基于多任务强化学习的堆垛机调度与库位推荐
2023-02-20饶东宁罗南岳
饶东宁,罗南岳
(广东工业大学 计算机学院,广州 510006)
0 概述
随着电子商务等行业的快速发展,物流订单井喷、土地成本快速上升,物流企业着手对仓储系统进行智能化管理。亚马逊研究开发了Kiva Systems 仓库机器人系统[1],使用数百个自动导航车代替了工作人员完成货物订单的存取任务,极大地提高了货物存取操作的效率。国内企业如京东、海康等先后实现了类Kiva 智能仓储系统并推广至国内市场[2]。
针对仓储中调度问题的建模与优化,很多学者进行了深入的研究。文献[3]针对仓库中的随机存储情况和不同类型的堆垛机,为每个存储或检索的位置选择了足够熟练的堆垛机,从而使得总使用时间最小化。于赫年等[4]通过分析多智能体调度系统的任务分配模式、作业流程及任务调度的约束条件,建立了以最小化任务完成时间为主要目标的数学模型。然而上述两种方法主要以时间作为优化目标,没有考虑到提高累计回报值。鲁建厦等[5]通过分析穿梭车仓储系统中的提升机与穿梭车的实际作业流程,建立了复合作业路径规划模型并通过人工鱼群算法求解,有效地提高了该仓储系统的运行效率。
尽管以上方法针对仓储中相关调度问题提出了解决方案,但库位问题方面依然存在不足。传统的库位分配通常基于人为经验,未充分考虑库位的使用状态和整体空间分布等,导致仓库管理效率下降。合理的库位安排,可以提高堆垛机的效率和可靠性,因此需要解决面向仓储的多任务问题。
堆垛机调度动作是基于时间步的动作序列,而强化学习常用于解决序列决策问题。为了实现对更大状态空间的问题实例进行更有效的求解,研究人员将深度学习的思想融入强化学习的算法中,并应用于该类调度问题中。
本文通过对堆垛机调度问题进行建模,构建仓储环境,并针对堆垛机调度问题,提出一种基于近端策略优化(Proximal Policy Optimization,PPO)[6]强化学习的调度方法。将调度问题视为序列决策问题,使智能体与环境进行持续交互,根据环境反馈不断优化动作的抉择,从而改善实验效果。针对调度中伴生的库位优化问题,提出一种基于多任务学习的调度、库位推荐联合算法,通过构建处理库位推荐的Actor 网络[7],使该网络与Critic 网络进行交互反馈,促进整体的联动和训练,以实现该算法在调度和库位问题场景下的应用。
1 研究背景
1.1 概率规划
概率规划[8]是人工智能的研究方向之一,描述的是马尔可夫决策问题,其主要特点是概率性和并行性,目标是最大化累计回报值。概率规划被应用于各类现实场景中。文献[9]基于概率规划的方法对股指模拟问题进行领域建模,并使用规划器求解问题。其中在国际概率规划比赛中表现最好的规划器为SOGBOFA[10]。
1.2 强化学习
随着人工智能的发展,研究人员提出了DQN(Deep Q-Networks)[11]、TRPO(Trust Region Policy Optimization)[12]等深度强化学习算法,并在移动机器人[13]、路径规划[14]、调度问题等应用场景中取得了较好的成果。例如,针对旅行商问题和有容量限制的车辆路径问题,文献[15]在关于路径问题的改进启发式算法上,构建一个基于自注意力机制的深度强化学习架构,该架构泛化性表现良好。文献[16]利用深度强化学习技术对适用于作业车间调度问题的优先调度规则进行自动学习,析取作业车间调度问题的图表示,根据该图表示提出了一种基于图神经网络的模式,并将其嵌入到状态空间。
强化学习的基本思想是使智能体在与环境交互过程中获得最大的累计回报值,从而不断优化自身动作的决策[17]。其理论基于马尔可夫决策过程,算法构成主要包括智能体、环境、状态、动作以及奖励等。智能体若处于状态st,根据策略函数得到动作at并施加于环境之上,获得返回奖励rt+1,期望回报Gt表示在γ折扣下估计的累计奖励。期望公式如下:

引入状态价值函数V(s)对Gt进行估计:

