基于ASPP-SOLOv2 的复杂场景下透明玻璃仪器实例分割
2023-02-24葛建统祝模芮冉进业
葛建统, 杨 鑫, 祝模芮, 冉进业, 翟 持, 张 浩
(1. 重庆理工大学 化学化工学院, 重庆 400054; 2. 布达佩斯技术与经济大学 电气工程与信息学院,布达佩斯 1111; 3. 西南大学 计算机信息与科学学院, 重庆 400715; 4. 昆明理工大学 化学工程学院,云南 昆明 650500; 5. 西南大学 化学化工学院, 重庆 400715)
1 前 言
全自动化学实验设备不仅避免重复劳动、操作失误和实验事故,而且能够尝试高危、高毒等极端条件实验。当前已存在较多自主化学实验设备[1]或者利用图像分析技术对系统内部进行特性判别[2-3]与流型辨识[4]来辅助实验。准确识别并操作玻璃仪器是化学机器人视觉系统必须解决的任务[5-6]。
由于实验室仪器繁多且排列紧密,识别对象高度重叠,遮挡导致的非自然物体边界和物体真实轮廓在语义上难以区别,进一步加大了实验室透明仪器实例分割的难度。作为物体检测和语义分割的有机结合,基于掩膜区域的卷积网络(Mask R-CNN)[7]、混合底层和高层信息的方法(BlendMask)[8]、搜索识别网络(SINet)[5]和一种动态快速实例分割2.0 版(SOLOv2)[9]方法等模型利用卷积核自动提取目标图像特征,在实例分割领域很成功,但通用的模型直接用于玻璃仪器实例分割效果尚有较大提升空间。针对透明目标的检测,部分研究[10-12]利用深度相机和超声波传感器等多传感器融合经典视觉辅助系统获取透明目标光学与深度信号。Xu 等[13]利用光场线性、遮挡检测和几何关系信息从四维光场图像中分割出透明物体;Chen 等[14]利用多尺度编解码器网络和残差网络同时获取任意背景图像中透明物体的轮廓掩膜、颜色衰减掩模和折射流场;Xie 等[15-16]通过融合浅层特征和高级特征获取边界线索改进透明目标语义分割准确率,可准确识别其透明物体分割数据集(Trans10K)中94.14% 的目标;Zhang 等[17-18]针对生活场景的透明物体进行语义分割,在Trans10K 数据集的平均交并比达到75.14%。然而,上述模型的训练数据集容量小、背景语义不合理且目标相对独立:Xu 等[13]的数据集仅包含49 张图片和7 种物品;Chen 等[14]的数据集包含876 张真实图像和178 000 张合成图像,背景和目标物体不够自然;目前Trans10K 由11 类真实家庭场景的图像组成,包含10 428 张图片。针对化学实验室场景实例分割,Eppel 等[19]建立了包含2 187 张图片的化学实验室数据集并进行语义和实例分割任务,平均交并比达到0.80。然而,该数据集未能对透明容器进行细分且背景简单,不能满足实验室自主化设备的视觉系统要求。
