基于特异性引物高效构建TALE 文库
2023-02-24蔡思杰张书衍王晓微郭显阳
蔡思杰, 张书衍, 王晓微, 郭显阳, 詹 硕
(1. 沈阳大学 生命科学与工程学院, 辽宁 沈阳 110044;2. 沈阳双鼎制药有限公司, 辽宁 沈阳 110179)
1 前 言
转录激活因子样效应物(TALE)是黄单胞菌分泌的针对特定DNA 序列的蛋白质[1-2]。TALE 家族成员包含一个高度保守和重复的区域,其与DNA 的结合能力取决于每个模块重复的第12 和第13 个氨基酸残基(即重复可变双氨基酸残基(RVD))。每个RVD 中都有一个简单的代码,用来指定对特定碱基的识别,这决定了TALE 核苷酸结合的特异性。例如,NI(Asn/Ile)对应A,NG(Asn/Gly)对应T,HD(His/Asp)对应C,NH(Asn/His)对应G[3-5]。人工构建的带有功能域的DNA 结合域(DBD)补充的TALE 可应用于基因工程的许多方面,包括用于转录调控的转录因子(TALE-TF)[6-9]和用于基因组编辑的转录激活因子样效应核酸酶(TALEN)[10-12]。因此,TALE 在基因工程领域发挥了巨大的作用。
TALE 的脱靶率比目前热门的 CRISPR/Cas9(Clustered Regularly Interspaced Short Palindromic Repeats/Cas9)[13-15]要低,识别DNA 长度也较长;基因调控和编辑的位置不受前间区序列邻近基序(PAM)的限制;具有更低的非靶点结合能力,更低的细胞毒性,基于TALE 具有高靶向能力[16],所以,已由法国Cellectis 公司用于生产通用嵌合抗原受体T 细胞[17],并已被批准用于癌症免疫疗法。接受该基因编辑疗法的患者已显示出显著的治疗效果[18]。最重要的是,在设计和构建TALE 时,理论上可以靶向任何DNA序列。但是构建TALE 的方法比较繁琐复杂,而且构建的TALE 长度有限,容易脱靶。并且,大多数研究人员仍然使用软件来预测TALE 靶向的目标区域,然后构建一个有针对性的TALE。在这种情况下,需要构建更多的TALE,构建周期太长,效率偏低[19-21]。
本研究发明了一种新的简单的TALE 文库的构建方法,设计了一种可以轻松实现靶向较长DNA 序列的TALE 文库的方法。该组装方法是快速且标准化的,能够精确控制产生的RVD 和整体DNA 结合域的组成。而且研究人员可以直接将其作为实验材料,为TALE 研究人员节省了大量的时间。
2 材料与方法
2.1 材料
金门组装试剂盒来自Addgene;限制酶BsaI、牛血清白蛋白(BSA)、T4 DNA 连接酶、腺嘌呤核苷三磷酸(ATP)来自NEB 公司;质粒核酸安全酶来自Epicentre 公司;BsmBI 来自Thermo Scientific 公司;DH5α感受态细胞、壮观霉素、卡那霉素、X-gal、IPTG(Isopropyl β-D-Thiogalactoside,异丙基硫代半乳糖苷)来自南京源恩浩生物试剂;PrimeSTAR®GXL DNA Polymerase 高保真聚合酶混合液来自Takara 公司。
2.2 方法
采用基于金门组装试剂盒优化改进的新方法构建了18 bp-TALE-VP64 文库(bp 表示碱基对)。
