应用于水下目标检测的YOLOv7 算法模型
2023-02-27邹敏
邹 敏
(福州大学 先进制造学院,福建 泉州 362200)
0 引言
随着计算机视觉的蓬勃发展,基于光学图像的水下目标探测技术得到了广泛的应用,在海洋渔业、水产养殖及海洋污染保护等领域发挥着重要作用[1]。在海洋渔业领域,大多数传统的海产品收集方法都以人工潜水捕鱼为基础,不仅效率低,而且需要工人有足够的潜水和捕鱼经验。由于长期水下作业的危害,劳动力减少,导致人工捕鱼作业的成本持续增加。另外,水下场景本质上比陆地场景更复杂,水下照相机获得的图像质量往往较低。因此,增强水下图像表达目标特征的能力,提高水下目标检测的精度,已成为迫切需要解决的问题。传统的目标检测方法依靠手动设计的滤波器来提取特征,往往导致特征表示不足且检测精度较低。深度学习网络的发展彻底改变了目标检测,通过多层神经网络提取目标图像特征,从而学习更抽象、更全面的表示信息。其中,两阶段目标检测具有代表性的算法为Faster RCNN[2]、级联R-CNN[3]以及Mask R-CNN[4]。另一种类型是基于回归的单级检测器,常见的单阶段目标检测有SSD[5]、YOLO(You Only Look Once)系列[6-9]等。它们都可以在合适的场景中显示出其优势。由于水下物体检测的实时性要求较高,一级探测器能够快速响应水下场景的需求。因此,水下目标检测研究大多基于一级探测器进行。ZHANG M H[10]使用YOLOv4,提出了一种结合注意力机制的轻量级方法,以实现准确性和检测速度的平衡。ZHANG J[11]在YOLOv5 的基础上加入全局注意力机制和颈部特征融合,取得了更好的检测精度。LIU K H[12]使用ACmix 替代YOLOv7 中的E-ELAN 结构,并引入全局注意力机制来提高特征提取的效率。
尽管一级探测器可以更好地满足水下目标检测的实时要求,但它们在检测精度方面仍然存在缺陷。本文在卷积块注意力模块(Convolutional Block Attention Module,CBAM)注意力基础上,提出一个通道残差拼接模块CBAM-CRMS,基于YOLOv7 的模型架构,将CBAM-CRMS 模块集成到YOLOv7 的Head 中的ELAN-H 之后,进一步增强水下图像表达目标特征的能力。
