采用改进闪电搜索算法的冷水机组故障特征选择研究
2023-02-27王华秋赵利军
王华秋,兰 群,赵利军
(1.重庆理工大学 两江人工智能学院, 重庆 401135; 2.河南中烟工业有限责任公司安阳卷烟厂, 河南 安阳 455000)
0 引言
冷水机组在工业生产中应用广泛,通过制冷剂在压缩机、冷凝器等关键部件中流动变化实现制冷循环[1],严格控制着生产环境的温度、湿度。但是随着机组工作时长逐渐增加,一些故障不可避免地出现。通常来说,发生之后导致机组立马停止工作的故障,被称为急性故障;而发生之后机组仍能运行但性能变差的故障则被称为渐变故障[2]。渐变故障短时间内不易被察觉到,如果不能及时发现,可能导致更大的生产事故,造成不必要的资源消耗。及时地从机组运行过程中的参数变化发现渐变故障,对于避免产生更大的生产问题有着非常重要的现实意义。本文即对这类故障进行研究,通过传感器获得冷水机组运行数据,判断出哪种故障发生并及时预警是故障检测与诊断的一种主要手段[3]。然而,冷水机组内部结构复杂、运行参数众多,使用全部的运行参数进行故障诊断易导致高额的诊断成本,而参数过少又会无法获得足够的故障信息,故障诊断精度不高,从中选择出能够指示故障的较优子集是故障诊断的前提,更为维护人员检修排障提供了参考。许多学者做了这方面的研究,Wang等[4]提出了DR-BN的特征选择方法,选出了5~8个特征以及3个补充特征,且仅用5个特征就使5种故障的诊断准确率超过90%;GAO等[5]通过随机森林的全局灵敏度分析探索冷水机组7种典型故障的敏感参数,并基于相关性分析和经验提出了级联特征清理补充混合特征筛选策略,从原始特征中分别筛选14个参数和9个参数,诊断准确率高达99.67%、99.79%;Yan等[6]考虑到不同的错分代价、保留已有的传感器,提出了回溯的序列前向选择算法(BT-SFS),将代价敏感学习嵌入到多分类的支持向量机(support vector machine,SVM)中作为BT-SFS的基分类器,选出了16个不同重要程度的特征,并且验证了所选特征能够提供更高的代价敏感分类精度。