基于CSSA-F-SVM模型的矿用卡车发动机智能故障诊断
2023-02-22顾清华王培培李学现姜秉佼
顾清华,王培培,李学现,姜秉佼
(1.西安建筑科技大学 管理学院,西安 710055; 2. 西安建筑科技大学 矿山系统工程研究所,西安 710055; 3. 西安建筑科技大学 资源工程学院,西安 710055)
随着“智慧矿山”建设的推进,矿山机械设备运行数据监测能力得到了较大的提升,但大多现有的矿山机械设备监测监控系统停留在传感数据可视化显示和简单阈值分析(信号值超标、超限)层面,能够对机械设备的运行过程进行监测,但无法识别设备关键部位的早期故障[1]。矿山恶劣的作业环境导致矿用卡车的维修任务占到总维修任务的一半以上,其中发动机故障大约占卡车故障的50%[2]。能够根据矿卡发动机的监测数据对计划维修外的卡车发动机故障进行提前诊断对矿山生产具有重大意义。然而,由于发动机故障维修记录不够完善,实际可以获取的有效故障数据极少,能够在小样本故障数据中实现对发动机的高精度预测是故障诊断的关键。
随着智能化的不断推进,机器学习、深度学习和数据挖掘等技术逐渐被应用到发动机故障诊断当中,如,神经网络[3]、深度网络[4]、随机森林[5]、支持向量机[6]等。周俊博等[3]针对目前拖拉机柴油机故障诊断中单个神经网络模型的局限性,提出一种LWD-QPSO-SOMBP神经网络模型的拖拉机柴油机故障诊断模型;仲国强等[4]为了提高船舶柴油机智能故障诊断的精度,引入深度学习方法,提出了一种基于深度置信网络的船用柴油机智能故障诊断方法;魏东海等[5]针对单一分类器的柴油机常见故障诊断识别效果不理想的问题,探索了一种随机森林分类器用于柴油发动机的故障诊断。然而神经网络由于具有较多的网络参数,更适用于大样本数据集,在样本数量有限的情况下,神经网络算法往往表现出较差的泛化能力;基于深度理论的故障诊断方法对大规模的复杂数据往往会有更准确的识别效果,对复杂设备的故障诊断有天然优势[7],但往往训练速度较低,导致预测效率不高;随机森林算法受决策树数量的影响,对噪声较大的数据集容易陷入过拟合,会导致预测效果不佳。相较于以上方法,支持向量机有参数少、模型简单等特点,且泛化能力优秀,能够在有限的样本中找到尽可能多的信息,适用于小样本数据的学习,符合矿用卡车发动机实际故障数据不足的特点。