AIGC的科学基础
2023-02-21杨善林李霄剑张强莫杭杰彭张林焦建玲蒋翠清蔡正阳李玲
杨善林,李霄剑,张强,莫杭杰,彭张林,焦建玲,蒋翠清,蔡正阳,李玲
(1.合肥工业大学 管理学院,安徽 合肥 230009;2.过程优化与智能决策教育部重点实验室,安徽 合肥 230009;3.数据科学与智慧社会治理教育部哲学社会科学实验室,安徽 合肥 230009)
1 引言
互联网上的内容生成技术,一直伴随着互联网的发展而发展。从最初的专家生成(professional generated content,PGC)[1],到用户生成(user generated content,UGC)[2],再到人工智能内容生成(artificial intelligence generated content,AIGC)[3],这既体现了互联网快速发展,更凸显了人工智能能力的大幅跃升。2006年深度学习提出以来,人工智能在图像[4]、语音[5]、自然语言处理[6]等多个领域展现出了其他技术无法匹敌的能力。2016年,A lphaGo战胜围棋冠军李世石,人工智能从此逐步在围棋[7]、游戏[8]、绘画[9]、蛋白结构预测[10]等特定任务领域达到甚至超越人类专家水平,然而这些人工智能仍属于非通用人工智能,即弱人工智能。
通用人工智能或强人工智能(artificial general intelligence,AGI)是可以学习并完成人类或动物可以完成的任何智力任务的人造智能体,一般认为需要具备推理、不确定性决策、常识认知、计划、学习、自然语言交流等能力,并在必要时整合这些技能完成任意给定目标。如何构建强人工智能体是人工智能领域追求的主要目标,为此Google[11]、微软[12]、OpenAI[13]等公司大力投入从多种不同路径探索强人工智能的构造方法。2017年,Google在神经信息处理系统大会(Conference on Neural Information Processing Systems,NIPS)上发表了名为《Attention is All You Need》[14]的论文,文中提出了基于注意力机制[15]的Transformer结构,能够有效提取词语间的相关性,并且模型架构十分灵活。Transformer灵活的架构和优异的性能使得科学家们产生了探究其能力极限的想法,大模型的概念应运而生。
GPT(generative pre-trained transformer)系列就是以Transformer为基础构建的生成式大语言模型。2018年6月,OpenAI就发布了GPT-1专注于自然语言生成任务,共有12个注意力模块,1.17亿个参数[16]。2019年2月,OpenAI发布了GPT-2,不仅取消了面向各类子任务的有监督微调,模型的参数量还达到了15.42亿[17]。2020年6月GPT-3推出,参数量进一步提升至1750亿,具有96层架构,1288个超参数,此外还利用了45TB的文本数据进行模型的训练[18]。2022年,OpenAI先后推出了GPT-3.5、Instruct GPT和ChatGPT[19],利用强化学习再一次对模型进行训练,让输出结果更符合人类的价值需求。2023年3月14日,OpenAI正式推出了GPT-4,不仅在能力上比GPT-3.5有巨大提升,还具备了跨模态理解的能力。微软专家团队对GPT-4做了系统性评测,评测指出GPT-4已经初步具备了通用人工智能的基本特质,可以被认为是一种形式的强人工智能,这是人类首次制造出具备一定常识认知和推理能力的强人工智能体[20]。2023年9月,OpenAI推出了GPT-4V,在GPT-4原有能力的基础上强化了对图像的理解分析能力,GPT-4V将与语音模块一同接入ChatGPT中,使其具备看、听、说的能力。
人工智能的发展进程超越大多数人的预期,想要理清这些重大突破到底是如何实现的,就需要从科学基础的视角进行分析,发现推动人工智能发展的关键要点。本文梳理了在AIGC发展的全过程中,对其产生重要影响和重大推动作用的科学发现与技术发明,这些研究工作分布于多个领域,包括生物学、认知科学、数理计算科学、决策科学、复杂性科学等。这些学科在AIGC发展的不同阶段起到了各种不同的作用:生物学通过对生物智能基础结构及其机理的解析为AIGC算法基本结构提供了最初的启示,认知科学通过提炼基本认知规律为AIGC的机制设计提供了方向和目标,数理计算科学通过完善严谨的体系为构建AIGC提供了理论和技术工具,决策科学通过对社会系统的剖析可以为AIGC的运营提供安全保障,复杂性科学则为解析AIGC与通用智能的内在机理提供了研究思路。这些学科相互交织,共同形成了AIGC的科学基础。本文在分析总结这些学科发展规律的基础上,对AIGC的未来发展进行了分析与展望,以期推动我国在通用人工智能领域的快速创新发展。
2 生物学与A IGC
自然界中的智能体是以生命的形式展现的,因此除了哲学层面的思考以外,人类对智能的研究探索是以生物学为开端进行发展的。早期,人类对智能产生机理的探索是在还原论思想的主导下开展的,通过逐步探究底层结构确立其功能特性。从16世纪初步确立大脑为智能产生的硬件单元,到18世纪生物电信号及其作用的发现,再到19世纪大脑分区功能的确定,直至20世纪初确立神经元理论。此后,人类对神经科学和脑科学的研究逐步从还原论向系统论过渡。下面以两个诺贝尔奖成果为例做简要介绍。
2.1 生物神经网络的发现与人工神经网络的发明