第1 部分:构建含10 个串联重复序列(RVDs:NH1-NH10)组合的PFUS-A+10×NH 质粒。
步骤1(第1 天,3 h):第1 次金门酶切连接反应。将10 个RVD 构建模块质粒(NH1 到NH10)各加入150 ng 于0.5 mL 离心管中。然后,加入150 ng pFUS-A 质粒、1 µL BsaI、1 µL BSA、1 µL T4 DNA 连接酶、2 µL T4 DNA 连接酶反应缓冲液。然后加入蒸馏水,使总反应体积达到10 µL。
步骤2(第1 天,10 min):上述反应体系混合并短暂旋转,涡旋混匀30 s。
步骤3(第1 天,3 h):将反应体系在PCR 仪上孵育。孵育条件为37 ℃、5 min 和16 ℃、10 min 共计10 个循环,然后50 ℃、5 min;80 ℃、5 min。
步骤4(第1 天,1 h):反应体系(10 µL)加入1 µL 质粒核酸安全酶和1 µL 10 mmol·L-1ATP 在37 ℃下孵育1 h。
步骤5(第1 天,4 h):将步骤4 的反应体系转化到100 µL DH5α 中,加入溶菌肉汤(LB)液体培养基得到1 mL 该细胞悬液,涂布于LB 琼脂细菌培养皿(含有壮观霉素50 μg·mL-1和20 mg·mL-1X-gal) (X-gal是β-半乳糖苷酶的显色底物)以及0.1 mol·L-1IPTG,由于PFUS-A+10×NH,PFUS-B7+7×NH 和pLR-NH骨架质粒都具有壮观霉素抗性,所以,培养微生物大肠杆菌细胞DH5α,有抗性的说明质粒构建转染成功,没有转染成功的没有抗性,不会生长出菌落。
步骤6(第2 天,6 h):从培养皿上挑选几个白色菌落,并使用引物pCR8-F1 和pCR8-R1(表1)进行菌落PCR 检验。PCR 程序:96 ℃预变性3 min;96 ℃变性20 s,55 ℃退火20 s,72 ℃延伸2 min,进行30 个循环;72 ℃总延伸3 min,4 ℃保存。PCR 检测正确的菌落经过培养、提取,得到PFUS-A+10×NH质粒。
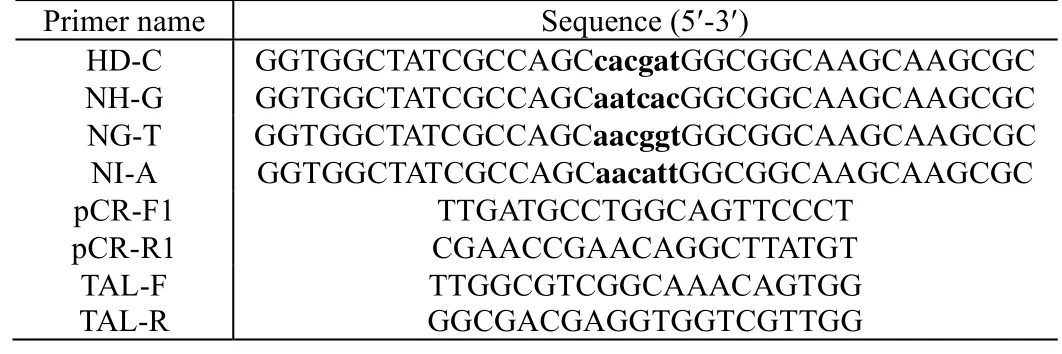
表1 质粒突变体和菌落PCR的引物Table 1 Primers for plasmid mutation and colony PCR
第2 部分:构建含有7 个串联重复序列(RVDs:NH1-NH7)组合的PFUS-B7+7×NH质粒。
步骤1(第1 天,3 h):取7 个RVD 构建质粒模块(NH1 到NH7)各加入150 ng,加入pFUS-B7 质粒150 ng、1 µL BsaI、1 µL BSA、1 µL T4 DNA 连接酶、2 µL T4 DNA 连接酶反应缓冲液。然后加入蒸馏水,使总反应体积达到10 µL。
步骤2(第1 天,10 min):反应体系短暂旋转混合,涡旋混匀30 s。
步骤3(第1 天,3 h):将反应体系在PCR 仪上孵育,孵育条件为37 ℃、5 min 和16 ℃、10 min 共计10 个循环;然后50 ℃、5 min;80 ℃、5 min。
步骤4(第1 天,1 h):反应体系(10 µL)加入1 µL 质粒核酸安全酶和1 µL 10 mmol·L-1ATP 在37 ℃下孵育1 h。