同时为了评价某一个状态或者动作的好坏,引入动作价值函数Q(s,a):
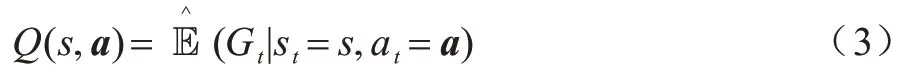
而针对动作a为离散的现象,可以将其松弛化为动作空间上的连续分布的采样。例如,用Softmax 将网络输出规范化为动作的概率分布,然后在此基础上采样动作并执行获得反馈。
1.3 近端策略优化
在可扩展性和鲁棒性等方面上,Q-Learning 在许多简单的连续问题上表现较差[18],而TRPO 相对复杂,并且与包含噪声或者参数共享的架构不兼容。因此,研究人员在策略梯度算法的基础上结合TRPO的优势,提出一种PPO 算法。
不同于基于Q值的强化学习算法,PPO 算法[6]将模型参数定义在策略函数[19]中:
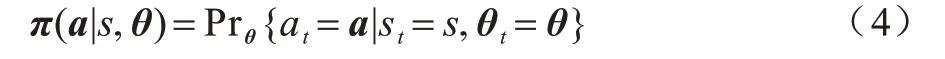
式(4)表示在t时刻状态为s,参数向量为θ时,模型选择动作a的概率。通过更新参数向量θt,可得到更优的策略函数,从而使得回报函数最大化。
但在训练过程中,不合适的学习率可能会导致较差的模型表现。为解决此问题,PPO 使用GAE 函数[20]对优势函数进行了多步估计,并利用衰减因子进行组合,将偏差控制到一定的范围内。k步优势估计公式和广义优势函数估计GAE(γ,λ)为:

同时,为了使该方法具有更高的数据效率性和鲁棒性,PPO 提出了包含裁剪概率比率的策略网络目标函数,该函数确保了策略性能的悲观估计(即下限)。令rt(θ)表示新旧策略概率比,即:

结合上述GAE 优势函数,PPO 提出的主要目标函数如下:
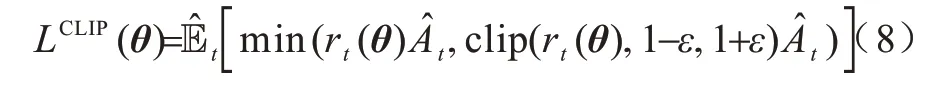
其中:clip(rt(θ),1-ε,1+ε)是裁剪函数,对新旧策略更新过大的情况进行裁剪,使得rt(θ)稳定在[1-ε,1+ε]区间。
1.4 多任务学习
传统的机器学习方法基于单任务学习的模式进行学习,处理复杂任务时会将其分解为多个独立的单任务,这种做法具有可行性,但忽略了任务之间的信息联系。通过任务之间的共享表示和信息联系,能够使模型更好地概括原始任务,这种方式称为多任务学习[21],其被应用于自然语言处理[22]、语音识别[23]、计算机视觉[24]和强化学习等各种领域。例如,针对三维装箱问题中较少的信息量和较大的动作空间的情况,YUAN等[25]将原始任务划分为序列、方向和位置3 个有信息联系的子任务,并基于深度强化学习的方法顺序处理3 个子任务,该算法采用了多模态编码器-解码器的架构。
本文通过深度强化学习的方法同时对堆垛机调度和库位推荐问题进行联合求解,其联合目标是在多问题环境中获得最大化累计回报值。
2 仓储问题
本文考虑了仓库货物存取的调度问题。三维仓储模型如图1 所示,整个仓库对象体系包含堆垛机(即小车)、通道、内外层库位、入库点和出库点。堆垛机在通道中移动并根据订单需求进行存货和取货,同时在入库点(出库点)进行入库(出库)。因此,堆垛机有关货物的动作分为2 类:1)装货,即将货物装入堆垛机中,包括上述的入库操作和取货操作;2)卸货,即从堆垛机中卸下货物,包括出库操作和存货操作。入库是指堆垛机从入库点载入货物,出库是指堆垛机在出库点卸下货物,存储货物是指将货物存储进库位中,取出货物是指从库位中拿出货物并置于车上。
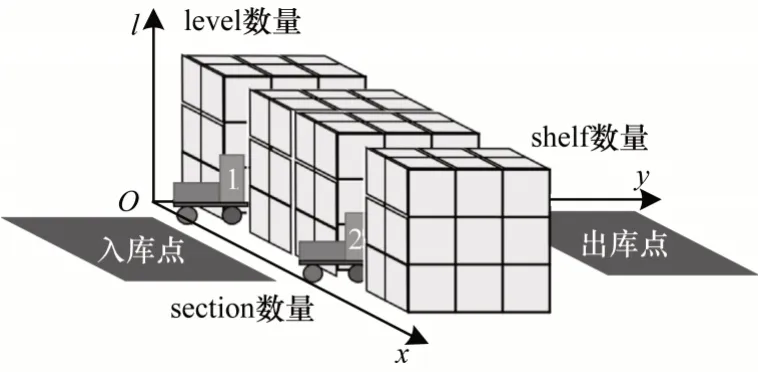
图1 三维仓储模型示意图Fig.1 Schematic diagram of 3D warehouse model
堆垛机调度问题的目标是以尽可能小的堆垛机运行代价满足尽可能多的订单存取需求,公式化为:

