有闭解的可控人脸编辑算法
2023-02-24陶玲玲李文博何希平
陶玲玲,刘 波*,李文博,何希平
(1.重庆工商大学 人工智能学院,重庆 400067;2.智能感知与区块链技术重庆市重点实验室(重庆工商大学),重庆 400067)
0 引言
人脸编辑是人脸分析的重要研究内容,它通过操纵人脸图像的单个或多个属性来生成新的人脸图像[1]。人脸编辑被广泛应用于娱乐、社交以及公共安全等领域。例如:在娱乐领域,人脸编辑软件通过编辑人脸图像的面部属性来实现人像美颜、妆造编辑等效果[2];在公共安全领域,可根据受害者和目击者的描述来创建与编辑嫌疑人图像,从而提高办案效率[3-4]。
人脸编辑模型和可控性是人脸编辑的主要研究内容。主流的人脸编辑模型以生成对抗网络(Generative Adversarial Network,GAN)为基础,并取得了丰硕的成果。比如:用于属性交换与重组的生成对抗网络GeneGAN(Learning Object Transfiguration and Attribute Subspace from Unpaired Data)[5]、通过改变目标内容进行属性编辑的生成对抗网络AttGAN(Facial Attribute Editing by Only Changing What You Want)[6]、基于条件的生成对抗网络(Conditional Generative Adversarial Network,CGAN)[7]等。尽管这些模型能较好地生成人脸图像,但编辑过程中的可控性仍然面临很多问题。例如:人脸不同属性之间高度耦合导致编辑的可控性差;编辑结果不自然,生成图像的变化过小或过大导致可控性难度较大等。
针对这些问题,本文基于潜在空间(latent space)的可解释方向提出一种高效的可控人脸编辑算法。该算法首先在现有的人脸编辑模型(例如:一种基于风格的生成对抗网络生成器架构(Style-based generator architecture for Generative Adversarial Networks,StyleGAN)[8]、为提高质量、稳定性和变化性的渐进式生成对抗网络(Progressive Growing of GANs for improved quality,stability,and variation,ProGAN)[9]、StyleGAN 图像质量的分析与改善(Analyzing and Improving the Image Quality of StyleGAN,StyleGAN2)[10])的潜在空间中采样构造一个样本矩阵,并计算出样本矩阵的主成分[11],再结合人脸属性的语义边界(semantic boundary)来计算人脸编辑的可解释方向向量,该向量要尽可能地靠近对可控性编辑有利的主成分向量,同时还要尽量远离人脸属性的语义边界向量,以便减少编辑过程中属性之间的相互影响,本文所提出的算法具有闭解(closed-form solution)。实验结果表明,该算法能很好地实现可控人脸编辑。
1 相关工作
早期的人脸编辑主要利用自编码器(AutoEncoder,AE)来实现[12]。基于自编码器结构,人脸属性编辑任务通过将给定人脸图像的属性进行编码以获得各个属性的特征向量,然后对这些特征向量进行编辑,最后将其进行解码以实现人脸编辑[13-14],但这类模型生成的图像容易模糊。当前,人脸编辑模型的研究逐渐转向生成对抗网络,并取得了大批显著性成果。例如:StyleGAN 可以将潜在空间经过仿射变换得到解纠缠的中间潜在空间(intermediate latent space),实现了人脸编辑时的无监督属性分离[8];ProGAN 可以生成1 024×1 024 分辨率的高质量图像[9];BigGAN(Large scale GAN training for high fidelity natural image synthesis)[15]可以生成高质量、多样性的结果。在人脸编辑的研究中,可控性作为关键技术得到了广泛、深入的研究。下面从5 个方面介绍人脸编辑可控性的研究工作。
