基于独立循环神经网络与变分自编码网络的视频帧异常检测
2023-02-24王来花王伟胜
贾 晴,王来花,王伟胜
(曲阜师范大学 网络空间安全学院,山东 曲阜 273165)
0 引言
传统的视频异常检测[1]需要工作人员对海量的监控数据进行长期而严密的观察来发现异常事件。这种检测方式繁琐且极易产生疲劳,容易造成关键信息的遗漏。为了准确地发现异常事件并及时做出响应,设计一种高效、智能的视频异常检测方法变得愈来愈重要。因此,视频异常检测也成为近年来计算机视觉领域的热门研究问题之一。
异常事件的偶发性以及多样性使得异常事件的数据很难收集;此外,异常事件的定义具有不明确性,使得同一行为的定义取决于所依赖的具体场景。例如奔跑这一行为发生在操场上被认为是正常事件,但出现在公共场所则被认为是异常行为。因此,视频异常检测仍然是一项充满挑战性的任务。
早期研究人员通常采用基于轨迹的或手工制作特征的方法进行异常检测。基于轨迹的方法[2]通过目标跟踪和目标检测等方法提取目标对象的行为轨迹,建立正常行为轨迹模型,将与模型不匹配的行为判定为异常。这种方法在拥挤场景尤其是有遮挡或重叠的场景下很难检测出异常。为解决这个问题,研究者们后续提出了基于梯度直方图[3]、光流直方图[4]、混合动态纹理模型[5]、社会力模型[6]等手工制作特征的方法,但这些异常检测模型局限于底层特征,难以表征复杂的高维特征。
随着深度学习的发展,深度学习模型[7-8]逐渐应用到视频异常检测领域,克服了传统异常检测方法的局限性。基于正常帧的重构误差较小、而异常帧的重构误差较大的思想,研究人员提出了一系列基于帧重构的异常检测方法。Hasan等[9]提出了一种可以有效学习视频规律的卷积自动编码(Convolutional AutoEncoder,Conv-AE)网络,通过构建正常事件的模型来检测视频中的异常行为;Ionescu 等[10]提出一种基于Unmasking 框架的异常检测模型Unmask(Unmasking),该模型通过训练二元分类器来区分视频序列,并根据训练准确率判定异常。由于深度模型学习能力越来越强,使得异常事件也可以被很好地重构,导致异常帧经常被误判为正常帧,降低了异常检测的准确率。因此,研究人员又基于正常行为可以预测、而异常事件不可预测的思想,提出了基于帧预测的异常检测方法。Liu 等[11]提出一种基于U-net 的未来帧预测(Frame Prediction,FP)的异常检测方法。该方法首先根据视频帧的历史信息预测下一帧,然后利用预测帧和真实帧之间的差别来检测异常。Zhou 等[12]提出一种注意力驱动(Attention Driven,AD)的未来帧预测模型,该模型解决了前景与背景之间的不平衡问题,将更多的注意力放在视频帧前景以提高异常检测准确度。此外,Fan 等[13]提出了基于高斯混合变分自编码(Gaussian Mixture Fully Convolutional Variational AutoEncoder,GMFC-VAE)网络的异常检测方法,分别利用RGB 视频帧与动态流提取外观和时间信息以检测异常事件。Deepak 等[14]提出了一种由3D 卷积层、反卷积层和卷积长短记忆(Convolutional Long Short-term Memory,ConvLSTM)网络组成的残差时空自编码(Residual SpatioTemporal AutoEncoder,R-STAE)网络,通过学习正常事件的行为规律,并将偏离正常模式的行为判定为异常。