粒子群局部优化的反距离权重插值算法
2023-02-24李中志李斌勇
向 峰,李中志*,熊 熙,李斌勇
(1.成都信息工程大学 网络空间安全学院,成都 610255;2.先进密码技术与系统安全四川省重点实验室(成都信息工程大学),成都 610225)
0 引言
目前,在各处布置自动监测设备是获取环境中污染物或其他研究成分实时数据,并绘制监测指标在整个研究区域的空间分布情况、分析其时空演变过程的重要途径。由于这些自动化监测设备数量众多,而且离散地分布在研究区域中,不便于及时维护,部分监测设备会受各种环境因素的影响导致数据上传不及时或丢失,不利于监测任务的进行。此外,由于还受监测成本的限制,很难通过大面积布置监测设备来获取空间中任意位置的真实数据,但可以对这些丢失数据或未布置监测的站点处的值进行估计,空间插值算法可利用在空间中已获取到的真实数据,根据待估计点与当前已知点之间的空间相关关系对未知区域的取值进行估算插值,以满足对损坏节点处的丢失数据进行补齐、得到某一未知点的估计数据以及更进一步研究的需要。
目前已有多种空间插值算法被提出,其中较为经典的有泰森多边形法、反距离权重(Inverse Distance Weight,IDW)法、克里金(Kriging)以及样条法等[1],这些算法在不同的场景中有各自的优势[2],并且在气象领域的降水[3]、气温[4]、空气质量[5]的分布规律,以及水土资源[6]、环境污染物[7]分布的研究领域应用广泛。
近年来由于神经网络较强的非线性拟合能力,许多学者也将神经网络应用于空间插值中,如,胡广义等[8]使用反向传播(Back-Propagation,BP)网络对降雨量进行插值;陈飞香等[9]使用径向基函数(Radial Basis Function,RBF)网络预测土壤铬含量,相较于简单的BP 网络,收敛速度更快,结果也更好;杜景林等[10]使用改进的聚类算法确定RBF 的参数;曾金迪等[11]提出了空间自回归网络(Spatial Auto-Regressive Neural Network,SARNN),通过空间距离求解权重。然而上述模型只是简单地拟合了研究区域某一时刻的空间相关关系。Ma 等[12]提出一种整合时空关系的Geo-LSTM(Geographic Long Short-Term Memory neural network)模型,利用Geo 层提取数据集的空间特征,而LSTM 则从序列数据中学习数据间的时间依赖性,最终使该模型同时具有插值及预测能力,但需要足够多的历史数据记录进行训练。Zhu 等[13]利用条件生成对抗网络获取空间分布数据集中的深层空间特征,通过地形数据训练生成器,最后使用得到的生成器能够准确地生成空间数据,但对其他类型数据的生成能力还需更多验证;此外该模型需要一定数量的高精度训练样本数据,且计算量偏大。
尽管上述研究使用神经网络取得了较好的效果,但还是需要一定的学习与训练以保证准确度,否则所得结果会不稳定。IDW 算法原理简单,运算速度较快,易于实现,仍具有一定的实用价值。近年来学者不断改进IDW 以提高准确性,如参考点选择方式[14-15]、幂指数[16]等。李慧晴等[17]考虑了地形对IDW 的影响,通过增设与地形相关的权重系数提高了精确度,但通用性不佳。空间数据中存在的空间异质性[18]包括某一处的属性与邻近区域不同(局部异质),以及研究区域中有多个属性互不相同的子区域(空间分层异质)两种情况。文献[19]中使 用K 近邻算法(K Nearest Neighbors,KNN)判断待插值点的空间属性,通过降低分层异质参考点的权重以提高最终结果的准确性,但存在误判的问题。文献[20]中考虑了要素空间分布的各向异性,得到的参考点权重能更好地反映数据实际的空间分布情况。文献[21]中使用粒子群优化算法,对参考点个数、幂指数、各向异性的参数进行全局寻优,提出多参数协同优化反距离权重插值(multi-Parameter co-optimization Inverse Distance Weighting,PIDW)算法,具有较好的普适性,但忽略了局部特性,因此在部分场景反而会降低准确度。
