高铁列控车载设备故障知识图谱构建方法研究
2023-02-24薛莲姚新文郑启明王小敏
薛莲,姚新文,郑启明,王小敏
(西南交通大学 信息科学与技术学院,四川 成都 611756)
车载设备是列车运行控制系统的重要组成部分,主要根据地面设备发送的行车信息,生成列车运行速度控制曲线,监督与控制列车的运行[1]。因结构复杂,故障多样的特性,在故障发生后,维修人员以文本的形式详细记录此次故障内容及处理情况,其中蕴含丰富的经验知识。但该类文本由于缺乏统一表述且包含大量冗余信息,难以直接利用,因此挖掘其中的关键信息用于指导故障维修,具有重要的研究意义。当前对故障日志的研究,可分为基于规则匹配方法获取故障信息和基于机器学习方法实现故障分类2类。陈曦等[2]提出在构建故障字典的基础上,利用正则表达式实现故障语句自动定位。上官伟等[3]改进了LLDA模型和SVM算法,提高了故障分类效果。胡小溪等[4]提出基于词项和语义融合的文本表示方法,结合KNN模型实现了车载故障的分类。但上述研究,多以获取故障类别为目的,忽略了故障间的联系,也缺少故障关联的可视化展现,影响了文本挖掘的实用价值。知识图谱[5]技术以“实体-关系-实体”三元组形式将散乱知识有效组织起来并以图的形式展现[6],在获取知识间的关联性的同时,能够挖掘知识背后隐含信息[6],在医疗、电网、金融等特定领域得到快速发展。在高铁信号领域的知识图谱研究较少,姜达[7]讨论了基于知识图谱的CTCS3-300T型车载信号故障诊断,但未建立构建图谱的系统框架,对于车载设备故障日志的知识图谱研究尚未深入开展。因此,本文以故障日志为研究对象,提出高铁车载信号设备的故障知识图谱构建框架。首先分析整合故障日志数据,采用无监督学习与模板匹配方法挖掘故障文本关键信息,实现车载数据的知识抽取;接着计算实体余弦相似度融合异构同源知识,减少冗余和错误实体;最后使用图数据库进行知识存储,构建面向列控车载设备的故障知识图谱,并以可视化方式展示和检索了车载设备的故障现象-原因-实体关系。
1 列控车载设备故障知识图谱设计
构建知识图谱的方式可分为自顶向下、自底向上和二者结合3种[6]。自顶向下的构建方式先确定知识图谱数据类型,再根据模型填充数据。自底向上的构建则相反,先按照三元组的方式收集数据,再根据数据内容来提炼数据模型。由于车载设备故障文本构成要素固定,知识图谱的构建采用二者结合的方式,在前期采用自顶向下的方式,先确定故障类型、故障类别、故障原因等实体数据模型和原因、分类、组成等关系数据模型。接着在数据模型指导下,采用自底向上的方式处理数据,补充完善模型,从而形成知识图谱。其中如何处理车载故障数据,分析故障实体关系是研究的重点。
通过对车载设备故障维修日志的分析,故障数据有以下特点:
1) 文本类型多样,包含结构化和半结构化2种数据类型。
2) 文本数据分布不平衡,包含大量高铁车载专用术语。
3) 文本数据量有限,缺乏标注数据。
本文充分考虑了上述特点,采取有针对性的故障文本数据处理方法,对不同类型的数据,使用不同实体关系抽取方法,实现知识抽取从手动到自动的转变,过程如图1所示。

图1 列控车载设备故障知识图谱构建流程Fig. 1 Construction process of the fault knowledge map of train control on-board equipment
2 实体关系知识抽取
2.1 实体抽取
实体是指文本中特定含义的对象,如故障原因、故障现象等。对于结构化的车载故障文本,可基于数据表直接提取。对于半结构化文本,由于车载故障数据量有限,且没有标注好的训练样本,因此将其视为无监督关键短语抽取问题,获取的关键短语即为故障实体,具体过程如下所示。
2.1.1 文本预处理
文本预处理是除去数据中非文本、无关部分的过程。本文为增强故障文本的识别能力,在通用词库的基础上构建车载专用词库,并借助jieba工具,使用基于词典与基于统计融合的算法,实现分词和词性标注。最后对切分后的词语进行过滤,去除其中符号、地点等停用词,以及形容词、副词这类包含关键信息较少的词性,以减少杂乱数据干扰。
2.1.2 实体抽取
实体抽取由文本表示、关键词语获取和关键短语获取3部分组成,流程图如图2所示。