Nawaratne 等[15]结合卷积层和ConvLSTM 网络提出了基于增量时空学习器的异常检测方法,利用主动学习不断更新和区分视频帧中的正常和异常行为。Yan 等[16]提出了由外观流和运动流组成的双流循环变分自编码(Two-Stream Recurrent Variational AutoEncoder,R-VAE)网络,通过融合空间信息和时间信息来检测异常事件。帧预测方法优化了异常检测模型的性能,提高了异常事件的检测准确率,但仍存在一些问题。例如,文献[11-12]中通过提取光流信息来约束运动信息,但无法捕获长期运动信息;文献[13]中利用由连续光流帧组成的动态流捕获运动信息,获取了视频帧之间的长期时间信息,但是对动态流的处理提高了模型训练的时间复杂度;文献[14-16]中利用卷积长短时记忆网络对时间信息建模,由于该网络存在梯度衰减问题,导致异常检测性能并没有得到显著的提升。
为解决上述问题,本文提出了融合独立循环神经网络(Independently Recurrent Neural Network,IndRNN)[17]和变分自编码(Variational AutoEncoder,VAE)网络[18]的预测网络IndRNN-VAE(Independently Recurrent Neural Network-Variational AutoEncoder)。该网络在保留视频帧空间信息的同时,能更有效地获取视频帧之间的时间信息。在帧预测的过程中,首先,将视频序列逐帧输入到VAE 的编码网络,以提取空间结构信息;然后,对捕获的空间信息通过全连接层进行线性变换等操作得到潜在特征,进而利用独立循环神经网络获取视频帧之间的时间信息;最后,将潜在特征与时间信息进行融合并输入到解码网络,预测出下一帧信息。在模型训练的过程中,为了提升预测帧与真实帧的相似性,引入了全变分损失、多尺度结构相似性损失和L1 损失的混合损失等损失函数。此外,为生成符合高斯分布的潜在特征分布,引入了生成对抗网络[19]对生成器(由编码网络和潜在特征处理模块中的全连接层FC1、FC2 组成的)和判别器进行对抗训练。
1 基于IndRNN⁃VAE的异常检测模型
异常检测的整体流程如图1 所示,在训练阶段将连续4帧正常帧作为IndRNN-VAE 网络的输入来生成预测帧,并从中学习正常事件的规律特性;在测试阶段将含有异常事件的测试帧输入到已训练好的预测网络IndRNN-VAE 中,得到预测帧。由于正常预测帧的图像质量更高,而异常预测帧的图像质量较差,可以通过计算真实帧Ιt+1与预测帧之间的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)值,进而得到异常得分来判断是否发生了异常事件。
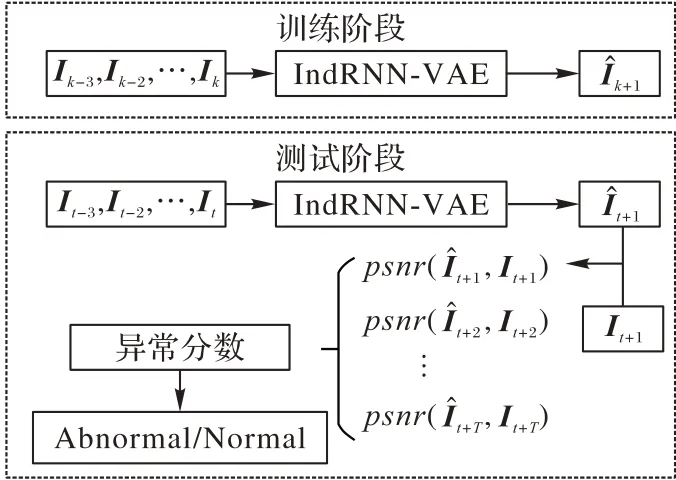
图1 视频异常检测整体流程Fig.1 Overall flowchart of video anomaly detection
1.1 IndRNN-VAE网络搭建
1.1.1 编码网络