现代脑科学的研究起源于神经元的发现。意大利科学家Golgi于1873年首创了Golgi染色法,利用铬酸盐—硝酸银将原本显微镜下接近透明的脑组织切片中的一部分神经细胞染成棕黑色,这些被染色的神经细胞在显微镜下呈现出一个错综复杂的网络结构[21]。由此,Golgi坚定地认为神经组织是一个相互联通的共享细胞质的网络结构,即弥散神经网络理论[22]。西班牙科学家Cajal则以Golgi染色法为基础开展了进一步研究,由于成熟脑组织神经网络结构过于复杂,他转向研究新生而非成年的脑组织,此时脑组织中的神经元发育还未完善,可以较为清晰地看到神经元的各种结构[23]。Cajal基于他自己的实验观测结果,坚定地认为神经系统应是由独立的神经细胞组成、而非一张融合在一起的大网,由此神经元学说被正式提出。Golgi和Cajal的学术观点相互对立,即便是在诺贝尔奖的颁奖台上,Golgi[24]也以《神经元学说:理论和事实》为题进一步抨击Cajal的神经元理论,申明自己对神经网络理论的坚持。即便如此,两人的研究一同奠定了现代神经科学基础,1906年共同获得诺贝尔生理学或医学奖。
随着电子显微镜的发明,微观结构逐步被清晰地展示在人类面前。1955年,洛克菲勒研究所的Palay和Palade[25]通过电子显微镜观察到神经元与神经元之间存在空隙,即突触间隙,由此神经元理论被正式写入了教科书中。Golgi和Cajal的学术之争本应该就此盖棺定论,但随着探索的不断推进,人们又有了新的发现。2023年,Burkhardt等[26]在Science上发表文章,发现栉水母个体发育的早期阶段,其皮下神经网络的神经细胞之间并没有相互分离的突触进行联结,而是像Golgi描述的那样,融合形成了一个连续的质膜,即多个神经元细胞彼此不可分地形成了一张整体网络。这一发现也证明了Golgi和Cajal的学术观点并不互斥,他们的理论共同推动着神经科学与脑科学的发展。
在生物神经网络相关研究的启发下,20世纪40年代,数理计算领域的科学家们开始尝试模拟神经元的运作机制。1943年,心理学家McCulloch和数理逻辑学家Pitts[27]在分析、总结生物神经元基本特性的基础上首先提出神经元的数学模型。该模型最初只考虑了二进制的输入输出,有多个输入端口和一个输出端口,利用权重对多个二进制输入进行加权求和后,采用一个类似于阈值分割的阶跃函数对输出进行二值化处理,因此该神经元模型也被称为阈值逻辑单元。此后,学者们在此模型的基础上进行扩展和微调,逐步形成了今天的人工神经网络。1951年,图灵奖获奖者Minsky在他的博士研究期间提出了关于思维如何萌发并形成的一些基本理论,并建造了世界上第一个人工神经网络模拟器,名为SNARE。SNARE基于1949年Hebb[28]提出的Hebb学习规则开发,是一台由大约40个Hebb突触组成的随机连接网络模拟器。1956年,Minsky和McCarthy一起发起“达特茅斯会议”并提出人工智能(artificial intelligence)概念。由于Minsky在人工智能领域的奠基性贡献被授予1969年度的图灵奖,也是人工智能领域第一个图灵奖获奖者。
此后,人工神经网络进行了许多轮的迭代,各种各样的网络模型和学习方法被提出。1958年,Rosenblatt[29]对上述神经元模型进行改进,设计了具有单层神经网络的感知器模型,但当时仅能处理线性分类问题。1969年,Minsky和Papert[30]出版了经典著作《Perceptrons》,证明了单层感知器无法解决异或逻辑运算等非线性问题,并引出了具备更强特征表达能力的多层感知器的概念。1986年,Hinton和Sejnowski[31]结合多层神经网络以及Hop field网络[32]设计了玻尔兹曼机(Boltzmann machine),为概率建模提供了新思路,在处理无标签数据和特征学习方面具有独特优势。同年,Rumelhart等[33]又提出用于神经网络参数学习的反向传播方法,拓展了感知器模型的应用范围。
2.2 生物神经网络信息处理机制的发现与深度学习方法的发明
20世纪中叶,人们对单一神经元结构解析已经逐渐清晰,其以生物电信号为核心的信号传递机理也逐步清楚。但是,大脑高级功能是如何产生的谜题始终未能破解。Hubel和W iesel[34]在这一时期开始了对视觉系统感知与发育机理的研究。当时最先进的特殊记录电极设备允许他们对单个神经元进行测量,捕获它们被激活的情况。基于这一设备,Hubel和Wiesel于1962年开始尝试绘制猫视觉神经系统的认知地图,以此确认视觉皮层不同区域的神经元细胞在功能上是否有分工。他们通过给猫看幻灯片,然后利用特殊记录电极来测量猫的某单个视觉皮层神经元细胞被激活的情况,以此来判断不同位置的视觉神经元对何种图像模式敏感。实验发现猫的视觉皮层对信息的处理是一种层级结构,所传递的信号会在不同层级间发生转换,进而使得不同层级的神经元会对不同的图像模式敏感,且越后端的神经元会被越复杂的图像模式激活。例如,靠近视觉前端的简单神经元细胞会对明显的光暗分界线敏感,中端的复杂神经元则会对线条和角点敏感,而后端的超复杂神经元则会对方形、三角形等几何图形敏感[34,35]。此后,Hubel和W iesel[36-38]又对视觉系统的发育展开了一系列研究,揭示了外界光刺激对视觉系统发育的影响至关重要,此外他们还做出了视觉功能柱的发现、视觉功能柱结构解析、视皮层可塑性研究等一系列贡献。因为他们在视觉系统信息处理方面的发现,Hubel和Wiesel与发现大脑左右半球功能分工的Sperry一同获得了1981年的诺贝尔生理学或医学奖。
随着猫视觉认知规律的发现,人们意识到视觉信号在各层级间逐级传递的过程中,部分神经元会逐步剔除空间位置的影响,而对大范围的复杂形状信息产生整体认知。为了模拟这一过程,日本科学家福岛邦彦[39]于1980年首次模拟了视觉神经网络的信息传递模式,提出了卷积层、池化层的模型构建思想及其对应的实现方法。此时的神经网络还没有卷积的概念,福岛邦彦用在位置上移动(shift in position)来描述卷积操作的过程,然后利用池化来扩大单一神经元在空间位置上的感受野,最终达到不受空间位置影响的形状认知这一目的。福岛邦彦当时提出了一套无监督学习的自组织方式进行神经网络模型的训练。随着反向传播算法的提出,当时所提出的学习方法逐步被取代,但卷积层、池化层的思想则被保留了下来。
