基于韵律特征辅助的端到端语音识别方法
2023-02-24万根顺高建清付中华
刘 聪,万根顺*,高建清,付中华
(1.科大讯飞股份有限公司 AI研究院,合肥 230088;2.西安讯飞超脑信息科技有限公司,西安 710000)
0 引言
近年来,随着应用数据的持续增加和计算能力的稳定提升,基于神经网络的深度学习得到了快速稳定的发展,在图像、语音和自然语言处理等领域均取得了重大突破[1]。语音作为人类最自然的沟通方式,逐渐成为人机交互的主要途径之一,语音识别不仅极大地提高了人机交互的便捷度,更是大幅提高了内容记录总结等相关从业人员的工作效率。
尽管语音识别系统在部分场景上识别率已经超越了人类,但在实际使用中仍有各种各样的问题难以解决,影响用户体验,尤其对于一些发音相近但是解码结果可以有多种组合的场景,容易引起后续语义理解的混淆。例如,“相对来说,确实比视野 更重要”和“相对来说,确实 笔试 也更重要”在没有明确上下文的情况下均有一定的语义合理性。而不同的停顿方式以及不同的重音强调方式,均会造成语义理解的偏向性。例如,当出现“bi3 shi4ye3”的停顿情况时,听者倾向于选择“比 视野”的语义进行理解;而当发音人停顿不明显,重音强调落在“ye3”的时候,听者倾向于选择“笔试也”的语义进行理解。因此,如何使语音识别结果更加符合用户的原始表达,成为语音识别中的一个重要研究课题。
对于发音相同或者相近、语义不同的解码组合,因为声学的区分性较弱,所以语言模型对于识别结果的筛选和确认影响较大。采用面向文本领域层面的自适应方法,可以在一定程度上实现解码空间的约束。常见的文本领域自适应方案包括语言模型的自适应和热词激励等。具体地,语言模型的自适应将领域相关文本加入通用语料训练带领域偏置的语言模型,或直接使用领域相关文本训练领域语言模型联合通用语言模型插值解码,从而强化领域文本的解码空间,提升领域相关内容的输出概率,但该方法需要进行领域的确认和文本的收集,使用场景受限;而热词激励,包括传统的基于字典树的后验激励和基于上下文相关的注意力机制端到端(Contextual Listen Attend Spell,CLAS)[2]方案的模型激励等,主要是对用户想要强化或重点关注的文本进行激励。
上述方法需要提前进行文本的选取和设置,需要用户事先知道领域信息或提供相关的热词。另一方面,用户在实际说话时,即使是发音完全相同,但因语义表达的不同,在语调、时域分布以及重音等韵律特征层面,也会表现出一定的区分性。例如,用户发音时,一般会在分词合理的地方进行停顿,而不会在任意字之间随意进行停顿。因此,直接使用韵律信息辅助进行语音识别也是一种可行的解决方法。基于韵律信息辅助的语音识别,目前国内外的研究思路较为固定。一般考虑提取基频或共振峰等韵律特征,然后将其加入特征向量[3],但是该方法的韵律特征对于语言部分的补充性较弱,无法最大化韵律特征对声学和语言的作用;或者直接使用带韵律标注的语料库训练韵律相关语音识别系统[4],但是因为缺少大规模具有韵律标注的语料库而难以推广,尤其是无法在工业产品中进行应用;其他对于韵律特征的使用,如利用时长模型对语音识别输出的最优多候选结果(N-best)结果进行重打分,需要额外增加对于时长的预测等造成计算量的增加[5]。而随着端到端语音识别系统的应用推广,声学与语言模型之间的关联性得到了进一步加强。尤其是当用户发音本身存在一定的口音时,声学信息间的混淆性增大、区分性变弱,容易导致语言模型的主导性变强,发音相同或相近、语义不同相关的识别错误更加常见。因此,如何基于端到端框架,更显式地利用到用户的韵律信息,平衡声学与语言之间的联系,对语音识别的效果提升以及后续的语义信息的理解,有着重要的影响,也能够进一步解决端到端语音识别落地鲁棒性的业界难题。