为实现复杂场景下透明玻璃仪器实例分割,本研究建立了包含1 548 张复杂场景图像的实例级标注数据。SOLOv2 在COCO 数据集可以18 帧·s-1的速度实现38.8% 的掩模分割精度,在显著目标的实例分割任务中具备较好的实时检测性能,但在复杂场景下无法完整地定位透明目标,故以具备出色实时检测性能的SOLOv2[9]方法为基础,提出了基于空洞空间金字塔池化的分割模型(ASPP-SOLOv2),提高对密集重叠透明物体的实例分割精度。该模型利用空洞空间金字塔池化(ASPP)[20]与特征金字塔输出的特征部分进行自下而上融合后增强多尺度信息[21-22],可以改善透明仪器的几何、边缘等浅层信息和高层语义的表示能力,最终提升模型在复杂场景下对目标的分割能力。
2 复杂背景化学实验透明玻璃仪器数据集
由于当前公开数据集规模小、类别少且缺少实例标注,本研究依据微软公开的数据集(COCO)[23]的相关标准采集某大学化学类实验室工作场景图片,使用Labelme 软件进行完全标注,形成了1 548 张带有实例标注的化学类透明仪器数据集(CTG)。CTG 数据集地址:https://github.com/Pau0031/Chemical-Transparent-Apparatus-Research。该数据集包含三颈烧瓶、上嘴抽滤瓶、圆底烧瓶、容量瓶、样品瓶、离心管、塑料吸管、比色管、量筒、锥形瓶、广口瓶、烧杯、螺纹试剂瓶和盐水瓶共14 类,分别统计分辨率、实例大小比例和类别分布,并与Eppel 的数据集(Vector-LabPics)[19]中的透明容器进行比较,如图1 所示,图1(a)为类别对比;图1(b)为图像分辨率分布,px 为像素单位;图1(c)为实例占全图比例分布;图1(d)为单幅图像实例个数分布。

图1 CTG 数据集与vector-LabPics 数据集特征对比图Fig.1 Comparison of features between CTG dataset and vector-LabPics dataset
由于实验室性质限制,CTG 数据集中锥形瓶和容量瓶数目远多于其他实例。数据集的分辨率、实例大小比例和实例类别数量分布统计如下:
1、分辨率:高分辨率图像能够提供更多边界细节[24],图1(b)中CTG 数据集图像最大高度为4 060像素,最小为150 像素;最大宽度为2 905 像素,最小宽度为150 像素,其中包括大量的1 080 像素分辨率图像。与Vector-LabPics 数据集相比,CTG 数据集分辨率分布更为集中,原始图像特征方差更小。图像分布在不同的高宽比(h/w)之间,1 020 张图像集中在高宽比为(0.70,1.10)区间上,占总体比例较大,只有4 张图像在高宽比为(1.90,2.30)的区间上。
2、实例大小比例:为实现复杂场景下透明玻璃仪器实例分割,本研究所建CTG 数据集实例大小比例与Vector-LabPics 数据集较为一致。归一化后实例大小分布[25](基于800 像素×800 像素的分辨率)见图1(c),整个数据集中目标占整图的比例在0.01%~71.00%。其中像素区域小于322的实例有242 个,占比3.97%。像素区域介于322~962的实例有1 585 个,占比26.01%。像素区域大于962的实例有4 266个,占比70.02%。单幅图像平均实例个数为3.94,是Vector-LabPics 数据集平均实例个数的2.01 倍,单幅最高实例个数达到54,场景复杂度大幅提高,如图1(d)。从图中看出CTA 数据集与Vector-LabPics数据集有相似的分布范围。
