基于改进沙漏网络的人体姿态估计方法
2023-02-27黄子健杨蕴杰张伯强魏旋旋
黄子健, 方 宇, 杨蕴杰, 张伯强, 魏旋旋, 杨 皓
(上海工程技术大学 机械与汽车工程学院, 上海 201620)
0 引 言
人体姿态估计是计算机视觉领域的重要研究方向之一,其目的是在给定的图片或视频中定位人体关节点的位置,进而实现人体姿态的跟踪和预测。姿态估计已被广泛应用于多个领域。如:人机工效学分析[1]、运动分析[2]和康复医疗[3-4]等。人的外观变化(如衣物和体型)和场景的复杂程度,都会对姿态估计结果的准确性产生影响。解决这些问题的关键,是如何利用数据中的特征来提取其中的上下文信息,以及如何利用人体各关节之间的相互位置关系,增强姿态估计结果的准确度。
传统的姿态估计大多使用基于图形结构[5-6]的方法,并依据人体各部件的相对空间位置关系建立人体结构模型;使用方向梯度直方图(Histogram of Oriented Gradient,HOG)[7]和尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)[8]来提取人工设定的特征。虽然该方法在某些场景下能实现较高的检测效率,但在人物遮挡、拍摄角度和图像光照等因素变化时,算法准确性会受到较大影响[9]。
随着人工智能技术的发展,基于深度学习的姿态估计方法因其精度高、泛化能力强等优点,成为人体姿态估计问题研究的主要方法[10]。DeepPose[11]是首个将深度学习用于姿态估计任务的方法,该方法将姿态估计问题转化为图像特征提取和关节点坐标回归问题,使用AlexNet提取图像特征,并使用级联回归器修正浅层网络在全连接层回归得到的关节点坐标,提高了算法预测精度。但该方法仅关注关节点坐标信息,忽视了关节点周围的特征信息,导致其预测结果缺乏鲁棒性[12]。Wei等人[13]提出了卷积姿态机(Convolutional Pose Machines,CPM)模型,CPM使用一种顺序化的卷积结构来提取图像特征信息,每个阶段将上一阶段的预测结果作为本阶段的输入,输出含有预测关节点信息的热图,并引入中间监督模块,用以解决训练过程中的梯度消失问题。Newell等人[14]以CPM为基础,提出了堆叠沙漏网络(Stacked Hourglass Networks,SHN),该网络由多个沙漏网络堆叠组成。与CPM不同的是,SHN在多个分辨率上学习关节点的特征,并且可以学习关节点之间的结构特征,预测结果更加准确。但是,该网络也存在一些缺陷。由于输入网络的图像仅通过简单预处理,无法提取出更加细致的底层特征用于后续的关节点预测,需要通过增加沙漏模块数量以改善预测精度。此外,因网络的上采样使用最邻近插值方法,在将图像从低分辨率还原为高分辨率的过程中,会丢失大量局部特征信息,影响各关节部位的纹理和形状特征提取。