2018年,WU 等[8]提出了一种基于凸半径边缘的F-SVM模型,通过结合主成分分析,将特征变换和SVM分类器的联合学习,实现了数据与分类器的契合,故本文选择F-SVM作为故障诊断的主体模型。然而,对于多分类问题,支持向量机的优劣一定程度上取决于本身惩罚因子C和核参数g的选择,这些参数的选取会影响识别准确率和效率[9],F-SVM模型也面临同样的问题。许多学者的研究已经证明,借助群智能算法对支持向量机模型的参数进行优化,可以显著提高其分类精度,在设备故障诊断领域有了很好的应用。文献[10-12]分别选用PSO、WOA、GA算法对SVM的参数进行寻优,均在故障诊断精度上取得了一定的提升。文献[13]提出了借助果蝇算法对F-SVM进行参数寻优的方法。然而上述算法在全局搜索能力、收敛速度上存在不足,有陷入局部最优的可能,影响诊断模型的精度。麻雀搜索算法(Sparrow Search Algorithm,SSA)[14]具有搜索精度高、收敛速度快、寻优能力强的突出特点,与其他群智能算法相比表现出极强的优势,目前已经应用于各种分类器的参数优化上;曹伟嘉等[15]利用改进后的麻雀算法(JYBack-SSA)优化随机森林,建立了变压器的故障诊断模型;单亚峰等[16]提出利用麻雀算法对AdaBoost-SVM模型进行优化,寻找最优的弱分类器权重和SVM参数;李黄曼等[17]通过改进麻雀算法优化SVM,建立基于DGA的ISSA-SVM故障诊断模型。以上参数优化方法均提高了原始模型的预测精度,可见,麻雀算法在参数优化方面已经取得了很大的成功。
针对矿用卡车发动机故障数据不足而导致诊断精度不高的问题,本文提出了一种基于改进麻雀搜索算法优化F-SVM的矿用卡车发动机故障诊断模型。通过引入链式搜索策略,对麻雀算法进行改进,优化了麻雀发现者和加入者的位置更新过程,提高了原麻雀算法的收敛速度和全局寻优能力。借助改进后的麻雀算法对F-SVM联合模型寻优,构建了CSSA-F-SVM故障诊断模型,通过寻找最合适的惩罚因子和核参数来平衡诊断模型的训练精度和泛化能力,降低了由于样本数据过少产生过拟合现象的可能。将本文模型与原始SVM和用传统SSA、PSO、FOA、EHO算法分别优化SVM和F-SVM的诊断模型对比,实验结果验证了所提方法应用于诊断小样本故障数据时的可行性和高精度。