3、实例类别数量:CTG 数据集中的实例共有6 093 个,且与Vector-LabPics 数据集的透明容器部分实例类别进行比较,如图1(a)。实例类别有4 个与Vector-LabPics 数据集相同。由于Vector-LabPics 数据集中烧瓶、容器和罐子等存在多目标交叉标注、多种不同类型的目标标注为1 类等问题,为了满足应用需求,在CTG 数据集新增10 个类别,使之更加接近实际实验室场景。
3 算法介绍
3.1 SOLOv2
动态快速实例分割(SOLO)[9]通过完整实例标注的有监督学习,引入实例类别概念对目标按位置进行分割,摆脱对边界框的精确检测和像素的分组处理。SOLOv2 在SOLO 模型的基础上引入掩膜学习和掩膜非最大抑制,大幅度提高了模型的推理速度。基于检测框的两阶段模型分割效果依赖于候选检测框的生成,这会影响模型的推理速度。相比两阶段模型,单阶段模型SOLOv2 在推理过程中免去了感兴趣区域的生成和目标框的回归,并优化后处理算法降低计算量以满足实时检测的需要,直接将输入图像映射到所需的实例类别和掩膜,该方法在COCO 数据集上以18 帧·s-1的速度实现38.8% 的掩模分割精度。所以本工作以SOLOv2 算法为基础,实现对化学类透明玻璃仪器的识别。
3.2 空洞空间金字塔池化
空洞空间金字塔池化在金字塔池化模块引入空洞卷积,采取并联式的空洞卷积弥补局部信息的丢失并获取远距离像素信息,捕捉多尺度上下文信息,即特征图上每个像素取值不仅考虑前一个卷积层上对应位置的参数,同时邻近像素的取值也会影响当前层该位置上的参数权重,提高复杂场景中重叠目标分割精度。通过具有不同感受野的多个并行空洞卷积层的计算,提取密集的特征映射并实现多尺度信息融合,有利于学习复杂场景中重叠目标之间的区别,网络结构如图2 所示。
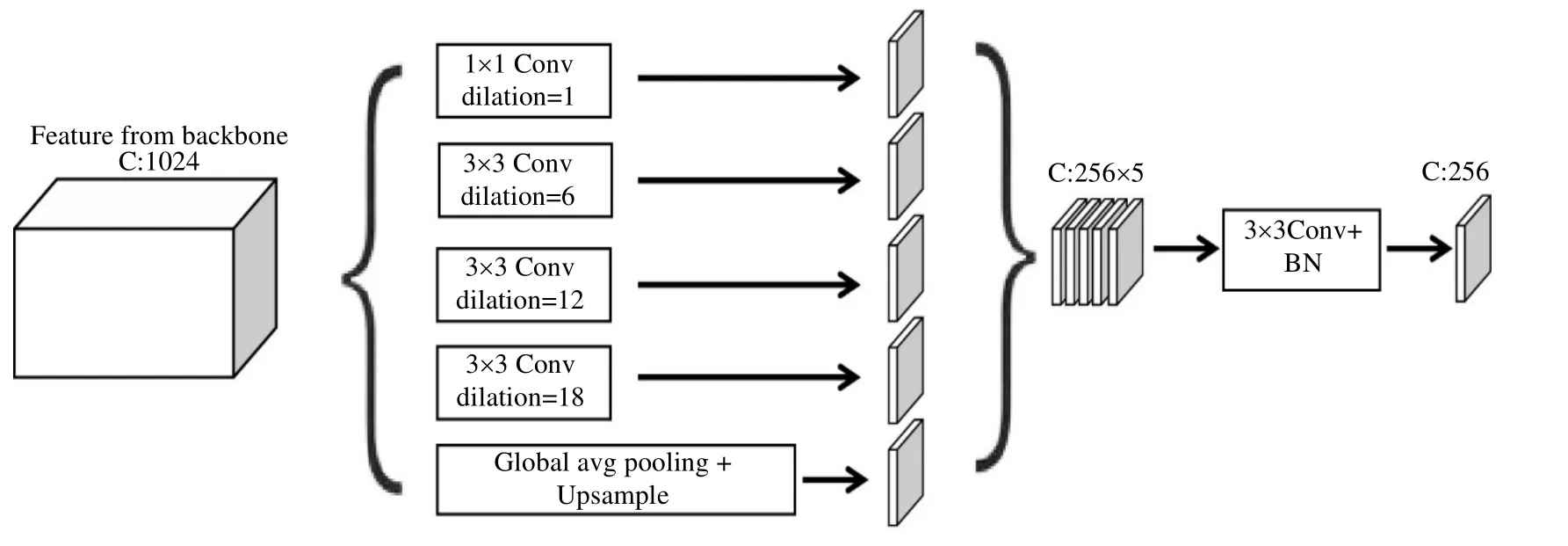
图2 空洞空间金字塔池化模块Fig.2 Schematic diagram of Atrous Spatial Pyramid Pooling Modules
3.3 ASPP-SOLOv2 模型结构
基于上述单阶段实例分割模型和空洞卷积的优点,本研究在SOLOv2 的骨干网络结构中引入ASPP 分支,并以自下而上的路径聚合方式进行合理的特征融合,提出ASPP-SOLOv2 模型来提高对密集重叠透明仪器的分割能力。该模型输入图像经过骨干网络和特征金字塔(FPN)提取特征信息,同时在骨干网络1/16 阶段,通过ASPP 在分辨率较大且图像边界细节信息充足阶段扩大感受野,提取多尺度信息。该信息与FPN 前4 层输出结果进行特征融合,经过3×3 卷积、批归一化和最大池化后输出的5 个不同尺寸的特征图,最终输入掩膜预测分支和类别预测分支产生实例结果,并用非极大值抑制方法筛选结果。