1 YOLOv7 算法介绍
YOLOv7 是一种基于深度学习的实时目标检测算法,网络架构如图1 所示。YOLOv7 是目前目标检测领域应用效果最好的算法之一。它使用了ELAN 和ELAN-H 模块,可以有效地增强网络的学习能力和收敛速度,同时减少参数量和计算量;SPPCSPC 结构可以提取多尺度的特征,并利用跨级连接和通道分离技术提高特征的表达能力和计算效率;Rep 结构可以实现模块的重参数化,将多个分支模块集成到一个等价的模块中,从而提高模型的泛化能力和推理速度;还使用了SimOTA 的标签分配策略,可以动态地根据损失函数和交并比(Intersection over Union,IoU)选择最优的正样本,避免了固定阈值和锚框的限制,提高了检测的准确性;使用了辅助训练头,可以在训练过程中增加正样本的数量和多样性,提高模型的健壮性和稳定性。
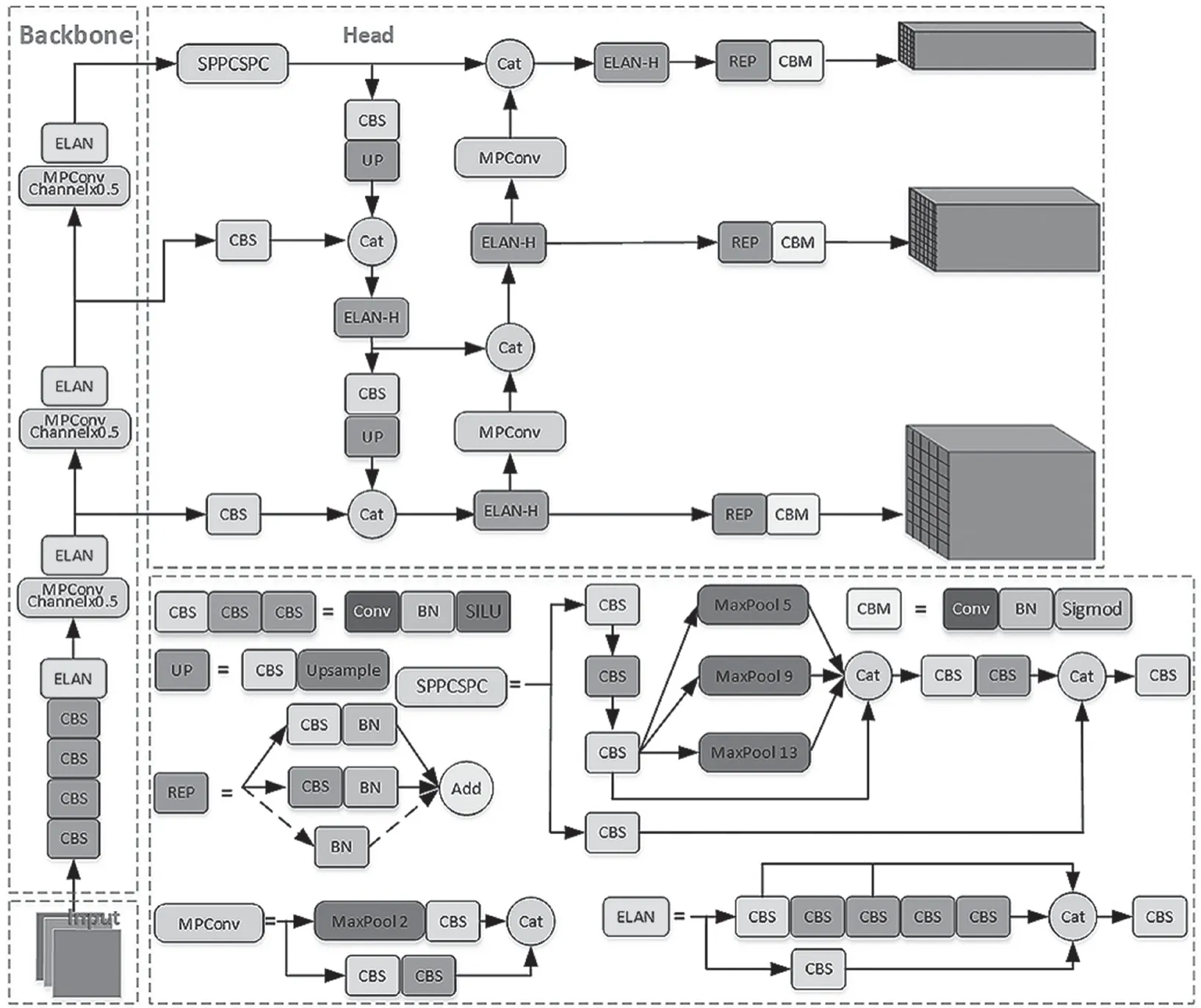
图1 YOLOv7 网络结构图
YOLOv7 的网络结构可以分为Input、Backbone及Head 共3 个部分。Input 是对原始图片进行预处理的部分,包括缩放、裁剪、翻转、旋转及颜色变换等数据增强操作,以提高模型的泛化能力和健壮性。输入的图片大小为640×640,通道数为3。Backbone 是对输入图片进行特征提取的部分,由50 层卷积层和池化层组成,使用ELAN 模块和MP 层作为基本组件。Backbone 的输出为3 个不同尺寸的特征图,分别为C3、C4 和C5,大小为80×80×512,40×40×1 024 和20×20×1 024。Head 是对主干网输出的特征图进行特征融合的部分,使用了PAFPN 的结构,即自顶向下和自底向上的特征金字塔网络。首先对C5 进行SPPCSP 操作,即空间金字塔池化和卷积层的组合,可以增加特征的感受野和多尺度信息,同时降低通道数为512。其次,自顶向下地将C5 和C4、C3 进行融合,得到P5、P4 和P3,大小为20×20×512,40×40×512和80×80×512。再次,自底向上地将P3 和P4、P5 进行融合,得到P3、P4 和P5,大小不变。最后,使用RepConv 操作,即可重参数化的卷积层,可以在训练和推理时有不同的表现,提高模型的效率和性能。