对于存在空间异质性的研究区域,使用固定的全局参数无法反映局部情况,会造成一定的局部误差,而针对区域局部特性设置相关系数的改进策略,虽然能够提高准确度但也会耗费一定的人力。因此,本文改进PIDW 算法,提出粒子群算法局部优化的反距离权重(Particle swarm Local optimization Inverse Distance Weight,PLIDW)算法,并使用模拟数据与气象要素数据进行对比验证。
1 算法概述
1.1 各向异性的反距离权重模型
1.1.1 反距离权重法
反距离权重法假设观测点对于插值点的影响随距离的增加而减弱,即成反比关系,表达式如下:
其中:Z*为预测值;n为选取的参照采样点数目;λi为观测点对估计插值点的权重系数;Zi为第i个检测点所测的实际值。权重系数由式(2)给出:
其中:di为待插值点与第i个观测点的距离;b为距离衰减系数。
1.1.2 各向异性模型
文献[21]引入“椭圆”距离,可以体现出参考点选取时,不同方向的差异:
对于坐标系中的两点(xi,yi)、(xj,yj),参数λ调节了二者在Y轴方向上的距离:λ>1 时增加Y轴方向的距离;λ<1 时则会使X轴方向的距离相对增加;λ=1 即退化为欧氏距离。
式(3)只调节了坐标轴方向上的距离,将坐标按式(4)变换,即可反映各向异性:
由式(3)、(4)最终可得到椭圆距离如下:
其中:代表调整后的椭圆距离;Δx与Δy为原数据间的欧氏距离;θ∈(0,2π)为旋转角度。
1.2 局部参数寻优反距离权重法
考虑到空间异质性的存在,本文通过粒子群优化算法,使用交叉验证的策略,分别对已知的参考点以式(2)中的参数n、b与式(5)中的参数θ、λ进行寻优并保留局部优化结果。
1.2.1 粒子群优化算法
粒子群优化算法模仿了鸟群的觅食行为,通过信息共享获取当前群体最优值[22],并经过迭代得到最终的全局最优值,有全局性能好、简单易实现的优点[23]。
算法运行时,粒子的位置向量p根据自身经过的最佳位置pbest和种群最佳位置gbest进行更新:
其中:ω为惯性系数;c1和c2为学习因子,反映粒子的学习能力;k代表迭代次数;xid代表当前d维的位置值;pid与pgd分别代表粒子自身第d维的最佳位置与群体最佳位置值,φ1与φ2是[0,1]区间内均匀分布的随机数。
1.2.2 优化策略
已知研究区域共有N个样本点{Z1,Z2,…,ZN},对其中任意的Zi利用粒子群优化算法对参数P=(n,b,θ,λ)进行寻优,得到Zi的一组最佳参数Pbesti,如式(7)所示:
其中:代表估计时不包含点Zi本身;Pk为某一组参数向量,对应了一个粒子的坐标;得到的Pbesti即为在点Zi处寻找到的一组最优参数,需要将它进行存储。
实际使用环境不一定处处都存在各向异性的情况,为了减少多参数寻优带来的不稳定,本文在对每个站点的参数寻优过程中使用两个粒子种群:一个种群对P=(n,b,θ,λ)进行完整的寻优,而另一个种群固定参数θ=0 和λ=1,即只对参数n、b进行寻优,最后只保留最优种群的全局最优结果。
1.2.3 算法流程
本文算法主要包含参数寻优过程以及插值使用过程,完成对所有已知样本点的最佳参数寻优后,得到相应的Pbesti(i=1,2,…,N)。假设空间距离越近,最优参数的取值也越相似,因此对于未知点的取值,算法将使用最近样本点的最优参数进行近似优化估计。
算法的整体流程如图1 所示。由于各个参考点的参数寻优过程相互独立,因此可进行并发优化处理,提高程序的运算速度。此外,由于算法需要反复地计算节点之间的距离,找到最近的参考点,为了提高效率,本文使用K 维树(KDimensional Tree,KD-Tree)优化查询过程,可减少选择最近参考点时的计算时间[24]。

图1 本文算法流程Fig.1 Flowchart of proposed algorithm
2 仿真实验与结果分析