目前许多针对冷水机组故障特征选择的研究都是依据经验,事先去掉部分特征参数,然后在剩余特征中进行选择[4];或者其选择特征的方法中融合了经验[5]。这样得到的特征子集往往不够理想,存在经验误差,本文中提出了一种将Fisher Score和元启发式算法结合用于冷水机组故障特征选择的方法,该方法使用传感器测得的全部特征进行实验,并通过计算筛选出有效特征。Fisher Score根据类间距离和类内距离来衡量特征是否被选择,一个好的特征应该使不同类样本的距离尽可能大、同类样本的距离尽可能小。从二分类到多分类,许多学者也不断提出了改进的Fisher Score方法,赵玲等[7]还将一种Fisher Score方法应用于齿轮箱故障特征选择,大大降低了特征的维数,因此,将Fisher Score用于冷水机组故障特征选择是可行的。元启发式算法通过随机搜索发现近似最优解,广泛用于控制系统、资源调度等问题[8],闪电搜索算法(lightning search algorithm,LSA)是Shareef等[9]在2015年提出的一种元启发式优化方法,任云等[10]将LSA算法与天牛须搜索算法(bettle antennate search algorithm,BAS)相结合以改善LSA算法的局部搜索能力,并将此方法用于装配序列规划问题,表现出了良好的性能。Fisher Score与闪电搜索算法共同进行特征选择的思路如下:求出每个特征的Fisher Score值,设置阈值对特征进行初选;再为留下的每一维特征分配权重,以诊断准确率为适应度值,使用闪电搜索算法对权重、需保留特征个数不断更新,最终得到冷水机组每个特征的权重值及故障特征较优子集,用于构建冷水机组故障诊断模型。
1 闪电搜索算法
闪电搜索算法受到闪电梯级先导传播机制的启发:放电体参与形成二叉树结构并且在分叉点同时形成2个先导尖端。考虑了闪电的概率性质和曲折特征,通过相对能量来控制算法的探索和开发能力。算法的3种放电体建模和2种分叉方式形成新通道的原理如下。
1.1 放电体建模
过渡放电体产生了梯级先导的初始种群,空间放电体试图到达最好的先导位置,先导放电体代表当前的最优位置,考虑到闪电的概率性质完成了3种放电体的建模。