由于变分自编码(VAE)在图像生成中的优越性,本文采用VAE 的编码网络提取输入视频帧的空间结构信息。如图2 所示,编码网络Encoder 由4 个Module 模块组成:Module1~Module3 均由两个卷积块与一层2×2 的最大池化层组成,Module4 由两个卷积块组成。其中,每个卷积块均由一个2 维的3×3 的卷积层、一个BN(Batch Normalization)层以及一个ReLU(Rectified Linear Unit)激活函数层组成。

图2 IndRNN-VAE网络模型Fig.2 IndRNN-VAE network model
在进行空间特征提取时,首先,将大小为256×256×3的连续4 帧视频帧依次输入Module1 模块进行处理,得到大小为128×128×64 的特征图;然后,每经一个Module 模块,特征图数量增加一倍,每经过一次最大池化层处理,特征图的分辨率减少为原来的1/2。经过Module1~Module4 四层处理后,最终得到大小为32×32×512 的空间特征。
1.1.2 潜在特征处理
为保持预测图像的时空连续性,本文模型除了要获取视频帧的空间结构信息,还需要学习连续视频帧之间的时间关系。在图2 中的潜在特征处理Latent 部分,本文利用独立循环神经网络IndRNN 对编码网络捕获的空间结构信息进一步处理,从中获取视频帧序列间的时间信息。具体步骤如下:
步骤1 对编码网络提取的空间结构特征分别通过全连接层FC1、FC2 进行线性变换操作,得到均值为μ、方差为σ的高斯分布,然后从高斯分布中采样得到一个大小为4 096×20 的潜在特征分布Z_sampling,即输入数据编码后的特征分布。经过一次线性变化和尺度调整后,得到与编码器最终输出大小保持一致的潜在特征z。
步骤2 如图3 所示,将获得的连续4 个潜在特征zt-3~zt循环输入到循环IndRNN 中,得到时间信息以及最终的隐藏状态ht:

图3 循环IndRNNFig.3 Cyclically Independently recurrent neural network
其中:t代表输入的连续视频帧的第t帧表示预测得到的第t+1 帧的时间信息。在循环训练中,首先对潜在特征zt-3进行全连接操作;然后将初始隐藏状态ht-4与循环权重进行向量点乘;最后输入到ReLU 激活函数中得到下一层隐藏状态ht-3:
其中:zt-3表示输入潜在特征序列的第t-3 帧,ht-4表示第t-4 帧的隐藏状态,W表示输入权重矩阵,c表示循环权重向量,b表示偏差,⊗代表Hadamard 乘积。将得到的隐藏状态ht-3与下一帧潜在特征zt-2结合,再次输入IndRNN,经过不断循环训练,最终得到下一帧时间信息。
步骤3 为了融合时空信息,保留时空间的联系,本文引入了残差块,将最终得到的时间信息与潜在特征按通道数所在维度进行拼接,作为解码器的输入以生成新的下一帧信息。
1.1.3 解码网络
如图2 中Decoder 模块所示,与编码器网络对称,解码网络也由4 个Group 模块组成。Group1~Group3 模块均由两个卷积块及一个反卷积块组成,而Group4 由两个卷积块、一层2 维3×3 的卷积层以及一层Tanh 激活函数组成。其中,反卷积块由一个BN 层、一个ReLU 激活函数层以及一个大小为3×3 的反卷积层组成。
生成预测帧的具体过程如下:首先,将大小为32×32 ×1 024 的时空融合信息输入解码网络;然后,经Group1~Group3 模块处理后,特征图数量减少一半,经反卷积块操作后,特征分辨率增加一倍;最后,通过解码网络的Group4 模块处理后,得到大小为256×256×3 的预测帧。