为了评估算法的效果,本文首先使用仿真环境进行对比实验。将本文算法与经典的IDW 算法、Kriging、PIDW、SARNN 进行对比。
2.1 评价方法
本文通过计算预测值与真实值之间的平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)、均方根误差(Root Mean Square Error,RMSE)以及平均绝对误差(Mean Absolute Error,MAE)并统计误差的最大值(MAXimum,MAX),对算法的效果进行评估。其中MAPE、RMSE 与MAE的数学表达式如式(8)~(10)所示,数值越小越准确。
2.2 仿真数据
本文对曲面进行插值测试,曲面的函数方程如下:
插值实验区间为(0,1),曲面的图像如图2 所示。
图2 测试曲面函数图像Fig.2 Image of test surface function
2.3 实验方法
实验随机生成50 组坐标点作为参考样本点,另外生成100 组坐标点进行效果评估,选择较少数量的参考点更能反映出不同算法间的差异。部分算法的参数设置与实现如下。
1)IDW。经过多次实验,设置参考最近7 个站点,距离衰减系数为2。
2)SARNN。输入层传递函数选择Softmax,隐含层激活函数选择ReLU(Rectified Linear Unit),损失函数选择RMSE,优化器选择随机梯度下降(Stochastic Gradient Descent,SGD),输入输出层神经元数为n,隐含层数为2,神经元数目均为2n,n为参考的样本点数目。使用Dropout 与Early stop防止神经网络过度拟合[25],神经网络由PyTorch 实现。
3)PIDW。粒子群算法需要寻优的参数为:n、b、θ、λ。经过多次实验测试,本文参照文献[15,17,19-21]的应用情况及建议,选取n∈[4,10],该范围能够应对多数场景;b∈[1,4];θ∈[0,2π],无需更改;λ∈[0.01,100],该参数范围可以根据实际情况调整。
4)PLIDW。参数n、b、θ、λ的设置与PIDW 一致;另一种群固定设置θ=0 和λ=1,其他也与PIDW 的参数保持一致。
2.4 仿真实验结果及讨论
仿真实验结果如表1 所示。预测值(Predictive Value,PV)与真实值(Actual Value,AV)的对比如图3 所示,数据点越贴近轴线PV=AV 说明越准确。
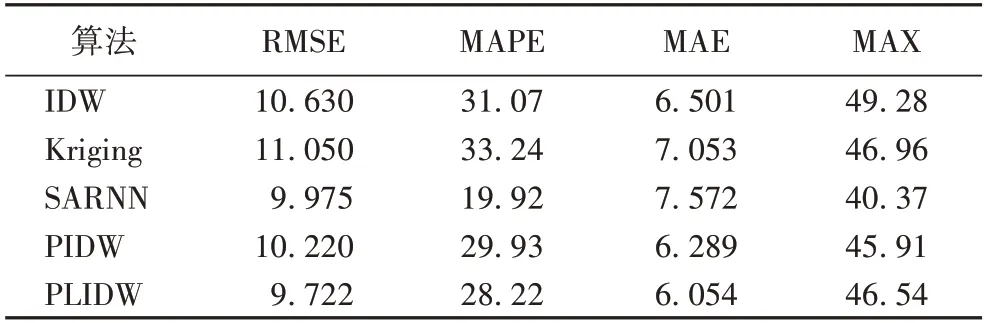
表1 仿真实验结果 单位:%Tab.1 Results of simulation experiments unit:%
如表1 所示,PLIDW 在RMSE、MAE 上表现最佳,相较于PIDW 与IDW,PLIDW 的四项指标都更低,准确度更高。SARNN 的MAPE 最低,这与它的MAX 最小有关,如图3(c)所示,在AV(0,0.2)的区间内,SARNN 的预测点偏离PV=AV 轴线的程度最低,但总体偏差更大,这可以从MAE 值得到反映,它的MAE 为7.572%,高于其他对比算法。Kriging 也出现了相同问题,总体上也出现偏差,MAE 值仅次于SARNN。由此可见,相较于对比算法,PLIDW 具有明显优势。
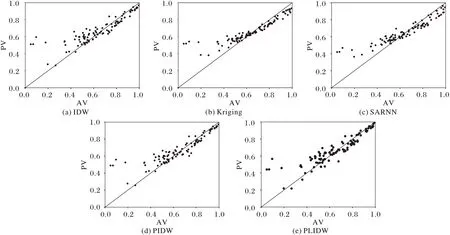
图3 各算法模拟数据散点图Fig.3 Simulated data scatter plot of different algorithms
3 气象要素数据实验与结果分析
为了得到更加可靠的结论,本文以四川省2021 年12 月某日整点的气温为例,在真实场景中对各算法进行比较,所有的数据来源于中国气象数据网,数据集中共有145 个自动化监测站点的监测数据。
本文首先以不放回的形式从所有的站点中随机抽取20个站点用作效果评估,再从剩余的站点中抽取站点作为参考点。第一组实验抽取20 个,后续实验以20 的倍数递增抽取,以此对数个算法进行多次对比实验,相关参数的设置与2.3节保持一致。