先导尖端在早期形成,经过渡向随机方向喷出放电体,因此过渡放电体pt可被认为是从解空间[m,n]上取得的随机数并服从均匀分布,根据以下公式来生成过渡放电体。
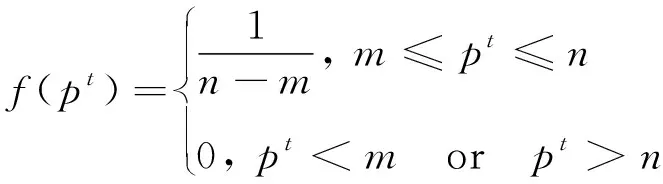
(1)
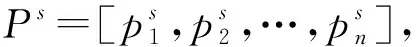
(2)
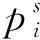
(3)
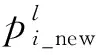
1.2 2种分叉方式形成新通道

(4)
2) 设置一个最大通道时间max_time,在达到max_time时,用最优的通道代替最差的通道进行通道更新。
2 FSLSA算法
2.1 SLSA
针对LSA做出了以下几点改进,提出了SLSA算法改善LSA算法跳出局部最优的能力。
1) 利用1-D Sine Powered混沌映射初始化种群
1-D Sine Powered(1DSP)混沌映射[11]定义如下:
di+1=(di(α+1))sin(βπ+di)
(5)
式中:α>0,β∈[0,1],初始值d0∈[0,1],di存在于方程的2个部分,这使得1DSP更加复杂,当α>2时,1DSP的输出表现出较高的混沌行为。
2) 放电体多变换更新
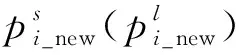
具体地,当前放电体先经过旋转变换邻域搜索得到一个中间放电体,如果中间放电体的能量值优于当前放电体,再进行平移变换和邻域搜索得到调整后的放电体,否则中间放电体将成为调整后的放电体,旋转、平移的表达式[14]如式(6)和式(7)所示。
(6)
式中:p为放电体;γ>0为旋转因子;n为放电体维数;R为n*n维,元素取值在[-1,1]之间均匀分布的随机矩阵;‖·‖2为向量2-范数或欧式范数。
(7)
式中:δ>0为平移因子;R是一个元素取值在[0,1]之间均匀分布的随机数。
3) 随机交叉
LSA算法的一种交叉方式是生成一个通道与原通道对称,两通道梯级先导能量值求和永远为上下限之和,式(8)中加入随机数增加了生成通道中放电体的不确定性,有利于扩大搜索区域。
