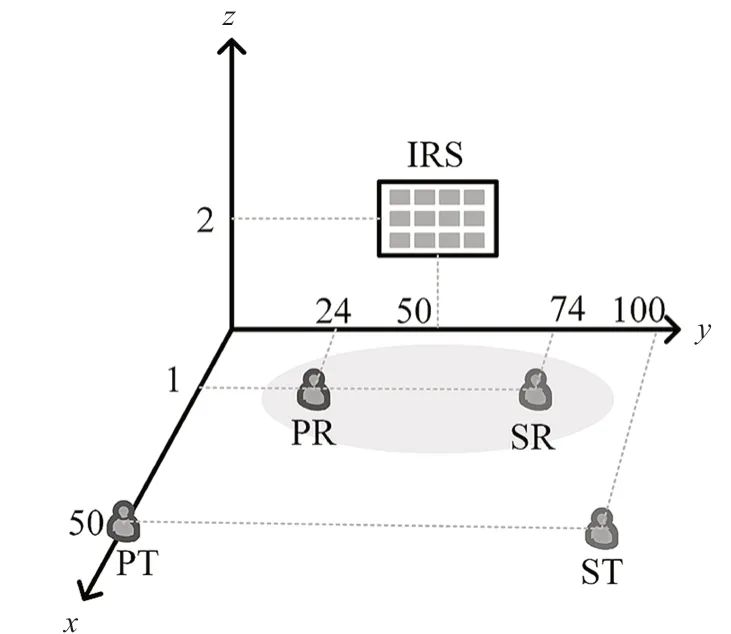
图4 系统模型三维位置仿真设置
为更好地展示所提算法的收敛性能,考虑即时奖励和平均奖励。其中平均奖励定义为
式中:ϖ表示平滑因子,初始值设置为0。
本文与其他3 种基准方案进行比较,分别是经典DQN 方案、多臂赌博机(Multi Arm Bandit,MAB)和随机方案。在经典DQN 方案中,采用深度Q 学习方法,通过训练神经网络来学习最优的动作策略,与环境交互来更新参数。在MAB 方案中,多臂赌博机有多个臂(拉杆),每个臂都代表一种动作或策略,赌博机的目标是找到最佳的臂以最大化收益。在随机方案中,智能体通过随机选择的策略来选取动作。
图5 比较了所提算法与其他基准算法的性能。迭代0 ~500 次时,4 种方法的平均吞吐量都在提高,这是因为滑动平均值更新,平均吞吐量会随着迭代次数的增加跟随立即奖励的变化。在平均吞吐量上升阶段,本文所提方案中智能体依据最优策略选择ST 传输功率以及优化IRS 相移矩阵;MAB 假设奖励的分布是固定的,无法建立动作与环境之间的联系;随机方案独立于任何信息。迭代次数在500 以后,平均吞吐量逐渐收敛。相比于经典DQN 算法,本文所提方案可将平均吞吐量提高13.8%。DRL 方法要明显优于传统算法。本文所提方案对比MAB 以及随机策略这两种方案可提高60.2%和120%。

