融合自注意力的ALBERT中文命名实体识别方法
2023-02-21游乐圻裴忠民罗章凯
游乐圻,裴忠民,罗章凯
(航天工程大学 复杂电子系统仿真重点实验室,北京 101416)
0 引 言
与基于规则和统计的传统命名实体识别(named entity recognition,NER)方法相比,深度学习有助于自动发现隐藏的特征,所以基于深度学习的方法在当前NER任务中占据主导地位。特别是预训练语言模型BERT的出现,大大提高了中文NER模型的性能。但是BERT的不足之处同样不可忽视:其训练时间长、参数量大,这导致基于BERT的NER模型在工程应用受限[1]。如何在减少训练时间的同时提高模型的识别性能成为现阶段中文NER研究的关键难点。
对此,本文基于ALBERT,融合“自注意力”层能采集上下文相关语义信息的优点,提出ALBERT BiLSTM-Self-Attention-CRF模型。具体考虑如下:为了减少模型训练时间,编码层选用参数量少的ALBERT。但是参数量大量减少就不可避免带来整体模型性能的损失。为此,模型又从两个方面来弥补损失。一是结合了BiLSTM-CRF,原因是ALBERT内部使用的Transformer结构弱化了语言序列的方向信息和位置信息,而BiLSTM中特殊的记忆单元可以捕捉语言序列的每个位置的依赖信息;二是融合了“自注意力”机制,其作用就是使模型将有限的信息处理能力更多地关注在对识别模型而言有效的实体信息上,进而达到提高模型识别性能的目的。
1 相关研究
预训练语言模型的应用,使得NER模型性能有了显著提高。2018年,预训练语言模型BERT[2]横空出世,研究者们将BERT应用于NER领域[3,4],发现基于BERT的中文NER取得了重大的突破,就算是在极小数据集的情况下,F1值都能达到92%以上的水平。但是BERT庞大的参数量使得模型抽取时存在训练时间过长而导致专业领域应用受限。在提出BERT的原论文中,BERT就有3亿的参数量,训练一个BERT-Large更是要64个TPU工作4天才能完成。
近年来的NER研究都不能兼得训练时间和模型性能。为解决BERT过大参数量的问题,文献[5]提出了ALBERT,从分解嵌入、共享参数、改进任务3个方面对BERT改进,减少了模型参数的同时也略微降低模型性能。文献[6]提出将ALBERT模型用于中文NER任务,达到了降低模型训练时间和成本的效果,但是在识别性能上整体弱于基于BERT的模型。文献[7]提出能在编码时融入中文字符及词汇信息的Lattice LSTM-CRF模型,模型识别效果逊色于基于BERT的模型。文献[8]提出BiLSTM-CNN-CRF模型。该方法的结合了人工神经网络可以卷积获取字符和词语表示,将此作为BiLSTM的输入,取得了不错的效果。文献[9]将顺序遗忘编码融合进BiLSTM,在中文NER中取得了F1值91.65%的成绩,效果仍不及BERT BiLSTM-CRF。
融合自注意力机制可以有效提高中文NER模型的性能。文献[10]在BiLSTM-CRF模型基础上加入自注意力机制,提高了领域实体识别精确率。文献[11]在BiLSTM-CRF基础上引入了一个多重的自注意力机制来把握因果词语之间的依赖关系,有效改进了模型性能。文献[12]设计了一种用于中文NER的名为“CAN”的卷积关注网络,采用GRU单元捕捉相邻字符和句子上下文的信息,比原来模型具有更高的识别性能。文献[13]提出BQRNN-CRF+Attention模型,和BiLSTM-CRF相比在性能和效率上都有了提高。文献[14]提出CWA-CNER模型。该模型融合了多头注意力机制和中文字词信息,在中文NER效果中取得新突破。
结合现有研究,本文提出ALBERT BiLSTM-Self-Attention-CRF模型,降低模型训练成本的同时又提高了模型整体识别性能。该模型采用ALBERT预训练语言模型,训练时间大大减小;同时融合了自注意力机制能很好采集上下文信息的优点,进一步改善了模型性能。
2 模 型
2.1 整体框架
本文提出的ALBERT BiLSTM-Self-Attention-CRF模型整体结构如图1所示,由ALBERT层、BiLSTM层、自注意力层、CRF层4个模块组成。模型组合顺序考虑:ALBERT层将语句向量化,作为模型输入层。CRF作用是对状态序列的寻优和输出,充当模型的输出层。将自注意力层放在BiLSTM层和CRF层之间,主要是考虑“自注意力机制”是在向量层面寻找最优的序列,输入和输出的都是向量,而BiLSTM层输出为带有位置信息的序列向量,因此,在BiLSTM和CRF之间接入最为合适。