其中:、、、分别表示堆垛机每次运行的移动代价、执行代价、时间代价和成功装卸货物得到的收益。
移动代价是指堆垛机在仓储环境中移动的开销,即:

其中:nnums表示执行了该动作的堆垛机数量。
执行代价是指当堆垛机执行了装货和卸货操作时的开销,即:

其中:nnum是存取操作下的货物数量。
时间代价是指堆垛机没有执行操作时的空耗的开销,即:

堆垛机完成装货、卸货时都会获得相应的收益:

本节包含的常量及其释义如表1 所示。

表1 部分相关常量的对应含义 Table 1 Corresponding meanings of some of the related constants
3 模型构建
针对以上问题,本文对环境中的状态空间、动作空间和奖惩规则这三大要素进行了定义。
3.1 状态空间
状态空间是调度过程中所有状态的集合,状态特征是对状态属性的数值表示。可以将状态特征表示为一个三维矩阵的形式;第一维和第二维记录了仓库的平面信息,包括该平面层仓储库位的使用情况、出入库点位置和货物信息、堆垛机位置及承载情况;第三维主要记录了垂直方向的层信息。观测的信息包括:

与仓库相关的观测信息如下:
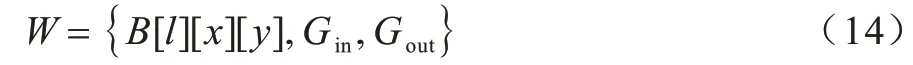
与堆垛机相关的观测信息如下:

最终智能体观察到的状态信息为:

3.2 动作空间
在堆垛机调度任务中,智能体可采取的动作为调度动作。在堆垛机调度和库位优化的联合任务中,智能体可采取的动作分为调度动作和库位动作两类。
3.2.1 调度动作空间
在堆垛机调度问题中,智能体执行的动作与堆垛机移动和货物存取操作相关联,共有以下5 类动作:
1)Idle:堆垛机在原地待命。
2)Forward:在通道中前进,方向为从入库点到出库点;若在通道中最靠近出库点的位置,则移动至出库点。
3)Backward:在通道中后退,方向为从出库点到入库点;若在通道中最靠近入库点的位置,则移动至入库点。
4)Load:在入库点的位置,将货物装入堆垛机中;若在通道中,则找到距离最近的待取货库位,从中取出货物。
5)Unload:在出库点的位置,堆垛机卸下货物;若在通道中,则找到距离最近的空余库位,并往库位中储存货物(就近原则只应用在调度环境中)。
调度动作以向量a=(ac1,ac2,…,aci,…,acN)形 式表示,aci是对应堆垛机ci的动作值,ci∈C。
3.2.2 库位动作空间
在调度和库位优化的双重问题中,调度动作Unload 进行存储货物的操作时,存储位置的选择由库位推荐网络来处理。库位优化的动作信息由向量(bc1,bc2,…,bci,…,bcN)表示,bci是对应堆垛机ci的库位动作值,bci∈{IL,AL,AR,IR},如图2 所示的IL、AL、AR 和IR,其物理意义如下:

图2 平面仓储模型示意图Fig.2 Schematic diagram of plane storage model
1)IL(Inner-Left):当前堆垛机的左侧货架中远离通道的库位。
2)AL(Aisle-Left):当前堆垛机的左侧货架中靠近通道的库位。
3)AR(Aisle-Right):当前堆垛机的右侧货架中靠近通道的库位。
4)IR(Inner-Right):当前堆垛机的右侧货架中远离通道的库位。
3.3 奖惩规则
在智能体与环境交互的过程中,奖励函数决定了环境对智能体的行为给出的反馈,该反馈用以指导智能体学习。令Action={Idle,Forward,Backward,Load,Unload}表示动作选项集合。基于式(9)的任务目标,对于智能体的动作a,本文定义其对应的反馈如下:

其中:cmovement为N辆堆垛机移动代价的总和;caction是执行代价的总和;ctime是时间代价的总和。计算公式分别如下:

其中:l表示货架层数,当l为0时,对应的是入库(出库)代价。

g是装货、卸货收益的总和:

其中:nnum指的是成功处理的货物数量。
4 网络模型设计
4.1 整体结构
继承于Actor-Critic(AC)架构,基于PPO 强化学习算法的堆垛机调度网络分为调度Actor 网络和Critic 网络,如图3 所示,下文简称为调度网络。
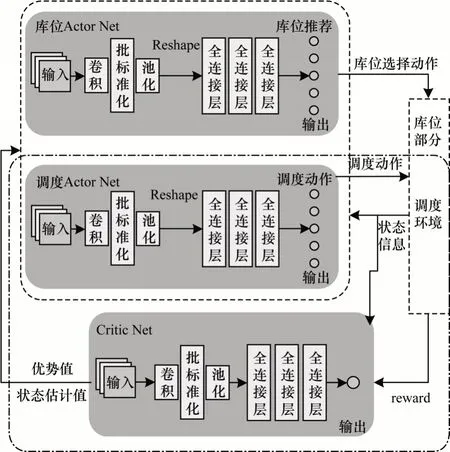
图3 网络模型整体架构Fig.3 Overall architecture of network model
在多任务的情况下,除堆垛机调度外,还包括库位推荐。所以,在原有的AC 框架下,本文引入了额外的库位Actor 网络用于库位推荐,整体对应的是基于多任务强化学习的调度、库位推荐联合算法的网络模型,简写为多任务网络。
4.2 堆垛机调度网络
4.2.1 网络架构设计
根据目标函数式(8),构造一个Actor 网络来生成调度行为策略,即图3 中的调度Actor 网络。网络的输入为3.1 节提到的状态空间S,网络的输出为调度动作的概率向量。
构造一个Critic 网络用于表示状态值函数,网络的输入为状态空间S,网络的输出为对应状态的状态估计值。
4.2.2 Actor 和Critic 网络设计
在强化学习中,策略网络和值函数网络通常是少量的全连接层或者全卷积层,因为过于复杂的网络层数会造成模型难以收敛。例如,PPO 在多个实验中使用了两层各64 个单元的全连接层。
仓储问题环境具有三维状态空间信息的特点,状态空间记录了入库点信息、货物信息等。每个库位状态表示具有相似性,所以在类似的库位状态下可以采用类似的策略安排货物,而卷积可以对相似空间中的明显数值特征进行提取。因此,本文在输入层后加入了卷积层和池化层。
同时为了简化计算过程、并保证网络的输入固定在一定范围内,缓解梯度消失,加速模型收敛,本文引入批标准化[26]处理,用以规范化网络的输入。基于卷积层和批标准化层的引入,本文调度网络模型命名为PPO-CB。如图3 中的调度Actor 网络和Critic 网络所示。
4.2.3 动作策略函数
为了使调度问题中的输出更具有稳定性,本文在PPO 算法的基础上,用Log-Softmax 函数重新定义目标函数中的策略函数,公式如下:

其中:φ(s,a)表示与状态和动作输入相关的向量;πθ表示参数向量;N为动作选项的总数。
基于该动作策略函数,调度动作从概率分布中进行采样。相较于Softmax 方法定义的策略函数,Log-Softmax 函数在数值稳定性、优化性和惩罚等方面有更好的表现。
与其他深度强化学习算法类似,PPO 算法也采用了缓冲库(Buffer)的思想。在每轮网络开始训练之前,将上一轮训练后的动作策略与环境进行交互,从而获取样本数据,同时计算状态估计值和优势值,最终将以上相关数据存储至缓冲库中,以备训练需求。另外,在本轮训练结束后,会清空缓冲库中所有数据。
相比较其他基于缓冲库的算法,PPO 算法根据裁剪目标函数有效地避免了训练前后策略差异过大的情况,从而提升了采样效率。
4.2.4 算法流程
基于PPO 的堆垛机调度算法主要内容包括:1)收集智能体在仓储环境中的交互数据,并存储至缓冲库中;2)多次调用缓冲库中的数据并反向训练神经网络,以获得良好的调度策略。
算法1基于PPO 的堆垛机调度算法
输入初始环境信息S0,训练迭代次数K,学习率η,超参数γ、ε
输出Actor 网络参数θ,Critic 网络参数φ
1.初始化Actor 网络的策略参数θ0和Critic 网络的值函数参数φ0,初始化数据缓冲库,大小为M。
2.从第k 次回合开始进行迭代(k=0,1,…,K)。
3.初始化累计回报值为0,初始化入库点货物数量、堆垛机初始位置和货架库位等信息。
4.在环境中运行策略,与环境交互输出动作,获得对应的奖励,计算状态估计值和优势估计值,并在缓冲库中存储当前状态动作序列和相关数值。根据以上步骤收集容量为M 的数据量。
5.从缓冲库中读取样本数据。通过最大化目标函数来更新策略,并得到参数θk+1,此处使用随机梯度上升的方法;通过均方误差函数来回归拟合值函数,并得到参数φk+1,此处使用梯度下降的方法。
6.结束当前回合,进入下一个回合。
7.结束。
4.3 多任务学习网络
4.3.1 网络架构设计
库位推荐的网络同样是一个策略网络,因此,构建一个Actor 网络来生成库位推荐的策略。网络的输入为多任务问题环境中观察到的状态空间,网络的输出为库位动作的概率向量。在多任务问题下,环境除了堆垛机调度之外还包含了库位相关因素。
在多任务环境(即包含堆垛机调度和库位问题的环境)中,两个任务是互相影响的个体,调度Actor网络和库位Actor 网络与状态值函数的Critic 网络有着直接的关联。
当智能体选择的调度动作为Unload(且为存储货物)时,库位Actor 网络根据环境中状态信息输出位置推荐,共同对环境施加影响,进而得到reward 反馈;Critic 网络根据reward 值进行状态值的估计和优势值的计算。同时,该状态估计值和估计优势值会作为相关反馈值,参与到两个Actor 网络的目标函数的参数训练,整体过程如图3 所示。本文多任务网络模型命名为PPO-CB-store。
4.3.2 算法流程
基于多任务学习的调度、库位推荐联合算法主要内容包括:1)初始化双Actor 网络和Critic 网络参数,构建多任务网络架构;2)库位动作和调度动作产生联动关系,并收集智能体在多任务问题环境中的交互数据,存储至缓冲库中;3)多次调用缓冲库中数据并训练神经网络,以获得基于堆垛机调度和库位推荐的策略。
算法2基于多任务学习的堆垛机调度和库位推荐算法