为了更好地利用说话人的韵律信息,减少发音相同或相近而语义不同等造成的语音识别结果的混淆,本文提出了一种基于韵律特征辅助的端到端语音识别方法。该方法结合编码-解码语音识别框架中的注意力分布等相关信息,提取发音间隔信息表征、发音信息能量表征等韵律信息,进而通过与解码端的融合更好地强化声学信息与语言模型的结合;同时,在二遍重打分过程中,通过韵律信息增加语言得分的惩罚,显式增加发音相同或相近语义不同的解码结果间的区分性,提升语音识别效果的合理性。
1 基于韵律特征辅助的端到端语音识别
本文基于注意力机制的编码-解码语音识别框架,利用注意力分布信息提取发音时长、停顿时长等反映说话人韵律信息的特征,提出一种结合韵律特征辅助的端到端语音识别方法,缓解语音识别发音相同或相近而语义不同等造成的识别错误。
1.1 基于注意力机制的编码-解码语音识别框架
目前,端到端语音识别模型常见的框架包括连接时序分类算法(Connectionist Temporal Classification,CTC)[6-8]、循环神经网络转换器算法(Recurrent Neural Network Transducer,RNN-T)[9-11]和基于注意力(Attention)机制的编码-解码(Encoder Decoder,ED)[12-14]等算法。其中,RNN-T 相对于ED模型更适合流式语音识别,但效果较ED 存在一定的差距;同时,ED 模型也弥补了CTC 上下文独立假设的缺点,对语言信息的建模能力更强。因此,本文选用ED 框架作为后续研究的基础框架。基于注意力机制的编码-解码语音识别框架如图1 所示。
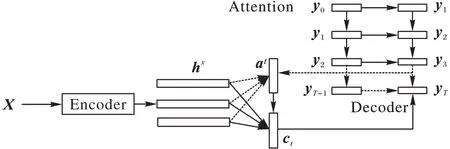
图1 基于注意力机制的编码-解码语音识别框架Fig.1 Encoder-decoder speech recognition framework based on attention mechanism
如图1 所示,该框架主要包括编码端、注意力模块和解码端三部分。编码端一般由循环神经网络(Recurrent Neural Network,RNN)[15-16]和卷积神经网络(Convolutional Neural Network,CNN)[17-18]等神经网络构成,其结构和传统的声学结构类似,即利用音频特征的输入X=(x1,x2,…,xK)获取高阶特征的表示在获取隐层特征后利用注意力模块重点关注与当前解码时刻信息强相关的隐层信息后,传递给解码端得到最终的文本序列Y=(y1,y2,…,yT)的输出概率分布,具体如式(1)所示。因为解码端采用自回归的方式进行解码,与上一时刻的输出相关,因此也发挥了语言模型的功能,从而实现了声学模型与语言模型的联合优化。
注意力模块基于编码端隐层特征,获取每次解码时所需的上下文信息ct,具体计算过程如式(2)~(7)所示:
t时刻的隐状态表示st通过RNN 等神经网络进行建模,输入包括上一时刻解码结果的输出yt-1、t-1 时刻的隐层状态输出st-1和上下文信息ct-1。而vT、Wh、Wd、Ws和ba、bs作为训练参数,主要利用st从编码端高阶的特征输出中提取当前时刻解码所需要的信息ct,然后与st拼接,并利用RNN 模型获取dt,以作为输入参与最终的解码。
基于注意力机制的端到端语音识别方法的突破,进一步降低了语音识别落地的门槛。但是,声学和语言模型联合建模的方式,将ct与语言模型相关的隐层表达st拼接作为解码端的输入,容易让解码端对语言模型产生一定的依赖性,削弱声学信息建模的能力。因此,当出现发音相同或相近而语义不同的解码可能性时,ED 模型对于结果的选择更加依赖语言模型。如何借助用户韵律信息等说话人声学特征,强化ED结构声学信息与语言信息能力的耦合,值得进一步的研究。
1.2 韵律特征的表示与提取