图1 ALBERT BiLSTM-Self-Attention-CRF模型结构
各层功能简述:模型的第一层是ALBERT层,在此层中使用ALBERT预训练模型获取字向量标记序列X=(x1,x2,…,xn), 利用文本内部关系提取文本重要特征;其次是BiLSTM层,字向量传入该层后,通过学习上下文特征信息得到特征权重;再经过自注意力层寻找序列内部联系,并输出得分序列;最后在CRF层中利用状态转移矩阵和相邻信息获得一个全局最优序列。
2.2 模型各层实现
2.2.1 ALBERT层
和NLP中其它的预训练语言模型一样,ALBERT主要作用就是计算语言序列的所有的可能概率P(S)
(1)
ALBERT和BERT一样都采用了Transformer作为编码器,Transformer编码单元主要是运用注意力机制来获得序列内部的关系权重,如图2所示。
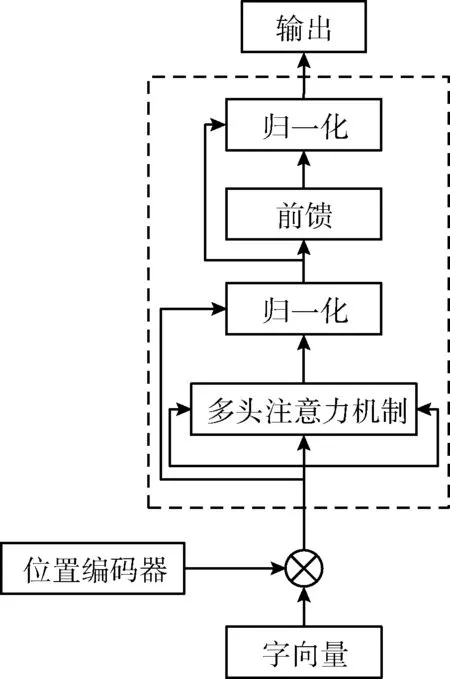
图2 Transformer编码单元
ALBERT主要在以下3个方面对BERT进行改进:
(1)对嵌入的因式分解
BERT的参数量复杂度为o(V×H), 其中V是总参数量的词汇表长度,H是每个词嵌入隐藏层大小。ALBERT的改进思想是,因为融合了上下文信息,隐藏层包含的信息会多于词汇表,则理论上有H≫E。 ALBERT对字向量参数进行因式分解,将其分解成2个更小的矩阵,参数量的复杂度改变如式(2)
o(V×H)→o(V×E+E×H)
(2)
(2)跨层参数共享
Transformer的跨层共享参数可以分为共享所有参数、只共享FFN相关参数和只共享attention相关参数3种模式。ALBERT选择了共享attention和FFN的相关参数,即把每个attention的参数共享给每个注意力头。从结果上看,跨层参数共享可以很有效地压缩参数总量,但副作用就是使得模型的性能有下滑。
(3)句间连贯性损失
ALBERT对下一句预测任务进行改进,方式是正样本和选择两个同文档中顺序相连的句子,负样本则是正样本相同的两个句子调换顺序,这只需要对句子之间的关系进行推理,提高预测效率。
2.2.2 BiLSTM层
长短期记忆神经网(LSTM)是一种特定的循环神经网络(RNN),其克服了传统RNN的梯度爆炸问题。通过专门设计的栅格结构(如图3所示),模型可以选择性地保存上下文信息。LSTM的主要由遗忘门、输入门和输出门3种门控单元来控制输入输出

图3 LSTM单元结构
it=σ(Wi·[ht-1,xt]+bi)
(3)
ft=σ(Wfhht-1+Wfxxt+bf)
(4)
ot=σ(Wo·[ht-1,xt]+bc)
(5)
(6)
(7)
ht=ot∘tanh(ct)
(8)