图2 车载故障文本实体识别流程图Fig. 2 Flow chart of on-board equipment fault text entity recognition
Step 1 文本表示
文本表示是将文字转为向量形式,为避免维度灾难,本文采用Word2vec分布式词向量表示方法。
Word2vec模型是VIEHWEGER等[8-9]提出的一种分布式文本表示的方法,本质上是双层神经网络,有CBOW和Skip-Gram 2种模型。CBOW的目标是通过上下文词语预测中间的词,Skip-Gram则相反,由一个特定的词来预测前后可能出现的词。模型的优化则采用层次softmax和负采样2种技巧,减少计算量,获取词语与向量的映射,表示词语之间的关系。
Step 2 关键词语获取
主题模型通过主题维度,将词语与文档联系起来,将文档看成主题的混合,而主题表现为跟该主题相关词项的概率分布[10]。LDA等[11-12](Latent Dirichlet Allocation)模型假设文档主题和主题词项的先验分布服从Dirichlet分布,选用Gibbs采样算法,训练故障数据,求解每篇文档的主题分布和主题词项分布。从输入输出上来看,LDA以故障记录集合作为输入,以每条记录对应的主题概率以及各个主题生成不同词项的概率为输出,概率值越大则表征该主题和该词项越关键。
由于车载专有名词在单个记录中出现次数较少,致使数据不平衡,算法效果不佳。研究提出将词典特征融入LDA主题模型实现关键词抽取。在LDA模型计算词项概率时,加入词典特征。以车载专用词库为基础,对词项进行权重ω加权,式如(1)所示。通过对文献[7]中故障短语的分析,词性分布如图3所示,从图中可以看出,故障短语中名词、动词占比居高,而且由于车载领域的特殊性,这类词语大多包含于构建的车载专用词库中。因此,为提高关键词语抽取的准确率,本文增加这2类词性词语的权重,设置名词权重为3,动词为2,其他词语设置权重为1。

图3 车载故障短语词性分布图Fig. 3 Part-of-speech distribution map of vehicle fault phrases
在该模型中,主题数是重要参数。主题数取值过小,不利于挖掘隐含语义信息,取值过大,则有效信息少。本文使用公式(2)所示的困惑度(perplexity)[13]评估确定主题数大小,其中M表示文档数,p(wd)表示单词出现wd频率,Nd表示文档d中的单词数。
Step 3 故障实体获取
上述模型聚类得到的是与主题相关的忽略上下文顺序的词语,而故障现象和故障原因实体多是有序短语形式,因此还需将其按原文本顺序转换为故障短语。故障短语获取模型使用Bi-gram模型[14]思想构建,即滑动窗口为2个字符,当临近词语为关键词语时,将其拼接为关键短语。将获取的短语依据词项概率进行加权评分,其中得分最高的短语即为故障实体。为避免词语数越多评分越高的缺陷,使用长度权重系数调节评分R,如式(3)所示,φp大小与候选短语p中单词w的数量n有关,这里取
2.2 关系抽取
关系是实体与实体间的桥梁,结构化的车载故障文本中实体关系可直接构建,半结构化文本数据关系抽取则采用基于模式匹配的方法。
如表1所示,在抽取过程中,根据车载故障文本构建实体间关系表示方式,如故障现象与故障原因的因果关系,构建车载故障实体[故障现象]原因[故障原因]的关系模板。在关系抽取时,基于该模式匹配,如“触发最大常用制动停车原因为丢失多组应答器信息”可从中抽取故障原因“丢失多组应答器信息”与故障现象“最大常用制动停车”之间的原因关系。