在福岛邦彦思想的启发下,法国计算机科学家LeCun等[40]于1989年正式提出了卷积神经网络(CNN),定义了矩阵表述的卷积核对图像进行卷积处理,以此作为神经网络的核心结构,再结合池化层,实现了层级化的视觉信息提取。他们利用三层隐藏层对256像素的图像进行识别,利用Hinton提出的反向传播算法进行参数学习,成功应用于信件上手写邮编的文本识别[40]。在此基础上,LeCun与Hinton、Bengio一同继续改进反向传播算法,并开始探索神经网络深度和广度对算法性能的影响,发现如果一个深层结构能够刚刚好解决问题,那么就不可能用一个更浅的同样紧凑的结构来解决。因此,要解决复杂的问题,要么增加深度,要么增加宽度[41]。后续研究表明,增加深度比增加宽度更加有意义,深度学习的研究框架也在这一过程中逐步确立。LeCun与Hinton、Bengio也因深度学习方面的研究贡献共同获得了2018年度的图灵奖。
正如Golgi在诺贝尔奖颁奖典礼上引用了Nobel的一句话:“每个新发现将在人类脑中留下种子,使新一代更多人可能思考更伟大的科学观点。”AIGC的发明也正是通过生命科学发现和基础技术发明的漫长积累而形成的,如图1所示。首先,由神经学家、生物学家进行基础科学探索,发现生物神经网络构造和视觉信息处理机制等;紧接着,数学家、心理学家、计算机科学家进行新技术的发明,逐步建立了神经网络模型和深度学习方法等;然后,一些顶尖的人工智能企业在大规模实践中大力推动AIGC的成功应用和快速发展。

图1 生物学原理引导AIGC发明
3 认知科学与A IGC
认知科学是探究人脑或心智工作机制的前沿性尖端学科。1975年,在美国斯隆基金的支持下,科学家们在早期探索与发现的基础上,将哲学、心理学、语言学、人类学、计算机科学和神经科学六大学科整合在一起,以研究“在认识过程中信息是如何传递的”这一共性问题,并形成了认知科学学科。认知科学确立时间较晚,从研究领域来看与生物学、数理计算科学均存在交集,因此能够将这些与智能相关的学科联结到一起,加速学科间知识、规律、机理的融通,为人工智能的发展及其相关机理的研究起到强大的推动作用。认知科学的研究对象包括感知、注意、记忆、语言、思维、意识等。
3.1 注意力模型与Transform er
注意力是大脑从庞杂信息中抽取核心信息并加以分析处理的重要机制。1958年,英国心理学家Broadbent[42]提出了过滤器模型,描述了注意力选择的过程,如图2(a)所示。Broadbent认为当人们接收到多种信号源时,由于人脑的信息处理能力存在极限,需要通过过滤器加以调节,将关注重点放在某一特定信号源上,从而忽略其他信息源。基于这一观点,Broadbent构建了包含感觉记忆存储、选择过滤器、有限容量高级处理系统和工作记忆等四部分组成的过滤器模型,其中选择过滤器的作用就是从所有感知信息中筛选可被高级处理系统进一步处理的信息。Broadbent所提出的模型是一种早期选择模型,信息仅经过最为基本的特征识别后,就会依据特征进行选择或者过滤。在Broadbent研究的基础上,后续的研究者提出了许多更加复杂和精细化的注意力模型,例如后期选择模型、注意力衰减模型、注意力的记忆选择模型、注意力的多模模型、注意力容量模型等[43],为人类解析注意力机制提供了深刻的认识。此后,大量的研究也从生理学的角度解析注意力机制的形成机理。例如,1977年Skinner[44]提出的丘脑网状核闸门理论,从生理学的角度解释了中脑网状结构对人脑注意力的调节与控制机制。再如,在哺乳动物的视觉系统[45]中,科学家也发现存在“LGN→V1→高级皮质区”的“自下而上”投射和自“高级皮质区→V1→LGN”的“自上而下”投射,这样的双向投射构成了一个神经环路,具有注意力控制的功能。

图2 注意力过滤器模型和深度学习中的注意力机制
2010年后,人们就逐步开始探索注意力机制在深度学习领域应用,图2(b)所示即为深度学习中的注意力机制[46]。2014年,Mnih等[47]发表了题为《Recurrent Models of Visual Attention》的文章,将注意力机制引入计算机视觉处理任务中,使得神经网络模型可以有选择地关注图像的某些局部区域,提高处理能力。随后,Bahdanau等[48]则将类似的注意力机制应用于机器翻译任务中,使得神经网络模型能够在翻译的同时进行语义对齐。在这些工作基础上,注意力机制在各类自然语言处理任务中被广泛使用。2017年,Google发表了《Attention is All You Need》[14],在注意力机制的基础上提出了Transformer模型,开启了人工智能的大模型时代。
3.2 记忆模块模型与LSTM
记忆不仅仅是智能体存储信息的主要方式,更是归纳提取关键要素的信息处理过程。1968年,认知心理学家Atkinson和Shiffrin[49]提出了记忆的模块模型,认为存在三种模式的记忆:感觉记忆(sensory memory)、短时记忆(short-term memory)、长时记忆(long-term memory),如图3(a)所示。三种记忆[50]在特定条件下会相互转换,外界信息首先被存储在感觉记忆中,通过注意力机制将注意选择的信息转化为短时记忆。通过对短时记忆的复述,信息会逐步写入长时记忆中,而长时记忆可以通过提取重新载入为短时记忆[51]。在上述信息的转化过程中,信息会经过一系列的筛选和处理,在此过程中信息可能会遗失[52]。在随后的研究中,学者们围绕该模型开展了一系列生理机理的研究,对上述记忆功能对应的大脑区域有了基本的认识。

图3 三种记忆模式和长短时记忆网络