5 实验与结果分析
5.1 实验环境和网络参数设置
本文算法基于Python 语言与Tensorflow2.5 框架实现,并基于OpenAI-Gym 库对仓储环境和堆垛机调度及库位问题进行建模。
在本文模型的网络结构中,Actor 网络第1 层为输入层,接着是卷积层、标准化层、池化层,之后是三层全连接层和输出层。Critic 网络的后半部分对应的是2 个全连接层,最终输出的是状态估计值,如图3 所示。参数设置如表2 所示。

表2 网络模型的部分参数设置 Table 2 Some parameter settings of the network model
5.2 问题环境设置
实验主要分为调度问题实验和多任务问题实验2 个部分。相对应的环境实例有调度环境和多任务问题环境2类。环境中的部分参数设置如表3所示。
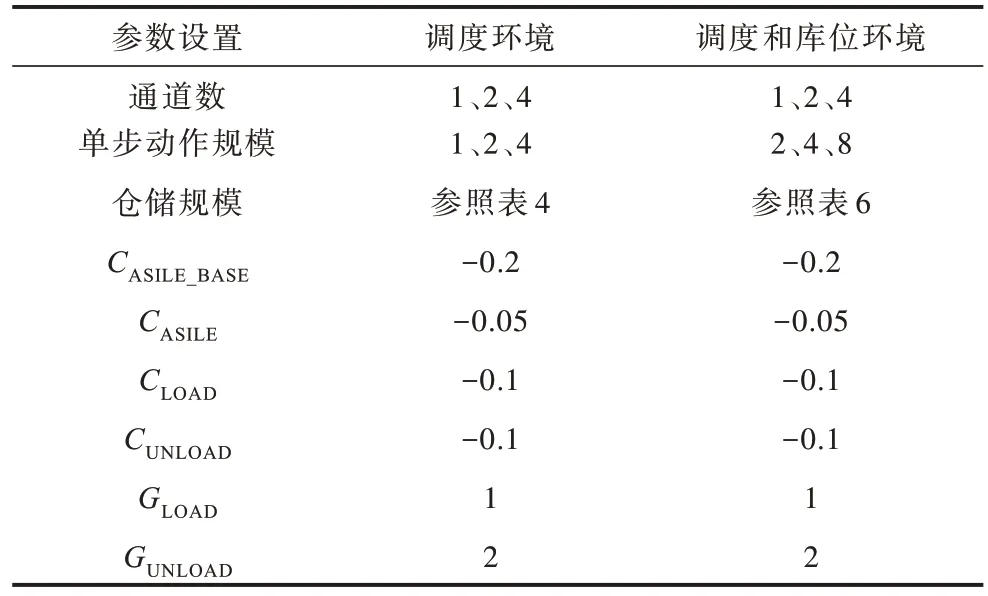
表3 仓储环境参数设置 Table 3 Parameter Settings of environment parameters
调度环境对应的动作信息为调度动作空间,实例标识为“level 数量×section数量×shelf数量”,以图1 为例,该仓储环境实例有3 层货架(level 数量为3)、2 条通道和8 排货架(总和section 数量为10),每个通道对应4 排货架,即两侧各有2 排内外层的货架;每排货架各有3 个库位(shelf 数量为3),将其标识为“3×10×3”。
多任务问题环境对应的动作信息为调度动作空间和库位动作空间,加前缀“S-”表示。
5.3 堆垛机调度实验分析
为验证调度模型算法的有效性,对表4 中所有实例进行实验,改进模型算法在表中标记为PPOCB。其中,PPO-CB、PPO 对每个实例分别进行训练以及测试。在当前实验中,最大累计回报信息作为评价指标。选用Ran(随机采样方法)、基于概率规划的SOG 算法、粒子群优化算法PSO、PPO 与本文算法进行比较。在粒子群优化算法[27]中,初始种群大小为200,最大迭代次数为1 000。