为了与SARNN 进行对比,需要将数据进行归一化,归一化方式如式(12)所示:
3.1 评价指标
由于本文选用的评价指标较多,为了更加直观地对各个算法进行比较,将所有不同参考点数量的实验结果的四个评估指标按照式(13)计算综合评分:
式(13)综合考虑了4 个评估指标,得分越高者综合表现更佳,本文以此衡量算法的准确度。
3.2 实验结果及讨论
将各个算法插值的结果通过式(8)~(10)计算误差,并统计误差的最大值IMAX。将所有实验的结果按照式(13)计算,得到的相关数据如表2 所示。PLIDW 的各项指标表现相较于对比算法更平稳,各个评测指标处于最优或偏上的水平。在6 组不同参考点数的测试中,PLIDW 有4 组的综合表现优于其他对比算法,虽然随着参考点数目的增加,SARNN 因为神经网络的拟合能力使优势得以显现,但收敛也因此减慢。而PIDW 由于未考虑区域中存在的局部特性,在少数场景中出现弱于经典IDW 的情况。总体上看,PLIDW 算法的表现明显优于IDW 与PIDW 算法,相较于PIDW 算法,PLIDW 算法的准确度提高了4.18%~40.08%。

表2 气象要素数据的实验结果Tab.2 Experimental results of meteorological element data
综上所述,本文提出的PLIDW 算法考虑了局部参数选取对精确度的影响,并使用两个粒子种群进行参数寻优,缓解多参数寻优的不稳定性对结果产生的影响,提高了算法的适应能力,在多数的实验对比场景中占据优势,不需要其他的辅助数据,易于实现和使用。
4 运行效率分析
由于比传统算法多了粒子群参数寻优的过程,因此增加了本文算法的时间复杂度。为在精度与耗时之间进行平衡,首先需对本文算法的时间复杂度进行分析。假设参考点总数为N,选择n个样本点参与计算,寻优区间为[a,b],a≤n≤b,迭代次数为K,种群规模为M。算法首先遍历N个参考点,分别找到其中距离最近的b个点,复杂度为O(Nbf(N)),f(x)表示某种寻找最近点的算法复杂度。设对一个粒子进行评估耗时为O′(1),可知对一个参考点的优化耗时为O′(KM),整个优化过程的时间复杂度为O′(KMN),最后还需寻找一次最近邻点再计算,与IDW 算法的时间复杂度相同,为O′(nf(N))。最终可得整体的时间复杂度为:O(Nbf(N)) +O′(KMN) +O′(nf(N)),实际应用场景中KM的量级与N较为接近,对计算时间影响较大,可针对它进行调整以减少耗时。
因为对K、M的取值作手动观察调整较为困难,本文根据文献[26]的建议,固定设置种群规模M为30,以在第3 章的数据中随机抽取120 个采样点为例,逐渐提高K的取值并计算准确度(式(13))得到的结果如图4 所示。

图4 准确度结果Fig.4 Results of accuracy
如图4 可以看出,迭代次数增加到一定程度时,算法的准确度很难再有明显提升,计算耗时反而成倍增加,因此迭代20 次左右即可。虽然本文算法的时间复杂度高于传统算法,但由于实际使用时参考点的总数通常在几十到数百之间,因此仍旧可以接受,在使用时逐渐增加迭代次数进行尝试,并尽量使量级不超过待寻优的参考点的数目N,可减少计算耗时。
5 结语
本文提出的PLIDW 算法提高了IDW 算法的准确度,相较于全局寻优的PIDW 算法,主要具有以下的特点:
1)考虑了研究区域内的局部特性,相较于使用不变的全局参数,能够减小局部误差。
2)算法同时还考虑了对各向同性模型的参数优化,与各向同性模型寻优结果的适应度进行比较,保存最佳的模型参数,减少寻优难度。
3)在多参数优化的过程中,各站点之间相互独立,易于设计并发程序以提升运行效率。
由于加入了粒子群算法,本文算法的复杂度有所提高,探索并使用更简单快速的优化算法可进一步提高运行效率。此外,本文算法对未知点插值参数的选取方式还可进一步改进,本文直接根据最近距离进行选择,而综合衡量周边多个节点的情况进行推断可能会更加准确。