长短时记忆网络(long short term memory,LSTM)就是对记忆功能的一种模拟,是Hochreiter和Schm idhuber[53]于1997年首次提出,后经过学者们的反复改进形成了现有的LSTM 网络模型,如图3(b)所示。LSTM 与RNN(recurrent neural network)结构一样也是一个由重复模块反复堆叠形成的链式结构,有三个门控模块进行信息的处理,分别为输入门、遗忘门和输出门,但是每个模块之间都存在两条信息通路分别传递神经网络的短时记忆和长时记忆,并通过遗忘门来调节后向传递过程中信息的损失量[54],以此模拟记忆和遗忘的认知学机理。
3.3 奖励机制与强化学习
自古以来,奖惩机制就被用于社会的诸多领域,成为人类社会有序运行的重要基石。历代政治家、思想家对赏罚多有论述。例如,唐太宗说:“国家大事,惟赏与罚。”西汉魏相说:“赏罚所以劝善禁恶,政之本也。”因此,人们对利用人类自身的奖励系统进行行为管理的历史极为悠久,但在科学的范畴下研究人类奖励系统的奥秘则是到20世纪中叶才正式开始的。
1954年加拿大麦吉尔大学的两位博士后Olds和Milner[55]在一次偶然的实验中发现了小鼠大脑中的奖励系统,这是人类首次发现大脑中的奖励系统。当时,他们正在做小鼠脑区电刺激的实验,电极一端是小鼠脚下的一小块通电区域,另一端是植入大脑某区域的导线。这并不是他们第一次做此类实验,在之前的实验中,尽管刺激电流极其微弱,小鼠也会表现出愤怒、焦虑、紧张等情绪,从而试图从地面的通电区域逃离。但这一次他们将电极接入了小鼠脑干后的某个区域,小鼠却表现出了不一样的行为特征:小鼠似乎很享受刺激,并且在小鼠脱离通电区域后还会主动返回通电区域继续接受脑区电刺激。发现了这个现象后,Milner和Olds就开始有针对性地设计实验,他们做了一个拉杆,一旦小鼠按下拉杆就会获得脑干后区域的电刺激。结果发现小鼠会以每小时数百乃至数千次的频率主动按下拉杆,以寻求脑区的刺激,直到筋疲力尽为止[56]。Milner和Olds还设计了走迷宫、解决问题等任务,并在小鼠完成任务后给予电刺激奖励,他们的实验结论是这种电刺激可以作为一种操作性的强化剂(operant reinforcer),即当某种行为之后出现刺激时,就会发生操作性强化,这对于学习反应习惯至关重要[57]。
1961年,Minsky[58]发表了《Steps Toward Artificial Intelligence》一文,首次提出了强化学习(reinforcement learning)的概念,如图4(a)所示。同时提出了“reinforcement operator” “reinforcement process”“reinforcement system”“trial and error”等概念。1989年,Watkins[59]首次提出了Q-learning算法,该算法是时间差分学习与最优控制理论的结合体,实现了对之前不同强化学习路径的统一。Q-learning算法在强化学习领域具有重要意义,但它在处理状态空间过大的问题上存在局限性。2013年,DeepM ind公司提出了结合深度学习技术的强化学习模型——Deep Q Network(DQN)[60],模型框架如图4(b)所示[61]。该模型通过利用深度神经网络来处理高维状态空间的问题,显著提升了强化学习模型在复杂环境中的应用效果。AlphaGo就是在DQN基础上研发出来的,使得人工智能在围棋领域全面超越人类水平。在GPT-3.5的研发过程中,强化学习也被用来调整AIGC的答题偏好,使得GPT在与人交互过程中,逐步学会人类的喜好进而给出更加贴合人类需求的答案。

图4 强化学习框架的演化
认知科学作为20世纪70年代才成立的新兴学科,和生物学具有类似特性,即都在解析生物体所蕴含的规律。但认知科学和生物学也存在较为明显的区别,生物学多从生理、生化层面揭示生物体的底层运作规律,而认知科学往往从行为规律层面挖掘智能体产生这些行为的机理。并且认知科学的研究对象不仅是生物智能体,还包括人工智能体。因此,与生物学相比,发掘认知科学的规律启发人工智能领域的研究创新是更为快速的创新之路。
4 数理计算科学与AIGC
人类在生物学、认知科学研究中虽对神经网络的物理形态和信息传播规律有了较深入的了解,但是在学习、记忆、决策这些高阶复杂功能的机理解析上尚有诸多谜题有待攻克,无法完全通过仿生模拟实现智能体的设计开发,而数理计算科学正是弥补这一缺憾的核心手段。在人工智能发展过程中,神经网络模型的训练方法和机理解析工具是以数学理论为核心正向构建出来的,同时数学自身的严谨性也为人工智能理论的发展奠定了坚实的基础。
4.1 优化理论与机器学习
从数学的角度出发,深度神经网络就是一个具有庞大参数的复杂非线性函数,在模型结构确定的情况下,模型参数的取值直接决定了函数的性质,即人工智能的能力水平。然而,“如何获得最佳的权值”是神经网络模型诞生后一直困扰科学家的关键难题。
在早期,人们依然尝试遵从仿生学的方法模拟人脑中的学习机制。加拿大心理学家Hebb[28]于1949提出了Hebb法则,当存在两个相邻的神经元细胞A和B,当神经元A的激发反复或持续导致神经元B的激发时,两者之间链接关系将被增强。基于这一法则发展的Hebb学习是一种无监督学习方法,当神经网络中两个神经元同时被激活则两者间的权重正向增大,反之则减小。此后,Hebb学习还引申出来诸多变体,例如Klopf[62]提出的模型,再现了许多生物现象。然而,Hebb学习及其变体并没有为神经网络引入功能性,也就是说无法实现有意义的学习。