2 CBMS-YOLOv7 算法介绍
CBMS-YOLOv7 算法由YOLOv7算法改进而来,在Head 中的ELAN-H 后面融合了CBAM-CRMS模块,进一步增强网络的特征提取能力。
2.1 CBAM 注意力机制
CBAM 是一种用于深度神经网络的注意力机制,旨在增强模型对重要特征的关注,从而提高网络的性能,总体流程如图2 所示。CBAM 由通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spatial Attention Module,SAM)两个关键组件组成。
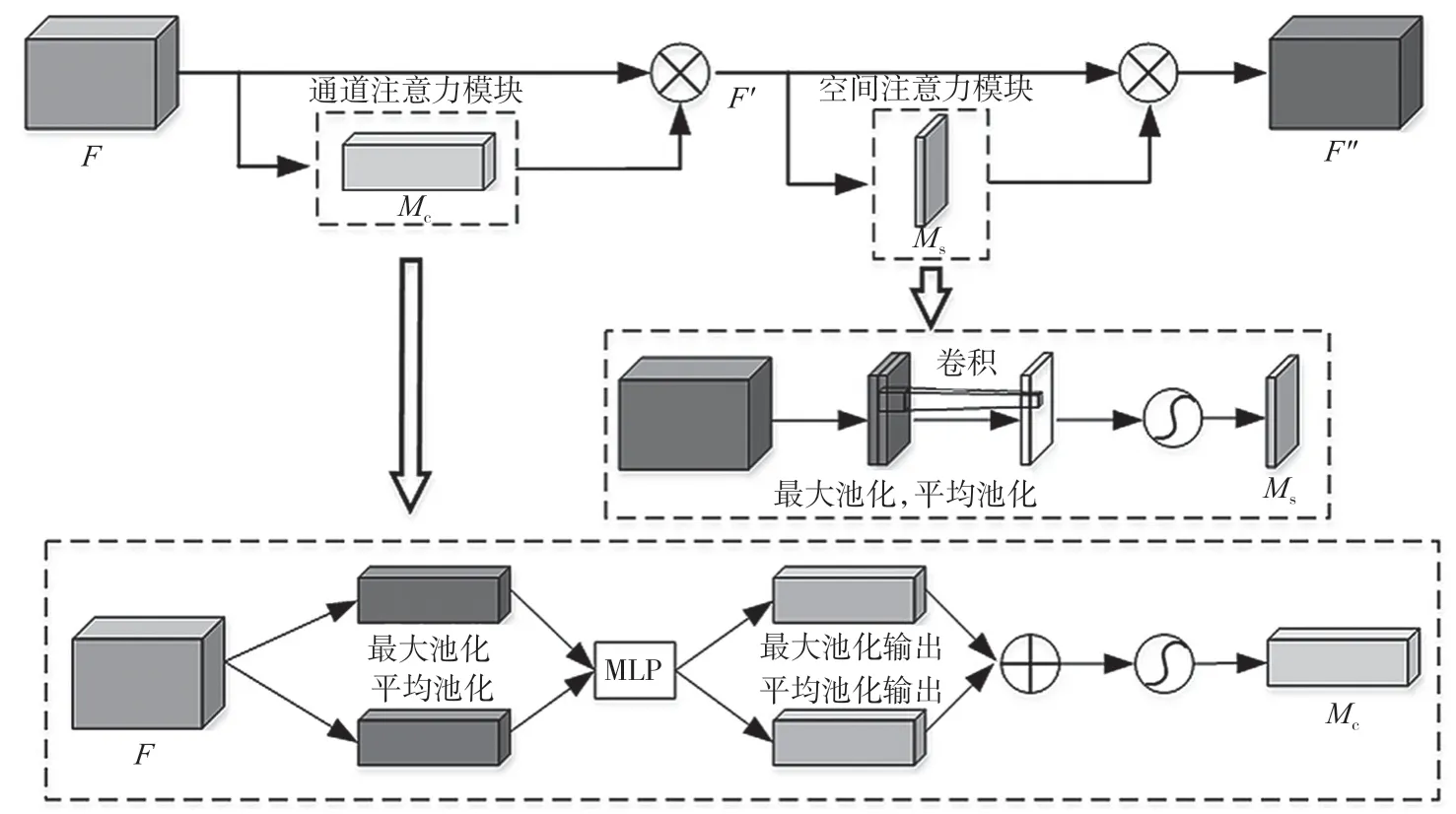
图2 CBAM 总体流程图
CAM 的目标是对输入特征图的每个通道进行加权,通过执行全局平均池化(Global Average Pooling,GAP)来获得每个通道的全局描述,经过全连接层和激活函数,生成一个权重向量,用于加权每个通道的特征图。SAM 旨在捕捉特征图中不同位置的相关性,通过对每个通道执行最大值池化和平均值池化操作,连接这两个操作的结果,通过卷积操作生成一个权重矩阵,用于加权每个位置的特征图。相关计算公式如式(1)~式(4)所示。
式中:MLP 为多层感知机,权重为W1和W2,该感知机是最大池化和平均池化共享的;f7×7表示一个卷积核大小为7×7 的卷积操作,σ为sigmoid 函数;⊗表示进行元素级的相乘,F'表示对特征图在通道维度上使用平均池化和最大池化的输出;F"表示对特征图空间维度上使用平均池化和最大池化的输出。
综合来看,CBAM 综合了通道级别和空间级别的注意力机制,使得网络在处理图像时能够更有效地关注重要的通道和位置,有助于提高网络的泛化能力和性能,尤其在处理具有复杂结构和变化的图像时,如水下图像目标检测中所描述的情景。