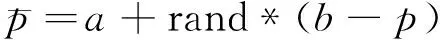
(8)
2.2 FSLSA
Song等[15]考虑到了类别分布不均匀的情况,提出了改进的Fisher Score方法,将类间散度定义为特征的平均类间距离,如式(9)所示。
(9)
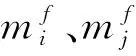
通过样本方差求和得到类内散度,如式(10)所示。
(10)
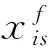
特征的Fisher Score值通过式(11)求出。
(11)
根据F值先剔除少数不敏感特征,再在保留特征上使用SLSA方法,求得最终的特征子集,记为FSLSA方法。
3 实验流程
3.1 冷水机组故障数据
实验数据来源于ASHRAE 1043研究项目,项目在一台90 t(316 kW)的冷水机上模拟引入7种故障,分别是冷却水流量不足(F1)、冷冻水流量不足(F2)、制冷剂泄漏(F3)、制冷剂过量(F4)、润滑油充注量过多(F5)、冷凝器污垢(F6)和不可冷凝(F7)。项目模拟了4种故障严重程度,其中故障等级1的模拟引入方法如表1所示。

表1 7种典型故障的模拟方法
数据采集的时间间隔为10 s,每种故障采集了5 191组数据,从中选取800条。因此7种故障总共有5 600条数据,按照7∶3的比例划分为训练集和测试集。指示故障的特征共有65个,其中包含温度特征30个、压力特征5个和流量特征5个等。65维特征参数中有 49个直接来源于传感器,其他通过计算得到,针对不同的参数传感器又可以分为温度传感器、压力传感器等,例如冷凝环路中传感器的安装位置如图1所示,S1、S2…S11分别代表一个传感器。
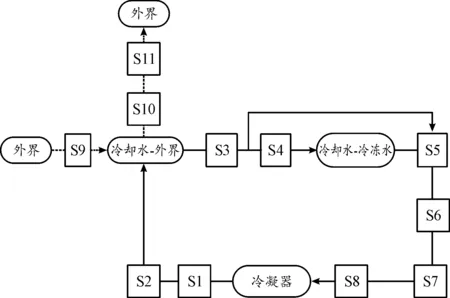
图1 冷凝环路传感器位置示意图
3.2 FSLSA基本实现