步骤5(第1 天,4 h):将步骤4 的反应体系转化到100 µL DH5α 感受态细胞。然后加入LB 培养基得到1 mL 细胞悬液涂布于LB 琼脂细菌培养皿(含有壮观霉素50 µg·mL-1和20 mg·mL-1X-gal 以及0.1 mol·L-1IPTG)。
步骤6(第2 天,6 h):从培养皿中挑选几个白色菌落,使用引物pCR8-F1 和pCR8-R1(见表1)进行菌落PCR 检测。PCR 程序:96 ℃预变性3 min;96 ℃变性20 s,55 ℃退火20 s,72 ℃延伸1 min,进行30个循环;72 ℃总延伸3 min,4 ℃保存。PCR 检测正确的菌落经过培养、提取,得到PFUS-B7+7×NH 质粒。
第3 部分:PFUS-A+10×NH 质粒突变体、PFUS-B7+7×NH 质粒突变体及pLR-NH 质粒突变体的构建。
步骤1(第3 天,3 h):PFUS-A+10×NH 质粒突变体、PFUS-B7+7×NH 质粒突变体、pLR-NH 质粒突变体均采用PCR 扩增得到,引物如表1 所示。利用HD-C、NH-G、NG-T 和NI-A 这4 种特殊引物(表1)对PFUS-A+10×NH 质粒、PFUS-B7+7×NH 质粒、pLR-NH 质粒分别进行PCR 扩增。3 个PCR反应(240 μL)均包含1 ng 质粒、10 μmol·L-1HD-C、10 μmol·L-1NH-G、10 μmol·L-1NG-T、10 μmol·L-1NI-A 和PrimeSTAR®GXL DNA Polymerase 高保真聚合酶混合液。PCR 程序:96 ℃预变性3 min;96 ℃变性20 s,58 ℃退火20 s,72 ℃ 延伸3 min,进行28 个循环;72 ℃总延伸3 min,4 ℃保存。PCR 产物用1% 琼脂糖凝胶电泳检测。PCR 产物经苯酚/氯仿萃取法纯化,用无水乙醇沉淀。PCR产物在水中重悬,3 种PCR 产物即PFUS-A+10×NH 质粒突变体、PFUS-B7+7×NH 质粒突变体、pLR-NH质粒突变体。
第4 部分:构建TALE-VP64 文库(RVDs:NH1-NH17 和pLR-NH)。
步骤1(第3 天,3 h):在20 µL 反应体系中,包括150 ng PFUS-A+10×NH 质粒突变体,150 ng PFUS-B7+7×NH 质粒突变体,150 ng pLR-NH 质粒突变体和75 ng TALE-backbone-VP64。加入1 µL BsmBI,1 µL T4 DNA 连接酶、2 µL T4 DNA 连接酶反应缓冲液。最后加入蒸馏水使总反应体积为20 µL。
步骤2(第3 天,10 min):该反应体系短暂旋转混合,涡旋混匀30 s。
步骤3(第3 天,3 h):将反应体系在热循环PCR 仪上孵育。热循环条件为37 ℃、5 min 和16 ℃、10 min,共计10 个循环;然后37 ℃、15 min;80 ℃、5 min。
步骤4(第3 天,4 h):将20 µL 的反应体系转化到200 µL DH5α 感受态细胞中。加入LB 培养基得到1 mL细胞悬液涂布于LB 琼脂细菌培养皿(含有卡那霉素50 µg·mL-1和20 mg·mL-1X-gal 以及0.1 mol·L-1IPTG)。