1)基于对比学习的可控人脸编辑。这方面的研究工作主要采用对比学习来研究人脸编辑的可控性。比如:文献[16]中将人脸图像的属性逐一进行对比,通过将相似属性尽量靠近,不同属性尽量分离来实现人脸属性编辑的可控性;文献[17]中结合三维人脸模型参数(3D Morphable Model,3DMM)和对比学习来进行可控性人脸编辑的研究。
2)基于条件向量的可控人脸编辑。这类方法在生成对抗网络的基础上加入了条件向量来控制人脸编辑过程。比如:CGAN 在生成器与判别器的输入中均引入了条件向量来指导模型的生成过程,从而控制人脸编辑的结果;条件Wassertein 生成对抗网络(Conditional-Wassertein Generative Adversarial Network,C-WGAN)[18]模型融合了CGAN 和WGAN(Wassertein Generative Adversarial Network)[19],将条件向量加入网络中的生成模型用来生成满足约束条件的样本进而控制图像生成;InfoGAN(interpretable representation learning by Information maximizing Generative Adversarial Nets)[20]不仅引入条件向量来指导模型的生成结果,还进一步引入互信息来约束条件向量和生成数据之间的关联程度来提高人脸编辑的可控性。
3)基于辅助分类器的可控人脸编辑。这类方法通常会在生成模型的基础上加入一个分类器,比如:ACGAN(Auxiliary Classifier GAN)[21],通过让判别网络在判别图像真假时,同时对图像进行分类,从而实现人脸编辑的可控性。文献[22]中获取图像不同属性的语义特征向量,然后通过分类器确定可解释方向来实现人脸编辑的可控性。
4)基于潜在空间解耦的可控人脸编辑。这类方法在生成对抗网络的潜在空间中得到丰富的人脸属性的特征向量,通过识别并利用各属性相对应的特征向量来实现可控的人脸编辑。比如,文献[23]中将潜在空间划分为多个线性子空间,使每个子空间控制一个属性变化来控制的人脸编辑操作。StyleGAN 在潜在空间的基础上,经过仿射变化提出了一个中间潜在空间,该空间与潜在空间相比耦合性更低,在人脸编辑过程中引起的变化更少,从而提高了可控性[8]。文献[24]中发现可以对潜在空间的特征向量进行线性插值,使得插值后的特征向量耦合性更低,所以在一定程度上可以更好地实现人脸编辑任务中的可控性。
5)基于语义内容的可控人脸编辑。这类方法对人脸属性语义内容进行人脸编辑,从而获得更好的控制性。比如,文献[25]通过分解模型权重来识别出潜在空间中语义层面上有意义的可解释性编辑方向,这些方向可以提高人脸编辑的可控性;文献[26]将语义候选矩阵与分类器结合来实现基于语义的可控人脸编辑。
2 本文算法
2.1 算法原理
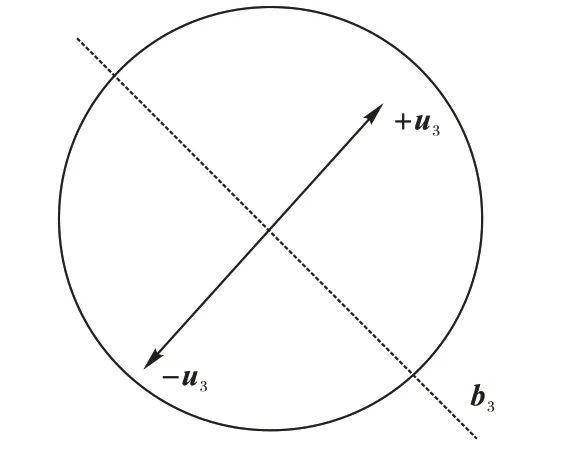
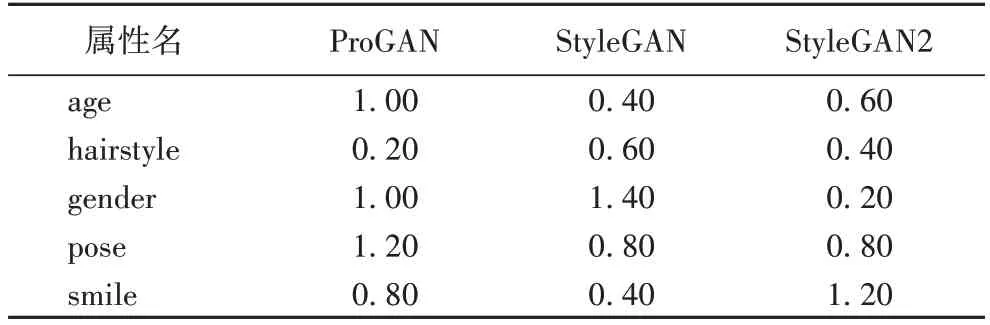
在人脸编辑模型的可控性研究中,人们发现随机采样n个潜在向量(latent vector)z∈Rd构成矩阵Z=[z1,z2,…,zn]∈Rd×n,并计算Z的前k(k 图1 改变主成分向量导致的人脸图像变化Fig.1 Changes of face image caused by changing principal component vectors 文献[23]中通过训练支持向量机(Support Vector Machine,SVM)来得到人脸各属性的语义边界。首先通过ResNet-50 网络[27]和CelebA 数据集[28]来训练出一个属性预测模型(ResNet-50 predictor),然后通过预训练生成模型(例如StyleGAN)合成50 000 张图像,使用ResNet-50 predictor 来对每幅人脸图像的属性进行预测并得出每个属性(本文实验选取姿态、微笑、年龄、性别以及发型5 种属性进行预测)在图像上出现的概率值作为预测结果。每个属性根据预测值对50 000 张图像进行排序,从排好序的图像中选出前1 000张图像和后1 000 张图像作为候选样本集(前1 000 张图像为正样本,标签为1;后1 000 张图像为负样本,标签为0)。