结合Transformer与非对称学习策略的图像检索
2023-02-21贺超魏宏喜
贺超,魏宏喜
1.内蒙古大学计算机学院,呼和浩特 010010;2.内蒙古自治区蒙古文信息处理技术重点实验室,呼和浩特 010010;3.蒙古文智能信息处理技术国家地方联合工程研究中心,呼和浩特 010010
0 引 言
在大数据时代,互联网等媒介中的图像数量呈指数级增长,如何从海量图像中快速查找出所需图像是值得研究的问题。近似最近邻(approximate nearest neighbor,ANN)搜索(Andoni和Indyk,2008;Zhang等,2010)是解决此问题的常用方法。作为一种广泛使用的近似最近邻搜索技术,哈希方法(Wu等,2019;Guo等,2017,万方 等,2021)的目的是将原始空间上的数据点映射到汉明空间上的离散2进制哈希码。同时,原始空间上的相似性也保留在汉明空间上。哈希码具有存储空间占用小、计算速度快等优点,广泛应用于图像的大规模检索。
哈希方法分为与数据无关的方法和与数据相关的方法两种(刘颖 等,2020)。前者将图像随机投影在特征空间中,用2进制方法生成哈希码(Gionis等,1999)。后者通过机器学习方法学习哈希函数,将图像特征映射为2进制代码(Lai等,2015)。对于依赖数据的方法,维数较少的哈希码可以很好地表示图像特征并获得更好的结果,因此与数据相关的哈希方法在现实中广泛使用。与数据相关的哈希方法分为有监督的哈希方法和无监督的哈希方法。最具代表性的无监督哈希方法是迭代量化(iterative quantization,ITQ)(Gong等,2013),它根据给定的训练样本,通过迭代投影和阈值法对投影矩阵进行优化。为了更好地利用语义标记进行特征表示学习,研究人员提出了监督学习方法。监督学习方法分为非深度监督哈希和深度监督哈希。传统的非深度监督哈希算法利用图像的颜色和纹理学习哈希函数。具有代表性的非深度监督哈希方法有核监督哈希法(supervised hashing with kernels,KSH)(Liu等,2012)、隐因子哈希法(latent factor hashing,LFH)(Zhang等,2014)和快速监督哈希法(fast supervised hashing,FastH)(Lin等,2014)等。随着深度学习的发展,哈希函数的学习嵌入到深度学习框架中。
随着卷积神经网络(convolutional neural networks,CNN)在图像分类、目标检测和文字识别等方面的优异表现,许多基于CNN的深度监督哈希方法相继提出。基于卷积神经网络的哈希算法(convolutional neural networks based hashing,CNNH)(Xia等,2014)是利用深度神经网络学习哈希码的早期工作之一。在CNNH的基础上,网中网哈希(network in network hashing,NINH)(Lai等,2015)提出了一种利用三重排序损失保持相对相似性的深层结构。之后,一些基于成对标签的深度哈希方法应用于相关任务中。深度成对监督哈希(deep pairwise supervised hashing,DPSH)(Li等,2016)在使用成对标签的同时学习特征表示和哈希函数。