表1 车载故障实体关系抽取模板Table 1 On-board equipment fault entity relationship extraction template
3 实体知识融合
知识融合即将多个意思相同但表示不同的实体融合为一个实体。如“ATP故障输出紧急制动”与“ATP输出紧急制动”。通常可通过计算语义相似度来解决,相似度越高表示二者表达越接近。若大于设定阈值,则将2个实体进行融合,具体实现方法如算法1所示。

算法1 车载故障知识融合算法Alg. 1 On-board equipment fault knowledge fusion algorithm
其中,短语向量是相似度计算的基础,将短语中包含的词语对应的词向量相加取平均,得到的向量即为短语向量。基于向量的文本相似度计算有欧式距离、曼哈顿距离和余弦相似度等方法。欧式距离是较为常用的距离计算公式,衡量多维空间中各个维度的绝对值,它将所有维度之间的差别同等看待,因而不适用于高维数据的处理。曼哈顿距离是欧式几何空间两点间距离在2个坐标轴的投影,虽然可以解决高维数据的问题,但存在某一维度特征掩盖其他特征间邻近关系的问题。与二者相比,余弦相似度[15]更加注重2个向量在方向上的差异,取值范围固定,适用于特征向量较多的情况。因此,本文通过短语间的余弦相似度表示短语的语义相似程度:假设2个短语向量为u和v,则余弦相似度余弦值越接近1,表明对应短语越相似,余弦值接近于0,则表明对应短语越无关。
4 知识图谱构建
4.1 实体关系抽取结果
本文以某铁路局2019~2020年车载设备故障维修日志为基础数据,抽取实体关系并构建知识图谱。
在实体识别模型中,词向量维度代表了词语的特征,维度越大越能区分不同词语,但维度过大会淡化词语间的联系,使得训练速度减慢。一般而言,维度大小取决于语料库的规模,本文语料库主要由车载故障相关论文构成大小在100 M以上,根据文献[16]的实验结果,词向量维度设置为128时效果最好。至于模型选择上,因CBOW比Skip-Gram模型训练速度更快[8-9],故本文选用CBOW作为词向量模型。LDA主题模型中主题数量以公式(2)所示困惑度为评估参数,实验结果如图4所示。困惑度可以理解为训练出的模型对于该故障现象或原因属于哪个主题的不确定程度,当困惑度越低时,说明对该主题越确定,即聚类效果越好。由图中可以看出,故障原因和故障现象的困惑度整体呈现先下降后上升的趋势,因而对于故障原因实体识别选取的主题数为24,故障现象实体识别为25。

图4 车载故障实体主题数量确定Fig. 4 Determination of the number of on-board equipment fault entity topics
主题数确定后,将每一行数据视为一个文档,取该文档可能性最大的主题,以及与主题最相关的前十个词语,以加权评分的方式获取得分最高的短语为关键短语,即故障实体,实验结果如表2所示。

表2 车载故障实体获取(部分)Table 2 On-board equipment fault entity acquisition (partial)
抽取的故障实体因冗余和错误问题难以直接利用,需经过知识融合,实现实体的消歧。通过对获取的相似故障实体采样分析,实体间余弦相似度计算结果如图5所示。相似实体间距离在[0.8,0.9)和[0.9,1]范围内的实体占采样总数的80%以上,因而设置余弦相似度阈值为0.8。

图5 相似故障实体间距离分布Fig. 5 Distance distribution between similar fault entities
经上述操作,抽取的实体有设备型号、故障原因、故障现象等类型,构建的实体关系有故障原因-故障现象、故障类型-设备型号、故障原因-故障类型等。累计数量为故障实体339个,故障关系734条,具体类型如表3所示。