本文中提出的FSLSA是一种数据集特征选择方法,将SLSA与Fisher Score结合起来,在训练集上计算出所有特征的Fisher Score值,设置一个较小的阈值,如果某特征的Fisher Score值<阈值则剔除,反之则保留。在SLSA中,将放电体维数设置为Fisher Score保留的特征数+1,为每一维特征初始化一个权值,权值越高则表示其对应的特征对故障类别越敏感,多出来的一维则是特征数k,权值都介于放电体的上下限之间。实验将使用频率较高的分类错误率[16]作为SLSA的目标函数值,利用libsvm库[17]计算在测试集上的错误率,分类错误率越低,表示能量值越优。SLSA每次迭代过程中需要对k按比例放大、四舍五入,如式(12)所示,得到应选特征个数,A(n)是权重向量最后一维的值,num_features是Fisher Score保留的特征个数,round()表示四舍五入。
k=round(A(n)*(num_features-1)+1)
(12)
SLSA将特征个数k与特征权重一起优化,每次迭代按权值由高到低的顺序选择出k个特征,用这些特征去求得目标函数值,SLSA不断优化求解,直至收敛。根据此时的特征权值和特征个数得到最终的特征子集。FSLSA实现的总体流程如图2所示,其中SLSA在使用1DSP生成过渡放电体时,需要将初步生成后的放电体每维取值归一化到上下限之间。
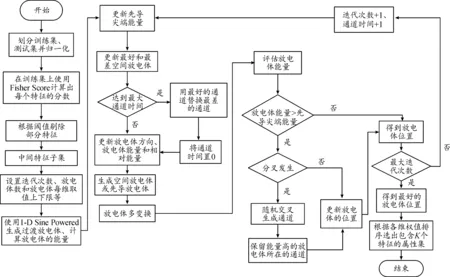
图2 FSLSA进行特征选择流程框图
4 实验及结果分析
4.1 使用FSLSA算法选择UCI数据集特征
为了验证FSLSA算法的性能,随机选取了7个常用的UCI数据集,数据集的特征数目、样本个数等信息如表2所示。将其同样按照7∶3的比例划分为训练集和测试集,并与所使用的Fisher Score方法、LSA、鲸鱼优化算法(whale optimization algorithm,WOA)[18]以及MRMI[19]方法进行比较。
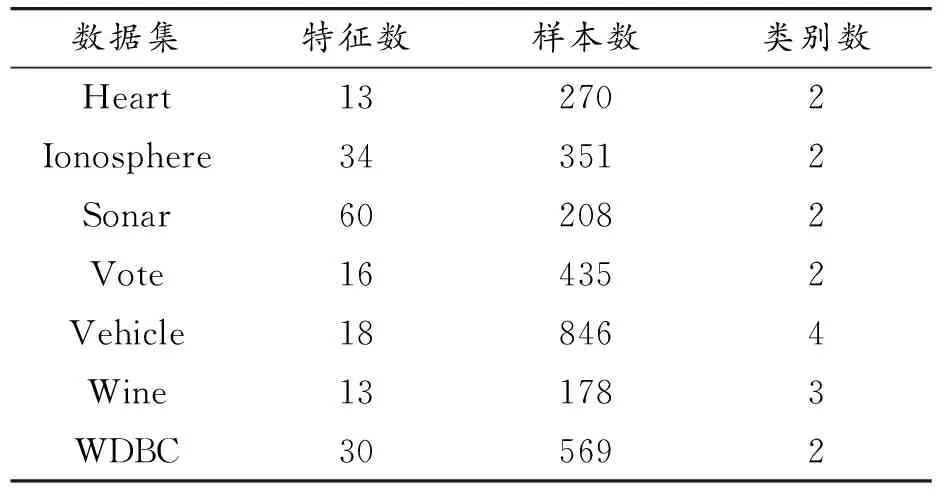
表2 UCI数据集基本信息
