姿态干扰下的深度人脸验证
2023-02-24王旭鹏
王 奇,雷 航,王旭鹏
(电子科技大学 信息与软件工程学院,成都 610054)
0 引言
人脸验证是计算机视觉的重要组成部分,其目标是基于一对一的比较,即判断输入的一组人脸图像是否属于同一对象[1]。近几年来,该技术取得了突破性进展,也被广泛应用于生活中各个领域。然而,大多数相关研究是基于普通RGB图像,而普通的数码相机很难在光照条件恶劣的情况下获取有效的图片信息[2],且大多数的方法均采用正面人脸信息作为输入,而如何在头部姿态干扰下进行有效的人脸验证依然是该领域研究的重点[3]。
目前,广泛应用的人脸验证方法主要采用RGB 彩色图像。随着深度学习方法的深入研究,人脸验证的准确性有了显著提高,且大多数的方法在LFW 数据集[4]上的准确率超过了人类。其中,Schroff 等[5]构建了新的网络FaceNet,该网络将成对的图像作为输入,并引入三元组损失计算图像之间的差异。Yang 等[6]将人脸图像及其标签用在一个分类框架中学习鉴别识别特征,然后Chen 等[7]直接利用这种分类信息计算一对图像的相似度来判定该对图像是否属于同一组对象。Huang 等[8]将一种基于学习聚类的边缘局部嵌入法和k-最近聚类算法相结合用于人脸识别和人脸属性预测,该方法在识别方面的性能有了显著提升。为解决低分辨率图像的人脸验证问题,Jiao 等[9]设计了一种双域自适应结构来提高图像质量,并提出了一种端到端低分辨率人脸翻译与验证框架,该框架在提高人脸图像生成质量的同时也提高人脸验证的精度。
随着深度相机的普及,低成本、高质量和随时可用的深度设备开始应用于各种计算机视觉任务[10]。深度图也被称为距离图像和2.5D 图像,其每个像素点代表设备到对应目标点的距离。与普通RGB 图像相比,深度图主要有两个优势:第一个是对光线变化的可靠性,基于红外的成像原理使其图像质量不受光照条件影响,这种优势可使它应用于一些特殊的应用场景,如夜间驾驶。第二个优势是可以利用深度数据处理检测任务中的目标尺寸问题[11]。
尽管缺乏大规模深度数据集,深度图凭借其对光照的稳定性也被应用于处理人脸验证问题。Kim 等[12]提出了一种迁移学习的方法,即在利用2D 图像训练一个卷积神经网络(Convolutional Neural Network,CNN)模型,再通过对模型参数的调整,应用到深度图上测试。Borghi 等[13]构建了JanusNet,该网络由深度、RGB 图像组成混合孪生网络。在训练阶段,混合网络通过RGB 和深度特征进行互补学习,在测试阶段仅依靠深度特征进行测试。随后Borghi 等[3]又利用两个完全相同的全卷积网络构建一个孪生网络,该网络仅依靠深度图进行训练和测试,依然取得了非常好的效果。
为应对光照变化以及头部姿态对人脸特征的影响,本文仅利用深度图作为输入,基于两个共享权重的卷积神经网络提出了一个新的深度学习框架L2-Siamese。该方法的主要思想是通过两个卷积神经网络分别提取一对图像的特征,并分析特征的L2 范数与头部姿态的联系,再将不同姿态的特征固定在一个半径为α的超球后,计算该对图像间的相似度,并通过全连接层将相似度映射为(0,1)的概率,设定阈值判断该组图像是否属于同一对象。
1 孪生神经网络
孪生神经网络最早由Bromley 等[14]提出并应用于签名验证。如图1 所示,该网络结构由一组平行网络组成,各网络输入层(Input layer)分别接受不同的输入,并通过隐藏层(Hidden layer)提取特征,末端由一个能量函数(Energy function)连接,该函数可根据任务需求计算特征间的某些指标。该对网络之间的参数相互绑定,因此在训练过程中,权重共享保证了两个极其相似的图像不会被各自的网络映射到特征空间中非常不同的位置,且能自然排列出两个输入之间的相似度。