1.2 模型训练
在模型训练过程中,基于输入数据的潜在特征分布Z_sampling服从高斯分布的假设[18],本文利用生成对抗网络[20]来生成近似于真实特征分布Z_real(Z_real从预先定义的高斯分布p(d)中采样)的潜在特征分布Z_sampling。此外,为提高预测帧与真实帧的相似度,本文利用了梯度损失、多尺度结构相似性损失和L1 损失的混合损失、全变分损失等损失函数对IndRNN-VAE 网络施加约束。
1.2.1 对抗训练
如图4 所示,生成对抗网络由1 个生成器(Generator,G)和1 个判别器(Discriminator,D)组成,其中,编码网络与潜在特征处理模块中的全连接层FC1 和FC2 组合充当生成器,判别器由3 个全连接层构成。在IndRNN-VAE 网络中的生成器训练中,生成器试图欺骗判别器,使判别器认为潜在特征分布Z_sampling来自预先定义的标准高斯分布p(d)。经过循环往复的训练,使潜在特征分布Z_sampling与真实特征分布Z_real逐渐接近。生成器对抗损失函数LG为:

图4 模型训练结构示意图Fig.4 Schematic diagram of model training structure
当生成器训练结束后,固定其参数,对判别器进行训练,其损失函数LD表示如下:
其中:(i,j)表示图像像素的空间索引,D(⋅)表示判别器,G(⋅)表示生成器,I表示输入的视频帧,Z_real表示输入的真实特征分布。
1.2.2 IndRNN-VAE网络训练
通过生成对抗训练,IndRNN-VAE 网络中的生成器生成符合高斯分布的潜在特征分布Z_sampling,然后经Latent 模块处理后输出融合信息,将其作为解码网络的输入以生成预测帧。为使生成的预测帧更加接近真实帧It+1,如图4所示,本文还利用了梯度损失、多尺度结构相似性损失和L1损失的混合损失、全变分损失等损失函数对IndRNN-VAE 网络进行约束,目标损失函数L为:
其中:λgdl、λmix、λtvl分别为梯度损失、混合损失、全变分损失的权重值。
在式(5)中,为增强图像的边缘和灰度跳变部分,保证图像的清晰度,引入了梯度损失函数Lgdl:
其中:(i,j)表示图像像素的空间索引,‖⋅‖1表示L1 范数。为保持亮度和颜色信息不变以及保留图像边缘细节信息,本文引入了混合损失函数Lmix:
其中:a、b分别为多尺度结构相似性损失Lms⁃ssim和L1 损失Llad的权重。
为了降低噪声对生成图像的影响,同时保持图像的光滑,引入了全变分损失函数Ltvl:
其中:(i,j)表示图像像素的空间索引;β用来控制图像的平滑程度,本文依据Mahendran 等[21]的参数设置,将β置为2。
1.3 异常检测评价分数
当预测网络IndRNN-VAE 训练结束后,在测试阶段加载该模型生成预测帧。本文参考Liu 等[11]的方法,通过计算真实帧It+1与预测帧之间的异常得分来判断异常。首先计算真实帧与异常帧的均方误差,得到每一帧的PSNR 值:
其中:i表示像素索引,N表示视频帧的像素总数表示视频帧中的最大颜色数,PSNR 值越高表示生成的图像质量越好。由于网络在训练阶段只学习了正常事件的规律特征,在测试阶段生成的异常预测帧与真实帧之间存在比较大的误差,即式(9)中值较高,使得PSNR 值变小,生成的异常预测帧的图像质量较差。然后将PSNR 值归一化到[0,1]区间,得到视频帧的异常分数