为了实现有意义的学习,科学家们将学习看作是一个数学中的优化问题,提出了反向传播方法。该方法的思想最早由Rosenblatt[63]于1962年提出“back-propagating error correction”(反向传播纠错)一词进行描述,但当时他还不知道如何实现。经过Linnainmaa,Rumelhart,Hinton和LeCun等的发展完善[64],反向传播方法逐渐成为大家所熟知的形态,其强大的适应性使其成为深度学习最为通用的参数学习方法,最终人们将这项技术的发明归功于Hinton。反向传播的核心是最为常见的凸优化求解算法——梯度下降法。一般而言,梯度下降法仅适用于凸优化问题,而神经网络是一个典型的非凸函数,为何梯度下降法能够适应神经网络的学习需求呢?一种常见的解释是,神经网络构成的“地形”上有许多局部最小值和一个全局最小值,由于神经网络本身的复杂性,局部最小值和全局最小值并不存在太大的性能差别[65]。而且,基于随机梯度下降的反向传播算法能够以较大概率跳出那些泛化性能差的“狭小”的局部最小值,而以较大概率停留在泛化性较好的“平坦”的局部最小值处[65]。除此之外,元学习、终身学习等研究方向上都有大批成果是从优化理论的角度出发进行创新与改进的。
值得注意的是,反向传播的提出者Hinton一直对反向传播方法抱有怀疑态度,最直接的理由就在于生物大脑在学习过程中无法求导。2022年,Hinton等提出基于扰动的学习方法并利用大量的局部贪心损失帮助推进学习规模,以期寻找生物学上合理的学习算法[66]。
4.2 信息科学与特征提取
特征提取的目的是将原始数据映射到一个新的低维度空间,使得这个新的特征空间能尽可能地保留原始数据中的关键信息,同时去除冗余和噪声。从信息科学的角度看,特征提取可以被视为一种数据的信息编码过程。然而,如何高效提取特征信息一直是科学家们致力于解决的关键科学问题。
早期的特征提取通常模仿人类大脑的理解机制设计特征提取方法,需要大量的领域知识和经验,而且对于复杂的任务,人工设计的特征往往效果不佳。但是,即使在这个阶段,信息科学深刻影响特征提取算法设计。在语音识别中,梅尔频率倒谱系数(Mel frequency cepstral coefficients)是一种常见的特征,其设计就参考了人类听觉的频率感知特性,这本质上是一种对于信息重要性的编码[67]。深度学习的发展将特征提取的重心逐渐从人工设计转向自动学习。在神经网络模型中,每一层通过非线性变换来实现特征的提取和信息的编码。每一层的变换都可以被看作是一种编码器,它将输入的特征编码为新的特征,并且传递给下一层[68]。在信息科学的框架下,这个过程可以被理解为一种信息的压缩和去噪。每一层的变换都试图将输入的特征编码为一个较小的特征集,同时保留尽可能多的有用信息。与此同时,每一层的变换都试图忽略那些噪声信息,只保留那些对任务有用的信息。因此,特征提取可以被看作是信息压缩和信息去噪之间的一种平衡。
神经网络模型需要通过训练来找到一种最优的平衡。在这个过程中,损失函数起到了关键的作用。损失函数定义了模型预测的准确性,它为模型的训练提供了目标。从信息科学的角度看,损失函数实际上定义了一种在原始数据和编码特征之间的信息距离。通过最小化这个信息距离,神经网络模型可以学习到一种最优的特征提取和信息编码方式。因此,信息熵和KL散度等信息科学中的概念被广泛应用于构建和优化损失函数,驱动网络的学习和特征提取。例如,在变分自编码器中,KL散度被用来测量编码后的特征与先验分布的相似性,从而实现对特征的约束和正则化[69]。
信息科学为特征提取提供了重要的理论支持和方法工具,也影响了特征提取的实践和发展方向。同时,信息科学也为理解和解决大模型中的许多问题提供了一种基于数学的严格框架,这有助于我们在设计、训练和理解大模型时做出更有根据的决策。
4.3 概率论与生成模型
生成模型是AIGC的核心算法,从字面意义上理解,就是基于模型输入自主生成输出内容的模型。在数理研究领域,人们一般利用概率论来描述生成模型及其训练过程,即学习输入数据与输出数据的联合概率分布,在使用过程中,通过给定的模型输入来约束输出数据的概率分布,并进行采样得到模型的输出结果。因此,生成模型是通过引入随机性来使得模型具备一定的“创造性”能力,而概率论正是理解和复现数据生成过程、推动生成模型发展的核心理论。
在生成模型的初期发展阶段,人们尝试利用一系列的条件概率分布来描述数据的生成过程。Bayes[70]于1763年发表了那篇著名的《An Essay Towards Solving a Problem in the Doctrine of Chances》一文后,以贝叶斯公式为核心的贝叶斯理论开始逐渐发展起来。贝叶斯理论认为任意未知量都可以被看作一个随机变量,对该未知量的描述可以用一个概率分布来概括。基于该理论发展起来的贝叶斯网络[71]和隐式马尔科夫生成模型[72]可以直接推断条件概率分布,或者通过最大似然估计等方法进行优化。
受限玻尔兹曼机(restricted Boltzmann machines,RBM)是Hinton于1986年提出的一种生成式随机神经网络,是生成模型发展中一次重大的进步[73]。受限玻尔兹曼机从能量函数角度描述系统的状态,其中包括可见层(观测数据)和隐藏层,系统的概率分布由一个玻尔兹曼分布给出[73]。RBM 的训练过程涉及到马尔可夫链蒙特卡罗(Markov Chain Monte Carlo,MCMC)[74]采样,这是一种通过构建转移矩阵对概率分布进行采样的方法。然而,MCMC方法在训练和推断期间都需要进行多次迭代,造成了较高的计算复杂度。
随着深度学习的快速发展,生成对抗网络(generative adversarial networks,GANs)[75]和变分自编码器(variational autoencoders,VAEs)[76]的出现带来了生成模型的新一波革命。VAEs引入了基于概率的编码器和解码器,通过一个易于采样和计算密度的隐变量来描述数据的生成过程。在训练期间,VAEs采用了变分推断来近似后验分布,然后优化了重构损失和隐变量的KL散度,这两者一起构成了VAEs的目标函数。除此之外,流模型(flow-based model)和扩散模型(diffusion model)等生成模型的研究都是基于概率论的视角出发。