韵律特征的时域分布表示的是说话人发音内容的时间特性。例如,“bi3 shi4 ye3 geng4 zhong4 yao4”在不考虑上下文的情况下,可能识别为“比视野更重要”,也可能识别为“笔试也更重要 ”。在语音识别的过程中,虽然两者的发音完全相同,但是语义却完全不同,容易导致后续语义理解的偏差。而一般情况下,用户真实的语义表达和韵律之间存在较强的相关性。如果是“比 视野 ”,则不同词之间“比bi3”与“视shi4”的间隔应大于同一个词内“视shi4”与“野ye3”的停顿间隔;如果是“笔试 也”则反之,即同一个词之间“笔bi3”与“试shi4”的间隔应小于不同词之间“试shi4”与“也ye3”的停顿间隔。因此,可以考虑加入时域分布相关的韵律特征辅助识别。
要想获取用户相关的发音时长以及停顿信息,首先需要确认解码结果字与字之间的边界信息等。传统方法中,可以通过强制对齐获得每个音素的起止时间信息,CTC 也可以使用尖峰位置作为字的时间信息等。而ED 模型中,Attention机制作为编码端与解码端的连接,能够通过对编码端声学信息的有效选取实现解码端的稳定解码。具体地,Attention 机制在每次解码时,都会关注到与当前解码相关的若干语音帧,即可以通过Attention 分布作为解码的时间边界信息。为了提升Attention 对于声学相关边界信息获取的准确性,常采用CTC 进行辅助训练,强化Attention 分布的时域相关性,因此本文后续均采用联合CTC 的训练方式。
因为没有明确的对于当前解码单元的出现时间和截止时间的界定,为了实现时域分布的统一表示,本文通过设定关注度的阈值,将从左到右关注度大于阈值的第一帧作为当前字的起始时间Tb,将从右到左关注度大于阈值的第一帧作为当前字的截止时间Te,同时使用关注度最大帧的下标作为当前字的确信时间Tc,具体如图2 所示。

图2 基于注意力系数的时域分布表示Fig.2 Time domain distribution representation based on attention coefficient
根据当前解码单元的起始时间Tb、截止时间Te和确信时间Tc,时域分布相关信息可以表示为:
1)发音停顿信息表征:第i+1 个解码单元Attention分布的起始时间-第i个解码单元Attention 分布的截止时间,即
2)发音持续信息表征:第i个解码单元Attention 分布的截止时间-第i个解码单元Attention 分布的起始时间,即
3)发音间隔信息表征:第i+1 个解码单元Attention分布的确信时间-第i个解码单元Attention 分布的确信时间,即。
4)发音能量信息表征:发音持续信息表征范围内的能量和。
在获得发音停顿信息、发音持续信息和发音间隔信息等时域分布信息和发音能量信息后,通过编码即可得到韵律的特征表达pt。
1.3 韵律特征的结合与使用
将韵律特征输入ED 模型时,首先需要考虑将它与声学特征还是文本特征结合。由于韵律特征本身属于声学特征的一种,而且发音相同或相近而语义不同的识别结果本质上和语言模型的联系更为直接,因此语言模型与韵律特征的结合互补性更强;同时,因韵律特征主要通过Attention 分布获取,若与声学特征再次结合,重复计算量较大。因此,为了强化声学与语言联合建模的耦合性,本文主要考虑在语言模型的使用时增加声学信息的融入,从而实现声学信息和语言信息的有效结合。而ED 模型在解码的过程中,语言模型的作用主要体现在一遍Decoder 解码与二遍重打分的过程中,因此,对于韵律特征的结合,本文提出以下两种思路:
1)韵律特征与一遍Decoder 解码的结合。
ED 模型的Decoder 扮演语言模型的作用,将韵律特征输入Decoder,其结构如图3 所示。