1 改进麻雀算法优化F-SVM的矿卡发动机故障诊断模型
基于凸半径边缘的SVM模型,即F-SVM,在提高分类精度的同时也实现了将数据的特征提取与SVM相结合。F-SVM模型如下:
st.yi(ωTfi+b)≥1-ξi,
ξi≥0,i=1,…,n
M>0
(1)

对于F-SVM模型而言,惩罚因子C和核参数g的选择在一定程度上决定着F-SVM的分类性能和泛化能力,因此选取最合适的参数组合将会极大提高分类精度。本文借助麻雀搜索算法进行参数组合的寻优,并为提高其寻优能力对算法进行改进。
1.1 麻雀搜索算法改进过程
标准的麻雀搜索算法具有设置参数少、寻优能力强等特点,但仍存在种群迭代后期多样性降低、容易陷入局部最优值等不足。本文针对种群中发现者和加入者的位置更新进行改进,引入链式搜索策略以协调发现者的局部搜索和全局搜索的能力,遵循位置最优原则对加入者的位置更新公式进行改进以提高加入者的收敛性能。
1)引入链式搜索策略
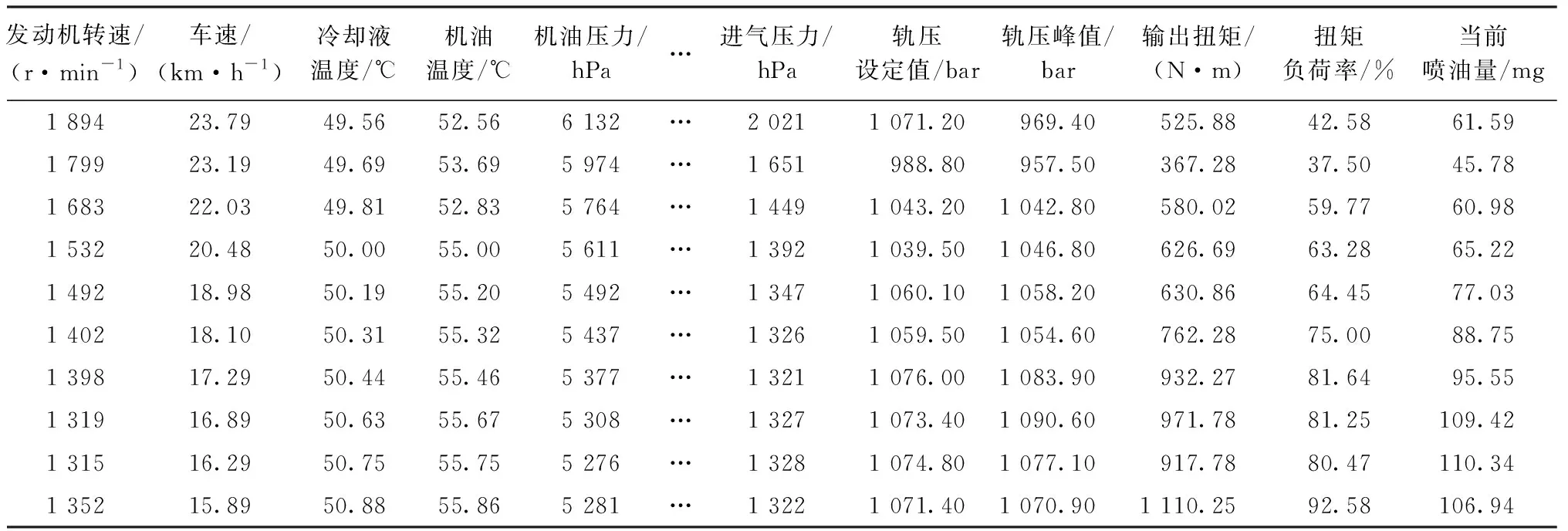
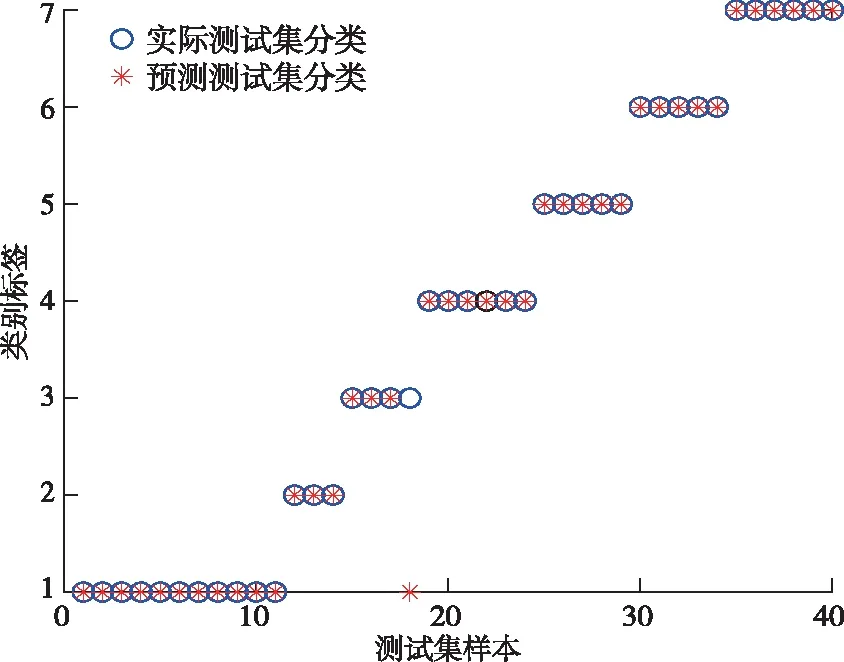
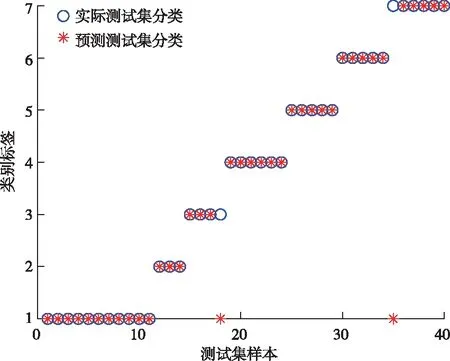
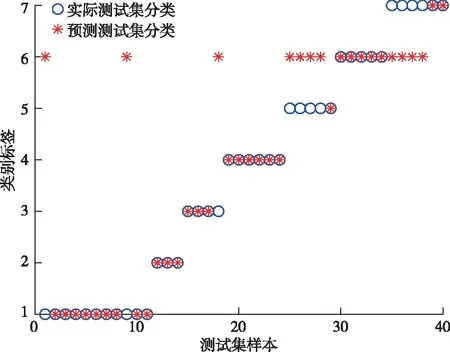
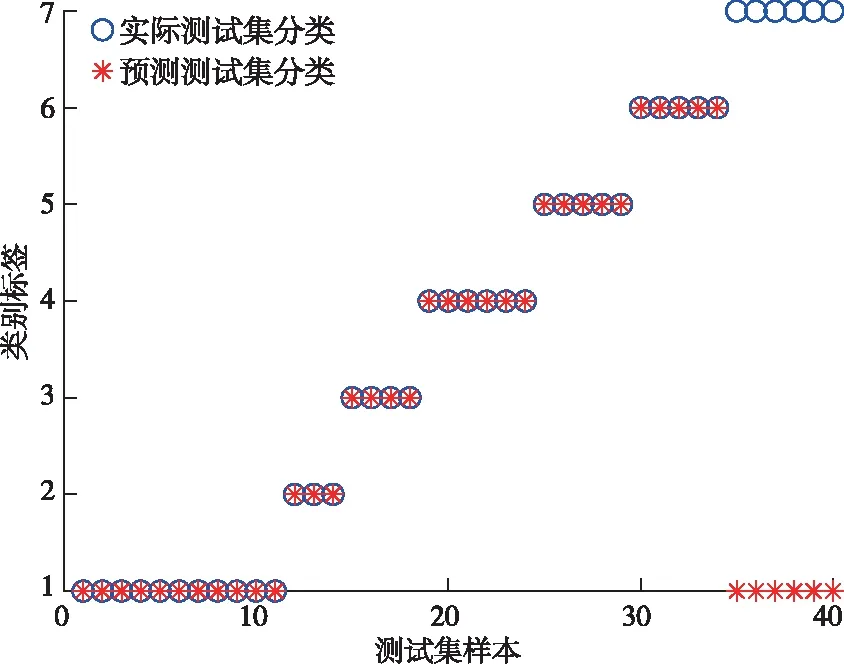
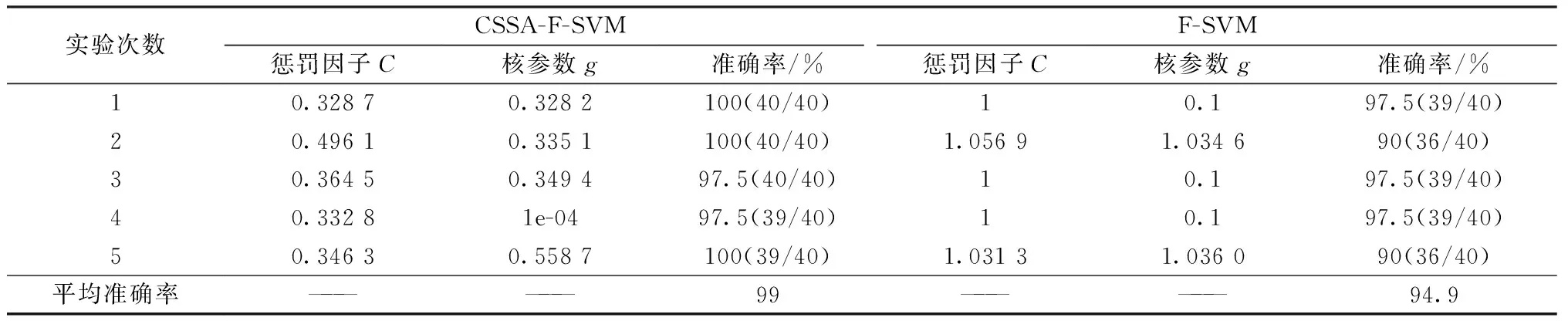
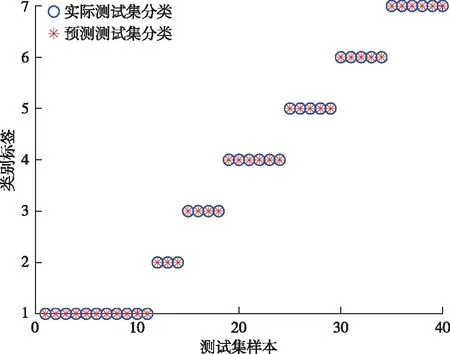
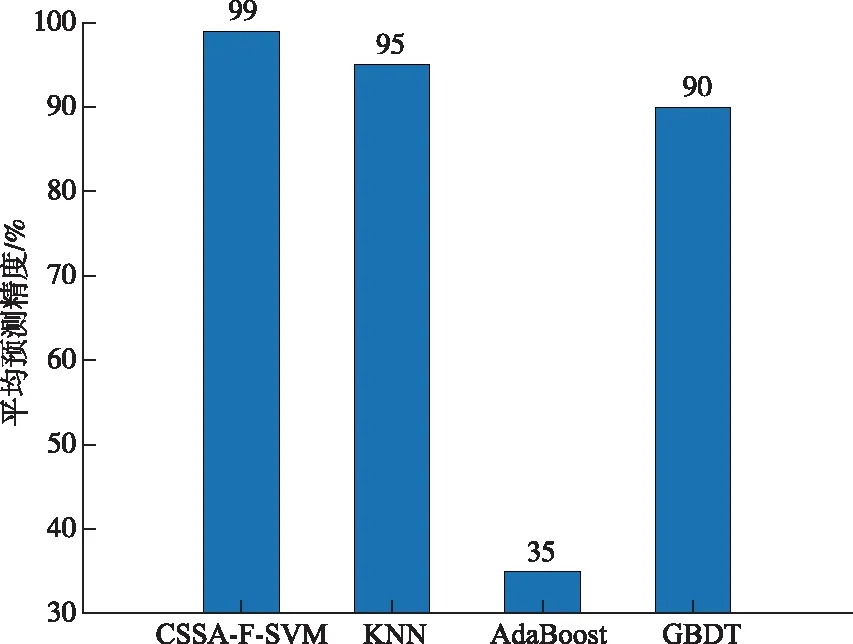
在传统麻雀算法中,当R2 (2) 式中:Xj1为领导者在第j维空间的位置,Fj为食物在第j维的位置,ub和1b分别是对应的上界和下界。c2和c3均为[0,1]之间的随机数,用来增强Xj1的随机性,可以起到提高链群的全局搜索和个体多样性;c1是算法中的收敛因子,由2递减到0,用于平衡全局搜索和局部开发能力。 (3) 式中:l是当前迭代次数,L是最大迭代次数。 借鉴链式搜索的思想,将麻雀算法中发现者的位置更新改进如下: (4) 式中:(ub-1b)c2+1b可以协调麻雀的全局搜索能力,但直接引入将会导致搜索范围过大,降低发现者的搜索精度和效率,因此需相应增加麻雀向零点靠近的速度,以平衡搜索范围过大的风险。