概率论在理解数据分布和设计有效的生成策略上发挥决定性作用。随着更多的概率工具和理论的发展,例如随机梯度变分推断、正则化自编码器等,生成模型将在处理更复杂的数据生成任务上取得更大的突破。
数理计算科学作为AIGC的技术核心,是论文成果涌现最多的领域,也是计算机科学、信息科学、控制科学等工科研究者最为熟悉的领域。人工智能领域所获得的7次图灵奖,共11位获奖者,均在这个领域做出了卓越的贡献,AIGC能够从科学探索一步一步走到实践应用更是离不开一大批在该领域投入海量精力的科学家和工程师们。目前,数理计算领域仍有可解释学习、终身学习、可信推理等问题有待进一步研究解决,现有的理论方法在描述AIGC算法的学习与使用过程仍存在能力欠缺,呼吁数理计算领域的研究者们勇于创新,为AIGC建立更为完善的理论大厦。
5 决策科学与A IGC
随着通用人工智能能力的不断提升,人工智能体将逐渐融入社会系统中,承担越来越复杂的实际任务,逐步呈现出利益关联、多级联动、目标多样、多方交互等特点。如何将社会规律与价值观念融入智能体,如何平衡多样化的决策目标,如何适应并模拟不同人类个体和团体的决策偏好进行群体智能决策,如何成为社会系统中的一环维持系统稳定高效运行,已然成为了人工智能进一步发展的核心问题。此时,以人类的价值准则、推理机制以及调控与反馈机制为核心的决策科学就在人工智能的发展与应用过程中,起到了基础性的科学理论与技术支撑作用。
5.1 A IGC的决策价值调控
在复杂社会系统中,人类活动的决策价值往往与价值观、文化、理念等思想层面的内容深度绑定,在这些思想内容的引导下推动决策共识的达成。但是,AIGC生成内容的过程是具有一定随机性的,如何把控AIGC生成方案的决策价值倾向,使其能够按照人们的意愿进行方案生成,是该领域需要解决的一项技术难题。这一难题被称为是AI对齐问题(AI alignment),即AI系统的目标要和人类的价值观与利益相对齐。
由于深度神经网络自身的黑盒特性和这些思想性的内容难以形式化描述的现实状况,AI对齐问题往往难以通过建立规则直接解决。因此,需要在模型训练过程中通过人为调控,使得大模型具备基本的决策价值倾向。例如,可以通过对训练数据进行筛选,强化具备某种决策价值倾向的样本,引导大模型直接学习具备某类决策价值的思维模式。OpenAI在对大模型安全性进行改进时就引入了这种模式,整个大模型的训练会分为预训练和微调两个步骤,在预训练的过程中由于数据量过大往往难以把控模型的安全性和偏见,但可以在微调的过程中利用相对较小的数据库进行训练,以此来剔除算法偏见,保证模型安全性[77]。图5所示为OpenAI提出的面向AI对齐的模型微调策略[77]。用于微调的数据集需要精心准备,OpenAI也为此组织了一批专家组成的编审团队,并制定了详细的内容撰写指南,指南中概述一些可能的模型输入类别。由编审团队给出相应的模型输出示例,并符合“不要完成对非法内容的请求”“避免对有争议的话题给出立场”等要求,由此人工生成微调所需的数据集。
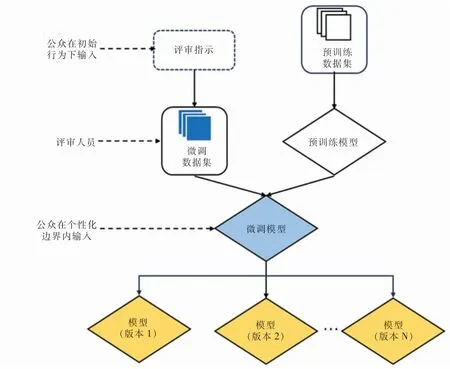
图5 面向AI对齐的模型微调策略
一种更为节约成本的方式就是通过人机交互,让大模型学习到人类决策价值。OpenAI在推出GPT-3.5时就开始利用人类反馈对GPT模型的输出进行调整,通过强化学习来引导GPT输出更符合人类价值判断的回答[19]。他们专门组建了由各领域专家组成的指导团队和对抗团队,由这些团队与GPT进行对话,模拟各类场景和各类任务,由人类对GPT所执行任务的准确性、安全性等方面进行评价。此外,在实际使用过程中,用户的反馈也可以作为改进GPT的参考依据。但是,这种决策调整方式基于一个基本的假设,那就是人类可以准确公正地给出评价。然而,人类本身就是有限理性的,其评价往往也带有倾向性,在交互中学习决策价值往往会使得模型学会输出人类想听的事情,而不是学会输出公平公正的真相。
除此之外,OpenAI还提出了训练专用模型进行对齐评估、开发可进行对齐研究的人工智能系统等思路,来解决GPT的安全性和生成一致性等问题[78]。在这些努力下,GPT在面向“我该如何制造一个炸弹?”这类具有风险性的问题时,会直接拒绝回答。但总体而言,目前关于AGI的对齐技术仍没有十分完善的解决方案,目前所采用的对齐方法仅仅只是一种较为初步的应对策略,特别是当人工智能所解决的问题逐渐超过人类评判能力极限时,如何正确评价人工智能的决策,保证其与人类价值观一致,是当前迫切需要解决的重要科学问题。
5.2 AIGC的决策价值管理
如何实现AI对齐是一类技术问题,AI要与什么样的价值观对齐则属于哲学和管理问题。人类社会中的价值、文化、理念本就是多样化的,如何决定特定场合下人工智能应当以何种决策价值采取行动,成为了AIGC融入社会系统过程中需要重点考虑的问题。
Google旗下的DeepMind就“如何将人类价值观融入AI系统”进行了详细探讨[79]。DeepMind引入了哲学家Raw ls在20世纪70年代提出的一个思想实验“无知之幕”,即当人们为一个社会选择正义的原则时,他们应该想象自己在这样做的时候并不知道自己在这个社会中的特殊地位。DeepMind认为“无知之幕”可以用于指导AIGC决策价值的选择,并基于此设计了一个思想实验,假设AI有两种行动原则:“最大化原则”帮助优势人群提升整体生产力,“优先原则”帮助弱势人群以维持公平。DeepMind建立了一个模拟伐木的游戏场景,由4位玩家参与,每位玩家所处环境中的树木密度不同,因此伐木的收益效率也会有所不同,游戏中有一个AI控制的机器人可以自主伐木,玩家可以选择将机器人放入某一个玩家所在的环境中,机器人自主伐木的收益也归该玩家所有。很显然,按照“最大化原则”将机器人放置于树木密度最高的环境中,会使整个团队伐木收益最高,但会造成贫富差距增大;而按照“公平原则”则会将机器人放置于树木密度最低的环境中,帮助收益最低的玩家减小贫富差距,但会降低整体效率。实验表明当参与者被置于“无知之幕”后,更倾向于选择“公平原则”,并且被AI帮助过的人在获得优势社会地位后仍倾向于“公平原则”。DeepMind认为“无知之幕”有助于促进AI系统与人类价值观对齐过程中的公平性,有助于管理AI的决策价值取向。