从候选集中选取70%的样本作为训练集,30%作为测试集。使用训练集来训练支持向量机,从而得到语义边界。 由于ProGAN、StyleGAN、StyleGAN2 会合成不同的图像,所以对于不同的预训练模型而言,都需要使用ResNet-50 predictor 对样本进行预测,从而获得相应的语义边界。 设人脸第i个属性的语义边界表示为bi∈Rd,若有k个属性,它们的语义边界就构成了边界矩阵B=[b1,b2,…,bk]∈R(d×k),这些边界可以很好地区分人脸的各个属性,对降低人脸编辑过程中属性之间的相互纠缠起着重要作用。具体而言,在语义边界同一侧的属性具有相同的语义内容,并且在语义边界附近的属性所对应的语义内容不够明确,因此人脸属性特征向量离语义边界越远,针对该属性的编辑结果就越明显。如图2 所示,语义边界向量b3将潜在空间分为包含属性的不同语义的两部分,当u3向两端移动而远离语义边界b3时,人脸属性的耦合度变低。例如:在年龄这一属性上,当沿着正方向(+u3)移动时,年龄逐渐增大,人脸图像逐渐衰老;朝着负方向(-u3)移动时,年龄逐渐减少,人脸图像逐渐年轻。 图2 人脸属性语义边界向量的编辑Fig.2 Editing of semantic boundary vector of face attribute 本文结合潜在空间的主成分和语义边界在人脸编辑中的优点,提出一种具有闭解的可控人脸编辑算法。具体而言,为了编辑l个人脸属性,所提出的算法要学习l个可解释方向向量[u1,u2,…,ul]∈Rd×l,使这些向量能够对人脸编辑起到很好控制作用。为了实现这一目标,让第i个可解释方向向量ui尽量靠近第i个潜在空间主成分向量vi,同时又能尽量远离人脸第i个属性的语义边界bi,以此来减少编辑人脸时各属性之间的纠缠,同时保证人脸编辑的质量。 这种思想可用式(1)来表示: 其中:‖·‖2表示向量的2 范数,ui表示在潜在空间中对人脸编辑有精确控制作用的第i个可解释方向向量;vi表示潜在空间中n个随机向量构成的样本矩阵Z的第i个主成分向量;bi表示人脸第i个属性的语义边界;λ、β为正则化参数。 根据向量2 范数的定义,式(1)可计算为如下形式: 式(2)是一个无约束优化问题,通过对ui求导并令它等于0 来得到最优解: 进一步化简得到: 所以ui的最优解为: 本文所提算法的具体实现步骤如下: 算法1 本文算法。 输入 随机数种子s,主成分向量的数量k; 输出 生成图像Image。 1)根据s随机采样n个潜在向量z1,z2,…,zn,由此得到样本矩阵Z。 2)计算Z的主成分v1,v2,…,vk。 3)对属性进行分类并利用支持向量机得到其语义边界b1,b2,…,bk。 4)对第i个属性利用式(4)计算出可解释方向向量ui。 5)通过ui编辑样本图像zi:Image= G(zi+ui) 6)返回编辑后的人脸图像Image。 其中,一个随机数种子s,为标量且是正整数类型,通过numpy 中的随机数函数random.randint()生成,范围通过numpy 中的iinfo(numpy.int32).max 限定,具体数值为[0,231-1)。随机采样n个潜在向量时,则需要生成n个不重复的随机数种子。 2.2.1 实验环境与参数设置 1)硬件环境:CPU 为Intel Xeon Gold 5118 CPU@2.30 GHz,GPU 为NVIDIA Corporation P40。 2)软件环境:操作系统为Ubuntu 20.04.1 LTS;开发环境:PyTorch 1.3.1,Python 3.7.10,CUDA 10.1.243。 3)参数设置。算法1 中的λ、β为正则化参数,其主要目的是防止模型过拟合,通过大量实验发现参数β对实验结果的影响较小,本文将其设置为1;而参数λ对实验结果起着关键作用,通过交叉验证的方式,本文计算出不同属性在不同模型上的λ值,具体取值如表1 所示。 表1 参数λ的取值Tab.1 Values of parameter λ 2.2.2 实验模型、数据集以及比较算法 本文采用的数据集为CelebA 与FFHQ[8]。