算例实验对比情况如表4 所示,其中,最优调度结果以粗体显示,—表示计算时间严重超时,无法求解。同时为了验证改进网络中新增的不同因素带来的影响,对基于批标准化的PPO 模型和基于卷积的PPO 模型分别进行实验,分别标记为PPO(BN)和PPO(CNN)。相较于PPO-CB,PPO(BN)不包括卷积和池化层,PPO(CNN)不包括批标准化层。
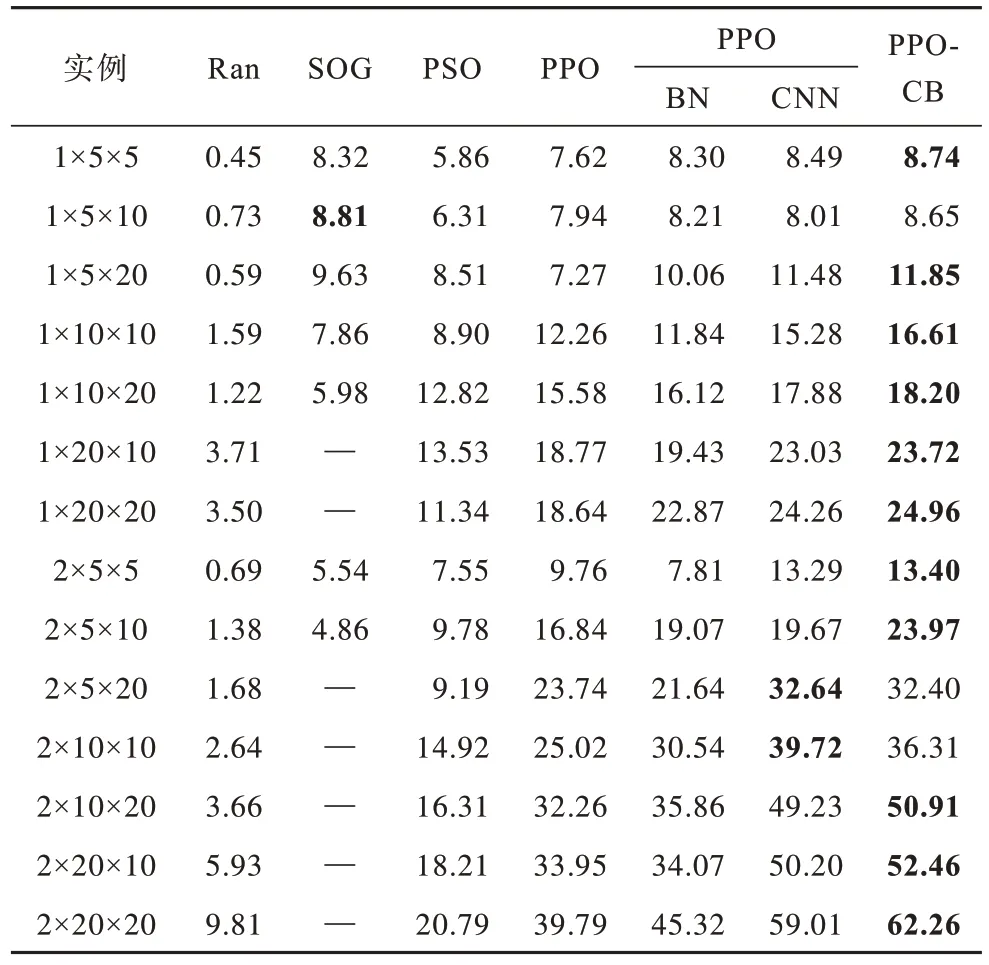
表4 调度问题实验结果对比 Table 4 Comparison of experimental results of scheduling problems
分析表4 可知,本文方法模型PPO-CB 在实例环境中的表现明显优于基础的Ran 算法。同时相较于原PPO 算法模型,本文模型虽然在1×5×5 和1×5×10实例中与原方法差距不大,但在其他实例环境中都有明显的提升。基于概率规划的SOG 算法在前两个小型实例环境中取得较好的效果,但在更大状态空间的实例环境中,效果逐渐趋同于Ran 算法,甚至无法求解。本文算法模型相较于粒子群算法PSO,在所有实例中都有着不同程度的提升,尤其是在2×10×20、2×20×10 和2×20×20 的实例中提升较大。
在不同因素的验证实验中,相较于原PPO 算法模型,PPO(BN)虽然在1×10×10、2×5×5 和2×5×20 实例环境略差于原算法模型,但在其他大多数环境中都能高于原算法模型,程度不一;而PPO(CNN)在大多数环境中,表现效果都为良好。
由表4 可知,在2×10×20 实例中,PPO-CB相较于原算法模型,其平均累计回报值提升最为明显,提升了58%,其随着迭代次数的增加逐渐收敛于较高的回报值,如图4 所示。在1×5×10 实例中,PPO-CB的提升效果最弱,其收敛曲线略微高于原方法,平均累计回报值只提升了8.9%,如图5 所示。综合表4 中所有实例的数据,可计算得到PPO-CB 相较于原PPO算法能收敛于更高的累计回报值,平均提升了33.6%。
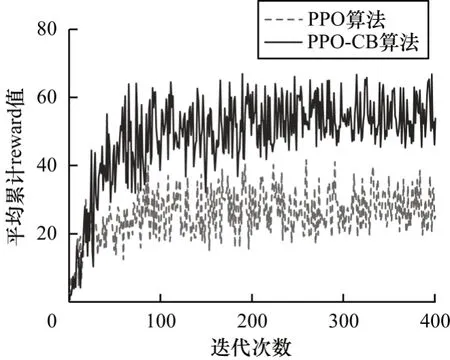