图1 孪生网络结构Fig.1 Structure of Siamese network
根据文献[15],本文基于一对完全相同的卷积神经网络构建孪生网络,为保证网络良好的性能以及实时约束条件,本文采用一个浅层的卷积网络架构用于特征提取[2]。如图2所示,该网络总共有4 个卷积层,各卷积层分别对应64、128、128、256 个卷积核,其卷积核大小分别为10×10、7×7、4 ×4、4×4。除最后一层卷积层外,各卷积层后分别对应一个2×2 的最大池化层。最终卷积层中的所有单元被平展映射成一个4 096×1 的一维特征向量。该网络选取线性整流函数(Rectified Linear Unit,ReLU)作为激活函数。
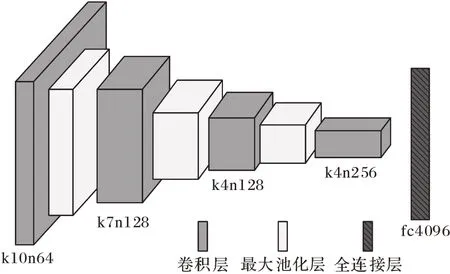
图2 卷积神经网络结构Fig.2 Structure of convolutional neural network
2 头部姿态与特征范数
两个共享权重的孪生网络通过能量函数连接,目的是让同一对象特征度量距离越近,不同对象度量距离越远。受Ranjan 等[16]研究特征范数与RGB 图像质量关系的启发,本文首先研究深度头像与头部姿态之间的关系,在Pandora 数据集[17]上获取深度人脸图像,分析不同姿态下的特征L2 范数,如图3 所示,3 个对象分别采样(1)(2)(3)三组不同姿态,每组姿态包含两张相近头部姿态信息。本文仅采用深度图用于模型训练与实验测试,但由于深度图缺乏纹理信息,为直观展示头部姿态信息,每组第一行为对应的灰度图像,第二行为采样的深度图。

图3 不同姿态下的深度头像Fig.3 Depth head images with different poses
通过图2 所示的卷积神经网络提取每张深度图的人脸特征,每张人脸特征被映射为4 096×1 的特征向量,并计算特征向量的L2 范数。L2 范数如表1 所示。对于同一对象,相近的头部姿态特征有相近的L2 范数,而姿态差异越大,其L2 范数差异也越大。即不同头部姿态特征,对应不同L2 范数,头部姿态越接近,其特征向量的L2 范数越接近。

表1 头部姿态与L2范数Tab.1 Head pose and L2 norm
以三维空间为例,所有具有相同L2 范数的向量(相同长度的向量),分布在一个半径固定的球面上。同理,高维空间具有相同L2 范数的向量,分布在一个半径固定的超球上。因此,为减小头部姿态对头部特征的影响,将所有姿态的头部特征,映射在一个半径为α的超球内,如图4 所示。

图4 头部特征映射示意图Fig.4 Schematic diagram of head feature mapping
根据式(1),将所有特征向量通过L2 范数归一化为特征空间中的单位向量(L2 normalization layer),再如式(2)所示将所有特征固定在一个半径为α的超球上(Scale layer)。
其中:x为卷积神经网络提取的人脸特征向量,y为L2 归一化后的特征向量。
这样做有两个优点:其一,本文通过孪生网络来度量一组面部特征的差异,在固定半径的超球上,可通过超球半径α的调节,使同一对象间度量距离越近,不同对象间的度量距离越远。其二,对同一对象而言,所有姿态的特征被映射在相同半径的超球上,具有相同的L2 范数,能使其差异最小化,可减少头部姿态带来的干扰。
通过L2-normalize 层和scale 层反向传播梯度,并使用下面给出的链式法则计算包含缩放参数α的梯度。
由式(3)可知,L2-normalize 层和scale 层完全可微,该模块可用于网络的端到端训练。
3 L2⁃Siamese网络
L2-Siamese 网络将包含完整头部信息的一组相同尺寸并包含真实值标签的深度图作为输入:若标签为1,则该组头部图像属于同一对象;若标签为0,则该组头部图像不属于同一对象。首先利用图2 所示的一组共享权重的卷积神经网络,分别提取特征后,再利用图4 所示的模块将特征向量通过L2 范数嵌入一个半径为α的超球内,之后通过计算特征向量各单元之间的绝对值误差(即各单元的L1 距离),获得一个新的4 096×1 的差异向量,该向量表征了该组深度头像之间的差异。最后通过三层包含128、32、16 个神经元的全连接层后,将该对图像的差异向量最终映射为含一个神经元的输出单元。完整的L2-Siamese 结构如图5 所示。