步骤5(第4 天,4 h):利用引物TAL-F 和TAL-R(表1)进行菌落PCR 实验,根据电泳条带鉴定阳性菌落。最后PCR 检测正确的菌落,过夜培养。
步骤6(第5 天,2 h):提取培养的菌液中的质粒为18 bp-TALE-VP64 文库质粒表达载体。
3 实验结果与分析
3.1 TALE 文库构建流程的建立
经过对金门法的优化构建了TALE 文库,详细流程见图1,此流程显示了构建TALE-VP64 文库的示例,该质粒文库可以结合18 bp DNA 长度的目标靶向位点。其中PFUS-A+10×NH 是一种由10 个单体质粒和一个骨架质粒PFUS-A 在第1 次酶切连接反应中制备的质粒;PFUS-B7+7×NH 是一种由7 个单体质粒和1 个骨架质粒PFUS-B7 在第1 次酶切连接反应中制备的质粒。因此,PFUS-A +10×NH 是表达与N1-N10 核苷酸结合的氨基酸的质粒载体,PFUS-B7+7×NH 是表达与N11-N17 核苷酸结合的氨基酸的质粒载体。编码与最后一个核苷酸(N18)结合的氨基酸的序列包含在另一个单体质粒(pLR-NH)中。第2 次酶切连接反应包含 4 个质粒,包括PFUS-A+10×NH 质粒突变体(PFUS-A+10×(NH,HD,NG,NI))、PFUS-B7+7×NH 质粒突变体(PFUS-B7+7× (NH,HD,NG,NI))、pLR-NH 质粒突变体(pLR-NH/HD/NG/NI)和TALE 骨架载体(TALE-backbone-VP64)(见图2,图中bp 为碱基对)。

图1 利用金门法基于4 种特异性引物构建TALE-VP64 文库的流程Fig.1 Flowchart of the construction of TALE-VP64 libraries by the Golden-Gate method based on new specific primers pipeline
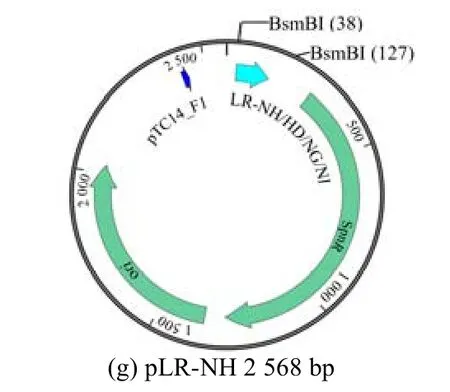
图2 质粒图谱及其组成Fig.2 Plasmids maps and their elements
另外,在构建过程中所使作的各种骨架质粒图谱(即突变前质粒)见图2 中PFUS-A+10×NH、PFUS-B7×NH、pLR-NH质粒。最后,预计构建成功的TALE-VP64 质粒文库具有转染各种细胞的能力,并可以激活下游基因的表达(见图3),Zhang 等[21]单独构建的TALE-VP64 质料转染293T 细胞,确实激活了绿色荧光基因ZsGreen,使绿色荧光蛋白高表达。TALE-VPR 质料转染HepG2细胞和PANCl 细胞,分别使得内源基因HNF4a 和E47 基因上调, 从而证实了TALE-VP64/VPR 强大的靶向和激活功能。TALE-VP64 文库中每个DNA 结合模块由34个氨基酸组成,其中每个模块的第12 和13 位氨基酸变化较大,其他氨基酸高度保守,这2 个不保守的氨基酸被命名为重复可变残基(RVD),RVD 氨基酸对应DNA 碱基之间的分子密码是NI 对应A、HD 对应C、NG 对应T、NH 对应G,所有的TALE 由N 末端的转移结构域(AD)组成(图3)。TALE 的末端转移结构域以及C末端的核定位信号和转录激活结构域具有高度的保守性,不同成员之间互换这些功能区域并不影响其正常发挥作用。TALE-DNA 结合域与合成的VP64 转录激活因子融合,该激活因子募集RNA 聚合酶和启动转录所需的其他因子,激活下游基因的表达(见图3)。