其中:psnrmin、psnrmax分别表示所测试视频数据集的PSNR 的最小值和最大值。由于异常预测帧的图像质量较差,即式(10)中的PSNR 值较低,且S()值随着PSNR 值的减小而减小,导致异常预测帧的异常分数S()偏低。因此,最后根据每一帧所得的异常分数S()判断异常,视频帧所获异常得分越低,表明异常事件发生的可能性越大。
2 实验结果与分析
2.1 实验数据与评价指标
UCSD Ped1 数据集是通过固定在学校人行道较高位置的摄像头拍摄的,记录了行人逐渐靠近和离开摄像机的场景,包含了分辨率为238×158 的34 个训练视频片段和36 个测试视频片段。每个视频片段由200 帧组成,其中异常的事件是出现在人行道上的自行车、滑板以及小汽车。
UCSD Ped2 数据集中行人移动的路径与摄像机记录的场景平行,由16 个训练视频片段和12 个测试视频片段组成,分辨率为360×240。异常行为包括骑车、突然出现的大卡车等。
Avenue 数据集包括16 个训练集和21 个测试集,总共有30 652 个视频帧,分辨率为640×360。异常事件包含行人走错方向、游荡以及跑步等。图5 给出了3 个数据集的异常事件的示例,异常事件用方框框出。

图5 不同数据集的异常事件示例Fig.5 Examples of abnormal events in different datasets
为评估模型性能,本文利用曲线下面积(Area Under Curve,AUC)以及等错误率(Equal Error Rate,EER)作为评价指标。AUC 值通过绘制由假正率、真正率作为横纵坐标轴的接收者操作特征曲线并计算其与横轴之间的面积得到。AUC 值越大,表明模型的性能效果越好。EER 的值为接收者操作特征曲线与由坐标(0,1)、(1,0)构成的直线相交点的横坐标值,其数值越小则模型效果越好。
2.2 实验设置
在实验的过程中,每个视频帧的分辨率均被调整为256×256,同时对像素值进行了归一化处理。实验中判别器的学习率设置为0.000 5,生成器的学习率设置为0.001。损失函数权重在不同的数据集差别不大,当λgdl=0.1、λmix=1、λtvl=0.01 时,UCSD Ped1、UCSD Ped2 数据集实验效果最好;当λgdl=1、λmix=10、λtvl=0.01 时,Avenue 数据集实验效果最好。为了更有效地提取时间信息,本文设置连续输入视频帧数为4 帧,每次循环的IndRNN 层数为5 层。
2.3 与目前先进方法对比
为验证本文方法的有效性,如表1 所示,本文在UCSD Ped1(以下简称Ped1)、UCSD Ped2(以下简称Ped2)和Avenue三个数据集上与近些年主流研究方法Conv-AE[9]、Unmask[10]、FP[11]、AD[12]、GMFC-VAE[13]、R-STAE[14]、R-VAE[16]进行了实验对比,其中对比方法的结果数据均来自相应的参考文献。

表1 相关异常检测方法的AUC值和EER值对比 单位:%Tab.1 AUC value and EER value comparison of related abnormal detection methods unit:%