其中,骨干网络使用变体残差网络(Res2Net)加强细粒度特征的提取。通过引入ASPP 分支并将其结果上采样4 倍后,与FPN 输出的最底层特征图进行维度叠加。借鉴路径聚合网络[21]的设计理念,为了更好地结合浅层特征和高层语义特征,将叠加后的特征图经过1×1 卷积降维后,与更深层特征进行维度叠加和特征融合,如图3 所示。这样可以使模型更准确地表示透明仪器的多尺度复杂特征,有利于下一阶段的预测输出。掩膜预测分支取FPN 前4 层特征进行卷积,分为掩膜特征分支和卷积核学习分支,通过产生相同数量的特征图和卷积核,将二者相乘得到实例掩膜预测结果。同时,对FPN 输出中最高分辨率和最低分辨率特征图分别进行2 倍双线性插值下采样和上采样后,由实例类别预测分支产生实例类别。根据实例中心在网格的位置映射实例掩膜结果和实例类别之间对应的关系,最终输出实例预测结果。
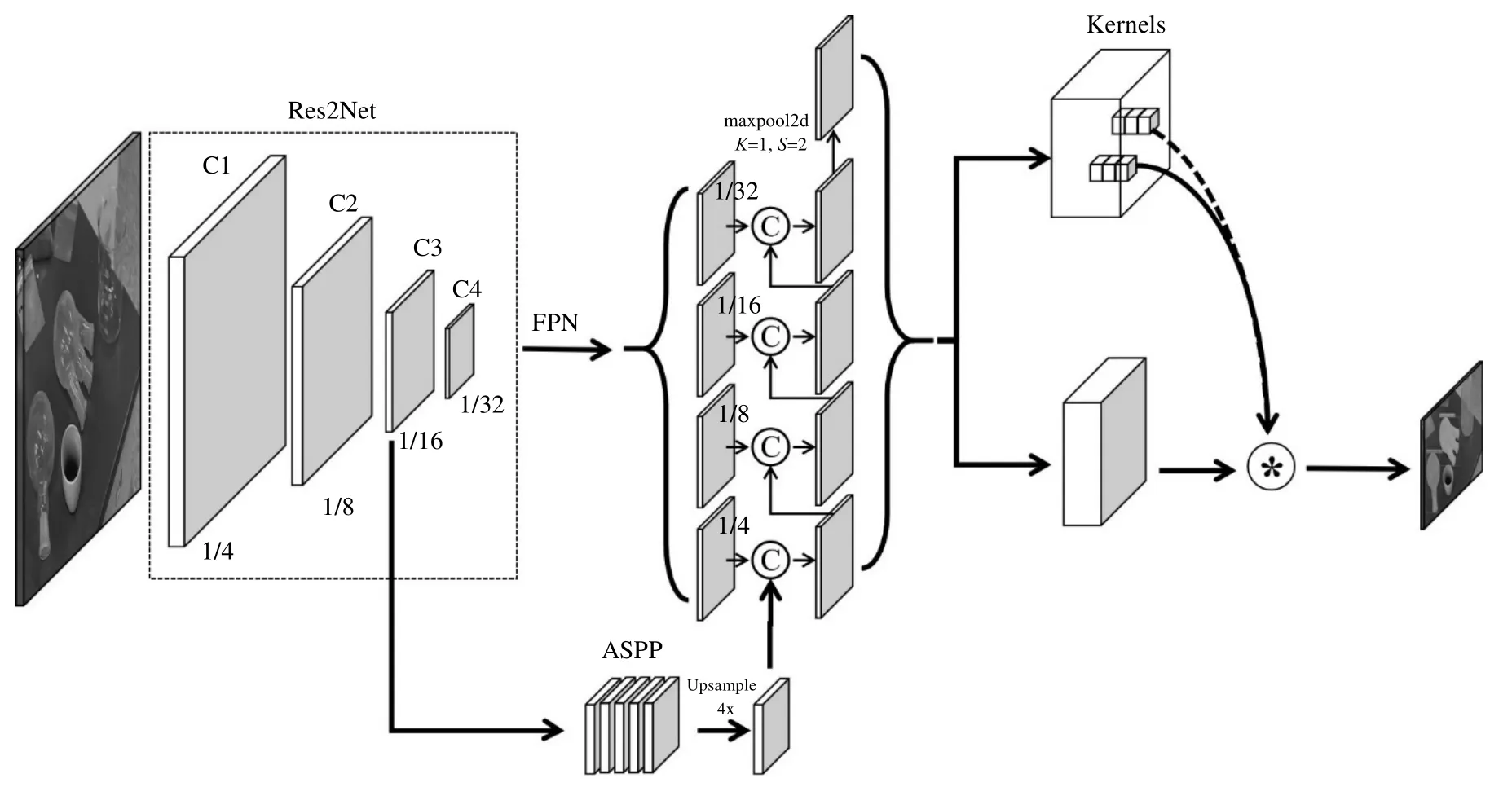
图3 ASPP-SOLOv2 结构示意图Fig.3 Schematic diagram of the framework of ASPP-SOLOv2
3.4 损失函数
模型损失函数L由分类损失Losscate和掩膜损失Lossmask构成,见式(1):
其中,分类损失Losscate为焦点损失函数[22],见式(2);掩膜损失Lossmask见式(3);超参数λ为掩膜损失权重,设置为3,与原始方法保持一致。
式中:Labels 为真实标签;σ(p)为预测类别经过激活函数计算后的结果;超参数α和γ分别默认为0.25和2.0。
式中:I为布尔型变量,i= [k/S];j=kmodS;k为正样本的全局序号;i为该样本所处的通道号;j为该样本在该通道的网格单元位置;S为网格单元数;Npos为正样本数;p和q分别为预测掩膜和真实掩膜;如果pi,j> 0,则I为1,否则为0;[ ]表示取整运算,mod 为取余数运算。
LossDice(p,q)是用于评估2 个样本相似性的度量函数,如式(4)所示:
式中:p(x,y)和q(x,y)分别为p和q中位于(x,y)处的像素值。
4 透明玻璃仪器的实例分割预测
4.1 评价指标
本研究采用基于交并比(IoU)的平均精确率(AP)和平均召回率(AR)评估模型性能。计算公式如式(5)~(7)所示。
式中:NTP为被正确检测出来的正样本数量;NFP为误检数量;NFN为漏检数量;N为类别数;APav为多类别AP 均值。
依据COCO 数据集标准,定义像素区域小于322的目标为小目标,介于322~962的目标为中型目标,大于962的目标为大型目标。精确率AP 为召回率曲线与坐标轴所围成的面积,面积越大模型性能越好。APav也是衡量模型性能优劣最重要的一个性能评估指标。本研究选取交并比IoU 阈值为0.50 和0.75 时得到的平均精度AP0.50和AP0.75,以及IoU 阈值介于0.50~0.95 时得到的平均精度APav衡量模型分割的效果,对分割精度依次表示为APS、APM、APL。平均召回率AR 表示对正样本预测正确的数量与所有预测为正样本数量的比值在所有类别的均值,可用于衡量模型的性能。
4.2 训练策略
为了验证方法有效性,论文训练集包括1 393 张图像,测试集为155 张。本工作硬件环境为NVIDIA- GeForce RTX 3060-12GB,AMD Ryzen 9 3950X 16-Core Processor 3.50 GHz,内存64.0 GB。软件环境为Paddlepaddle。训练批量设置为2;初始学习率为10-3,在第18 阶段降至10-4,第33 阶段降至10-5,第44 阶段为10-6;空洞空间金字塔池化模块的各层空洞设为[1,6,12,18]。在预处理阶段,使用随机分辨率缩放策略将输入图像缩放至640~800 像素。本研究使用COCO 数据集上ResNet50、ResNet101、Res2Net50 网络权重作为预训练参数。