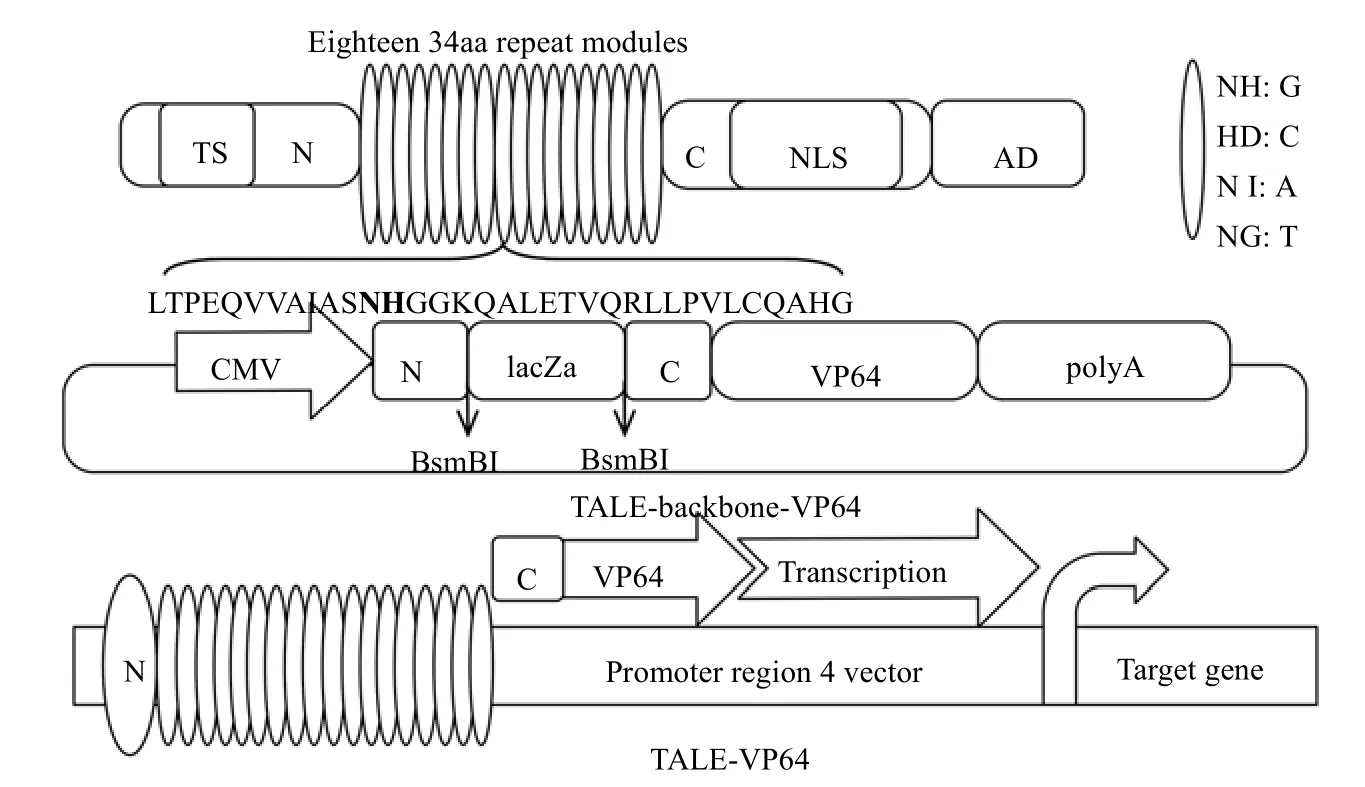
图3 用于基因组工程的TALE-VP64 文库Fig.3 The TALE -VP64 libraries for genome engineering
3.2 质粒和文库的菌落PCR 检测
第1 部分和第2 部分中从每个平板上选取白色菌落,使用引物pCR8-F1 和pCR8-R1 进行菌落PCR检验。条带应达到预期大小(PFUS-A+10×NH 质粒约12 kb、PFUS-B7+7×NH 载体约0.8 kb (kb 表示1 000 碱基对)),但一般不可能得到单一的条带,一般条带“阶梯”从约200 bp 开始,这是正确克隆的标志,是克隆中重复的结果[22](见图4 中1 和2 泳道)。

图4 质粒和菌落 PCR 产物的琼脂糖凝胶电泳结果Fig.4 Results of agarose gel electrophoresis of plasmid and colony PCR products
第 3 部分中用 4 种特异引物和长链高保真 DNA 聚合酶分别扩增 PFUS-A+10×NH 质粒、PFUS-B7+7×NH 和pLR-NH 质粒(见图4 中4、6、8 泳道),获得各个质粒载体突变体(见图4 中3、5、7泳道),由于质粒突变体实际是PCR 产物,并且主要是各种质粒的混合物,但是也不排除有短链的一些PCR 产物,所以,从电泳图观察,质粒突变体主要条带的分子量与对应的质粒基本一致。
第4 部分中挑取4 个白色菌落用菌落PCR 检测最终18 bp-TALE-VP64 文库。全长PCR 产物通常不太突出,大约是2 051 bp,从结果观察,主条带确实在2 051 bp 左右,但是不明显。而“阶梯效应”是成功组装的有力指标[22](见图4 中9 泳道)。
PFUS-A+10×NH、PFUS-B7+7×NH、pLR-NH 骨架质粒分别与各自的质粒突变体不同,3 种质粒突变体是各自以3 种质粒(PFUS-A+10×NH、PFUS-B7+7×NH 和pLR-NH 骨架质粒)为模板,加入4 种特异性引物经过PCR 反应后得到3 种PCR 产物,PFUS-A+10×NH 质粒突变体就是PFUS-A+10× (NH,HD,NG,NI 不同排列组合)的混合物,即410种质粒的混合物;PFUS-B7+7×NH 质粒突变体就是PFUS-B7+7× (NH,HD,NG,NI 不同排列组合)的混合物,即47种质粒的混合物;pLR-NH 质粒突变体就是pLR-NH、pLR-HD、pLR-NG、pLR-NI 的混合物,即4 种质粒的混合物。
3.3 TALE 文库质粒的基因测序