改进后的收敛因子c*表达式如下: (5) 当周围环境安全时,改进后的发现者既能带领加入者以链式的方式广泛搜索食物,又能实现以更高的搜索效率寻找食物,从而协调了算法的全局搜索和局部搜索的能力。 2)加入者位置更新策略 加入者位置更新策略如下: (6) 式中:Xbest表示当前全局最优的位置。当i>n/2 时,表明第i个加入者适应度较低,为获得更多的能量,需要飞往其它地方觅食,且此时的位置距当前全局最差的位置更近,距离当前全局最优的位置更远。基于此,当加入者进行随机搜索时,遵循位置最优的原则,改进后的加入者会以更快的收敛速度进行位置更新。 在基于改进麻雀搜索算法的参数优化过程中,利用F-SVM分类器的分类精度构建合适的适应度函数,指导麻雀位置的更新,并通过麻雀种群个体位置的不断迭代来寻找最优的参数C、g。 本文基于改进的麻雀算法CSSA和F-SVM,建立矿用卡车发动机故障诊断模型,CSSA-F-SVM模型结合了半径信息和参数优化。如图1所示,整个诊断模型可分为两部分:参数优化部分和模型训练及诊断部分。参数优化部分主要是使用分类器精度构造适应度函数来指导麻雀位置的更新,并通过位置的不断迭代来寻找最合适的参数;模型训练及诊断部分是利用参数优化部分得到的最优惩罚因子和核参数建立F-SVM分类器,通过该分类器在测试集上得到最终的分类结果。诊断模型具体步骤如下: Step 1:采集矿用卡车发动机故障数据,进行归一化处理,并将其划分为训练集和测试集; Step 2:种群初始化,设置CSSA算法的种群规模、最大迭代次数和初始参数; Step 3:初始化M矩阵并将数据集放入特征空间L中; Step 4:利用SVM平均交叉验证分类精度计算适应度值,进行迭代寻优,按照式(4)、(6)分别对发现者、加入者进行位置更新; Step 5:重新计算每个个体的适应度值并进行排序; Step 6:重复Step 4和Step 5,直至达到最大迭代次数,输出适应度值最好的麻雀位置, 确定最优参数C、g,利用最优参数建立故障诊断模型,使用十倍交叉验证的方法进行训练。 Step 7:根据训练结果对测试集进行预测,为保证预测结果的可靠性,对测试集进行K=5次预测,输出故障诊断结果,并计算平均预测精度。 