4.3 实验结果
基于本工作提出的数据集,同时训练了不同规格的SOLOv2、BlendMask 和Mask R-CNN,最终均达到收敛,模型结果见表1。相比于Mask R-CNN 对化学实验透明玻璃容器的先检测再分割,SOLOv2 在目标物体局部区域的分割相对精细。采用Res2Net50 FPN 主干网络的SOLOv2 比主干网络为ResNet50 FPN 的SOLOv2 模型在APav和AP0.75更为优秀,平均精度达到67.3%,比后者高7.1%。其主要原因为Res2Net50 利用层次残差连接方式替换通用的3×3 卷积核,可以在更细粒度级别上表达多尺度特征,经过特征融合提高网络复杂度和性能。随着网络深度的增加,SOLOv2(ResNet101_FPN)的平均精度达到75.2%,比SOLOv2(Res2Net50_FPN)的平均精度高了7.9%。由于BlendMask 不仅融合了FPN 的高低层信息,还利用该结果与有效的边界框预测结果产生感兴趣区域,将具有不同注意力权重的特征信息进行叠加,生成实例预测区域,对小目标的分割精度更为有利。为了在边界细节信息丰富且分辨率较大的图像提取特征,在Res2Net50 的1/16 大小的特征图上使用ASPP 模块提取多尺度信息,通过自底向上的方式获取底层的定位信号,增强整个特征层次结构,ASPP-SOLOv2 实例分割APav上可达76.0%,比SOLOv2(ResNet101_FPN)高出 0.8%,网络的整体参数降低了 6.8 MB。用 ResNet101_FPN 作为ASPP-SOLOv2 的Backbone 后APav为75.8%,参数量为82.6 MB,其参数量比以Res2Net50_FPN 作为Backbone 的ASPP-SOLOv2 增加20.8 MB。虽然骨干网络的深度可以影响图像的基础特征提取的效果,但是对这些特征的合理加工和利用是下一步定位和分割的关键。故ASPP-SOLOv2 在引入ASPP 模块后,通过自下而上融合手段增强多尺度信息,在骨干网络卷积层数较少的情况下,弥补对透明物体的特征提取能力不足。这表明在纵向卷积层数较少的情况下,原始方法对透明物体的检测能力不足,但是通过侧边连接方式来增强特征是可行的,之后可以探索更好的方案。

表1 实例分割对比结果Table 1 Comparison of mask AP in instance segmentation with different net-structures
模型预测可视化结果如图4 所示,SOLOv2(ResNet50_FPN)和SOLOv2(Res2Net50_FPN)不能精确分割锥形瓶和烧杯重叠区域,在实例像素的分配上存在误差,然而主干网络为ResNet101_FPN 的SOLOv2模型可实现精确分割且产生正确边界框。得益于根据实例位置和大小为实例中每个像素分配类别的设计理念,ASPP-SOLOv2 在近距离检测和分割玻璃仪器方面,明显比Mask R-CNN 更具优势,如图5 所示。故ASPP-SOLOv2 比Mask R-CNN 的平均分割精度高5.5%,略高于BlendMask,总体上分割精度较高。