CelebA 数据集包含202 599 张人脸图片,由10 177 位不同身份的人组成,每张图片总有40 个二分属性标签;FFHQ 数据集由70 000 张分辨率为1 024×1 024 的高质量人物图像组成,在年龄、种族和背景方面有着较大的差异,并且在眼镜、帽子等配件上有良好的覆盖范围。 本文采用的模型为 StyleGAN[8]、ProGAN[9]和StyleGAN2[10],其中ProGAN 在CelebA 数据集上进行实验,StyleGAN 与StyleGAN2 在FFHQ 数据集上进行实验。 为了验证本文算法对可控人脸编辑的有效性,在相同的实验环境下,与SeFa(closed-form Factorization of latent Semantics in GANs)算法[25]和 GANSpace(Discovering Interpretable GAN Controls)算法[11]进行了比较。其中,SeFa算法是通过对不同生成模型的权重求特征向量来得到人脸编辑时的可解释方向,GANSpace 算法是通过在生成模型的潜在空间中对样本矩阵进行主成分分析得到人脸编辑时的可解释方向。 2.2.3 评价指标 本文采用初始分数(Inception Score,IS)[29]、弗雷歇距离(Fréchet Inception Distance,FID)[30]、最大平均差异(Maximum Mean Discrepancy,MMD)[31]这三个指标来评价本文算法与SeFa 算法和GANSpace 算法所生成的图像质量。 将本文所提算法与SeFa 算法和GANSpace 算法从生成图像的质量和编辑效果两方面进行了对比分析。大量的实验证明,本文算法优于SeFa 算法和GANSpace 算法。 比较本文所提算法与SeFa 算法和GANSpace 算法在不同模型上的IS、FID 以及MMD 值,实验选择人脸图像中较为重要的姿态(pose)、微笑(smile)、年龄(age)、性别(gender)以及发型(hairstyle)这5 种属性分析比较,这5 种属性所对应的语义边界向量依次为b1,b2,b3,b4,b5,所对应的可解释方向向量依次为u1,u2,u3,u4,u5。本文将三种生成模型(ProGAN、StyleGAN、StyleGAN2)的实验结果详细展示在表2 中。 表2 预训练生成模型所生成图像的定量比较Tab.2 Quantitative comparison of images generated by pre-trained generation models 从表2 中可看出,本文算法通常可以生成质量更好的编辑结果,具体表现为本文算法所生成的图像质量与SeFa 算法和GANSpace 算法相比,本文算法的IS 值均高于SeFa 算法和 GANSpace 算法,FID 值与MMD 值均低于SeFa 算法和GANSpace 算法。 对于ProGAN 模型而言,本文算法所生成的图像质量在IS 值上与SeFa 算法相比平均升高了0.18,与GANSpace 算法相比平均升高了0.21;在FID 值上,与SeFa 算法相比平均降低了0.08,与GANSpace 算法相比平均降低了0.35;在MMD值上,与SeFa 算法相比平均降低了0.05,与GANSpace 算法相比平均降低了0.25。 对于StyleGAN 模型而言,本文算法所生成的图像质量在IS 值上与SeFa 算法相比平均升高了0.43,与GANSpace 算法相比平均升高了0.65;在FID 值上,与SeFa 算法相比平均降低了0.01,与GANSpace 算法相比平均降低了0.88;在MMD 值上,与SeFa 算法相比平均降低了0.01,与GANSpace算法相比平均降低了0.23。 对于StyleGAN2 模型而言,本文算法所生成的图像质量在IS 值上,与SeFa 算法相比平均升高了0.58,与GANSpace算法相比平均升高了0.69;在FID 值上,与SeFa 算法相比平均降低了0.02,与GANSpace 算法相比平均降低了0.01;在MMD 值上,与SeFa 算法相比平均降低了0.07,与GANSpace算法相比平均降低了0.16。 综上所述,本文所生成的图像质量更好、更接近于真实图像。 