图3、图4和图5是为了对SLSA的收敛特性进行分析,使SLSA、LSA、WOA在Heart、Ionosphere、Sonar数据集上的迭代次数、种群数目、每维取值上下限等条件完全一致,运行了20次,取结果的均值绘制的收敛曲线,横坐标为迭代次数,纵坐标为分类错误率。
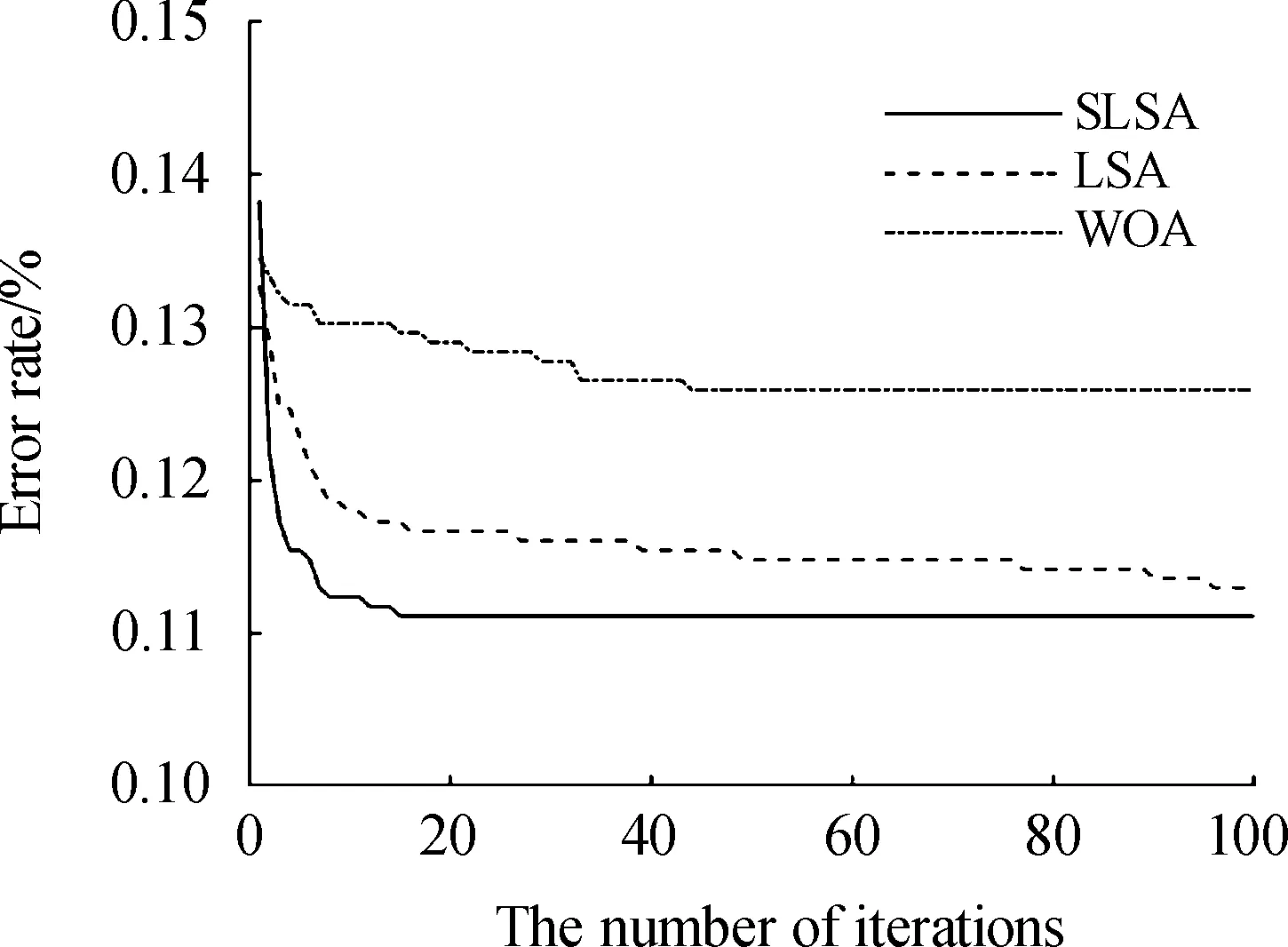
图3 SLSA、LSA和WOA在Heart上的迭代过程曲线
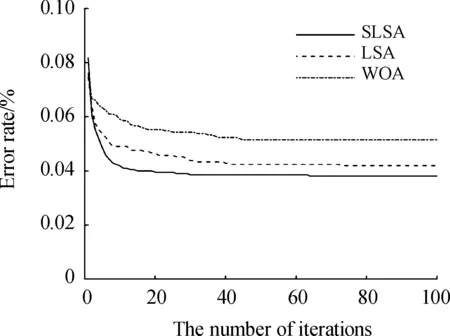
图4 SLSA、LSA和WOA在Ionosphere上的迭代过程曲线
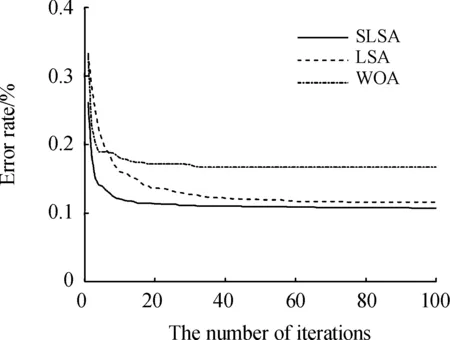
图5 SLSA、LSA和WOA在Sonar上的迭代过程曲线
SLSA方法对比基本的LSA、WOA求得的错误率更低。另外,在Vehicle和WDBC 2个数据集上也是如此,在Vote和Wine数据集上错误率优势不明显。
FSLSA与这几种方法在UCI数据集上选出来的特征子集维数(num)、在特征子集上得到的分类准确率(acc)如表3所示。从表中可以看出,这几种方法都从不同程度上减少了原始数据的维度并保证了分类准确率,所提的FSLSA算法相较于其他算法有明显优势,在所有的数据集中都达到了最高的准确率。
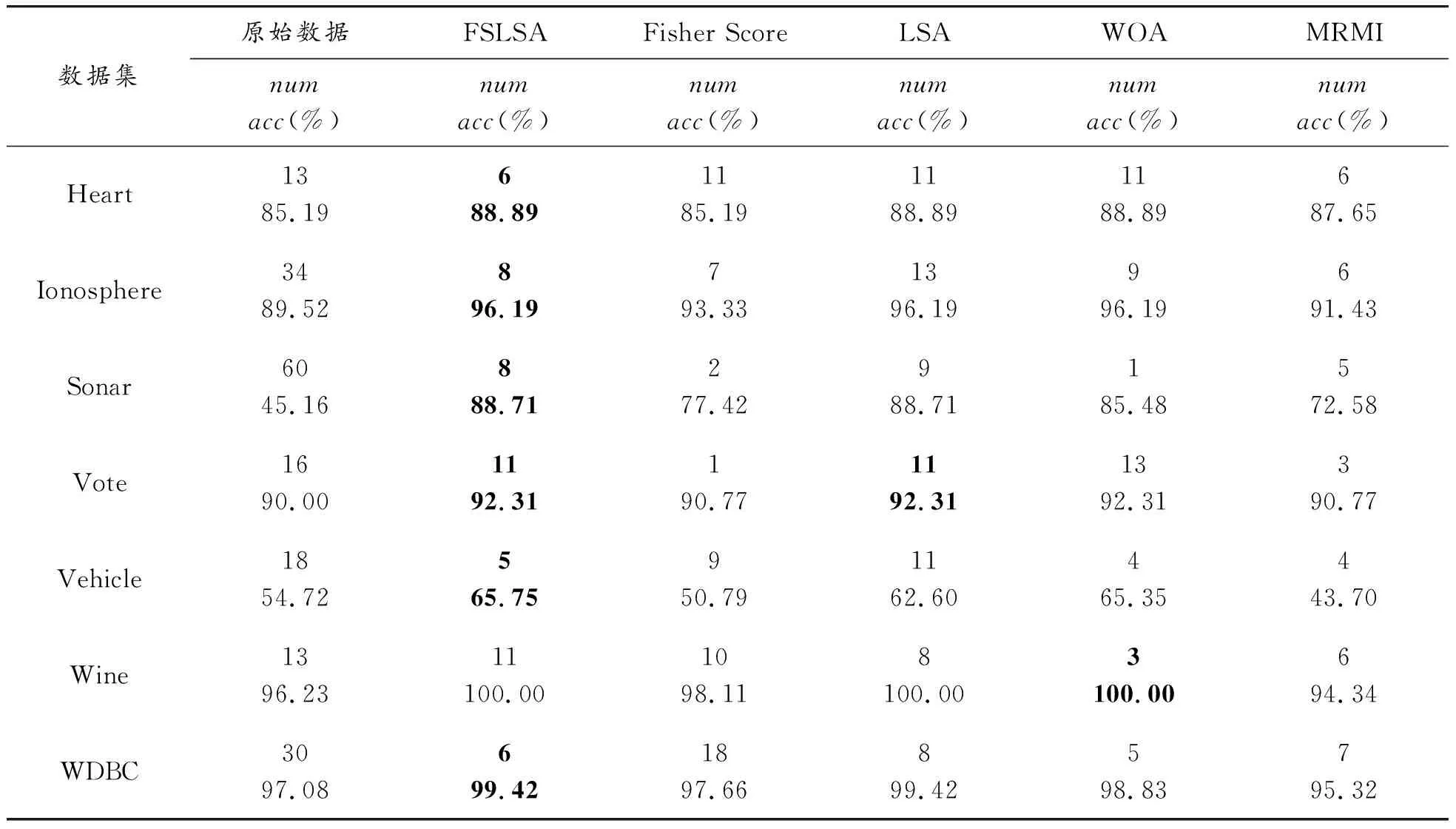
表3 不同方法在UCI数据集上特征选择的结果
相较于基本的LSA算法,在保证数据集准确率不变的情况下,FSLSA减小了大部分数据集所需的特征维数(即Heart、Ionosphere、Vehicle和WDBC),尤其是在Heart数据集上,将其特征维数减到6,是所有方法中维数最低但是准确率最高的,可以看出FSLSA有效缩减了计算开销、降低了特征的冗余性。相较于MRMI和Fisher Score,FSLSA增加特征数所带来的准确率提升是值得的。在Ionosphere数据集中,FSLSA选择8个特征,完成了96.19%的准确率,远高于MRMI(6特征数)的91.43%和Fisher Score(7特征数)的93.33%。在Vote数据集中,FSLSA选择11个特征,完成了92.31%的准确率,而选择3个特征的MRMI为90.77%,同样远高于选择1个特征数的Fisher Score(90.77%)。