深度哈希网络(deep hashing network,DHN)(Zhu等,2016)优化了语义相似性损失和更紧凑的哈希码量化损失。为了更好地利用标签信息,深度监督离散哈希(deep supervised discrete hash,DSDH)(Li等,2017)综合了语义相似性损失和分类损失。对称式深度监督哈希方法目前取得了相对较好的效果,如果想进一步提升性能,可以使用更大规模的卷积神经网络。但是大规模模型的训练周期较长,并且待检索图像参与网络训练也会增加训练时间。为了解决上述问题,Jiang和Li(2018)提出了非对称深度监督哈希(asymmetric deep supervised hashing,ADSH),这是第1个以非对称方式学习训练图像和待检索图像哈希码的基于卷积神经网络实现的算法,待检索图像哈希码可直接由训练图像哈希码计算得到,这使得训练效率大幅提升。基于联合学习的深度监督哈希算法(joint learning based deep supervised hashing,JLDSH)(Gu等,2020)以ADSH为基础,将分类损失与哈希损失结合起来,更加充分利用了监督信息。
一些研究人员尝试将 Transformer(Vaswani等,2017)应用到计算机视觉领域。Transformer在自然语言处理任务中有着十分出色的表现,在机器翻译和语音识别等领域得到了广泛应用。主流方法大都是在大型文本语料库上进行预训练,然后在较小的特定任务数据集上进行微调。Transformer具有出色的计算效率和扩展性,使得训练规模庞大的模型成为可能。这些特性使得将Transformer应用于计算机视觉领域的研究变得流行起来。VIT(vision transformer)(Dosovitskiy等,2021)在图像分类领域有着突出表现,它将图像切成小块输入到Transformer中,并加入图像块的位置信息和分类位,经过Transformer编码器可以对图像进行分类,在海量的训练数据下,达到了很高的分类正确率,性能超过现有的分类模型。图像处理Transformer(image processing transformer,IPT)(Chen等,2021a)可以应用于图像去噪和超分辨率等图像处理任务,在大规模数据集上训练的该模型可在上述任务中获得最先进的性能。基于Transformer的端到端目标检测网络(detection transformer,DETR)(Carion等,2020)使用2进制匹配和Transformer编码器—解码器进行预测,极大简化了目标检测过程。
受VIT和ADSH的启发,本文提出了一种基于 Transformer的非对称监督深度哈希方法(asymmetric deep hashing method based on transformer,ADSHT)。本文的主要贡献如下:1)使用Transformer生成图像的哈希表示,结合非对称学习策略将Transformer应用到大规模图像检索任务中,在提高训练效率的同时,提升了检索性能。2)为了更加充分地利用监督信息,将哈希损失与分类损失相结合,使模型能够更好地学习哈希函数,使图像的哈希表示更加真实。3)在两个公开数据集CIFAR-10(Krizhevsky,2009)(该数据集为单标签数据集)和NUS-WIDE(Chua等,2009)(该数据集为多标签数据集)上进行实验,通过与主流的对称式方法和最优的非对称式方法进行比较,验证了所提出方法的有效性。