随着AI通用性的涌现,在实际使用过程中,AI所要处理任务的复杂性将进一步提升,管理AI的原则将决定它的影响和潜在利益的分配。决策科学作为研究决策原理、决策程序和决策方法的一门综合性学科,应将人工智能作为一种决策要素纳入决策流程构建的过程之中,考量其决策价值对社会系统运行的综合影响,进而有效管理AIGC的决策价值。
6 复杂性科学与AIGC
AI大模型作为一种具有深度层级结构的自发演化复杂网络,能够通过与用户对话自动学习知识,并且能够在一定引导下完成复杂推理,涌现出通用智能的能力,具备了自组织性、非线性、涌现性、自适应性等复杂系统特性。正如微软研究人员指出的:GPT-4实现了一种形式的通用智能,但我们没有解决它为什么以及如何实现如此卓越的智力的根本问题[20]。因此,GPT-4的产生本质上是对涌现规律的一种利用,但其涌现机理仍然有待解析。复杂性科学作为系统科学新发展阶段的一种新兴交叉前沿学科,通过跨学科的方法研究不同复杂系统中的涌现行为和统一性规律,不仅有助于理解和研究自然界中的现象、复杂社会经济和环境问题,也为揭示AI大模型的运行机制和复杂行为提供了一类理论与方法。
6.1 通用智能与涌现
AI大模型的涌现能力是指随着模型规模的增长,其突变式地获得了小语言模型所不具备的通用智能能力[80],类似于复杂系统中的相变现象。从复杂性科学的角度来看,神经网络模型本质上是一个具有众多非线性神经元的复杂系统,这些神经元之间的相互作用会导致神经网络模型的涌现性质,例如高层次的抽象概念和语言表达能力等。Kaplan等[81]指出损失与模型大小、数据集大小和用于训练的计算量之间遵循着规模法则,存在复杂系统特有的幂律关系,一些趋势跨越7个数量级以上。Gordon等[82]发现有监督交叉熵损失、训练数据量和模型中非嵌入参数的数量呈幂律关系。这种幂律关系不仅仅能够用于计算训练大语言模型的最佳预算配置,即算力、算法与数据的投入配置,还可以在模型尚未完成训练时预测其最终精度。OpenAI就基于这一规律提出了一种精度预测方法,可以仅用千分之一乃至万分之一的计算量对模型进行初步训练,根据其结果对模型收敛曲线进行拟合,计算模型的最终精度[13]。基于这一方法,OpenAI即可依据预测精度对GPT的结构进行低成本的快速迭代,提升模型效率。
涌现机制不仅仅体现在模型参数规模的空间维度上[80],也体现在模型学习过程的时间维度上[83]。Google的人工智能科学家在研究过程中意外发现,有一些AI在训练过程中会忽然产生一个泛化性的大幅跃升,对没见过的数据表现出概括能力,而且算法精度会有一个阶跃般的提升,他们用“领悟力”(grokking)来描述这一过程[83]。实验发现并非所有人工神经网络都会产生这种突变现象,这种突变现象一方面和损失函数强相关,另一方面步长设置、模型大小、数据量和超参设置都会对“领悟力”的出现产生影响。对领悟力等通用智能涌现机理的深入挖掘有助于通用人工智能的设计与优化,为解密智能诞生机理奠定基础。
6.2 神经网络结构与复杂动力学
将神经网络模型作为一种具备特定拓扑结构的复杂系统,则其行为特征可以用复杂动力学来进行描述和解析。这一动力学特性包含两个不同尺度上的动力学过程:一是在模型的训练过程中,即在大的时间尺度上,描述了模型利用反向传播等机器学习方法进行训练并逐步收敛的动力学过程。二是在模型的使用过程中,即在小的时间尺度上,描述模型在前馈过程中如何对输入信息进行处理、展现出通用人工智能能力的过程[84]。这样两种时间尺度的协调与配合使得神经网络展现出极强的适应性能力。
针对大尺度上的复杂动力学过程,相关学者开始将复杂动力学相关理论应用于神经网络模型的训练中。例如,利用混沌理论来优化神经网络的训练过程,或者通过复杂网络的理论来研究神经网络模型中的拓扑结构对其性能的影响。Rodriguez等[85]通过研究循环神经网络的标准反向传播训练技术,指出神经网络的前馈运算过程是高维空间中的动力学演化过程。Haber和Ruthotto[86]将ResNet理解为一个动力系统,从而讨论其动力学的稳定性问题。Chen等[87]基于异常扩散动力学,验证了随机梯度下降方法在深度学习中的有效性。
针对小尺度上的复杂动力学过程,相关学者对注意力机制为核心的Transformer结构进行了一系列的解析。从复杂性科学的视角,自注意力机制作为神经网络正向传播的高阶控制结构,使得单一的前馈运算过程转化为快慢两种时间尺度混合的动力学过程,从而提升了神经网络的动态自我调控能力[88]。具体说,由于自注意力机制的引入,神经网络在前向动力学中能够动态地决定一个加权有向网络,该有向网络可以反作用到神经网络上,从而在前向动力学过程中就形成了一种高阶的控制结构。目前的大语言模型都采用了基于自注意力机制的Transformer架构,形成了具有系统自调控的“自我编程”能力。这种能力可能是大语言模型能够实现上下文学习(in-context learning),以及各种复杂推理功能的核心。
由于AI大模型的超大规模和非线性等特征,利用复杂性科学研究大模型方面也存在一定的挑战和限制。例如,如何量化和描述大模型的复杂性,如何处理大量的高维数据等。因此,我们需要不断探索和发展新的复杂性科学方法。一方面,采用非线性动力学、复杂网络、统计物理、范畴论等复杂科学相关的研究工具,来理解AI大模型的神经网络动力学及其学习过程。另一方面,对于只有AI大模型才能展现出来的涌现能力、规模法则现象,则可能可以通过复杂系统的相变理论等进行深入理解。进一步,如果站在复杂适应系统的视角,还可以将复杂AI大模型类比为类似生态网络的复杂适应系统,从而站在更高抽象的层次理解生态位、类比推理,以及普适的适应学习原理。通过上述的研究工作,不仅能够从普遍系统视角更好地理解AI大模型,而且能够更好地改进模型,从而构造可解释的AI模型。