4.2 FSLSA算法选择冷水机组故障特征
在已经划分好的训练集上使用Fisher Score对特征进行初选,求出冷水机组65维特征的Fisher Score值,其中有50多维特征的Fisher Score值介于0~0.1,因此将阈值设置为0~0.1的某个数,经过多次实验验证,发现阈值为0.03时选出的特征数较少且诊断准确率较高。此时65维特征保留了31维,包括TWE_set(蒸发器设置)、TEI(蒸发器侧进水温度)和TEO(蒸发器侧出水温度)等。SLSA算法的一些参数设置及含义如表4所示。
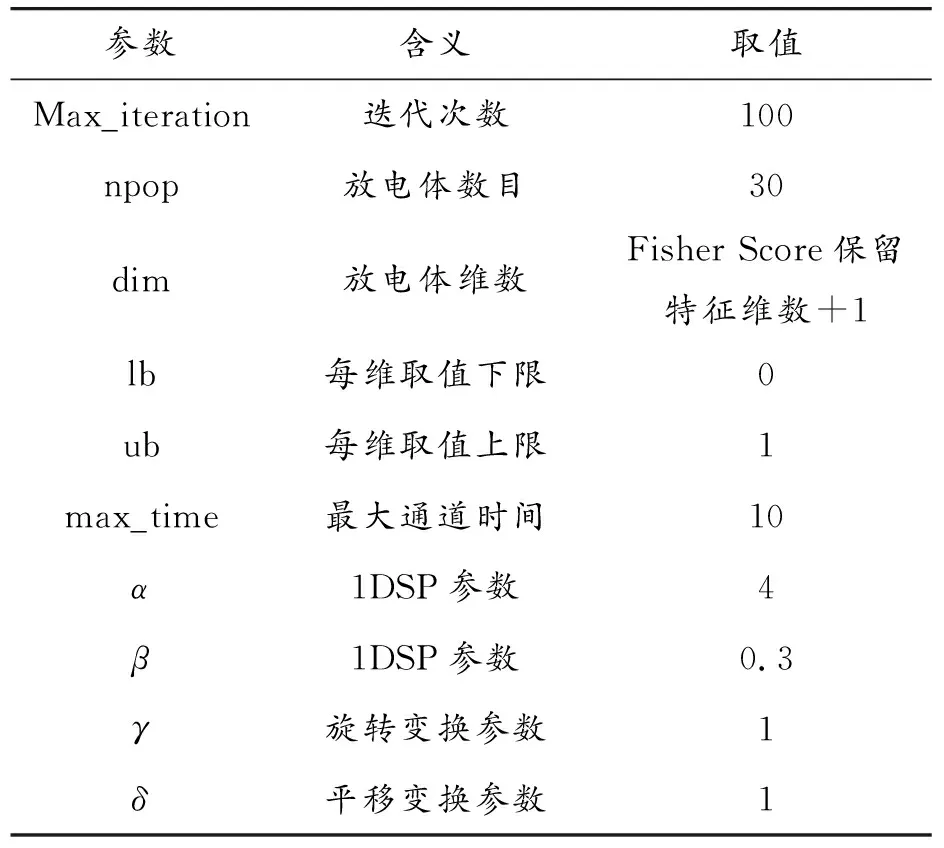
表4 SLSA算法参数设置
SLSA迭代过程的收敛曲线如图6所示,横坐标是SLSA的迭代次数,纵坐标为故障诊断错误率,仅经过大概6次迭代,曲线降到最低、逐渐平稳,这说明SLSA的收敛速度较快;收敛后的最小值等于0,这意味着,在测试集上libsvm的诊断准确率达到了100%。
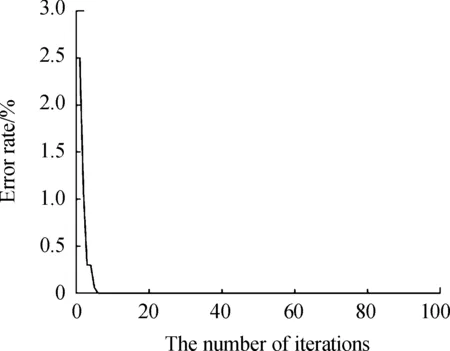
图6 SLSA迭代过程曲线
由FSLSA求得的特征权重介于0.11~0.78,得到的特征子集最终包含13个特征参数,按照权值对其进行排序,特征参数及其含义如表5所示,13个参数中,有9个温度参数、2个压力参数和1个阀位参数。
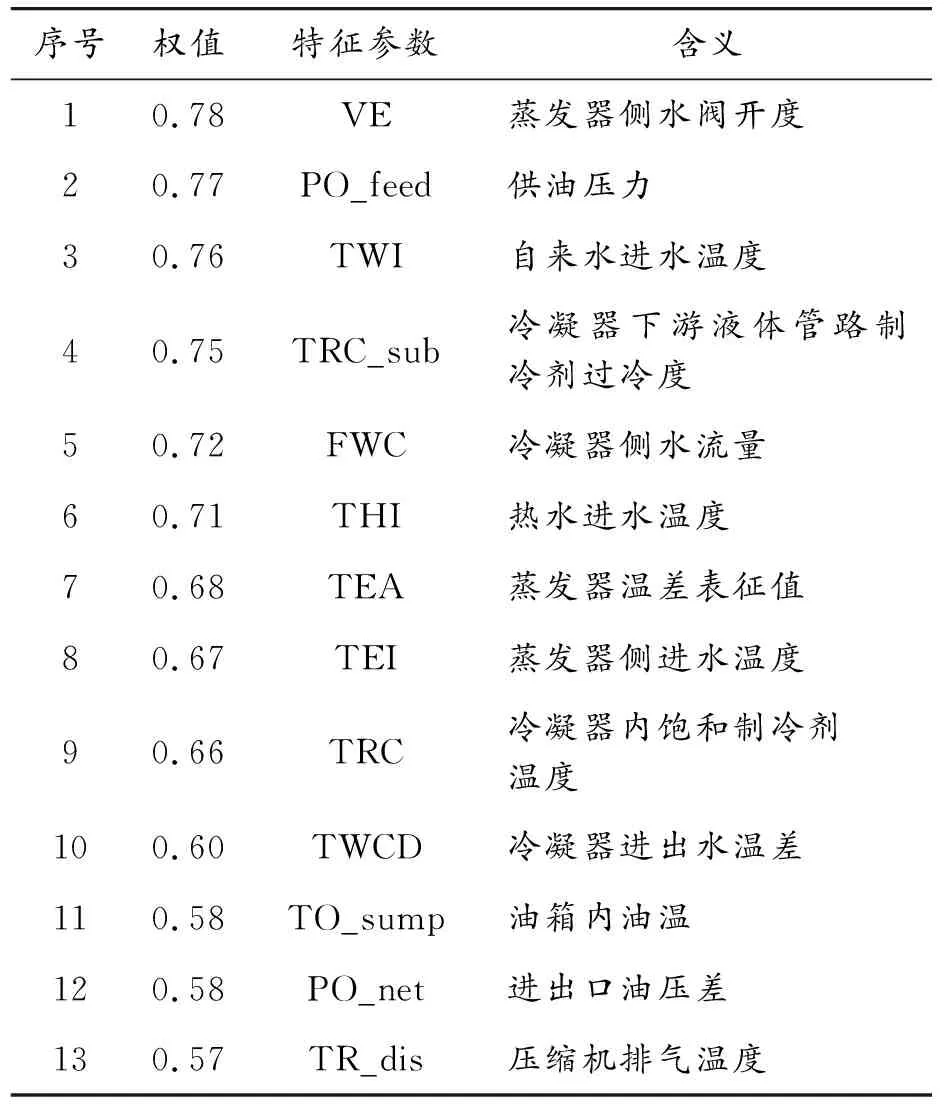
表5 冷水机组最终特征子集
4.3 验证冷水机组特征子集的有效性
从5 600条故障数据中依次选择表4中的特征参数,组成维度为5 600*14的特征子集,其中第一列为故障的类别标签。使用KNN、RF、BP和GRU[20]4种方法,方法的一部分参数设置见表6,将特征子集按照7∶3的比例划分为训练集和测试集,得到7种故障的诊断准确率,与原始的冷水机组故障数据进行对比,结果如图7和图8所示,图中横坐标为7种故障,纵坐标为单类故障诊断准确率。