图5 L2-Siamese整体结构Fig.5 Overall structure of L2-Siamese
如图5 所示,L2-Siamese 除输出层外,所有的卷积层和全连接层采用ReLU 作为激活函数。输出层采用Sigmoid 作为激活函数,将深度头像间的差异映射为(0,1)的概率值。人脸验证可视为一个分类问题,所以L2-Siamese 采用交叉熵作为损失函数:
其中:p表示真实值,q表示预测值。在超参数的选取上,batch 的大小为64,学习率为0.001,衰减率为0.99,衰减步长为500。
4 实验与结果分析
本章首先介绍了公用数据集Pandora[17],并在该数据集上进行了一系列的实验,验证L2-Siamese 的性能。
如引言所示,L2-Siamese 将图像差异映射为(0,1)的概率,实验第一步,通过设置不同阈值,分析不同阈值对测试结果的影响;随后实验并分析了不同缩放参数α对网络性能的影响,并选取最佳结果组合与近几年先进方法进行对比。为进一步验证L2-Siamese 在头部姿态干扰下的性能,本章根据头部姿态角偏航角(yaw)、俯仰角(pitch)、侧倾角(roll)对数据集进行划分后,进行实验分析。
4.1 数据集
Pandora 数据集[17]为头部和肩部姿势估计任务而创建,收集了22 名受试者(10 男12 女)的坐姿上半身图像,每张深度图对应一张RGB 图像,且每张图像对头部中点以及头部姿态角进行了真实值标注。共110 个序列,超过25 万张图像,并通过眼镜、围巾、手机以及各种姿态产生干扰。该数据集通过微软Kinect One 采集。
本文根据文献[18]中提出的方法,在已知头部中点p={x,y}的前提下,根据式(5)计算宽度和高度分别为wp、hp头部矩形框来采集深度头部图像。
其中:fx、fy为相机内部参数,分别为水平和垂直焦距;R为头部平均宽度和高度(设为300 mm);Dp为头部中点p={x,y}的深度值。获取头部图像后,先去除背景,将深度值大于Dp+L(L=200 mm)的所有像素点置0,再将所有图像统一尺寸为105×105。
4.2 阈值设定
理想状态下,同一对象间相似度概率趋近于1,不同对象相似度概率趋近于0。受姿态、距离等因素的影响,模型无法达到最理想状态,而阈值的选取会直接影响测试结果。本节从(0,1),每0.1 个间隔取一次阈值,在Pandora 数据集上进行测试,其结果如表2 所示。当阈值偏高或偏低时,准确率均有所下降:阈值过高,主要针对同一目标而言,受姿态变化的影响,其相似度概率值降低,达不到阈值,则会增加误判率;当阈值设置偏低时,针对姿态特征非常接近的不同对象而言,其相似度概率偏高,容易大于所设阈值,也会增加误判概率。L2-Siamese 阈值选定为0.6 时,准确率最高,该值对整个数据集有最佳的包容性,能最大限度地减少姿态干扰对测试结果的影响。