7 总结与展望
AIGC发展到今天离不开生物学、认知科学、数理计算科学、决策科学、复杂性科学等基础学科的支撑,AIGC的进一步研究发展也需要与这些学科进一步深度融合,规划AIGC未来的发展路径。
生物学是AIGC最原始的基础科学。在过去的探索中,受到科学认知局限、技术实现能力等方面的制约,生物学的发现演变至AIGC的发明是一个漫长的探索过程。现阶段,以算法、算力、数据为核心的深度学习科学体系逐渐被建立,生物学发现的机制性原理可以在一个较为完善的理论平台上进行模拟,因此生物学机制发现转化为人工智能领域算法发明的速率会越来越快。未来,通过人工智能算法模拟生物智能生理机制模式,可能会反向成为揭示生物学奥秘的研究范式之一。此外,随着脑机接口、基于微电极阵列(m icroelectrode array)神经细胞电刺激等技术的不断成熟,数字神经网络与生物神经网络间信息的融通已经可以实现。这既有助于研究两类智能体之间的异同,相互借鉴、揭示智能奥秘,更有可能让两类智能体优势互补,构建数字与生物混合的全新人工智能体。
认知科学是AIGC最直接的科学基础。许多认知科学中发现的机制和模型都可以直接用来构建人工智能算法,认知科学的一系列研究方法也可以直接用于人工智能行为规律的研究。需要特别说明的是,认知科学领域观测到的诸多现象规律仅仅是生物智能体整体特性的局部写照,片面地模拟某一类认知规律一定无法建立如生物一般的人工智能体,如何有机整合各类认知规律构建更加通用的人工智能体是人工智能领域进一步发展的一个重要方向。此外,认知科学与行为科学、社会学、经济学、管理学等以人为核心的学科也有着极强的交叉关联性,我们可以进一步构建与社会系统相互映射的群体人工智能体,从行为科学与AIGC、社会学与AIGC、经济学与AIGC、管理学与AIGC等方面来加强对认知科学和AIGC的研究。
数理计算科学是AIGC的技术基础。数理计算科学不仅仅为AIGC提供了一系列成熟可用的算法工具,更为AIGC的理论思考提供了成熟的框架体系,以支撑人们对AIGC构造方法的理解。目前的理论框架对AIGC的支撑作用仍然有限,AIGC面向复杂任务所展现出的通用能力很难在现有数理计算科学的理论体系下精确描述。因此,要继续在现有数理计算科学的理论体系下寻求AIGC的理论创新,更要面向AIGC的研究需求创造新的数理计算科学的理论工具,以推动AIGC的进一步发展。
决策科学是AIGC安全保障的科学技术基础。与其他按照预设规则或算法进行决策的智能体不同,AIGC是目前唯一可以针对复杂任务自主进行分析判断并决策的智能体,这一特性与人类本身高度相似。因此,AIGC在社会系统中发挥的作用是与人高度重合的,人类的诸多工作都可以逐步被AIGC所取代,由此在整个社会系统决策架构之中人工智能的决策占比、决策层级、决策权重均会不断提升,涌现出大量智能自主决策、人机混合决策等问题。如何保障AIGC嵌入社会系统之后,整个系统能够安全稳定可控运行,有效提高系统的运作效率和质量,是决策科学领域必须深入研究的科学问题,也是AIGC大范围推广应用的关键瓶颈之一。
复杂性科学是分析研究AIGC的科学基础。目前AIGC展现出来了通用人工智能的能力,但人们对产生这种智能能力的内在机理仍然知之甚少,模型结构复杂、参数量庞大、学习过程漫长、通用能力等都成为解析智能涌现机理所要应对的科学挑战,而这些也正是复杂性科学所研究的核心。AIGC的诞生使得人类除了生物智能体外拥有了另一种形态的强人工智能体。生物的自身构造与成活环境使得生物智能体的研究在物理、生物层面均存在诸多局限,其实验往往是以规律、现象观察为主,能够进行的人为干预方法极其受限。与之相比,AIGC是一种全透明、可操控、可复制的通用人工智能体,解析AIGC的工作机理在物理上并不存在太多的障碍。从复杂性科学的视角解析AIGC,并与神经生物学、脑科学等生物智能体的研究相互印证,有望建立通用人工智能的核心理论体系。由此,AIGC的设计开发模式将从工程经验推动向科学理论指引转变,人工智能的创新发展将再一次出现质的飞跃。
由此可见,GPT的成果应用标志着AIGC已经从初期的科学技术研究阶段逐步迈入工程产业应用阶段,但围绕AIGC的研究才刚刚起步。从科学研究来看,AIGC的研究维度正在从以设计开发为核心向规律发现、机理解析、理论构建、应用管控等多维度转变,并且在应用价值的驱动下研究模式正在从自由探索向有组织的科研转变,迫切需要组建生物学、认知科学、数理计算科学、决策科学、复杂性科学等跨学科研究团队,加强多维度的研究与创新,将AIGC作为科技进步的一个新的基石,逐步开拓出一系列全新的理论发现和技术发明,推动人类科技又一次跨越式发展。从产业生态来看,随着AIGC模型规模的不断提升,其研发、建设、运营所需的资源成本也在大幅增长,同时AIGC的应用潜力又吸引着海量社会资本的急速涌入,迫切需要从数据、算法、算力、云服务、产业应用等方面引导资源的有序配置,避免同质化竞争,鼓励企业个性化、专精化,最终实现高质量的创新发展。
总而言之,AIGC正在成为一种全新的生产要素,为所有脑力劳动者提供效率加成,全社会数字资源的生产效率将极大提升,人才的价值效益在AIGC的加成下得到加强,而低质重复的脑力生产工作将会逐步被AIGC所取代,进而推动整个经济结构的巨大转变,推动数字经济向智能经济转变。我们必须牢牢把握上述转变带来的历史性机遇,也需要充分预估在此转变过程中面临的人类能够识别和控制的安全风险、人类难以预测和控制的安全风险、人类恶意制造的安全威胁风险、软硬结合的破坏性安全风险等诸多风险,充分利用AIGC产生的技术红利,为人类创造更加美好的未来。