(9)
2.2.3 自注意力层
文本信息经过BiLSTM层编码成的隐向量具有相同的权重,因此进一步的特征区分很有必要。本文引入“自注意力”机制(如图4所示)来弥补模型的准确性损失,自注意力机制只在序列内部完成注意力计算,寻找序列内部联系。
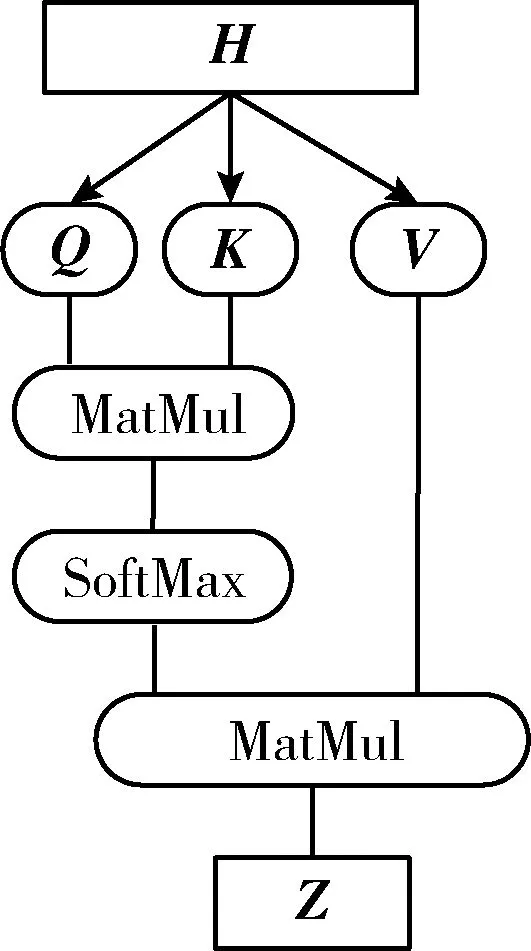
图4 自注意力机制
给定H作为BiLSTM层的输出,注意力机制首先将矩阵H投影到矩阵:Q,K和V,并行计算注意力矩阵,最后通过并联头部产生的所有矩阵均匀,得出最终值Z。具体到每个词的重要程度,使用SoftMax对score=Q·K处理得到,如式(10)
(10)

本文使用的多头注意力机制就是分别让每个头独立计算注意力矩阵,最终结果就是将各个头的结果拼接,能多维度捕捉文本上下文特征
(11)
Multi(Q,W,V)=Concat(headi,…,headh)Wo
(12)
2.2.4 CRF层
条件随机场(CRF)是使用机器学习处理NER的一种常用算法。CRF层可以通过考虑标签序列的全局信息并将约束添加标记到最后预测结果中的方式学习上下文信息,组合标签序列的全局概率和输出层结果,并预测具有最高概率的标签序列。对于给定句子,即输入序列X=(x1,x2,…,xn) 和相对应的输出标签序列Y=(y1,y2,…,yn), 定义CRF评估分数为
(13)
其中,A和P分别是转移得分矩阵和输出得分矩阵。Ayi,yi+1表示从标签i到标签i+1的转移分数。Pi,yi表示第i个中文字符的输出分数yi。
用Softmax函数归一化所有可能的序列之后,所产生的输出序列的概率p(y|x) 可如式(14)表示
(14)