图7中KNNfull表示在原始特征上使用KNN方法得到的单类故障诊断准确率曲线,KNNsub则是KNN在所选特征子集上的单类故障诊断准确率曲线,其余方法类似。从图中可以看出,采用特征子集后,KNN和BP对某些故障的识别精度有明显提升,尤其是采用KNN方法时,F3(制冷剂泄漏)和F4(制冷剂过量)的故障诊断精度提高了10%以上;RF和GRU方法的诊断精度虽然没有明显改善,但相对更为稳定,平均准确率有所提高。
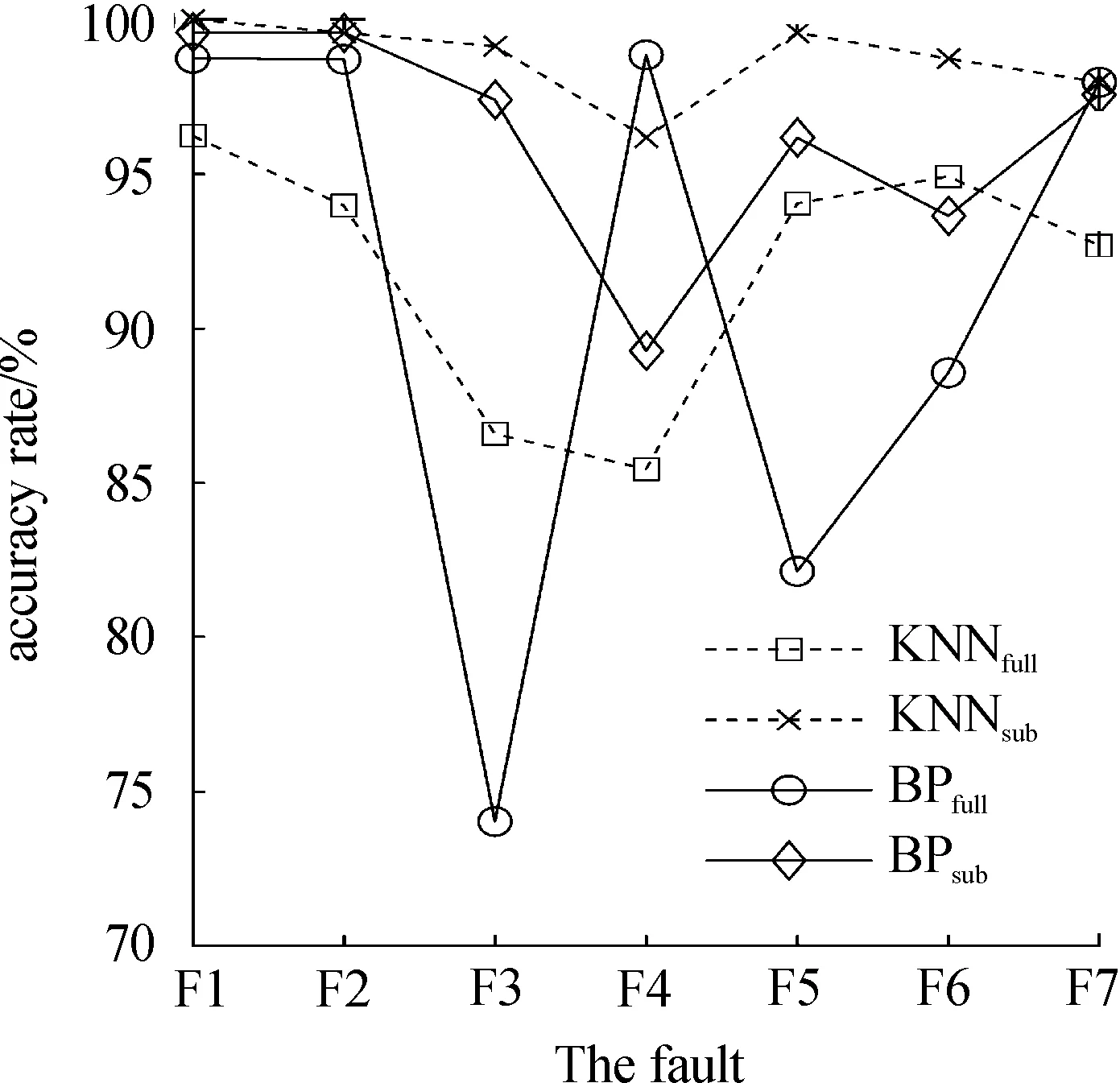
图7 KNN和BP故障诊断曲线
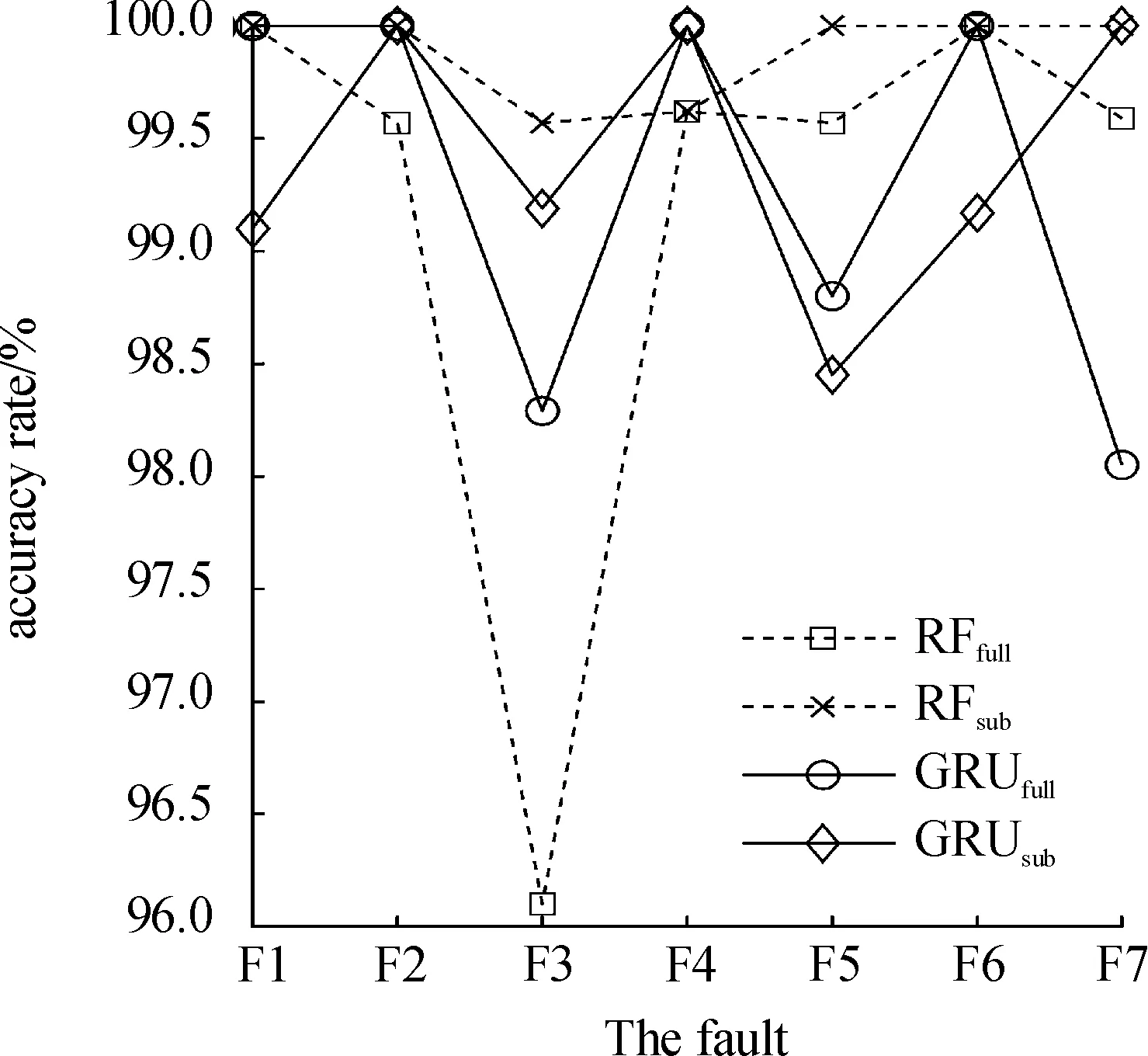
图8 RF和GRU故障诊断曲线
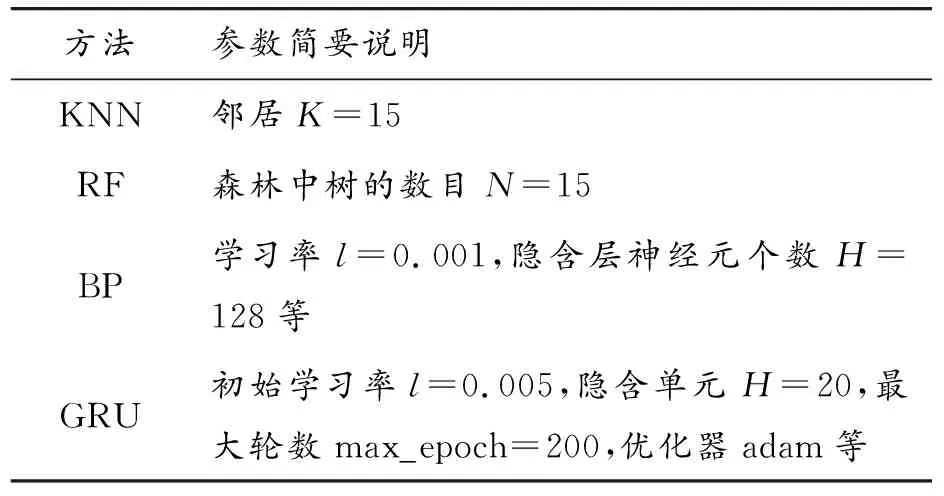
表6 KNN、RF等方法的超参数
F3代表制冷剂泄漏,是冷水机组应用中发生频次最高的故障,而选用特征子集的4种方法对该故障的识别精度均有明显提高,极具现实意义,在实际生产中能够有效预防意外的发生。另外,从图中可以观察出,在特征子集上这7种故障的识别精度变化范围更稳定。可以看出,使用FSLSA方法对冷水机组进行故障特征选择,去除了一些弱相关特征数目,避免弱相关特征数目过多,误导诊断模型。也去掉了故障特征中很大一部分的冗余信息,例如压缩机功率、性能系数和建筑进水温度等,从而提高模型的诊断精度。
5 结论
1) 通过在UCI数据集上进行对比实验,改进的闪电搜索算法(SLSA)选择的特征子集维数较少,准确率较高。
2) 使用Fisher Score对冷水机数据集进行特征选择,不仅使SLSA选出来的特征数目更少,而且大大缩短了SLSA算法的运行时间。要注意的一点是,Fisher Score的阈值设置不应过大,否则会导致SLSA选择的特征信息不充分,降低故障诊断的准确率。
3) FSLSA选出的13个特征参数中大部分是温度参数,因此,工作人员可以多多留意冷水机组工作过程中的温度变化,及时发现故障。
4)在使用KNN、RF、BP和GRU对所选的特征子集进行验证时,发现在RF和GRU上测得的故障诊断精度较高,在设计冷水机组故障诊断模型时,可以考虑优先使用RF或者GRU。