表2 不同概率阈值对应的准确率Tab.2 Accuracy corresponding to different threshold value
4.3 缩放参数α
超球半径即缩放参数α对L2-Siamese 的性能起着至关重要的作用。如式(3)所示,α可微,即可通过网络学习获取,但在实际应用中,相同对象不同姿态间L2 范数差异较大,不同对象相同姿态的L2 范数也存在差异,通过学习所得的α更趋近于一个包含更多样本的L2 值[16],而该值包含的姿态非常离散,即该超球表面嵌入了更多的姿态特征,容易使α值偏大,而且会增加模型的训练负担,因此本文将α设置为固定值,并在Pandora 数据集上进行实验对比,找出α最优值。实验结果如表3 所示。为进一步验证L2 范数和缩放参数α对网络的影响,删除L2-Siamese 中L2 约束层和缩放层,仅用图2 所示的孪生网络在相同的数据集下进行实验对比。
根据表3 所示,缩放参数α偏小和偏大时,均会导致模型性能降低:α偏小时,超球表面积过小,所有特征分布过于密集,特征间的差异也过小,不便于特征间的区分;而α过大时,超球表面积过大,所有特征的差异均偏大,且不利于损失函数的收敛。适当选取缩放参数α,能显著提高孪生网络的性能,且当α=10 时,L2-Siamese 准确率最高。因此选取最优α作为L2-Siamese 的固定缩放参数,并与其他方法进行实验对比。
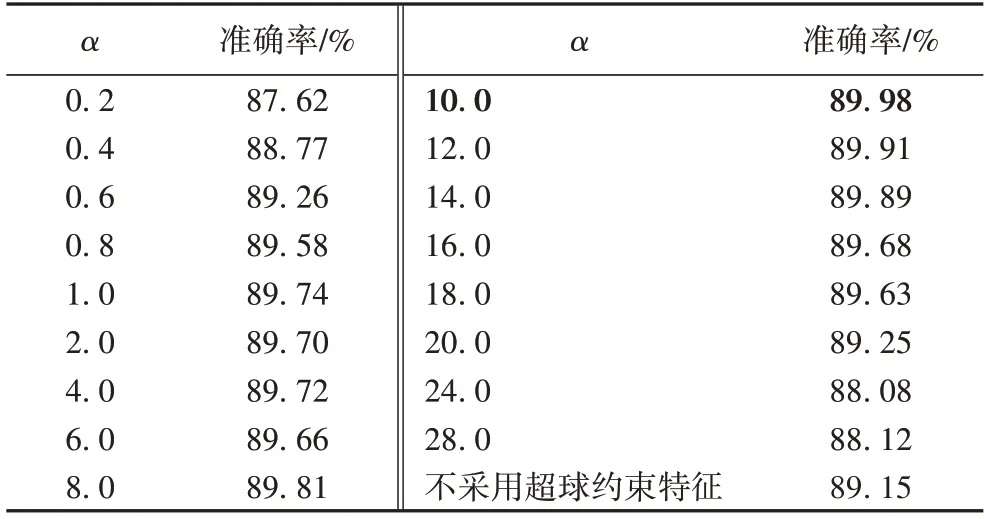
表3 不同缩放参数α对应的准确率Tab.3 Accuracy corresponding to different scaling parameters α
图6 给出了当α=10 时,在Pandora 数据集上训练时损失函数和模型准确率的变化曲线。

图6 损失值及模型准确率变化曲线Fig.6 Curves of loss value and accuracy
4.4 数据分析
Pandora 数据集包含RGB 图像和深度图两种类型的数据,深度图的获取不依赖于光照条件,但与RGB 图像相比缺乏细节轮廓,为公平比较,本文与仅采用深度图测试的方法进行对比,实验结果如表4 所示。