图4 2×10×20 调度问题实例中累计回报值的训练迭代对比Fig.4 Training iteration comparison of cumulative reward values in 2×10×20 scheduling problem instances
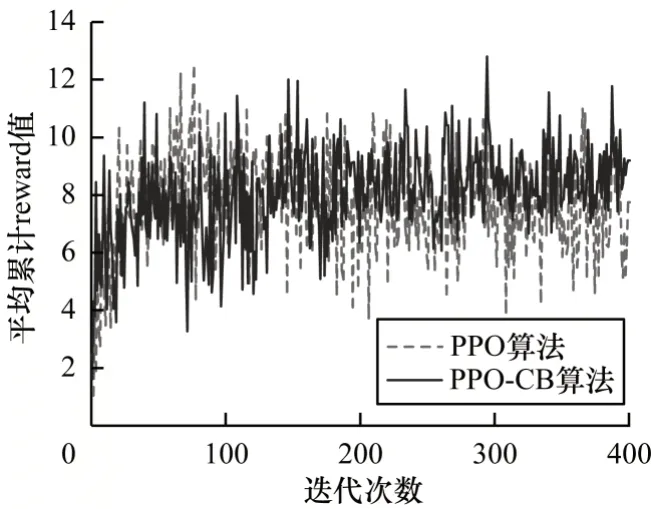
图5 1×5×10 调度问题实例中累计回报值的训练迭代对比Fig.5 Training iteration comparison of cumulative reward values in 1×5×10 scheduling problem instances
在本文实验中,实例输入的状态空间与对应仓库环境大小呈正相关,同时动作空间的大小与对应环境中的堆垛机通道数量有直接关联,所以不同实例之间的状态、动作空间的规模差别较大。例如,实例1×5×10 与1×20×20 之间的库位数量相差了16倍,通道数量相差了4倍。因此,在面向模型训练时,不同实例的输入输出规模均不相同,所以需要对每个实例分别进行训练和测试。
在基于不同方法的实验时间对比中,PPO 类算法整体求解时间明显比常规方法较长,因为需要对实例进行训练。相较于原PPO 算法模型,PPO-CB 相对复杂的网络架构导致训练时间更长,其最短训练时间为34 min,最长为63 min,如表5 所示。
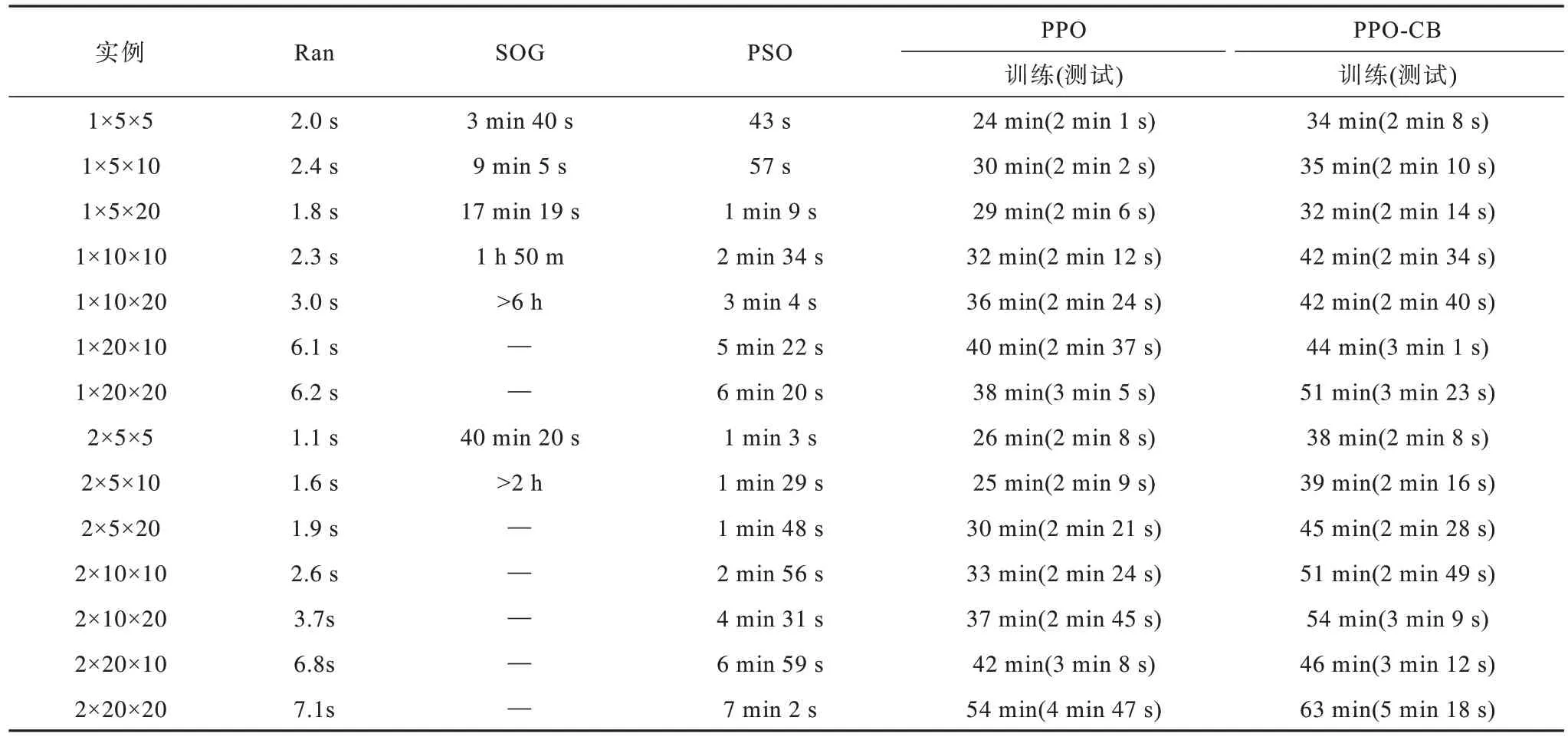
表5 实验平均时间对比 Table 5 Comparison of experimental mean time
综合而言,本文提出的改进模型算法在大多数实例环境中表现良好,同时可以对较大状态空间的实例环境进行求解。
5.4 调度和库位问题实验分析
为验证多任务模型算法的可行性,对表6 中实例进行实验,多任务模型在表中标记为PPO-CB-store。在当前实验中,最大累计回报值作为评价指标。在该部分实验,主要验证该算法的可行性。选用Ran(随机采样方法)作为对比,实验效果情况如表6 所示,其中最优调度结果用粗体显示。