表3 车载设备故障知识图谱实体及关系数量统计Table 3 On-board equipment fault knowledge graph entity and relationship statistics
为评估实体识别效果,本文使用准确率P(Precision)、召回率R(Recall)和F1值来衡量,其中P是正确识别的实体数与识别的实体总数之比,R是正确识别的实体数与应识别的实体数之比。F1值是二者的综合评价,公式如式(4)所示。
以《信号设备故障一点通》和《列控车载设备典型故障案例》中故障描述为专家模板,对抽取6类实体数据进行评估,结果如图6所示。从图中可以看出,故障类型、设备型号、故障部位和故障分类识别的效果优于故障原因和故障现象,其原因为上述类别实体数量相对较少,且类别间差异较大,存在干扰少,使得提取较为容易,而故障现象和故障原因存在词语间的嵌套问题,实体类型容易混淆,降低了提取准确率。整体来看,各类实体识别很难找全所有实体,原因为车载故障数据量较小且发生故障的部位不均衡,导致识别的实体尚不丰富,该问题可通过增加数据量解决。
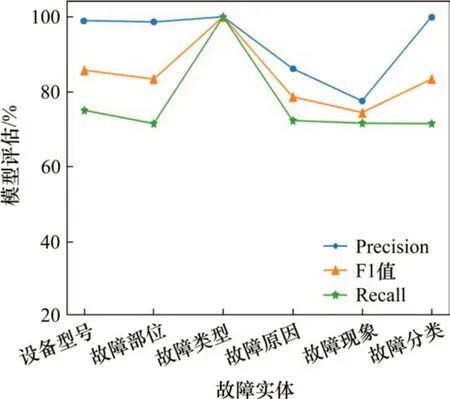
图6 车载故障实体识别模型评估结果Fig. 6 Evaluation results of on-board equipment fault entity recognition model
4.2 车载故障知识图谱展示与应用
将上述实体关系转为“实体-关系-实体”三元组后构成车载设备故障图谱。以CTCS3-300H型列控车载设备为例,其知识图谱如图7所示。通过检索可知,CTCS3-300H型列控车载设备故障可分为TCR及天线模块故障、DMI模块故障、BTM及天线故障等。各故障模块有其对应的故障现象,如DMI模块故障现象有DMI黑屏、主机与DMI通信中断等。根据故障现象可追溯故障原因,如图8所示,收不到进路预告的故障现象,其原因有GSM-R数据单元故障、TAX箱DMIS板工作不良、GPRS无线连接故障等。根据故障原因,可检索其故障属性,如BP继电器故障、BSA临时性错误、ATP双系CCTE插件同时死机属于电务设备故障。

图7 CTCS3-300H型车载设备故障知识图谱Fig. 7 Fault knowledge graph of CTCS3-300H On-board equipment

图8 收不到进路预告故障现象与原因关系展示Fig. 8 Phenomenon and cause relationship display of failure to receive advance notice
其他类型数据同理,如此便构建了车载设备故障实体间不同层级的相互关系,能更方便的展现车载故障对象间关联,更快速的检索查询特定对象关系。
车载设备故障知识图谱的应用主要在以下2个方面。
1) 故障成因溯源
通过查询故障知识图谱中的实体关系,可由故障部位查询到故障现象,进而追溯故障原因,可以帮助维修人员更快速准确的对故障做出判断。
以BTM及天线故障为例展示故障关系,如图9所示。可看出BTM及天线故障的故障现象有ATP无法进入正常模式、应答器信息丢失、ATP无法正常启动等,通过查询,可知应答器信息丢失这一现象的原因有BTM-R天线偶发工作不良、车组通过分相区段受干扰、BTM软件存在缺陷等原因,这些均属于电务设备故障。

图9 BTM及天线故障的故障关系展示Fig. 9 Fault relationship display of BTM and antenna faults
2) 辅助故障诊断
构建的车载设备故障知识图谱记录了各类故障事故特征,蕴含了大量历史经验。以DMI黑屏为例,如图10所示。当事故发生时,对知识图谱自动检索,辅之以故障次数标签,通过后续故障判断规则,可实现故障智能诊断与预测,减少了对维修人员的经验依赖。

图10 DMI黑屏故障信息Fig. 10 DMI black screen fault information
5 结论
1) 将故障实体识别转换为故障关键短语抽取问题,提出LDA模型与词典特征相结合方法,弥补了标注数据不足,无法采用有监督学习方法的缺陷。
2) 针对数据记录格式不一的问题,利用短语词向量间的余弦相似度大小衡量短语相似程度,实现了实体的融合。
3) 在知识图谱构建过程中,共抽取实体339个,故障关系734条,形成了具有一定规模的车载故障知识图谱,可视化展现了故障知识查询与检索服务,为车载设备故障智能维护提供支持。