3.2.1 比较在ProGAN上编辑效果 图3 为SeFa 算法、GANSpace 算法和本文算法在ProGAN模型上生成的人脸图像。 图3 ProGAN模型的实验结果Fig.3 Experimental results of ProGAN model 从图3 可以观察到,本文算法生成的结果明显优于SeFa算法和GANSpace 算法所生成的结果,具体如下: 1)编辑性别(样本图像从女性转变为男性)时,观察图3中第2 列可以看出,本文算法很精确地实现了这一目标,且未引起除性别之外的其他变化;而SeFa 算法虽然也改变了原图的性别属性,但原图的黑框眼镜被改变为了无框眼镜,原图的微笑程度从高至低被改变了;GANSpace算法在将样本图像从女性编辑为男性时,原图的表情也从微笑被改变为不笑,原图的黑框眼镜被改变为无框眼镜。 2)编辑发型时,从图3 中的第3 列发现,本文算法很好地改变了原图的发型,并且与SeFa 算法和GANSpace 算法相比与原图更加贴近。SeFa 算法不仅改变了原图的发型,还让头部产生了向右偏转,同时还让眼镜框架变得模糊;GANSpace算法在改变发型的同时也改变了面部表情,并让原图的眼镜消失。 3)编辑姿态(头部姿态从左向右偏转)时,观察图3 中的第4 列发现本文算法只是简单地将原图的头部姿态从左向右进行了偏转,并未改变其他属性。而SeFa 算法不仅对原图的头部姿态产生了影响,使其向右偏转,还去掉了原图的眼镜;GANSpace 算法同样如此,在编辑头部姿态的同时消除了原图的眼镜,改变了原图的发型等。 4)编辑微笑时(从微笑变为不笑),观察图3 中第5 列发现本文算法相较于SeFa 算法和GANSpace 算法而言能够实现更加精准的控制。本文算法仅编辑了微笑这一个重要属性并未改变其他属性;而SeFa 算法在改变微笑的同时还改变了原图的姿态,使其由右偏转变为正面偏转,原图发型的发色变深;通过定性比较可以发现GANSpace 算法在编辑微笑属性时直接改变了人脸的身份特征,从发型、眉毛、人脸轮廓等重要属性处直接体现了这一点。 5)编辑年龄时,观察图3 中第6 列发现,本文算法在编辑年龄属性时的解耦性明显优于其他两种算法。例如:本文算法在改变年龄时并未改变发型、姿态等其他较为重要的属性。而SeFa 算法在编辑年龄这一属性的同时还改变了姿态、发型和眼镜等,使编辑后的图像头部向左偏转的程度加大,头发的卷度变大,长度变短,眼镜的清晰度变低;GANSpace算法也非常明显地产生了耦合,在改变原图年龄的同时还改变了原图的发型与眼镜,使得编辑后的图像头发变短,眼镜变得不太明显,导致生成图像和原图相差较远。 3.2.2 比较在StyleGAN上所生成的图像 图4 为SeFa 算法、GANSpace 和本文算法在StyleGAN 模型上生成的人脸图像。从图4 中可以观察到本文算法所生成的结果优于其他两种算法生成的结果,具体如下: 1)编辑性别时,观察图4中的第2列发现本文算法非常精确地实现了性别的转换,且将原图从女性编辑为男性时并未引起其他属性的变化。SeFa算法在改变原图的性别时还改变了嘴巴的动作单元,由原来的闭合状态转变为微微张开的状态,GANSpace算法在改变原图性别的同时还改变了原图的面部表情,且瞳孔颜色的深浅程度发生了变化。另外,通过定性分析发现,GANSpace算法编辑后的图像和原图的身份特征相差较远。 2)编辑发型时,观察图4中的第3列发现本文算法和SeFa算法都非常精确地改变了原图的发型,但是仔细观察可以发现,本文算法生成图像的头部姿态更符合原图,而SeFa 算法编辑后图像的头部姿态微微向下偏转,且本文算法所生成的图片在发型上的改变大于SeFa 算法。GANSpace 算法在改变原图发型的同时还引起了其他面部属性的改变。例如:和原图相比,编辑后图像的面部表情更加严肃,嘴角的上扬程度小于原图。另外通过定性分析发现GANSpace 算法编辑后的人脸与原图的身份特征有明显区别。 3)编辑姿态时,观察图4中的第4列发现三种算法均很好地将原图的头部姿态向左偏转了一定角度,但是仔细比较可发现,SeFa 算法在编辑原图姿态的同时还将原图的直发变为微卷;GANSpace 算法较为明显了改变了发型,将原图的刘海由右分改变为左分,发型颜色由深变浅。