针对以上问题,本文提出一种改进沙漏网络,主要改进工作为:
(1)使用预训练好的ResNet50[15]网络取代SHN的预处理模块,提高输入网络的图像底层特征的质量,从而提高模型的检测精度。
(2)通过调整残差模块的参数,改进网络中使用的残差模块,使得网络能在不同分辨率下学习到差异化的特征,增强网络对于局部细节特征的学习能力。
(3)使用反卷积替代上采样。相较于最邻近差值方法,反卷积在还原原始图像像素的任务上表现更好,有利于网络对于细节特征的学习。
1 算法描述
1.1 堆叠沙漏网络
沙漏模块的结构(图1)与全卷积网络(Fully Convolutional Networks,FCN)[16]相似,沙漏模块的前半部分通过4个残差模块和下采样操作降低图像分辨率并扩大感受野,在其中心的C5卷积层得到最低分辨率和最大感受野的特征图(feature map)后,进行4次上采样操作,并将通过跳连接传递的图像特征与上采样得到的图像特征进行融合,逐步将图像还原至高分辨率。SHN通过堆叠沙漏网络,重复地进行自下而上(高分辨率至低分辨率)、自上而下(从低分辨率到高分辨率)的过程,同时结合中间监督评估整个图像的初始特征和检测结果,学习人体各关节点的图像特征以及各关节点之间的相对位置信息。
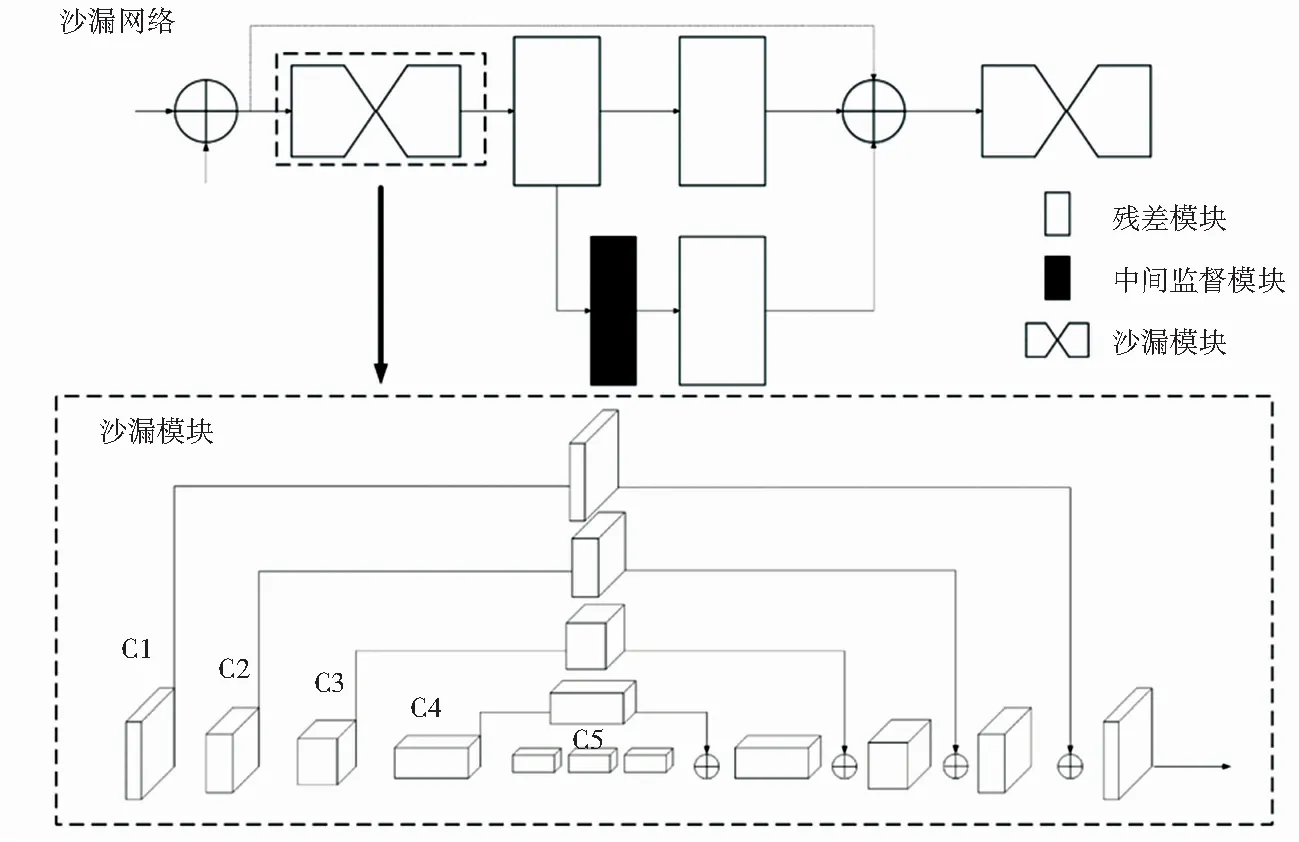
图1 堆叠沙漏网络
1.2 改进的沙漏网络
1.2.1 预处理模块
SHN在对图像进行预处理时,首先使用64个7×7、步长为2的卷积核,将输入图像的分辨率从256×256降至128×128,随后使用一个残差模块和一次最大池化操作,再将分辨率从128×128降至64×64,以此减少后续训练所需的GPU内存量。但是,该操作无法很好地提取图像的底层特征,影响了SHN前部沙漏网络的关节点预测精度。因此,使用在ImageNet上预训练好的ResNet50网络提取更高质量的底层特征,使后续网络能更快地学习到关节点部位的纹理和形状特征。ResNet50的网络参数见表1。

表1 ResNet50网络参数
由于ResNet50输出的图像分辨率为原始图像的1/32,因此本文使用3次反卷积操作,将ResNet50输出的图像还原至原图像1/4分辨率大小。预处理模块如图2所示。

图2 预处理模块
1.2.2 改进的残差模块
SHN中使用maxpooling作为下采样手段,maxpooling除了可以减少feature map的尺寸从而降低计算量外,还能抑制图象中的噪声,被广泛应用于卷积神经网络中。然而,池化会带来特征信息丢失的问题,影响网络预测性能。因此,本文使用步长为2的卷积核代替池化实现图片的下采样。在ResNet网络中,对于一个如图3所示的残差模块,其下采样是在bottleneck的1×1卷积处完成的,但该方式会使3/4的信息丢失,影响下采样得到的feature map质量。若推后至在3×3卷积处进行下采样操作,使卷积核宽度大于步长,则卷积核在移动过程中能够遍历输入特征上的所有信息,保证下采样后的feature map能完整保留原图像特征。