图5 平均吞吐量随训练回合数变化曲线
图6 进一步研究了RF 能量采集对系统平均吞吐量的影响。存在RF 能量采集时,通信设备平均吞吐量增高,因为CR 通信设备运行时,RF 能量采集可以利用周围环境中的能量为设备提供持续电力供应。当能量采集因子为0.2,相较于无能量采集场景,本文方案可使SU 平均吞吐量提高44.8%。
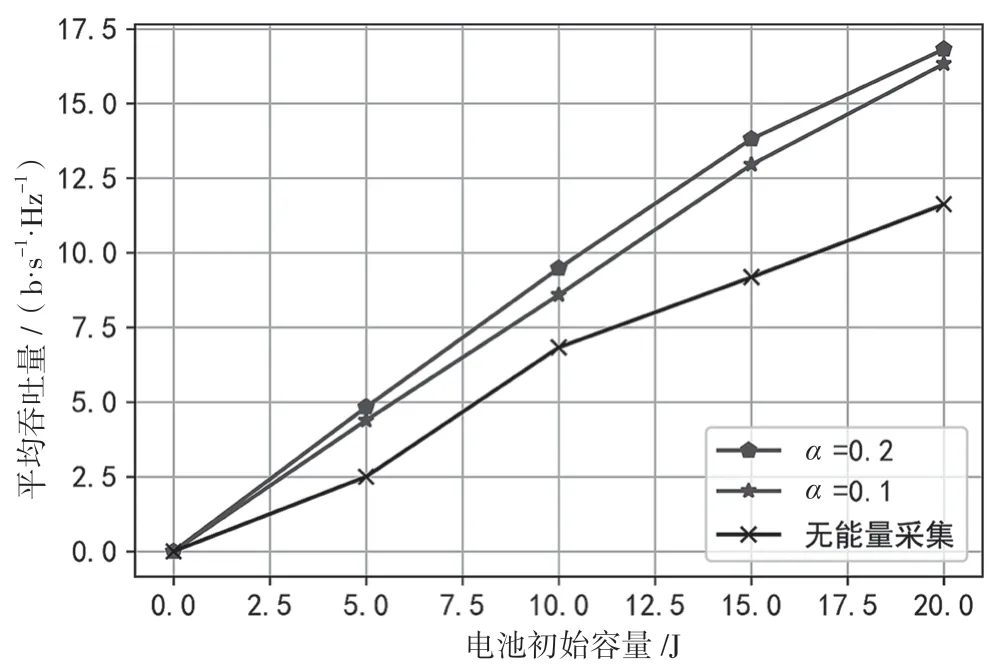
图6 不同能量采集时间因子下的平均吞吐量
图7 展示了IRS 反射元件个数L对SU 平均吞吐量的影响。当IRS 反射元件数目增加(如L>4),本文所提方法相比经典DQN 算法更有效。随机算法和MAB算法无法展现出比DRL更加强大的性能,说明本文所提算法是稳定且实用的,表明IRS 在辅助认知通信上存在巨大应用潜力。
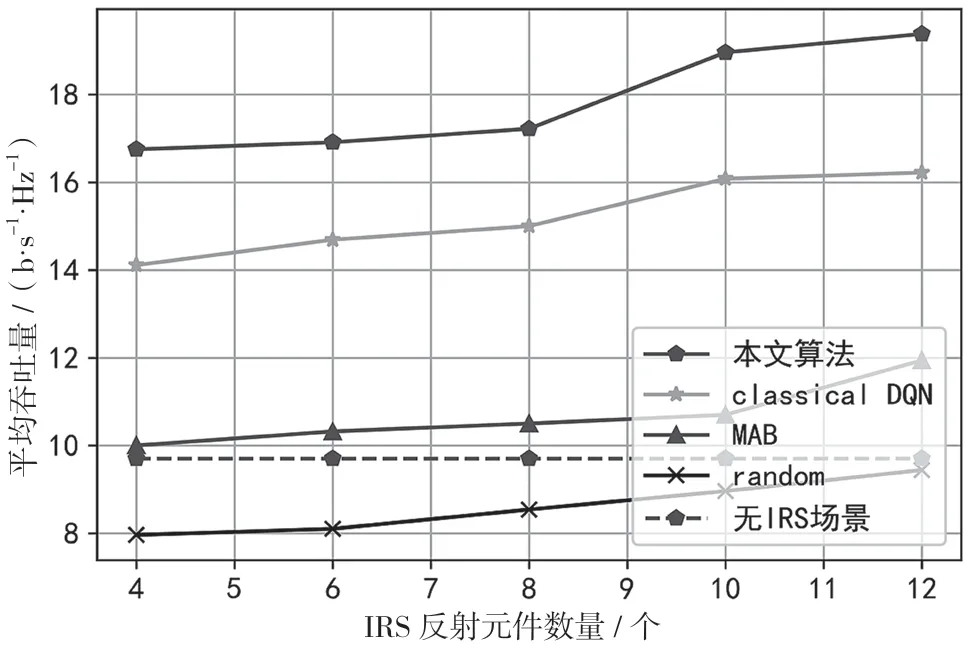
图7 不同IRS 反射元件数量对平均吞吐量的影响
4 结语
本文提出一种IRS 辅助认知电视频谱资源优化方法。先将ST 的功率控制与IRS 相位控制建模为MDP,并提出基于残差网络的DDQN 资源优化算法,设计了DRL算法的状态空间、动作空间及奖励函数。结果表明,与基准情况相比,在该算法下,SU 长期累积吞吐量提高13.8%。本文还通过仿真验证了在电池电量受限下的能量采集可以提高SU 的通信续航能力,可将吞吐量提高44.8%。