1 问题定义
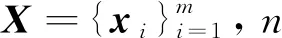
2 提出方法
2.1 模型架构
本文提出的ADSHT模型主要包括图像块嵌入部分、特征提取部分(Dosovitskiy等,2021)和损失函数部分(Gu等,2020),结构图如图1所示。特征提取模块是提取图像的特征,并将特征转换为哈希编码表示。损失函数部分是使图像特征更接近真实的哈希码,并保持查询图像与待检索图像的相似性。原始的Transformer只能处理1维数据。为了能够处理2维图像,本文将图像x∈RH×W×C重塑为一系列扁平的2维图像块xp∈RN×(P2×C)。H、W和C为原始图像的高度、宽度和通道数,(P,P)是每个图像块的高度和宽度,p为图像的序号。N=HW/P2是Transformer输入的序列长度。
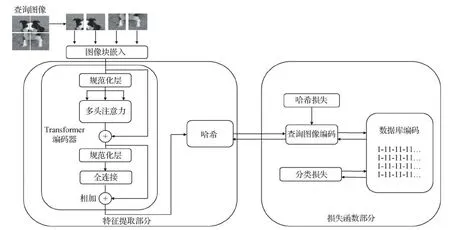
图1 ADSHT模型结构图
本文使用线性投影层E∈R(P2×C)×D将每个图像块向量映射到D维空间。随后,拼接所有图像块向量,使之成为一个完整的图像向量,并在该图像向量第1位加入分类位向量xclass。最后,将每个图像块的位置信息Epos∈R(N+1)×D与图像块向量xp相加,最终得到嵌入的图像向量sq∈R(N+1)×D。上述过程称为图像块嵌入,如图2所示。

图2 图像块嵌入
本文方法的特征提取部分使用Transformer的编码器模块,并在该模块后加入哈希模块。编码器模块在 ImageNet1k数据集上进行预训练,该模块由多层交替的多头注意力模块(multi-head self-attention,MSA)(Vaswani等,2017)和全连接模块(fully-connected network,MLP)组成,具体为

(1)
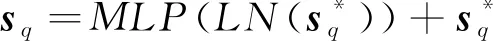
(2)
式中,B表示编码器模块的层数。在每个模块之前使用规范化层(layernorm,LN)(Wang等,2019),在每个模块之后均使用残差连接。最后通过哈希模块HASH输出图像的哈希表示h∈Rc,具体为
(3)
传统的对称式学习方法只利用监督信息获得相似矩阵,很少关注监督信息对图像的分类作用。本文对检索图像添加分类约束,充分利用监督信息,使待检索图像得到更真实的哈希表示。为了使损失函数最小化,在待检索图像哈希码与查询图像哈希码均不更新的情况下,对损失函数求导,计算分类损失函数参数。模型结束训练时,会输出查询图像的哈希码和分类损失函数的参数,令上述两个参数不更新,计算待检索图像的哈希码。
2.2 损失函数
为了更好地学习能够保持查询图像和待检索图像相似性的哈希码,可以优化监督信息的相似度矩阵与查询—待检索图像哈希码对的内积之间的损失。损失函数(Jiang和Li,2018)定义为

(4)