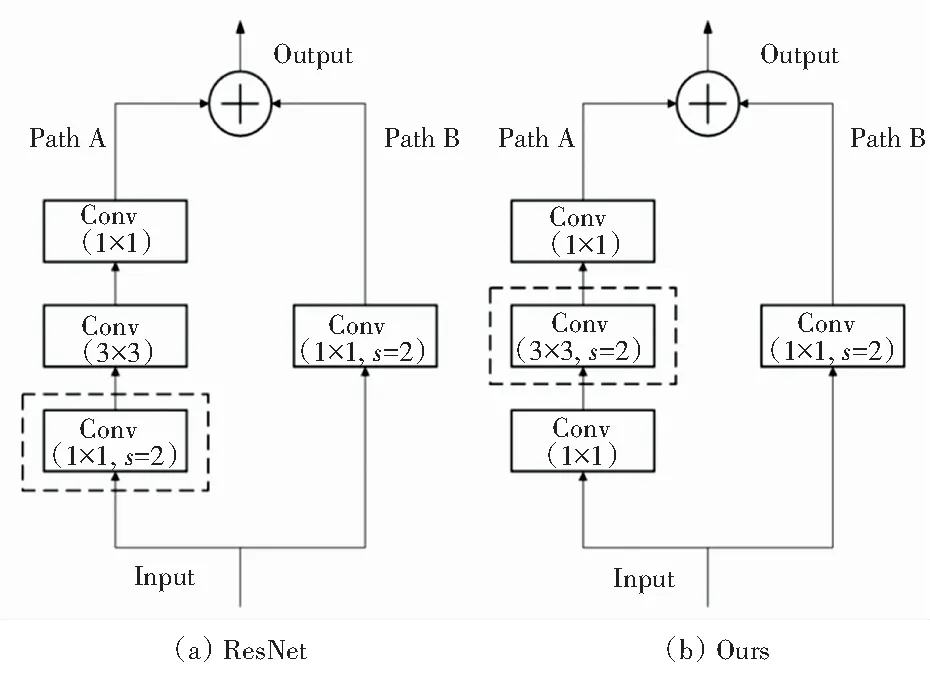
图3 下采样结构
当图片输入网络后,随着下采样次数的增加,卷积核的感受野随之增大,在图像下采样至最小辨率时,能得到信息最为丰富的feature map。由于SHN对于不同分辨率的图像均使用相同的残差模块进行处理,并未考虑到不同分辨率下图像信息的差异性。因此,本文使用一种差异化的残差模块,处理不同分辨率下单图像信息。对于不同分辨率的图像,对应的残差模块见表2。通过使用差异化的残差模块处理不同分辨率的图像信息,能增加网络对图像特征的学习能力,从而提升网络整体性能。

表2 改进的残差模块参数
1.2.3 反卷积模块
SHN使用最近邻差值的方法对图像进行上采样,将图像从低分辨率还原至高分辨率。该方法在还原图像分辨率时,只能根据当前图像的内容进行还原,还原出的图像像素值区分度不强,与下采样前的图像信息差距过大。本文使用反卷积层取代SHN中使用的上采样和残差模块,对于每一层反卷积层,记反卷积层输入分辨率为i,则输出分辨率o为
o=s×(i-1)+k-2p
式中:s为步幅,k为卷积核大小,p为边界扩充参数。
反卷积模块需要按照对应残差模块生成的feature map尺寸,适当调整卷积核和通道数的大小,以得到相同分辨率的feature map。
2 实验结果及分析
为评估本文提出的改进沙漏网络性能,在COCO[17]数据集和MPII[18]数据集上进行性能验证。本文实验使用TensorFlow深度学习框架作为实验框架,操作系统为Ubuntu18.04 LTS,使用Python3.6作为编程语言, GPU为RTX3080,显存为42 GB,采用Adam优化器对训练进行优化。
2.1 实验数据及评价标准
2.1.1 实验数据集
本文选用两个公开数据集:COCO数据集和MPII数据集对本文提出的网络进行性能评估。COCO数据集包括约200 K的图像,图像中含有约250 K个人体实例。COCO数据集定义了17个人体关键点,并对这些关键点进行了标注。本文将数据集中的train2017图像集(约57 K张图像,包含150 K人体实例)作为训练集,val2017图像集作为验证集。MPII(Max Planck Institute for Information, MPII)人体姿势数据集包含约25 K的图像,涵盖410种人类日常活动。本文将数据集划分为两部分,其中20 K用于训练,其余用于验证。