图4 不同骨干网络下SOLOv2 的分割结果Fig.4 Segmentation results of SOLOv2 under different backbone conditions

图5 实例分割结果可视化结果对比Fig.5 Comparison of instance segmentation visual results
4.4 消融实验
为研究ASPP 模块及其位置对模型实例分割效果的影响,本研究进行了如下消融实验:删除ASPP 模块,保留路径聚合并将FPN 输出的1/4 阶段时的特征图通道数由3×3 卷积调整为原来的2 倍;使用ASPP对骨干网络中C1、C2、C3 和C4 特征进行计算(C1、C2、C3 和C4 分别表示相较于原图像尺寸1/4、1/8、1/16 和1/32 的输出阶段,见图3),比较ASPP 对不同阶段的特征提取对ASPP-SOLOv2 的影响,结果见表2。
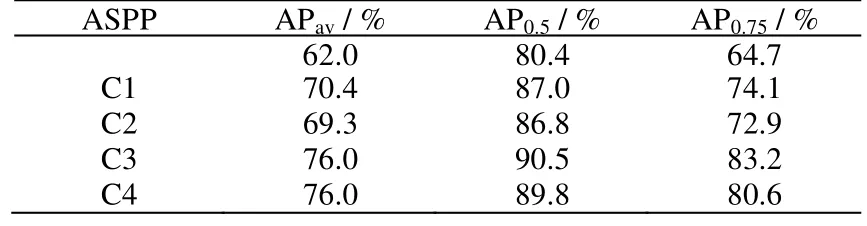
表2 ASPP 模块应用于模型不同阶段的效果对比Table 2 Effects of applying ASPP modules at different model stages
从表中可以看出,去掉ASPP 模块后,模型平均分割精度为62.0%,相比ASPP-SOLOv2(76.0%)性能降低18.42%,是因为该方案仍然保留了后续的自下而上的侧向连接和下采样,对FPN 的输出结果进一步融合,意图向深层传递浅层位置信息,性能下降5.3%。结果表明,缺少ASPP 分支提取的特征,对FPN输出的多尺度特征进行反复融合,反而会使模型的性能下降。实验表明该模块的加入可大幅度提高对透明玻璃仪器的分割精度。随着ASPP 模块加入位置的后移,模型AP0.5和AP0.75呈现余弦波动趋势并于C3 阶段达到顶点,其主要原因是图像尺寸在卷积过程中不断缩小,产生高级语义信息的同时丢失大量的浅层信息,两类信息对实例分割精度的影响在C3 阶段形成最佳组合,如图6 所示。

图6 不同阶段下,ASPP 输出结果的特征可视化Fig.6 Feature visualization of ASPP output under different stages
5 结 论
为实现复杂场景下透明玻璃仪器的实例分割,本研究提供了包含1 548 张化学实验室内日常拍摄的透明玻璃仪器实例级别标注的数据集,利用空洞空间金字塔池化强化SOLOv2 模型对透明仪器多尺度特征的提取,改善密集重叠情况下的特征表示,提高目标分割精度。 提出的ASPP-SOLOv2 模型的APav达到76.0%,AP0.5为90.5%,AP0.75为83.2%,相比于SOLOv2(Res2Net50_FPN)分别高出8.7%、4.3% 和11.0%。由于对小目标检测不佳,未来将考虑采用注意力机制解决远景小目标分割不准确的问题。