式中,qi=h(xi)很难学习,它分布是离散的,因此设置h(xi)=sign(F(xi;Θ)),F(xi;Θ)∈R,而h(xi)分布依然是离散的,很难通过反向传播来优化网络参数。其中,F(xi;Θ)是Transformer编码器网络的输出,Θ是该网络的参数。因此,本文使用tanh(F(xi;Θ))代替h(xi)来解决上述问题。ξ={1,2,…,n}表示所有待检索图像的索引值,Ω={1,2,…,m}⊆ξ表示所有查询图像的索引值。损失函数(Jiang和Li,2018)为
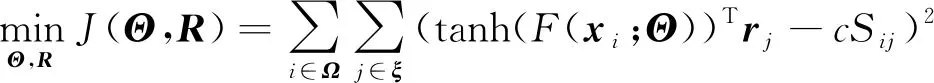
(5)
由于X⊆Y,xi有两种表示,分别是待检索图像中的2进制代码rj和查询图像中的2进制代码tanh(F(xi;Θ))。本文添加另一个约束来减少它们之间的差异。新的损失函数(Jiang和Li,2018)定义为

(6)
式中,γ是超参数。为了更好地利用监督信息,本文采用简单的线性分类器对检索图像的哈希码和对应的标签信息进行建模,利用标签信息约束待检索图像的哈希码的学习,让学习到的待检索图像哈希码更接近真实的哈希码。令L={i1,i2,i3,…,in}表示真实图像标签信息的One-hot编码。ii∈{0,1}h,i=1,…,n是每幅图像的标签信息组成的向量,h表示类别的数量。元素1表示图像包含此标签,元素0则相反。用W表示分类器的权重,将分类损失和哈希损失结合起来。最终的损失函数(Gu等,2020)为

(7)
式中,μ和φ为超参数。
2.3 优化方法
2.3.1 优化参数Θ
当R和W不改变时,令zi=F(xi;Θ),ui=tanh(F(xi;Θ)),zi的梯度计算为
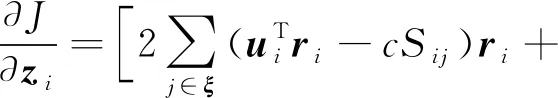
(8)

2.3.2 优化参数W
当Θ和R不改变时,式(7)变为
(9)
这是一个具有封闭解的最小化问题,对其求解,解得W为
(10)
式中,L代表真实图像标签信息的One-hot编码。
2.3.3 优化参数R
当Θ和W不改变时,式(7)变为
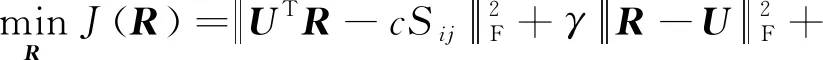
(11)

(12)
式(12)用来更新R。最后可以得到整个数据库对应的哈希码。
2.4 学习算法
ADSHT学习算法的具体步骤如下:
输出:待检索图像的哈希码R,神经网络参数Θ。
1)初始化Θ、R和W,批处理大小M,迭代次数Tout和Tin。
2)FORi→ToutDO;
(1)从待检索图像中随机选取查询图像X=YΩ,并获取查询图像的相似矩阵SΩ。
(2)FORj→TinDO;
FORs=1,2,…,m/MDO;
①从X中随机选取M幅图像,构建一次批处理。
②通过前向传播计算批处理中各幅图像的zi和ui。
③计算批处理的哈希损失,并根据式(8)计算梯度。
④根据反向传播算法更新网络参数Θ,并根据式(10)更新W。
3)FORk=1,2,…,cDO;
根据式(12)更新R*j。
3 实 验
3.1 数据集
CIFAR-10是单标签数据集,包含60 000幅图像,50 000幅为查询图像,10 000幅为测试图像,共10个类别,每个类别包含6 000幅图像,每幅图像的大小为32×32像素。NUS-WIDE是大规模图像检索任务常用的多标签数据集,包含269 648幅图像,共81个类别。