表4 不同方法的人脸验证的实验结果在Pandora数据集上的比较Tab.4 Comparison of experimental results of different methods on Pandora dataset
在相同的实验环境下,与近年来最先进的方法进行对比。本文与文献[13]在卷积层提取特征后均采用了全连接层结构,但相较于后者,本文采用了4 096 个神经元,更宽的维度提升了模型的学习能力,同时也大量增加了网络的训练参数,对模型效率造成一定的影响。本文与文献[3]方法均直接采用深度图进行训练和测试,后者仅采用了全卷积的网络结构,该结构网络参数更少,运行速度更快。为兼顾在实际应用中的运行效率,L2-Siamese 采用了浅层网络结构,相较于文献[3,13]中方法,运行速度偏低,但能满足多数任务的实时性需求。其准确率相较于当前最好的方法提升了4.6 个百分点,准确率明显高于竞争对手。
为进一步验证L2-Siamese 在头部姿态干扰下的预测性能,根据文献[3,13]的方法,将Pandora 数据集按如下方式进行划分:
其中:ρ、θ、σ为均为欧拉角,分别代表头部姿态的偏航角(yaw)、俯仰角(pitch)、侧倾角(roll)。其示例如图7 所示。其中图7(a)为图A1分组示例,所有姿态角均在10°以内,姿态干扰最小;图7(b)为A2分组示例,存在大于10°的姿态角,头部姿态对模型有较小的姿态干扰;图7(c)为A3分组的示例,三个姿态角都大于10°,头部姿态对模型的干扰最大。
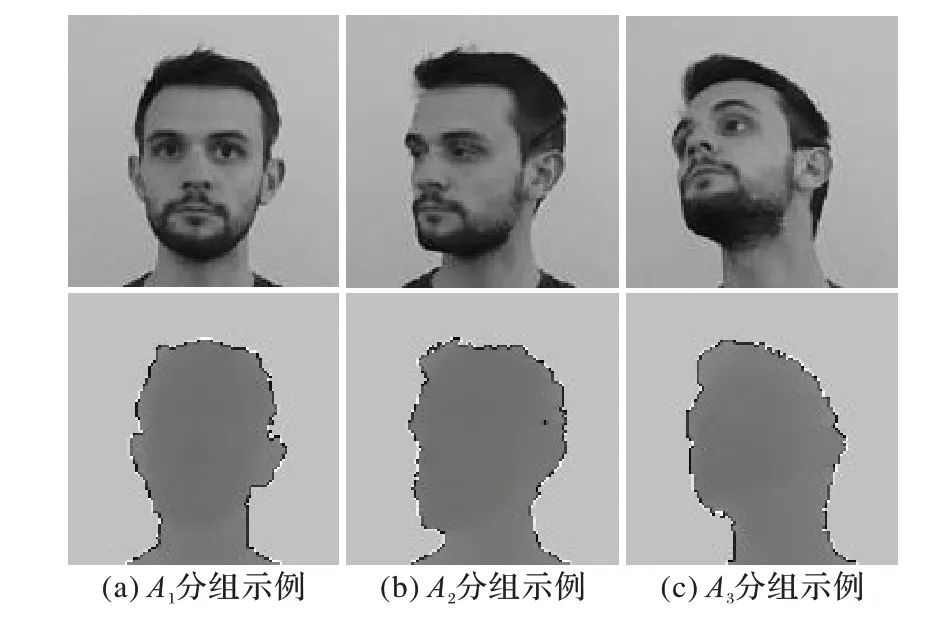
图7 数据集分组示例Fig.7 Examples of dataset grouping
Pandora 数据集根据头部姿态分组后,按文献[3,13]中方式进行交叉训练、测试,准确率结果如表5 所示。由表5 可知,当训练数据采用A1序列时,训练样本受头部姿态干扰最小,所有方法均取得较好测试结果,其中L2-Siamese 取得90%准确率高出文献[3]方法4 个百分点;当测试数据采用A3序列时,样本受姿态干扰越大时,所有方法准确率都有所下降,其中文献[13]准确率下降最快,而L2-Siamese 准确率下降最慢,相较于其他方法,L2-Siamese 在姿态干扰下有更好的稳定性。
当训练数据采用A2序列时,所有样本均受到小的姿态干扰。结果显示,小幅度姿态干扰下的样本有助于提升模型的泛化能力,L2-Siamese 同样取得较好测试结果,L2-Siamese对小幅度姿态保持稳定。
当采用A3序列训练模型时,样本受姿态影响最大,文献[13]方法已无法应对较大姿态的干扰。而L2-Siamese 与文献[3]方法相比,各测试序列准确率均高于文献[3]方法,即使在姿态干扰最大的A3测试序列下,准确率高出该方法6个百分点。
当采用{A1,A2}训练序列时,更广泛的训练样本使L2-Siamese 取得最佳测试结果。如表5 所示,所有训练测试序列下,L2-Siamese 准确率均高于其他方法。

表5 按姿态划分Pandora数据集后不同方法的实验结果准确率对比Tab.5 Accuracy comparison of experimental results of different methods after grouping Pandora dataset according to poses
L2-Siamese 仅采用深度图进行训练测试,选择更宽的全连接层,并引入L2 模块及缩放参数对特征进行约束,大量的训练参数增加了模型的学习能力,提升了模型的预测性能,使L2-Siamese 能对小的姿态干扰保持稳定,也能在大的姿态干扰下有较好的性能。
5 结语
为了解决在光照以及头部姿态干扰下的人脸验证问题,本文提出L2-Siamese 网络,该网络直接处理深度图,并通过孪生神经网络提取特征,以及二范数和缩放参数约束特征后,计算图像之间的差异。在公共数据集Pandora 上进行实验对比,在姿态干扰下L2-Siamese 准确率明显高于其他方法。由于深度图对光线变化的稳定性,该模型可被应用于光照条件差的场景,如夜间驾驶等。但同时,L2-Siamese 依靠大量的训练参数提升模型的学习能力,对模型的速度造成影响。在较大姿态干扰下,其准确率依然有很大的提升空间。
未来我们将对网络进一步优化,提升网络效率,同时研究算法,进一步提升在姿态干扰下的准确率。