训练时,使用随机旋转(-30°,30°),随机缩放(0.75,1.25)和左右翻转等数据增强手段,加强网络的泛化能力。
2.1.2 评价标准
对于COCO数据集,采用官方指定关节点相似度OKS(Object Keypoint Similarity, OKS)为模型性能评价的度量方法。OKS的值在0~1之间,越接近1说明预测得到的人体关节点与数据集标注的真实值(groudtruth)越相似,预测效果越好。OKS的定义为
式中:p表示groudtruth中人的id,i为每个关键点的id,dpi表示每个人预测关键点和groundtruth的欧氏距离,vi为关键点的可见性标志,Sp为当前人体的尺度因子,σi表示第i个关键点的归一化因子,vpi代表第p个人的第i个关键点是否可见,δ用于将可见点选出用于计算。
此外,使用平均精确度AP(Average Precision, AP)和评价召回率AR(Average Recall, AR),作为算法在COCO数据集上预测性能的评估指标。
对于MPII数据集,采用关键点准确估计百分比PCKh(Head-Normalized Probability of Correct Keypoint, PCKh)作为实验评估指标。若预测的关键点落在groundtruth的αlr(两个参数的乘积)个像素内,则认为该关节点预测正确。其中,α为一个常数,lr为参考距离。评估时采用α=0.5(PCKh@0.5)作为评估标准,lr取头部边界对角线长度。
2.2 实验结果及分析
本文算法在COCO数据集上的结果与其它相关算法所得准确率的对比结果见表3。可以看出,本算法较SHN的AP和AR分别提升了4.7%和1.9%。相较于Baseline[19],本文算法的AP和AR分别高出1.2%和0.5%。
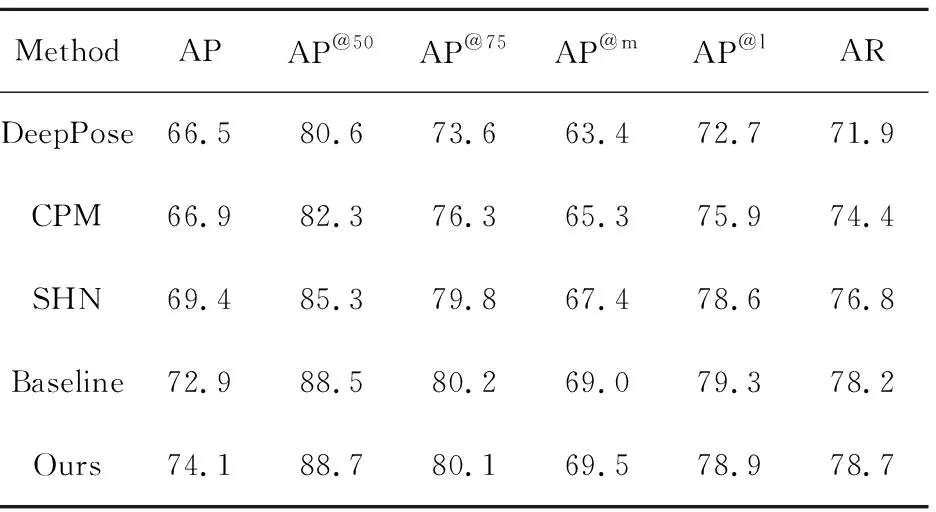
表3 不同方法在COCO数据集上结果对比
在MPII数据集上,测试7个部位的准确率。可以看出,本文提出的方法相较其它方法,对于部位检测的准确率更高。

表4 不同方法在MPII数据集上结果对比
3 结束语
本文以堆叠沙漏网络为基础进行改进,设计了一种基于改进沙漏网络的人体姿态估计网络。改进模型的预处理模块使用特征提取能力更强的ResNet50网络,提高了底层特征的质量;使用改进的残差模块处理不同分辨率的feature map,并使用步长为2的卷积代替最大池化进行下采样操作,确保图像信息的完整性;用反卷积模块扩大图片分辨率,使图片像素值多样化,减少上采样得到的图片与原图片间的信息损失。本文的模型相较SHN精度更高,能有效识别遮挡的关节点。如何对模型进行轻量化改进并应用到实际工作中,将是下一步的研究方向。