本文算法也对发型造成了一定程度的影响,使原图的发色变深,但所生成的图像和原图的相似度明显优于SeFa算法和GANSpace算法。 4)编辑微笑时,观察图4中第5列发现三种算法均很好地改变了人脸的面部表情,但是SeFa 算法和GANSpace 算法均引起了除微笑以外的其他属性的变化。SeFa 算法对于发型,眼睛的影响明显大于本文算法,编辑的发色由原图的深色变为浅色,编辑后的眼睛大于原图的眼睛;GANSpace 算法引起了微弱的头部姿态的偏转,使得编辑后的图像向左偏转了一定角度,编辑后的发型也发生了微弱变化。 5)编辑年龄时,观察图4中第6列发现本文算法在编辑年龄时优于SeFa 算法和GANSpace 算法。SeFa 算法在编辑年龄的同时还改变了原图的发型,将原图的发型由长发变为短发,直发变为卷发。GANSpace 在编辑年龄的同时引起了面部动作单元的变化,例如:眉毛的上挑程度大于原图,眼睛的大小大于原图,原图的长发变为短发,原图的发色由深色变为浅色。本文算法和SeFa 在编辑年龄属性时均引起了微弱的头部姿态的偏转,但仍然可以看出本文算法在编辑原图的年龄后,身份特征和原图更加相近,面部动作和原图更加符合。 图4 StyleGAN模型的实验结果Fig.4 Experimental results of StyleGAN model 3.2.3 比较在StyleGAN2上所生成的图像 图5 为SeFa 算法、GANSpace 算法和本文算法在StyleGAN2 模型上生成的人脸图像。 图5 StyleGAN2模型的实验结果Fig.5 Experimental results of StyleGAN2 model 从图5 中可以明显地观察到,本文算法的编辑结果优于其他两种算法。具体如下: 1)编辑性别时,观察图5 中第2 列发现本文算法并不会造成其他属性的变化,编辑后的人脸图像和原图相比具有相同的面部表情和头部姿态。而SeFa 在编辑性别时还改变了人脸的头部姿态,将原图的头部姿态由左转改变为正面。 2)编辑姿态时,观察图5 中第4 列发现本文算法很好地将原图的头部姿态由向左偏转编辑为向右偏转。而SeFa 算法尽管也实现了头部姿态由左向右的偏转,但是编辑后的人脸面部特征明显和原图相差较远;GANSpace 算法虽然很好地实现了头部姿态由左向右的偏转,但偏转后人脸图像的面部出现了由发型引起的裂痕。 3)编辑微笑时,观察图5 中第5 列发现本文算法将原图的面部表情由微笑变为不笑,且保持其他属性不变。而SeFa算法在实现微笑编辑时还造成了皮肤纹理的细粒度的改变,并且通过定性分析发现,SeFa 算法编辑后图像的年龄和原图不符,身份特征和原图相差较远;GANSpace 算法除改变面部表情外还改变了原图的发型,从有刘海变为无刘海。 4)编辑年龄时,观察图5 中第6 列发现本文算法非常精确地将原图的年龄增大了。SeFa 算法虽然明显地增加了原图的年龄,但也非常明显地改变了原图的头部姿态,由原图的向左偏转变为正面;GANSpace 算法在编辑原图的年龄属性的同时还改变了原图的发型,由原图的有刘海变为无刘海。本文算法和SeFa 算法与GANSpace 算法在改变了原图的年龄时均产生了不同程度的耦合,造成其他属性不同程度的变化,但从定性分析的角度来看,本文算法所生成图片的身份特征与原图更加贴近。 针对人脸编辑过程中的可控性问题,本文提出了一种新的人脸编辑模型。该模型结合了潜在空间的主成分和人脸属性语义边界的优点来降低人脸图像编辑过程中属性之间的耦合性,本文建立了模型对应的目标函数和相应的求解方法。由于目标函数存在闭式解,因此整个求解过程简单、高效。实验结果表明,本文提出的算法能提升人脸编辑的质量和可控性,然而人脸图像的编辑是一项非常精细的工作,涉及到表情、身份等多种信息的改变,所以在未来的工作中,将进一步在保持身份不变的情况下研究细粒度的人脸编辑内容,并且为了提高语义边界向量的求解效率,考虑将多个二分类支持向量机整合为一个多分类支持向量机,实现同时训练多个语义边界向量的目标。
2.2 实验
3 实验结果与分析
3.1 分析比较生成图像的质量

3.2 分析比较生成图像的编辑效果



4 结语