2.2 CBAM-CRMS 模块
CBAM-CRMS 注意力是一种基于CBAM 的注意力机制,在通道注意力模块中增加了一个通道残差模块CRMS。该模块通过残差的方式设计,输入的特征图分别经过两层卷积层,上条支路的卷积层在保留原始输入特征的位置信息的同时,下条支路进一步提升特征图的语义信息。通过通道残差模块的设计,可以将特征原始的位置信息和更丰富的语义信息和经过通道注意力权重元素级相乘的特征图进行通道拼接,并将拼接后的特征图作为空间注意力机制的输入,保留了有利于产生空间注意力权重的信息。
CBAM-CRMS 总体流程如图3 所示。在CBAM注意力机制中,特征图通过通道注意力生成通道注意力权重。通道注意力权重再与输入的特征图进行元素级相乘,将相乘的结果作为空间注意力机制的输入。由于空间注意力机制是进行通道级别的池化,特征图在经过通道注意力权重时,将会改变通道的权重,这将会对后期生成空间注意力权重产生影响,丢失有利于产生空间注意力权重的信息。
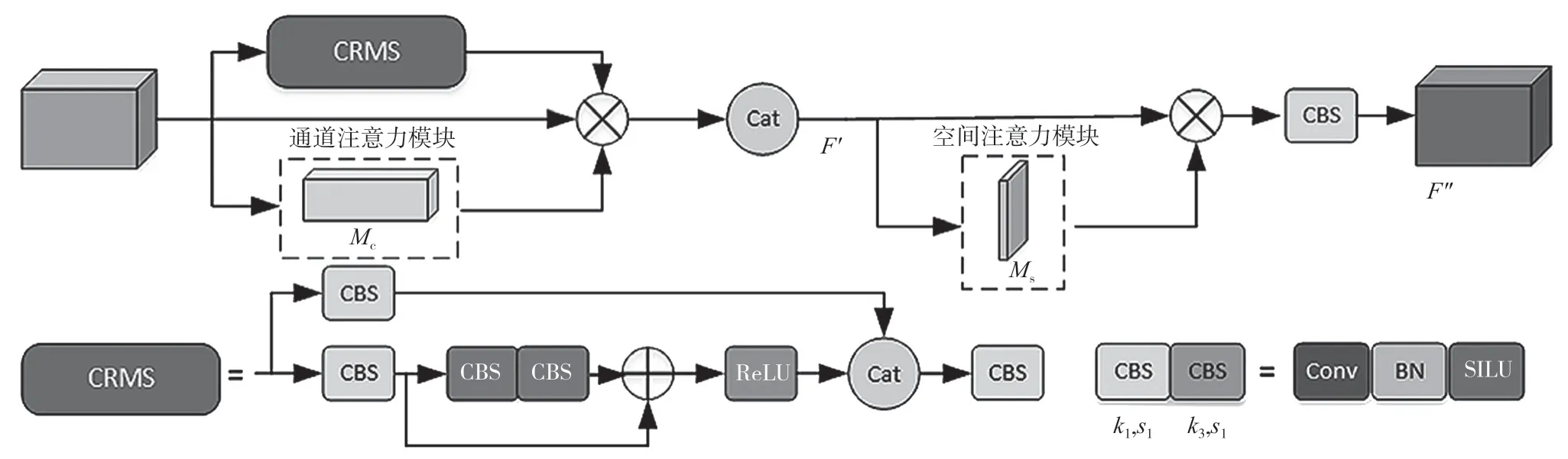
图3 CBAM-CRMS 总体流程图
3 实验分析
3.1 数据集准备
URPC2020 水下光学数据集是2020 年全国水下机器人大赛使用的数据集,包含5 543 张分辨率为1 920×1 080 像素的水下图像及其VOC 格式xml文件。测试集A 榜包含800 张图像及其VOC 格式xml 文件,测试集B 榜包含1 200 张图像及其VOC格式xml 文件。测试集在赛后公布了图片和对应的标签,可以自行测试。其检测的目标类别包括海参(Holothurian)、海胆(Echinus)、扇贝(Scallop)和海星(Starfish)4 类。将所有图片按照6 ∶2 ∶2的比例随机划分为训练集、验证集、测试集。
3.2 实验平台
本文使用Pytorch 作为模型的训练框架,学习率设置为0.01,epoch 设为150,batch_size 设为8。采用Linux 操作系统作为实验平台,采用Intel Xeon(R) CPU E5-2678 v3 @ 2.50 GHz 的CPU 处理器,2 个Nvidia GeForce GTX 2080Ti 的图形处理器(Graphics Processing Unit,GPU),具有64 GB 内存以及24 GB 显存。