由表1 可得,与其他异常检测方法相比,本文方法的检测性能有了明显提升,在Ped1、Ped2 和Avenue 数据集上的AUC 值和EER 值达到84.3%、22.7%、96.2%、8.8% 和86.6%、19.0%。与GMFC-VAE 方法相比,本文方法的性能在Ped2、Avenue 数据集达到了最优,在Ped1 数据集上表现效果欠佳。这是由于Ped1 数据集分辨率较低,GMFC-VAE 方法利用双流网络更容易识别特征,并且该方法利用动态流能够捕获长时间的运动特征,因此GMFC-VAE 方法在Ped1 数据集上取得了较好的性能。
为进一步验证本文方法的有效性,本文使用每秒生成帧数(Frames Per Socond,FPS)作为时间性能指标,并与相关异常检测方法进行了时间复杂度的对比。表2 给出了对比结果。
本文方法在NVIDIA Tesla V100 GPU 上运行,采用pytorch 平台上的Python 语言进行编程,得到时间性能为28 FPS。通过观察表2 可以发现,与其他异常检测方法相比,本文方法具有较好的时间性能。文献[13]中所提GMFCVAE 模型未提供时间性能指标,但该方法利用双流(stream)网络分别提取时间和空间特征,然后进行融合。然而动态流的获取首先需要提取视频帧的光流信息,然后通过Ranking SVM 排序算法对光流信息训练。光流信息的提取有较高的计算成本,且利用Ranking SVM 训练额外增加了预处理时间成本。本文方法不需要对输入数据进行预处理,节约了时间成本。

表2 相关异常检测方法的时间性能对比Tab.2 Time performance comparison of related abnormal detection methods
此外,本文在Ped1、Ped2 和Avenue 三个数据集上分别计算了正常帧和异常帧平均异常得分的差值ΔS,ΔS的值越大表明越能正确区分正常帧与异常帧。如表3 所示,与重构模型Conv-AE[9]以及未来帧预测模型的基准方法FP[11]进行对比,可以发现本文方法得到的ΔS值分别为0.263、0.497、0.293,均大于其他两种对比方法的ΔS值,这说明了本文方法区分正常帧和异常帧的能力比较强。

表3 不同数据集上的差值ΔS对比Tab.3 Difference value ΔS comparison on different datasets
2.4 视频帧异常分数可视化
图6~8 给出了本文所提方法在Ped1、Ped2 和Avenue 数据集中的一段视频片段的异常分数和对应的视频标签值的可视化结果。异常事件分别为Ped1 和Ped2 数据集中骑车与滑滑板以及Avenue 数据集跑步与做奇怪的动作等。通过可视化结果可以得出正常事件的异常分数曲线呈平稳状态,分数值趋近于1,当异常事件出现时,异常分数曲线会有明显的下降趋势变化,异常得分接近于0。这说明本文方法对异常事件的发生十分敏感,并能准确响应。

图6 Ped1数据集上视频帧的异常分数Fig.6 Anomaly scores of video frames on Ped1 dataset
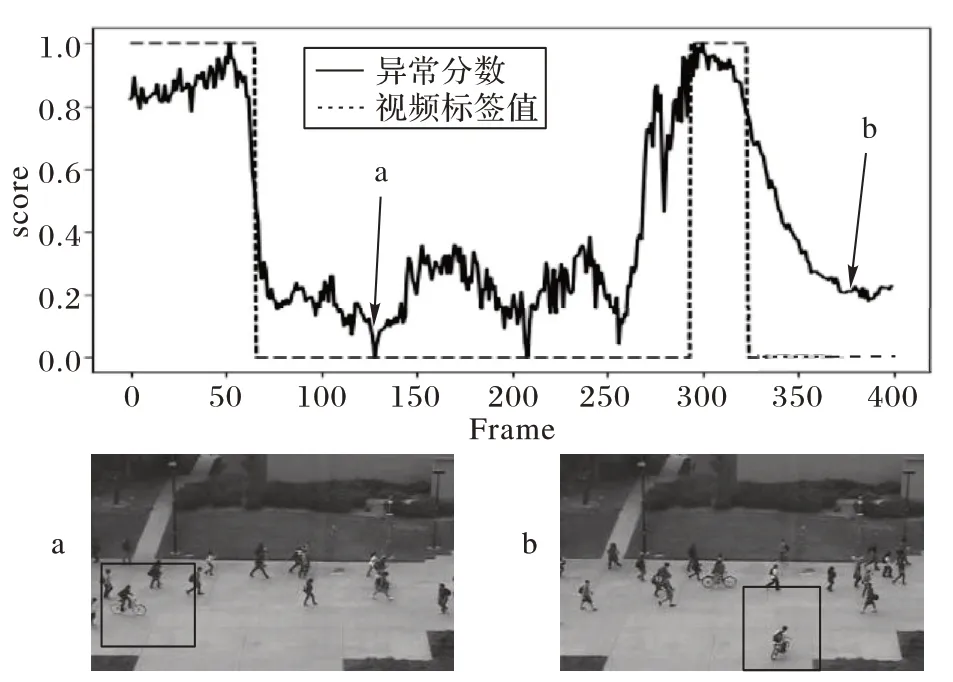
图7 Ped2数据集上视频帧的异常分数Fig.7 Anomaly scores of video frames on Ped2 dataset