图3 基于韵律特征辅助的编码-解码语音识别框架Fig.3 Encoder-decoder speech recognition framework based on prosodic features
韵律特征pt与yt-1和ct-1拼接重新输入Attention 的RNN模型,具体如式(8)所示:
由于RNN 本身有记忆功能,所以它预测每个字时都知道字的时域以及能量信息等。例如,如果当前间隔更大,说明当前字应该属于一个新词,反之则应与上一个字组成词。
2)韵律特征与二遍重打分的结合。
ED 模型的二遍结果在重打分时,一般对N-best 的输出考虑ED 模型分与语言模型分的结合,具体如式(9)所示。对于第j个结果,Sj表示重打分数,EDj表示ED 的解码得分,LMj表示语言模型得分,β为融合系数。
因经过编码后的韵律特征无法直接在重打分上进行融合,考虑根据时域分布信息进行语言模型得分的惩罚。例如,当连续多个字的解码结果为“比视野”时,则“比视野”三个字的发音间隔信息表征理论上应该是(比-视)>(视-野),即“比”和“视”词间的发音间隔时长应该大于“视”和“野”词内的发音间隔时长,否则认为真实的发音停顿时长与“比视野”不一致,需要进行额外的语言分的惩罚;当连续多个字的解码结果为“笔试也”时,则“笔试也”三个字的发音间隔信息表征理论上应该是(笔-试)(试-也),即“笔”和“试”词内的发音间隔时长应该小于“试”和“也”词间的发音间隔时长,否则认为真实的发音停顿时长与“笔试也”不一致,也需要进行额外的语言分的惩罚。具体如式(10)所示:
其中:M表示不合理分布的个数;P表示语言模型的惩罚分,一般根据选取的语言模型进行调节。
最后,根据N-best 的重打分数Sj进行结果的重新排序。
2 实验结果与分析
本文基于Encoder 为Conformer[19-20]、Decoder 为长短期记忆(Long Short-Term Memory,LSTM)网络[21]的ED 框架在1 000 h 中文连续语音识别任务上进行实验。训练数据为16K 采样率,内容主要包括采访、会议、授课等多人自由交谈、口语化风格较为明显的场景,每段音频约为10 min,数据均由实际使用场景进行录制。测试集为5 h、共计30 段的测试音频,数据的风格和训练数据相同。声学特征均采用40维的Filter Bank 特征。语言模型为4-gram 模型,其中词典规模为10 万词,N-gram 的数目为5×108。训练基于PyTorch 工具在4 张V100-32G GPU 上进行,并采用了随机梯度下降法(Stochastic Gradient Descent,SGD)、初始学习率0.02 的方式进行训练。当开发集合的准确率不再稳定提升时,在新的一轮数据迭代时对学习率进行折半,整个训练过程数据共计迭代了12 轮。
基于韵律特征与Decoder 的结合,本文首先验证了不同时域信息分布表征对语音识别结果的影响,具体的实验结果如表1 所示。因测试数据偏向远场带噪、多人讨论的复杂场景,所以整体识别效果偏差,准确率仅为78.66%。而增加了不同的时域信息分布表征后,语音识别效果均有了不同程度提升。其中,以增加发音间隔信息表征的提升最大,相对提升达到5.7%。
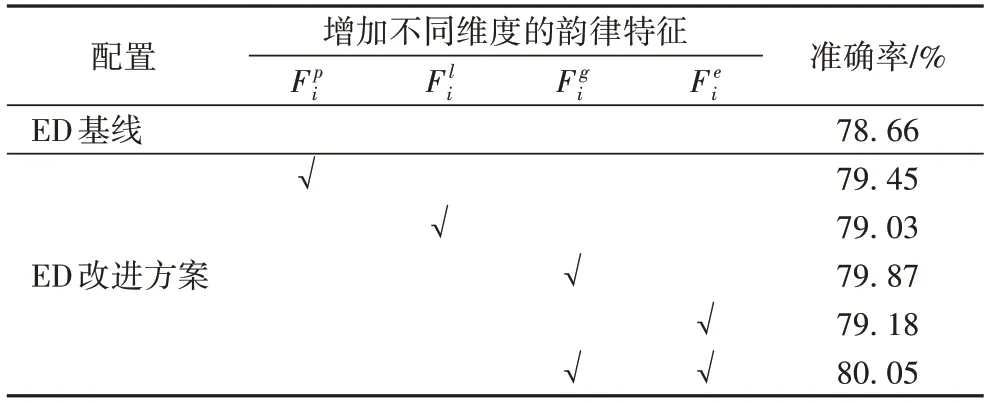
表1 基于韵律特征辅助的ED语音识别效果Tab.1 Effect of ED speech recognition based on prosodic features
对比三种不同的特征,发音停顿信息以及发音持续信息,两者均需根据设定的阈值产生,而在不同的Attention 上该阈值可能存在不通用等问题,因此解码结果存在一定的波动情况。同时,Attention 分布并不一定能覆盖整个字的边界,因此Attention 区域大小和字持续时间可能不存在精确的映射关系。而发音间隔信息表征一定程度上包括了发音停顿信息以及发音持续时长等信息,同时其根据Attention 分布的最大值获得确信时间,时间的准确性更高,因此效果提升更为稳定。