表6 多任务问题实验结果对比 Table 6 Experimental results for multi-task problems
由表6 分析可知,PPO-CB-store 在实例环境中能够有正面的效果表现,且相对于Ran 这种基础的抽样方法有着明显的提升。同时随着实例规模的扩大,PPO-CB-store 依然能够求解实例问题,验证了该方法的可行性。
图6和图7 分别为PPO-CB-store 在2×10×10 和2×10×20 实例环境中累计回报值随迭代次数变化的曲线。

图6 2×10×10 多任务问题实例中累计回报值的迭代对比Fig.6 Iteration comparison of cumulative reward values in 2×10×10 multi-task problem instances

图7 2×10×20 多任务问题实例中累计回报值的迭代对比Fig.7 Iteration comparison of cumulative reward values in 2×10×20 multi-task problem instances
从图6 和图7 中分析可知:PPO-CB-store 在迭代过程中可以收敛至较高的累计回报值,并且能有效地应对调度和库位优化的多任务场景。
6 结束语
本文针对仓储环境问题进行建模,提出一种基于深度强化学习算法的堆垛机调度算法,来实现仓储环境问题在PPO 强化学习算法中的应用,同时针对仓储系统中衍生的库位优化问题,提出基于多任务学习的算法模型,并通过实验验证了该模型的可行性,为该类多任务问题提供一个有效的解决方案。由于不同实例的状态空间规模不相同,因此在求解时间方面仍存在不足,下一步将考虑引入编码器-解码器架构,使单个网络模型能够对多个实例进行训练,从而减少重复训练,并将模型迁移到未曾训练过的实例中实现模型的复用,以从根本上降低求解时间。