故障诊断流程图如图1: 图1 基于CSSA-F-SVM的矿用卡车发动机故障诊断流程图Fig.1 Flow chart of fault diagnosis of mining truck engine based on CSSA-F-SVM 本文以潍柴WP12G460E310发动机为研究对象,借助潍柴智多星路谱监测装置采集了河南某露天矿自卸卡车发动机的210组21维故障数据,来测试CSSA-F-SVM的性能。由于矿山作业环境的特殊性,矿用卡车发动机的故障类型主要为滤芯及管道堵塞等故障。本文采集了八种故障类型数据,分别为正常、进气管堵塞、增压器故障、空滤堵塞、中冷器配套故障、燃滤堵塞、中冷器内部堵塞。将所有数据分为训练集170组和测试集40组,并对训练集采用10倍交叉验证的方法进行训练,部分实验数据见表1,实验数据分类情况及状态编号见表2。 表1 潍柴发动机WP12G460E310的部分故障数据Table 1 Partial fault data of Weichai engine WP12G460E310 表2 数据集分类情况Table 2 Classification of datasets 对训练集进行数据归一化及降维,利用改进麻雀搜索算法(Convergent Sparrow Search Algorithm,CSSA)、麻雀搜索算法(Sparrow Search Algorithm,SSA)、粒子群优化算法(Particle Swarm Optimization,PSO)、象群优化算法(Elephant Herding Optimization,EHO)、果蝇优化算法(Fruit Fly Optimization Algorithm,FOA)对SVM进行参数优化,得到最优的C、g值。对测试集进行数据归一化后输入优化后的SVM模型中进行故障诊断,诊断结果如图2至图7所示。 图2 CSSA-SVM故障诊断结果(97.5%) Fig.2 Fault diagnosis results of CSSA-SVM (97.5%) 图3 SSA-SVM故障诊断结果(95%)Fig.3 Fault diagnosis results of SSA-SVM (95%) 图5 EHO-SVM故障诊断结果(72.5%) Fig.5 Fault diagnosis