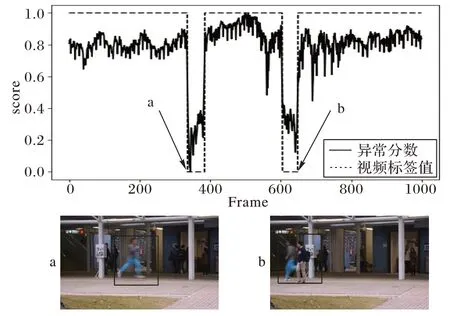
图8 Avenue数据集上视频帧的异常分数Fig.8 Anomaly scores of video frames on Avenue dataset
2.5 消融实验
2.5.1 IndRNN层数分析
为了分析IndRNN 层数对异常检测性能的影响,本文设置了不同的网络层数值,并在Ped2 数据集上进行了实验,图9 显示了不同层数下的模型检测性能。通过观察可知,当IndRNN 层数为5 层时,模型的性能达到最优,故本文将IndRNN 的层数设置为5。
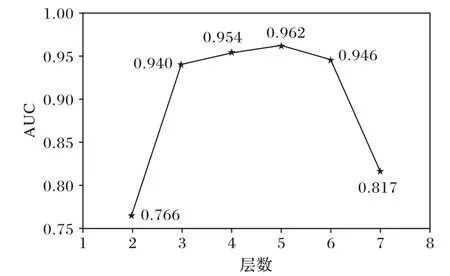
图9 Ped2数据集上不同层数的AUC值Fig.9 AUC values of different layers on Ped2 dataset
2.5.2 模型分析
为了验证本文所提方法的每个模块都发挥了作用,在Ped2 数据集上进行了对比实验。首先,分析加入时间信息的效果,本文设计实现了一个只含有编解码结构,没有IndRNN 的模型变体,称为Base;然后,测试加入IndRNN 时间模块的效果,得到Base+IndRNN 模型。通过观察表4,发现性能有了明显的提升,与Base 模型相比AUC 值提高1.6 个百分点,EER 值降低1.5 个百分点,验证了使用IndRNN 捕获时间信息的有效性。同时为了验证加入生成对抗网络GAN 的异常检测性能效果,设计了Base+IndRNN+GAN 模型。观察表4发现,相较于Base+IndRNN 模型,AUC 值提高0.6 个百分点,EER 值降低2.1 个百分点。因此,将变分自编码器、IndRNN以及生成对抗网络组合在一起可以达到更好的异常检测效果。

表4 网络中不同模块组合的性能 单位:%Tab.4 Performance of different module combinations in network unit:%
2.5.3 损失函数分析
为了分析损失函数对异常检测性能的影响,在Ped2 数据集上进行了不同损失函数组合的实验测试。通过观察表5 可以发现,梯度损失+混合损失的损失组合比梯度损失+多尺度结构相似性损失的损失组合性能提升了2 个百分点。加入全变分损失后,性能提升了0.3 个百分点,这验证了混合损失与全变分损失的有效性。由于加入混合损失后模型性能提升更明显,进一步说明了混合损失在网络训练中发挥着更重要的作用,在参数调整时,也赋予了梯度损失和混合损失更高的权重值。

表5 网络中不同损失函数组合的性能 单位:%Tab.5 Performance of different loss functions combinations in network unit:%
3 结语
本文提出的IndRNN-VAE 预测网络分别利用变分自编码器和独立循环神经网络提取空间结构信息和时间信息,并将它们进行了有效的融合。为了使预测帧尽可能地接近真实帧,本文引入了全变分损失、多尺度结构相似性损失与L1损失的混合损失等损失函数对IndRNN-VAE 进行训练。在IndRNN-VAE 训练的过程中,为了获得服从标准高斯分布的潜在特征分布,本文引入了生成对抗网络。此外,本文在UCSD Ped1、UCSD Ped2、Avenue 三个典型数据集上进行了大量的实验。实验结果表明,与主流方法相比,本文所提方法的性能达到了较高的水平。