3.2 评价指标
实验采用全局平均精度(mean average precision,mAP)作为评价指标。mAP是图像检索中最重要的衡量模型检索性能的指标,是一组查询中每个查询的平均精度(AP)相加所取的平均值,定义为
(13)
式中,N表示数据集的大小,R是数据集中相关图像的数量,c是进行检索以后,数据集中返回图像的数量,Rc是前c中返回相关图像的数量,如果排名在第c位置的图像是相关的,则relc为1,否则为0(Zheng等,2020)。
3.3 实现细节
深度监督哈希算法大多基于对称式方法,少部分基于非对称式方法,目前非对称式方法都是基于CNN实现的。实验通过与目前最优的对称、非对称深度监督哈希算法对比,验证本文方法的性能。
在CIFAR-10数据集上,选择Transhash(Chen等,2021b)、ADSH(Jiang和Li,2018)、DBDH(deep balanced discrete hashing)(Zheng等,2020)、JLDSH(Gu等,2020)、DFH(deep Fisher hashing)(Li等,2019)、DSDH(Li等,2017)和DSHSD(deep supervised hashing based on stabe distribution)(Wu等,2019)进行对比。实验中,遵循Jiang和Li(2018)的方法,随机选取1 000 幅图像(每个类别100幅)用做测试集,其余59 000幅图像用做检索集,并从检索集中随机抽取5 000幅图像(每个类别500幅)作为训练集。
在NUS-WIDE数据集上,选择Transhash(Chen等,2021b)、ADSH(Jiang和Li,2018)、DBDH(Zheng等,2020)、DFH(Li等,2019)、DSDH(Li等,2017)和DSHSD(Wu等,2019)进行对比。与Li等人(2017)的方法类似,共选择195 969幅图像,包含21个常见类别,每个类别至少有5 000幅图像。实验随机选取2 100幅(每类100幅图像)作为测试集,其余图像作为检索集,并从检索集中随机抽取10 500幅(每类500幅图像)图像作为训练集。特别说明,mAP结果是基于NUS-WIDE数据集返回的Top-5K样本计算的。
实验参数参考Jiang和Li(2018)使用的参数,为了避免过拟合,权重衰减参数设为10-5。批处理数量为128,学习率的调试范围为[10-6,10-2],超参数γ为200,Tout为60,Tin为3。本文将S中元素-1的权重设为元素1的数量与元素-1的数量之比。
3.4 实验结果
ADSHT-R和ADSHT模型的提取特征模块分别为ResNet50网络和Transformer编码器网络。实验使用Tesla P40 GPU,两个模型都在ImageNet1k数据集上进行预训练,设置训练轮数为60,批处理大小为32,都使用随机梯度下降方法,超参数γ为200。两个模型在32位哈希码上的训练效率对比如表1所示。可以看出,在相同训练轮数下,ADSHT的参数量大约是ADSHT-R的13倍,但训练时间少于ADSHT-R,表明ADSHT的训练效率更高。