(15)
预测时,通过等式输出具有最高概率的一组序列
(16)
3 实验设置与结果分析
3.1 数据集与数据标注
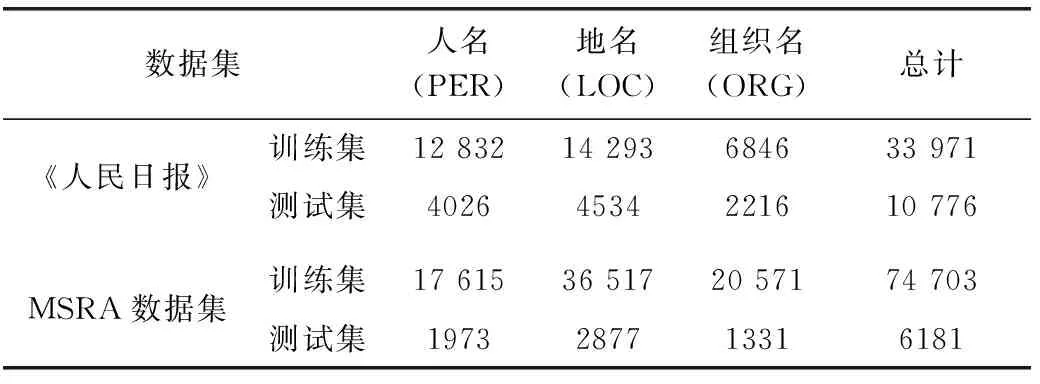
表1 数据集实体个数统计
数据集使用BIEO模式标记,即将实体的首个字符标记为“B-(实体名称)”,中间字符全部标记为“I-(实体名称)”,结尾字符标记为“E-(实体名称)”,其它不相关字符标记为O。
3.2 评价指标与环境设置
本文采用的NER评价标准主要包括精确率(P)、召回率(R)和F1值,并定义TP为模型正确识别到相关实体的样本数,FP为模型将非相关实体误识别为相关实体的样本数,FN为模型未识别到其中所包含的相关实体的样本数。具体如式(17)~式(19)
(17)
(18)
(19)
本文进行实验时所采用的环境见表2。

表2 实验环境配置
3.3 参数设置
为更好对比研究模型性能,实验的参数统一做如表3设置。

表3 实验参数设置
为使得模型结果最优,在《人民日报》数据集上分析参数不同取值对模型性能的影响。其中,batch size、rnn units、dropout这3个参数对模型的训练时间和性能具有重要作用。图5选取batch size为16、32进行实验,继续增大时出现不适用的情况;图6为rnn unit设置为32、64、128、256实验结果;图7为dropout从0.1变化到0.9时模型性能的变化。

图5 不同batch size时的模型性能

图6 不同rnn units时的模型性能

图7 dropout对模型性能的影响
综合图5、图6、图7可知,当batch size=32,rnn units=64,dropout=0.5时,模型的性能最佳,并且具有较好的泛化能力。
3.4 实验结果与分析
本文实验主要是从两个方面来验证本文提出模型的有效性:一是对ALBERT同系列模型内对比,目的是为了验证融合“自注意力”机制对模型性能的作用;二是和近年来的NER模型对比,目的验证本文模型的优越性。
3.4.1 与ALBERT同系列模型对比
本小节设置了ALBERT BiLSTM-CRF、ALBERT CRF两个对照实验,实验在《人民日报》数据集上进行,从损失函数和精确率两个角度分析模型性能。
为了分析模型在训练过程中损失和精确率随着训练程度的变化情况,本文每隔70个数据条选取1个节点,统计分析总共48个节点的损失和精确率。得到损失和精确率变化曲线如图8、图9所示。

图8 损失变化曲线

图9 精确率变化曲线
综合图8、图9,对比个模型的损失函数曲线和精确率曲线可知,训练达到一定的阶段后,ALBERT BiLSTM-Self-Attention-CRF模型的损失函数小于其余两个模型,精确率大于其余两个模型。由此可以看出,融合“自注意力机制”可以提升模型性能。但是,可以发现所提模型收敛速度是三者中最慢的。究其原因,模型层数的增加收敛速度变慢,增加自注意力机制造成的结果是需要更多的训练来使模型达到最优性能。具体实体识别效果见表4。