results of EHO-SVM (72.5%) 图6 SVM故障诊断结果(77.5%)Fig.6 Fault diagnosis results of SVM (77.5%) 图7 FOA-SVM故障诊断结果(85%) Fig.7 Fault diagnosis results of FOA-SVM(85%) 通过对比可知,CSSA-SVM模型对测试集的预测准确度达到最高值97.5%,均明显高于其他算法优化的SVM模型,证明了本文改进的麻雀算法良好的参数寻优能力。此外,CSSA-SVM模型提高了对燃滤堵塞故障(类别6)及中冷器内部堵塞故障(类别7)与其他故障类型的区分准确度,而在增压器故障(类别3)的诊断上仍存在失误。 用CSSA、SSA、PSO、EHO、FOA算法对F-SVM进行参数优化,得到最优的C、g值。对测试集进行数据归一化后输入优化后的F-SVM模型中进行故障诊断,不同模型运行5次的平均对比结果如表3所示。 表3 不同算法优化F-SVM故障诊断精确度对比(运行5次)Table 3 Comparison of F-SVM fault diagnosis accuracy optimized by different algorithms(5 runs) /% 从平均训练精度和预测精确度来看,不同算法优化F-SVM模型的诊断精确度整体高于优化SVM模型的诊断精度,CSSA-F-SVM模型诊断性能更为突出。其中,CSSA-F-SVM模型分别较PSO-F-SVM、EHO-F-SVM、FOA-F-SVM、SSA-F-SVM模型准确精度提高了3%、5.25%、2.75%、1.5%。 又从表4中可知,采用CSSA优化的F-SVM模型的最高准确率可达100%,最低为97.5%,平均准确率99%;而采用F-SVM模型的最高、最低和平均诊断精度分别为97.5%、90%、94.5%。惩罚因子和核参数均是在一定范围内随机变化的。证明了本文基于改进麻雀算法优化F-SVM的模型针对小样本发动机数据进行故障诊断的优秀性能。 表4 CSSA-F-SVM寻优与诊断结果Table 4 Optimization and diagnosis results of CSSA-F-SVM 由图8所示,采用本文模型对各个状态的诊断正确率均可达100%。