若只增加发音能量信息表征,相对提升达到了2.4%,这主要是因为用户有些情况下停顿信息并不明显,而增加一定的发音能量有助于强化分词信息。而在利用发音间隔信息表征的基础上,进一步增加了能量信息表征,语音识别的准确率达到了80.05%,相对提升达到6.5%。
在ED 解码结果的基础上,进一步验证了二遍重打分(rescore)的结合,具体效果如表2 所示。由实验结果可知,基于ED 基线的5-best 解码结果,利用额外的LSTM 的语言模型进行二遍重打分,相对提升达到了3.5%,而增加发音间隔信息惩罚rescore 的相对提升则达到了5.3%。发音间隔信息在ED 得分和语言模型得分的融合中,进一步补充了韵律信息作为辅助判断,能够一定程度上缓解语言模型过强造成的识别结果偏差。而当ED 模型解码过程中已经使用了韵律特征作为辅助,则改善幅度有限,主要是ED 在一遍解码过程中已经利用了韵律特征对Encoder 的声学信息和语言信息进行融合,二遍rescore 整体的提升空间有限。结合一遍解码的韵律特征辅助和二遍重打分的韵律特征惩罚,在1 000 h 数据上效果由79.41%提升为80.49%,效果累计相对提升达5.2%。

表2 基于二遍重打分的ED语音识别效果Tab.2 Effect of ED speech recognition based on rescoring
为了验证该方法的推广性,本文进一步在10 000 h 的数据上进行了对比实验,具体结果如表3 所示。训练数据同样以采访、会议和授课等场景为主,数据相关特性和1 000 h 数据相同。和1 000h 数据训练不同的是,10 000 h 的训练采用32 张V100-32G GPU 多机多卡并行训练的方式减少训练时间,同时训练数据总共进行了6 轮迭代。可以看出,结合发音间隔信息表征以及发音能量信息表征的韵律特征辅助方法,在大数据上仍然有5.2%的效果相对提升;同时,在rescore 的过程中进一步增加韵律特征惩罚,相对基线rescore 效果由89.42%提升为89.95%,相对提升同样达到了5.0%。

表3 基于大数据的ED语音识别效果Tab.3 Effect of ED speech recognition on big data
对实验结果进行分析可以看出,效果明显变化的部分多为语音相同或相近、语义不同类型相关的错误,具体如表4所示。当语言模型作用过强时,甚至会影响到声学的选择,如“因 yin”和“鹦 ying”,而增加韵律特征,则会缓解该类型错误的发生。因此,即使训练数据达到了工业级应用的覆盖,也难以实现对该类错误的有效缓解。而该方法显式地将韵律相关特征加入了解码端,能够进一步强化声学特征与语言模型结合的合理性;同时,该方法基于目前主流的端到端框架进行改进,是对该框架落地鲁棒性的有效补充,进一步改善了端到端识别系统落地的用户体验。

表4 语音识别结果变化示例Tab.4 Examples of change in speech recognition results
3 结语
本文结合语音识别实际应用过程中可能存在的发音相同或相近而语义不同等错误,考虑从韵律特征的角度出发,强化声学特征对语言模型预测的辅助优化。实验结果表明,基于发音间隔的韵律特征和发音能量的韵律特征的辅助优化方法,能够实现语言层面语义的进一步确认和区分,提升语音识别的效果。当然,精确的韵律信息常常难于在识别过程中实时获取,因此后续将进一步拓展韵律信息的维度,同时考虑对时长、重音等韵律表征进行实时的预测提取,从而辅助语音识别的优化。