3.3 实验结果分析
检测一般用精确率(Precision,P)、召回率(Recall rate,R)、平均精度(Average Precision,AP)、平均精度均值(mean Average Precision,mAP)等几个指标对模型检测效果进行评价。精确率、召回率的计算公式为
式中:QTP表示预测为正样本且正确的数量,QFP表示预测为正样本但错误的数量,QFN表示预测为负样本但错误的数量。AP 表示在不同的召回率下准确率的平均值。AP 的计算方法是在PR 曲线(Precision-Recall curve)上,以召回率为横轴、准确率为纵轴画出检测结果的变化曲线,然后计算曲线下的面积即为AP。mAP 表示在多个类别上AP 的平均值。
本文分别使用YOLOv5s、YOLOv7、YOLOv7+CBAM、CBMS-YOLOv7 算法进行实验并对比,具体训练结果如表1 所示。根据实验效果可知,YOLOv5 检测效果较差,YOLOv7 检测效果较YOLOv5 有很大提升,mAP@0.5 提升10.1%;在YOLOv7 中嵌入CBAM 模块,检测效果较YOLOv7的mAP@0.5 提升9%;在CBAM 的基础上,提出的改进模块CBMS 嵌入到YOLOv7 中,检测效果较YOLOv7+CBAM 的mAP@0.5 提升1%,mAP 效果检测提升3.7%,说明本文的改进具有进一步增强水下图像表达目标特征的能力。
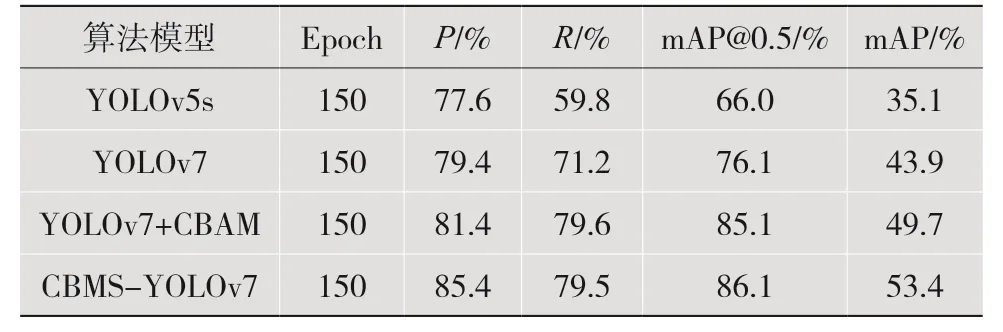
表1 模型训练结果
4 结语
水下场景复杂,采集到的图片背景色会有明显差别,而且水流扰动大,会造成采集数据图像时产生一些运动模糊和本身水质浑浊带来的中心模糊。这些图像数据相比陆地上的特征提取要复杂得多,导致检测精度受到很大的影响。本文提出了CBMS模块,以YOLOv7 为主干网络,从实验结果可知提升了模型检测的效果。