表1 不同网络下模型的效率对比
本文方法结合了分类损失函数和哈希损失函数,分类损失函数是式(7)的最后两项,超参数分别为μ和φ。若μ为0,则最小化分类权重为
(14)
这样求得的分类权重为0或任意值。若φ为0,则最小化分类权重为
(15)
超参数μ不会影响分类权重,在求解当中会被消掉。因此两项要一起存在,本文令p=φ/μ,对不同的p值(0,0.05,0.1,0.2,1,5,10,20)进行实验,得到的结果如图3所示,本文取φ=1。
从图3可以看出,在CIFAR-10数据集上,模型在p=0.2时,μ=5,得到最好的性能。在NUS-WIDE数据集上,在p=5时,μ=0.2,模型获得最好的性能。

图3 两个数据集的超参数取值
不同方法的检索性能如表2所示。ADSHT为仅使用哈希损失函数的模型,ADSHT-F代表结合分类损失函数的模型。从24位、32位和48位3种不同的哈希位数与其他方法对比,可以发现ADSHT-F在CIFAR-10和NUS-WIDE数据集上的mAP值都高于其他方法。尤其在CIFAR-10数据集上,与表中mAP值最高的JLDSH相比,ADSHT-F在24位时提升高达5.06%。在NUS-WIDE数据集上,ADSHT-F与ADSH相比,在24位时提升了4.17%。ADSHT-F模型相对于ADSHT模型,性能也有一定提升,说明监督信息得到充分利用,分类损失会产生一定贡献。从表2可以看出,随着哈希表示位数的增加,模型性能会逐渐提升,因为位数增加可以更好地表示图像特征。表中前5行的DSDH(Li等,2017)、DFH (Li等,2019)、DSHSD(Wu等,2019)、DBDH (Zheng等,2020)和Transhash(Chen 等,2021b)模型均使用对称式方法,第6—10行的JLDSH(Gu等,2020)、ADSH(Jiang和Li,2018)、ADSHT-R、ADSHT和ADSHT-F模型均使用非对称式方法,可以看出除了ADSHT-R模型因未完全收敛导致性能偏低以外,非对称式方法的性能明显优于对称式方法。将ADSHT与ADSHT-R对比,可以看出,ADSHT模型性能远高于ADSHT-R,并且从实验结果中可以观察到,训练轮数设置为60的情况下,ADSHT-R模型并没有完全收敛,因此其性能偏低。这也说明ADSHT模型的收敛速度快于ADSHT-R模型。
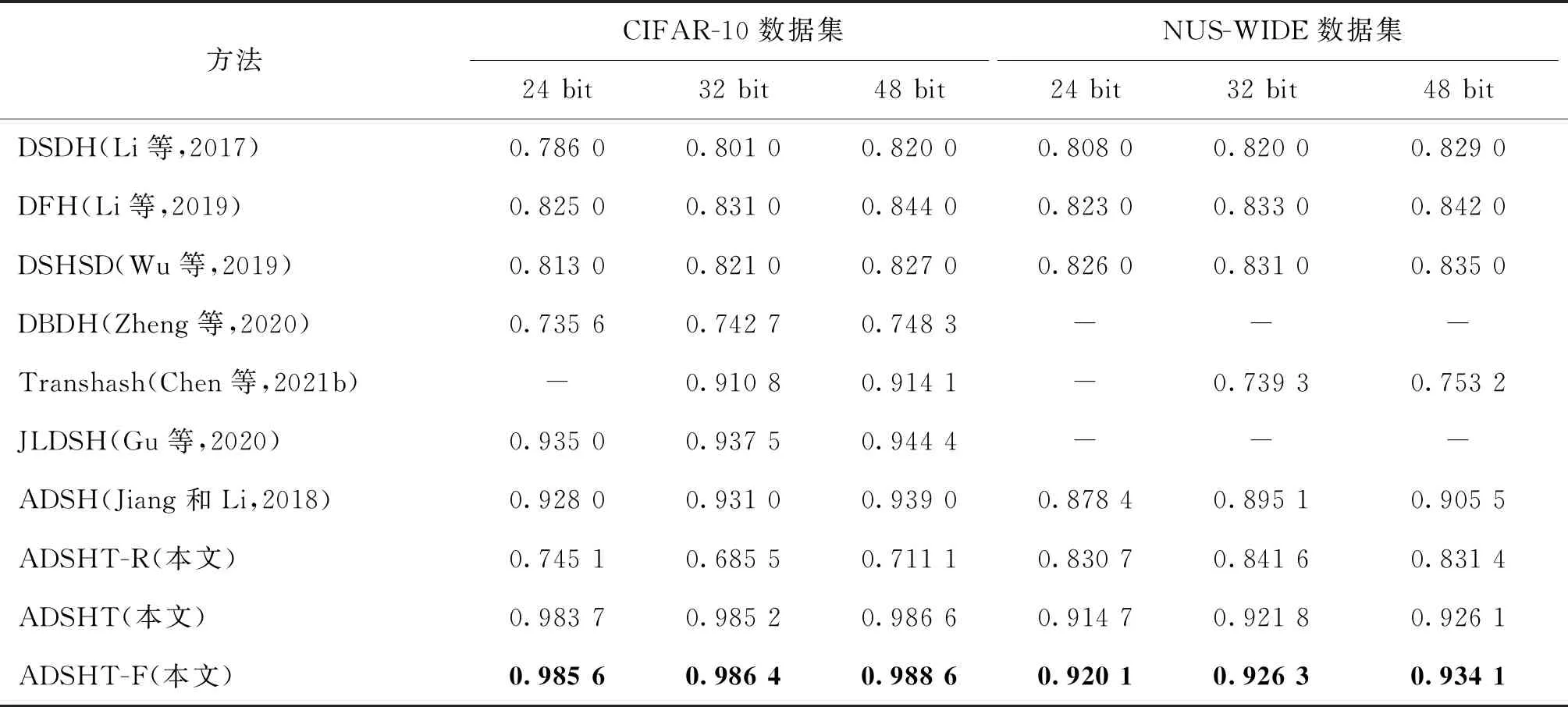
表2 不同方法的mAP对比
4 结 论
本文提出了一种Transformer与非对称学习策略相结合的图像检索方法。一方面,利用哈希损失学习哈希函数,并使用Transformer生成查询图像的哈希表示,使查询图像的哈希表示更加真实;另一方面,采用非对称式学习策略,根据查询图像的哈希表示与分类损失函数直接计算得到待检索图像的哈希表示。在此过程中,将哈希损失与分类损失相结合,充分利用监督信息,提高训练效率。与目前最优的对称、非对称深度监督哈希算法的对比实验表明,本文方法在CIFAR-10和NUS-WIDE数据集上均获得了最优性能,验证了本文方法的有效性。但是本文方法使用的Transformer模型未关注图像局部信息,且模型参数量较大,解决这些问题是后续工作的重点。