将最后提取的18bp-TALE-VP64 质粒文库送基因公司测序,最后得到的测序结果见图5,图中有6 个核苷酸的重复序列(RVDs),显示“噪声”信号。RVD结构域预期核苷酸组成与构建的18 bp-TALE-VP64 文库一致(图5)。通过基因测序验证了该文库的所有序列是正确的,并且包含所有可能的DNA 靶点的序列组合,该TALE-VP64 质粒文库对18 个碱基(ATCG)的排列组合都有靶向性,所以就是418,共计68 719 476 736个组合。所以涵盖了可能的核苷酸DNA 靶点。因为也有很多研究者构建针对11 个碱基或者12 个碱基的TALE 文库质粒,由于靶向的碱基越多,脱靶的可能性越小,此处主要是体现该质粒文库的高靶向性。另外从测序结果观察,虽然NH 对应的序列较多,但是也存在HD、NG、NI 对应的序列,由于测序的质粒文库实际是多种质粒的混合物,里面相当于418的各种排列组合的质粒的混合物。注意观察峰图,RVD 对应有几个是双峰、三峰,所以从测序结果得出,构建的文库涵盖了预期的RVD 组成。

图5 18-bp TALE-VP64 文库的DNA 测序图谱Fig.5 DNA sequencing profiles of the 18 bp-TALE-VP64 libraries
4 讨 论
先前文献报道中的构建TALE 的方法都是构建独立个体的方法,无论用什么方法来单独构建若干TALE 质粒,都不可能形成一个巨大的文库,这些方法是低效和耗时的。在本研究中,建立了一种基于独特引物组装完整、高效的TALE 文库构建的方法,与其他技术相比[23-24],TALE 靶向DNA 目标的长度可以控制。增加DNA 靶标的长度将获得更高的特异性,然而,构建TALE 文库的成本和时间也将大大增加;另一种增加文库靶向DNA 目标长度的方法,不增加额外的实验负担或增加复杂性,包括利用RVD特异性。例如,已知RVD-NN 可以同时靶向A 和G,因此,只有4 个模块(即NH、NI、NG 和HD)可用于组装完整的TALE 文库。所以,研究构建的这4 个模块的18 bp-TALE 文库将产生最多68 719 476 736种组合。靶向DNA 长度更大的TALE 文库的组装在实验上可能很麻烦,在某些情况下,实际上是无法实现的。另一个问题在于,在破译给定的RVD 序列的TALE-DNA 结合方面存在一定程度的不确定性,这可能也会使全基因组分析中潜在目标序列的识别复杂化,这个问题可以通过染色质免疫共沉淀-测序技术(ChIP-seq)[25]进行进一步研究。总之,本研究成功建立了一种基于TALE 的多功能文库的组装方法,构建成功的TALE 文库可以利用酵母单杂交试验探索其功能完整性[26]。进一步说明,TALE-DBD 可以完全定制,以靶向任何核苷酸含量(如GC 含量丰富的DNA 区域)、核苷酸限制(如转录因子基序)或其他修饰[27-28]。最后,TALE 蛋白的编码序列易于分离和测序,便于快速识别其靶基因。总之,考虑到该组装方法的高度模块化的特性,控制其靶向DNA 长度大小从而调整其文库特异性的能力,以及构建的文库的多功能性和方便性,预计未来将有更广泛的应用。
5 结 论
在本研究中,使用TALE 试剂盒和独特设计的引物,建立了一种快速构建TALE 文库的新方法。利用该方法构建了可靶向18bp-DNA 序列的TALE 文库,并对其进行了DNA 测序验证,满足预期结果。为基因组调控和基因组编辑技术提供了简单高效的方法和实验工具。