对于相同的故障数据,其他四种诊断方法对各状态下的分类结果如表5所示。本文所提的方法弥补了对比方法对于发动机进排气系统中冷器内部堵塞、增压器故障和中冷器配套故障诊断效果不足的缺陷,在故障数据有限的条件下,对各种常见故障类型起到了真正的诊断效果。 图8 CSSA-F-SVM故障诊断结果(单次100%)Fig.8 Fault diagnosis results of CSSA-F-SVM (single result 100%) 表5 其他算法优化F-SVM模型的正确率Table 5 The correct rate of optimizing the F-SVM model with other algorithms /% 为了进一步分析本文所提方法在解决矿用卡车发动机小样本故障诊断问题上的优越性,将本文方法与KNN(K-Nearest Neighbor)、AdaBoost(Adaptive Boosting)、GBDT(Gradient Boosting Decision Tree)传统的机器学习方法做了对比。如图9所示,在样本数量相同的情况下,每种方法取5次运行的平均结果,本文所提方法的预测精度明显高于其他方法。 图9 与其他机器学习方法对比结果Fig.9 Comparison results with other machine learning methods 本文针对矿卡发动机实际故障数据较少导致诊断精度不足的问题,通过对麻雀算法的改进和对F-SVM方法的研究,提出了基于CSSA-F-SVM模型的矿用卡车发动机智能故障诊断方法。可得出以下结论: 1)通过改进后的麻雀算法寻找F-SVM的最优参数C、g,降低了参数选择对诊断精度的影响。实验结果表明,基于CSSA-F-SVM模型方法的平均诊断准确率为99%,分别较传统SVM和F-SVM模型提高了21.5%和4.1%。 2)新CSSA-F-SVM模型方法克服了其他群智能算法优化SVM模型对于中冷器内部堵塞、增压器故障等诊断不足的缺点。能够较好地实现矿用卡车发动机常见故障的诊断,可为实际应用提供一定的参考。1.2 基于参数优化的F-SVM矿用卡车发动机故障诊断过程

2 仿真分析与实验验证

2.1 不同算法优化SVM性能对比

2.2 不同算法优化F-SVM性能对比


2.3 与其他机器学习方法的对比结果
3 结论