表4 ALBERT系列模型实体识别效果
由表4可知:
(1)ALBERT BiLSTM-CRF相比于ALBERT CRF模型各个指标都更优。可见,加入BiLSTM层能够更好地利用上下文信息,提高模型的识别性能。
(2)ALBERT BiLSTM-Self-Attention-CRF模型相比于ALBERT BiLSTM-CRF模型,精确率P提高了1.82%、召回率R增加了0.41%,F1值增加了0.97%。由此可知,融合“自注意力”机制能多维度捕捉文本上下文特征的特点,可以进一步改善模型性能。
3.4.2 和近年来NER模型对比
本小节设置了3个对比实验,分别在两个数据集上都进行对比实验。3个对比模型如下:
BERT CRF模型,是2017年由文献[2]提出的BERT组合CRF层。
BERT BiLSTM-CRF模型,由文献[3]于2019年提出,是当前使用最广泛的NER模型,许多研究也是此模型基础上改进或者以此作对比验证。
Lattice-LSTM-CRF模型,2018年由文献[7]提出,该模型只针对中文NER,融合了中文字符与词序信息,在MSRA数据集上取得了当时最优识别结果。
各NER模型实验结果见表5。
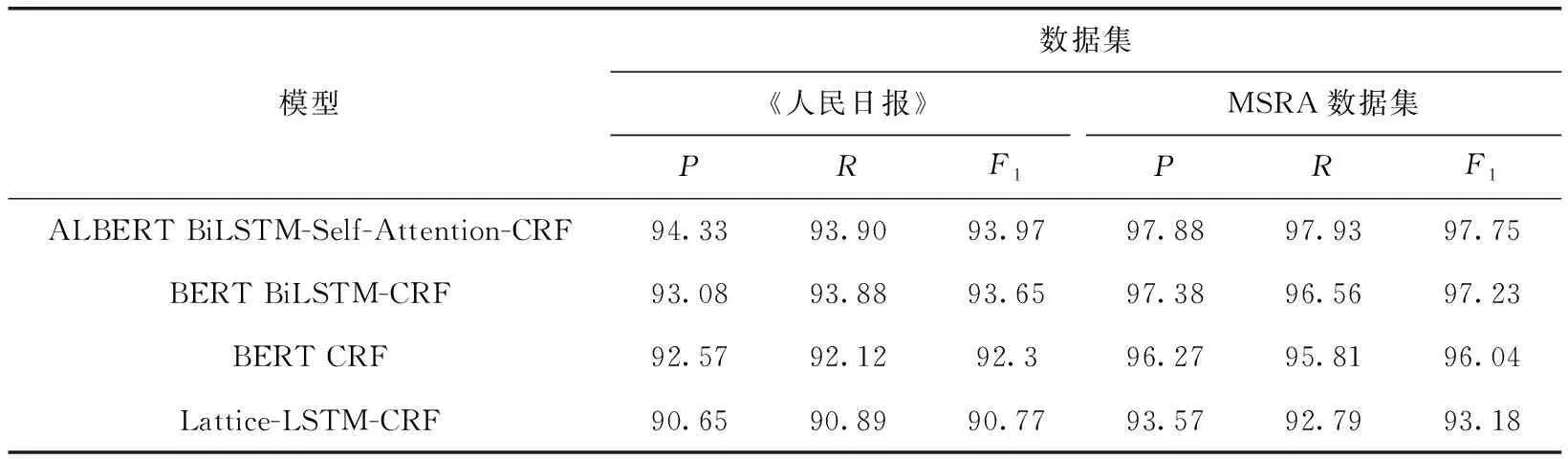
表5 各NER模型实体识别效果
在《人民日报》数据集上对比所提模型和BERT BiLSTM-CRF每epoch所需的训练时间,见表6。

表6 两模型运行时间统计
综合表5、表6可得:
(1)Lattice-LSTM-CRF识别效果远低于其它3个模型,这表明Lattice-LSTM-CRF虽然融合了文字字符词汇信息可以提升模型识别效果,但是神经网络模型处理语言信息的能力弱于预训练语言模型。
(2)本文所提模型相比基于BERT的NER模型P、R、F1在两个数据集上均提升0.8%左右,训练时间比BERT BiLSTM-CRF减少约13.8%。所提模型达到了减少训练时间、提升模型性能的效果。
此外,为了进一步验证本文研究的先进性,将本文模型和近年来对中文NER的研究对比,语料都采用《人民日报》数据集。
由表7可知,前4种中文NER模型都是在神经网络的基础上进行融合词汇、字符等信息的方式提高模型的识别效果,但是性能都逊色于本文模型,这验证了本文在ALBERT基础上融合自注意力做法的有效性。

表7 各中文NER研究对比
4 结束语
针对现阶段中文NER模型识别性能有待提高和训练时间过长的不足,本文提出ALBERT BiLSTM-Self-Attention-CRF模型,和BERT BiLSTM-CRF相比,提升了性能的同时还减少了模型训练时间。该方法的贡献在于:①将“自注意力机制”、ALBERT、BiLSTM-CRF三者相融合,和基线模型相比,在更少的训练时间下取得了更优的识别效果,一定程度上解决了预训练语言模型在中文NER任务中的应用受限问题;②和在中文NER模型中融合词典、词汇、词序等平行研究相比,本文模型取得了最优的识别效果,为中文NER后续的研究方向提供参考。
